

JetBrains AI
Supercharge your tools with AI-powered features inside many JetBrains products
Kotlin으로 AI 에이전트 구축하기 – 5부: 에이전트에게 잊는 법 가르치기

이전 시리즈:
- Kotlin으로 AI 에이전트 구축하기 – 1부: 최소 구성의 코딩 에이전트
- Kotlin으로 AI 에이전트 구축하기 – 2부: 도구에 대한 심층 탐구
- Kotlin으로 AI 에이전트 구축하기 – 3부: 관찰 가능성 확보
- Kotlin으로 AI 에이전트 구축하기 – 4부: 위임과 서브 에이전트
에이전트는 결국 컨텍스트 한도에 도달합니다. 컨텍스트가 부족해지면 시스템이 충돌하며, 작업 도중 모든 데이터를 잃게 됩니다.
저희는 1부부터 GPT-5 Codex를 활용해 왔으며 이 모델은 SWE-bench Verified에서 0.58점을 기록했습니다. 다음으로 Claude Sonnet 4.5를 사용해 보았더니 이 모델은 0.6점을 기록했으며 대부분의 작업에서 더 빠른 속도를 보여주었습니다. 하지만 문제가 복잡하면 Claude의 200K 컨텍스트 창이 금방 찼습니다.
여러분은 성능 향상, 비용 절감 또는 로컬 실행을 위해 모델을 교체해야 하는 상황을 겪게 될 수 있습니다. 때로는 메모리가 비싸서 로컬 모델에서 더 작은 컨텍스트 창을 사용해야 할 수도 있습니다. 설혹 가장 큰 컨텍스트 창을 사용한다 해도 복잡하고 긴 작업에서는 답이 없습니다. 컨텍스트 용량을 계속 구매할 수도 없는 노릇입니다.
문제는 에이전트가 모든 파일, 명령어 출력, 검색 결과, 사용자 메시지 등 모든 데이터를 보관한다는 점에 있습니다. 그렇게 되면 결국 공간이 남아나지 않습니다.
그래서 압축이 필요합니다. 여유 공간이 없다고 해서 오래된 메시지부터 무작정 지워버리는 단순한 방식이 아닙니다. 다른 개발자에게 업무를 인계하는 상황을 떠올려 보세요. 모든 작업 기록을 넘겨주지는 않을 것입니다. 대신 최종 목표가 무엇인지, 어떤 파일을 수정했는지, 무엇이 성공하고 실패했는지를 전달할 겁니다. 이것이 바로 스마트한 압축 방식입니다. 작업을 이어가는 데 필요한 컨텍스트는 유지하고 장황한 기록은 과감히 덜어내는 것이죠.
이제 Koog에서 이를 어떻게 구현하는지 알아보겠습니다. 먼저 strategy = singleRunStrategy()가 1부부터 어떤 역할을 해왔는지 이해해야 합니다. 여기에서 전략이 어떻게 에이전트의 루프를 제어하는지, 그리고 여러분만의 워크플로를 만들기 위해 이를 어떻게 수정할 수 있는지 확인할 수 있습니다. singleRunStrategy()를 살펴본 뒤, 자동으로 압축을 수행하는 버전을 직접 구축해 보겠습니다.
전략 줄의 기능
이전 단계에서는 코딩 에이전트를 구축했습니다. 이제 다음 코드를 사용하여 에이전트에게 필요한 도구를 부여할 차례입니다.
strategy = singleRunStrategy()
여기서 전략이란 에이전트 루프를 실행하는 코드를 의미합니다. 모든 전략에는 LLM 호출, 도구 실행, 결과 반환 및 반복이라는 핵심 요소가 있습니다. 하지만 전략마다 중단 시점과 반복 사이의 동작 방식은 다릅니다.
singleRunStrategy()는 구현 가능한 가장 단순한 버전입니다. 이 전략은 LLM이 도구 호출을 반환하는 한 반복을 계속합니다. 다시 말해, LLM 호출 → 도구 호출 반환? → 실행 → 다시 호출 → 텍스트 반환?의 과정을 거칩니다. → 완료되었습니다.
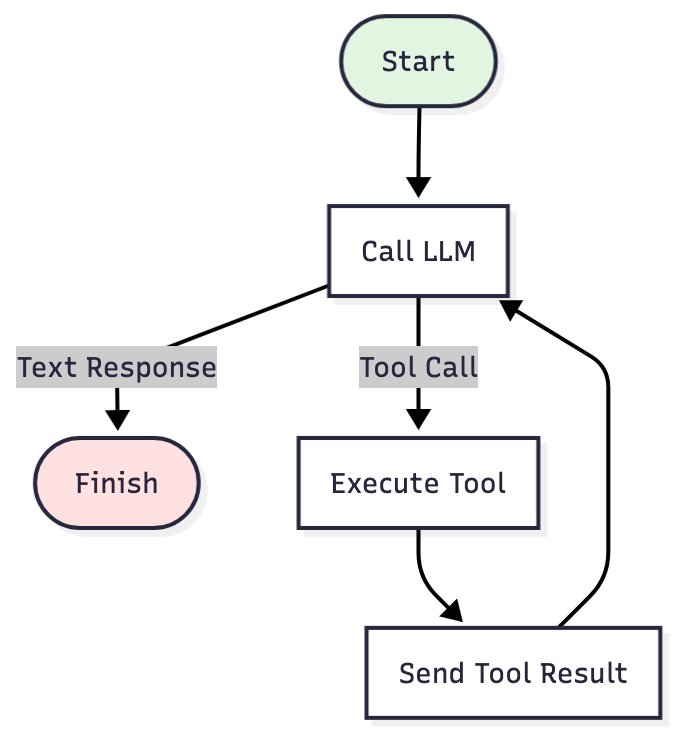
단순한 작업에서는 이 방식이 문제없이 작동합니다. 하지만 복잡한 문제일수록 기록은 끊임없이 쌓여갑니다. 모든 명령어 출력, 파일 읽기 결과, 검색 결과가 컨텍스트에 그대로 남게 됩니다. 결국 한계치에 도달하여 작업 도중 시스템이 충돌하게 됩니다.
우리에게 지금 필요한 것은 동일한 루프를 실행하되, 기록 크기를 확인하고 너무 커지면 압축을 수행하는 전략입니다.
압축 기능 추가
기존의 방식은 다음과 같습니다.
strategy = singleRunStrategy()
새로운 방식은 다음과 같습니다.
strategy = singleRunStrategyWithHistoryCompression()
전체적인 루프는 동일하게 유지되지만, 이제 Execute Tool과 Send Tool 사이에 체크포인트가 추가됩니다. 도구를 실행할 때마다 전략은 다음과 같은 질문을 던집니다.
- 확인: 현재 기록이 임곗값을 초과했는가?
- 초과한 경우, 압축: 핵심적인 사실만 추출합니다. 나머지는 삭제합니다.
- 초과하지 않은 경우, 작업을 계속해서 진행합니다.
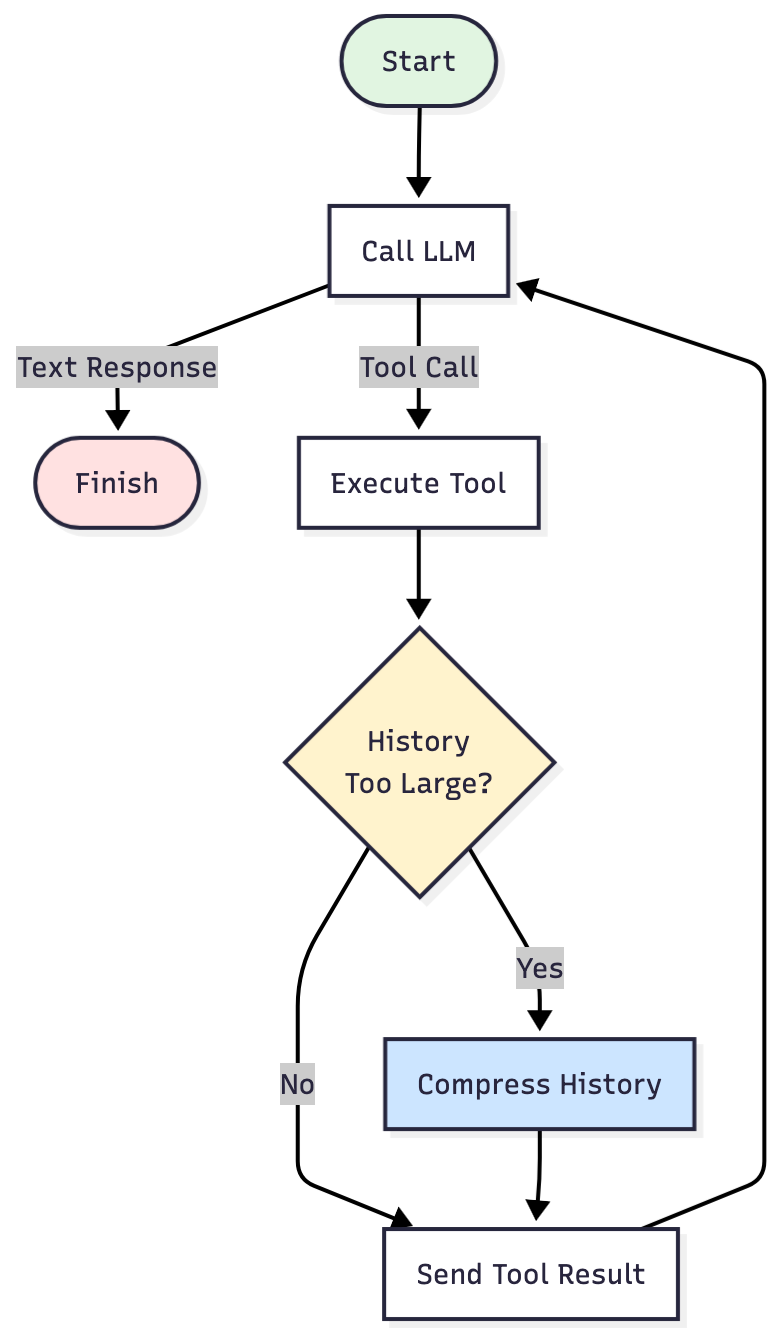
이 체크포인트 덕분에 에이전트는 제한된 토큰 예산 내에서 ‘컨텍스트 창 초과’ 오류를 피하며 장시간 실행되는 작업을 완료할 수 있습니다.
하지만 체크포인트는 직접 구성해야 합니다. 전략은 기록이 얼마나 커졌을 때 압축할지, 작업에 중요한 기록이 무엇인지 추측하지 못합니다. 따라서 에이전트에게 언제 압축할지, 무엇을 남길지 두 가지를 알려줘야 합니다.
압축 시점
먼저 압축 실행 전에 허용할 메시지 수나 문자 수의 임곗값을 설정해야 합니다.
val CODE_AGENT_HISTORY_TOO_BIG = { prompt ->
prompt.messages.size > 200 || prompt.messages.sumOf { it.content.length } > 200_000}
왜 이 수치를 사용할까요? 저희는 어디에서 오류가 발생하는지 관찰하며 다양한 임곗값으로 실험해 보았습니다.

이 에이전트는 22만 개 토큰에 도달했을 때 충돌이 발생했습니다. Claude의 한도는 20만 개 토큰입니다. 따라서 해당 지점에 도달하기 전에 압축을 수행해야 했습니다.
200개의 메시지 또는 20만 개의 문자 중 먼저 도달하는 시점에 압축하도록 설정했습니다. 여기서 코드는 토큰이 아닌 문자 수를 측정한다는 점에 유의하세요. 이 둘은 서로 다른 단위지만, 임곗값을 불필요한 압축을 피할 수 있을 만큼 높고 한도 초과를 방지할 수 있을 정도로 낮게 설정하면 토큰 한도를 지킬 수 있습니다.
물론 이 수치가 정답은 아닙니다. 여러분의 에이전트가 한도에 더 빨리 도달한다면 임곗값을 낮추어야 합니다. 해당 임곗값을 넘어도 여전히 작업이 진행되나요? 임곗값을 높여보세요. 어떤 수치를 선택할지는 파일 크기, 메시지 길이, 도구 출력의 상세 수준, 작업의 복잡도 등 사용 사례에 따라 달라집니다. 실험을 통해 최적의 값을 찾아보세요.
남길 기록
이제 압축이 실행되는 시점을 설정했으니 무엇을 남길지 결정할 차례입니다.
두 가지 옵션이 있습니다. 무엇이 중요한지 LLM의 판단에 맡기거나, 무엇을 추출할지 LLM에 정확히 지시하는 것입니다.
옵션 1: LLM의 요약 기능 신뢰
LLM은 WholeHistory를 사용하여 무엇이 중요한지 스스로 결정합니다.
compressionStrategy = WholeHistory
압축이 트리거되면, Koog는 LLM에 전체 대화 기록에 대한 TL;DR 요약 생성을 요청합니다.
압축 전:
- 시스템 프롬프트, 사용자 메시지, 어시스턴트 응답, 도구 호출 및 결과 등 임곗값까지 쌓인 모든 메시지가 포함되어 있습니다.
압축 후:
- 시스템 프롬프트(보존됨).
- 첫 번째 사용자 메시지(에이전트가 원래 목표를 기억할 수 있도록 보존됨).
- LLM이 작성한 한 개의 TL;DR 요약 메시지.
장단점: 이 방식은 단순하고 빠르지만, 무엇이 중요한지에 대한 판단을 LLM에 의존하게 됩니다. LLM은 정확히 필요한 세부 정보를 남기기도 하지만 중요한 정보를 삭제하기도 합니다.
옵션 2: 추출할 정보를 LLM에 정확히 지시
모든 내용을 요약하라고 시키는 대신, RetrieveFactsFromHistory를 사용하여 추출해야 할 기록을 정확히 명시합니다.
compressionStrategy = RetrieveFactsFromHistory( Concept(...), Concept(...), ... )
작동 방식:
에이전트가 반드시 기억해야 할 작업 관련 특정 질문을 담은 Concept 객체를 정의해 줍니다. 압축이 실행되면 Koog는 Concept마다 하나의 LLM 호출을 수행합니다. 이때 전체 대화 기록을 매번 보내며 해당 질문 하나에 대해서만 질문합니다.
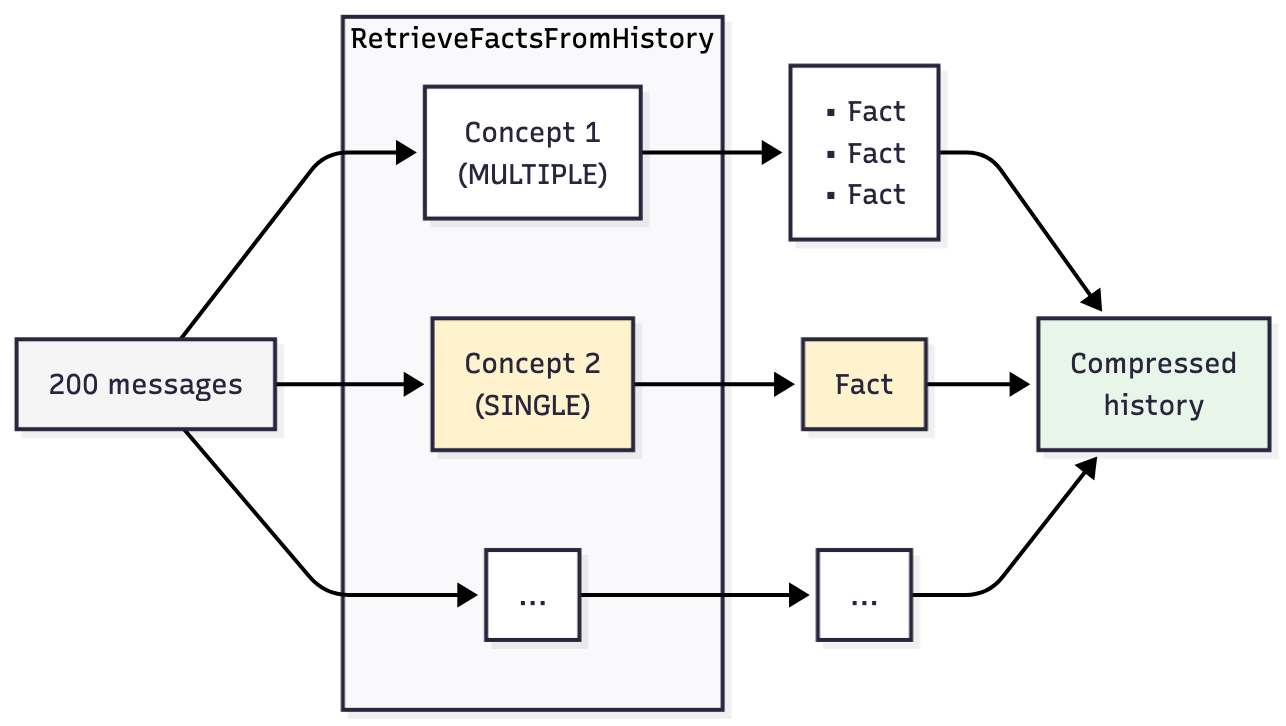
왜 호출을 여러 번으로 나눌까요? LLM은 여러 질문을 한꺼번에 던질 때보다 하나씩 질문할 때 더 정확한 답변을 내놓기 때문입니다. 이는 테스트를 통해 확인되었습니다. 8개의 Concept를 하나의 프롬프트에 묶었을 때, 일부 답변은 모호하거나 불완전하게 돌아왔습니다. 질문을 한 번에 하나씩 던지면 각 응답의 신뢰도가 높아집니다.
Concept 정의
각 Concept 인스턴스는 세 부분으로 구성됩니다.
keyword: 로그 라벨description: LLM이 답변해야 할 실제 질문 또는 지침factType: 필요한 답변의 형식MULTIPLE: 목록의 경우SINGLE: 단일 값의 경우
Concept(
keyword = "project-structure",
description = "What is the project structure?",
factType = FactType.MULTIPLE
)
적합한 Concept 선택
코딩 에이전트를 설계할 때 핵심적인 질문은 바로 이것입니다. “어떤 정보를 잃어버렸을 때, 에이전트가 작업을 처음부터 다시 시작해야만 하는가?”
압축 과정에서 중요한 정보가 삭제되면 다음과 같은 문제가 발생합니다.
- 에이전트가 이미 열어본 파일을 마치 처음 보는 것처럼 다시 엽니다.
- 이미 있는 테스트를 다시 작성합니다.
- 이렇게 되면 사용자가 원래 지시한 작업에서 점차 벗어나게 됩니다.
각각의 실패는 압축에서 보존해야 할 기록이 무엇인지 보여줍니다.
- 파일 재탐색 →
project-structureConcept가 필요합니다. - 완료된 작업 반복 →
important-achievementsConcept가 필요합니다. - 방향 상실 →
agent-goalConcept가 필요합니다.
우리 코딩 에이전트의 Concept
SWE-bench-Verified에서 테스트를 진행했을 때, 최종적으로 8개의 Concept를 사용했습니다. 그중 세 가지는 다음과 같습니다.
val CODE_AGENT_COMPRESSION_STRATEGY = RetrieveFactsFromHistory(
Concept(
"project-structure",
"What is the structure of this project?",
FactType.MULTIPLE
),
Concept(
"important-achievements",
"What has been achieved during the execution of this current agent?",
FactType.MULTIPLE
),
Concept(
"agent-goal",
"What is the primary goal or task the agent is trying to accomplish in this session?",
FactType.SINGLE
),
...
여러분의 에이전트에는 이와 다른 Concept가 필요할 수도 있습니다. 목적은 이 목록을 복사하는 것이 아니라, 여러분의 에이전트가 계속 작업하는 데 필요한 상태가 무엇인지 파악하고 그 정보를 보존할 Concept를 정의하는 것입니다.
8개 Concept의 전체 구현은 GitHub 저장소에서 확인할 수 있습니다.
사용할 모델
서브 에이전트(4부 참조)와 마찬가지로, 프로세스의 단계마다 서로 다른 모델을 사용할 수 있습니다. retrievalModel 매개변수를 사용하면 기록 압축을 처리할 LLM을 지정할 수 있습니다. 이 매개변수는 선택 사항이며, 지정하지 않으면 에이전트의 메인 모델이 압축에 사용됩니다.
retrievalModel = OpenAIModels.Chat.GPT4_1Mini
다음은 코딩 에이전트 전략을 위한 전체 구성입니다.
strategy = singleRunStrategyWithHistoryCompression(
config = HistoryCompressionConfig(
isHistoryTooBig = CODE_AGENT_HISTORY_TOO_BIG,
compressionStrategy = CODE_AGENT_COMPRESSION_STRATEGY,
retrievalModel = OpenAIModels.Chat.GPT4_1Mini
)
)
세 가지 매개변수는 언제 압축할지(isHistoryTooBig), 무엇을 남길지(compressionStrategy), 어떤 모델이 작업을 수행할지(retrievalModel)입니다.
결론
이제 에이전트는 컨텍스트 제한에 걸리지 않고 더 긴 작업을 수행할 수 있습니다. 드디어 압축 문제가 해결되었습니다. 공간이 부족해지면 충돌이 발생하지 않고 에이전트가 기록을 압축합니다. 장황한 출력은 삭제하고 중요한 결정과 결과물만 유지하며, 주어진 토큰 예산 내에서 작업을 이어갑니다.
1부에서 기본적인 코딩 에이전트로 이 시리즈를 시작했습니다. 그 이후, 도구, 관찰 가능성, 서브 에이전트, 기록 압축을 추가했습니다. 이 5개 글은 실제 모델의 제약 조건 내에서 작동하는 실무 수준의 Kotlin 기반 AI 에이전트를 구축하는 데 필요한 정보를 제공합니다.
이러한 패턴을 계속해서 구축하고 연습하고 싶다면, 에이전트가 여러 차례에 걸쳐 의사결정을 내리는 방식이나 복잡한 문제를 세분화하는 방법에 관한 계획과 추론을 탐구해 보시길 추천합니다. 시리즈에서 이 내용을 다루지는 않았지만, 지금까지 글을 잘 따라왔다면 좋은 연습 주제가 될 것입니다.
전체 코드는 GitHub에서 확인할 수 있습니다. 문제가 발생하면 댓글을 남겨 주세요. 최선을 다해 도와 드리겠습니다 ?
게시물 원문 작성자



