

Schnelleres Python: Entfernen des Global Interpreter Lock in Python

Was ist der Global Interpreter Lock (GIL) in Python?
Der „Global Interpreter Lock“ (oder „GIL“) ist ein gängiger Begriff in der Python-Community. Es handelt sich um ein allgemein bekanntes Merkmal von Python. Aber was genau ist der GIL?
Wenn Sie Erfahrung mit anderen Programmiersprachen (z. B. Rust) haben, wissen Sie vielleicht schon, was ein Mutex ist. Es steht für „mutual exclusion“, also „gegenseitiger Ausschluss“. Ein Mutex sorgt dafür, dass immer nur ein Thread auf die Daten zugreifen kann. Dadurch wird verhindert, dass Daten von mehreren Threads gleichzeitig geändert werden. Sie können es sich als eine Art „Schloss“ vorstellen. Dieses blockiert den Zugriff aller Threads auf die Daten, mit Ausnahme des einen Threads, der den Schlüssel besitzt.
Der GIL ist technisch betrachtet ein Mutex. Er erlaubt jeweils nur einem Thread den Zugriff auf den Python-Interpreter. Ich stelle ihn mir manchmal wie das Steuer eines Autos vor. Sie wollen nie mehr als eine Person am Steuer haben! Andererseits wechseln sich bei einer Reise oft mehrere Personen am Steuer ab. In etwa so wird auch der Zugriff auf den Interpreter an einen anderen Thread abgegeben.
Aufgrund des GIL sind in Python keine echten Multithreading-Prozesse möglich. Diese Funktion hat im Verlauf des letzten Jahrzehnts Debatten ausgelöst, und es gab viele Versuche, Python schneller zu machen, indem der GIL entfernt und Multithreading-Prozesse ermöglicht wurden. Kürzlich hat Python 3.13 eine Option eingeführt, mit der wir Python ohne GIL verwenden können – dies wird manchmal auch als No-GIL-Python oder Free-Threaded-Python bezeichnet, also Python mit freiem Threading. Dies läutet eine neue Ära in der Python-Programmierung ein.
Warum gibt es den GIL überhaupt?
Wenn der GIL so unbeliebt ist, warum wurde er überhaupt eingeführt? Der GIL hat in Wirklichkeit auch Vorteile. In anderen Programmiersprachen mit echtem Multithreading kommt es manchmal zu Problemen, wenn mehr als ein Thread Daten modifiziert, denn das Endergebnis hängt davon ab, welcher Thread oder Prozess zuerst fertig wird. Dies wird als „Race-Condition“ bezeichnet. Sprachen wie Rust sind oft schwer zu erlernen, da beim Programmieren Mutexe verwendet werden müssen, um Race-Conditions zu verhindern.
In Python haben alle Objekte einen Referenzzähler, um Buch darüber zu führen, wie viele andere Objekte Informationen von ihnen benötigen. Wenn der Referenzzähler null erreicht, können wir sicher davon ausgehen, dass das Objekt nicht mehr benötigt wird und sein Speicher freigegeben werden kann, denn in Python gibt es ja aufgrund des GIL keine Race-Conditions.
Als Python 1991 veröffentlicht wurde, hatten die meisten PCs nur einen CPU-Kern, und nur wenige Programmierer forderten eine Unterstützung von Multithreading. Mit einem GIL lassen sich viele Probleme bei der Programmimplementierung lösen, und auch die Codewartung wird erleichtert. Daher hat Python-Erfinder Guido van Rossum Python im Jahr 1992 mit einem GIL ausgestattet.
Im Jahr 2025 stellt sich die Lage ganz anders dar: PCs haben Mehrkernprozessoren und damit viel mehr Rechenleistung. Wir können diese zusätzliche Leistung nutzen, um echte Nebenläufigkeit zu erreichen, ohne den GIL einzustampfen.
Später in diesem Beitrag werden Sie erfahren, wie Sie den GIL loswerden können. Aber erst einmal sehen wir uns an, wie echte Nebenläufigkeit mit GIL funktioniert.
Multiprocessing in Python
Bevor wir uns dem Entfernen des GIL zuwenden, sehen wir uns an, wie sich bei der Python-Entwicklung mit der multiprocessing-Bibliothek echte Nebenläufigkeit erreichen lässt. Die multiprocessing-Standardbibliothek bietet sowohl lokale als auch Remote-Nebenläufigkeit. Der Global Interpreter Lock wird dabei durch die Verwendung von Subprozessen anstelle von Threads umgangen. Auf diese Weise können Entwickler*innen mit dem multiprocessing-Modul mehrere Prozessoren auf einem System voll ausnutzen.
Um unser Programm jedoch multiprocessing-fähig zu machen, müssen wir es etwas anpassen. Sehen Sie sich das folgende Beispiel für die Verwendung der multiprocessing-Bibliothek in Python an.
Sie erinnern sich sicher an unser asynchrones Burger-Restaurant aus Teil 1 dieser Blogreihe:
import asyncio
import time
async def make_burger(order_num):
print(f"Preparing burger #{order_num}...")
await asyncio.sleep(5) # time for making the burger
print(f"Burger made #{order_num}")
async def main():
order_queue = []
for i in range(3):
order_queue.append(make_burger(i))
await asyncio.gather(*(order_queue))
if __name__ == "__main__":
s = time.perf_counter()
asyncio.run(main())
elapsed = time.perf_counter() - s
print(f"Orders completed in {elapsed:0.2f} seconds.")
Für denselben Zweck können wir auch die multiprocessing-Bibliothek verwenden:
import multiprocessing
import time
def make_burger(order_num):
print(f"Preparing burger #{order_num}...")
time.sleep(5) # time for making the burger
print(f"Burger made #{order_num}")
if __name__ == "__main__":
print("Number of available CPU:", multiprocessing.cpu_count())
s = time.perf_counter()
all_processes = []
for i in range(3):
process = multiprocessing.Process(target=make_burger, args=(i,))
process.start()
all_processes.append(process)
for process in all_processes:
process.join()
elapsed = time.perf_counter() - s
print(f"Orders completed in {elapsed:0.2f} seconds.")
Wie Sie sich vielleicht erinnern, sind zahlreiche Methoden im multiprocessing-Modul denen im threading-Modul sehr ähnlich. Um den Unterschied durch Multiprocessing zu erkennen, sehen wir uns einen komplexeren Anwendungsfall an:
import multiprocessing
import time
import queue
def make_burger(order_num, item_made):
name = multiprocessing.current_process().name
print(f"{name} is preparing burger #{order_num}...")
time.sleep(5) # time for making burger
item_made.put(f"Burger #{order_num}")
print(f"Burger #{order_num} made by {name}")
def make_fries(order_num, item_made):
name = multiprocessing.current_process().name
print(f"{name} is preparing fries #{order_num}...")
time.sleep(2) # time for making fries
item_made.put(f"Fries #{order_num}")
print(f"Fries #{order_num} made by {name}")
def working(task_queue, item_made, order_num, lock):
break_count = 0
name = multiprocessing.current_process().name
while True:
try:
task = task_queue.get_nowait()
except queue.Empty:
print(f"{name} has nothing to do...")
if break_count > 1:
break # stop if idle for too long
else:
break_count += 1
time.sleep(1)
else:
lock.acquire()
try:
current_num = order_num.value
order_num.value = current_num + 1
finally:
lock.release()
task(current_num, item_made)
break_count = 0
if __name__ == "__main__":
print("Welcome to Pyburger! Please place your order.")
burger_num = input("Number of burgers:")
fries_num = input("Number of fries:")
s = time.perf_counter()
task_queue = multiprocessing.Queue()
item_made = multiprocessing.Queue()
order_num = multiprocessing.Value("i", 0)
lock = multiprocessing.Lock()
for i in range(int(burger_num)):
task_queue.put(make_burger)
for i in range(int(fries_num)):
task_queue.put(make_fries)
staff1 = multiprocessing.Process(
target=working,
name="John",
args=(
task_queue,
item_made,
order_num,
lock,
),
)
staff2 = multiprocessing.Process(
target=working,
name="Jane",
args=(
task_queue,
item_made,
order_num,
lock,
),
)
staff1.start()
staff2.start()
staff1.join()
staff2.join()
print("All tasks finished. Closing now.")
print("Items created are:")
while not item_made.empty():
print(item_made.get())
elapsed = time.perf_counter() - s
print(f"Orders completed in {elapsed:0.2f} seconds.")
Hier ist die Ausgabe, die wir erhalten:
Welcome to Pyburger! Please place your order. Number of burgers:3 Number of fries:2 Jane has nothing to do... John is preparing burger #0... Jane is preparing burger #1... Burger #0 made by John John is preparing burger #2... Burger #1 made by Jane Jane is preparing fries #3... Fries #3 made by Jane Jane is preparing fries #4... Burger #2 made by John John has nothing to do... Fries #4 made by Jane Jane has nothing to do... John has nothing to do... Jane has nothing to do... John has nothing to do... Jane has nothing to do... All tasks finished. Closing now. Items created are: Burger #0 Burger #1 Fries #3 Burger #2 Fries #4 Orders completed in 12.21 seconds.
Beachten Sie, dass es beim Multiprocessing einige Einschränkungen gibt, die es erfordern, den obigen Code auf diese Weise zu programmieren. Sehen wir sie uns der Reihe nach an.
Wie Sie sich erinnern, hatten wir zuvor die Funktionen make_burger und make_fries, um eine Funktion mit der richtigen order_num zu generieren:
def make_burger(order_num):
def making_burger():
logger.info(f"Preparing burger #{order_num}...")
time.sleep(5) # time for making burger
logger.info(f"Burger made #{order_num}")
return making_burger
def make_fries(order_num):
def making_fries():
logger.info(f"Preparing fries #{order_num}...")
time.sleep(2) # time for making fries
logger.info(f"Fries made #{order_num}")
return making_fries
Bei der Verwendung von Multiprocessing geht das nicht. Wenn wir es versuchen, erhalten wir eine Fehlermeldung, die ungefähr so aussieht:
AttributeError: Can't get local object 'make_burger..making_burger'
Das liegt daran, dass Multiprocessing pickle verwendet, das im Allgemeinen nur Funktionen auf der obersten Modulebene serialisieren kann. Dies ist eine der Einschränkungen von Multiprocessing.
Zweitens wird es Ihnen im obigen Codeabschnitt, der Multiprocessing verwendet, aufgefallen sein, dass wir keine globalen Variablen für das Teilen von Daten verwenden. Zum Beispiel können wir keine globalen Variablen für item_made und order_num verwenden. Für den Datenaustausch zwischen unterschiedlichen Prozessen werden spezielle Klassenobjekte wie Queue und Value aus der multiprocessing-Bibliothek verwendet und als Argumente an die Prozesse übergeben.
Ganz allgemein wird das Teilen von Daten und Zuständen zwischen unterschiedlichen Prozessen nicht empfohlen, da dies zahlreiche weitere Probleme verursachen kann. In unserem obigen Beispiel müssen wir einen Lock verwenden, um sicherzustellen, dass jeweils nur ein Prozess auf den Wert von order_num zugreifen und ihn erhöhen kann. Ohne den Lock kann die Anzahl der Bestellungen auf folgende Weise durcheinander geraten:
Items created are: Burger #0 Burger #0 Fries #2 Burger #1 Fries #3
So wird ein Lock verwendet, um Probleme zu vermeiden:
lock.acquire()
try:
current_num = order_num.value
order_num.value = current_num + 1
finally:
lock.release()
task(current_num, item_made)
Weitere Informationen zur Verwendung der multiprocessing-Standardbibliothek finden Sie in der Dokumentation.
Entfernen des GIL
Das Entfernen des GIL wird seit fast einem Jahrzehnt diskutiert. 2016 präsentierte Larry Hastings auf dem Python Language Summit seine Überlegungen zu einer „GIL-Ektomie“ am CPython-Interpreter und die Fortschritte, die er mit dieser Idee erzielt hatte [1]. Dies war ein erster Versuch, den GIL aus Python zu entfernen. 2021 entfachte Sam Gross die Diskussion über die Entfernung der GIL neu [2], und das führte im Jahr 2023 zum Python-Verbesserungsvorschlag PEP 703: Making the Global Interpreter Lock Optional in CPython.
Wie wir erkennen können, ist die Entfernung des GIL keineswegs eine übereilte Entscheidung und war innerhalb der Community Gegenstand erheblicher Debatten. Wie die obigen Multiprocessing-Beispiele (und der oben verlinkte PEP 703) zeigen, werden die Dinge schnell kompliziert, wenn die Absicherung durch den GIL wegfällt.
[1]: https://lwn.net/Articles/689548/
[2]: https://lwn.net/ml/python-dev/CAGr09bSrMNyVNLTvFq-h6t38kTxqTXfgxJYApmbEWnT71L74-g@mail.gmail.com/
Referenzzählung
Wenn der GIL vorhanden ist, sind Referenzzählung und Garbage Collection einfacher. Wenn jeweils nur ein Thread Zugriff auf Python-Objekte hat, können wir uns mit einer einfachen, nicht-atomaren Referenzzählung begnügen und das Objekt zum Löschen freigeben, wenn der Referenzzähler null erreicht.
Ohne GIL ist die Sache komplizierter. Eine nicht-atomare Referenzzählung ist nicht mehr möglich, da diese keine Threadsicherheit bietet. Wenn mehrere Threads gleichzeitig den Referenzzähler eines Python-Objekts erhöhen oder erniedrigen, kann das schiefgehen. Im Idealfall sollte eine atomare Referenzzählung verwendet werden, um die Threadsicherheit zu gewährleisten. Diese Methode ist jedoch mit einem hohen Overhead verbunden, und bei zahlreichen Threads leidet daher die Effizienz.
Die Lösung besteht in der Verwendung einer teilweise atomaren Referenzzählung („biased reference counting“), die ebenfalls threadsicher ist. Die Idee dahinter ist, jedes Objekt einem Besitzerthread zuzuordnen, also dem Thread, der am häufigsten auf das Objekt zugreift. Besitzerthreads können eine nicht-atomare Referenzzählung für die ihnen zugeordneten Objekte durchführen, während andere Threads bei diesen Objekten zu einer atomaren Referenzzählung gezwungen werden. Diese Methode ist der einfachen atomaren Referenzzählung vorzuziehen, da auf die meisten Objekte die meiste Zeit nur von einem Thread aus zugegriffen wird. Wir können den Overhead bei der Ausführung reduzieren, indem wir dem Besitzerthread eine nicht-atomare Referenzzählung erlauben.
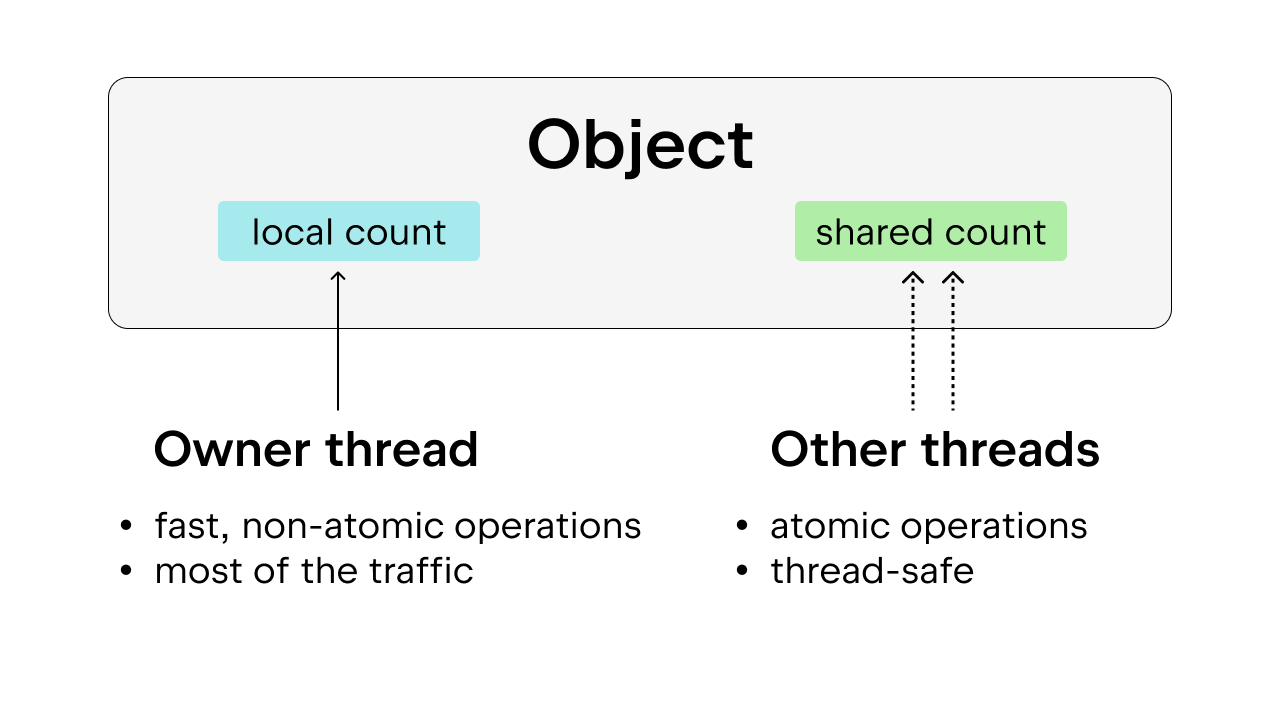
Außerdem werden einige häufig verwendete Python-Objekte, wie True, False, kleine Ganzzahlen und einige internalisierte Zeichenfolgen, „unsterblich“ gemacht. „Unsterblich“ bedeutet in diesem Zusammenhang lediglich, dass die Objekte während der gesamten Lebensdauer des Programms im Speicher verbleiben und somit keine Referenzzählung erforderlich ist.
Garbage Collection
Wir müssen auch die Art und Weise ändern, wie durch Garbage Collection Speicher freigegeben wird. Anstatt den Referenzzähler sofort zu erniedrigen, wenn eine Referenz freigegeben wird, und das Objekt sofort zu entfernen, wenn der Referenzzähler null erreicht, wird die sogenannte „verzögerte Referenzzählung“ verwendet.
Wenn der Referenzzähler erniedrigt werden soll, wird das Objekt in einer Tabelle gespeichert. Diese Tabelle wird dann nochmals überprüft, um festzustellen, ob das Erniedrigen des Referenzzählers korrekt ist oder nicht. Dadurch wird vermieden, dass das Objekt vorzeitig entfernt wird, während es noch referenziert ist, was ohne GIL passieren kann, da die Referenzzählung nicht so einfach ist wie mit GIL. Dies macht den Garbage-Collection-Prozess komplexer, da die Garbage Collection unter Umständen den Stack jedes Threads durchlaufen muss, um den Referenzzähler der einzelnen Threads zu erhalten.
Eine weitere Sache, die wir berücksichtigen müssen: Der Referenzzähler muss während der Garbage Collection unverändert bleiben. Wenn ein zu löschendes Objekt plötzlich referenziert wird, führt dies zu ernsthaften Problemen. Aus diesem Grund muss während des Garbage-Collection-Zyklus „die Welt angehalten“ werden, um die Threadsicherheit zu gewährleisten.
Speicherallokation
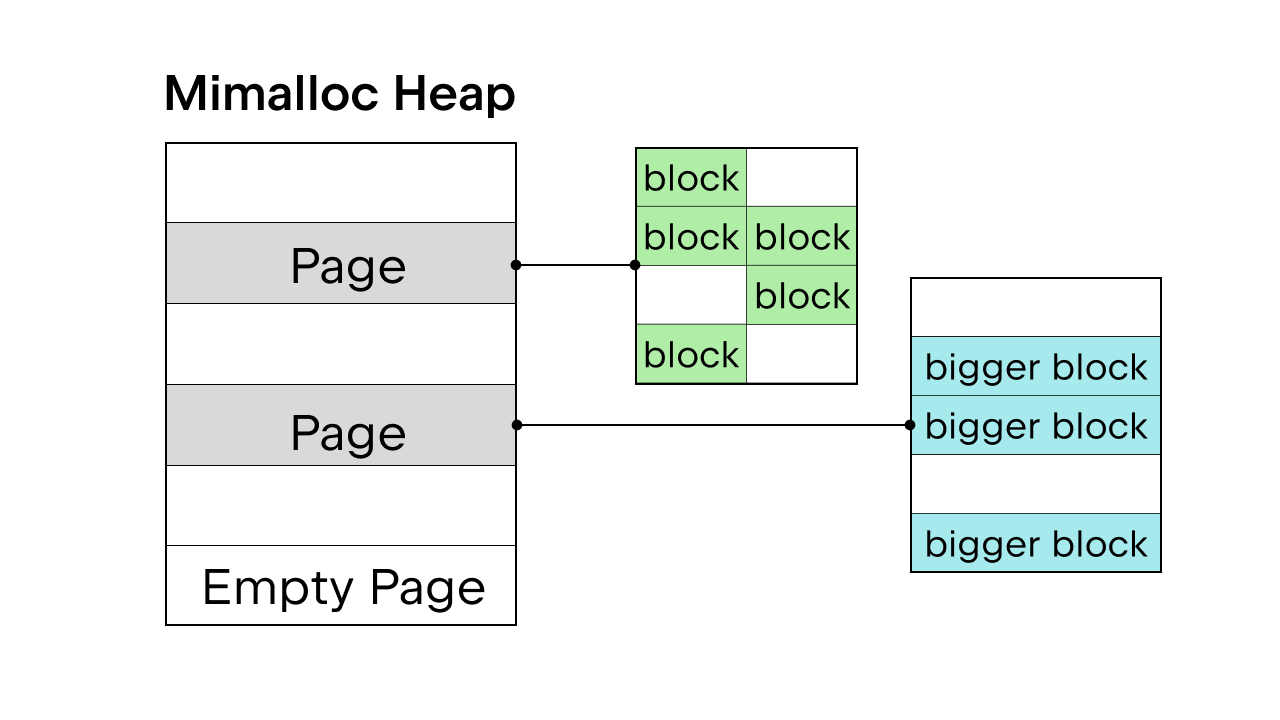
Wenn ein vorhandener GIL die Threadsicherheit garantiert, wird der Python-interne Speicherallokator pymalloc verwendet. Ohne GIL brauchen wir jedoch einen neuen Speicherallokator. Sam Gross schlug im PEP mimalloc vor, einen universellen Allokator, der von Daan Leijen entwickelt und von Microsoft gepflegt wird. Dieser ist eine gute Wahl, da er threadsicher ist und bei kleinen Objekten eine gute Performance bietet.
Mimalloc füllt seinen Heap mit Seiten und die Seiten mit Blöcken. Jede Seite enthält Blöcke, und die Blöcke innerhalb jeder Seite sind alle gleich groß. Durch das Einführen einiger Einschränkungen in Bezug auf den Zugriff auf list- und dict-Objekte muss der Garbage Collector keine verknüpfte Liste führen, um alle Objekte zu finden, und auch der Lesezugriff auf list- und dict-Objekte ist ohne das Belegen des Locks möglich.
In Bezug auf das Entfernen des GIL gibt es noch weitere Details zu berücksichtigen – wir können hier unmöglich auf alle eingehen. Eine vollständige Liste finden Sie in PEP 703 – Making the Global Interpreter Lock Optional in CPython.
Performanceunterschiede mit und ohne GIL
Da Python 3.13 optional freies Threading erlaubt, können wir die Performance der Standardversion von Python 3.13 mit der Free-Threaded-Version vergleichen.
Python mit freiem Threading installieren
Wir verwenden pyenv, um beide Versionen zu installieren: die Standardversion (z. B. 3.13.5) und die Free-Threaded-Version (z. B. 3.13.5t).
Alternativ können Sie auch die Installationsprogramme auf python.org verwenden. Achten Sie darauf, während der Installation die Option Customize auszuwählen, und klicken Sie auf das zusätzliche Kontrollkästchen, um die Installation von Free-Threaded-Python zu aktivieren (wie im Beispiel in diesem Blogartikel).
Nachdem wir beide Versionen installiert haben, können wir sie als Interpreter zu einem PyCharm-Projekt hinzufügen.
Klicken Sie zunächst auf den Namen Ihres Python-Interpreters unten rechts.
Wählen Sie im Menü Add New Interpreter und dann Add Local Interpreter aus.
Wählen Sie Select existing, warten Sie, bis der Interpreter-Pfad geladen ist (was eine Weile dauern kann, wenn Sie wie ich viele Interpreter haben), und wählen Sie dann den soeben installierten neuen Interpreter im Dropdown Python path aus.
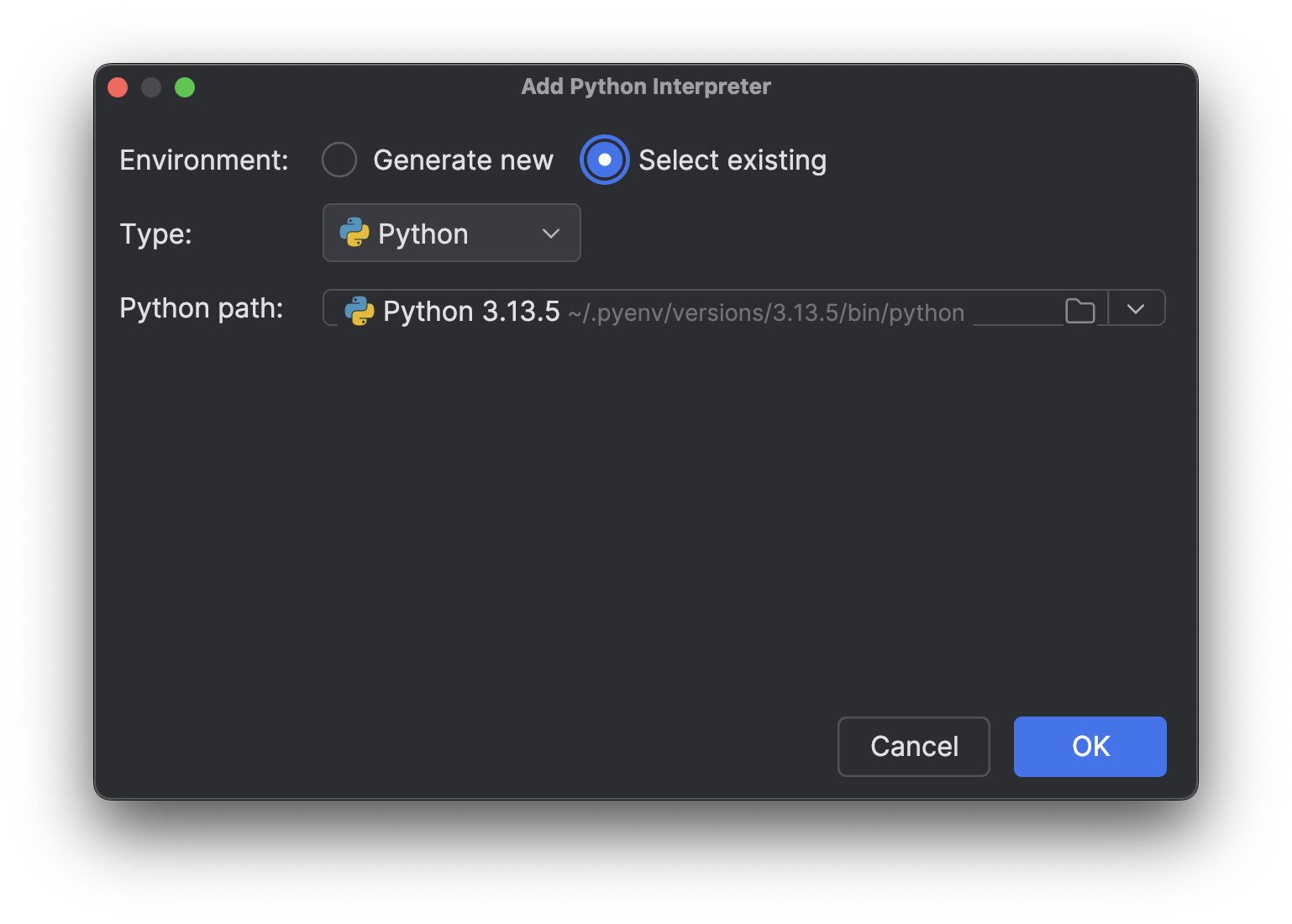
Klicken Sie auf OK, um ihn hinzuzufügen. Wiederholen Sie die gleichen Schritte, um auch den anderen Interpreter hinzuzufügen. Wenn Sie jetzt wieder auf den Interpreter-Namen unten rechts klicken, sehen Sie mehrere Python-3.13-Interpreter, genau wie im Bild oben.
Testen mit einem CPU-limitierten Prozess
Als Nächstes benötigen wir ein Skript, um die unterschiedlichen Versionen zu testen. Wie Sie sich erinnern werden, haben wir in Teil 1 dieser Blogreihe geklärt, dass wir echtes Multithreading benötigen, um CPU-limitierte Prozesse zu beschleunigen. Um zu sehen, ob das Entfernen des GIL echtes Multithreading ermöglicht und Python beschleunigt, können wir einen Test mit einem CPU-limitierten Prozess und mehreren Threads durchführen. Hier ist das Skript, dessen Generierung ich an Junie delegiert habe (mit einigen abschließenden Anpassungen meinerseits):
import time
import multiprocessing # Kept for CPU count
from concurrent.futures import ThreadPoolExecutor
import sys
def is_prime(n):
"""Check if a number is prime (CPU-intensive operation)."""
if n <= 1:
return False
if n <= 3:
return True
if n % 2 == 0 or n % 3 == 0:
return False
i = 5
while i * i <= n:
if n % i == 0 or n % (i + 2) == 0:
return False
i += 6
return True
def count_primes(start, end):
"""Count prime numbers in a range."""
count = 0
for num in range(start, end):
if is_prime(num):
count += 1
return count
def run_single_thread(range_size, num_chunks):
"""Run the prime counting task in a single thread."""
chunk_size = range_size // num_chunks
total_count = 0
start_time = time.time()
for i in range(num_chunks):
start = i * chunk_size + 1
end = (i + 1) * chunk_size + 1 if i < num_chunks - 1 else range_size + 1
total_count += count_primes(start, end)
end_time = time.time()
return total_count, end_time - start_time
def thread_task(start, end):
"""Task function for threads."""
return count_primes(start, end)
def run_multi_thread(range_size, num_threads, num_chunks):
"""Run the prime counting task using multiple threads."""
chunk_size = range_size // num_chunks
total_count = 0
start_time = time.time()
with ThreadPoolExecutor(max_workers=num_threads) as executor:
futures = []
for i in range(num_chunks):
start = i * chunk_size + 1
end = (i + 1) * chunk_size + 1 if i < num_chunks - 1 else range_size + 1
futures.append(executor.submit(thread_task, start, end))
for future in futures:
total_count += future.result()
end_time = time.time()
return total_count, end_time - start_time
def main():
# Fixed parameters
range_size = 1000000 # Range of numbers to check for primes
num_chunks = 16 # Number of chunks to divide the work into
num_threads = 4 # Fixed number of threads for multi-threading test
print(f"Python version: {sys.version}")
print(f"CPU count: {multiprocessing.cpu_count()}")
print(f"Range size: {range_size}")
print(f"Number of chunks: {num_chunks}")
print("-" * 60)
# Run single-threaded version as baseline
print("Running single-threaded version (baseline)...")
count, single_time = run_single_thread(range_size, num_chunks)
print(f"Found {count} primes in {single_time:.4f} seconds")
print("-" * 60)
# Run multi-threaded version with fixed number of threads
print(f"Running multi-threaded version with {num_threads} threads...")
count, thread_time = run_multi_thread(range_size, num_threads, num_chunks)
speedup = single_time / thread_time
print(f"Found {count} primes in {thread_time:.4f} seconds (speedup: {speedup:.2f}x)")
print("-" * 60)
# Summary
print("SUMMARY:")
print(f"{'Threads':<10} {'Time (s)':<12} {'Speedup':<10}")
print(f"{'1 (baseline)':<10} {single_time:<12.4f} {'1.00x':<10}")
print(f"{num_threads:<10} {thread_time:<12.4f} {speedup:.2f}x")
if __name__ == "__main__":
main()
Um die Ausführung des Skripts mit unterschiedlichen Python-Interpretern zu erleichtern, können wir unserem PyCharm-Projekt ein benutzerdefiniertes Run-Skript hinzufügen.
Wählen Sie oben Edit Configurations… im Dropdown-Menü neben der Run-Schaltfläche (![]() ) aus.
) aus.
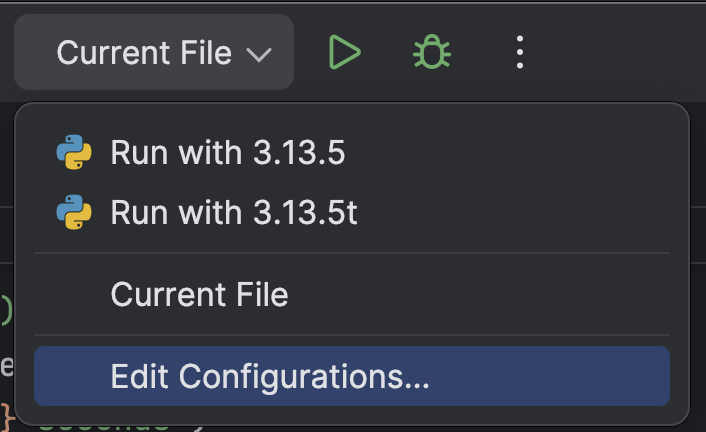
Klicken Sie auf die Schaltfläche + oben links und wählen Sie dann im Dropdown Add New Configuration Python aus.
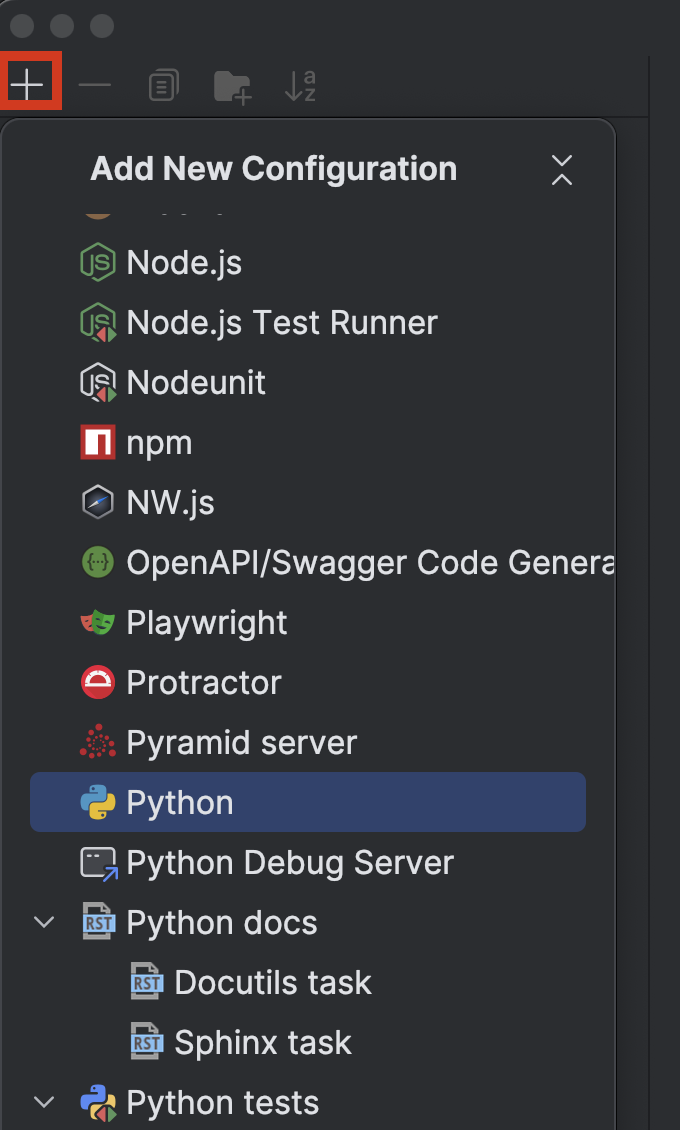
Wählen Sie einen Namen, an dem Sie erkennen können, welcher Interpreter verwendet wird, z. B. 3.13.5 bzw. 3.15.3t. Wählen Sie den richtigen Interpreter aus und geben Sie den Namen des Testskripts wie folgt an:
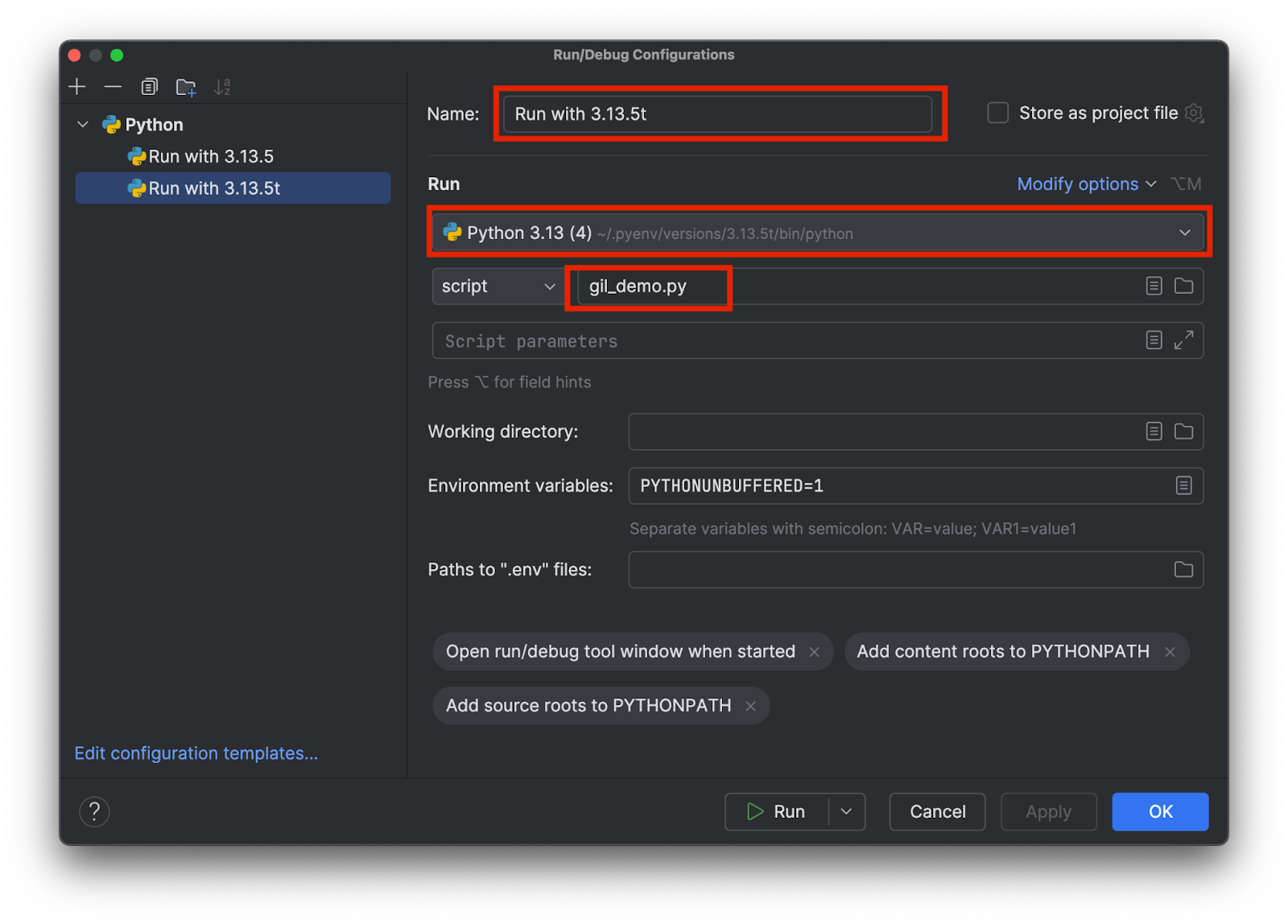
Erstellen Sie zwei Konfigurationen, eine für jeden Interpreter. Klicken Sie dann auf OK.
Jetzt können wir das Skript unkompliziert mit oder ohne GIL ausführen, indem wir die entsprechende Konfiguration auswählen und oben auf die Schaltfläche Run (![]() ) klicken.
) klicken.
Vergleich der Ergebnisse
Beim Ausführen der Standardversion 3.13.5 mit GIL habe ich folgende Ergebnisse erhalten:
Python version: 3.13.5 (main, Jul 10 2025, 20:33:15) [Clang 17.0.0 (clang-1700.0.13.5)] CPU count: 8 Range size: 1000000 Number of chunks: 16 ------------------------------------------------------------ Running single-threaded version (baseline)... Found 78498 primes in 1.1930 seconds ------------------------------------------------------------ Running multi-threaded version with 4 threads... Found 78498 primes in 1.2183 seconds (speedup: 0.98x) ------------------------------------------------------------ SUMMARY: Threads Time (s) Speedup 1 (baseline) 1.1930 1.00x 4 1.2183 0.98x
Wie Sie sehen, ändert sich die Geschwindigkeit bei der Version mit 4 Threads im Vergleich zur Single-Thread-Ausführung nicht wesentlich. Sehen wir uns an, welche Ergebnisse wir erhalten, wenn wir die Free-Threaded-Version 3.13.5t ausführen:
Python version: 3.13.5 experimental free-threading build (main, Jul 10 2025, 20:36:28) [Clang 17.0.0 (clang-1700.0.13.5)] CPU count: 8 Range size: 1000000 Number of chunks: 16 ------------------------------------------------------------ Running single-threaded version (baseline)... Found 78498 primes in 1.5869 seconds ------------------------------------------------------------ Running multi-threaded version with 4 threads... Found 78498 primes in 0.4662 seconds (speedup: 3.40x) ------------------------------------------------------------ SUMMARY: Threads Time (s) Speedup 1 (baseline) 1.5869 1.00x 4 0.4662 3.40x
Diesmal war die Geschwindigkeit mehr als 3-mal höher. Zu beachten ist, dass es in beiden Fällen einen Overhead für das Multithreading gibt. Daher ist die Geschwindigkeit selbst bei echtem Multithreading mit 4 Threads nicht 4-mal so hoch.
Fazit
In Teil 2 der Blogreihe „Schnelleres Python“ sind wir auf die Gründe für die Verwendung des GIL in Python, die Umgehung der durch den GIL auferlegten Beschränkungen durch Multiprocessing, das Vorgehen zum Entfernen des GIL und die Auswirkungen des Entfernens eingegangen.
Zum Zeitpunkt dieses Blogartikels ist die Free-Threaded-Version von Python noch nicht die Standardversion. Mit der zunehmenden Verbreitung in der Anwendergemeinschaft und der Anpassung der Drittanbieter-Bibliotheken geht die Community jedoch davon aus, dass Free-Threaded-Python in Zukunft zum Standard wird. Es wurde angekündigt, dass Python 3.14 eine Free-Threaded-Version enthalten wird, die nicht mehr im experimentellen Stadium, aber immer noch optional sein wird.
PyCharm stellt eine klassenführende Python-Unterstützung bereit, die das Schreiben von schnellem und korrektem Code erleichtert. Profitieren Sie von der intelligentesten Code-Completion, PEP-8-Prüfungen, sinnvollen Refactorings und einer Vielzahl von Inspektionen, die alle Anforderungen bei der Programmierung abdecken. Wie Sie in diesem Blogartikel gesehen haben, ermöglicht PyCharm benutzerdefinierte Einstellungen für Python-Interpreter und Run-Konfigurationen, sodass Sie mit wenigen Klicks zwischen unterschiedlichen Interpretern wechseln können, um die IDE optimal an eine Vielzahl von Python-Projekten anzupassen.
Autorin des ursprünglichen Blogposts






