

JetBrains AI
Supercharge your tools with AI-powered features inside many JetBrains products
Introducing a Recommended Agent in AI Chat, With Codex as the Current Default

JetBrains AI supports multiple coding agents, including Junie, Codex, Claude Agent, and any ACP-compatible agent you bring yourself. Previously, AI users in JetBrains IDEs started in Chat mode and had to choose an agent themselves.
As models became more advanced, agents became more capable and their adoption grew. We recognize that agents help users achieve more, so we recommend using an agent from the get-go.
To make that experience simpler, we’ve selected a specific agent to be the default. This post explains how we made the choice.
You can still switch to any other agent at any time.
“JetBrains evaluated coding agents on the things that matter in practice: Can they solve real software engineering tasks, quickly, and at a cost that makes sense? We’re proud that Codex is the recommended starting point in JetBrains AI. It’s a meaningful step in the shift from AI chat to agents that meet developers where they are, work in the tools they already use, and take on complex, multi-step work.”
Stuart McMeechan, EMEA Deployment Engineering Lead, OpenAI
Evaluation using real-world development tasks
We evaluated candidate agents using a benchmark dataset built from real software engineering tasks across three ecosystems: Java (225 tasks), C# (38 tasks), and Python (90 tasks).
Each task is grounded in a real codebase, with a prompt describing what needs to be done and automated tests that verify the result. Together, these tasks cover bug fixes, feature development, enhancements, and other common development tasks across real applications, libraries, frameworks, and developer tools.
Data points used for choosing the recommended agent are accessible in the Developer Productivity AI Arena (DPAIA) repository – JetBrains’ open benchmark for evaluating AI coding tools, making the evaluation reproducible. The C# dataset is internal and not publicly available.
The Java dataset was our primary evaluation set. It’s the largest of the three, spanning 17 repositories across five organizations and covering a broad mix of task types.
The С# and Python datasets produced a similar overall ranking of candidate agents, giving us additional confidence that the results were not specific to a single ecosystem.
Our methodology
We compared candidates within the same model tier. Our goal was not to find the most powerful model available, but the best agent behavior at comparable model capability and cost. We projected what agent usage would cost, taking into account JetBrains AI token usage. Setups that would push more than 2% of users over $20/month were ruled out before we ranked candidates on quality and latency.
In choosing which agent to recommend, we focused on three questions:
- Can it handle the task? → Here, we measured by solve rate – the percentage of benchmark tasks where all tests passed.
- Is the cost reasonable? → We looked at the median cost per task.
- Is it fast enough? → We looked at median end-to-end latency.
These three metrics (solve rate, cost, and latency) formed the basis of our ranking. We also tracked additional signals, including compilation success and average tool calls, but they did not materially affect the results.
Alongside the offline benchmark, we ran an online A/B test with real users. This experiment served as a validation layer, helping us understand whether the offline results translated into real-world usage. Because it’s difficult to measure task success reliably at scale, we focused on behavioral signals, such as engagement and how often users switched to another agent or returned to the chat. The online results were consistent with the offline benchmark, giving us additional confidence in our choice.
Candidate configurations
We tested agents available with JetBrains AI (Codex, Junie, and Claude Agent) across multiple model configurations. Candidates were selected based on prior benchmarking and internal assessment; we focused on the most promising options within each agent’s model family rather than testing every possible setup. Eventually, Codex and Junie were shortlisted.
Codex – we started with an initial sweep across GPT-5.2 and GPT-5.3. When GPT-5.4 mini became available, it outshined the previous top performer in terms of both solve rate and cost, making the model choice straightforward. The remaining question was reasoning level: medium vs. low. GPT-5.4 mini with default medium reasoning had the best solve rate within reasonable cost range across all three ecosystems and was selected for the final evaluation.
Junie – Junie can work with different model providers. We evaluated the Gemini model family, pre-selected based on the Junie team's own benchmarks as the most promising options. Gemini 3 Flash was selected as the winning model.
Final showdown: Junie vs Codex
The offline results were too close to call on their own. Neither agent dominated across all metrics and ecosystems.
We included both in an online A/B test to see which held up better in real-world usage. We tracked activation, churn, and failure rate. Codex came out ahead. That tipped the decision.
Junie still remains the best JetBrains-native agent for IDE-deep workflows, Java-heavy projects, BYOK setups and cost-sensitive teams.
What's next for the recommended agent
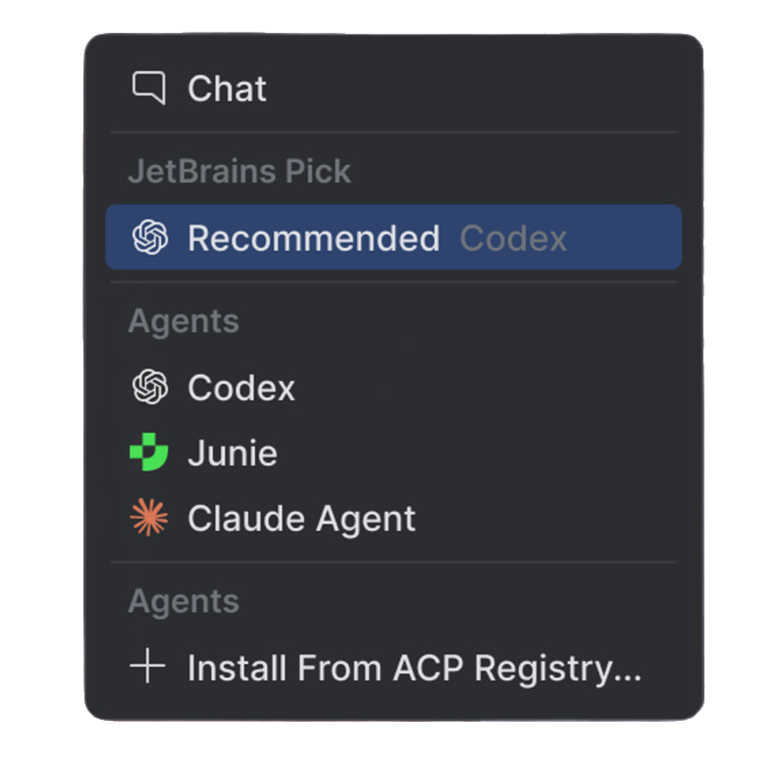
Codex is now the recommended agent, having delivered the strongest combination of solve rate and cost across the tasks we tested. This isn't a permanent decision, however. As models evolve, new agents join, and our benchmark coverage grows, we'll re-evaluate the decision and update our recommendation based on what the data tells us.
And if a different agent works better for your workflow, you can switch at any time. Our recommendation is a starting point, not a constraint.
Disclaimer: As GPT5.6 has recently been released we are also running new evaluations. If this model version turns out to be better we will update the recommended agent to use this model.






