

Big Data Tools
A data engineering plugin
Big Data Tools 2023.1 现已发布!

我们的最新版本包含多项新功能和基于用户反馈的改进。 在此版本中,我们在 Big Data Tools 中添加了与 Kafka 架构注册表、Kerberos 身份验证的集成,并扩展了对所有云存储的支持。 继续阅读以了解 Big Data Tools 插件中最重要的变化,或者通过将其安装到 IntelliJ IDEA Ultimate、PyCharm Professional、DataSpell 或 DataGrip 2023.1 以立即试用。
新功能:Kafka 架构注册表连接
应大量请求,我们已将 Kafka 架构注册表连接集成到 2023.1 版本的 Big Data Tools 插件中。 架构注册表定义数据结构并帮助您的 Kafka 应用程序与数据更改保持同步。 通过这项最新更新,您可以直接从 IDE 探索以 Avro 或 Protobuf 序列化的 Kafka 主题。
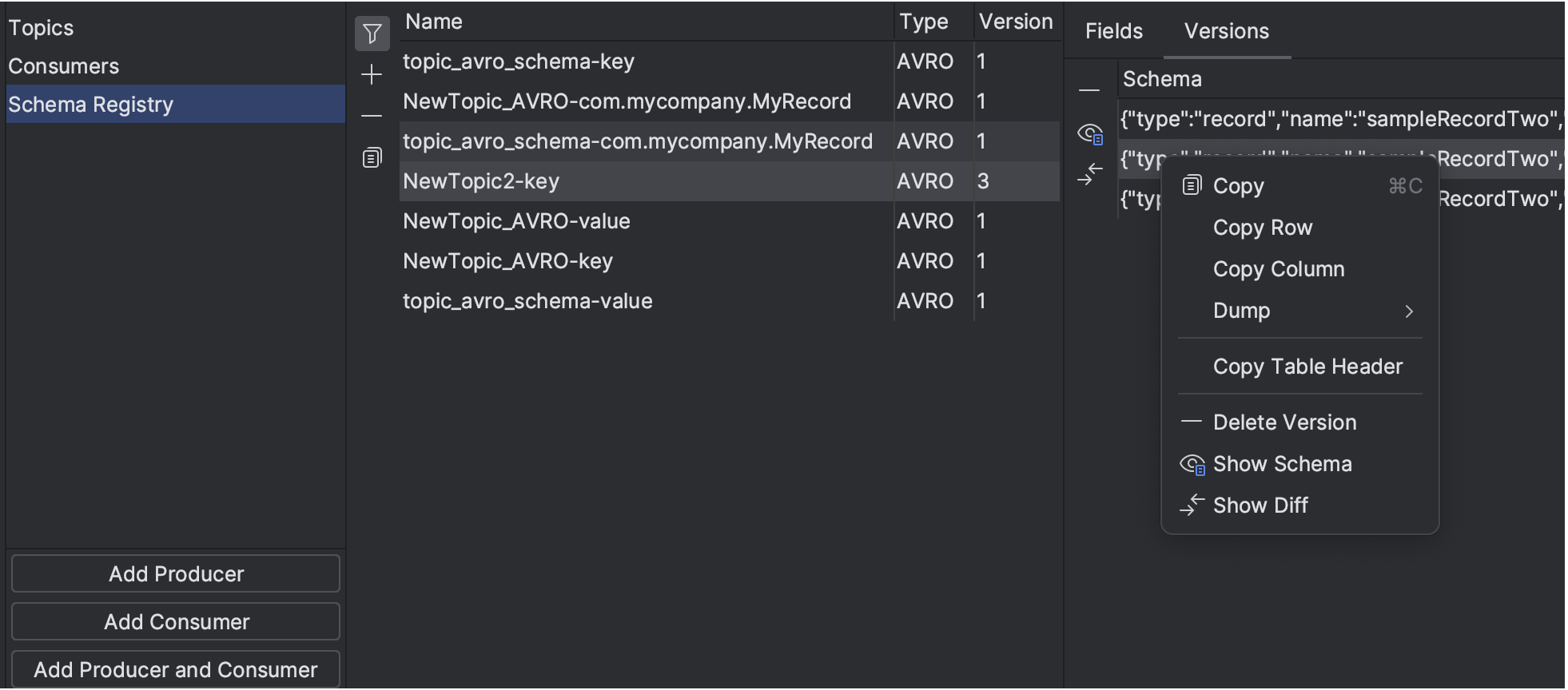
我们还通过安全的 SSH 隧道实现了与架构注册表的连接,以帮助您从本地机器使用和生产消息。
使用云存储更加方便
我们已在所有受支持的远程文件存储(例如 Amazon S3、Google Cloud Storage 和 Microsoft Azure Blob Storage)之间对我们的功能集进行了统一调整。 以下是最为显著的改进:
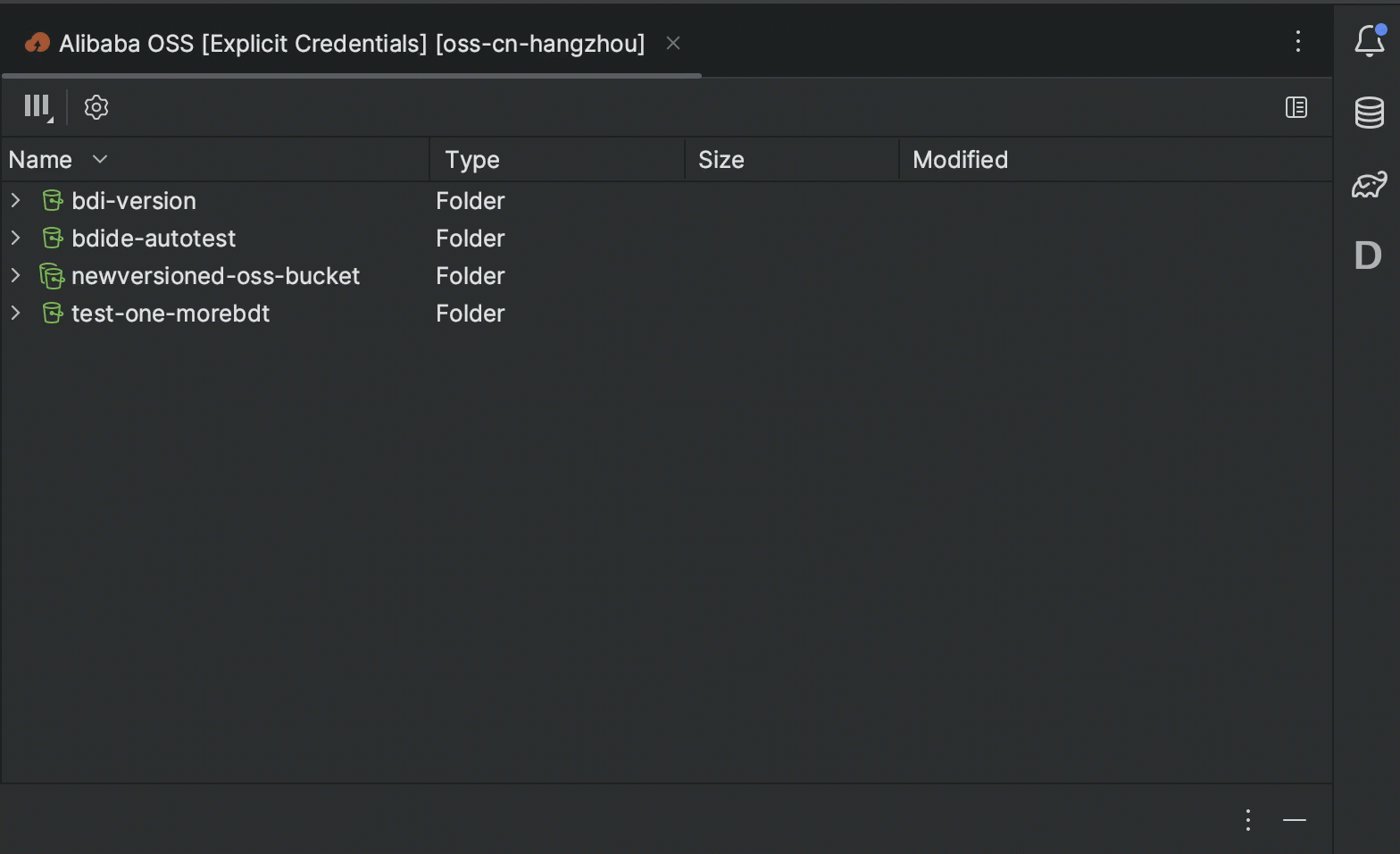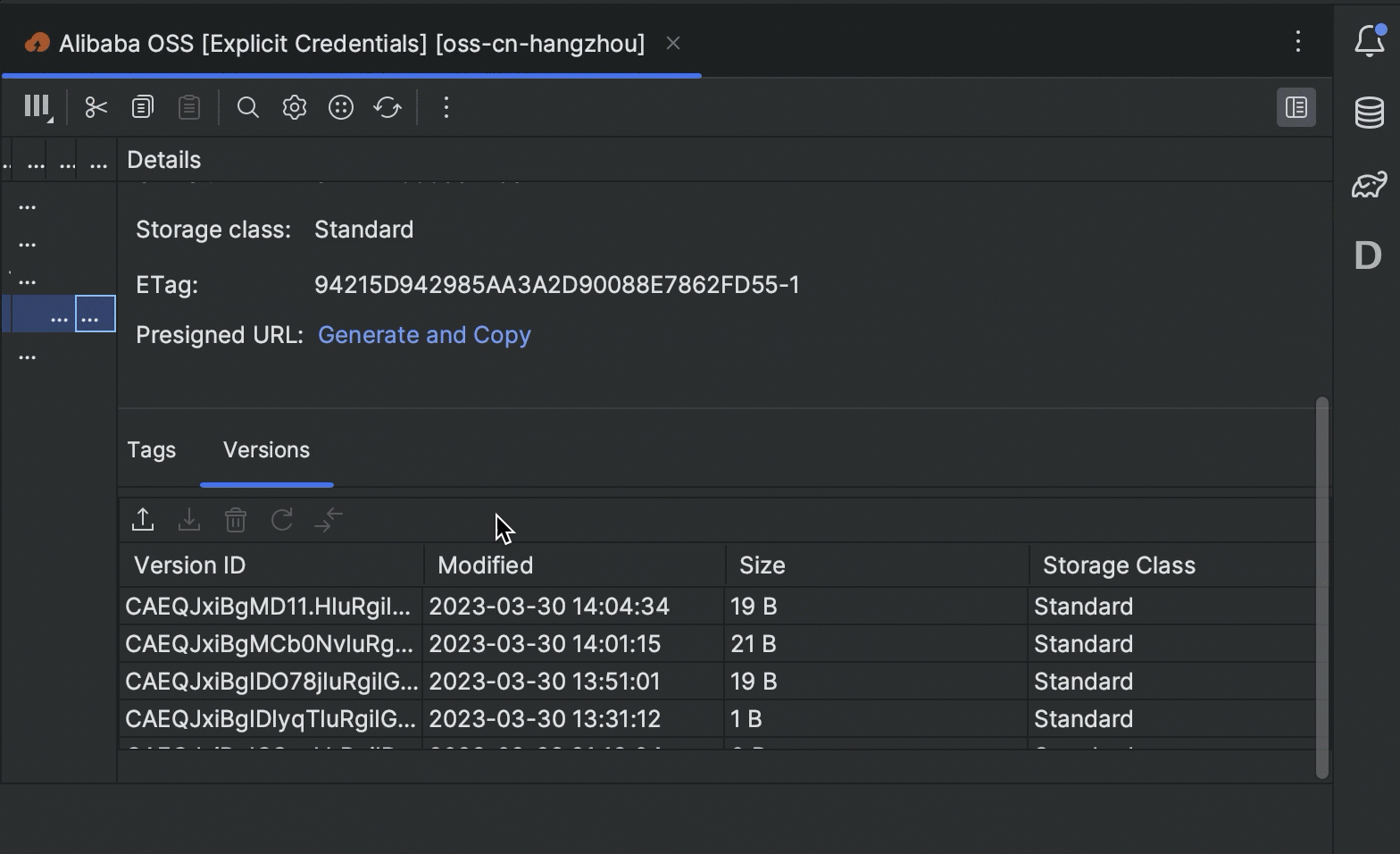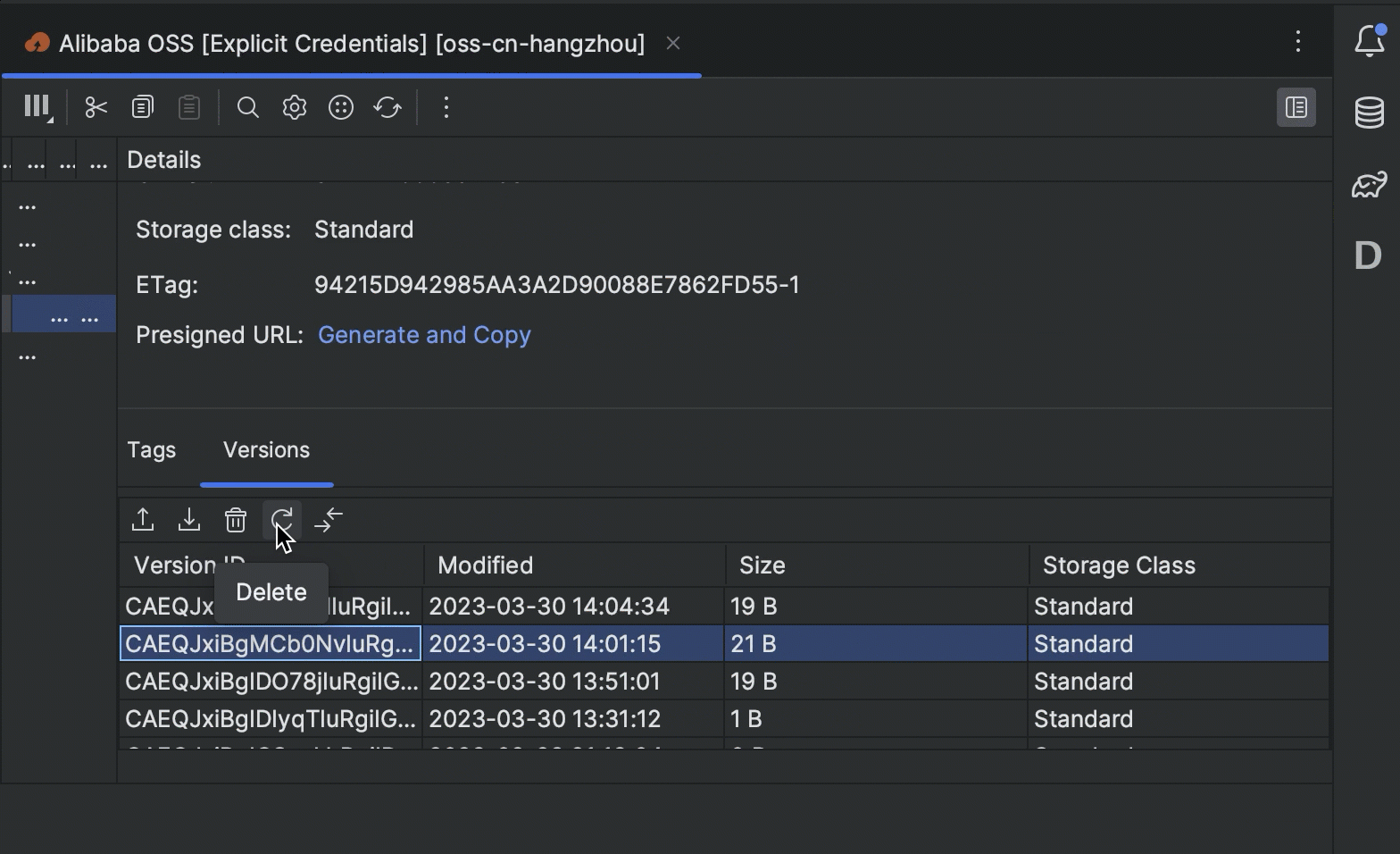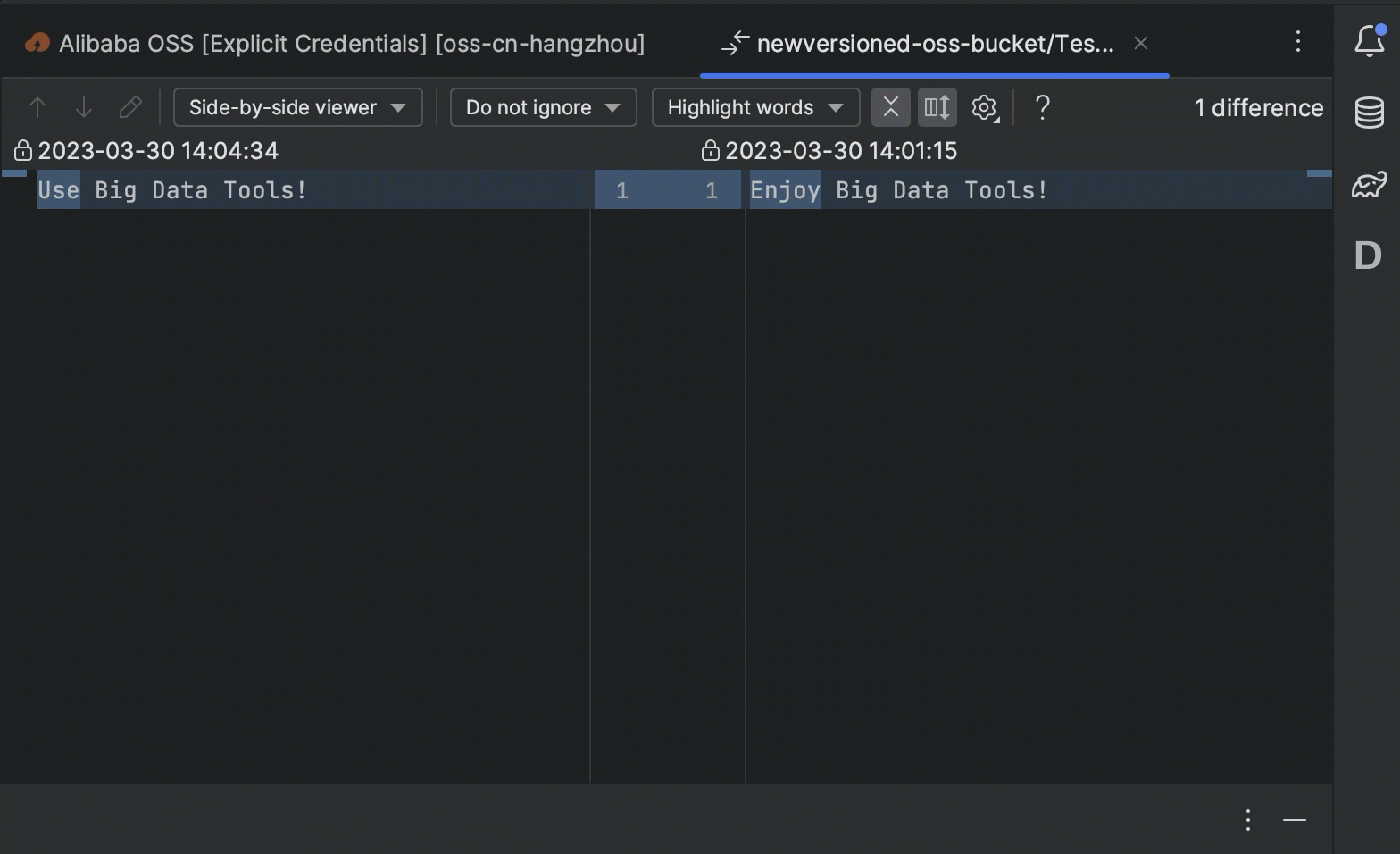
- 您现在可以直接在 IDE 中查看和管理存储桶对象的版本。
- 如果您使用对象或存储桶标记对存储进行分类,您现在可以在不离开编辑器窗口的情况下对其进行修改和查看。
- 新的上下文搜索功能支持通过输入相关关键字快速定位到云存储中的特定存储桶。
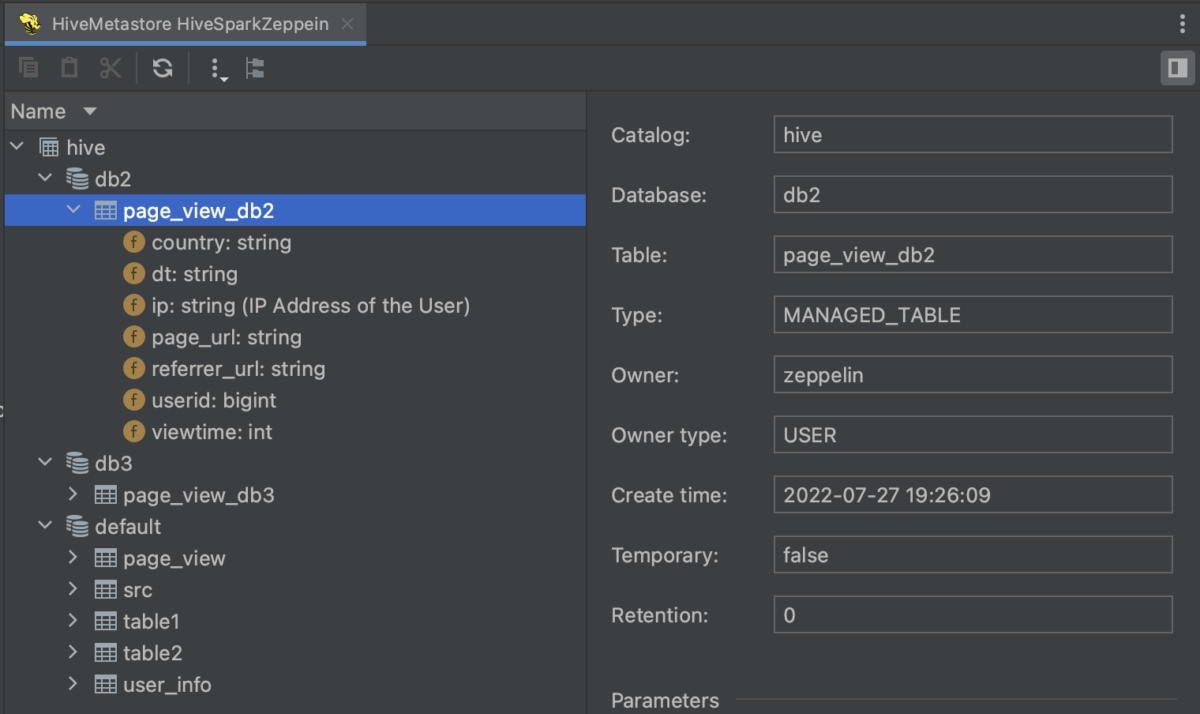
Hive Metastore 集成得到扩展
插件现在同时支持 Hive 3 和 Hive 2,使用户能够在自己的 IDE 中预览和了解自己的数据。 您可以在编辑器的单独标签页中打开 Hive Metastore 或其特定目录、数据库和表。
针对 Apache Zeppelin 集成的改进
如果您在 IDE 中使用 Zeppelin Notebook,可以将 Spark 作业代码提取到 Scala 文件中,以便在 IDE 项目中继续处理。 在此版本中,我们添加了用于提取所选 Scala 代码和段落中代码的选项。
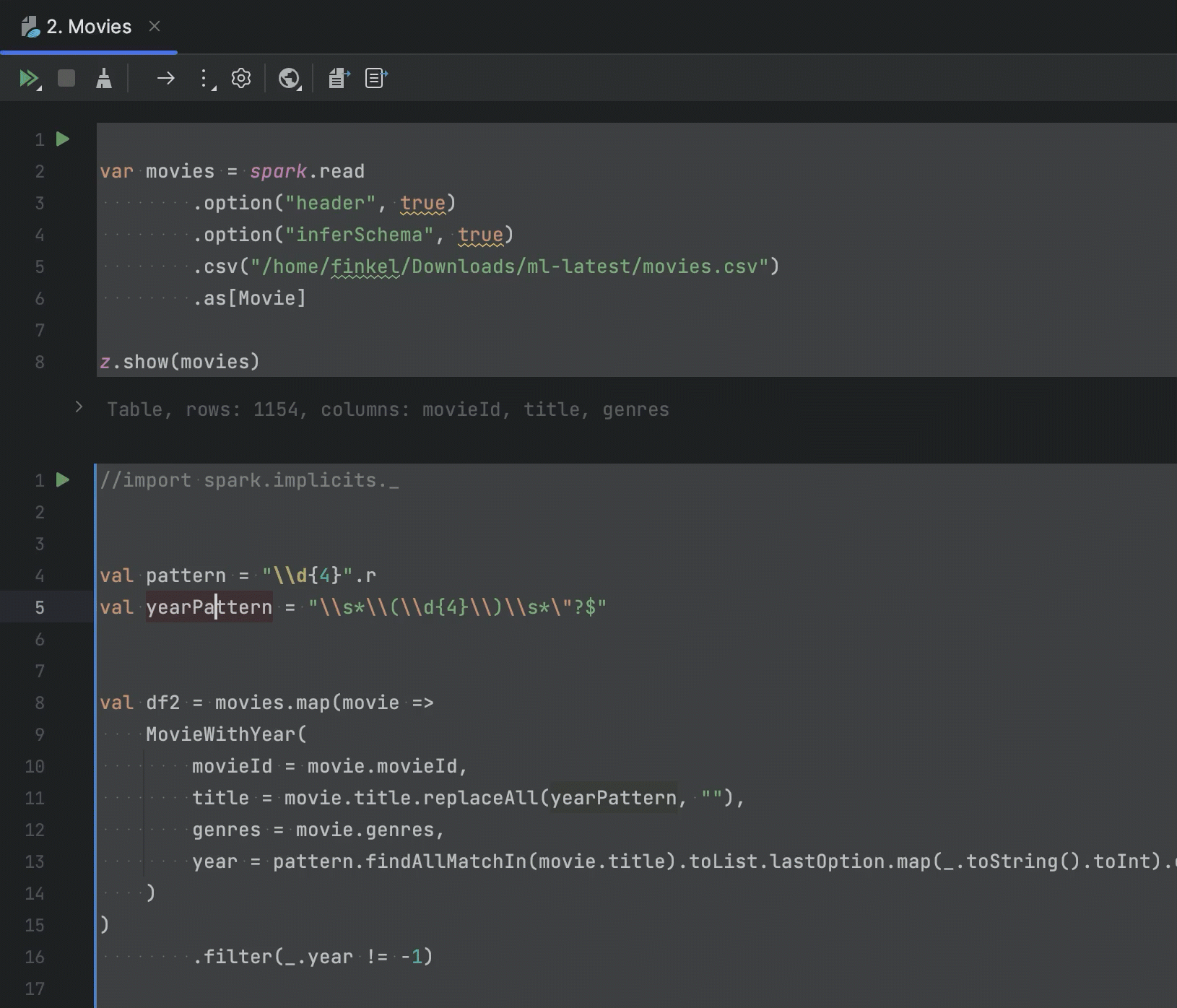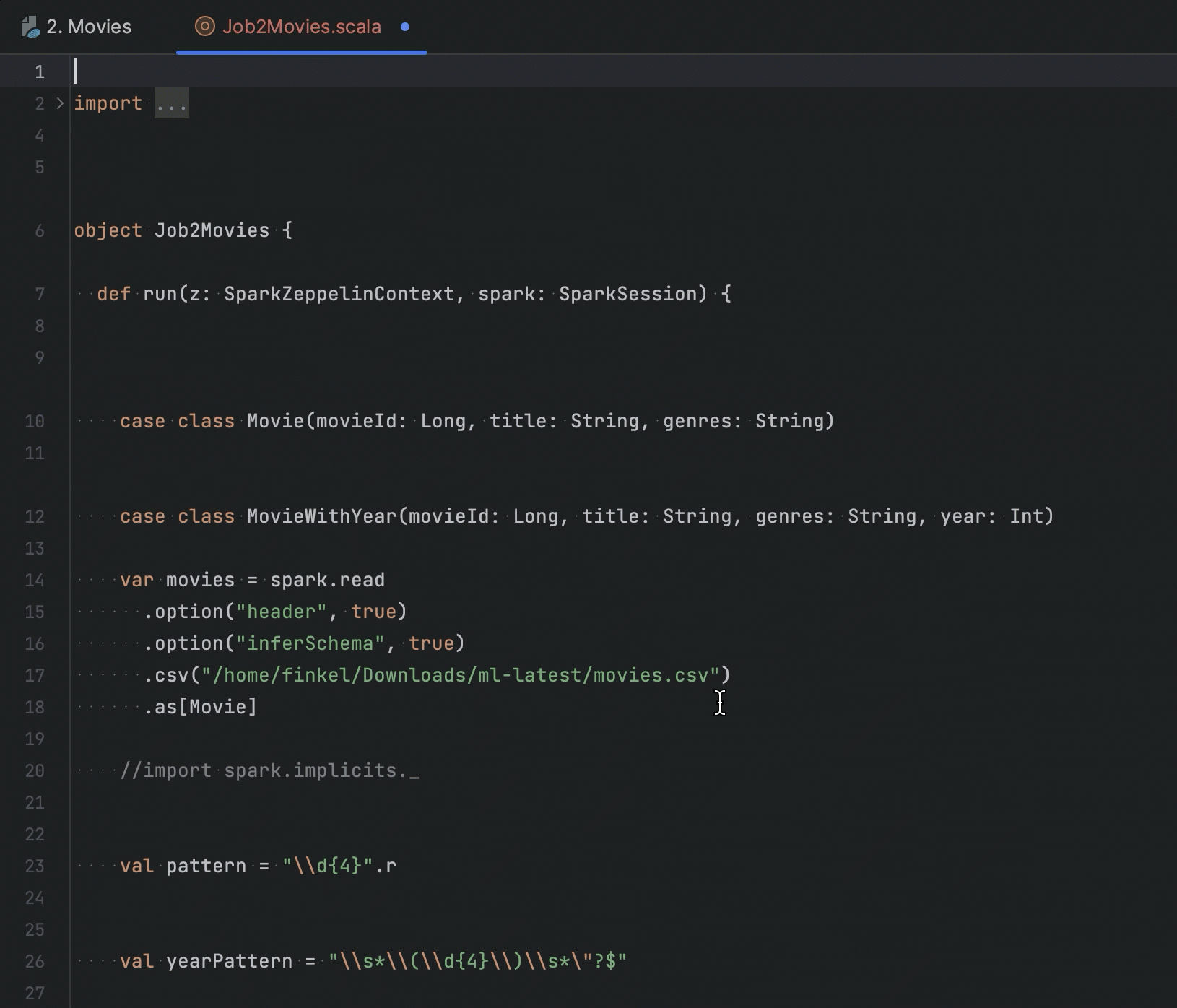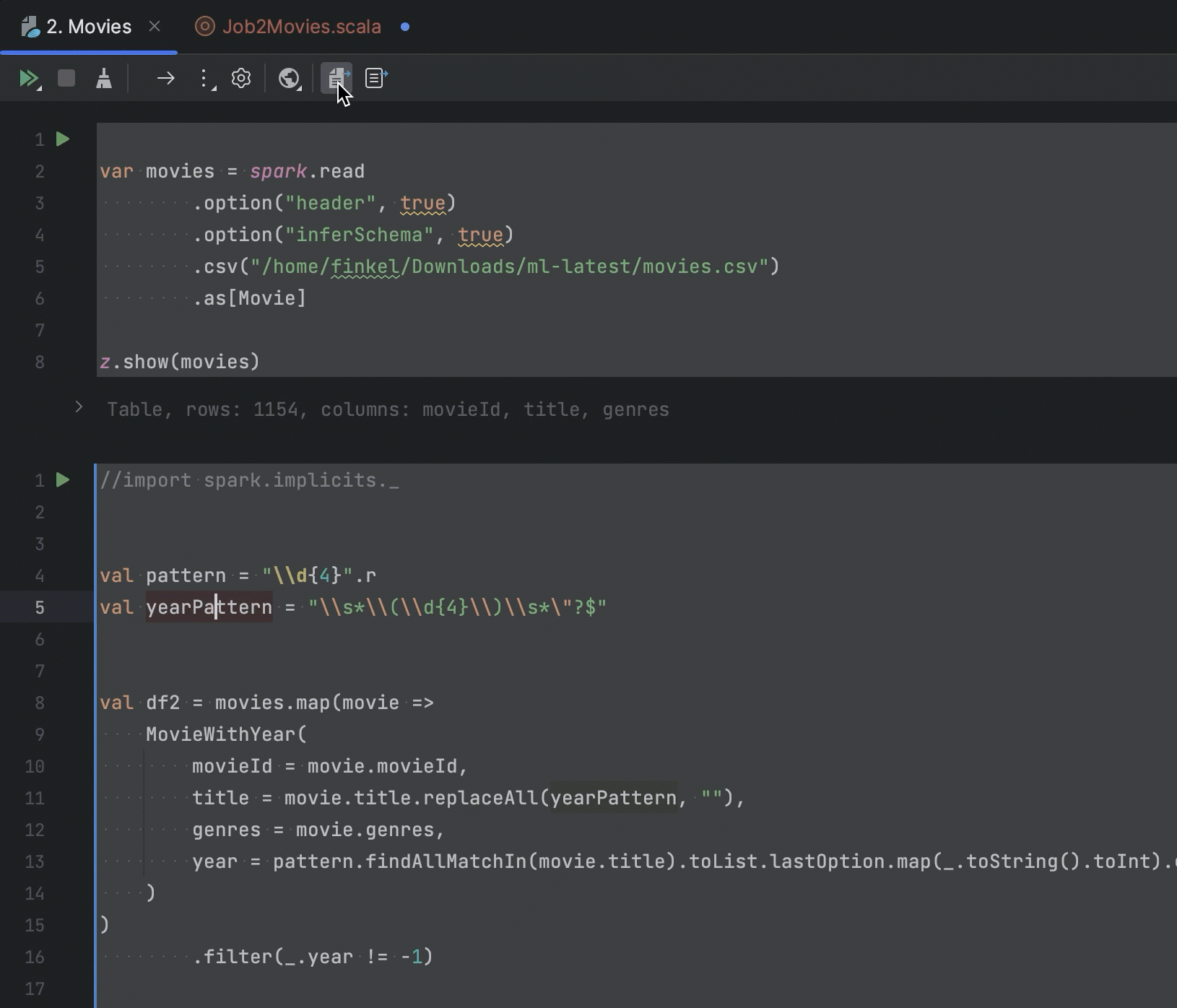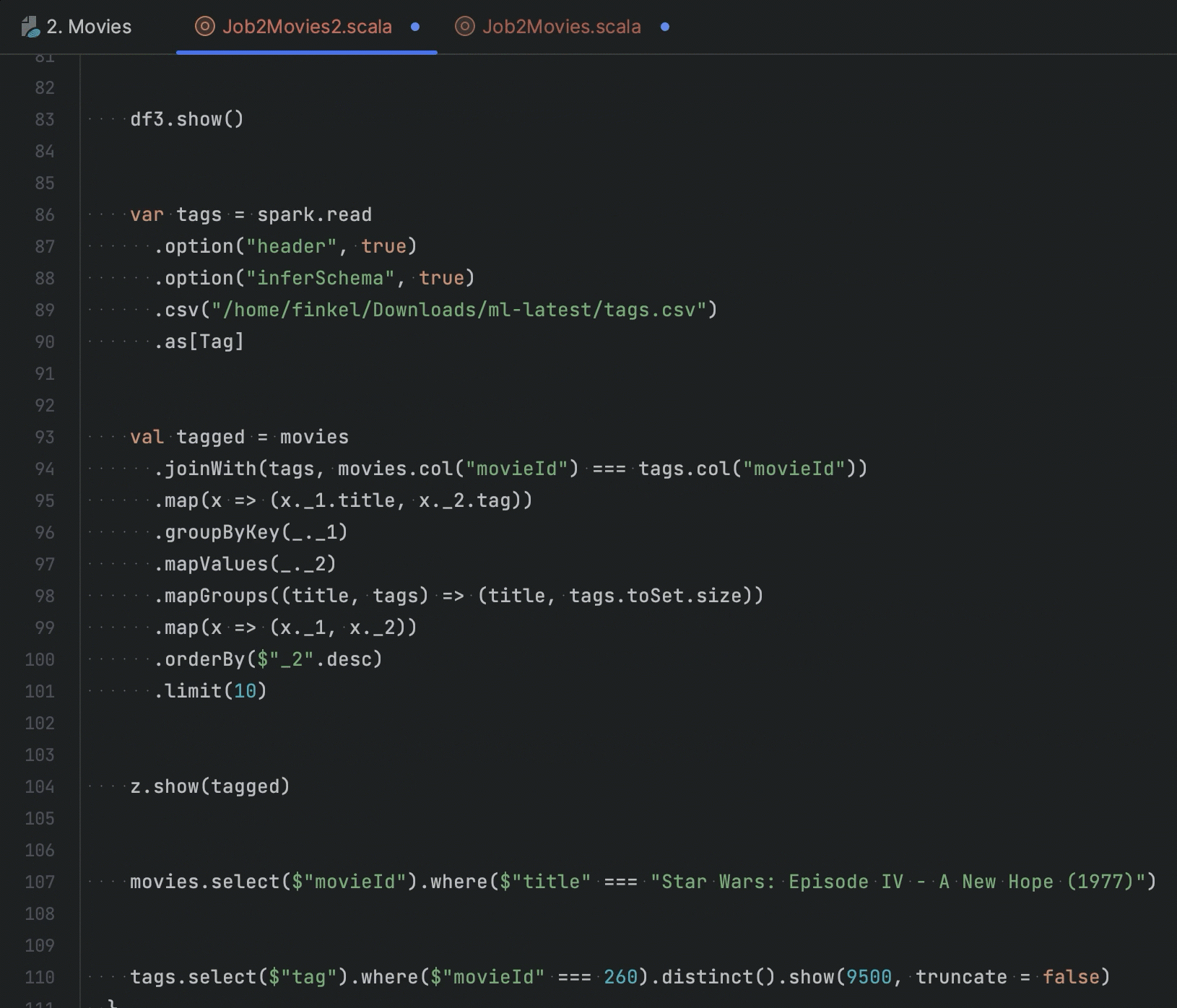
我们添加了针对 Zeppelin 中的 PySpark 段落的代码补全,它会通过提供从 DataFrame 推断的列的列表来补全列名。
我们还将 Dependencies(依赖项)和 Interpreter Settings(解释器设置)合并到了一个窗口中,从而更容易找到必要的设置。
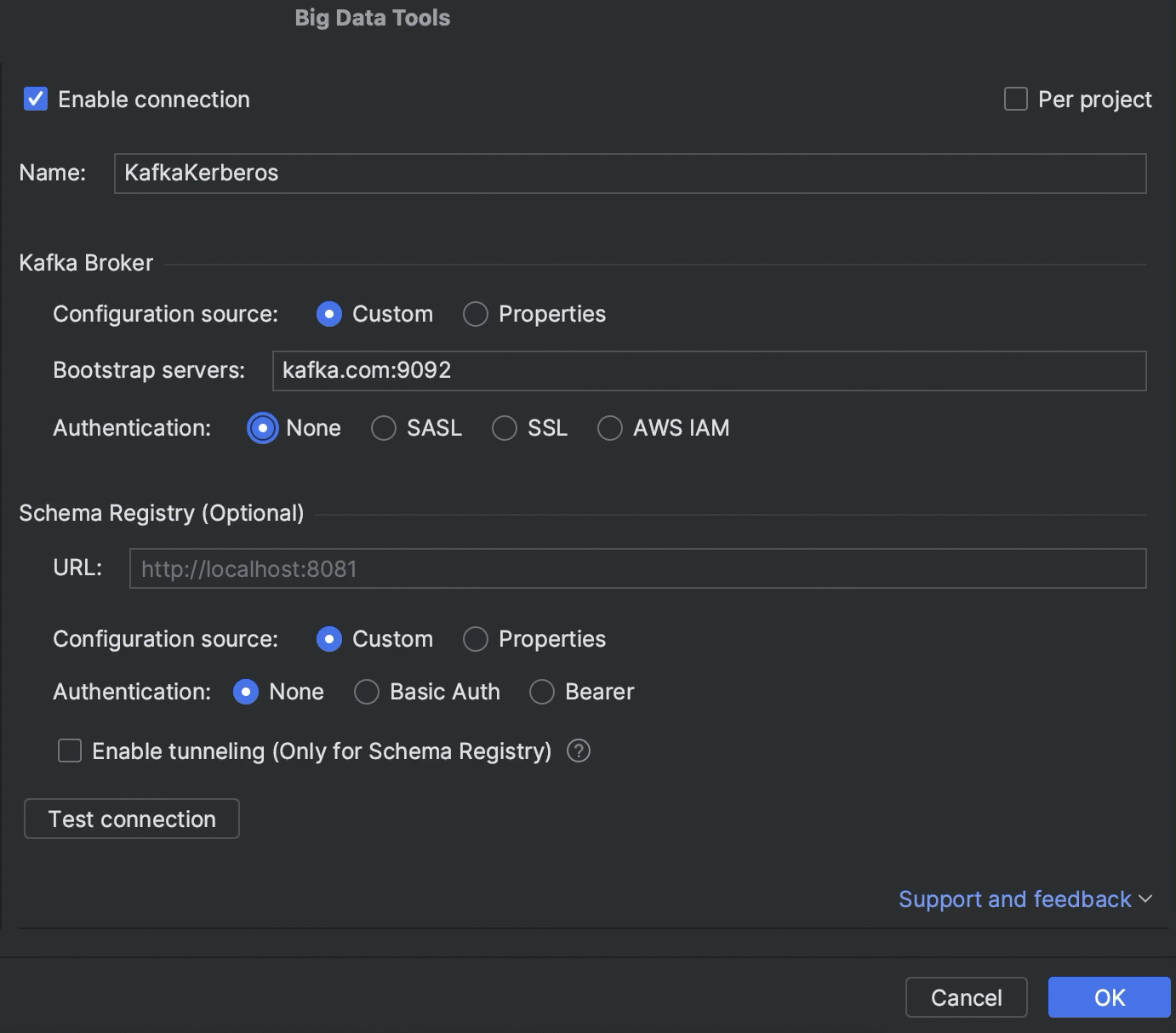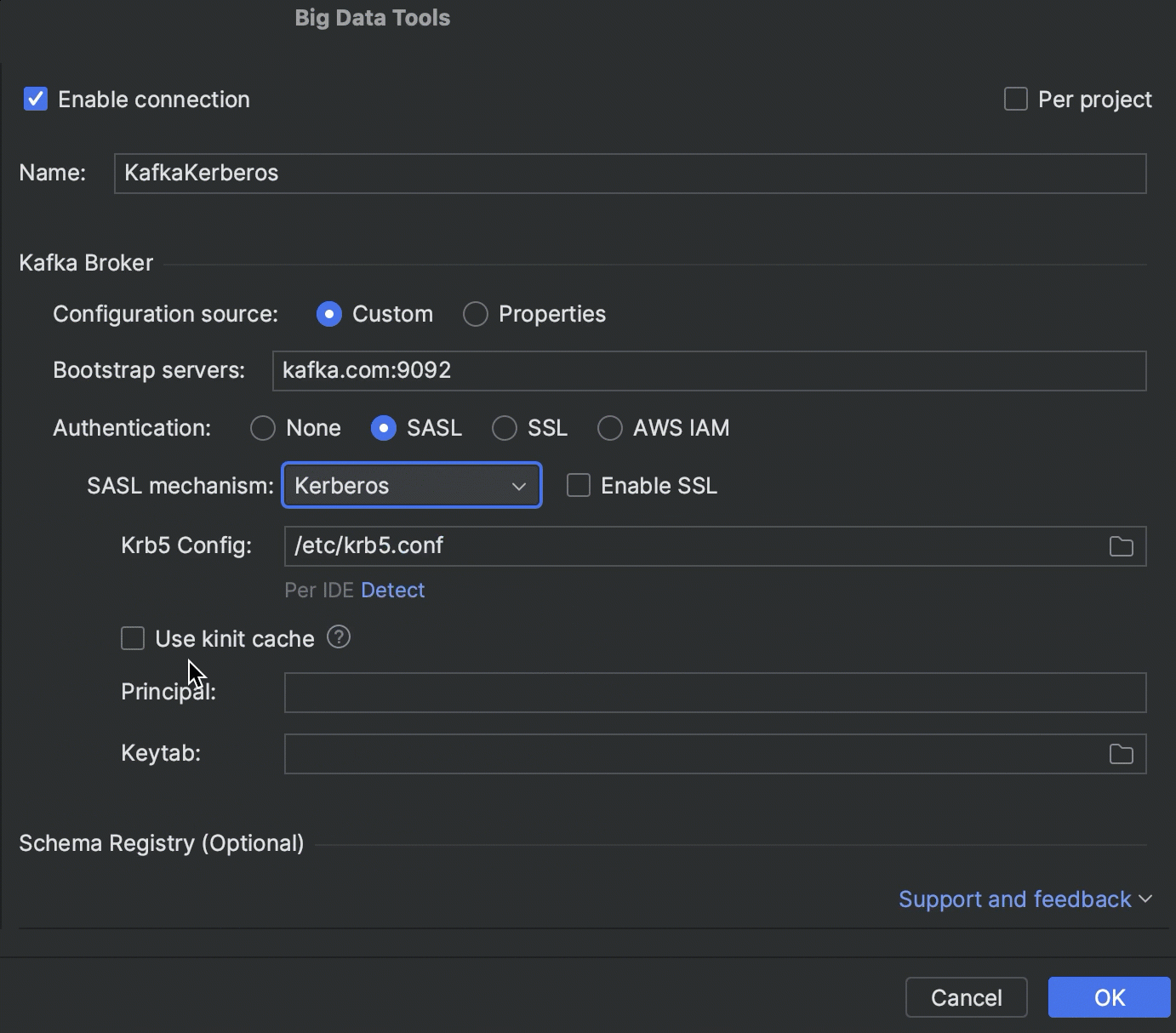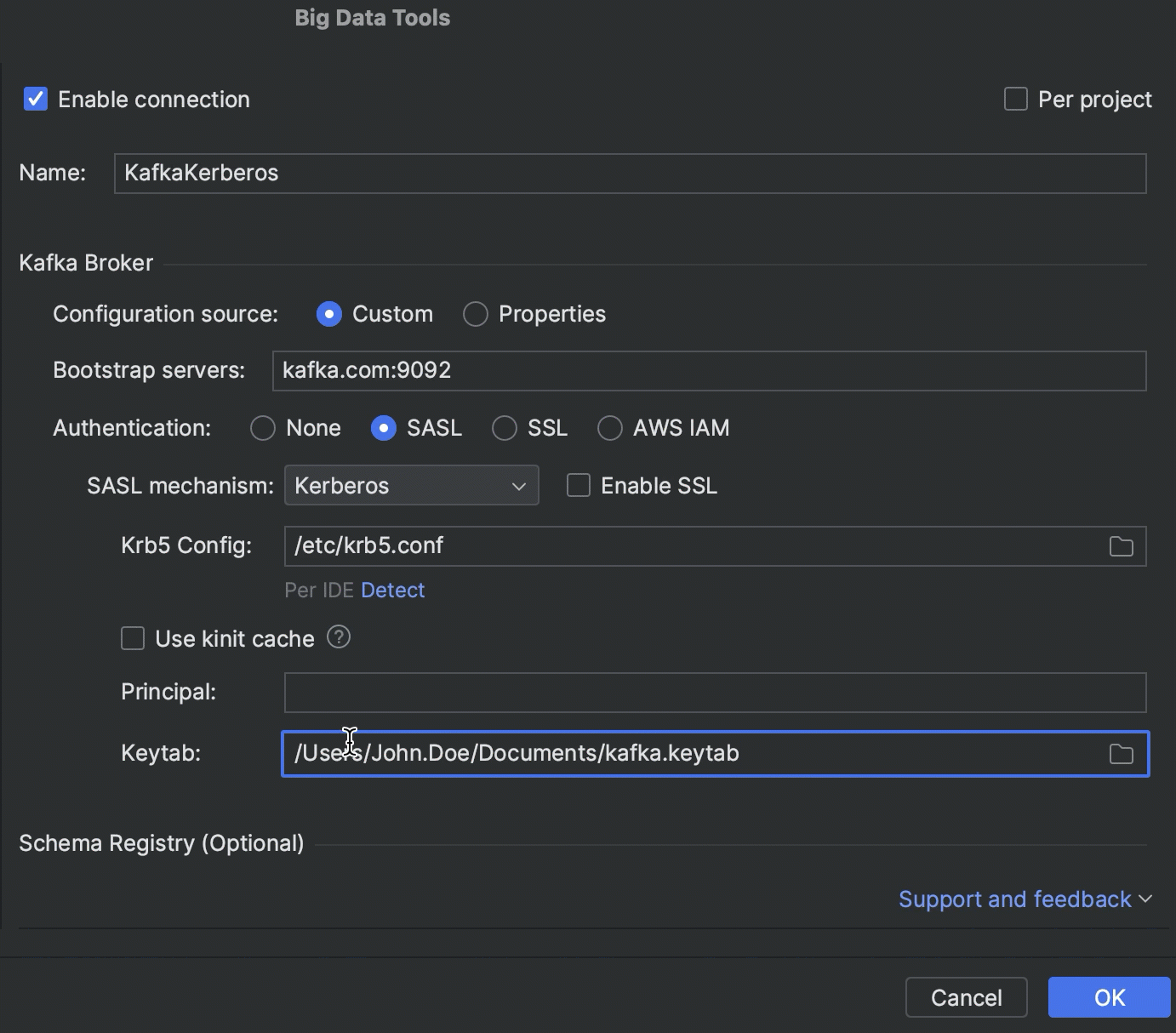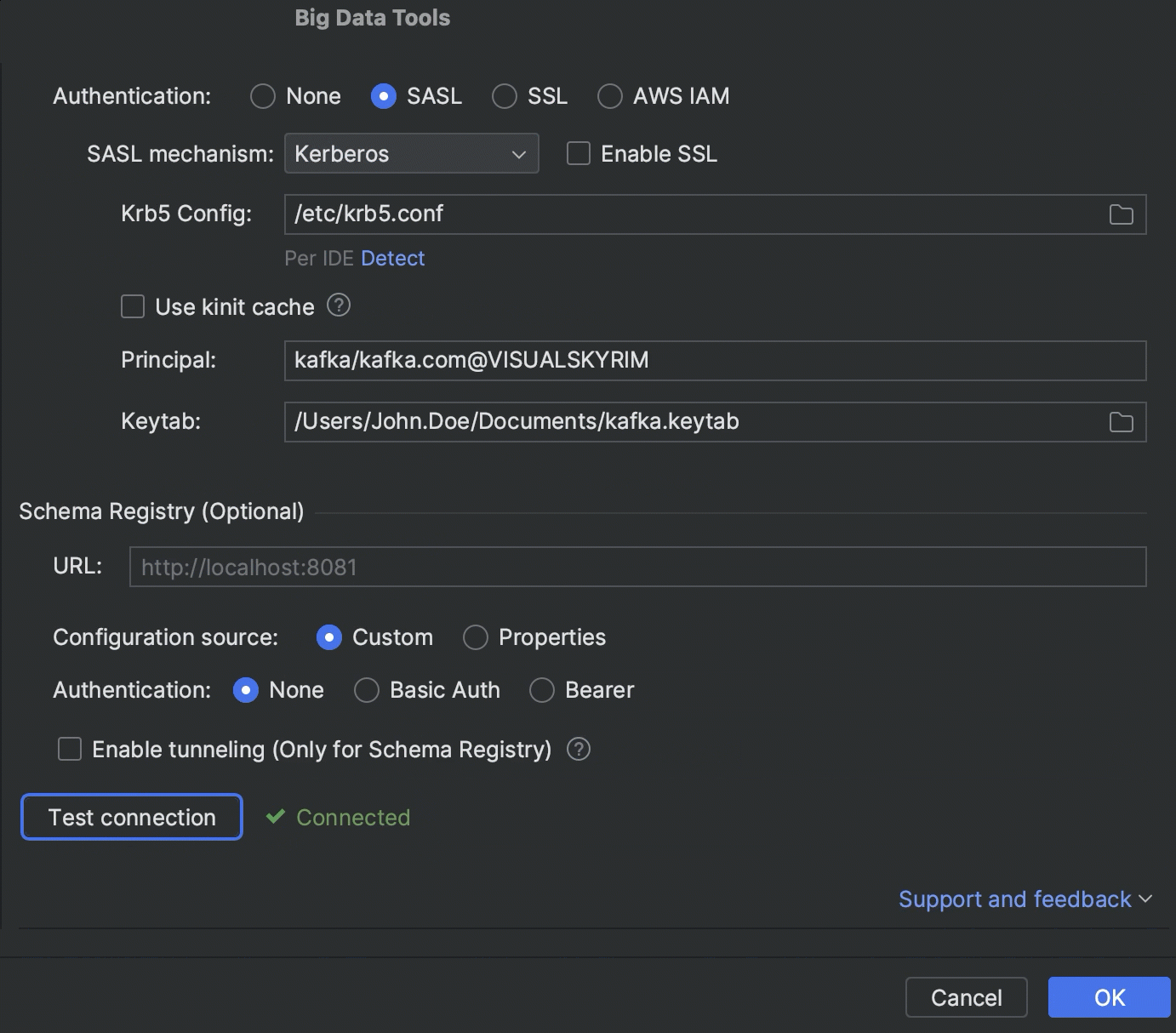
Kerberos 身份验证
现在可以使用 Kerberos 身份验证连接到 Kafka、HDFS 和 Hive Metastore。
AWS 服务中的单一身份验证
我们添加了跨 AWS S3、AWS Glue 和 AWS EMR 连接共享 AWS 身份验证的功能。 这消除了针对每个连接重复输入密钥或执行 MFA 身份验证的需求。
查看大数据二进制文件
借助 Big Data Tools 插件,您可以在不离开 IDE 的情况下方便地预览大数据文件格式的内容。 最新版本支持打开使用 zstd、Brotli 和 LZ4 等压缩方法的 Parquet 文件。
有关新功能和增强功能的完整列表,请参阅 Big Data Tools 插件页面上的更改日志。 请在我们的问题跟踪器中分享您的反馈并报告您遇到的任何问题。
Big Data Tools 团队
本博文英文原作者: