
JetBrains Platform
Plugin and extension development for JetBrains products.
Speeding up interactive rebase in JetBrains IDEs

Introduction
Git integration in JetBrains IDEs has been evolving for more than fifteen years, and throughout that time, we followed one guiding principle: At the lowest level, we simply run porcelain Git commands, parse their output, and avoid doing anything Git itself would not do. All user scenarios and UI are built on top of that. This approach kept the integration reliable and made it much less likely that the IDE would corrupt the repository state.
Over time, Git grew more complex, repositories grew larger, and some operations became noticeably slower. By then, the pattern was hard to miss. We saw more community projects focused on Git performance, users kept reporting slow command execution, and we could reproduce the issue ourselves. Even rewording a single commit in the IntelliJ IDEA monorepo could take tens of seconds, depending on the machine and OS.
Interactive rebase was one of the clearest pain points, along with several IDE actions built on top of it. So we decided to focus on low-level optimizations there and turn the work into a dedicated internship project.
Interactive rebase: A technical deep dive
To see where those seconds went, we need to look at what Git actually does during an interactive rebase.
Internally, Git has three main kinds of objects, stored as files in the .git/objects directory: blobs, trees, and commits. Every object is identified by a unique 20-byte SHA-1 hash.
- A blob simply contains the contents of a file.
- A tree is a recursive object that corresponds to a directory. It can contain individual files, represented as an entry with a file name, mode, and the respective blob’s hash, as well as subdirectories, represented by the names and hashes of other trees. Because an object’s hash is unique, Git can reuse files and directories when they are identical.
- A commit is essentially a tree with metadata. It contains the hash of its parent commit(s), author and committer information with timestamps, and a commit message. Each commit represents a snapshot of the entire directory; the diff between a commit and its parent is computed by comparing their two trees.
The index is a map linking file names to blob objects, sorted by file name. It acts as a scratchpad for Git operations. For example, during a merge, the index expands to hold three entries for a single conflicted file. It keeps these entries unmerged so that Git can create conflict markers in the working directory. After you resolve the conflicts, running git add marks the entries as merged. Following these operations, Git writes a new tree object from the current index using git write-tree.
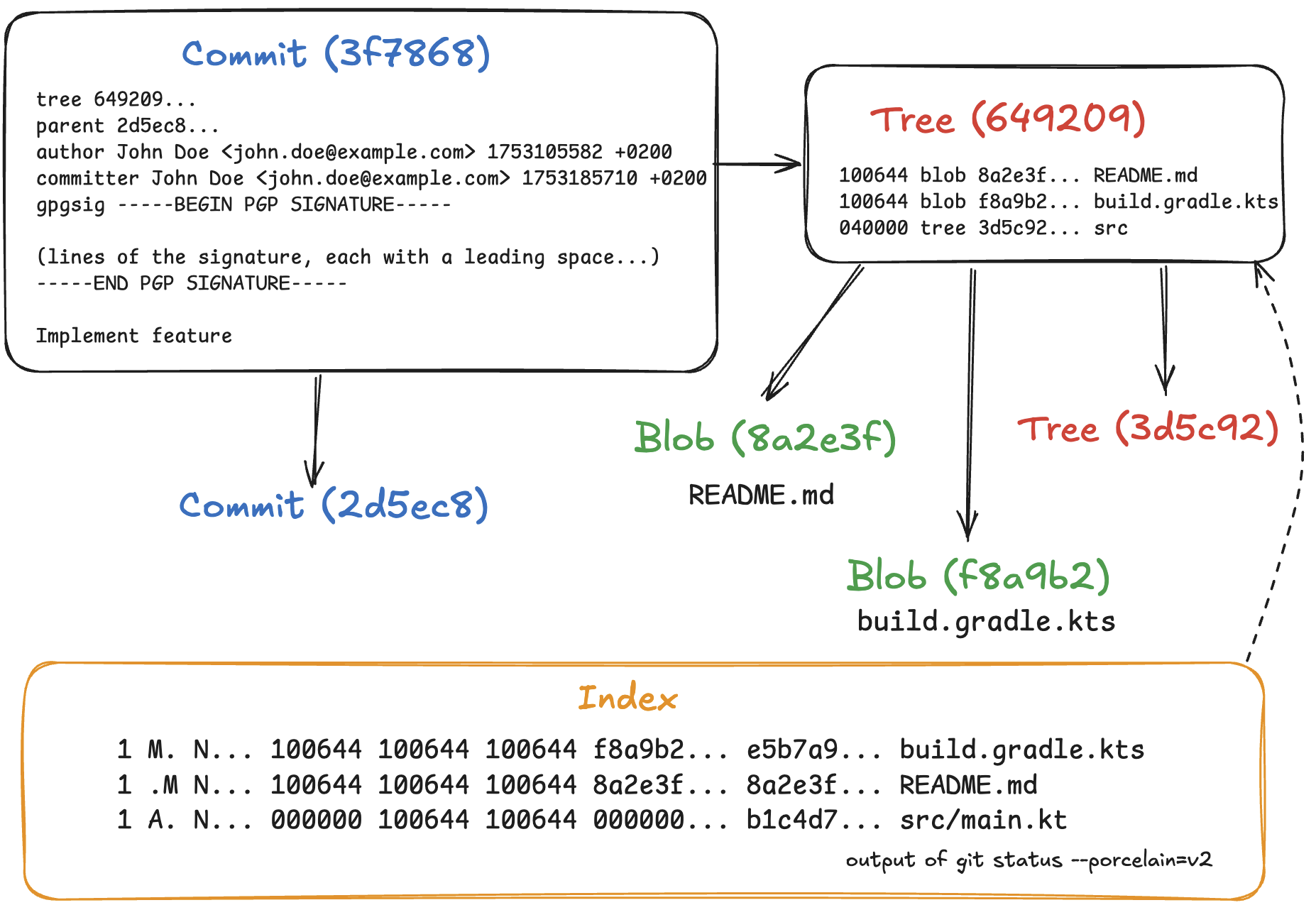
Now, let’s consider how an interactive rebase is performed. To build a sequence of commits according to the git-rebase-todo file, Git checks them out sequentially, updates the working tree, and populates the index so that it can create a tree object from it. This can impact performance. However, in some scenarios, we can construct these trees without touching the index.
In-memory rebase optimization: How it works
The optimization for Edit Commit Message… is the simplest case. If you look at the sequence of commits from the selected one up to the top of the branch, the underlying tree hashes do not change during this operation. For the selected commit, we only need to change the commit message and committer information. Then, for every commit after that, we just rebuild the chain by updating the parent commit and computing a new hash.
Git provides low-level plumbing commands for managing Git objects. Using git cat-file, we can extract and parse the body of an object. We can create a new commit object by passing a tree hash and metadata to git commit-tree. Once the whole sequence has been rebuilt, we can use git update-ref to atomically update the branch reference.
The git merge-tree command can perform a three-way merge directly in memory. It takes the tree hashes and returns the resulting tree, failing if there is a merge conflict. So, for rebases that modify trees but do not cause conflicts, we can still avoid touching the working tree and index.
The same idea extends to a general interactive rebase. If we know the rebase plan, such as reordering, dropping, squashing, or renaming commits, we can build the new sequence in memory using the same commands.
That is the approach we implemented. When you perform commit-editing operations, the IDE first tries a fast in-memory path. If it runs into a merge conflict, it silently falls back to a regular Git rebase and stops so you can resolve the conflicts. Otherwise, it updates the branch reference atomically.
We applied the same optimization to other operations. For example, in the Git Log, when you select a commit, the Changed Files pane appears on the right. Here, you can select a subset of files and click Extract Selected Changes to Separate Commit… to split one commit into two and never cause a merge conflict. It works by recursively building a split tree in memory and omitting the changes at the specified paths.
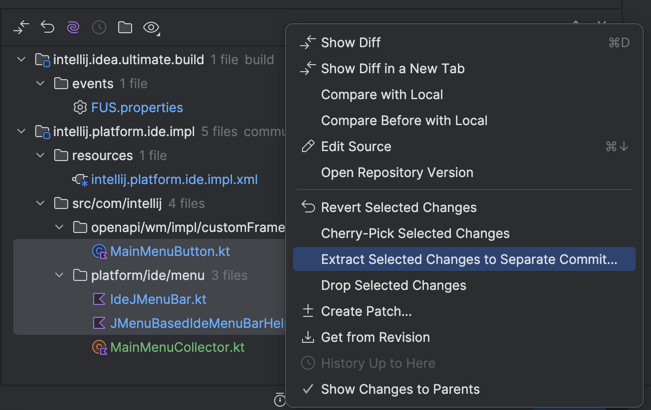
Upstream Git is moving in a similar direction as well. The git replay command performs a fast in-memory rebase, but it is still experimental and does not support interactive rebase or GPG signing.
Results
On the IntelliJ monorepo, the average execution time of interactive rebase dropped from tens of seconds to just a few seconds. The exact numbers varied across operating systems, but the overall improvement was consistent.
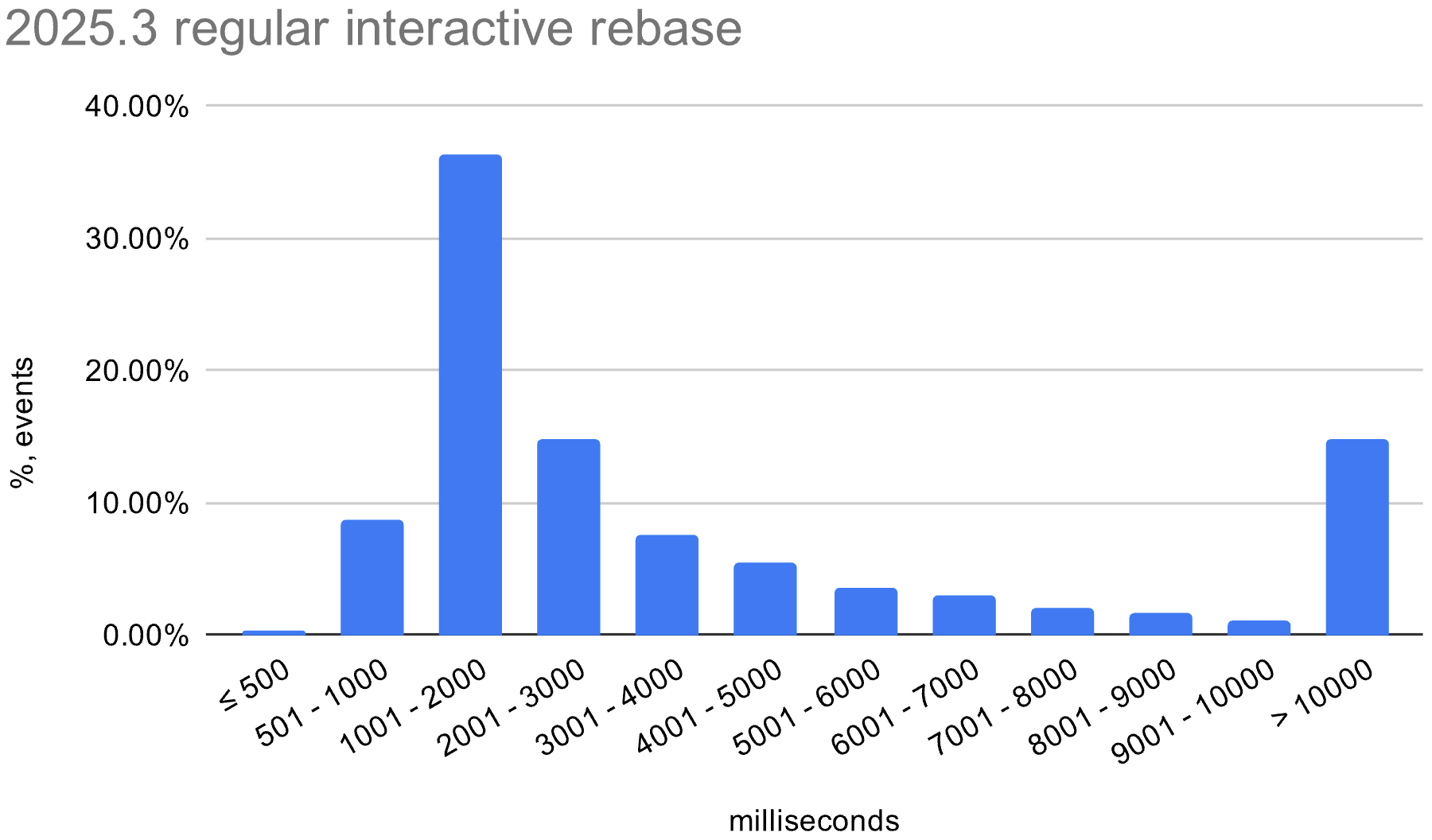
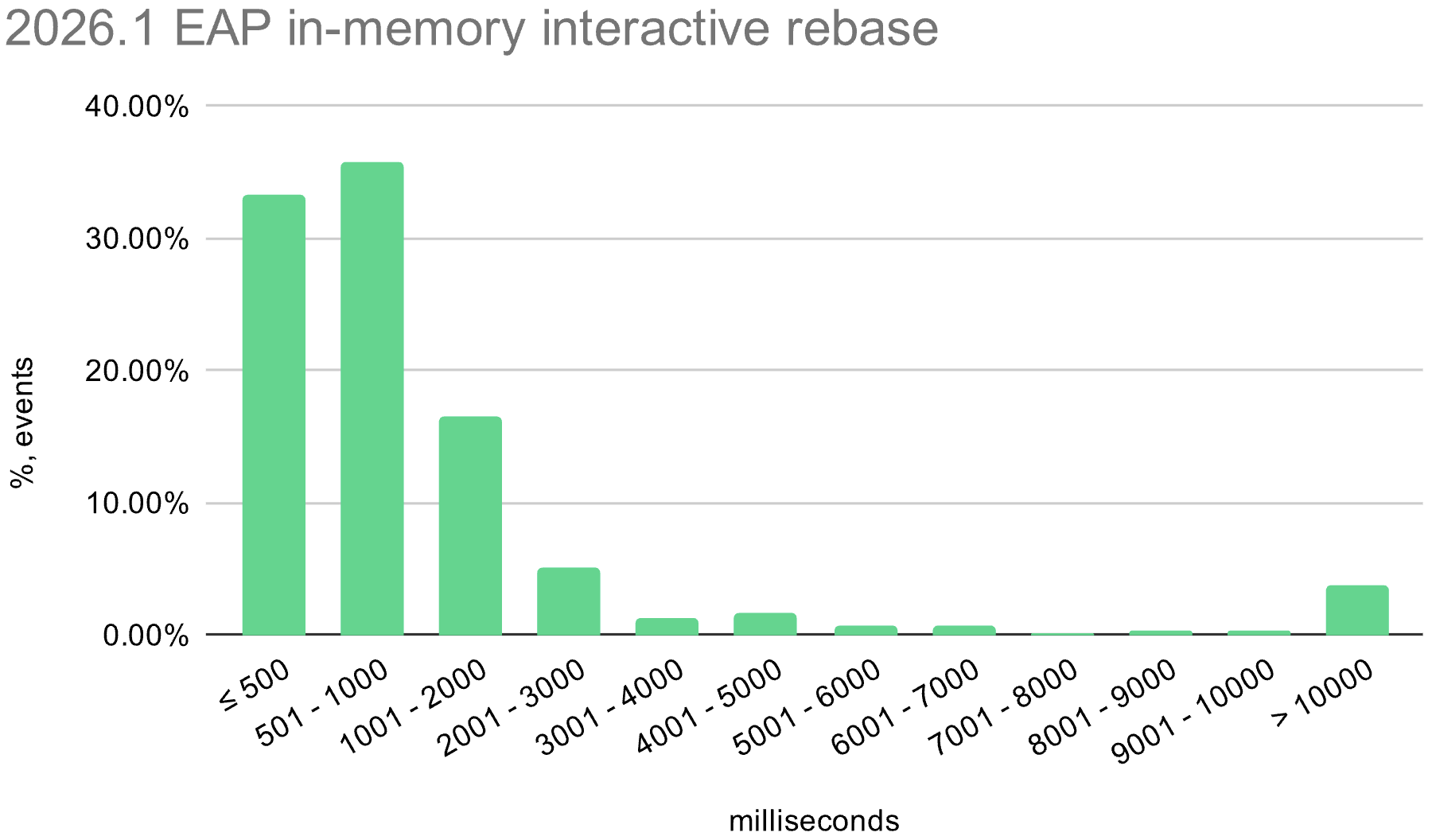
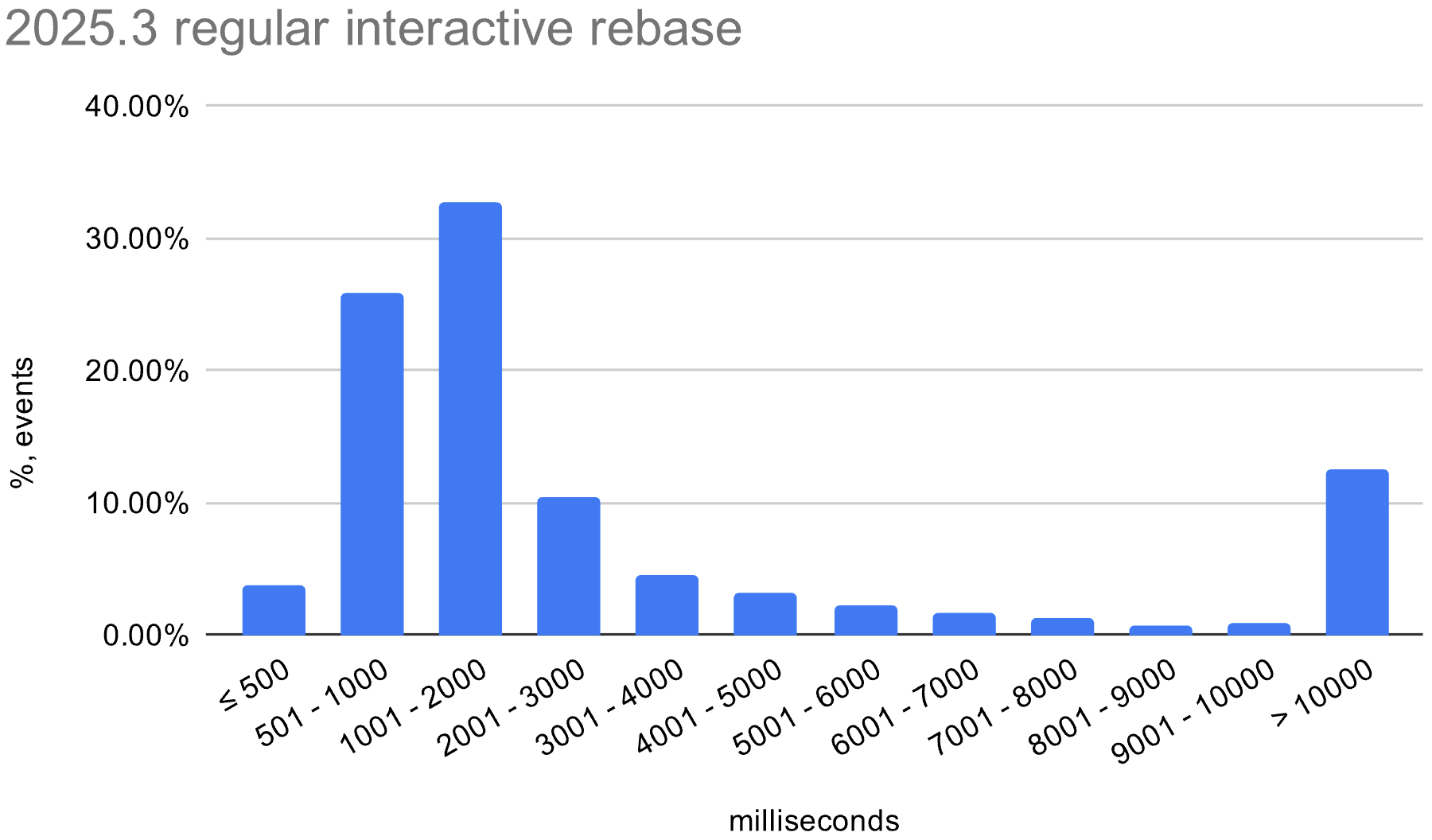
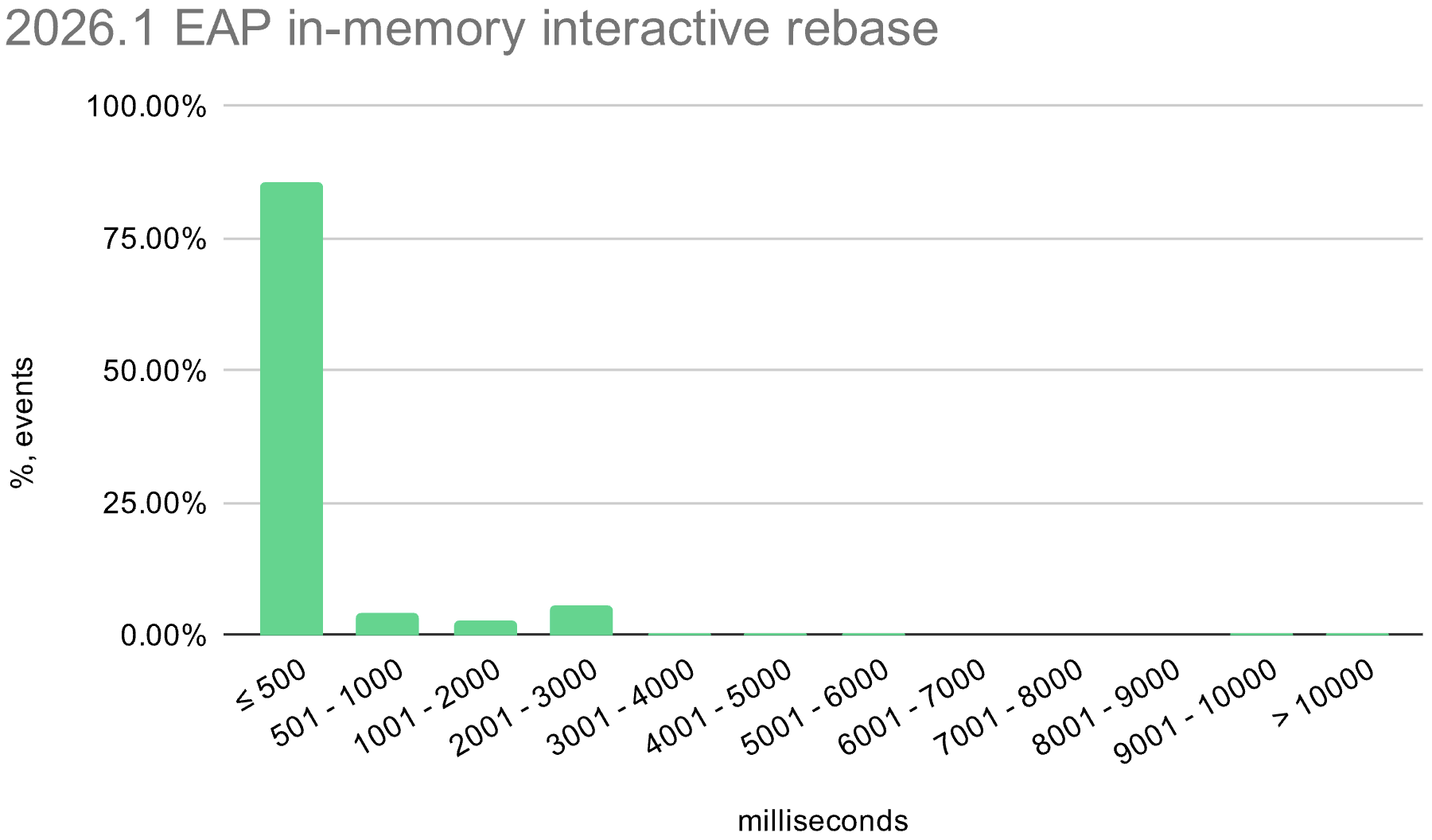
We also enabled the in-memory optimization in EAP builds during the 2026.1 release cycle. The histograms below show the distribution of interactive rebase execution times in data collected from EAP builds, compared with 2025.3.
macOS
Windows
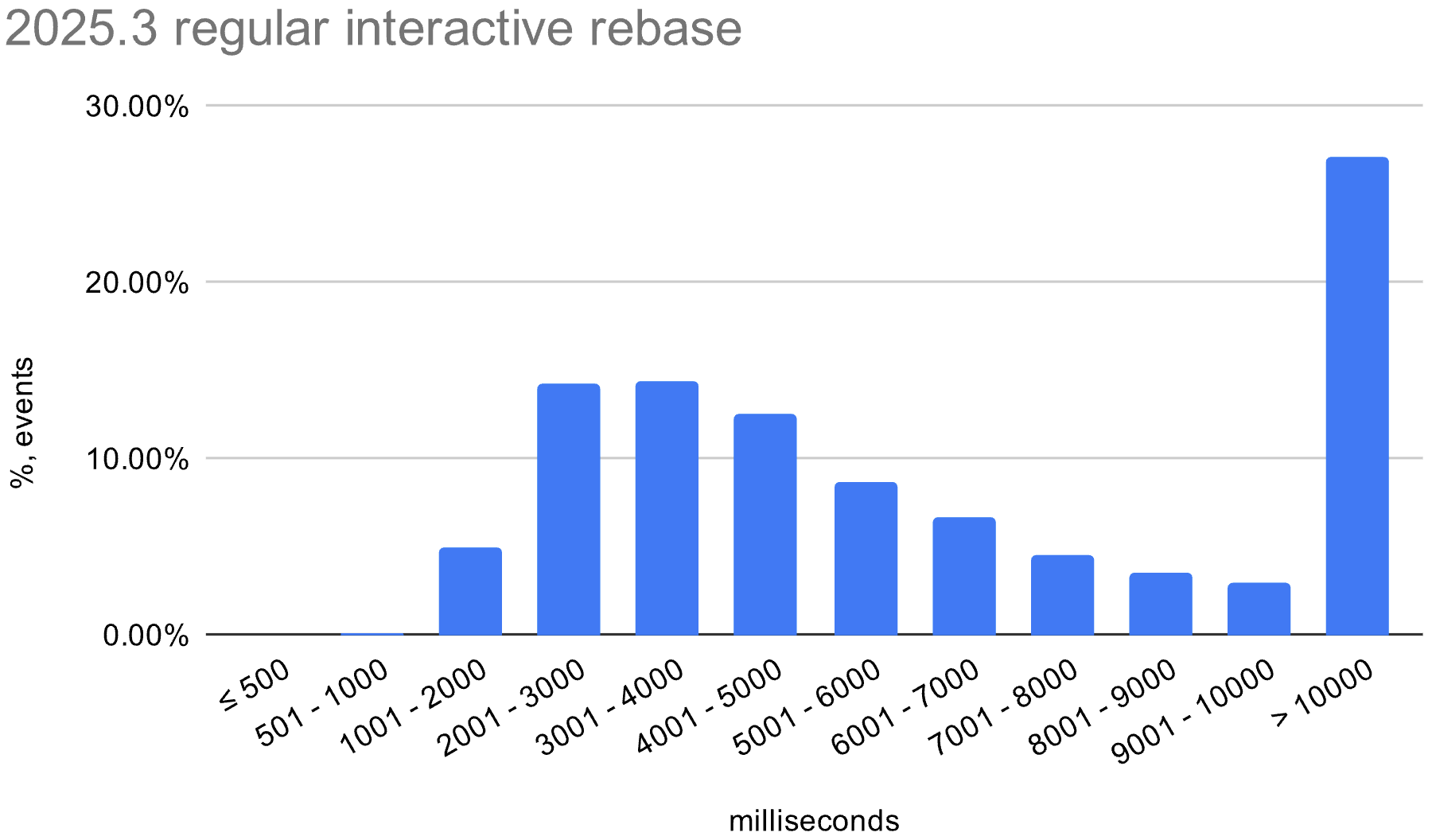
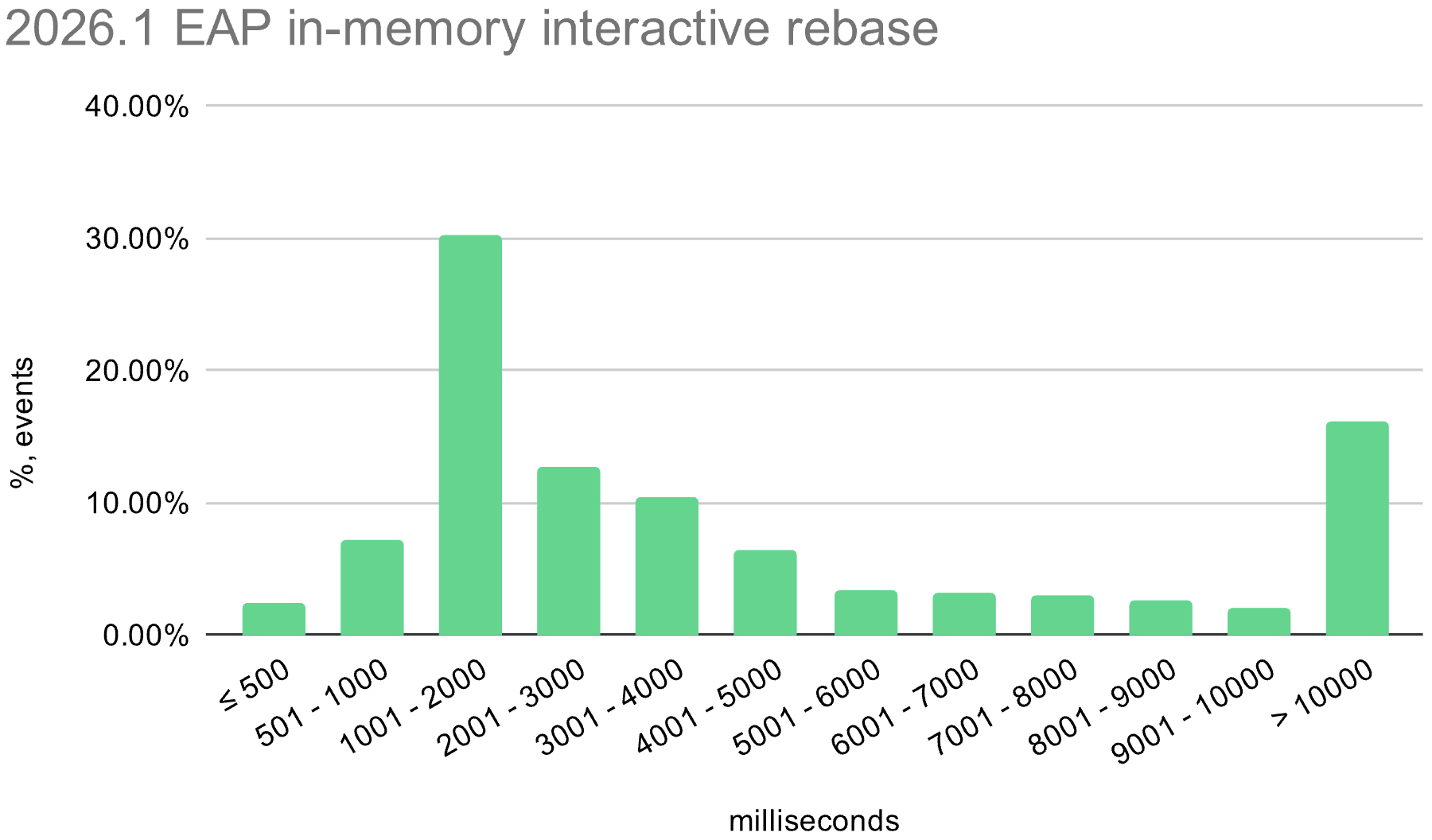
Linux
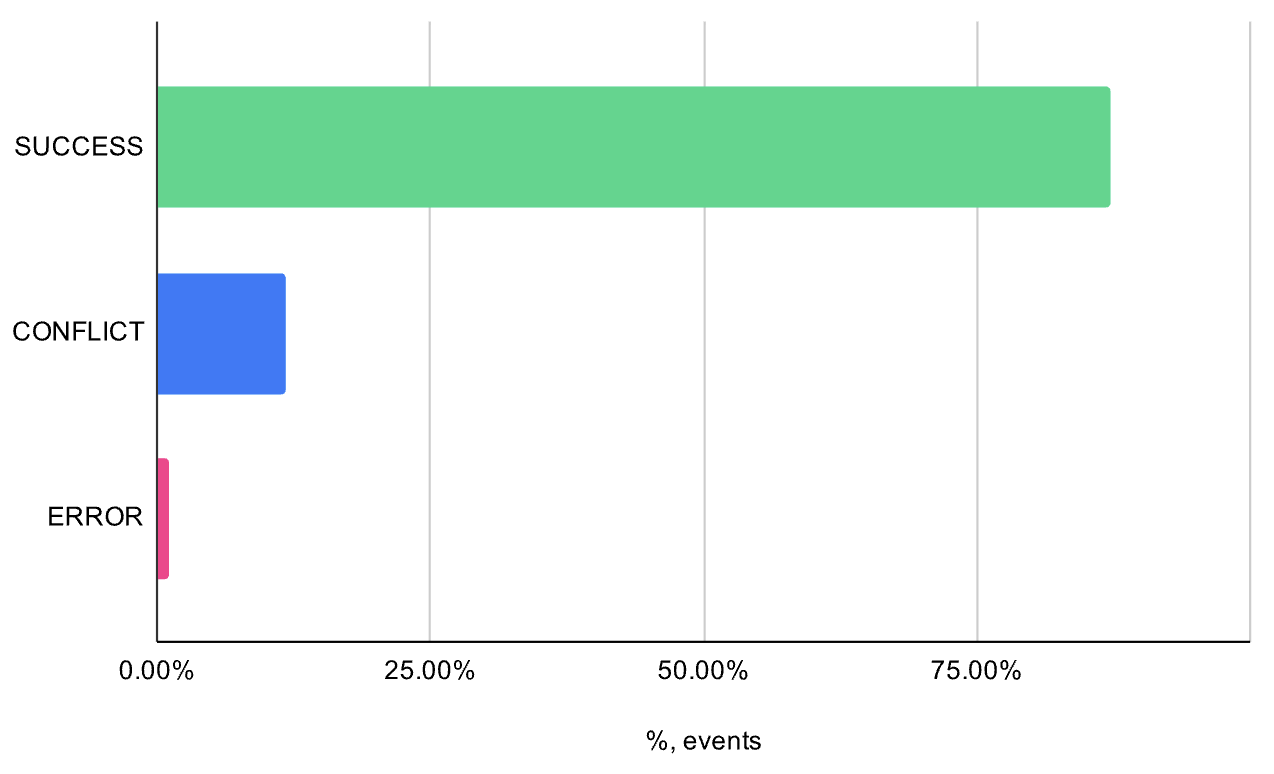
Conflicts
While collecting data on interactive rebase executions, we could also measure how often conflicts occurred. The data shows that around 12% of interactive rebases resulted in merge conflicts, and about 1% failed due to errors. In both cases, we fall back to the regular interactive rebase process.
The in-memory optimization reduces average execution time across all operating systems. There is still room for improvement, especially on Windows, where the worst-case time is still quite high.
After testing this optimization internally at JetBrains and in EAP builds, we decided to enable it by default in the upcoming 2026.1 release. This applies to standard interactive rebase and actions based on it, such as reword, drop, and squash, as well as extracting selected changes into a separate commit. We expect this to make commit-history editing faster and less disruptive.
Credits and further reading
The broader developer community was a huge help in shaping our implementation. We would like to acknowledge:
- git-revise: The logic in this project was instrumental in guiding our in-memory rebase approach.
- Waleed Khan’s blog post: An excellent read that explores this exact topic.
- Jujutsu (jj) VCS Discussion #49: A discussion that sheds light on why the standard Git implementation can be slow in these scenarios.
Interested in the implementation details? Check out the solution in the IntelliJ Platform sources.
Any feedback is welcome! Please leave a comment or email us directly at vcs-team@jetbrains.com.







