

The Unglamorous Side of Rust Web Development


This is a guest post by Mateusz Maćkowski and Marek Grzelak, co-maintainers of cot.rs and speakers at Rustikon 2026. You can watch their full talk here.
In the very beginning, all we wanted to do was build a JSON API. After doing that a few times in Rust, we noticed a recurring pattern. Every new project meant choosing libraries, wiring everything together, writing the same glue code, and solving the same setup problems again.
That pattern is one of the reasons we started working on cot.rs. We wanted Rust web development to feel less like assembling a custom toolbox every time, and more like starting with the pieces you already know you’ll need.
The advantages of Rust are well known: its safety, performance, strong types, and the specific confidence you get when your code finally compiles. This post is about everything that happens before compilation.
TL;DR
- Async Rust is powerful, but the debugging experience is still rough. One panic! can give you a 100-frame backtrace, with the actual issue in your code appearing between frames 9 and 10.
- Rust ORMs require you to maintain the same schema in multiple places. Declarative migrations are a better direction, and several projects are exploring this.
- Error handling in Rust web frameworks is inconsistent. Getting errors to behave predictably across an entire application is harder than it sounds.
- Macros are everywhere in the Rust web stack. When they work, great. When they don’t, you’re reading thousands of lines of generated code.
- Compile times are a real cost for web development. A single web framework dependency can grow your dependency tree tenfold.
- The ecosystem is fragmented. You choose almost every part of the stack yourself, which is powerful for experienced developers and overwhelming for everyone else.
- Batteries-included frameworks like Loco.rs and cot.rs are closing the gap, but we’re not at Django or Rails level yet.
Async: Fast, clever, and not always friendly
The first problem, and arguably the most prominent one, is async.
Rust’s async model is genuinely ingenious. It was implemented in a very clever way, and it really shows that smart people worked on it. But while it’s technically impressive, the developer experience is not quite there yet.
To use it comfortably, you need to understand both async fn and how to implement Future yourself, and they’re different enough that it can feel like learning two separate things. Then there’s the question of tasks versus threads, and if you mix them up and use the wrong data structures, you can end up with deadlocks or subtler problems. There’s still no async drop in stable Rust. And if you’ve ever tried to truly understand pinning, it’s genuinely difficult to wrap your head around why it’s even needed.
Debugging is where all of this becomes very visible. When you yield from an async function, execution returns to the runtime, and when it resumes in your function, the backtrace is essentially reset. That produces backtraces that are both huge and hard to use, and it creates problems not just for debugging, but for logging, tracing, and learning.
Here is the code that produced one of our own backtraces:

One line. The backtrace ran to 100 frames, most of them async runtime machinery. The actual program, an issue from our code, was visible between frames 9 and 10. Technically correct. Practically, not very useful.
And that’s before you get into questions like why your future isn’t Send, or why a particular future is consuming an unexpected amount of memory. Async Rust gives you performance and flexibility, but for web development specifically, it makes simple things feel more complicated than they need to be. There are active initiatives in the Rust community to improve this, but the current state still has a way to go. If you want to go deeper on where the async ecosystem is heading, this conversation with Carl Lerche, the creator of Tokio, is worth reading.
Database access: Write your schema once, then write it again
The next rough edge is database access.
Rust has solid libraries for working with databases, but the workflow can feel more manual than it should be. In Diesel, you define your model in Rust, write SQL migrations, and also maintain an automatically generated schema.rs file. That’s three representations of the same data. And yes, Diesel still uses raw SQL migrations, which is why tools like diesel-guard exist, to warn you when a migration is written in a way that could cause problems on large tables.
SeaORM improves parts of the experience, but migrations can still feel like SQL written with Rust syntax on top. It’s a common pattern across the ecosystem: specialized query DSLs that each create their own little language. We want to write modern web applications, but we end up feeling like it’s a 2005 PHP project.
The problem isn’t that SQL exists. The problem is how much repeated work builds up around it. If we’re already creating another layer for queries, it should at least be readable. Django figured this out over 20 years ago. You shouldn’t need to write migrations by hand just to change a schema.
Compare these two approaches to the same query:

VS

You read code much more often than you write it. If we’re already inventing another language, we can at least make it a readable one.
The same principle applies to migrations. In cot.rs, we’re exploring declarative migrations, where a migration is represented as a structured operation at the framework level rather than raw SQL you write and maintain yourself:
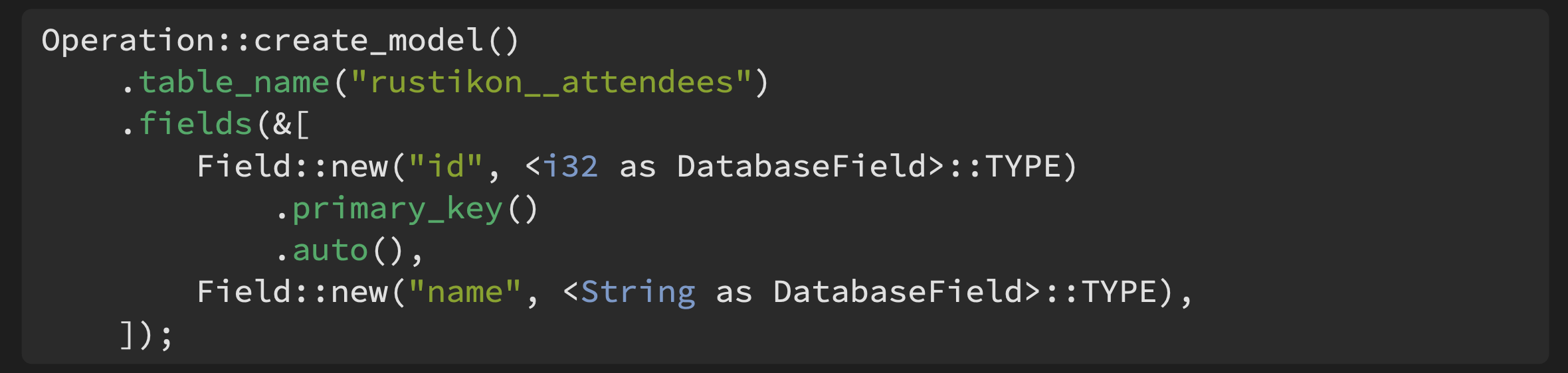
Instead of writing SQL directly, the framework represents the change as an operation, validates it, and generates the SQL itself. Problems like a migration that would be dangerously slow on a large table can be caught and handled at the framework level rather than by a separate linting tool.
We’re not the only ones thinking about this. Projects like toasty and rorm are experimenting with similar approaches. Database access in Rust doesn’t need to become magical. It just shouldn’t feel like writing the same thing three times in three slightly different languages.
Error handling: Returning an error is easy; returning the right one is harder
Error handling in a web framework sounds simple until you start caring about the details.
A good error handling approach needs to do several things at once: be easy to write and register, have access to as much context as possible, be consistent across the whole application, and pass through the same middleware as any other response. That’s a surprisingly hard combination to get right.
In Axum, there are two different mechanisms for converting errors into responses, IntoResponse and HandleErrorLayer, which means when you’re starting out, it’s not obvious which one you should actually use. IntoResponse requires you to implement it for every individual error type, so different error types from different libraries can end up returning different response shapes. Consistency is hard to guarantee.
Actix-web takes a different approach with the ResponseError trait, which is cleaner in some ways. But it can only access the error object itself, not the broader request context you might need to build a useful response.
Middleware adds another layer of complexity. If your application compresses responses, adds headers, or does any other processing, you want error responses going through the same path. The tower-http ecosystem has a lot to offer here, but it was designed in a way that consumes the request, which means when you’re handling an error, you may no longer have access to the context you need.
Rust is very good at making errors explicit. The harder part for web development is making them consistent, predictable, and well-integrated with the rest of the application stack.
Metaprogramming: Useful magic is still magic
Macros are one of the reasons Rust web frameworks can feel nice to use. They handle boilerplate, provide powerful functionality, and make APIs feel cleaner than they’d otherwise be. Routing, serialization, extractors, database queries, framework setup. Macros are everywhere in the Rust web stack.
When they work, they’re great. When they don’t, they become black boxes. Unless you dig into the generated code, it can be very hard to understand what went wrong. Error messages from failed macro expansions often point somewhere inside the generated code rather than at what you actually did wrong. And if the macro generates a lot of code, figuring out the problem becomes a real task.
IDE support for procedural macros is also uneven. Generating that much code is not a simple challenge, and not all IDEs handle it equally well.
And then there are generics. They help us build composable, reusable software. But in web frameworks, you have many layers stacked on top of each other: middleware, extractors, serializers, the request itself. We found that generics alone could push a binary from around 2MB to 37MB in release mode once everything was compiled. Monomorphization makes your program fast at runtime, but it gives the compiler considerably more work to do.
The issue isn’t that macros or generics are bad choices. It’s that Rust web development tends to layer many powerful abstractions on top of each other, and at some point understanding that stack becomes part of the job.
Iteration speed: “I changed a string, see you in a minute”
All of those abstractions have a cost that becomes very visible when you’re trying to move fast.
Web development is a tight loop: You make a change, run it, see what happens, and then make another change. That loop needs to be fast. In Rust, it often isn’t, and in web applications specifically, the problem compounds because you’re combining several things that each make the compiler work harder.
Monomorphization from generics takes time. Dependencies add up fast; adding a single web framework crate can increase your dependency tree tenfold. Macros have their own cost, too.
If you want a concrete example of how bad this can get, one documented analysis found expand_crate taking 67.5% of total compile time in a macro-heavy SQLx project. The compile-time SQL verification SQLx does is genuinely useful, but it comes with a real cost.
Can you speed it up? Yes, but only a little. You can disable optimizations in development builds, use alternative compiler backends, and adopt faster linkers. You can also prefer dynamic dispatch over generics in places where the performance trade-off is acceptable. Your code compiles faster, though you give up some compile-time safety guarantees. Hot reloading is also being explored; subsecond from the Dioxus team is one project attempting to tackle this, and we’ve been experimenting with it.
None of these make the problem disappear. For now, Rust web development asks you to accept a slower feedback loop than many web developers are used to. The friction rarely lives in just one place. It’s the way async, macros, generics, and dependencies all accumulate when you’re trying to build something complete.
Ecosystem fragmentation: Choosing everything yourself
This brings us to the part that makes everything else harder to navigate. When you start a Rust web project, the stack is yours to assemble. You pick the web framework, the database layer, the migration approach, the templating engine, the frontend integration, and the authentication method. Each piece has several options, and they don’t always compose cleanly.
The arewewebyet.org project summarizes it well. The page hasn’t been updated in about five years, but the point mostly still stands: Rust doesn’t have a dominant batteries-included framework at the level of Django or Rails. Most Rust web frameworks are smaller and modular, closer in spirit to Flask or Sinatra. The ecosystem is diverse, but you generally have to wire everything together yourself.
For experienced Rust developers who already have a preferred stack, that flexibility is often welcome. For developers newer to the ecosystem, or teams that just want to start building, it can be overwhelming before you’ve written a single line of business logic.
This is part of what motivates batteries-included frameworks. Loco.rs is the most established of them, already used in production by many teams. We’re working on cot.rs with similar goals, trying to close the gap and give developers a more complete starting point. Roadster is another project in this space, though it’s less widely known and we’re honestly not sure how much production use it sees yet.
None of these projects solve every problem we’ve described. Async is still async. Compile times still matter. Macros still need to be understood. But a more coherent starting point removes at least some of the repeated work that comes before the actual application.
So, is it worth it?
Rust web development in 2026 is better than it’s ever been, but it’s still not the fastest ecosystem to work in. The compiler catches most bugs before you ship, and in production that matters. Whether that tradeoff is worth it comes down to one honest question: How expensive are your bugs really?
If reliability and performance are core requirements, Rust’s drawbacks are probably worth it. If you need to move fast on something simple, Python will still get you there faster. Just go in knowing the difference.
We’re not there yet. But we’re getting there.
Frequently asked questions
Is Rust good for web development in 2026?
Yes, with realistic expectations. The ecosystem is more mature than ever, but it asks more of you upfront than Python or JavaScript. If your project needs performance, memory safety, or long-term reliability, it’s worth the investment. If you need to move fast on a simple CRUD app, you might be happier somewhere else for now.
What are the main problems with async Rust?
Backtraces become hard to read because the runtime resets them when execution yields. There’s still no async drop in stable Rust. Understanding tasks versus threads and how to handle pinning adds real complexity on top of an already demanding model. The performance is excellent. The ergonomics are catching up.
Why are Rust compile times so slow in web projects?
Several things compound each other: monomorphization from generics, large dependency trees, macro expansion at compile time, and the complexity of async code. Tools like faster linkers and alternative compiler backends help, but none of them solve it completely.
What is cot.rs?
A batteries-included Rust web framework we’re building to make starting a web project feel less like assembling a toolbox. It includes declarative migrations, readable query macros, auto-generated OpenAPI documentation, admin panel, and a more integrated approach to the full stack. You can find it at cot.rs.
Which Rust web framework should I use?
Axum and Actix-web are the most widely used for APIs. For a more complete starting point with less configuration, Loco.rs and cot.rs are worth exploring. There’s no single dominant choice yet, and that’s part of what makes starting a new Rust web project harder than it should be.





