February 23, 2004
Thunderbird support in OmniaMea
We've been getting quite a few requests for implementing Mozilla Mail/Thunderbird support in OmniaMea, and today I investigated our options for that. I'm not too much of an expert on Mozilla development, so any comments and additions are highly welcome.
The main advantages and disadvantages of Mozilla as compared to Outlook are clear. The advantage is that Mozilla is open-source. The Outlook plugin has been a constant source of reliability and stability problems both for OmniaMea and for Outlook, and in many cases we had to resort to guesswork - "probably the incorrect behavior is caused by the fact that we're doing this wrong, so let's rewrite it that way". On the other hand, with Mozilla we'll be able to debug both sides of the integration, and clearly understand the reasons for all the problems.
However, the main disadvantage is that while Mozilla has a rich set of internal XPCOM interfaces, XPCOM does not support out-of-process calls, so we won't be able to call Mozilla APIs directly from the OmniaMea process.
The basic level of integration - importing the folder structure and the e-mail message and letting you read your e-mail in OmniaMea - can be implemented by parsing the mail database directly, without any calls to the mail client API. Integration at that level can be done for basically any client, and does not require too much effort. However, the utility of that is limited - you'll be able to read, search and categorize, but how convenient will it be if you'll have to switch to a different program for writing messages and replying?
The only project I've found which provides cross-process support for XPCOM is Blackwood Connect. However, this project is targeted at Java (and it's not clear how easy would it be to use it from .NET), and it looks like the project died before reaching version 1.0 (the latest release is dated mid-2001). Doesn't look like a good foundation for what we need.
Another option is to implement an XPCOM plugin that runs inside Mozilla (and thus has complete access to its internal API) and communicates with OmniaMea through some proprietary channel. The only problem with that is implementation difficulty. Looks like the effort to create both the Mozilla side of the integration and the OmniaMea side is more than we can afford to spend before the release of 1.0.
And finally, we can use Simple MAPI. It provides the main missing part of the "import the database directly" solution - creating messages. And that's it, basically. We can send messages and attachments, but even the simple function of deleting messages is not supported by the Mozilla implementation of Simple MAPI. And the slightly more complex stuff (marking messages as read, moving messages between folders) is outside the scope of Simple MAPI altogether. However, the advantage in supporting Simple MAPI is that it is implemented by many other mail clients besides Mozilla.
So, basically those are the options I've discovered. If I missed anything, please comment!
February 20, 2004
February 08, 2004
Gush, and instant messaging in OmniaMea
Stowe Boyd links to Gush, a new tool which integrates instant messaging and news aggregation in a single UI.
I'm fairly neutral on the entire concept of such a tool; the idea that my IM client should be the place where I read RSS feeds never really resonated with me, although RSS plugins for both Miranda and Trillian have been available for quite a while. Blogging through IM also was possible through the ICQ to LiveJournal gateway (note: page in Russian), but I find that longer posts written in a specialized client tend to be more interesting to read than one-liners which are typically written through IM.
Split Chat offers an interesting solution to the problem of replying in IM when there are several parallel threads of conversation between you and your correspondent (you can choose a specific message to which you're replying, and the reply appears side-by-side with it). However, the extra added complexity makes split chat logs considerably harder to read than regular chronological ones, and I think I'd rather use conventional logs.
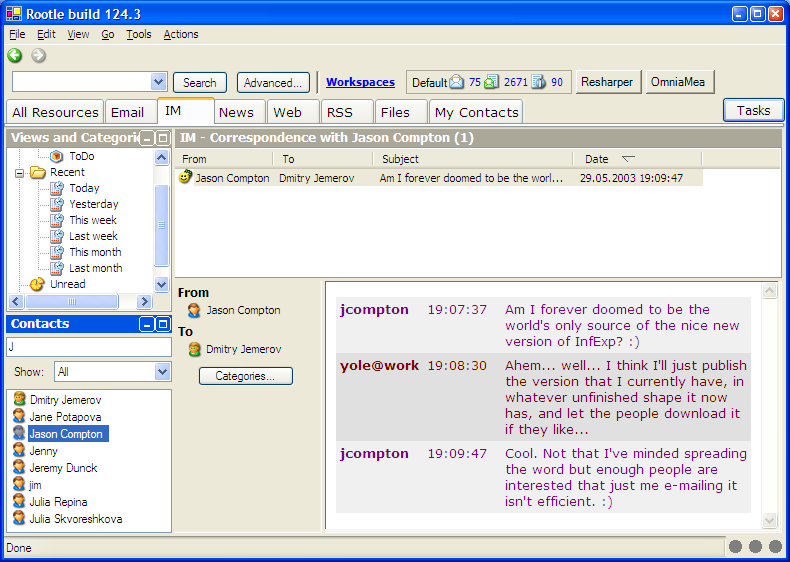
However, one thing Gush does undoubtedly right is organizing the chat history into conversations. A problem of many existing IM clients is that they display the history of conversations in a linear list, without distinguishing which messages were sent with the interval of a minute, and which - with the interval of a week. When we initially implemented ICQ import in OmniaMea, it was even worse - individual ICQ messages totally clobbered the today view, and e-mails and other important items were lost among them. Thus, the need to group the messages into conversations was immediately obvious.
Since we do not completely integrate with IM clients, there is no way to detect correctly when a conversation starts or ends (that is, when the conversation window is opened or closed). Thus, we had to use a simpler criterion - if the interval between messages exceeds a certain value (1 hour by default), these messages are split into different conversations, otherwise they are part of the same conversation.
The screenshot shows an example of an IM conversation displayed in OmniaMea. Note that the "From" field shows the contact which started the conversation, and the "Subject" is automatically generated from the beginning of the first meaningful message in the conversation (we have some extra logic to skip greetings, so that you won't have lots of conversations all called "hello" or "hi").
February 07, 2004
Segusoland, and categories in OmniaMea
Just stumbled across a link in the More Theory blog pointing to segusoLand, a file browser with "some truly revolutionary ideas behind it". And since I always try to keep track of innovation in all areas related to our project, I was curious to see what was so new about it.
But in fact, while segusoLand is indeed innovative, I don't think it really improves on the existing solutions.
I'll start with discussing a problem with which we've had first-hand experience when developing OmniaMea: categorizing information. Initially, when I designed the interface for working with categories in OmniaMea, I was greatly influenced by the paper "User Interfaces for Supporting Multiple Categorization" by the developers of Haystack. My reasoning was that, since we give the user the possibility to assign multiple categories to each resource, she will use it to create independent category hierarchies (for example, one for company products and another for departments - development, testing, marketing and so on). Then she will naturally find the category intersections - "IDEA Marketing" or "OmniaMea testing" - very useful.
However, when I got initial feedback from users trying to figure out the implementation, I quickly saw the problems with that implementation. First of all, it was tremendously confusing for the users. The categories were presented in a tree, and by expanding a categories node you saw all the categories intersecting the one you have expanded. And the users couldn't really understand how the tree worked, why it could be expanded in so many directions and still show the same items everywhere, and what was actually shown when a node was selected.
Second, we immediately tried to convert the folder structure that our users had into the new category structure. The result was that the all the user's folders (up to 200 on real databases we used for testing) were presented as a single alphabetically sorted list. Since expanding nodes was reserved for showing intersections, we couldn't also show the folder hierarchy in the same tree, so the list had to be linear. As a result, it was much less manageable than the original tree, and many folders which made sense in the context of their parent folders were confusing when shown at the top level of the tree.
And third, most of the folders actually existing in the users' databases couldn't possibly fit in the independent hierarchy system I described above, and the intersections between them were mostly random. It was mildly interesting to see that Ben Laurie posts both to the OSAF dev list and to python-dev, but the value of such an intersection for me personally was zero.
(Not to mention the problems with implementing fully correct updates of the intersection tree when categories are added or removed from resources, which can cause nodes to disappear from the middle of the tree. I never actually solved this - my implementation didn't update correctly in some cases).
Thus, we eventually decided to go with a much more conventional implementation - a resource can still belong to multiple categories, but the categories are shown in a simple hierarchical tree, and the intersections between categories can be built through standard mechanisms of advanced search or custom views.
The segusoLand implementation of file organization suffers from many of the same problems - except that the number of folders in my filesystem is not 200 but closer to 20 thousand (and is probably still greater than 1000 if you count only the folders that I actually work with). Showing them in a linear list instead of a logical categorization will seriously cripple my ability to work with them. And even if you look at the screenshot provided (where the list of folders is very short), you will see that very few of the possible folder intersections make sense. How many cartoons on C# or configuration files authored by Douglas Adams do you actually have on your machine, after all?
{kind=link}
I'll briefly mention other problems with segusoLand. For example, the Time column makes sense for very few operations (the mainframe batch job era has ended some 30 years ago, and there is no need for me to schedule printing of my PDF files hours in advance), but for the sake of uniformity, it is displayed for all commands, and takes up quite a lot of the UI space. (Looks like I can hide it, but why create it in the first place)?
Another problem is that, while I have quite a lot of programs capable of viewing pictures installed on my machine - IE, Firebird, Opera, Paint, the standard image viewer and so on - I always use only one of them, namely ACDSee. Making me choose the program I want to use every time I want to view a picture is a complete waste of time. (But of course, assigning the default application breaks the principle of uniformity - namely that the actions I use 50 times a day and actions I use once a year must be equally hard to do from the UI).
However, these problems have little to do with OmniaMea, so I'd better stop now and leave segusoLand alone. :-)
February 04, 2004
OmniaMea name
Just to clarify: neither "OmniaMea", which I'm using here, nor "Rootle", which you can see on the screenshot, is the final name of the product. OmniaMea is the name that has been around for the longest time, so it's the name I'm using in the blog, but it's hardly suitable for a product name. It means nothing for the majority of people who don't know Latin, it's not clear how the name should be pronounced in English, and it's very hard to spell right (I've seen lots of incorrect spellings from different people so far).
As for "Rootle", that name is... shall we say, aesthetically unpleasing for some of my colleagues.
OmniaMea plans
So when we'll be able to try it?
I won't give any specific dates here - "when it's done" is our usual answer to such questions. What I can say is that the public beta (Early Access Preview program) will start very soon. It will not contain the full set of features planned for the release 1.0, but it should be stable and usable enough for daily usage. Most likely the beta will initially be restricted, but we haven't decided on the exact policy yet.
The final release is still several months away.
OmniaMea platform
What is the platform OmniaMea will run on? Will it run on Linux and Mac OS X as well?
OmniaMea is a .NET application, and currently it runs only under Windows. We will support Windows 2000/XP/2003; support for Windows 98/Me is still under discussion.
We are interested in supporting MacOS X and Linux through Mono. However, by the time we plan to release OmniaMea version 1.0, we don't expect that Mono will be mature enough to do a port of a complex WinForms application with little effort, and we don't have the development resources to do a second version of the UI (in GTK or a different toolkit). So, most likely, support for other platforms will have to wait until after 1.0 is released.
Using OmniaMea with other e-mail clients
Another user's question:
So if I understood you correctly, you did not create a standalone application, "just" an add-on to MS Outlook, am I right? But what if you use Thunderbird - will you also be able to use OmniaMea?
OmniaMea is actually a standalone application that, in the version 1.0, integrates with Outlook for its email features. If you use a different email client, you will be able to use all other features of OmniaMea - news, RSS, file indexing and so on. In the next release after 1.0, we will have our own email client, but integration with Outlook will always remain a supported mode of operation, because many corporate environments require the use of Outlook.
We currently don't have the development resources to support integration with other email clients, so we hope to get some help from third-party developers, through our open API. Since Thunderbird is open-source, there should be no major problems in developing a plugin for integrating with it.
Feature spotlight: Workspaces
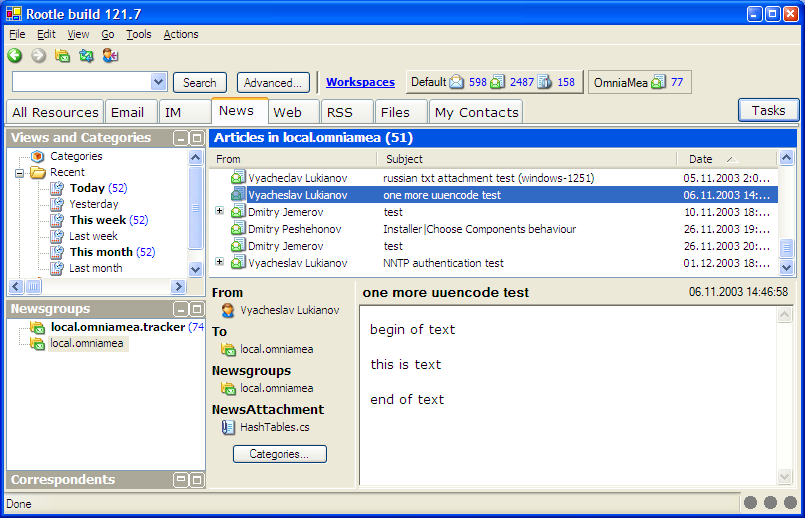
One of the innovative features of OmniaMea is its support for workspaces. A workspace is a global filter that restricts the information displayed in all views of the program to the resources related to a certain project or activity.
Workspaces are a more high-level information grouping than, for example, e-mail folders. If I create a workspace for the OmniaMea project, I can add to it some contacts (members of my team), some Ooutlook folders (build logs, tracker notifications), some newsgroups (local and public), some RSS feeds (blogs of OmniaMea users) and so on. Then, when the workspace is active, the Outlook folders tree will show only the folders in the workspace, the Correspondents pane will show only the contacts in the workspace, and so on.
Besides information containers (folders or newsgroups), I can also add individual information items (emails or newsgroup posts) to a workspace. Besides that, workspaces can also be divided by the e-mail account through which the e-mail was received. This allows one to keep personal and work-related communication separate and yet handle both from the same program.
Workspaces are also much easier to set up than, for example, custom views. All that is needed to add a resource to a workspace is to drop it on the workspace button or select it in the workspace configuration dialog. You don't need to bother with selecting search criteria, specifying their parameters and so on.
Another purpose of workspaces is notification. The workspace buttons show the count of unread items for each workspace, grouped by resource type. Thus, when a new item arrives, you can quickly see whether it came into your main workspace (and needs to be investigated urgently) or if it's just something that you can read when you have spare time.
The attached screenshot shows an example of an OmniaMea screen with one workspace defined.
February 01, 2004
Error patterns: read-only "last"
In my programming experience, I find that there are some common errors that I make quite often. Maybe it'll be easier for me (or even for someone else) to get rid of them if I describe them in my blog.
The error I just made has to do with a common optimization: when a function is called with some parameter, do not do anything if it's equal to the parameter of the last call to that function. The error is forgetting to actually store the last selected value.
public void SetCurrentSomething( IResource something)
{
if ( something == _lastSomething )
return;
// do stuff
// forget to actually set _lastSomething
}