

Anomalieerkennung in Zeitreihen


Wie erkennen Sie ungewöhnliche Muster in Daten, die kritische Probleme oder verborgene Chancen aufzeigen könnten? Die Anomalieerkennung hilft bei der Identifizierung von Daten, die erheblich von der Norm abweichen. Zeitreihendaten, die aus Daten bestehen, welche im Laufe der Zeit gesammelt wurden, beinhalten oft Trends und saisonale Muster. Anomalien in Zeitreihendaten treten auf, wenn diese Muster unterbrochen werden. Dies macht die Anomalieerkennung zu einem wertvollen Tool in zahlreichen Branchen, z. B. Vertrieb, Finanzen, Fertigung und Gesundheitswesen.
Da Zeitreihendaten einzigartige Merkmale wie Saisonalität und Trends aufweisen, sind spezielle Methoden erforderlich, um Anomalien effektiv zu erkennen. In diesem Blogbeitrag stellen wir Ihnen einige beliebte Methoden zur Anomalieerkennung in Zeitreihen vor, darunter STL-Zerlegung und LSTM-Vorhersage – samt detaillierten Codebeispielen, um Ihnen den Einstieg zu erleichtern.
Zeitreihen-Anomalieerkennung in Unternehmen
Zeitreihendaten sind für viele Unternehmen und Dienstleistungen unerlässlich. Zahlreiche Unternehmen halten Daten im Laufe der Zeit mit Zeitstempeln fest. Das ermöglicht es, Veränderungen zu analysieren und Daten im Zeitverlauf zu vergleichen. Zeitreihen sind nützlich, wenn Sie eine bestimmte Menge über einen gewissen Zeitraum hinweg vergleichen, z. B. bei einem Jahresvergleich, im Rahmen dessen die Daten Merkmale von Saisonalitäten aufweisen.
Umsatzüberwachung
Eines der häufigsten Beispiele für Zeitreihendaten mit Saisonalität sind Umsatzdaten. Da viele Verkäufe von den jährlichen Feiertagen und der Jahreszeit beeinflusst werden, ist es schwierig, Rückschlüsse auf die Umsatzdaten zu ziehen, ohne die Saisonalität zu berücksichtigen. Aus diesem Grund ist eine gängige Methode zur Analyse und Anomalieerkennung in Umsatzdaten die STL-Zerlegung, die wir später in diesem Blogbeitrag ausführlich behandeln werden.
Finanzen
Finanzdaten, etwa Transaktionen und Aktienkurse, sind typische Beispiele für Zeitreihendaten. In der Finanzbranche ist die Analyse und Anomalieerkennung in Bezug auf diese Daten eine gängige Praxis. Zeitreihen-Vorhersagemodelle können zum Beispiel beim automatischen Handel eingesetzt werden. Wir werden später in diesem Blogbeitrag eine Zeitreihenvorhersage verwenden, um Anomalien in Aktiendaten zu identifizieren.
Verarbeitendes Gewerbe / Fertigungsindustrie
Ein weiterer Anwendungsfall für die Erkennung von Anomalien in Zeitreihen ist die Überwachung von Defekten in Produktionslinien. Maschinen fungieren häufig als Überwachungsgeräte, die Zeitreihendaten bereitstellen. Die Möglichkeit, das Management über mögliche Ausfälle zu informieren, ist von entscheidender Bedeutung, und die Anomalieerkennung spielt dabei eine Schlüsselrolle.
Medizin und Gesundheitswesen
In der Medizin und im Gesundheitswesen werden die menschlichen Vitalfunktionen überwacht und Anomalien können erkannt werden. Das ist in der medizinischen Forschung wichtig, aber in der Diagnostik entscheidend. Wenn ein Patient in einem Krankenhaus Anomalien in Bezug auf seine Vitalfunktionen aufweist und nicht sofort behandelt wird, kann das tödlich enden.
Warum ist es wichtig, spezielle Methoden zur Anomalieerkennung bei Zeitreihen zu verwenden?
Zeitreihendaten sind besonders, da sie manchmal anders behandelt werden müssen als andere Datentypen. Wenn wir zum Beispiel einen Train-Test-Split auf Zeitreihendaten anwenden, dürfen wir die Daten aufgrund ihrer sequenziellen Verknüpfung nicht mischen. Dies gilt auch für die Anwendung von Zeitreihendaten auf ein Deep-Learning-Modell. Ein rekurrentes neuronales Netz (RNN) wird üblicherweise verwendet, um die sequenzielle Verknüpfung zu berücksichtigen. Die Trainingsdaten werden als Zeitfenster eingegeben, in denen die Abfolge der Ereignisse erhalten bleibt.
Zeitreihendaten sind auch deshalb etwas Besonderes, weil sie oft Saisonalität und Trends aufweisen, die wir nicht ignorieren dürfen. Diese Saisonalität kann sich mitunter in einem 24-Stunden-Zyklus, einem 7-Tage-Zyklus oder einem 12-Monats-Zyklus manifestieren. Anomalien können erst bestimmt werden, nachdem die Saisonalität und die Trends berücksichtigt wurden, wie Sie in unserem Beispiel unten sehen werden.
Methoden zur Anomalieerkennung in Zeitreihen
Da Zeitreihendaten etwas Besonderes sind, gibt es spezielle Methoden, um Anomalien in ihnen zu erkennen. Je nach Art der Daten können einige der Methoden und Algorithmen, die wir im vorherigen Blogbeitrag zur Anomalieerkennung erwähnt haben, auf Zeitreihendaten angewendet werden. Bei diesen Methoden ist die Anomalieerkennung jedoch möglicherweise nicht so zuverlässig wie bei Ansätzen, die speziell für Zeitreihendaten entwickelt wurden. In einigen Fällen kann eine Kombination von Erkennungsmethoden verwendet werden, um das Ergebnis zu bestätigen und Irrtümer zu vermeiden.
STL-Zerlegung
Eine der beliebtesten Methoden zur Verwendung von Zeitreihendaten, die Saisonalität aufweisen, ist die STL-Zerlegung – die Zerlegung saisonaler Trends unter Verwendung von LOESS (lokal geschätzte Streudiagramm-Glättung). Bei dieser Methode wird eine Zeitreihe unter Verwendung einer Schätzung der Saisonalität (mit der bereitgestellten oder mit einem Algorithmus bestimmten Periode), eines (geschätzten) Trends und des Restwerts (das Rauschen in den Daten) zerlegt. Eine Python-Bibliothek, die STL-Zerlegungstools bereitstellt, ist statsmodels.
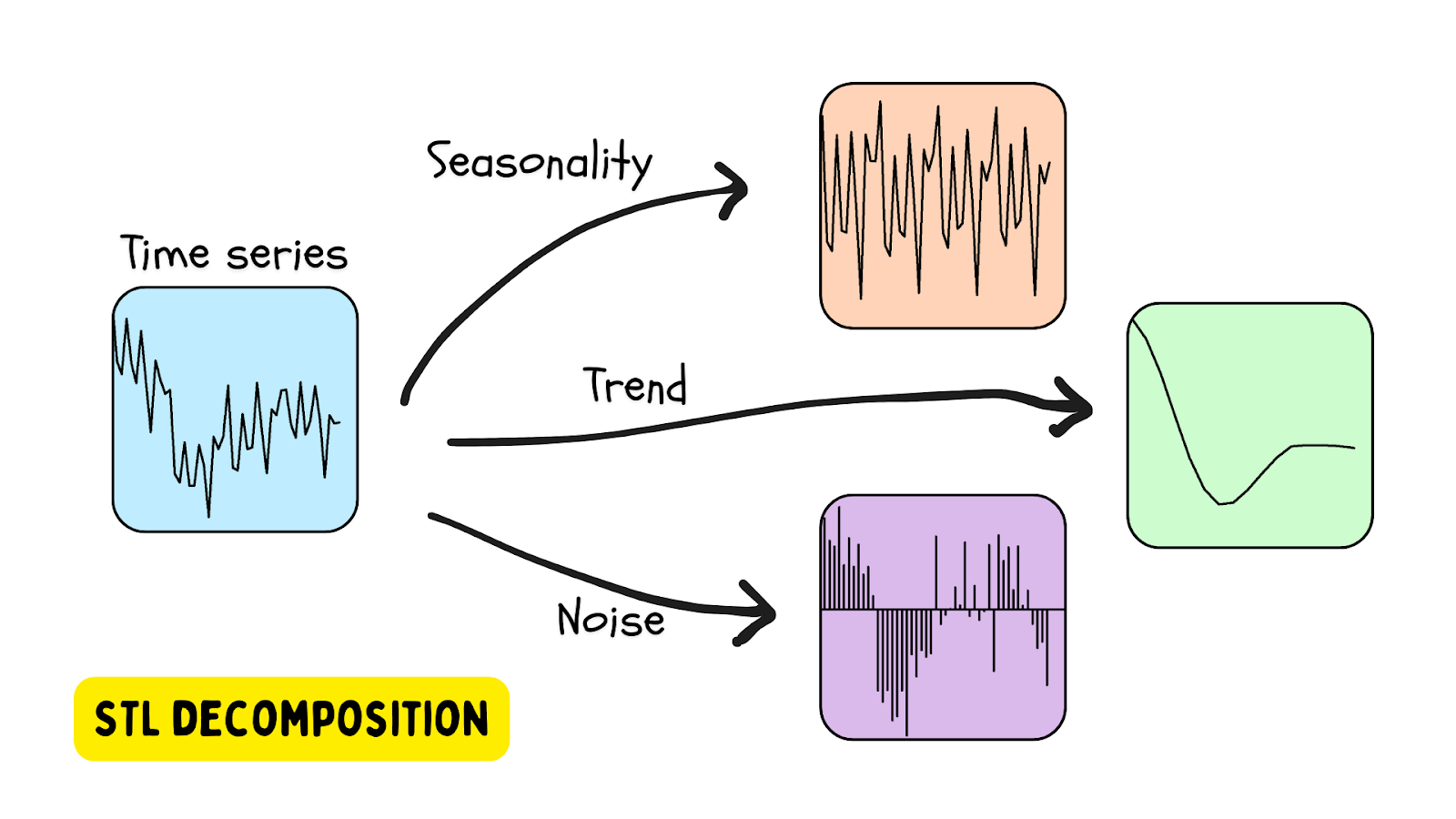
Eine Anomalie wird erkannt, wenn der Restwert über einem bestimmten Schwellenwert liegt.
Verwendung von STL-Zerlegung bei Bienenstockdaten
In einem früheren Blogbeitrag haben wir die Anomalieerkennung in Bienenstöcken mithilfe der Methoden OneClassSVM und IsolationForest untersucht.
In diesem Tutorial werden wir Bienenstockdaten als Zeitreihe analysieren. Dazu verwenden wir die STL-Klasse, die von der statsmodels-Bibliothek bereitgestellt wird. Um zu beginnen, richten Sie Ihre Umgebung mit dieser Datei ein: requirements.txt.
1. Bibliothek installieren
Da wir nur das von Scikit-learn bereitgestellte Modell verwendet haben, müssen wir statsmodels von PyPI installieren. Dies ist in PyCharm leicht zu bewerkstelligen.
Rufen Sie das Fenster Python Package auf (wählen Sie das Symbol unten links in der IDE aus) und geben Sie statsmodels in das Suchfeld ein.
Auf der rechten Seite sehen Sie alle Informationen über das Paket. Um es zu installieren, klicken Sie einfach auf Install package (Paket installieren).
2. Jupyter Notebook erstellen
Um den Datensatz weiter zu untersuchen, erstellen wir ein Jupyter Notebook. So können wir die Vorteile der Tools nutzen, welche die Jupyter-Notebook-Umgebung von PyCharm bietet.
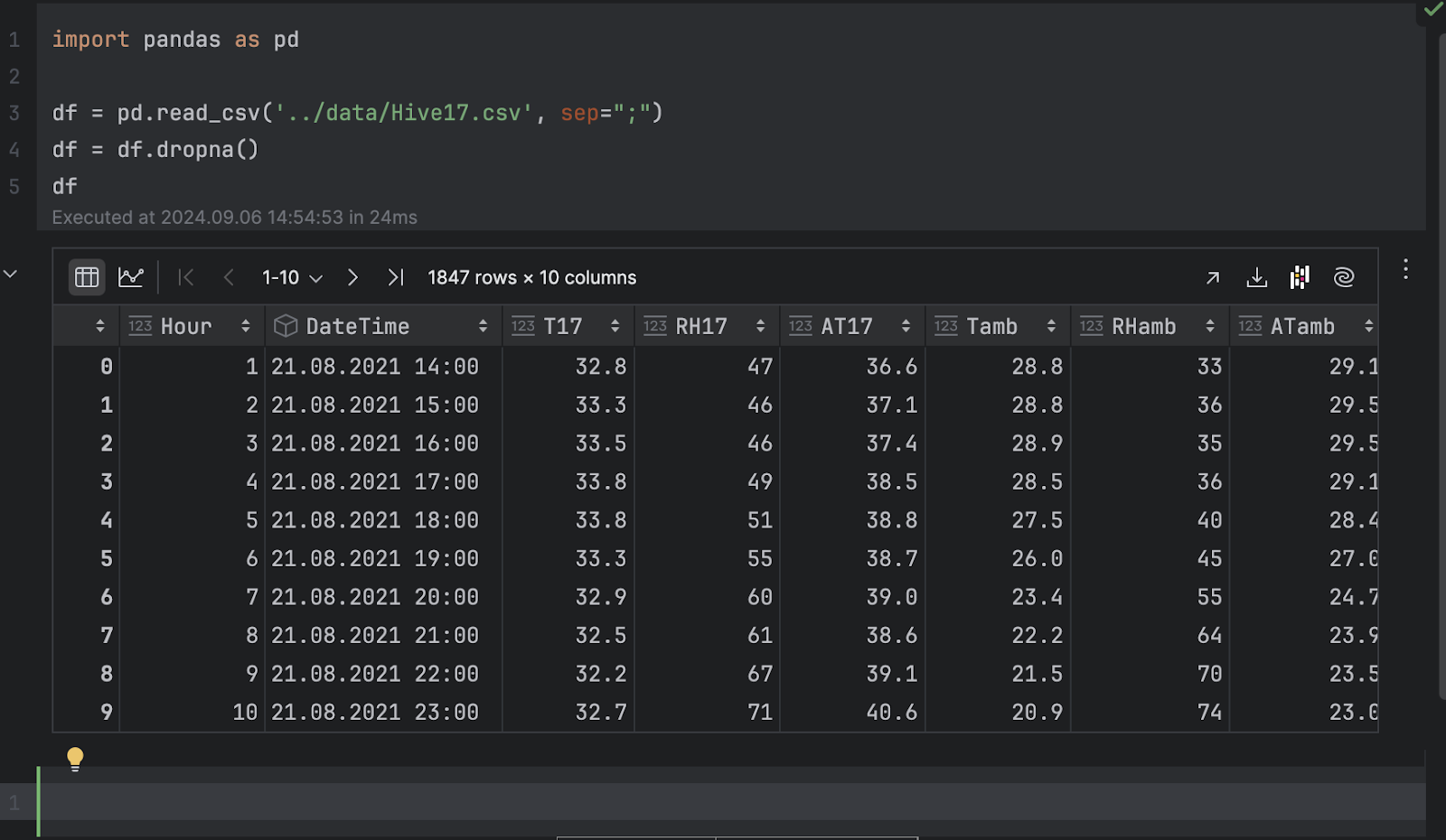
Wir werden pandas importieren und die .csv-Datei laden.
import pandas as pd
df = pd.read_csv('../data/Hive17.csv', sep=";")
df = df.dropna()
df
3. Daten als Diagramme untersuchen
Jetzt können wir die Daten als Diagramme betrachten. Hier würden wir gerne die Temperatur des Bienenstocks 17 im Laufe der Zeit sehen. Klicken Sie auf Chart view (Diagrammansicht) im Dataframe-Inspektor und wählen Sie dann T17 als y-Achse in den Reiheneinstellungen.
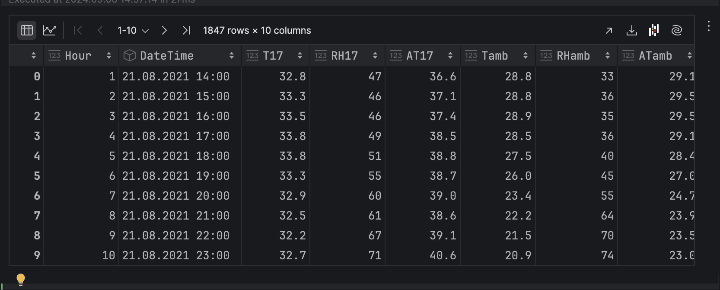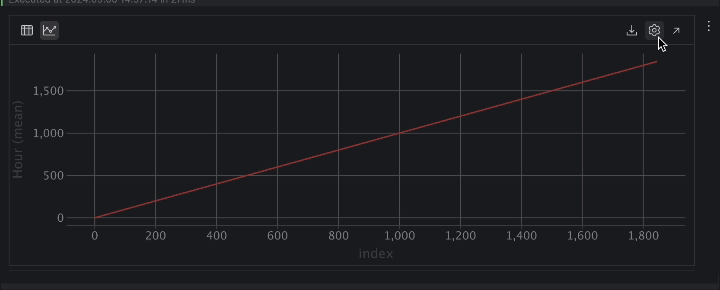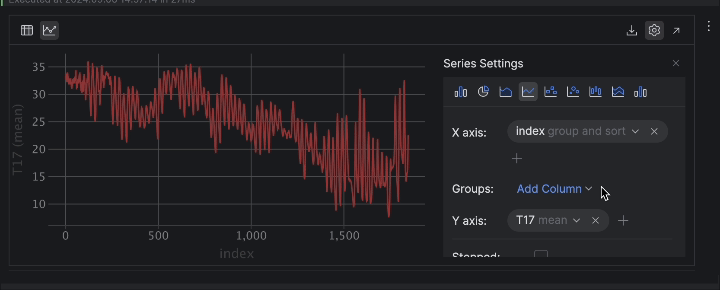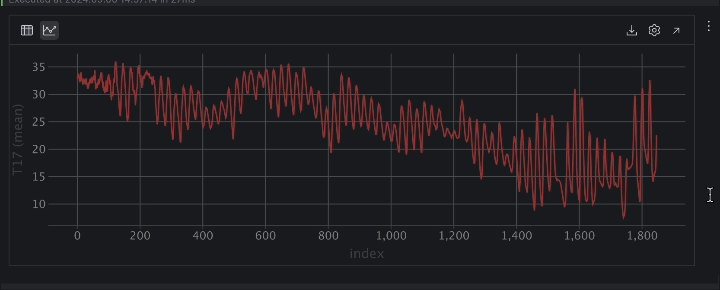
Wenn die Temperatur als Zeitreihe dargestellt wird, zeigt sie viele Schwankungen. Dies deutet auf ein periodisches Verhalten hin, das wahrscheinlich auf den Tag-Nacht-Zyklus zurückzuführen ist, sodass man davon ausgehen kann, dass es einen 24-Stunden-Zeitraum für die Temperatur gibt.
Weiterhin ist ein Trend hin zum Temperaturrückgang im Laufe der Zeit zu erkennen. Wenn Sie sich die Spalte DateTime ansehen, können Sie feststellen, dass die Daten von August bis November reichen. Da die Kaggle-Seite des Datensatzes angibt, dass die Daten in der Türkei erhoben wurden, erklärt der Übergang vom Sommer zum Herbst unsere Beobachtung, dass die Temperatur im Laufe der Zeit sinkt.
4. Zerlegung von Zeitreihen
Um die Zeitreihen zu verstehen und Anomalien zu erkennen, führen wir eine STL-Zerlegung durch, indem wir die Klasse STL von statsmodels importieren und sie auf unsere Temperaturdaten anpassen.
from statsmodels.tsa.seasonal import STL stl = STL(df["T17"], period=24, robust=True) result = stl.fit()
Wir müssen einen Zeitraum angeben, damit die Zerlegung funktioniert. Wie bereits erwähnt, können wir von einem 24-Stunden-Zyklus ausgehen.
Der Dokumentation zufolge zerlegt STL eine Zeitreihe in drei Komponenten: Trend, Saison und Restwert. Um einen genaueren Blick auf das zerlegte Ergebnis zu erhalten, können wir die integrierte plot-Methode verwenden:
result.plot()
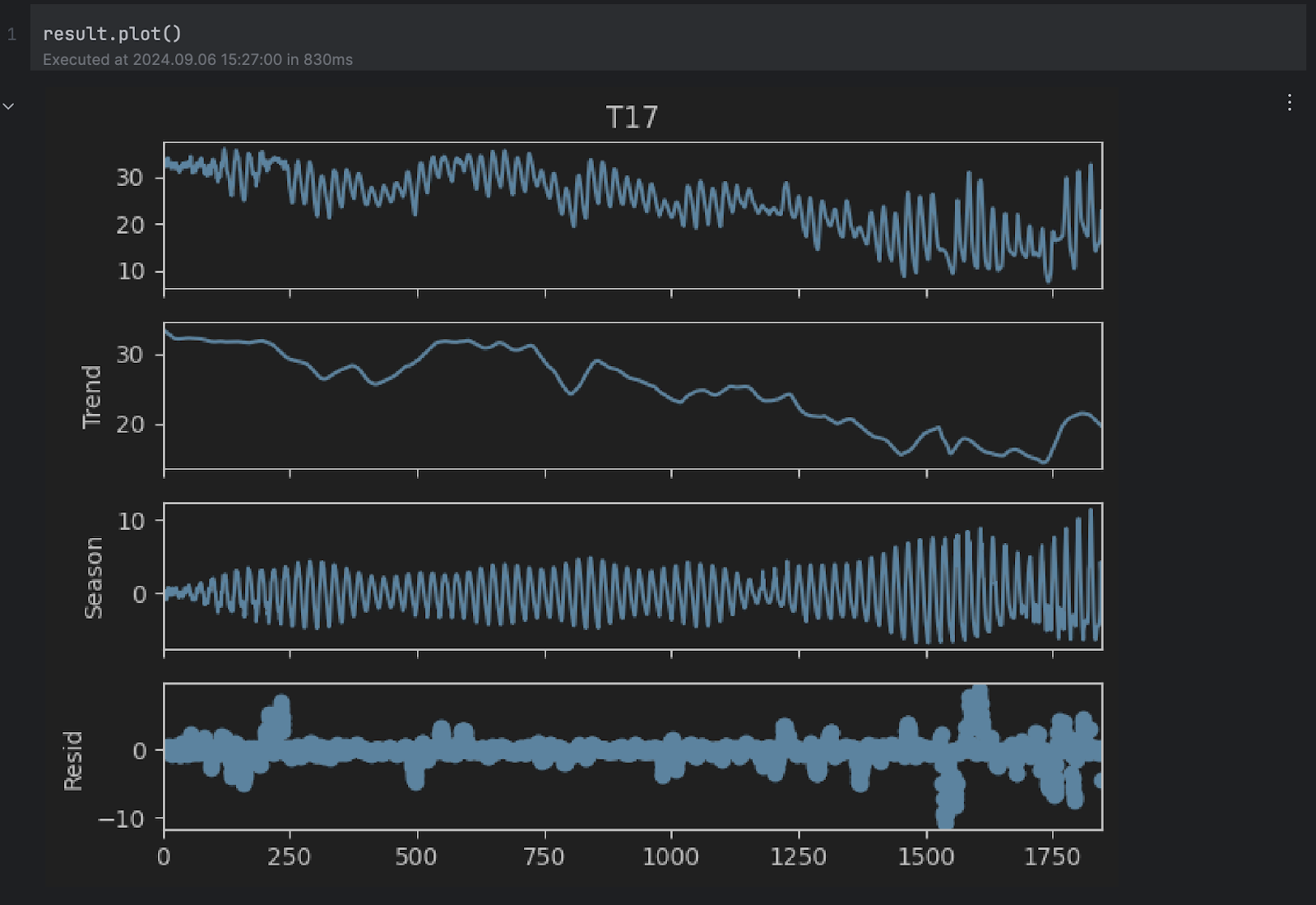
Sie können sehen, dass die Trend– und Saison-Diagramme mit unseren obigen Annahmen übereinzustimmen scheinen. Wir interessieren uns jedoch für das Restwertdiagramm unten, das die ursprüngliche Serie ohne den Trend und die saisonalen Veränderungen darstellt. Jeder extrem hohe oder niedrige Restwert weist auf eine Anomalie hin.
5. Schwellenwert für Anomalien
Als Nächstes möchten wir festlegen, welche Restwerte wir als abnormal erachten. Dazu können wir uns das Restwerthistogramm ansehen.
result.resid.plot.hist()
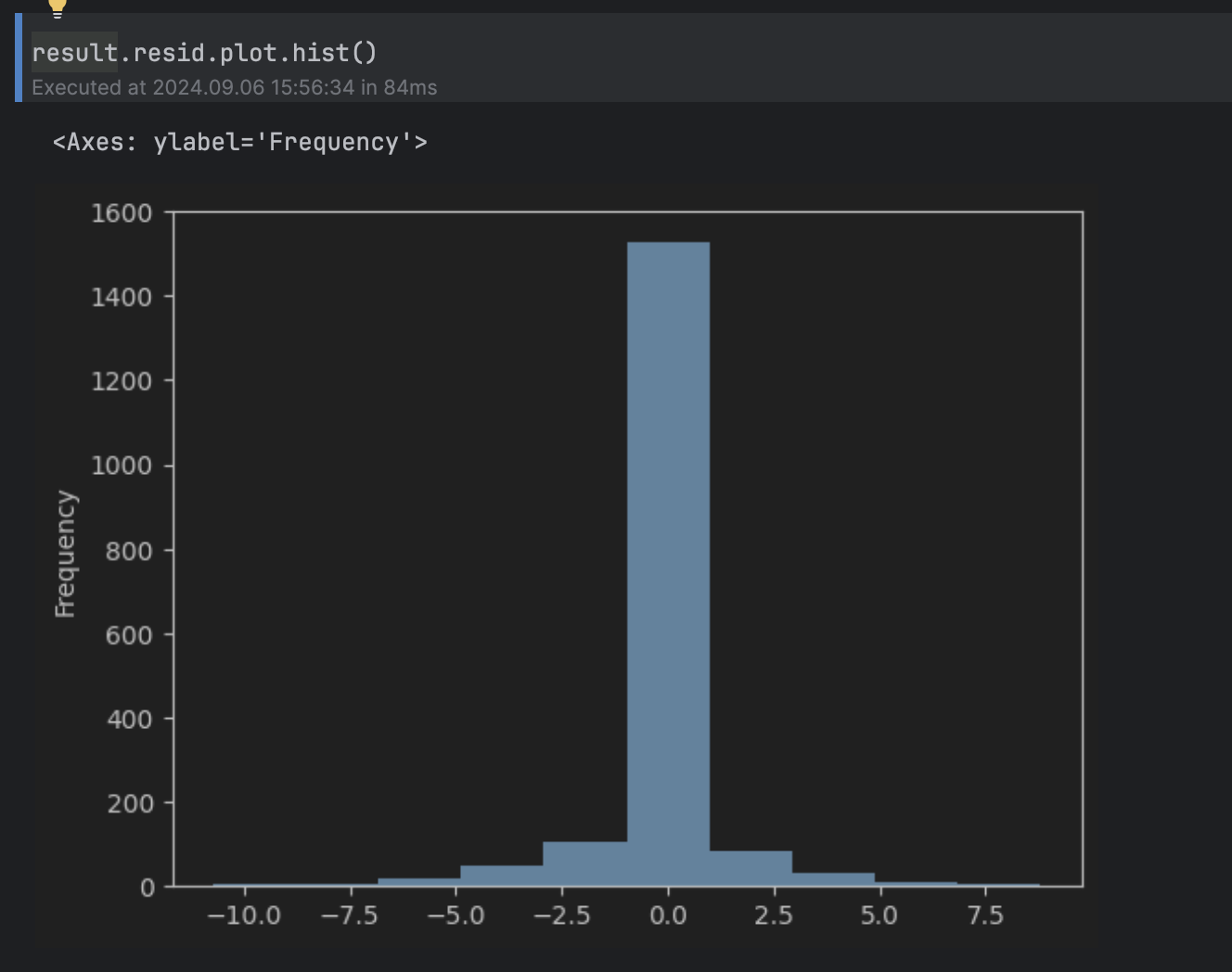
Wir betrachten dies als Normalverteilung um 0 mit langen Ausläufern über 5 und unter –5, weshalb wir den Schwellenwert auf 5 festlegen.
Um die Anomalien in der ursprünglichen Zeitreihe zu zeigen, können wir sie im Diagramm wie folgt rot einfärben:
import matplotlib.pyplot as plt
threshold = 5
anomalies_filter = result.resid.apply(lambda x: True if abs(x) > threshold else False)
anomalies = df["T17"][anomalies_filter]
plt.figure(figsize=(14, 8))
plt.scatter(x=anomalies.index, y=anomalies, color="red", label="anomalies")
plt.plot(df.index, df['T17'], color='blue')
plt.title('Temperatures in Hive 17')
plt.xlabel('Hours')
plt.ylabel('Temperature')
plt.legend()
plt.show()
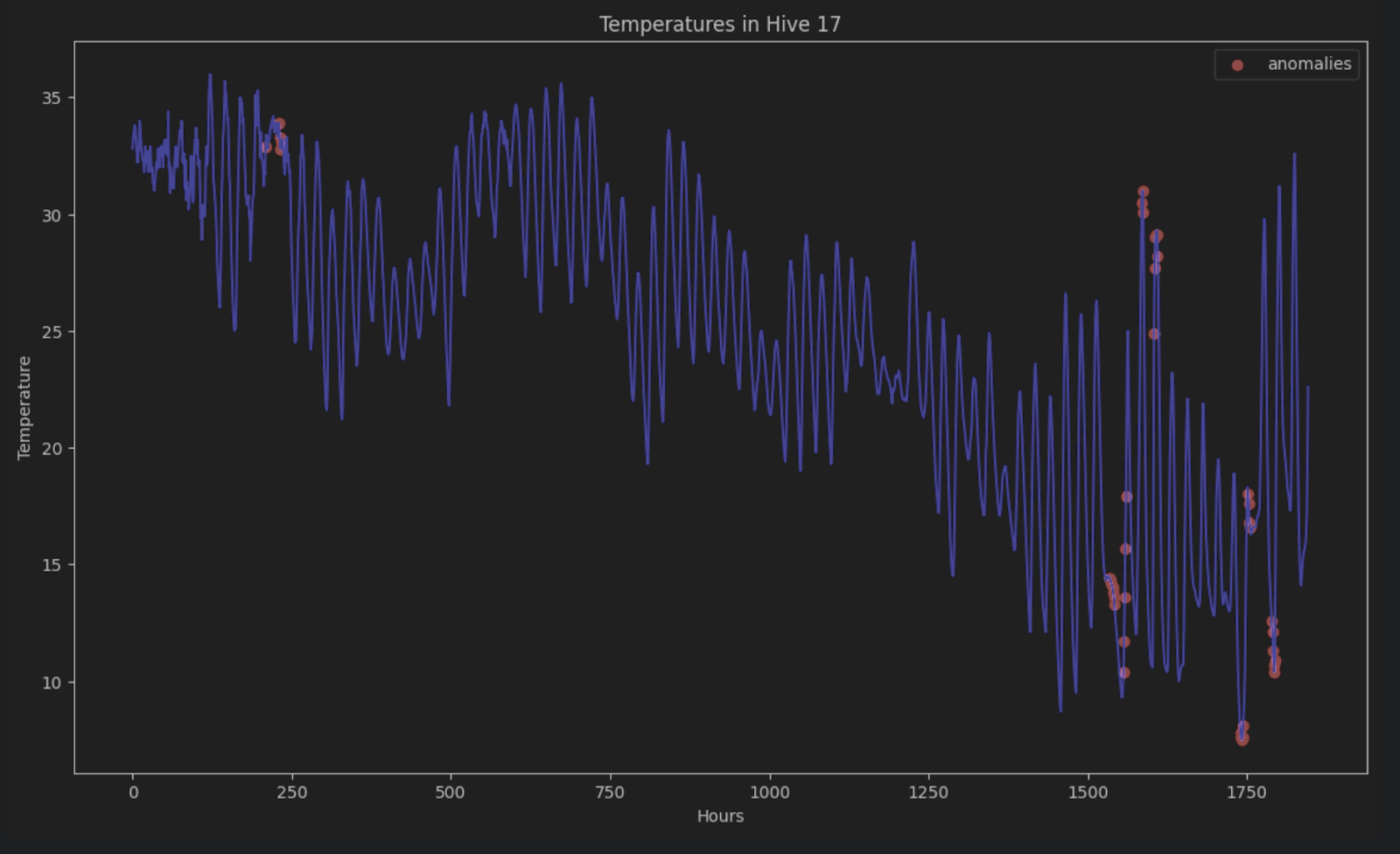
Ohne STL-Zerlegung ist es äußerst schwer, diese Anomalien in einer Zeitreihe, die aus Zeiträumen und Trends besteht, zu erkennen.
LSTM-Vorhersage
Eine andere Möglichkeit, Anomalien in Zeitreihendaten zu erkennen, besteht darin, eine Zeitreihenvorhersage mithilfe von Deep-Learning-Methoden durchzuführen, um das Ergebnis der Datenpunkte zu schätzen. Wenn eine Schätzung stark vom tatsächlichen Datenpunkt abweicht, könnte dies ein Anzeichen für anomale Daten sein.
Einer der beliebtesten Deep-Learning-Algorithmen für die Vorhersage von sequenziellen Daten ist das LSTM-Modell (langes Kurzzeitgedächtnis), eine Art rekurrentes neuronales Netz (RNN). Das LSTM-Modell hat Eingabe-, Vergessens- und Ausgabetore, die Zahlenmatrizen sind. Dadurch wird sichergestellt, dass wichtige Informationen bei der nächsten Iteration der Daten weitergegeben werden.
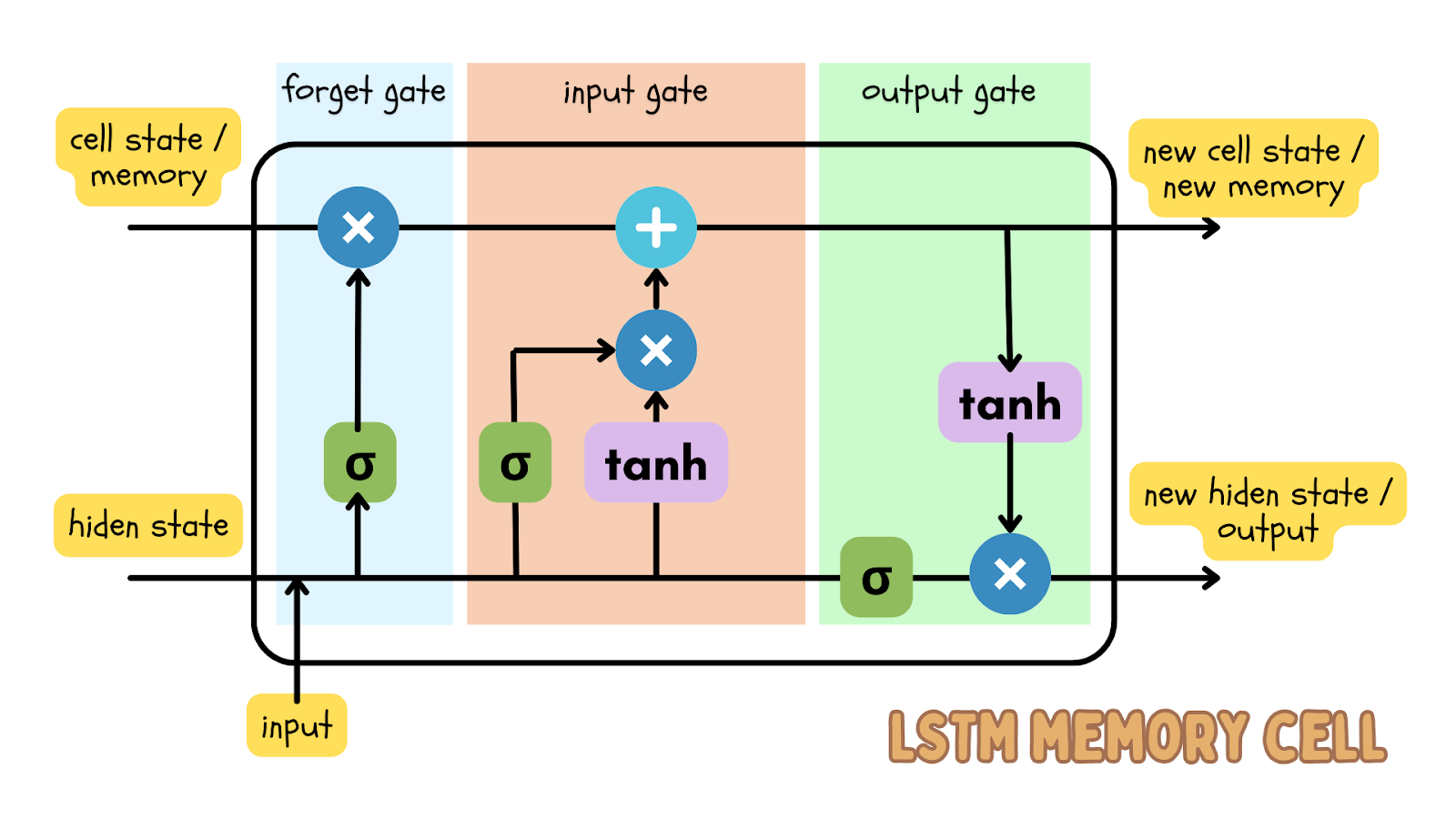
Da es sich bei Zeitreihendaten um sequenzielle Daten handelt (d. h. die Reihenfolge der Datenpunkte ist sequenziell und sollte nicht gemischt werden), ist das LSTM-Modell ein effektives Deep-Learning-Modell, um das Ergebnis zu einem bestimmten Zeitpunkt vorherzusagen. Diese Prognose lässt sich mit den realen Daten abgleichen und es kann ein Schwellenwert definiert werden, um festzustellen, ob die realen Daten eine Anomalie darstellen.
Verwendung von LSTM-Vorhersagen für Aktienkurse
Lassen Sie uns nun ein neues Jupyter-Projekt starten, um Anomalien im Apple-Aktienkurs der letzten 5 Jahre zu erkennen. Der „stock price“-Datensatz zeigt die aktuellsten Daten. Wenn Sie den Blogbeitrag mitverfolgen möchten, können Sie den von uns verwendeten Datensatz herunterladen.
1. Jupyter-Projekt einrichten
Wenn Sie ein neues Projekt beginnen, können Sie ein Jupyter-Projekt erstellen, das für datenwissenschaftliche Vorgänge optimiert ist. Im Fenster New Project (Neues Projekt) können Sie ein Git-Repository anlegen und bestimmen, welche conda-Installation Sie für die Verwaltung Ihrer Umgebung verwenden möchten.
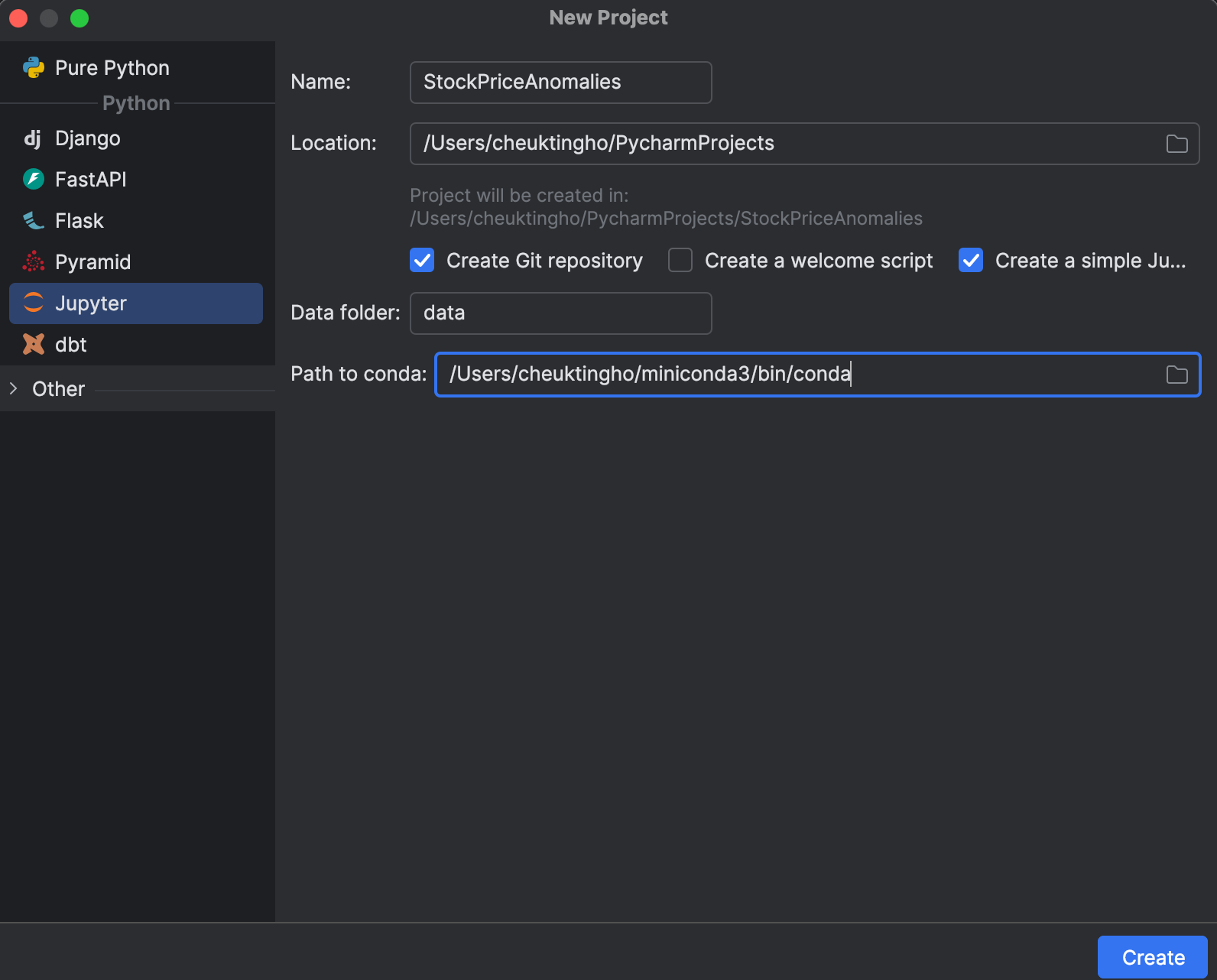
Nachdem Sie das Projekt begonnen haben, sehen Sie ein Beispiel-Notebook. Richten Sie ein neues Jupyter Notebook für diese Übung ein.
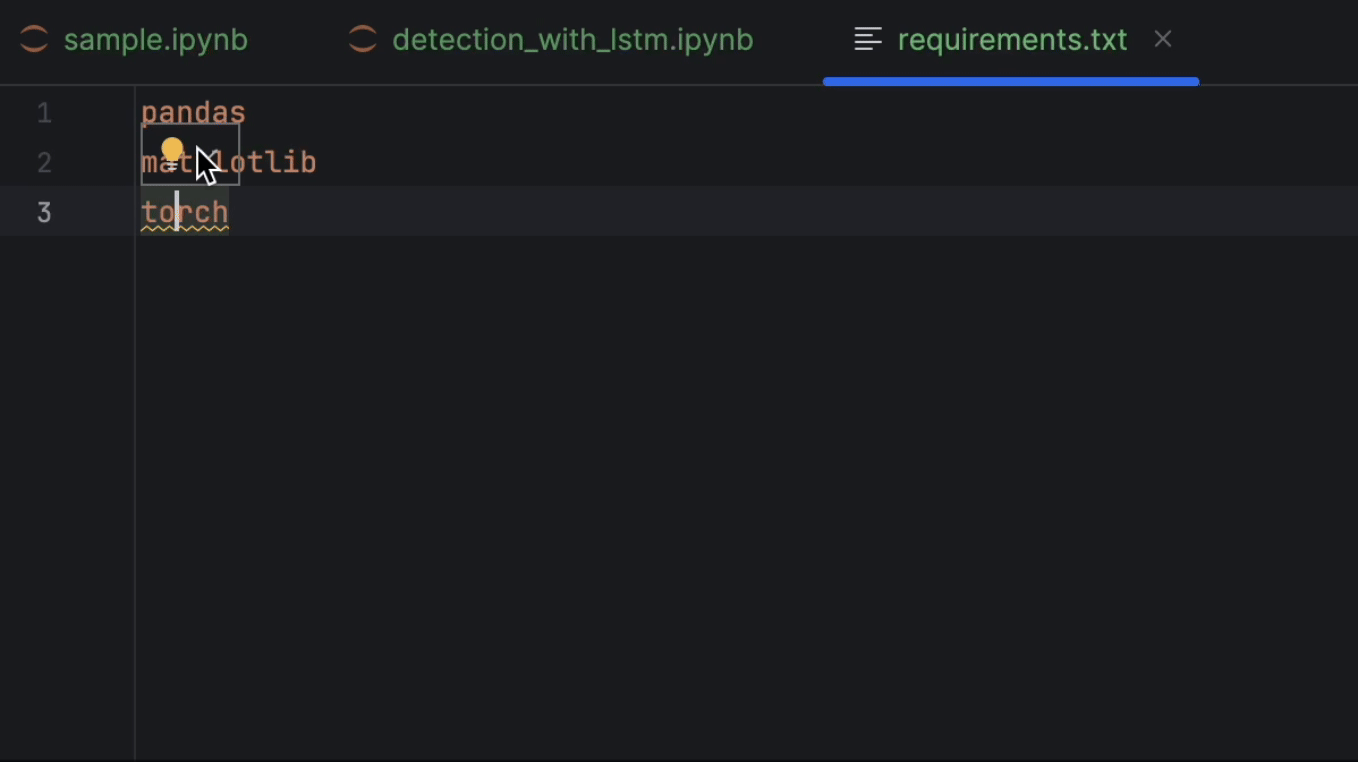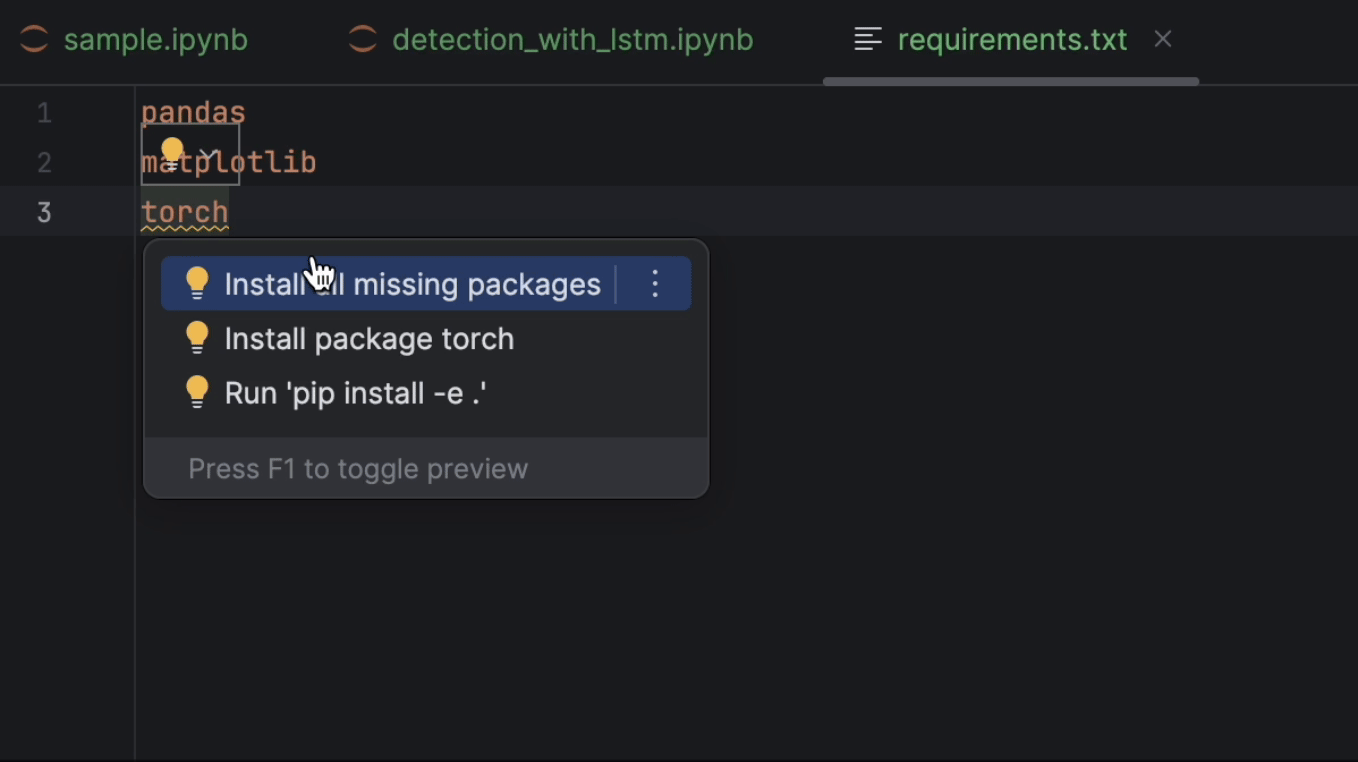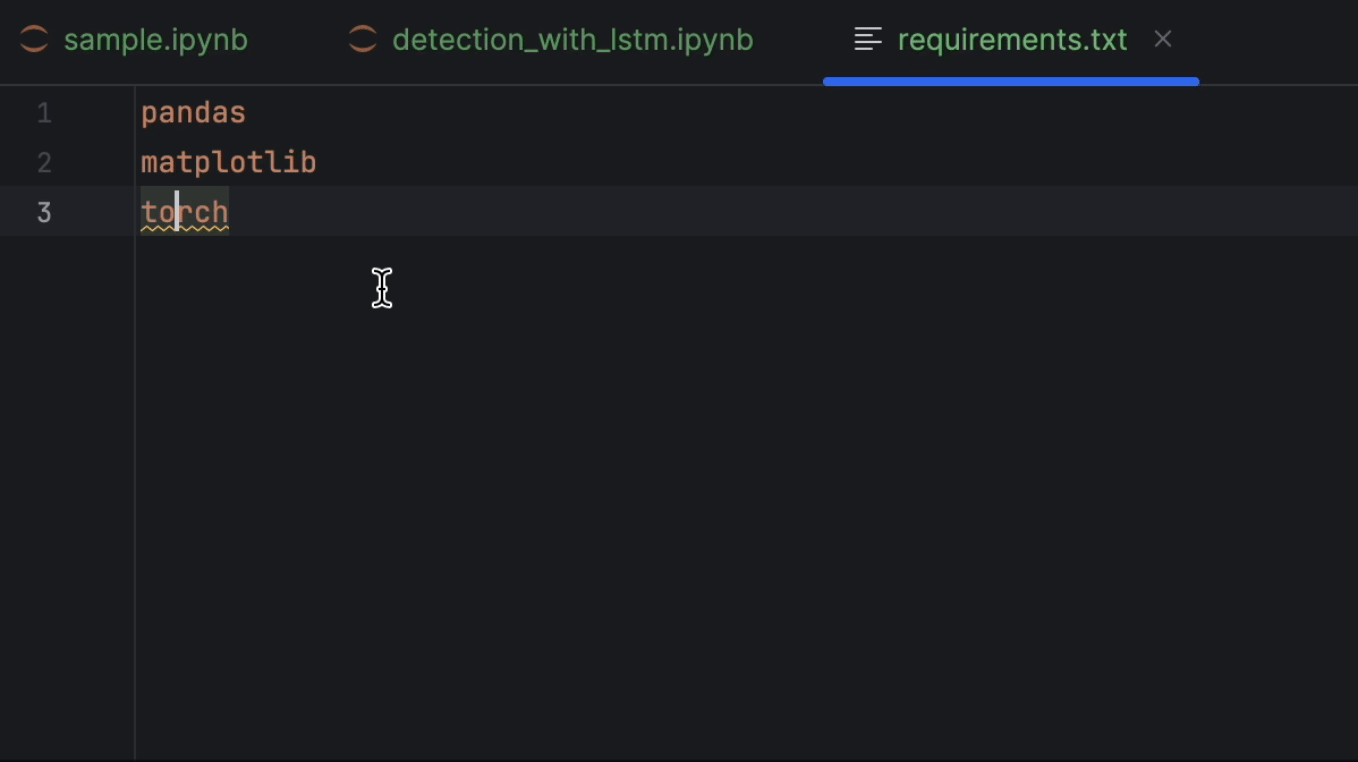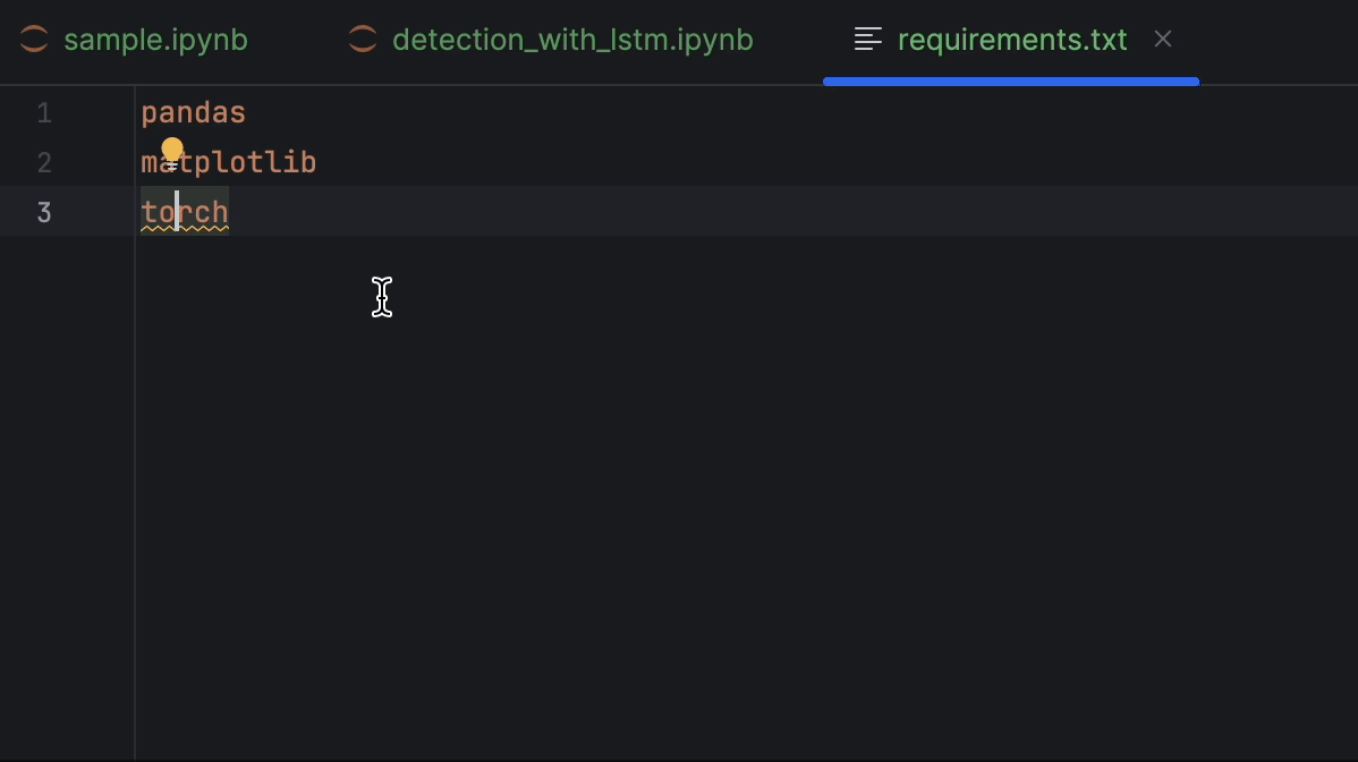
Danach setzen wir die Datei requirements.txt auf. Wir benötigen pandas, matplotlib und PyTorch, das bei PyPI torch heißt. Da PyTorch nicht in der conda-Umgebung enthalten ist, meldet PyCharm, dass uns das Paket fehlt. Um das Paket zu installieren, klicken Sie auf die Glühbirne und wählen Sie Install all missing packages (Alle fehlenden Pakete installieren).
2. Laden und Prüfen der Daten
Als Nächstes verschieben wir unseren Datensatz apple_stock_5y.csv in den data-Ordner und laden ihn als pandas-DataFrame, um ihn zu untersuchen.
import pandas as pd
df = pd.read_csv('data/apple_stock_5y.csv')
df
Anhand der interaktiven Tabelle können wir leicht erkennen, ob Daten fehlen.
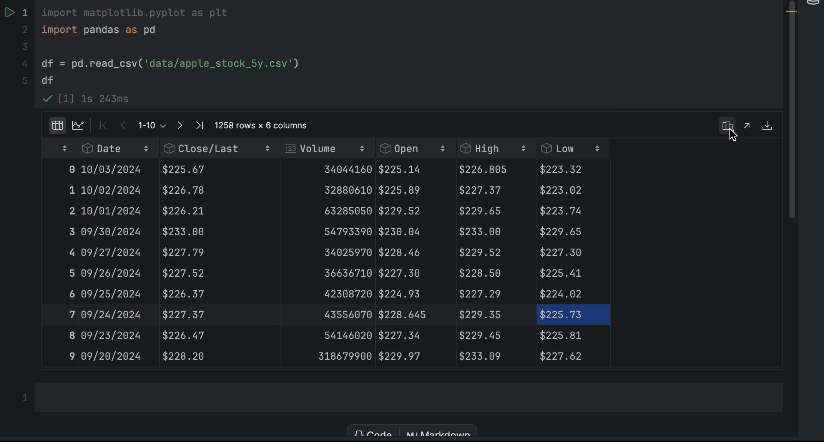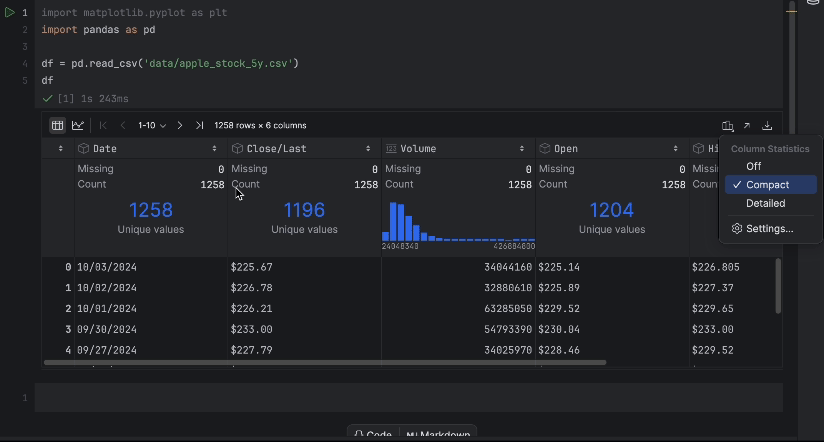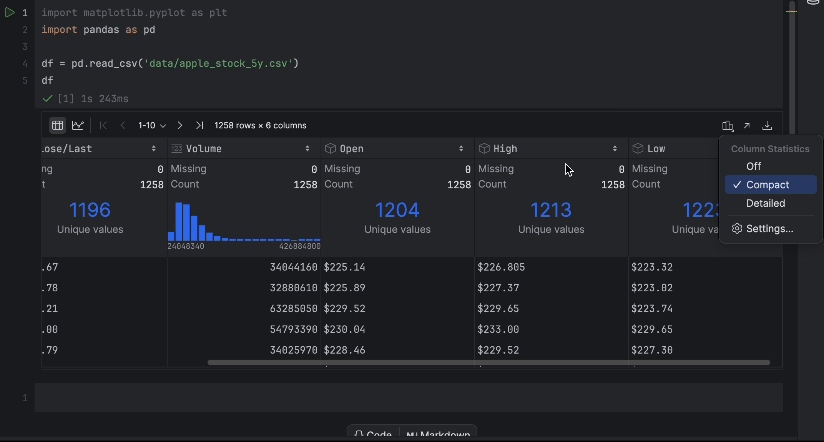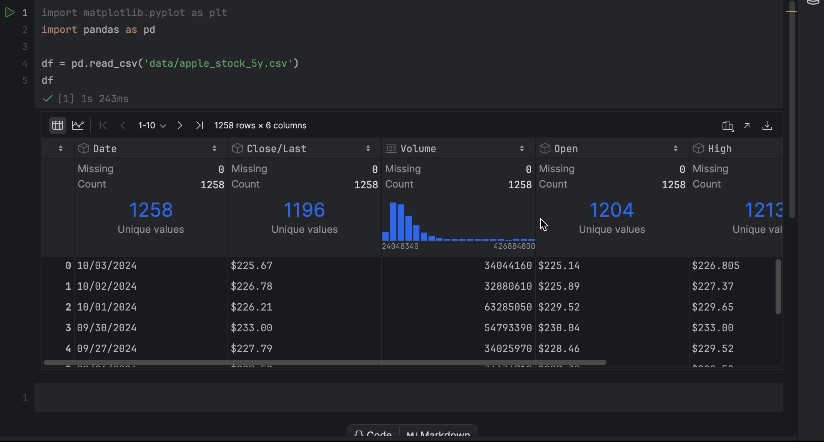
Es fehlen keine Daten, aber wir haben ein Problem: Wir würden gerne den Close/Last-Preis verwenden, aber es handelt sich nicht um einen numerischen Datentyp. Wir sollten eine Konvertierung vornehmen und unsere Daten noch einmal untersuchen:
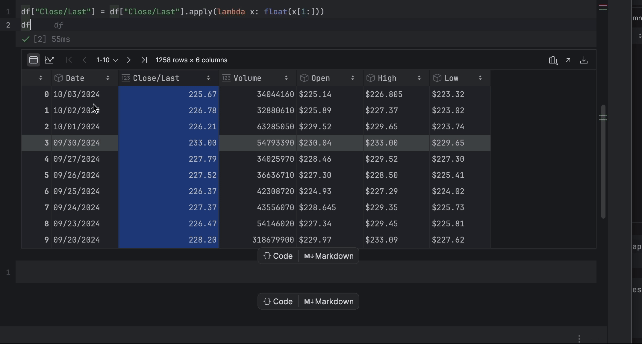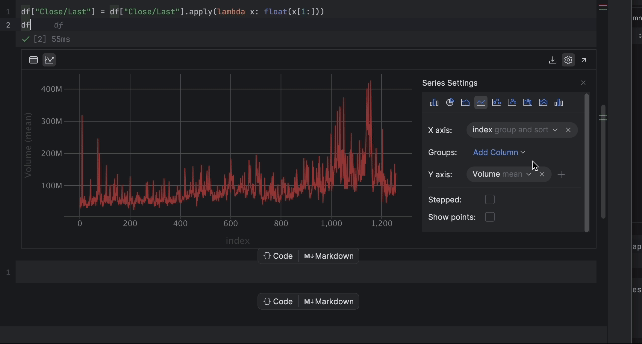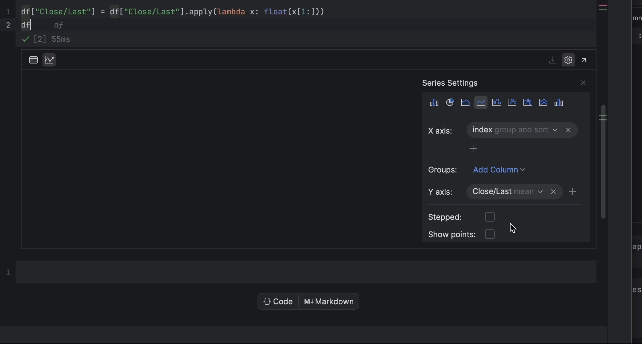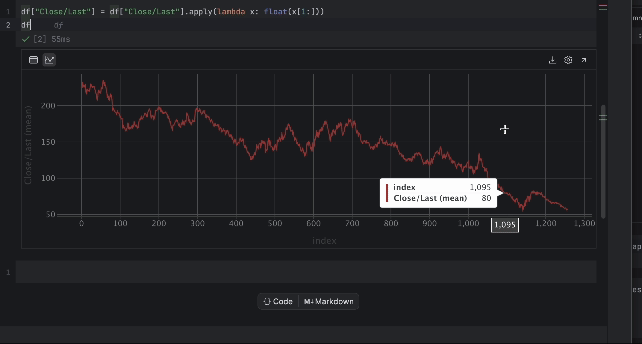
df["Close/Last"] = df["Close/Last"].apply(lambda x: float(x[1:])) df
Jetzt können wir den Preis anhand der interaktiven Tabelle überprüfen. Klicken Sie auf das Diagrammsymbol auf der linken Seite – es wird dann ein Diagramm erstellt. Standardmäßig wird Date als x-Achse und Volume als y-Achse verwendet. Wir möchten den Close/Last-Preis untersuchen; gehen Sie also zu den Einstellungen, indem Sie auf das Zahnradsymbol auf der rechten Seite klicken, und wählen Sie Close/Last als y-Achse aus.
3. Aufbereitung der Trainingsdaten für LSTM
Als Nächstes müssen wir die Trainingsdaten vorbereiten, die im LSTM-Modell verwendet werden sollen. Wir müssen eine Sequenz von Vektoren (Feature X) vorbereiten, die jeweils ein Zeitfenster repräsentieren, um den nächsten Preis vorherzusagen. Der nächste Kurs wird eine weitere Sequenz bilden (Ziel y). Hier können wir mit der Variable lookback festlegen, wie groß dieses Zeitfenster ist. Der folgende Code erstellt die Sequenzen X und y, die dann in PyTorch-Tensoren umgewandelt werden:
import torch
lookback = 5
timeseries = df[["Close/Last"]].values.astype('float32')
X, y = [], []
for i in range(len(timeseries)-lookback):
feature = timeseries[i:i+lookback]
target = timeseries[i+1:i+lookback+1]
X.append(feature)
y.append(target)
X = torch.tensor(X)
y = torch.tensor(y)
print(X.shape, y.shape)
Im Allgemeinen gilt: Je größer das Fenster, desto größer wird unser Modell, da der Eingabevektor größer ist. Bei einem größeren Fenster wird die Sequenz der Eingaben jedoch kürzer, sodass die Festlegung dieses lookback-Fensters ein Balanceakt ist. Wir beginnen mit 5, aber Sie können gerne andere Werte ausprobieren, um die Unterschiede zu sehen.
4. Modell erstellen und trainieren
Wir können das Modell erstellen, indem wir eine Klasse mit dem nn-Modul in PyTorch anlegen, bevor wir es trainieren. Das nn-Modul liefert Bausteine, z. B. verschiedene Ebenen neuronaler Netze. Im Rahmen dieser Übung erstellen wir eine einfache LSTM-Ebene gefolgt von einer linearen Ebene:
import torch.nn as nn
class StockModel(nn.Module):
def __init__(self):
super().__init__()
self.lstm = nn.LSTM(input_size=1, hidden_size=50, num_layers=1, batch_first=True)
self.linear = nn.Linear(50, 1)
def forward(self, x):
x, _ = self.lstm(x)
x = self.linear(x)
return x
Als Nächstes werden wir unser Modell trainieren. Vor dem Training müssen wir einen Optimierer, eine Loss-Funktion zur Berechnung des Verlusts zwischen den vorhergesagten und den tatsächlichen y-Werten sowie einen Data Loader zur Einspeisung unserer Trainingsdaten erstellen:
import numpy as np import torch.optim as optim import torch.utils.data as data model = StockModel() optimizer = optim.Adam(model.parameters()) loss_fn = nn.MSELoss() loader = data.DataLoader(data.TensorDataset(X, y), shuffle=True, batch_size=8)
Der Data Loader kann die Eingabe mischen, da wir die Zeitfenster bereits erstellt haben. Dadurch bleibt die sequenzielle Verknüpfung in jedem Fenster erhalten.
Das Training wird mit einer for-Schleife durchgeführt, die jede Epoche durchläuft. Alle 100 Epochen geben wir den Verlust aus und beobachten, wie das Modell konvergiert:
n_epochs = 1000
for epoch in range(n_epochs):
model.train()
for X_batch, y_batch in loader:
y_pred = model(X_batch)
loss = loss_fn(y_pred, y_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 100 != 0:
continue
model.eval()
with torch.no_grad():
y_pred = model(X)
rmse = np.sqrt(loss_fn(y_pred, y))
print(f"Epoch {epoch}: RMSE {rmse:.4f}")
Wir beginnen mit 1000 Epochen, aber das Modell konvergiert recht schnell. Probieren Sie ruhig eine andere Anzahl von Epochen für das Training aus, um das beste Ergebnis zu erzielen.
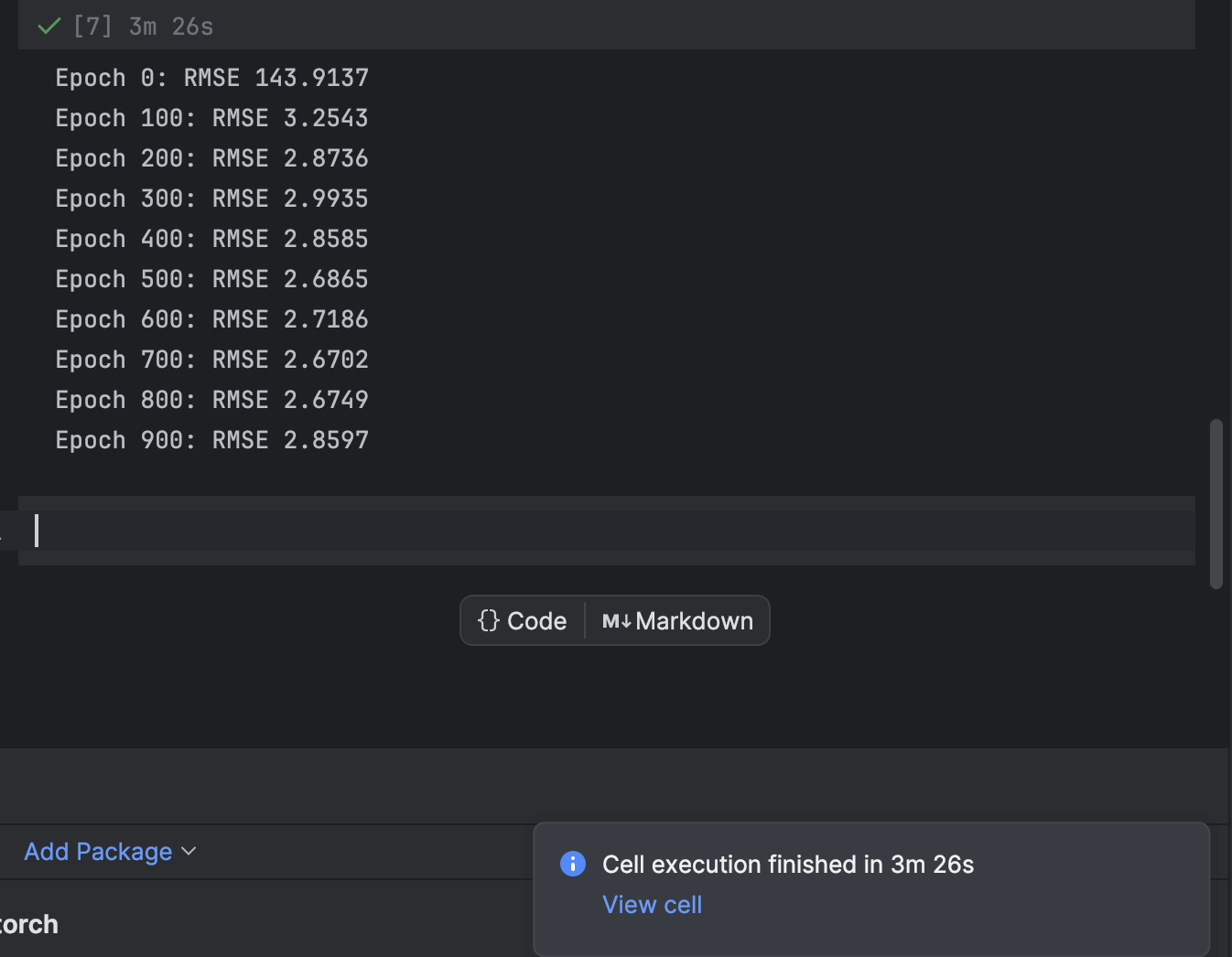
In PyCharm zeigt eine Zelle, die etwas Zeit zum Ausführen benötigt, eine Benachrichtigung darüber an, wie viel Zeit noch verbleibt, sowie eine entsprechende Verknüpfung. Das ist sehr praktisch, wenn Sie Machine-Learning- und insbesondere Deep-Learning-Modelle in Jupyter Notebooks trainieren.
5. Vorhersage als Diagramm darstellen und Fehler finden
Als Nächstes erstellen wir die Vorhersage und bilden sie zusammen mit der tatsächlichen Zeitreihe als Diagramm ab. Beachten Sie, dass wir eine 2-D-np-Reihe erstellen müssen, die mit der tatsächlichen Zeitreihe übereinstimmt. Die tatsächliche Zeitreihe wird blau dargestellt, während die vorhergesagte Zeitreihe rot abgebildet wird.
import matplotlib.pyplot as plt
with torch.no_grad():
pred_series = np.ones_like(timeseries) * np.nan
pred_series[lookback:] = model(X)[:, -1, :]
plt.plot(timeseries, c='b')
plt.plot(pred_series, c='r')
plt.show()
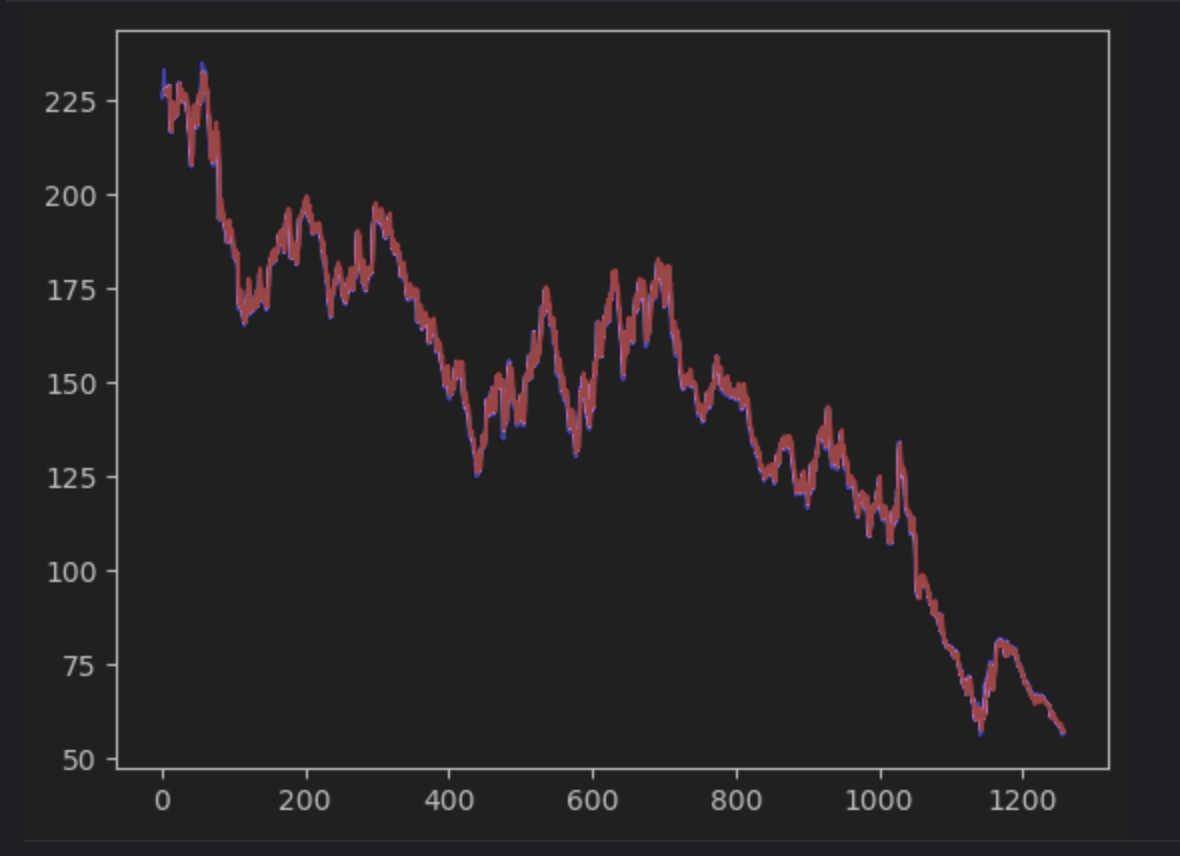
Wenn Sie genau hinsehen, werden Sie feststellen, dass die Vorhersage und die tatsächlichen Werte nicht perfekt übereinstimmen. Die meisten Vorhersagen sind jedoch gut.
Um die Fehler genau zu untersuchen, können wir eine Fehlerserie erstellen und die interaktive Tabelle verwenden, um sie zu beobachten. Wir verwenden dieses Mal den absoluten Fehler.
error = abs(timeseries-pred_series) error
Verwenden Sie die Einstellungen, um ein Histogramm mit dem Wert des absoluten Fehlers als x-Achse und der Anzahl des Wertes als y-Achse zu erstellen.
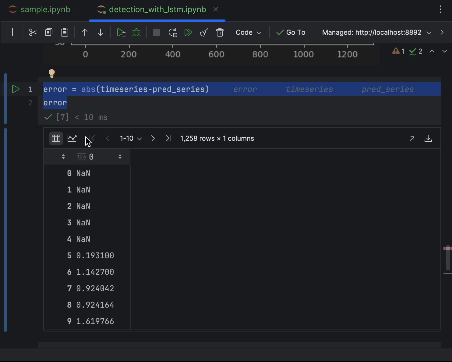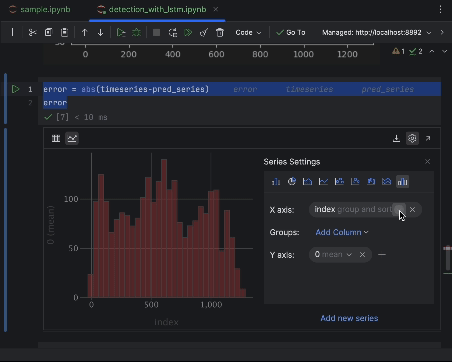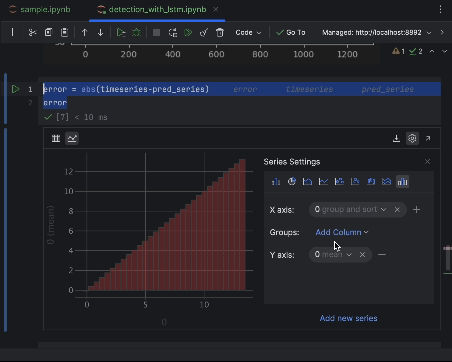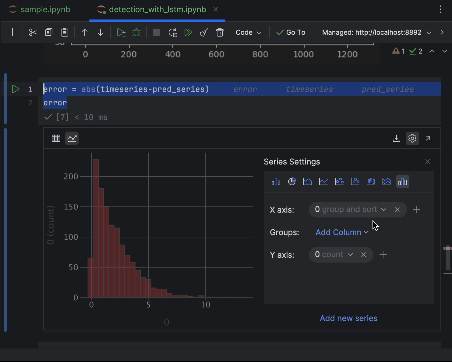
6. Anomalie-Schwellenwert festlegen und visualisieren
Die meisten Punkte werden einen absoluten Fehler von weniger als 6 haben, sodass wir dies als Schwellenwert für die Anomalie festlegen können. Ähnlich wie bei den Bienenstockanomalien können wir die anomalen Datenpunkte in das Diagramm einzeichnen.
threshold = 6
error_series = pd.Series(error.flatten())
price_series = pd.Series(timeseries.flatten())
anomalies_filter = error_series.apply(lambda x: True if x > threshold else False)
anomalies = price_series[anomalies_filter]
plt.figure(figsize=(14, 8))
plt.scatter(x=anomalies.index, y=anomalies, color="red", label="anomalies")
plt.plot(df.index, timeseries, color='blue')
plt.title('Closing price')
plt.xlabel('Days')
plt.ylabel('Price')
plt.legend()
plt.show()
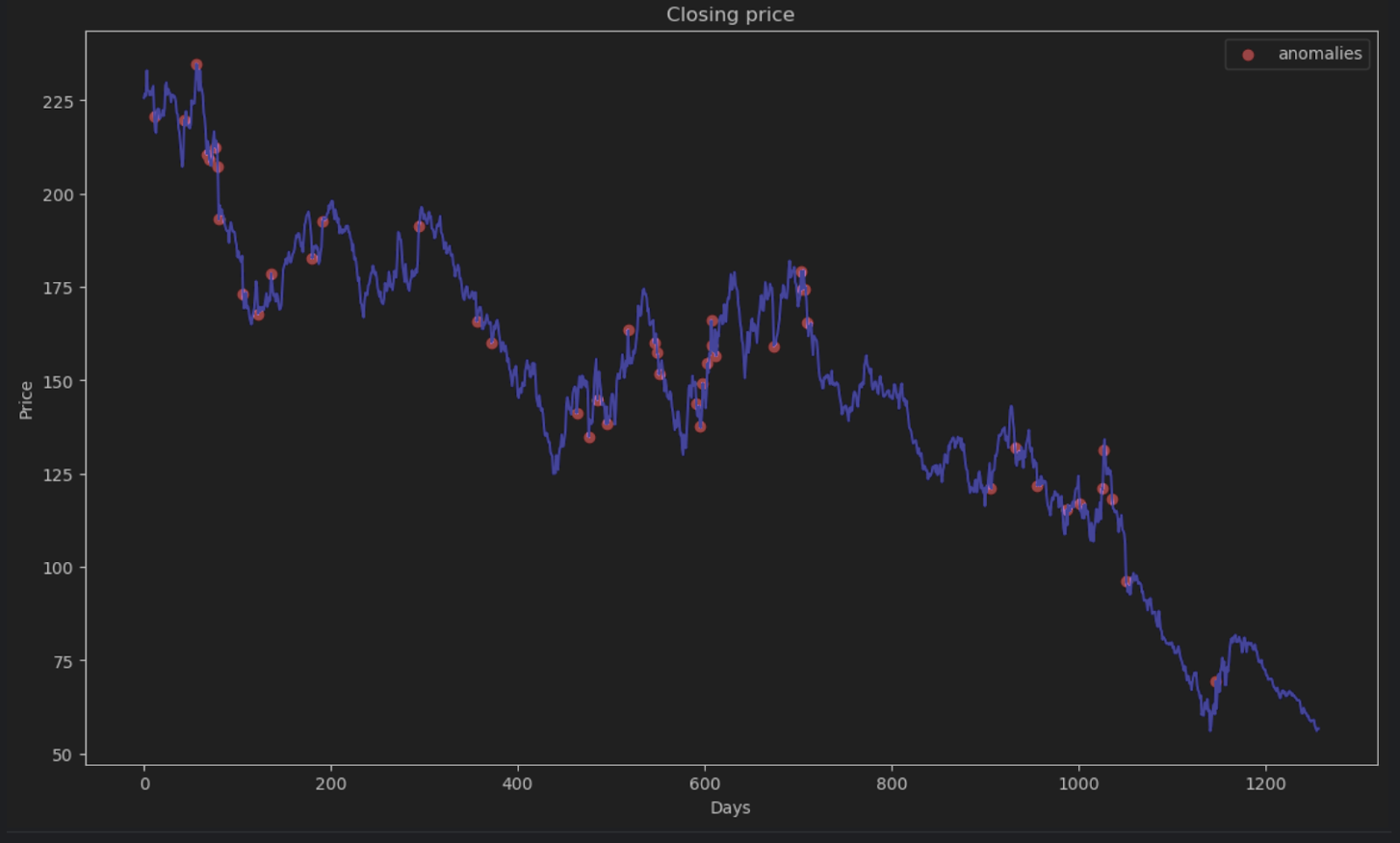
Zusammenfassung
Zeitreihendaten sind eine gängige Datenform, die in vielen Anwendungsbereichen, einschließlich der Geschäftswelt und der wissenschaftlichen Forschung, eingesetzt wird. Aufgrund des sequenziellen Charakters von Zeitreihendaten werden spezielle Methoden und Algorithmen verwendet, um Anomalien in diesen Daten zu ermitteln. In diesem Blogbeitrag haben wir Ihnen gezeigt, wie Sie Anomalien mithilfe der STL-Zerlegung identifizieren können, um saisonale Schwankungen und Trends zu eliminieren. Wir haben außerdem demonstriert, wie man Deep Learning und das LSTM-Modell verwendet, um die geschätzten Werte mit den tatsächlichen Daten zu vergleichen und Anomalien zu identifizieren.
Anomalien mit PyCharm erkennen
Mit dem Jupyter-Projekt in PyCharm Professional lässt sich Ihr Projekt zur Anomalieerkennung mühelos mit zahlreichen Datendateien und Notebooks strukturieren. Sie können Graphen erstellen, um Anomalien zu untersuchen, und Diagramme sind in PyCharm äußerst benutzerfreundlich. Weitere Funktionen, wie etwa Auto-Vervollständigungsvorschläge, gestalten das Navigieren durch die Scikit-learn-Modelle und die Matplotlib-Diagrammeinstellungen besonders angenehm.
Verbessern Sie Ihre Data-Science-Projekte mit PyCharm und sehen Sie sich die verfügbaren Data-Science-Features an, um Ihren Data-Science-Workflow zu optimieren.
Autorin des ursprünglichen Blogposts





