A new way to compile

Together with the IDEA 12 release Scala plugin brings a brand new Scala compilation subsystem. Here are the main updates:
- The compilation is now “external”.
- Incremental compilation is now handled by SBT (instead of IDEA itself).
- Compile server is now implemented via Nailgun (instead of FSC).
Of course, a lot of explanations is needed to clarify all the details.
External build
External build is a one of the major features of IntelliJ IDEA 12.
External build implies that all compilation tasks (including project model interpretation) are performed in a separate process, fully isolated from the main IDE’s process.
As a result, we can:
- lower IDEA memory consumption and free its garbage collector;
- reduce load on IDEA’s code model (PSI) and virtual file system (VFS);
- speedup compilation (according to this and that).
Now we can compile IDEA projects without running IDEA itself, e. g. from command line or from build tools (like Ant, Maven, etc.).
An additional benefit is an ability to use an automatic background compilation, so that your project will be kept in compiled state all the time.
Background compilation can be also used as a means to reveal code errors when type-aware highlighting can’t keep up with code complexity.
For more information on external build you may check the Brand New Compiler Mode in IntelliJ IDEA 12 blog post.
SBT compiler
Although “SBT compiler” sounds like a completely new kind of Scala compiler, that is not really so. To see what SBT compiler is and how it fits into Scala compilation, let’s start with a “big picture”.
Here are the main tasks we need to perform during Scala project compilation:
- We need to compile source code to bytecode (and to search for all kind of errors along the way). This task is always performed by Scalac (or Javac, for Java sources) no matter what tool is used to invoke it (IDE, SBT, Maven, Ant, Zinc or whatnot). So, Scalac (and Javac) is the actual “true” compiler, however it knows nothing about project structure, incremental compilation and so on. All it can do is to take a list of source files and produce a set of corresponding compiled classes.
- We need to perform compilation incrementally (as opposed to compiling all sources all the time). Strictly speaking, this task is not required for project compilation (and it can even slow down a full project build). The whole point here is to save time during subsequent compilations. To do that, we need to track code changes and re-compile only affected files. And it is harder than it sounds — we need to monitor timestamps, store source-to-output mappings, check for public API changes, analyze direct and transitive dependencies (including ones between Scala and Java) and so on. There are not many tools capable of such a feat, and that is exactly what SBT “compiler” (as well as IDEA) does.
- We need to compile project parts according to project structure i. e. to split project into separate, possibly dependent, modules of various types (test, production, resources, etc.), devise compilation order, apply compiler settings, provide required libraries and so on. Each tool (like IDEs, SBT, Maven, etc.) uses its own way of describing and storing project information.
So, bytecode is still generated by Scalac (and Javac), project format is still IDEA’s, but incremental compilation is now handled by SBT instead of IDEA (so, we don’t use SBT project model, only SBT compiler, that acts as a wrapper around Scalac).
What’s the point of such an update? – Because there is a qualitative difference between how IDEA and SBT discover dependencies and process changes.
IDEA analysis is bytecode-based and language-agnostic. While it’s a very fine-grained, robust and time-proved method, there may be some rare unexpected glitches, specific to Scala code.
For example, let’s define a class C (in C.scala):
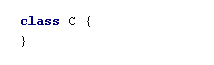
and then “add” a method name via an implicit conversion (in Main.scala):

After we compile and run the main method, we will see that the output is “foo”, and that’s what we expect it to be.
Then, let’s add a “real” method name to the class C:
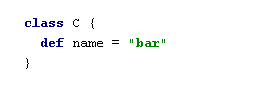
After the next compilation, we will discover that the output is … still “foo”, and that is is not what we expected… Why so? – Because, in terms of the bytecode, there’s no need to recompile Main class yet.
There are many additional cases (for example, related to named- and default parameters) which demonstrate, that bytecode analysis is not enough for proper incremental compilation of Scala code.
That is where SBT compiler comes to rescue, because it relies on source-based analysis of compiled code (to do that, SBT intercepts internal Scala compiler data), so it can take account of Scala-specific details to perform incremental compilation correctly (though SBT analysis of Java classes is still bytecode-based).
As a bonus, because SBT uses a so-called compiler interface layer to communicate with the Scala compiler, we can now run multiple versions of in-process Scala compilers in the same JVM. That’s how we can:
- reap the benefit of JIT compilation (either during compilation of multiple modules or when using a compile server),
- avoid creation of temporary files (with compiler arguments),
- avoid compiler output parsing,
- make compiler JVM parameters (in Scala facet) obsolete.
It’s worth noting, that there is a one side-effect of using SBT compiler, resulting in how Java files are handled in Scala projects (ones with a least one Scala facet). Because we need to maintain a coherent model of dependencies, compilation of all Java files, event in “pure” Java modules, is routed through SBT. For most use cases that is perfectly OK, unless you need to use a non-standard Java compiler (by the way, SBT supports in-process Java compiler as well).
For more information on SBT compiler you may check Understanding Incremental Recompilation article in SBT documentation.
New compile server
Scala compiler is a quite complex piece of software, so it takes time to load and initialize it. When you compile a project with hundreds (or thousands) of files, this time is negligible comparing to the time needed to compile the code. However, when incremental compilation is used, and all you need is to re-compile a few files, it may take longer to warm-up a Scala compiler than to actually compile those files.
One solution to this problem is to run Scala compiler in-process to avoid compiler re-instantiation when compiling subsequent modules. This, however, still cannot liberate us form a first compiler initialization. To speedup compilation further, we need to use a pre-initialized compiler instance, and that is exactly what compile server does.
Originally, Scala compile server was implemented via FSC (Fast Scala Compiler). While it works well enough, it has several limitations:
- FSC instance is bound to a single compiler version, so compile server settings were a part of project configuration and FSC instances are not shared between projects.
- Because FSC reuses symbol table between runs, it sometimes might produce various errors during compilation.
Now, because of our newfound ability to run multiple versions of Scala compiler in a single JVM, we can do better than that. New compile server is implemented using Nailgun (basically, it’s just a JVM process that can be accessed via a TCP/IP connection), so:
- It is now a matter of personal preference whether or not to use a compile server. Compile server configuration is moved from project settings to application settings.
- Compile server is now application-wide – it is reused for multiple compiler versions and shared between all projects (so we can save a lot of RAM).
Compile server configuration is now located in Settings / Scala:

It’s recommended to use the following JVM parameters for the Scala compile server:
-server– to maximize peak operating speed (for the price of longer start-up time) and to encourage soft references retention (that we use to cache compiler instances).-XX:MaxPermSize=256m– to provide enough memory for loading of multiple sets of compiler classes.-Xss1m– to ensure that there will be enough stack space for recursive code in Scala compiler.
If compile server is not used, it’s still recommended to use the same parameters (except, maybe, -server) in Project Settings / Compiler / Additional compiler process VM options.
How all this is related to Zinc
Zinc is a stand-alone launcher for SBT incremental compiler (and Nailgun server). It was created, primarily, to be used in command line tools (like Scala Maven Plugin).
Because both Zinc and the new compilation subsystem use the same tools and techniques, they are essentially equivalent. There is not much sense in using a launcher from another launcher, so we run both SBT compiler and Nailgun directly, rather than via Zinc.
Besides, we need much more data from the compiler (to display compilation messages, report progress, compile UI forms, run annotation processors, etc.) which is not available from Zinc output. Zinc’s Nailgun server also cannot be used by IDEA because its process is started without IDEA-specific classes (communication protocol) in JVM classpath.
As Zinc cannot build a project by itself, it must be invoked from another tool (like Maven), which stores all incremental compilation data using its own scheme, that differs from IDEA’s one. So, currently we cannot unite IDEA’s and Zinc/Maven’s incremental compilation even though they are very much alike.
Summary
Let’s sum-up all the advantages of the new Scala compilation subsystem:
- Less load on IDEA process.
- External project build.
- Background compilation.
- Source-based incremental compilation.
- In-process Scala and Java compilers.
- Simplified project configuration.
- Application-wide compile server.
There must be a catch in it somewhere, you know… And here it is – because the new compilation subsystem is written completely from scratch, some bugs are simply inevitable. Please, report them so we can fix them as soon as possible.
Keep in mind, that the previous compilation subsystem is still available, and can be always turned on by clearing “Use external build” checkbox in Project Settings / Compiler page:

You may also check there whether the external build is enabled in your existing projects.
For those who want to know even more details, here is source code for all the tools: