

LLM Evaluation and AI Observability for Agent Monitoring

This is a guest post from Naa Ashiorkor, a data scientist and tech community builder.

Artificial intelligence keeps evolving at a rapid pace. The latest major application of AI, specifically of LLMs, is AI agents. These are systems that use their perception of their environment, processes, and input to take action to achieve specific goals, and they are built on LLMs.
Increasingly, complex AI agents are being used in real-world applications. While simpler agentic applications that use only one agent to achieve a goal still exist, organizations are now shifting towards multi-agent systems that use multiple subagents coordinated by a main agent. These are more adaptable and can mimic human teams when it comes to performing specialized tasks such as data analysis, compliance, customer support, and more. The reasoning and autonomy of AI agents have improved; consequently, they can gather data, conduct cross-references, and generate analysis.
As we move towards these complex, real-world applications of agents, an ever-stronger spotlight is being shone both on how we observe AI agents and how we evaluate the LLMs they’re built upon. The complexity, interactions, and autonomous processes under the surface of AI agents make rigorous monitoring and assessment an essential part of building and maintaining these applications. LLM evaluation determines if the AI agent can work, while AI agent observability determines if it is working. LLM evaluation tests an agent’s basic capabilities before and during deployment, while agent observability provides deep, real-time visibility into an agent’s internal reasoning and operational health once it is live. It is pretty obvious that having just one of these is a loss and a formula for failure.
In this blog post, we’ll explore how to evaluate agents using advanced metrics and observability tools. It’s designed as a practical, end-to-end reference for teams that want to move beyond demos and actually run AI agents in live, real-world environments, avoiding the common pitfalls that cause failure in production.
Core LLM evaluation metrics for modern AI systems
As LLMs are now applied to a wide range of use cases, it is important that their evaluation covers both the tasks they may perform and their potential risks. Evaluation metrics give a better understanding of the strengths and weaknesses of LLMs, influence the guidance of human-LLM interactions, and highlight the importance of ensuring LLM safety and reliability. Hence, LLM evaluation metrics for assessing the performance of an LLM are indispensable in modern AI systems. Without well-defined evaluation metrics, assessing model quality becomes subjective.
There are several key evaluation metrics, each with a different purpose, and the table below provides a summary of some of them.
| Evaluation Metric | What the metric evaluates |
| Hallucination rate | Factual accuracy and truthfulness of generated content |
| Toxicity scores | Harmful, offensive, or inappropriate content |
| RAGAS (Retrieval Augmented Generation Assessment) | Measures whether the RAG system retrieves the right documents and generates answers that are faithful to those sources |
| DeepEval | Tests everything from basic accuracy and safety to complex agent behaviors and security vulnerabilities across the entire LLM application |
Hallucination rate
Hallucinations in LLMs produce outputs that seem convincing yet are factually unsupported and can be categorized as either intrinsic, where the output contradicts the source content, or extrinsic, where it simply cannot be verified. They can stem from a range of factors across data, training, and inference, from quality issues in the large datasets used for initial training and the data used to fine-tune model behavior to post-training techniques that make models overly eager to provide responses to imperfect decoding strategies at inference. Because hallucination is an unsolved challenge cutting across every stage of model development, measuring and assessing it remains a vital part of LLM evaluation.
There is a wide variety of techniques for detecting hallucinations. These include:
- Fact-checking: Extracting independent factual statements from the model’s outputs (fact extraction) and then verifying these against trusted knowledge sources (fact verification).
- Uncertainty estimation: Using the certainty provided in the model’s internal state to estimate how likely a piece of factual content is to be a hallucination.
- Faithfulness hallucination detection: Ensures the faithfulness of LLMs to provide context or user instructions.
There are several metrics for hallucination detection. Some of the most commonly used metrics include:
- Fact-based metrics: Assessing faithfulness by measuring the overlap of facts between the generated content and the source content.
- Classifier-based metrics: Utilizing trained classifiers to distinguish between the level of entailment between the generated content and the source content.
- QA-based metrics: Using question-answering systems to validate the consistency of information between the source content and the generated content.
- Uncertainty-based metrics: Assessing faithfulness by measuring the model’s confidence in its generated outputs.
- LLM-based metrics: Using LLMs as evaluators to assess the faithfulness of generated content through specific prompting strategies.
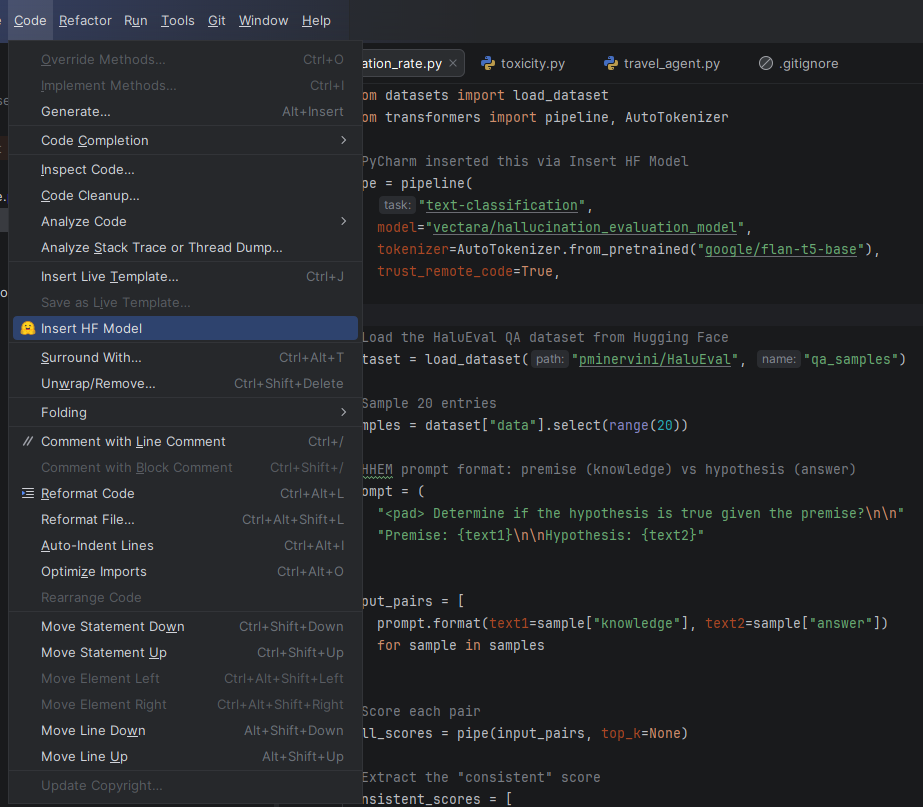
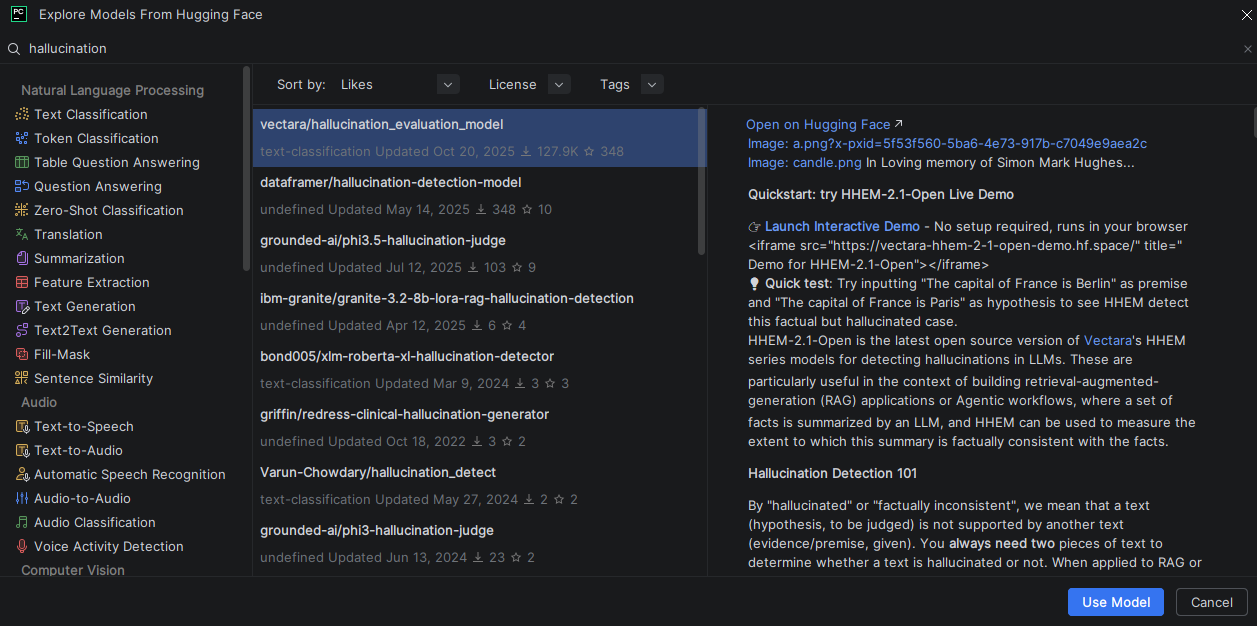
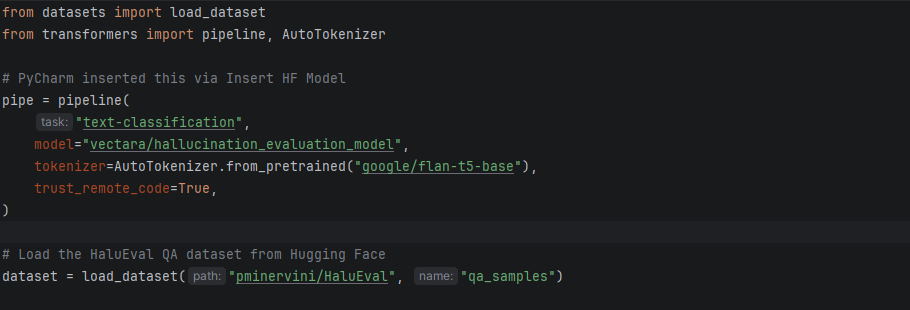
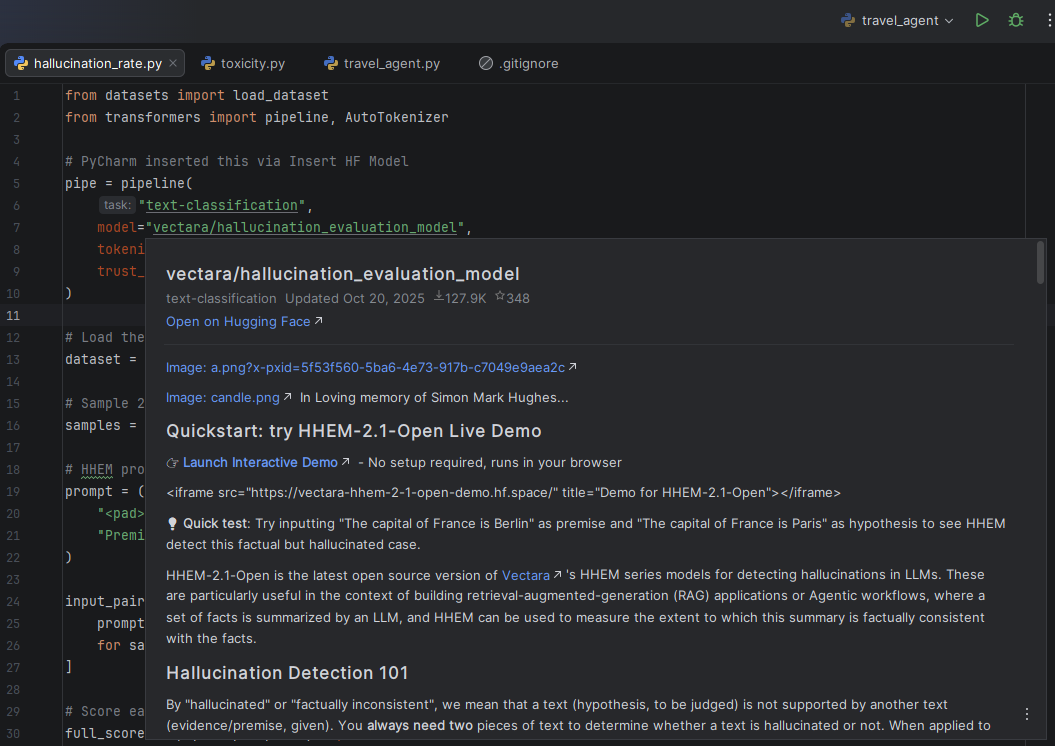
PyCharm’s Hugging Face integration lets you discover evaluation models and datasets without leaving the IDE. Use the Insert HF Model feature to search for hallucination or toxicity classifiers, and hover over any model or dataset name in your code to instantly preview its model card, including training data, intended use, and limitations. This means you can import a dataset, evaluate your LLM, and verify the tools you’re using, all from one place.
Trust is imperative in the acceptance and adoption of technology. Trust in AI is especially important in areas such as healthcare, finance, personal assistance, autonomous vehicles, and others. Hallucinations have a huge impact on users’ trust in LLMs.
In 2023, a story went viral about a Manhattan lawyer who submitted a legal brief largely generated by ChatGPT. The judge quickly noticed how different it was from a human-written submission, revealing clear signs of hallucination. Incidents like this highlight the real-world risks of LLM errors and their impact on user trust. As people encounter more examples of hallucination, skepticism around LLM reliability continues to grow.
Toxicity scores
LLMs that have been pretrained on large datasets from the web have the tendency to generate harmful, offensive, and disrespectful content as well as toxic language, such as hate speech, harassment, threats, and biased language, which have a negative impact on their safe deployment. Toxicity detection is the process of identifying and flagging toxic content by integrating open-source tools or APIs into the LLM workflow to analyze both the user input and the LLM output. Some of the available toxicity tools include the OpenAI Moderation API, which is free, works with any text, and has a quick implementation. Perspective API by Google is also widely used with a transparent methodology, but will no longer be in service after 2026. Detoxify, which is open source, has no API costs, and is Python-friendly, and Azure AI Content Safety by Microsoft, which is customizable and best for enterprise deployments and existing Azure users. Hugging Face Toxicity Models have many model options and easy integration with Transformers.
Toxicity detection has become a guardrail; hence, it is important in public-facing applications. They prevent toxic content from reaching users, which protects both individuals and organizations. In public-facing applications, toxicity detection operates by input filtering, output monitoring, and real-time scoring. This prevents attacks where users intentionally train AI to produce toxic content through coordinated toxic inputs; toxic content will never reach the user, even if produced by the underlying AI, so systems can adjust their behavior dynamically based on conversation content and escalating risks. Unguarded AI can be exploited, which leads to reputational damage.
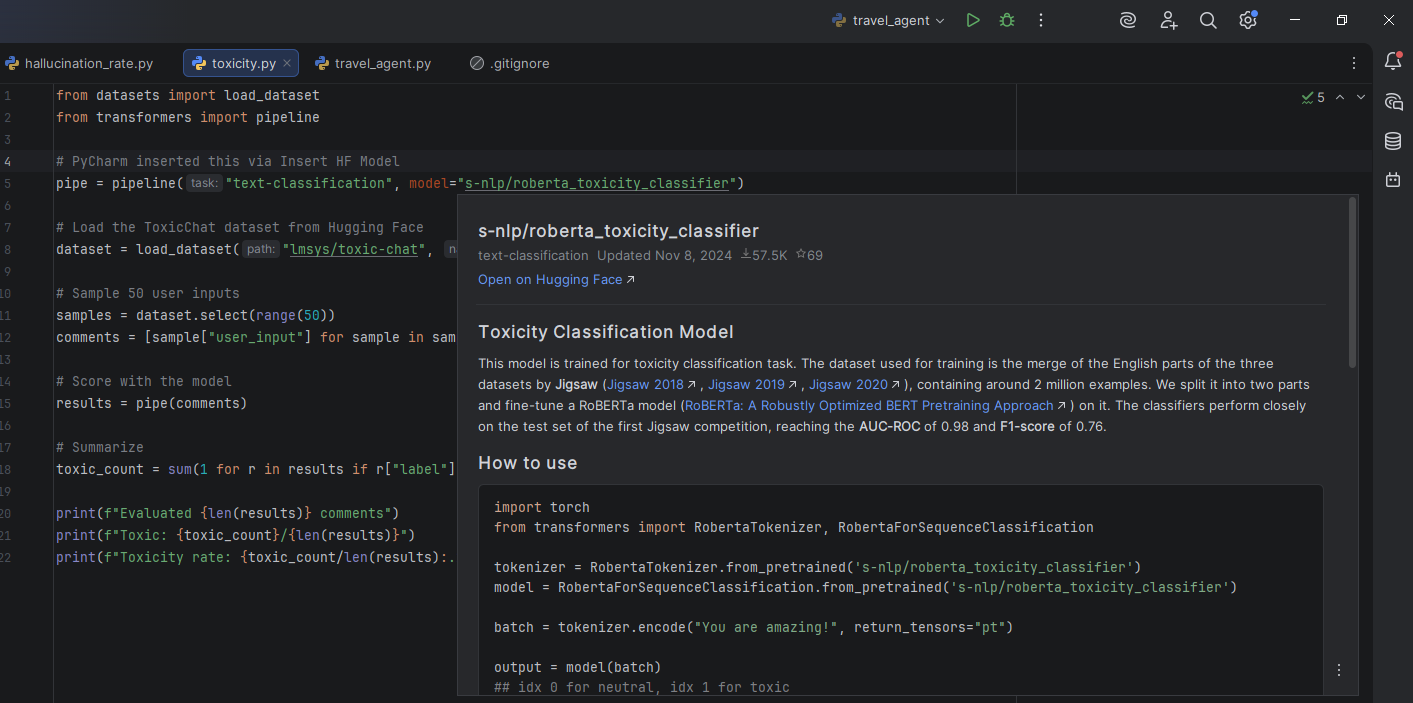
For toxicity evaluation, PyCharm’s Hugging Face Insert HF Model feature helps you discover classifiers like s-nlp/roberta_toxicity_classifier directly in the IDE. Hovering over the model name reveals its model card, where you can see it was trained on the Jigsaw toxic comment datasets, helping you understand what the model can and can’t detect before you write a single line of evaluation code.
Frameworks for LLM evaluation
Frameworks for LLM evaluation have changed the game; teams don’t have to rely on manual reviews, gut instinct, and subjective judgment to assess model quality. These frameworks automate the measurement of model quality using standardized, quantifiable metrics. They assign numerical scores to outputs that measure faithfulness, relevancy, toxicity, and other important dimensions. This automation results in reproducibility, speed, and objectivity.
Consequently, the same input always produces the same score; evaluation runs 10–100 times faster, so in minutes instead of days; and there are no more debates on the quality of the output. Some of these frameworks include DeepEval and Retrieval Augmented Generation Assessment (Ragas). DeepEval is an open-source evaluation framework built with seven principles in mind, such as the ability to easily “unit test” LLM outputs in a similar way to Pytest and plug in and use over 50 LLM-evaluated metrics, most of which are backed by research and all of which are multimodal.
It is extremely easy to build and iterate on LLM applications with two modes of evaluation, namely, end-to-end LLM evals and component-level LLM evals. It is used for comprehensive testing across RAG, agents, and chatbots. Ragas is a framework for reference-free evaluation of RAG pipelines. There are several dimensions to consider, such as the ability of the retrieval system to identify relevant and focused context passages, as well as the capability of the LLM to exploit such passages in a faithful way; hence, it is challenging to evaluate RAG systems. Ragas provides a suite of metrics for evaluating these dimensions without relying on ground-truth human annotations.
The limits of static prompt evaluation
Traditional LLM evaluation methods are useful for single prompt-response pairs, measuring output quality, RAG systems with straightforward retrieval, and static evaluation with fixed inputs. But they are limited for multi-step agents because LLM evaluation focuses on the final output quality, not the decision-making process that produced it. Multi-step agents exhibit a different kind of complexity, as they chain multiple decisions.
Why traditional LLM evaluation isn’t enough for agents
Agents operate independently within complex workflows, and this independence can introduce challenges such as deviation from expected behavior, errors in production, and more failure points than in traditional software applications. Hence, an agent can perform well in testing but fail in production. Traditional LLM evaluations don’t have the capacity to test such use cases. Testing is usually done in a controlled environment with limited scenarios, but production involves real users, edge cases, unpredictable inputs, and scale. This means that agents can make decisions that are not seen in testing, and in production, tasks could be completed, though incorrectly, without generating an error signal. This is where advanced evaluation and monitoring practices come to the rescue! They provide the visibility and systematic measurement needed to deploy agents confidently, rather than relying on trial and error.
The complexity of agent behavior
Traditional LLM evaluation measures single prompt-response pairs: provide an input prompt, receive an output response, and measure quality through metrics such as accuracy, relevance, and faithfulness. Due to the complexity and non-deterministic, multi-step reasoning of AI agents, they cannot be reliably evaluated using traditional evaluation metrics.
Agent behavior is complex, and this complexity introduces challenges. Agents operate in dynamic environments where APIs might be down, databases change between queries, and the “right” answer depends on current conditions. They can use external tools and APIs to complete tasks, and may either use the wrong tool or use the right tool with the wrong parameters or input type. Their internal reasoning traces remain hidden unless they are logged explicitly, so it might be challenging to determine whether an agent was successful through logic or chance. An agent’s output could be perfectly correct despite poor internal decisions, or the entire task could fail despite correct step execution.
This is where observability tooling becomes essential. PyCharm’s AI Agents Debugger breaks open the black box of agentic systems, letting you trace LangGraph workflows and inspect each agent node’s inputs, outputs, and reasoning directly in the IDE, with zero extra code. Just install the plugin, run your agent, and the debugger automatically captures execution traces. Click the Graph button to visualize the full workflow, making it easy to spot where an agent chose the wrong tool, passed bad parameters, or succeeded by luck rather than logic.
To see this in action, I built a simple travel-planning agent using LangGraph in two steps: a research node that suggests summer destinations based on my preferences, and a plan node that picks the best option and builds a three-day itinerary. With the AI Agents Debugger, you can trace exactly what information flowed between these two steps – what the research node suggested and how the planner used those suggestions to build the final itinerary.
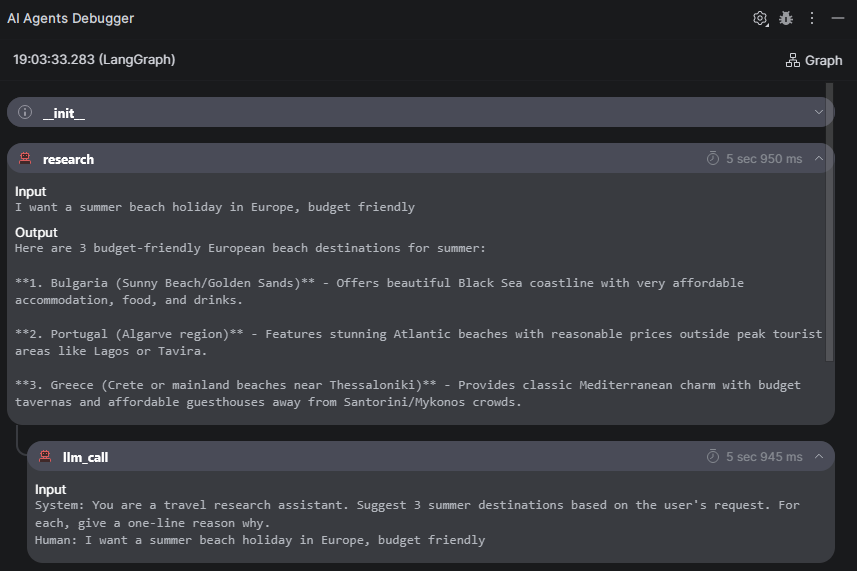
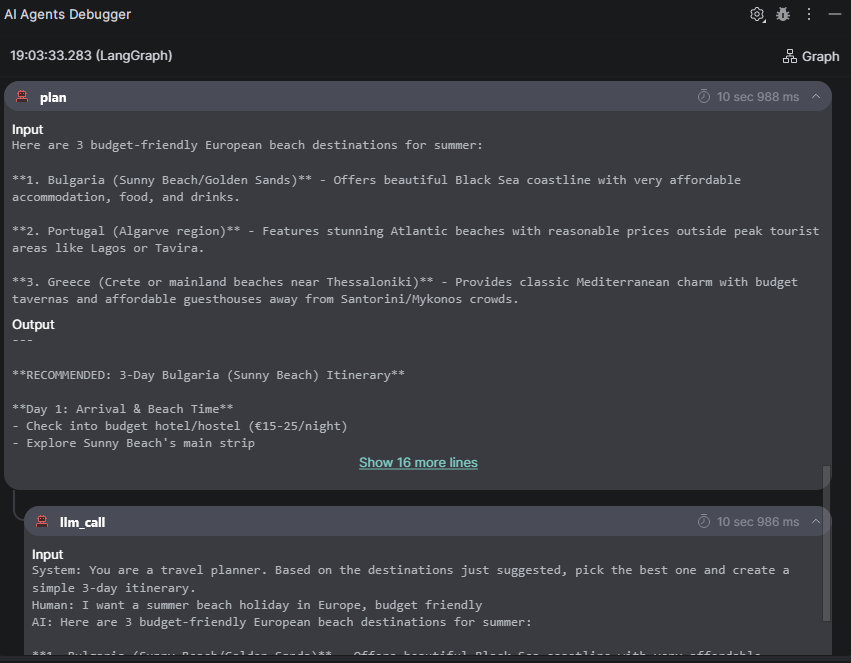
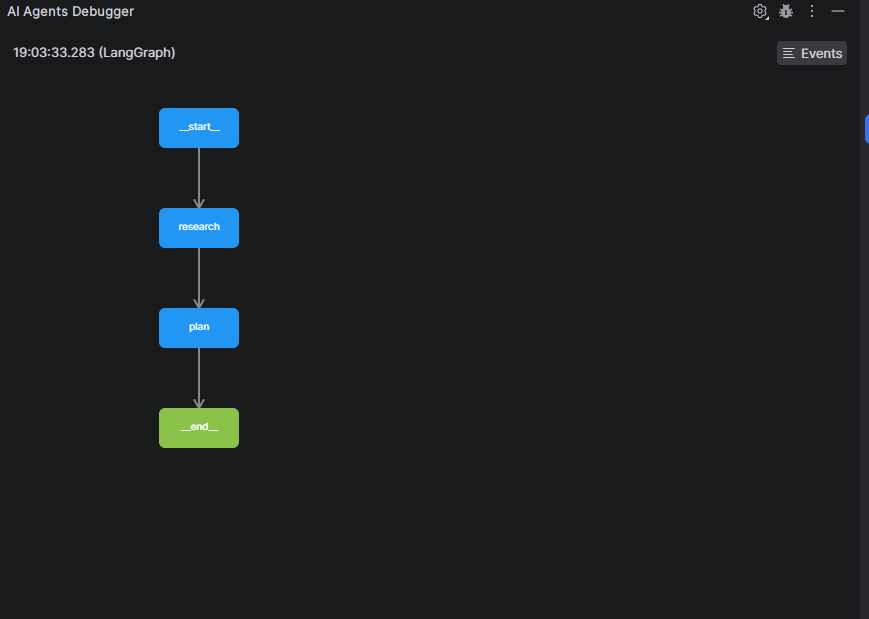
Advanced agent evaluation metrics
The complexity of AI agents demands evaluation that goes beyond considering the final output quality, that is, measuring whether it is accurate, relevant, and grounded. Specialized agent evaluation assesses the complete decision-making process, including the planning logic, tool selection, parameter construction, reasoning coherence, and resource efficiency that led to the final output. Hence, the advanced agent evaluation metrics are designed to make such a process visible and measurable. Some of them are task completion rate, tool usage, reasoning quality, efficiency, and error handling.
Task completion rate
Task completion rate measures the percentage of tasks where an agent successfully achieves the end goal. This is calculated as the number of completed tasks divided by the total number of tasks attempted. The context of “completed” differs by use case. There are real-world use cases for task completion rate. Let’s start with a basic use case. Consider a customer service agent handling a specific food delivery order: “Where is my order #0001? It has not been delivered to me.” Completion rate means successfully looking up the order ID, retrieving the tracking information, and providing an accurate delivery estimate, so all three steps must succeed. If the agent retrieves the wrong order or fails to assess the tracking system, that is a failed task, even if it produces the same output.
Next, let us look at a medium-complexity use case, sequential API calls. Consider an agent tasked with creating a Jira support ticket and notifying the relevant team in Slack. The agent calls the Jira API to create a ticket, parses the response to get the ticket ID, calls the Slack API with the ticket link, and finally verifies the success of both. If the agent successfully creates the Jira ticket, but the Slack notification fails, that is considered a failed task even if the ticket exists in Jira, since the team wasn’t notified.
Finally, let’s examine a high-complexity use case: An agent is given the task of completing an online purchase, which means it must handle everything from checkout to order confirmation. Six steps are involved: Verify the item is still in stock, process the payment with a credit or debit card, reserve or decrement inventory, create an order record, generate an order confirmation number, and send a confirmation email to the customer. If the agent successfully charges the customer’s card but the confirmation email fails to send, that’s a failed task, even if the payment was processed and the order was created. In such a situation, the customer has no proof of purchase, so they will likely contact support or attempt to purchase again.
Tool usage correctness
Tool usage correctness assesses whether an agent correctly identifies and invokes the relevant tools and APIs. It is a deterministic measure that is assessed using techniques such as LLM as a judge, like most LLM evaluation metrics. It has three dimensions:
- Did the agent choose the right tool for the task (tool selection)?
- Were the parameters constructed correctly (input parameters)?
- Did the agent properly use the tool results (output handling)?
Hence, it is important for reliability and functional correctness.
Step-by-step reasoning accuracy
In real-world use cases, an LLM agent’s reasoning is shaped by much more than just the model itself. Modern frameworks such as LangChain expose the agent’s internal “thoughts” through structured logging of intermediate reasoning steps. This is done using the ReAct (Reasoning and Acting) pattern, which involves the agent thinking about what to do, using a tool, observing the tool result, and then repeating until the task is complete. Each “thought” is logged as text, which creates a complete trace of the reasoning process from initial query to final answer. These traces can be extracted programmatically and evaluated to assess whether the agent’s logic is sound even when the final output appears correct. Evaluating planning steps involves assessing aspects such as the overall approach’s logic, the ordering of steps, and whether any steps are unnecessary or redundant. Evaluating execution assesses whether the implementation worked, such as whether tools were called with correct parameters, whether each step was completed successfully, whether errors were handled appropriately, and whether the output was interpreted correctly. This can be done seamlessly in PyCharm using the AI Agents Debugger.
Groundedness (faithfulness)
Groundedness, also known as faithfulness, is the most critical metric for retrieval-augmented generation (RAG), which is a common component of agentic applications. It assesses whether the agent’s response is actually supported by the retrieved source documents or whether, instead, the model hallucinated information. Different evaluation techniques include:
- Atomic claim verification: Breaks up the response into atomic claims and checks each claim against the retrieved context. It is slow but best for production RAG and thorough evaluation.
- Semantic similarity: Compares the embeddings of the response and source documents. It is fast, so it is best for quick checks and first-pass filtering.
- LLM-as-Judge: works by prompting the LLM to score groundedness by extracting factual statements from the response and then checking each statement against the retrieved context. It offers medium speed and is best for flexible, custom criteria.
AI observability and why it matters
AI observability is about visibility into what the agent is doing. This covers recording everything that happens when a task is executed, including the agent’s reasoning at each step, which tools were called with what parameters, what data was retrieved, and how decisions were made from start to finish. With such a transparent system where every decision can be logged and traced, teams are able to understand why an agent fails, behaves unexpectedly, or becomes expensive to run because issues can be debugged and behavior can be audited. Consequently, system design improves, and guesswork is eliminated.
Definition of AI observability
AI observability is the real-time monitoring of agent actions, thoughts, and environmental interactions: what went in, what came out, how the agent thought through the problem, and which tools, APIs, and data were used. AI observability builds on the three pillars of DevOps observability – that is, metrics, logs, and traces – but extends each one for AI’s unique needs. DevOps metrics track CPU and latency, while AI metrics track token usage and cost per interaction. DevOps logs capture system errors, while AI logs capture reasoning traces and decision points. DevOps traces follow requests through services, while AI traces follow reasoning through agent steps, tool calls, and observations.
Benefits for agent monitoring
Agent monitoring has immense benefits – here are some of the most important:
- It debugs reasoning errors: When an agent fails or gives an unexpected output, monitoring provides a complete trace of its decision-making process, which shows exactly where the logic broke down. Hence, there is no need to spend hours guessing the causes.
- It measures performance and latency over time: Since metrics such as average latency, token usage, cost per interaction, and completion rates across all queries are tracked, degradation patterns can be identified before they affect users. As a result, performance issues can be identified and resolved before users file any complaints.
- It identifies regressions after model or prompt updates: Baseline metrics such as completion rate, faithfulness scores, latency, and cost are established and then monitored for deviations after deployments. If a new prompt drops the compilation rate or a model update increases the hallucination rate, automated alerts catch it immediately. Hence, issues are caught before users are affected.
Popular tools for agent monitoring
Several frameworks and platforms have emerged to provide built-in observability for AI agents, with each having different strengths and integration approaches and matching different features and requirements. The choice of the right tool depends on the framework, deployment preferences, and primary needs. The table below shows some popular tools and whether they match different features and requirements.
| Tool | Traces agent steps? | Tracks costs? | Detects regressions? | Self-hostable? | Open source? | Easy integration? |
| Helicone | Yes | Yes | Yes | Yes | Yes | Yes |
| LangSmith | Yes | Yes | Yes | Limited | No | Yes |
| LangFuse | Yes | Yes | Yes | Yes | Yes | Moderate |
| OpenLLMetry | Yes | Limited | Limited | Yes | Yes | Moderate |
| Phoenix | Yes | Limited | Yes | Yes | Yes | Moderate |
| TruLens | Yes | Limited | Yes | Yes | Yes | Moderate |
| DataDog | Limited | Yes | Yes | No | No | Moderate |
Best practices for evaluating agents in production
Evaluation does not end after deployment; rather, it is intensified. This continuous evaluation tracks how much the system costs to run, how quickly it responds under various loads, and how it handles errors or unusual inputs. Without such evaluation, problems can only be identified after the users are affected. An agent can pass all the quality checks with excellent faithfulness scores, high completion rates, and strong reasoning but fail in production if costs spiral, latency increases, or edge cases cause instability. Hence, there is a critical need for ongoing evaluation and monitoring, which will lead to systems that are reliable, scalable, and financially sustainable.
Monitor cost and latency
Monitoring cost and latency is critical for production sustainability. Token usage and response time must be tracked continuously because small inefficiencies compound dramatically over time, and the cost per token of the powerful reasoning models used for agents can be high. Production workloads require cost and latency monitoring to identify problems before user experience and budget are impacted. Cost monitoring tracks token usage at different levels, such as per request, per query type, and over time. Without visibility into patterns generated by these, teams end up discovering cost problems through surprise bills. With monitoring, they can proactively cache common queries and optimize prompts to reduce token use. Latency monitoring reveals track response time and component breakdowns to identify bottlenecks.
Cost control in production workloads is important because production costs can spiral quickly, unmonitored systems can exceed budgets, and latency impacts user experience and retention.
Combine offline and online evaluation
Effective agent evaluation requires combining offline and online evaluation, where each addresses gaps the other leaves. Offline evaluation uses fixed test databases for reproducible benchmarking, which enables fast iteration on prompts and models in controlled environments without production risk. Online evaluation monitors real user interactions in production, which reveals edge cases in testing that were never expected, so it is useful for real-time feedback, user data, and observability tools. A combination of both results in an optimal strategy where offline evaluation validates changes before deployment, then online evaluation monitors production reality.
Use human-in-the-loop when necessary
LLM agents are appreciated for how they have played a positive role in the different ecosystems, but not every agent should run autonomously since they can misinterpret prompts, cross boundaries, or make dreadful errors that can’t be caught by automation alone. Hence, the need for human-in-the-loop failsafes. Human-in-the-loop is also essential during initial setup: Unless teams already have domain-specific evaluation datasets for monitoring the agent, these will need to be created manually by assessing the agent’s performance. A hybrid approach is required when critical decisions require human validation, such as approving transactions, modifying sensitive data, or triggering irreversible workflows. In this approach, it is important that decisions are routed through a human checkpoint before proceeding. The intention is not to slow automation but rather to ensure that the right decisions involve the right oversight. A well-designed human-in-the-loop system delivers compound returns over time. Every human correction becomes feedback, which improves the agent’s accuracy and gradually reduces the need for manual review. Human oversight isn’t treated as a failure but rather as a safety net that makes the system better with use.
Final thoughts
Fundamentally, AI agents are different from single-prompt LLMs. They navigate multi-step workflows, make autonomous decisions, and use external tools, which introduces complexities that demand continuous evaluation, not just static testing. Evaluation must evolve from pre-deployment checkpoints to ongoing monitoring. Production-ready agents aren’t just well-tested; they’re continuously observed and improved based on real behavior. LLM evaluation and AI observability enable faster, safer iteration by catching issues early and feeding production insights back into development.
PyCharm streamlines agent development with integrated debugging, profiling, and testing. Step through reasoning with breakpoints, find cost bottlenecks, and iterate on evaluation tests rapidly. These workflows transform hours of debugging into minutes of systematic investigation. Explore PyCharm for AI development to see how integrated tools can help you build, evaluate, and deploy reliable AI agents.
About the author







