JetBrains AI
Supercharge your tools with AI-powered features inside many JetBrains products
Introducing Koog Integration for Spring AI: Smarter Orchestration for Your Agents


Spring AI is the application-facing integration layer you may already use. Koog is the next layer up when you need agent orchestration. Spring AI already covers the chat model API, chat memory, and vector storage for RAG, and it provides Spring Boot starters with auto-configuration. Koog’s role is not to erase that, but rather to add a stronger agent runtime, offering:
- Multi-step strategies and workflows for more precise control.
- Persistence and checkpoints for fault-tolerant execution.
- Sophisticated history management for cost-optimization.
- Automated deterministic planning.
You can now get the best of both worlds. Koog offers seamless Spring AI integration and can be easily layered on top as a higher-level agentic runtime.
Spring AI
If you already use Spring AI, you’re familiar with its broad integration landscape: 13+ LLM providers, 18+ vector databases, and 10+ chat memory backends, all built seamlessly into the Spring ecosystem.
Your application likely already relies on some of these integrations and wasn’t built in isolation. But as your agent’s complexity increases and business requirements demand more reliability, you start needing things that sit above the integration layer, for example, controlled execution logic, guardrails, fault tolerance, and cost optimization. These are the problems Koog was built to solve.
| Capability | Spring AI | Koog |
| LLM providers | ✅ 13+ | ✅ 16+ |
| Streaming | ✅ Supported | ✅ Supported |
| Tool calling | ✅ Supported | ✅ Supported |
| Database integrations | ✅ 10+ (e.g. PostgreSQL and MongoDB) | Uses the underlying ecosystem with a few integrations provided out of the box (e.g. Postgres) |
| Vector databases | ✅ 18+ (e.g. Milvus, Weaviate, and PGvector) | ✅ Uses underlying integrations |
| RAG (retrieval-augmented generation) | ✅ Supported via advisors and VectorStore | ✅ Supported and integrated into agent workflows |
| Chat memory (short-term) | ✅ Supported | ✅ Supported |
| Long-term memory | ✅ Supported via vector DB integrations | ✅ Built-in and pluggable (semantic and structured memory) |
| Observability | ✅ Basic observability from the Spring ecosystem (Micrometer, etc.), not tailored for LLM or AI observability tooling | ✅ OpenTelemetry support, built-in tailored support for popular LLM or AI observability tooling (e.g. Langfuse, W&B Weave, and Datadog) |
| Parallel execution | ❌ Limited, manual | ✅ Native (coroutines and concurrent node execution) |
| Agent strategies | ❌ Basic (prompt chaining and tool calling) | ✅ Advanced type-safe graph workflows (multi-step reasoning, branching, tool orchestration, domain modeling approach), advanced planners (LLM-based and GOAP) |
| Persistence | ❌ Not built in, only the message history can be saved | ✅ Built-in advanced persistence for the agent’s logic and state |
| History compression | ❌ Not built in | ✅ Native support with out-of-the-box advanced strategies (summarization, pruning, and token optimization) |
The good news is you don’t have to choose one or the other, or dramatically change your existing setup to get there. Koog’s new Spring AI integration lets you keep your current LLM providers and databases exactly as they are, while writing your agents in Koog with minimal configuration changes. Your integration layer stays intact. Koog simply adds a powerful orchestration runtime on top of it.
Let’s take a look at how it works. This post uses a Kotlin and Gradle setup for simplicity, but you can also use the recently released native Java Koog API (and, of course, Maven).
Koog’s Spring AI integration
Let’s say your Spring project already uses three common Spring AI interfaces: ChatModel, ChatMemoryRepository, and VectorStore. Adding Koog on top is just a three-step process.
Step 1: Keep your existing Spring AI dependencies.
// LLM
implementation("org.springframework.ai:spring-ai-starter-model-openai")
// Chat memory
implementation("org.springframework.ai:spring-ai-starter-model-chat-memory-repository-jdbc")
// Vector store
implementation("org.springframework.ai:spring-ai-starter-vector-store-pgvector")
Step 2: Add the Koog integration dependencies.
// Koog
implementation("ai.koog:koog-agents-jvm:0.8.0")
// Bridges ChatModel to Koog's LLMClient / PromptExecutor
implementation("ai.koog:koog-spring-ai-starter-model-chat:0.8.0")
// Bridges ChatMemoryRepository to Koog's ChatHistoryProvider
implementation("ai.koog:koog-spring-ai-starter-chat-memory:0.8.0")
// Bridges VectorStore to Koog's KoogVectorStore
implementation("ai.koog:koog-spring-ai-starter-vector-store:0.8.0")
Step 3: Use the auto-configured Koog beans. Each Koog starter automatically exposes a Spring bean that wraps your existing Spring AI bean:
| Spring AI interface | Koog bean(s) |
ChatModel | PromptExecutor, LLMClient |
ChatMemoryRepository | ChatHistoryProvider |
VectorStore | KoogVectorStore |
The beans are auto-configured by default when there is a single matching Spring AI candidate, so your existing Spring AI application config stays untouched.
That’s it for setup. Now let’s walk through what you can build. To make things concrete, we’ll use a customer support agent as our running example and progressively add capabilities.
When a pure Spring AI agent reaches its limit
One version of an agent that you could build in pure Spring AI would look like this:
@Service
class CustomerSupportService(
chatClientBuilder: ChatClient.Builder,
vectorStore: VectorStore,
chatMemory: ChatMemory,
) {
// Build a fully configured ChatClient once at construction time
private val chatClient: ChatClient = chatClientBuilder
.defaultSystem("""
You are an e-commerce support assistant.
Be concise and policy-aware.
Never invent order data.
If order context is missing for an order-specific request, ask for it.
""".trimIndent())
.defaultAdvisors(
// Vector store RAG advisor – enriches every prompt with relevant docs
QuestionAnswerAdvisor(
vectorStore,
SearchRequest.builder()
.topK(4)
.similarityThreshold(0.7)
.build()
),
// Sliding-window chat memory advisor – keeps last N turns per session
MessageChatMemoryAdvisor(chatMemory)
)
.build()
suspend fun createAndRunAgent(userPrompt: String, sessionId: String): String? =
chatClient.prompt()
.user(userPrompt)
// Scope memory to session
.advisorParam(ChatMemory.CONVERSATION_ID, sessionId)
.call()
.tools()
.content()
}
This agent implements a simple tool-calling loop that runs on top of the LLM defined in the config and inserted as a ChatClient. Besides this, the agent has two features. The first is QuestionAnswerAdvisor, which is built on top of VectorStore and behaves like RAG, enriching the conversation with relevant information from external docs. The second is ChatMemory, which keeps only a specified number of messages, helping you control the number of messages in a conversation and save tokens.
But what if we don’t want a window of messages but a message history summary instead? Or, increasing complexity, what if, instead of a primitive tool-calling agentic loop, we wanted a more controllable and tailored strategy with different e-commerce support scenarios, or persistence and durable execution to make our agent fault-tolerant? This is where we reach the limits of Spring AI. But these, and many other agentic features, already exist in Koog and, thanks to the integration, they can easily be built on top of what you’ve already set up for Spring AI in your project.
What does Koog’s Spring AI integration enable?
First of all, this is what our e-commerce agent would look like in Koog.
@Service
class CustomerSupportService(
private val promptExecutor: PromptExecutor,
private val chatStorage: ChatHistoryProvider,
private val knowledgeBase: SearchStorage<TextDocument, SimilaritySearchRequest>
) {
suspend fun createAndRunAgent(userPrompt: String): String {
val agentConfig = AIAgentConfig(
prompt = prompt("ecommerce-support") {
system(
"""
You are an e-commerce support assistant.
Be concise and policy-aware.
Never invent order data.
If order context is missing for an order-specific request, ask for it.
""".trimIndent()
)
},
model = OpenAIModels.Chat.GPT5Nano,
maxAgentIterations = 100
)
val toolRegistry = ToolRegistry {
tools(EcommerceSupportTools())
}
val agent = AIAgent(
promptExecutor = promptExecutor,
agentConfig = agentConfig,
toolRegistry = toolRegistry,
// Simple tool-calling loop strategy
strategy = singeRunStrategy()
) {
// Vector store RAG advisor – enriches every prompt with relevant docs
install(LongTermMemory) {
retrieval {
storage = knowledgeBase
searchStrategy = SimilaritySearchStrategy(
topK = 4,
similarityThreshold = 0.70
)
promptAugmenter = UserPromptAugmenter()
}
}
// Sliding-window chat memory advisor – keeps last N turns per session
install(ChatMemory) {
chatHistoryProvider = chatStorage
windowSize(20)
}
}
return agent.run(userPrompt)
}
}
With Koog’s Spring AI integration, the PromptExecutor bean is auto-configured from your existing Spring AI ChatModel. You inject it directly into your service – no boilerplate configuration class needed.
The same is true for the doc database and chat memory storage features. You don’t need to make any changes to the application config. With Koog beans, they are seamlessly injected into Koog’s LongTermMemory and ChatMemory and used under the hood.
What can you add on top?
Controllable type-safe workflows
Simple LLM loops lack predictability and control for enterprise scenarios. Each iteration is opaque. You can’t branch based on tool results, retry failed steps, or enforce specific conversation flows. For production support agents handling refunds, escalations, or multi-step verifications, you need explicit control over the execution path.
With Koog, in addition to using predefined strategies (such as default loop or ReAct), you can customize a strategy using graphs:
val agent = AIAgent(
promptExecutor = promptExecutor,
agentConfig = agentConfig,
toolRegistry = toolRegistry,
// Graph strategy, can accept and return anything!
strategy = strategy<String, String>("ecommerce_support") {
// Define graph here
}
)
Instead of putting all of the instructions in a single naive text prompt, the best way to do this is to use structured output and then append an intent-specific prompt to it. This approach reduces the amount of context and gives you more control.
@SerialName("SupportIntent")
@Serializable
enum class SupportIntent {
ORDER_STATUS,
CHANGE_ADDRESS,
REFUND,
OTHER
}
@Serializable
@LLMDescription("Normalized support request extracted from a user message.")
data class SupportRequest(
@property:LLMDescription("Detected support intent")
val intent: SupportIntent,
@property:LLMDescription("Order ID if present, otherwise null")
val orderId: String? = null,
)
val graphStrategy = strategy<String, String>("ecommerce_support") {
// 1) Detect the intent of the request from user message
val classifyRequest by nodeLLMRequestStructured<SupportRequest>(
examples = listOf(
SupportRequest(
intent = SupportIntent.ORDER_STATUS,
orderId = "84721",
userRequest = "Check the status of order 84721"
)
)
)
}
Once you know the intent, you can append intent-specific instructions or narrow down the required tools and delegate the task to a subgraph with a tool-calling loop:
val graphStrategy = strategy<String, String>("ecommerce_support") {
...
// 2) Check that all request information is provided
val checkRequest by node<SupportRequest, CheckRequestResult> { request ->
when {
request.intent == SupportIntent.OTHER ->
CheckRequestResult(
request = request,
needsMoreInfo = true,
clarificationQuestion = "Specify the intent: order status, refund, change address?"
)
...
else ->
CheckRequestResult(
request = request,
needsMoreInfo = false
)
}
}
// 3a) Process order status request in separate subgraph with additional prompt (or tools subset)
val orderStatusFlow by subgraphWithTask<SupportRequest, String>(
tools = EcommerceSupportTools().asTools()
) { req ->
"""
Handle this request as an ORDER STATUS case.
Use the order status tool and then answer the user clearly.
Request: ${req.userRequest}
Order ID: ${req.orderId}
""".trimIndent()
}
// 3b) Process other intents
...
}
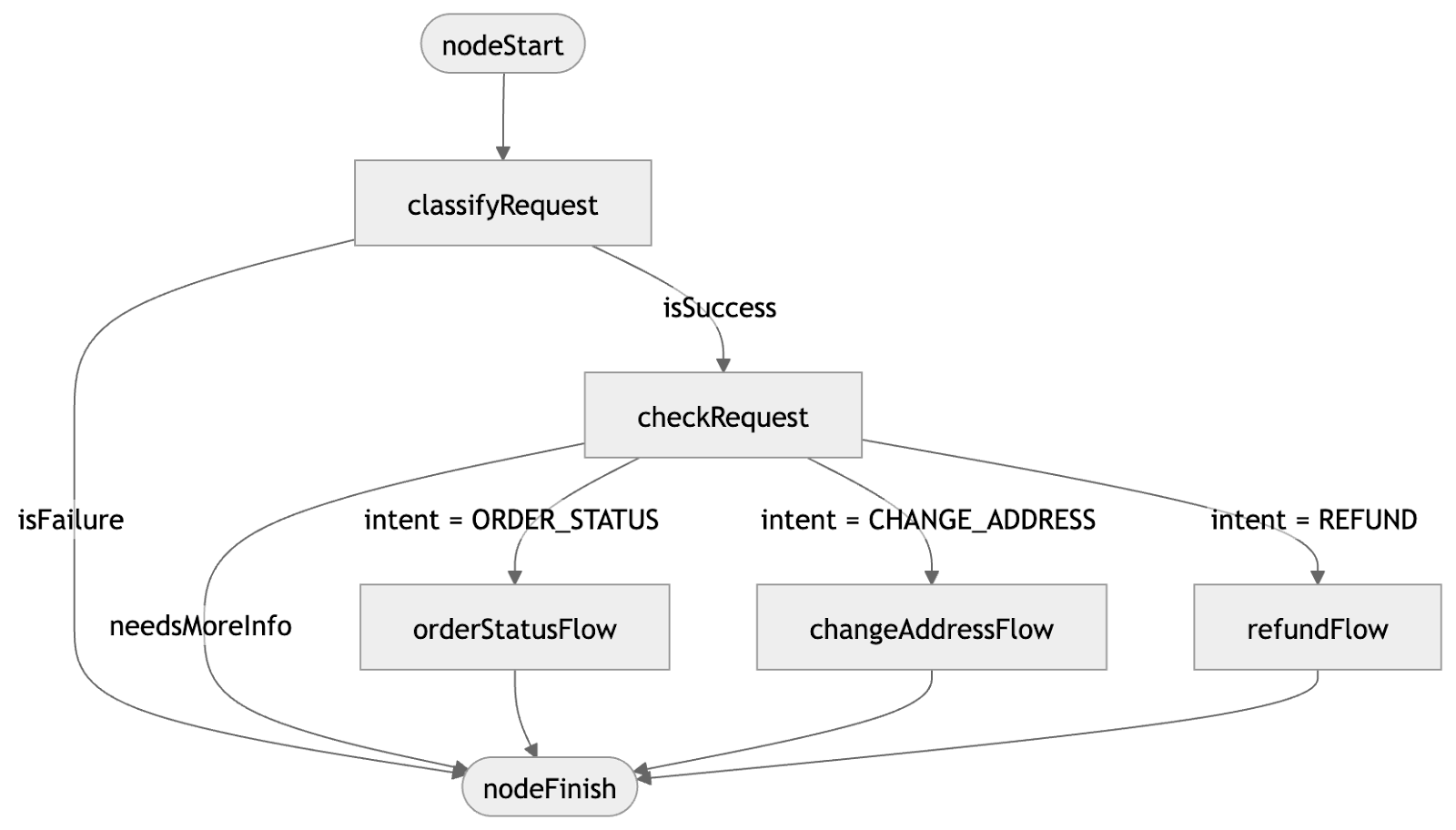
Finally, you can organize each step of your workflow into a graph using type-safe edges and conditions that control your agent’s behavior:
val graphStrategy = strategy<String, String>("ecommerce_support") {
...
// Chain all nodes by edges
edge(nodeStart forwardTo classifyRequest)
edge(classifyRequest forwardTo checkContext
onCondition { it.isSuccess }
transformed { it.getOrThrow().data }
)
edge(classifyRequest forwardTo nodeFinish
onCondition { it.isFailure }
transformed { "Failed to classify request." }
)
// If more information is required
edge(checkContext forwardTo nodeFinish
onCondition { it.needsMoreInfo }
transformed { it.clarificationQuestion }
)
// If we know the intent
edge(checkContext forwardTo orderStatusFlow
// Add intent == SupportIntent.ORDER_STATUS condition for the transition
onCondition { request.intent == SupportIntent.ORDER_STATUS }
transformed { it.request }
)
...
edge(orderStatusFlow forwardTo nodeFinish)
}
You have complete freedom to experiment and make the agent as complex as you need it to be.
Persistence (durable execution)
There’s complex logic at play, so you need to be extremely careful not to lose the execution point and state. And thanks to graphs, that’s possible. Just install and configure the Persistence feature, which will also use the data source from Spring!
@Service
class CustomerSupportService(
private val dataSource: DataSource,
...
) {
...
val agent = AIAgent(
...
) {
// Make agent fault-tolerant using Koog's persistence.
// The agent will recover from the exact graph node where it crashed
install(Persistence) {
// Configure where to store the checkpoints:
storage = PostgresJdbcPersistenceStorageProvider(dataSource)
}
}
}
The persistence feature allows the agent to recover from the exact graph node where it failed and continue execution, which is essential for building reliable services.
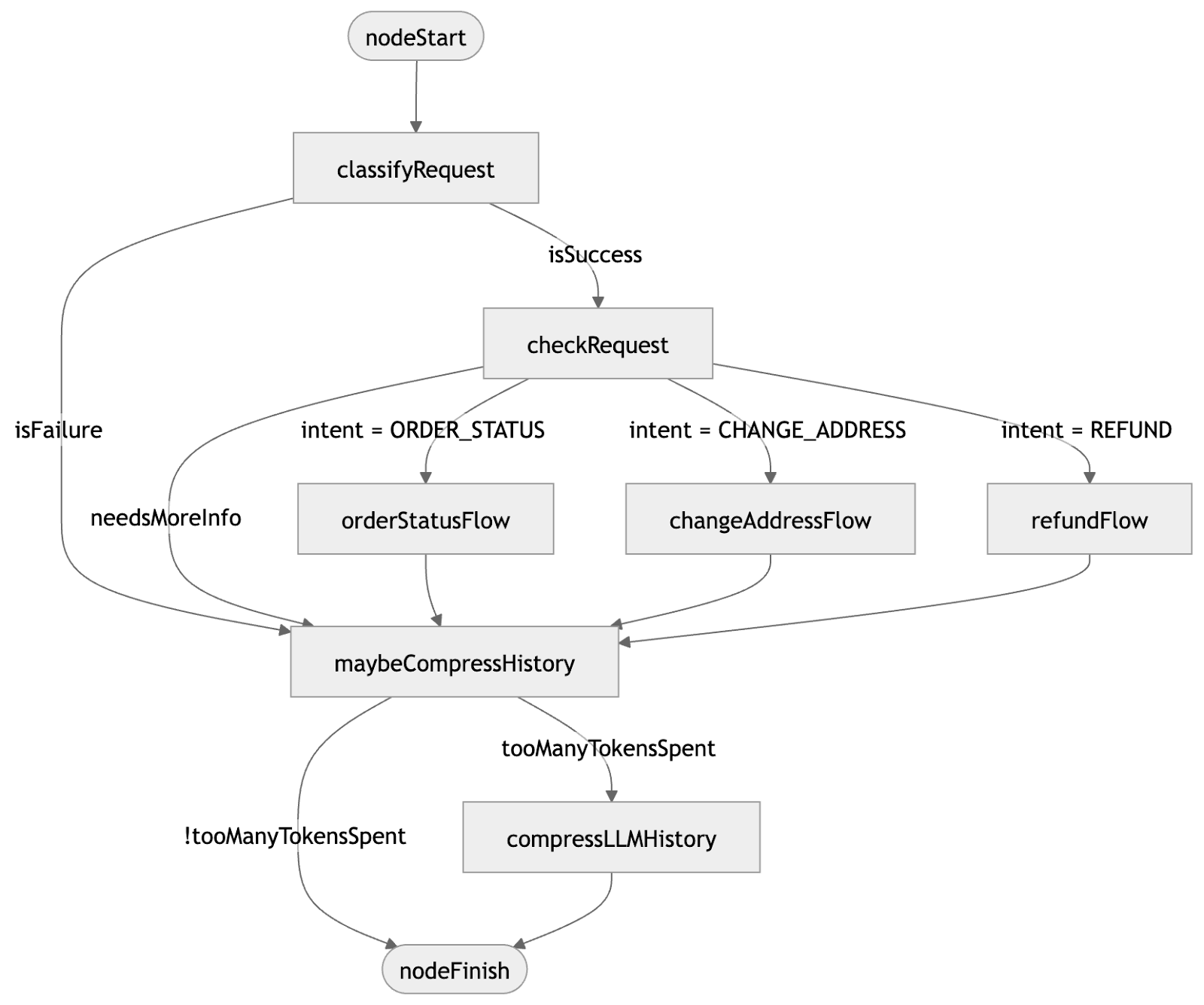
History compression
Once you start scaling your AI agents to millions of users and longer-running sessions, managing LLM costs becomes critical. Each step of the agent’s execution, typically a tool call or an LLM request, adds to the message history, and every token has a price. Beyond cost, every model has a context window limit that’s easy to hit when processing large documents, handling tool outputs, or running extended sessions.
You don’t want to silently drop earlier messages when the window fills up. But you also don’t want to pay for irrelevant tokens or risk the model losing important context. Instead of dropping the history, you can replace it with a summary:
private fun AIAgentGraphContextBase.tooManyTokensSpent(): Boolean =
llm.prompt.latestTokenUsage > 1000
val graphStrategy = strategy<String, String>("ecommerce_support") {
...
// Compress history node with compression strategy
val compressLLMHistory by nodeLLMCompressHistory<String>(
// Substitute every 5 messages with TL;DRs
strategy = HistoryCompressionStrategy.Chunked(5)
)
// Do nothing node for navigation only
val maybeCompressHistory by nodeDoNothing<String>()
edge (orderStatusFlow forwardTo maybeCompressHistory)
edge (maybeCompressHistory forwardTo compressLLMHistory
onCondition { tooManyTokensSpent() }
)
edge (maybeCompressHistory forwardTo nodeFinish
onCondition { !tooManyTokensSpent() }
)
edge (compressLLMHistory forwardTo nodeFinish)
}
After adding history compression into the strategy, our updated graph workflow for the e-commerce agent would look like this:
Check out the full example in Kotlin or Java.
The bottom line
In this article, we saw how you can use Koog and Spring AI together to benefit from Spring AI’s model connections and database integrations, as well as the advanced production-focused orchestration layer from the Koog framework.
If you want to learn more about Koog, its product page is a good place to start, and if you have any questions or feedback, be sure to join the discussion on GitHub.
Finally, don’t forget to join #koog-agentic-framework on the Kotlin Slack (get an invite here).