

Feintuning und Bereitstellung von GPT-Modellen mit Transformers von Hugging Face

Für Forschende und Interessierte im Bereich des maschinellen Lernens ist Hugging Face mittlerweile zu einem Alltagsbegriff geworden. Zu den größten Erfolgen von Hugging Face zählt Transformers, ein Modelldefinitions-Framework für ML-Modelle in den Bereichen Text, Computer Vision, Audio und Video. Aufgrund der umfangreichen Sammlung modernster Machine-Learning-Modelle, die im Hugging Face Hub verfügbar sind, und der Kompatibilität mit den meisten Trainingsframeworks wird Transformers häufig für Inferenz und Modelltraining eingesetzt.
Warum benötigen KI-Modelle ein Feintuning?
Das Feintuning von KI-Modellen ist entscheidend, um ihre Leistung an bestimmte Aufgaben und Datensammlungen anzupassen. Dadurch können sie im Vergleich zu universellen Modellen eine höhere Genauigkeit und Effizienz erzielen. Durch das Feintuning eines vortrainierten Modells muss das Training nicht von Grund auf neu erfolgen, sodass Zeit und Ressourcen gespart werden. Darüber hinaus können spezifische Formate, Nuancen und Sonderfälle innerhalb eines bestimmten Bereichs besser gehandhabt werden, was zuverlässigere und besser angepasste Ergebnisse ermöglicht.
In diesem Blogartikel werden wir ein GPT-Modell für mathematisches Denken optimieren, damit es mathematische Fragen besser beantworten kann.
Verwendung von Hugging-Face-Modellen
In PyCharm können wir unkompliziert alle auf Hugging Face bereitgestellten Modelle durchsuchen und hinzufügen. Wählen Sie in einer neuen Python-Datei aus dem Menü Code in der oberen Menüleiste die Option Insert HF Model.
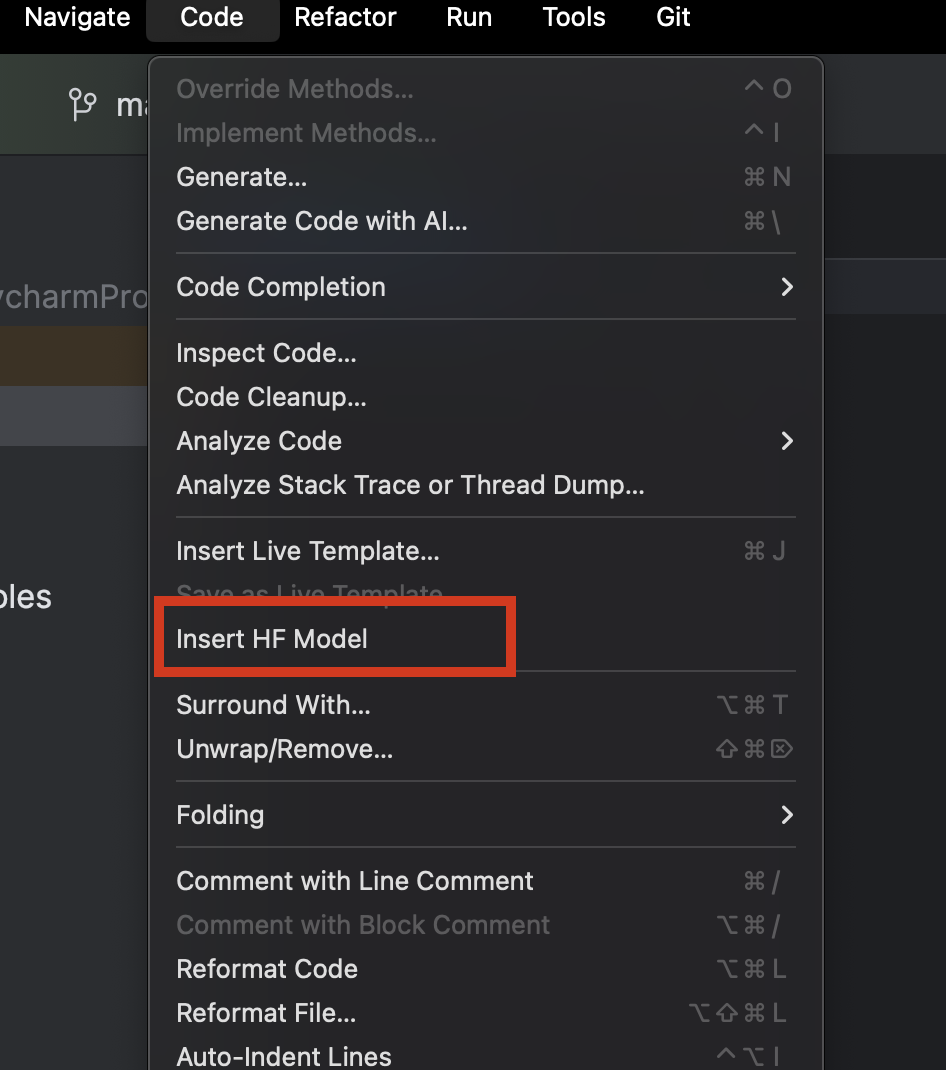
Im angezeigten Menü können Sie die Modelle nach Kategorien durchsuchen oder in die Suchleiste oben einen Suchtext eingeben. Wenn Sie ein Modell auswählen, wird dessen Beschreibung auf der rechten Seite angezeigt.
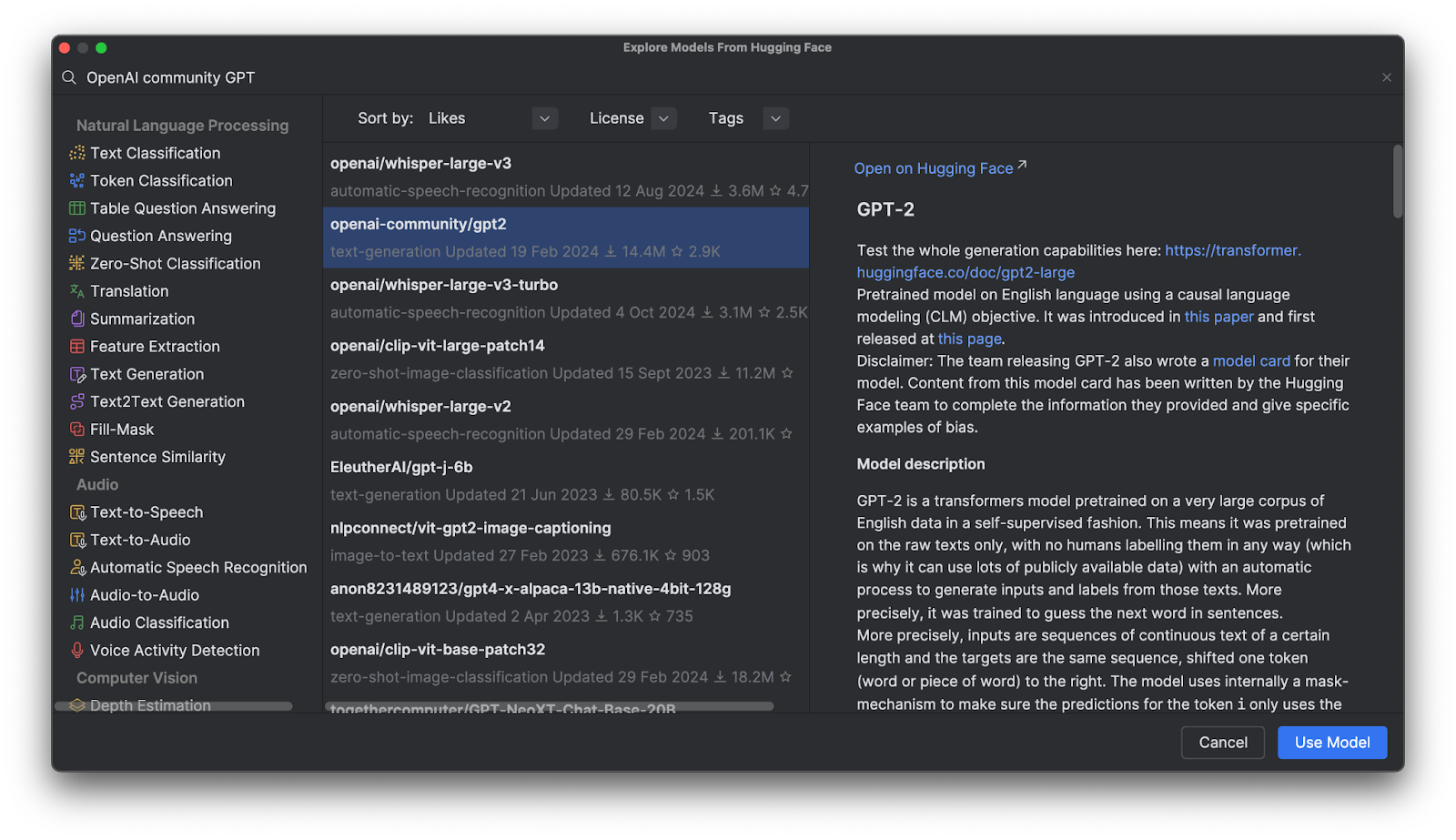
Wenn Sie auf Use Model klicken, wird ein Codeabschnitt in Ihre Datei eingefügt. Das war’s – Sie können nun Ihr Hugging-Face-Modell verwenden.

GPT-Modelle (Generative Pre-Trained Transformer)
GPT-Modelle sind im Hugging Face Hub sehr populär – aber was sind sie eigentlich? GPTs sind trainierte Modelle, die natürliche Sprache verstehen und qualitativ hochwertige Texte generieren. Sie werden hauptsächlich für Aufgaben im Bereich der textuellen Inferenz, der Beantwortung von Fragen, der semantischen Ähnlichkeit und der Dokumentklassifizierung eingesetzt. Das bekannteste Beispiel ist das von OpenAI entwickelte ChatGPT.
Im Hugging Face Hub sind zahlreiche OpenAI-GPT-Modelle verfügbar. Wir werden sehen, wie wir diese Modelle mit Transformers verwenden, mit unseren eigenen Daten optimieren und in eine Anwendung integrieren können.
Vorteile von Transformers
Transformers stellt in Verbindung mit anderen von Hugging Face bereitgestellten Tools hochentwickelte Instrumente für das Feintuning komplexer Deep-Learning-Modelle bereit. Sie müssen nicht die Architektur und die Tokenisierungsmethode jedes einzelnen Modells bis ins Detail verstehen, denn diese Tools ermöglichen die Plug-and-Play-Nutzung von Modellen mit beliebigen kompatiblen Trainingsdaten und bieten dabei umfangreiche Anpassungsmöglichkeiten für Tokenisierung und Training.
Transformers im Einsatz
Um einen genaueren Einblick in die Funktionsweise von Transformers zu erhalten, sehen wir uns an, wie wir es für die Interaktion mit einem GPT-Modell verwenden können.
Inferenz unter Verwendung eines vortrainierten Modells in einer Pipeline
Nachdem wir das OpenAI-GPT-2-Modell ausgewählt und hinzugefügt haben, sieht unser Code wie folgt aus:
from transformers import pipeline
pipe = pipeline("text-generation", model="openai-community/gpt2")
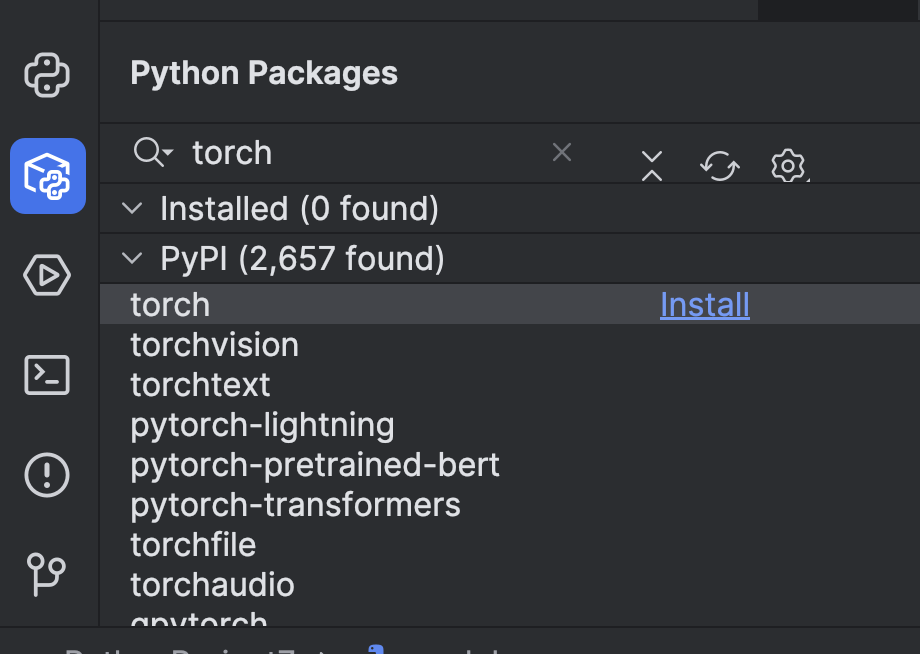
Um das Modell verwenden zu können, müssen wir einige Vorbereitungen treffen. Zunächst müssen wir ein Machine-Learning-Framework installieren. In diesem Beispiel verwenden wir PyTorch. Sie können es unkompliziert im PyCharm-Fenster Python Packages installieren.
Anschließend müssen wir Transformers mithilfe der Option `torch` installieren. Sie können dies im Terminal erledigen, das Sie mit der Schaltfläche auf der linken Seite oder mit der Tastenkombination ⌥ F12 (macOS) bzw. Alt + F12 (Windows) öffnen können.
Da wir uv verwenden, nutzen wir im Terminal die folgenden Befehle, um das Paket als Abhängigkeit hinzuzufügen und zu installieren:
uv add “transformers[torch]” uv sync
Wenn Sie pip verwenden:
pip install “transformers[torch]”
Außerdem installieren wir einige weitere Bibliotheken, die wir später benötigen werden, darunter python-dotenv, datasets, notebook und ipywidgets. Sie können eine der oben genannten Methoden verwenden, um sie zu installieren.
Anschließend empfiehlt es sich, ein GPU-System hinzuzufügen, um das Modell zu beschleunigen. Je nachdem, wie Ihr System ausgestattet ist, können Sie den Device-Parameter der Pipeline anpassen. Da ich ein Mac-M2-System verwende, kann ich wie folgt device="mps" einstellen:
pipe = pipeline("text-generation", model="openai-community/gpt2", device="mps")
Wenn Sie CUDA-GPUs haben, können Sie auch device="cuda" verwenden.
Nachdem wir unsere Pipeline eingerichtet haben, testen wir sie mit einem einfachen Prompt:
from transformers import pipeline
pipe = pipeline("text-generation", model="openai-community/gpt2", device="mps")
print(pipe("A rectangle has a perimeter of 20 cm. If the length is 6 cm, what is the width?", max_new_tokens=200))
Führen Sie das Skript mit der Run-Schaltfläche (![]() ) am oberen Rand aus:
) am oberen Rand aus:
Das Ergebnis wird in etwa so aussehen:
[{'generated_text': 'A rectangle has a perimeter of 20 cm. If the length is 6 cm, what is the width?nnA rectangle has a perimeter of 20 cm. If the length is 6 cm, what is the width? A rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width? A rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width? A rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width?nnA rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width? A rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width? A rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width? A rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width?nnA rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width? A rectangle has a perimeter'}]
Von Nachdenken ist hier nicht viel zu sehen – das ist nur ein Haufen Unsinn.
Möglicherweise wird auch folgende Warnung angezeigt:
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Dies ist die Standardeinstellung. Sie können auch wie unten gezeigt eine manuelle Einstellung vornehmen, damit diese Warnung verschwindet, aber wir müssen uns zu diesem Zeitpunkt nicht allzu viele Gedanken darüber machen.
print(pipe("A rectangle has a perimeter of 20 cm. If the length is 6 cm, what is the width?", max_new_tokens=200, pad_token_id=pipe.tokenizer.eos_token_id))
Nachdem wir nun gesehen haben, wie sich GPT-2 standardmäßig verhält, wollen wir versuchen, seine mathematischen Fähigkeiten durch etwas Feintuning zu verbessern.
Eine Datensammlung vom Hugging Face Hub laden und vorbereiten
Bevor wir mit der Arbeit am GPT-Modell beginnen, benötigen wir zunächst Trainingsdaten. Sehen wir uns an, wie wir eine Datensammlung vom Hugging Face Hub beziehen können.
Falls Sie dies noch nicht getan haben, erstellen Sie einen Hugging-Face-Account und lassen Sie sich einen Zugangstoken ausstellen. Fürs Erste benötigen wir nur einen `read`-Token. Speichern Sie Ihren Token in einer `.env`-Datei:
HF_TOKEN=your-hugging-face-access-token
Wir werden dieses Math Reasoning Dataset verwenden, dessen Beschreibung auf mathematisches Denken hinweist. Wir werden unser GPT-Modell mit dieser Datensammlung optimieren, damit es mathematische Probleme effektiver lösen kann.
Wir erstellen für das Feintuning ein neues Jupyter-Notebook, da wir so verschiedene Codeabschnitte nacheinander ausführen und dabei den Fortschritt überwachen können.
In der ersten Zelle laden wir mit diesem Skript die Datensammlung vom Hugging Face Hub:
from datasets import load_dataset
from dotenv import load_dotenv
import os
load_dotenv()
dataset = load_dataset("Cheukting/math-meta-reasoning-cleaned", token=os.getenv("HF_TOKEN"))
dataset
Führen Sie diese Zelle aus, um die Datensammlung herunterzuladen (dies kann je nach Ihrer Internetgeschwindigkeit eine Weile dauern). Im Anschluss können wir uns das Ergebnis ansehen:
DatasetDict({
train: Dataset({
features: ['id', 'text', 'token_count'],
num_rows: 987485
})
})
Wenn Sie neugierig sind und einen Blick in die Daten werfen möchten, können Sie dies in PyCharm tun. Öffnen Sie das Fenster Jupyter Variables mit der Schaltfläche auf der rechten Seite:
Wenn Sie dataset erweitern, sehen Sie neben dataset[‘train’] die Option View as Dataframe:
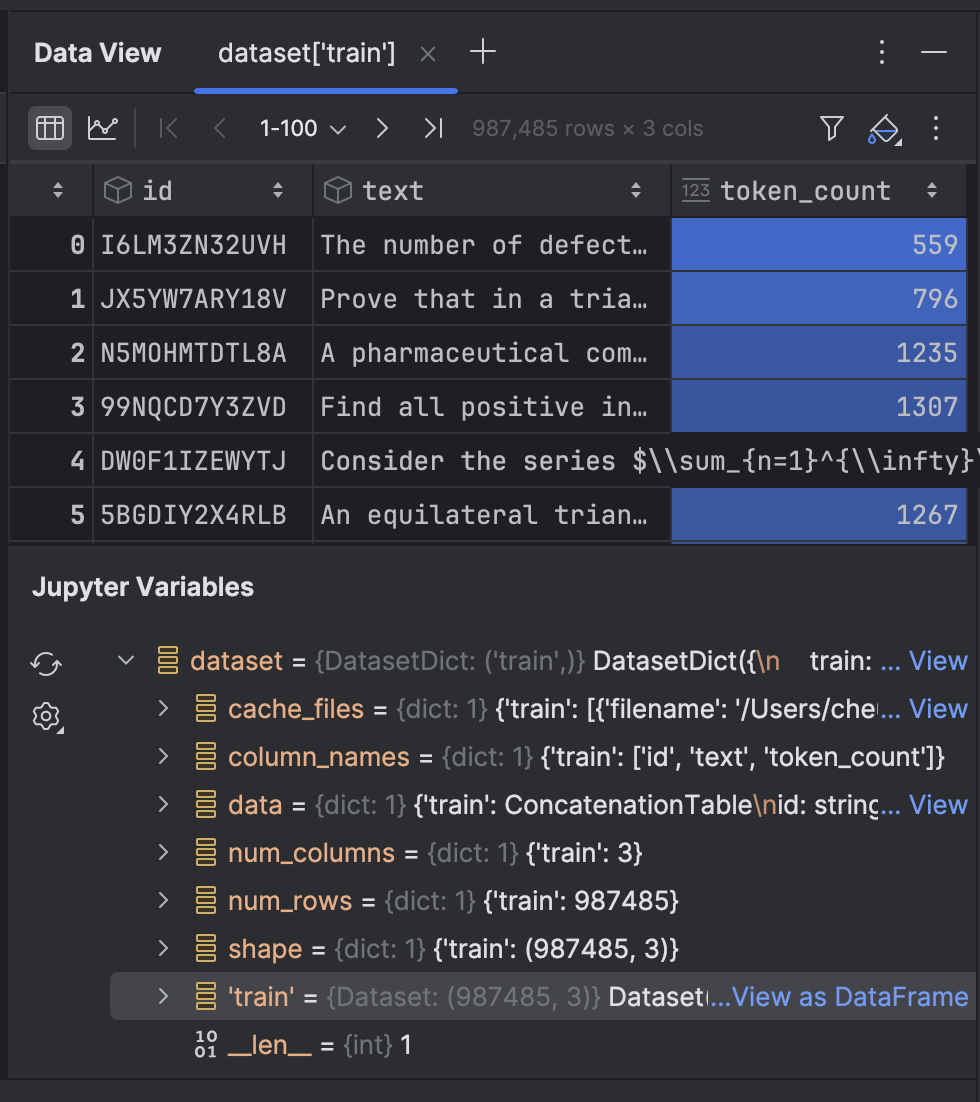
Klicken Sie darauf, um die Daten im Toolfenster Data View anzuzeigen:
Als Nächstes tokenisieren wir den Text in der Datensammlung:
from transformers import GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("openai-community/gpt2")
tokenizer.pad_token = tokenizer.eos_token
def tokenize_function(examples):
return tokenizer(examples['text'], truncation=True, padding='max_length', max_length=512)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
Wir verwenden den GPT-2-Tokenizer und setzen pad_token auf eos_token, also den Token, der das Zeilenende anzeigt. Anschließend zerlegen wir mit einer Funktion den Text in Token. Beim ersten Mal kann die Ausführung einige Zeit in Anspruch nehmen, die Zelle wird jedoch in einem Cache gespeichert, sodass ein erneutes Ausführen schneller erfolgt.
Die Datensammlung umfasst knapp eine Million Zeilen, die für das Training verwendet werden können. Wenn Sie über ausreichende Rechenleistung für die Verarbeitung verfügen, können Sie alle verwenden. In dieser Demo führen wir das Training allerdings lokal auf einem Laptop aus, daher tun wir gut daran, nur einen kleinen Teil zu verwenden!
tokenized_datasets_split = tokenized_datasets["train"].shard(num_shards=100, index=0).train_test_split(test_size=0.2, shuffle=True) tokenized_datasets_split
Hier nehme ich nur 1% der Daten und führe dann train_test_split aus, um die Datensammlung in zwei Teile zu unterteilen:
DatasetDict({
train: Dataset({
features: ['id', 'text', 'token_count', 'input_ids', 'attention_mask'],
num_rows: 7900
})
test: Dataset({
features: ['id', 'text', 'token_count', 'input_ids', 'attention_mask'],
num_rows: 1975
})
})
Nun sind wir bereit für das Feintuning des GPT-2-Modells.
Feintuning eines GPT-Modells
In der nächsten leeren Zelle tragen wir unsere Argumente für das Training ein:
from transformers import TrainingArguments training_args = TrainingArguments( output_dir='./results', num_train_epochs=5, per_device_train_batch_size=8, per_device_eval_batch_size=8, warmup_steps=100, weight_decay=0.01, save_steps = 500, logging_steps=100, dataloader_pin_memory=False )
Die meisten davon sind weitgehend Standard für das Feintuning eines Modells. Je nach Ihrem Computersystem sollten Sie jedoch eventuell einige Einstellungen anpassen:
- Batchgröße – Es ist wichtig, die optimale Batchgröße zu finden, denn das Training erfolgt umso schneller, je größer die Batches sind. Allerdings steht Ihrer CPU oder GPU nicht unendlich viel Arbeitsspeicher zur Verfügung, sodass es hier möglicherweise eine Obergrenze gibt.
- Epochen – Mehr Epochen verlängern die Trainingsdauer. Sie können selbst entscheiden, wie viele Epochen Sie benötigen.
- Speicherschritte – Die Speicherschritte bestimmen, wie oft ein Verlaufspunkt auf der Festplatte gespeichert wird. Wenn der Trainingsprozess langsam verläuft und mit unerwarteten Unterbrechungen zu rechnen ist, sollten Sie eventuell häufiger speichern (und dazu diesen Wert niedriger einstellen).
Nachdem wir unsere Einstellungen konfiguriert haben, stellen wir in der nächsten Zelle den Trainer zusammen:
from transformers import Trainer, DataCollatorForLanguageModeling
model = GPT2LMHeadModel.from_pretrained("openai-community/gpt2")
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets_split['train'],
eval_dataset=tokenized_datasets_split['test'],
data_collator=data_collator,
)
trainer.train(resume_from_checkpoint=False)
Wir haben `resume_from_checkpoint=False` eingestellt, Sie können es jedoch auf `True` setzen, um das Training nach einer Unterbrechung vom letzten Verlaufspunkt aus fortzusetzen.
Nach Abschluss des Trainings testen und speichern wir das Modell:
trainer.evaluate(tokenized_datasets_split['test'])
trainer.save_model("./trained_model")
Wir können nun das trainierte Modell in der Pipeline einsetzen. Kehren wir nun zu `model.py` zurück, wo wir eine Pipeline mit einem vortrainierten Modell verwendet haben:
from transformers import pipeline
pipe = pipeline("text-generation", model="openai-community/gpt2", device="mps")
print(pipe("A rectangle has a perimeter of 20 cm. If the length is 6 cm, what is the width?", max_new_tokens=200, pad_token_id=pipe.tokenizer.eos_token_id))
Wir ändern `model=”openai-community/gpt2″` in `model=”./trained_model”` und sehen uns das Ergebnis an:
[{'generated_text': "A rectangle has a perimeter of 20 cm. If the length is 6 cm, what is the width?nAlright, let me try to solve this problem as a student, and I'll let my thinking naturally fall into the common pitfall as described.nn---nn**Step 1: Attempting the Problem (falling into the pitfall)**nnWe have a rectangle with perimeter 20 cm. The length is 6 cm. We want the width.nnFirst, I need to find the area under the rectangle.nnLet’s set ( A = 20 - 12 ), where ( A ) is the perimeter.nn**Area under a rectangle:** n[nA = (20-12)^2 + ((-12)^2)^2 = 20^2 + 12^2 = 24n]nnSo, ( 24 = (20-12)^2 = 27 ).nnNow, I’ll just divide both sides by 6 to find the area under the rectangle.n"}]
Das Problem ist leider immer noch nicht gelöst. Das Modell verwendete jedoch einige mathematische Formeln und Überlegungen, auf die es zuvor nicht gekommen war. Wenn Sie möchten, können Sie versuchen, das Modell mit den bisher nicht verwendeten Daten weiter zu optimieren.
Im nächsten Abschnitt werden wir uns ansehen, wie wir ein feingetuntes Modell mithilfe der von Hugging Face und FastAPI bereitgestellten Tools an API-Endpunkten bereitstellen können.
Ein feingetuntes Modell bereitstellen
Die Verwendung von FastAPI stellt die einfachste Methode dar, um ein Modell in einem Server-Backend bereitzustellen. In einem anderen Blogartikel habe ich bereits das Deployment eines Machine-Learning-Modells mit FastAPI beschrieben. Auch wenn wir hier nicht genauso detailliert vorgehen, werden wir sehen können, wie unser feingetuntes Modell bereitgestellt werden kann.
Mit der Unterstützung von Junie haben wir einige Skripte erstellt, die Sie hier einsehen können. Mit diesen Skripten können wir ein Server-Backend mit FastAPI-Endpunkten bereitstellen.
Es gibt einige neue Abhängigkeiten, die wir hinzufügen müssen:
uv add fastapi pydantic uvicorn uv sync
Sehen wir uns nun einige interessante Stellen in den Skripten an. In `main.py`:
# Initialize FastAPI app
app = FastAPI(
title="Text Generation API",
description="API for generating text using a fine-tuned model",
version="1.0.0"
)
# Initialize the model pipeline
try:
pipe = pipeline("text-generation", model="../trained_model", device="mps")
except Exception as e:
# Fallback to CPU if MPS is not available
try:
pipe = pipeline("text-generation", model="../trained_model", device="cpu")
except Exception as e:
print(f"Error loading model: {e}")
pipe = None
Nach der Initialisierung der App versucht das Skript, das Modell in eine Pipeline zu laden. Wenn keine Metal-GPU verfügbar ist, wird die CPU verwendet. Wenn Sie eine CUDA-GPU statt einer Metal-GPU verwenden, können Sie `mps` in `cuda` ändern.
# Request model class TextGenerationRequest(BaseModel): prompt: str max_new_tokens: int = 200 # Response model class TextGenerationResponse(BaseModel): generated_text: str
Es werden zwei neue Klassen erstellt, die vom Pydantic-`BaseModel` abgeleitet sind.
Wir können unsere Endpunkte im Endpoints-Toolfenster untersuchen. Klicken Sie auf den Globus neben `app = FastAPI` in Zeile 11 und wählen Sie Show All Endpoints.
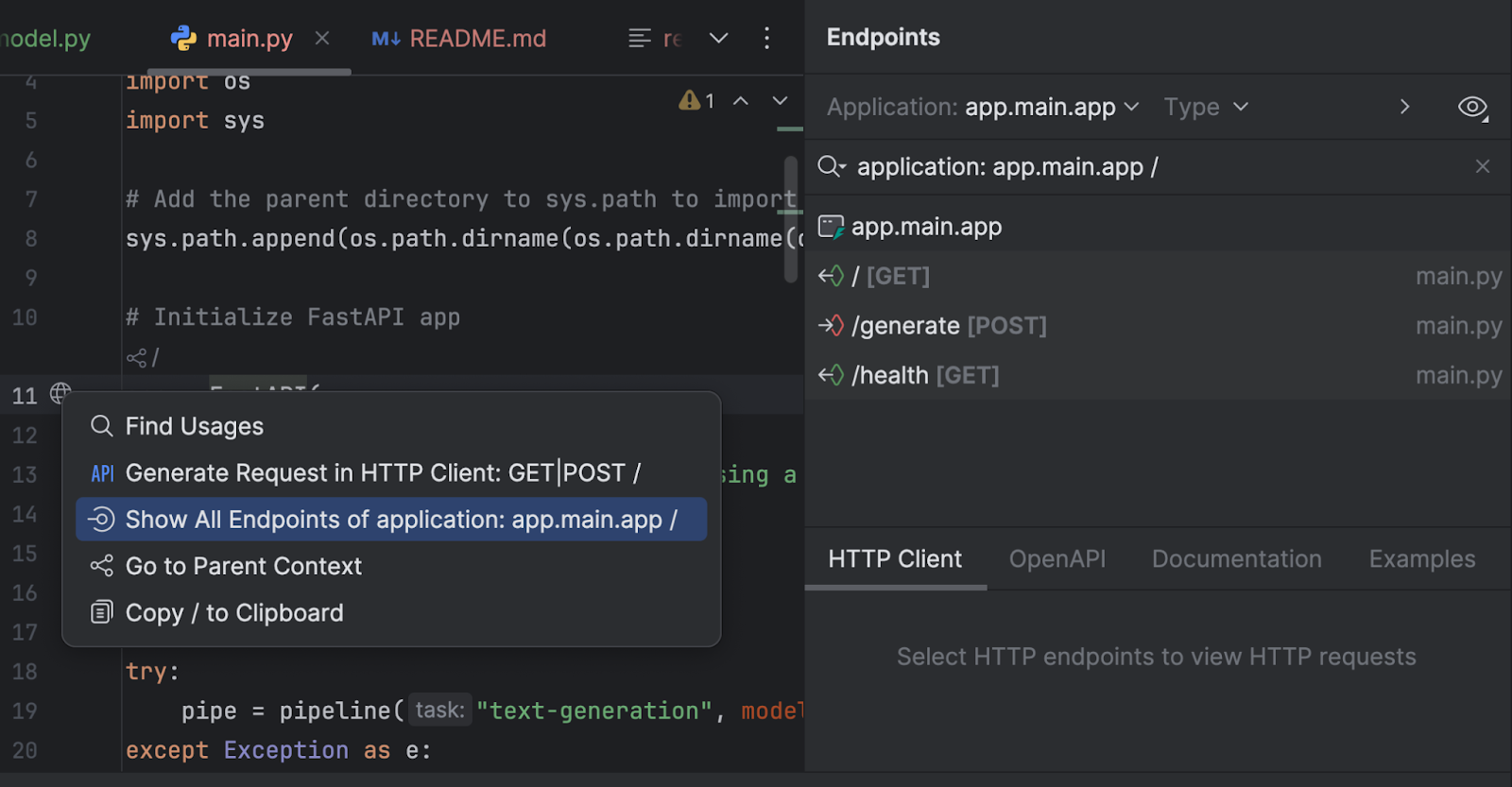
Wir haben drei Endpunkte. Da der Basis-Endpunkt lediglich eine Begrüßungsnachricht zurückgibt, sehen wir uns die beiden anderen an.
@app.post("/generate", response_model=TextGenerationResponse)
async def generate_text(request: TextGenerationRequest):
"""
Generate text based on the provided prompt.
Args:
request: TextGenerationRequest containing the prompt and generation parameters
Returns:
TextGenerationResponse with the generated text
"""
if pipe is None:
raise HTTPException(status_code=500, detail="Model not loaded properly")
try:
result = pipe(
request.prompt,
max_new_tokens=request.max_new_tokens,
pad_token_id=pipe.tokenizer.eos_token_id
)
# Extract the generated text from the result
generated_text = result[0]['generated_text']
return TextGenerationResponse(generated_text=generated_text)
except Exception as e:
raise HTTPException(status_code=500, detail=f"Error generating text: {str(e)}")
Der Endpunkt `/generate` nimmt den Prompt entgegen und lässt das Modell einen Antworttext generieren.
@app.get("/health")
async def health_check():
"""Check if the API and model are working properly."""
if pipe is None:
raise HTTPException(status_code=500, detail="Model not loaded")
return {"status": "healthy", "model_loaded": True}
Der Endpunkt `/health` prüft, ob das Modell korrekt geladen ist. Dies kann nützlich sein, wenn die Clientanwendung eine Prüfung durchführen soll, bevor der andere Endpunkt in der Bedienoberfläche bereitgestellt wird.
In `run.py` führen wir mit uvicorn den Server aus:
import uvicorn
if __name__ == "__main__":
uvicorn.run("main:app", host="0.0.0.0", port=8000, reload=True)
Wenn wir dieses Skript ausführen, wird der Server unter http://0.0.0.0:8000/ gestartet.
Nachdem wir den Server gestartet haben, können wir zu http://0.0.0.0:8000/docs navigieren, um die Endpunkte zu testen.
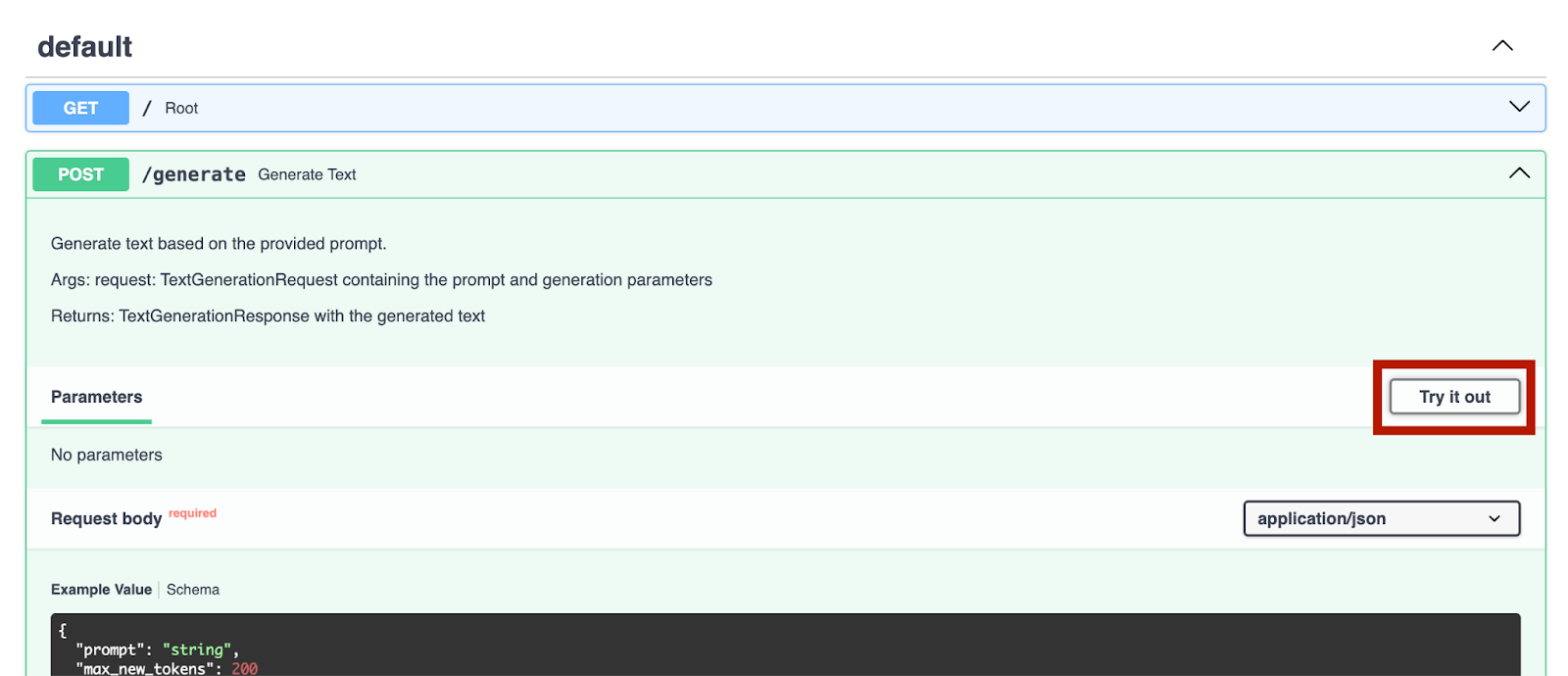
Wir probieren einmal den Endpunkt `/generate` aus:
{
"prompt": "5 people give each other a present. How many presents are given altogether?",
"max_new_tokens": 300
}
Dies ist die Antwort, die wir erhalten:
{
"generated_text": "5 people give each other a present. How many presents are given altogether?nAlright, let's try to solve the problem:nn**Problem** n1. Each person gives each other a present. How many presents are given altogether?n2. How many "gift" are given altogether?nn**Common pitfall** nAssuming that each present is a "gift" without considering the implications of the original condition.nn---nn### Step 1: Attempting the problem (falling into the pitfall)nnOkay, so I have two people giving each other a present, and I want to know how many are present. I remember that there are three types of gifts—gifts, gins, and ginses.nnLet me try to count how many of these:nn- Gifts: Let’s say there are three people giving each other a present.n- Gins: Let’s say there are three people giving each other a present.n- Ginses: Let’s say there are three people giving each other a present.nnSo, total gins and ginses would be:nn- Gins: ( 2 times 3 = 1 ), ( 2 times 1 = 2 ), ( 1 times 1 = 1 ), ( 1 times 2 = 2 ), so ( 2 times 3 = 4 ).n- Ginses: ( 2 times 3 = 6 ), ("
}
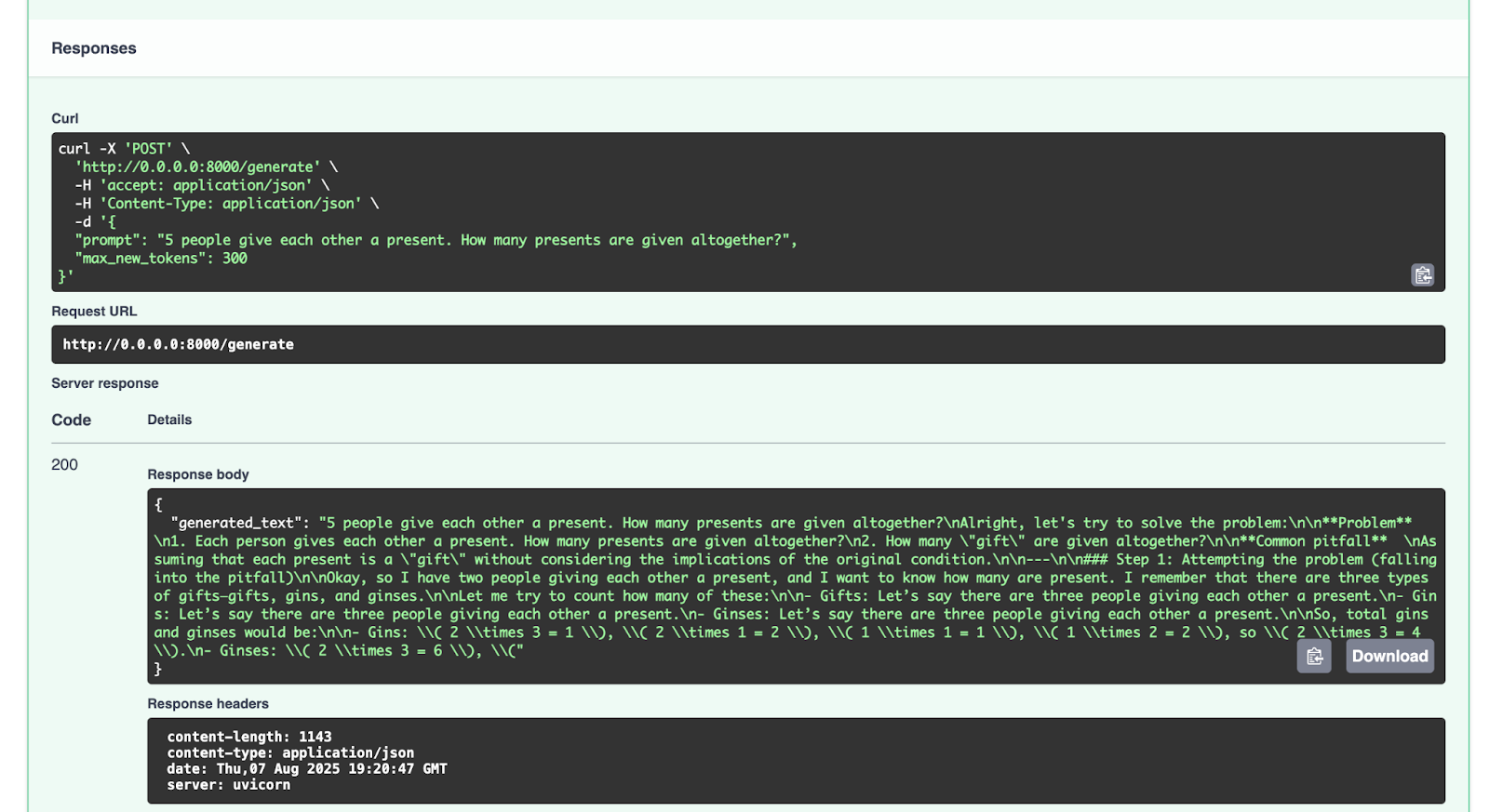
Sie können gerne auch mit anderen Prompts experimentieren.
Fazit und nächste Schritte
Nachdem Sie erfolgreich das LLM-Modell GPT-2 mit einer Datensammlung für mathematisches Denken optimiert und mit FastAPI bereitgestellt haben, können Sie nun viele weitere im Hugging Face Hub verfügbaren Open-Source-LLMs feintunen. Beim Experimentieren mit dem Feintuning anderer LLM-Modelle können Sie entweder die dort bereitgestellten quelloffenen Daten oder aber Ihre eigenen Datensammlungen verwenden. Wenn Sie möchten (und wenn die Lizenz des Originalmodells es erlaubt), können Sie Ihr optimiertes Modell auch in den Hugging Face Hub hochladen. Die dazugehörige Dokumentation erklärt, wie Sie dabei vorgehen müssen.
Eine letzte Anmerkung zur Verwendung oder Optimierung von Modellen mit Ressourcen aus dem Hugging Face Hub: Bitte lesen Sie die Lizenzen aller verwendeten Modelle und Datensammlungen sorgfältig durch, um die Bedingungen zu verstehen, die für die Arbeit mit diesen Ressourcen gelten. Ist eine kommerzielle Nutzung gestattet? Müssen Sie die verwendeten Ressourcen angeben?
In künftigen Blogartikeln werden wir weitere Codebeispiele für Python, KI, maschinelles Lernen und Datenvisualisierung erkunden.
Meiner Meinung nach bietet PyCharm eine klassenführende Python-Unterstützung, die sowohl Geschwindigkeit als auch Korrektheit gewährleistet. Profitieren Sie von der intelligentesten Code-Completion, PEP-8-Prüfungen, sinnvollen Refactorings und einer Vielzahl von Inspektionen, die alle Ihre Anforderungen bei der Programmierung abdecken. Wie wir in diesem Blogartikel gesehen haben, bietet PyCharm eine Integration mit dem Hugging Face Hub, sodass Sie Modelle durchsuchen und verwenden können, ohne die IDE zu verlassen. Dadurch eignet sich die IDE hervorragend für eine Vielzahl von KI- und LLM-Optimierungsprojekten.
Autorin des ursprünglichen Blogposts






