

Python mais rápido: Desbloqueando o Global Interpreter Lock do Python

O que é o Global Interpreter Lock (GIL) do Python?
“Global Interpreter Lock” (ou “GIL”) é um termo conhecido na comunidade Python. É um recurso bem conhecido do Python. Mas o que exatamente é um GIL?
Se você tem experiência com outras linguagens de programação (como o Rust), talvez já saiba o que é um mutex. É uma abreviação de “mutual exclusion” (exclusão mútua). Um mutex garante que os dados só possam ser acessados por um thread de cada vez. Isso evita que eles sejam modificados por vários threads ao mesmo tempo. Você pode pensar nisso como um tipo de “bloqueio”. Ele impede que todos os threads acessem os dados, exceto o thread que possui a chave.
O GIL é tecnicamente um mutex. Ele permite que apenas um thread tenha acesso ao interpretador Python de cada vez. Às vezes, eu o imagino como um volante para o Python. Não dá para ter mais de uma pessoa no controle do volante! Por outro lado, um grupo de pessoas em uma viagem de carro geralmente troca de motorista. É como transferir o acesso ao interpretador para um thread diferente.
Devido ao GIL, o Python não permite processos verdadeiramente multithread. Esse recurso provocou debates na última década, e houve muitas tentativas de tornar o Python mais rápido removendo o GIL e permitindo processos multithread. Recentemente, no Python 3.13, foi implementada uma opção para utilizar o Python sem o GIL, às vezes conhecido como no-GIL ou Python com threads livres. Assim começa uma nova era da programação em Python.
Por que o GIL estava lá, afinal?
Se o GIL é tão impopular, por que ele foi implementado para início de conversa? Na verdade, há benefícios em ter um GIL. Em outras linguagens de programação com multithread verdadeiro, às vezes os problemas são causados por mais de um thread que modifica os dados, com o resultado final dependendo de qual thread ou processo termina primeiro. Isso é chamado de “condição de corrida”. Linguagens como Rust costumam ser difíceis de aprender porque os programadores precisam usar mutexes para evitar condições de corrida.
Em Python, todos os objetos têm um contador de referências para monitorar quantos outros objetos requerem informações deles. Se o contador de referências chegar a zero, como sabemos que não há condição de corrida no Python devido ao GIL, podemos declarar com segurança que o objeto não é mais necessário e pode ser coletado como lixo.
Quando o Python foi lançado pela primeira vez em 1991, a maioria dos computadores pessoais tinha apenas um núcleo, e não havia muitos programadores solicitando suporte para multithread. Ter um GIL resolve muitos problemas na implementação de programas e também pode facilitar a manutenção do código. Portanto, um GIL foi adicionado por Guido van Rossum (o criador do Python) em 1992.
Avançando para 2025: os computadores pessoais têm processadores de vários núcleos e, portanto, muito mais capacidade de computação. Podemos aproveitar esse poder extra para alcançar verdadeira concorrência sem nos livrar do GIL.
Mais adiante neste post, detalharemos o processo de remoção. Mas, por enquanto, vamos dar uma olhada em como a verdadeira concorrência funciona com o GIL implementado.
Multiprocessamento em Python
Antes de nos aprofundarmos no processo de remoção do GIL, vamos dar uma olhada em como os desenvolvedores Python podem alcançar a verdadeira concorrência usando a biblioteca de multiprocessamento. A biblioteca padrão de multiprocessamento oferece concorrência local e remota, contornando o Global Interpreter Lock efetivamente com o uso de subprocessos em vez de threads. Dessa forma, o módulo de multiprocessamento permite que o programador aproveite totalmente vários processadores em uma determinada máquina.
No entanto, para realizar o multiprocessamento, teremos que projetar nosso programa de maneira um pouco diferente. Vamos dar uma olhada no seguinte exemplo de como utilizar a biblioteca de multiprocessamento em Python.
Você se lembra da nossa hamburgueria assíncrona na parte 1 da série de blogs:
import asyncio
import time
async def make_burger(order_num):
print(f"Preparing burger #{order_num}...")
await asyncio.sleep(5) # time for making the burger
print(f"Burger made #{order_num}")
async def main():
order_queue = []
for i in range(3):
order_queue.append(make_burger(i))
await asyncio.gather(*(order_queue))
if __name__ == "__main__":
s = time.perf_counter()
asyncio.run(main())
elapsed = time.perf_counter() - s
print(f"Orders completed in {elapsed:0.2f} seconds.")
Podemos usar a biblioteca de multiprocessamento para fazer o mesmo, por exemplo:
import multiprocessing
import time
def make_burger(order_num):
print(f"Preparing burger #{order_num}...")
time.sleep(5) # time for making the burger
print(f"Burger made #{order_num}")
if __name__ == "__main__":
print("Number of available CPU:", multiprocessing.cpu_count())
s = time.perf_counter()
all_processes = []
for i in range(3):
process = multiprocessing.Process(target=make_burger, args=(i,))
process.start()
all_processes.append(process)
for process in all_processes:
process.join()
elapsed = time.perf_counter() - s
print(f"Orders completed in {elapsed:0.2f} seconds.")
Como você deve se lembrar, muitos dos métodos de multiprocessamento são muito semelhantes ao processo de threading. Para ver a diferença no multiprocessamento, vamos explorar um caso de uso mais complexo:
import multiprocessing
import time
import queue
def make_burger(order_num, item_made):
name = multiprocessing.current_process().name
print(f"{name} is preparing burger #{order_num}...")
time.sleep(5) # time for making burger
item_made.put(f"Burger #{order_num}")
print(f"Burger #{order_num} made by {name}")
def make_fries(order_num, item_made):
name = multiprocessing.current_process().name
print(f"{name} is preparing fries #{order_num}...")
time.sleep(2) # time for making fries
item_made.put(f"Fries #{order_num}")
print(f"Fries #{order_num} made by {name}")
def working(task_queue, item_made, order_num, lock):
break_count = 0
name = multiprocessing.current_process().name
while True:
try:
task = task_queue.get_nowait()
except queue.Empty:
print(f"{name} has nothing to do...")
if break_count > 1:
break # stop if idle for too long
else:
break_count += 1
time.sleep(1)
else:
lock.acquire()
try:
current_num = order_num.value
order_num.value = current_num + 1
finally:
lock.release()
task(current_num, item_made)
break_count = 0
if __name__ == "__main__":
print("Welcome to Pyburger! Please place your order.")
burger_num = input("Number of burgers:")
fries_num = input("Number of fries:")
s = time.perf_counter()
task_queue = multiprocessing.Queue()
item_made = multiprocessing.Queue()
order_num = multiprocessing.Value("i", 0)
lock = multiprocessing.Lock()
for i in range(int(burger_num)):
task_queue.put(make_burger)
for i in range(int(fries_num)):
task_queue.put(make_fries)
staff1 = multiprocessing.Process(
target=working,
name="John",
args=(
task_queue,
item_made,
order_num,
lock,
),
)
staff2 = multiprocessing.Process(
target=working,
name="Jane",
args=(
task_queue,
item_made,
order_num,
lock,
),
)
staff1.start()
staff2.start()
staff1.join()
staff2.join()
print("All tasks finished. Closing now.")
print("Items created are:")
while not item_made.empty():
print(item_made.get())
elapsed = time.perf_counter() - s
print(f"Orders completed in {elapsed:0.2f} seconds.")
Aqui está o resultado obtido:
Welcome to Pyburger! Please place your order. Number of burgers:3 Number of fries:2 Jane has nothing to do... John is preparing burger #0... Jane is preparing burger #1... Burger #0 made by John John is preparing burger #2... Burger #1 made by Jane Jane is preparing fries #3... Fries #3 made by Jane Jane is preparing fries #4... Burger #2 made by John John has nothing to do... Fries #4 made by Jane Jane has nothing to do... John has nothing to do... Jane has nothing to do... John has nothing to do... Jane has nothing to do... All tasks finished. Closing now. Items created are: Burger #0 Burger #1 Fries #3 Burger #2 Fries #4 Orders completed in 12.21 seconds.
Observe que há algumas limitações no multiprocessamento que fazem com que o código acima seja projetado dessa maneira. Vamos examiná-las uma a uma.
Primeiro, lembre-se de que anteriormente tínhamos as funções make_burger e make_fries para gerar uma função com o order_num correto:
def make_burger(order_num):
def making_burger():
logger.info(f"Preparing burger #{order_num}...")
time.sleep(5) # time for making burger
logger.info(f"Burger made #{order_num}")
return making_burger
def make_fries(order_num):
def making_fries():
logger.info(f"Preparing fries #{order_num}...")
time.sleep(2) # time for making fries
logger.info(f"Fries made #{order_num}")
return making_fries
Não podemos fazer o mesmo usando o multiprocessamento. Uma tentativa de fazer isso nos dará um erro do tipo:
AttributeError: Can't get local object 'make_burger..making_burger'
O motivo é que o multiprocessamento usa pickle, que só pode serializar funções de nível de módulo superior em geral. Essa é uma das limitações do multiprocessamento.
Em segundo lugar, observe que, no trecho de código do exemplo acima, usando o multiprocessamento, não usamos nenhuma variável global para dados compartilhados. Por exemplo, não podemos utilizar variáveis globais para item_made e order_num. Para compartilhar dados entre diferentes processos, objetos de classe especial, como Queue e Value da biblioteca de multiprocessamento, são usados e passados para os processos como argumentos.
De modo geral, o compartilhamento de dados e estados entre processos diferentes não é incentivado, pois pode causar muitos outros problemas. No nosso exemplo acima, precisamos usar um bloqueio para garantir que o valor de order_num só possa ser acessado e incrementado por um processo de cada vez. Sem o bloqueio, o número do pedido do item pode ser bagunçado, desta forma:
Items created are: Burger #0 Burger #0 Fries #2 Burger #1 Fries #3
Veja como usar um bloqueio para evitar problemas:
lock.acquire()
try:
current_num = order_num.value
order_num.value = current_num + 1
finally:
lock.release()
task(current_num, item_made)
Para saber mais sobre como usar a biblioteca padrão de multiprocessamento, você pode consultar a documentação aqui.
Removendo o GIL
A remoção do GIL tem sido um tema para discussão há quase uma década. Em 2016, no Python Language Summit, Larry Hastings apresentou suas ideias sobre a realização de uma “GIL-ectomia” no interpretador CPython e o progresso que ele havia feito com essa ideia [1]. Foi uma tentativa pioneira de remover o GIL do Python. Em 2021, Sam Gross reacendeu a discussão sobre a remoção do GIL [2], e isso levou ao PEP 703 – Tornando o Global Interpreter Lock opcional no CPython em 2023.
Como podemos ver, a remoção do GIL não é, de forma alguma, uma decisão precipitada e tem sido objeto de considerável debate na comunidade. Conforme demonstrado pelos exemplos acima de multiprocessamento (e o PEP 703, no link acima), quando a garantia fornecida pelo GIL é removida, as coisas se complicam rapidamente.
[1]: https://lwn.net/Articles/689548/
[2]: https://lwn.net/ml/python-dev/CAGr09bSrMNyVNLTvFq-h6t38kTxqTXfgxJYApmbEWnT71L74-g@mail.gmail.com/
Contagem de referências
Quando o GIL está presente, a contagem de referências e a coleta de lixo são mais simples e diretas. Quando apenas um thread por vez tem acesso a objetos Python, podemos confiar na contagem de referências não atômica e remover o objeto quando ela chega a zero.
Com a remoção do GIL, as coisas ficam mais complicadas. Não podemos mais usar a contagem de referências não atômica, pois isso não garante a segurança dos threads. As coisas podem dar errado quando vários threads estão realizando vários incrementos e decrementos da referência no objeto Python ao mesmo tempo. O ideal seria usar a contagem de referências atômica para garantir a segurança dos threads. No entanto, esse método sofre uma alta sobrecarga, e a eficiência é prejudicada quando há muitos threads.
A solução é usar a contagem de referências tendenciosa (biased), que também garante a segurança dos threads. A ideia é atribuir a cada objeto uma tendência (bias) para um thread proprietário, ou seja, o thread que acessa esse objeto na maior parte do tempo. Os threads proprietários podem realizar a contagem de referências não atômica nos objetos que possuem, enquanto outros threads devem realizar a contagem de referências atômica nesses objetos. Esse método é preferível à contagem de referências atômica simples, porque a maioria dos objetos só é acessada por um thread na maior parte do tempo. Podemos reduzir a sobrecarga de execução, permitindo que o thread proprietário realize a contagem de referências não atômica.
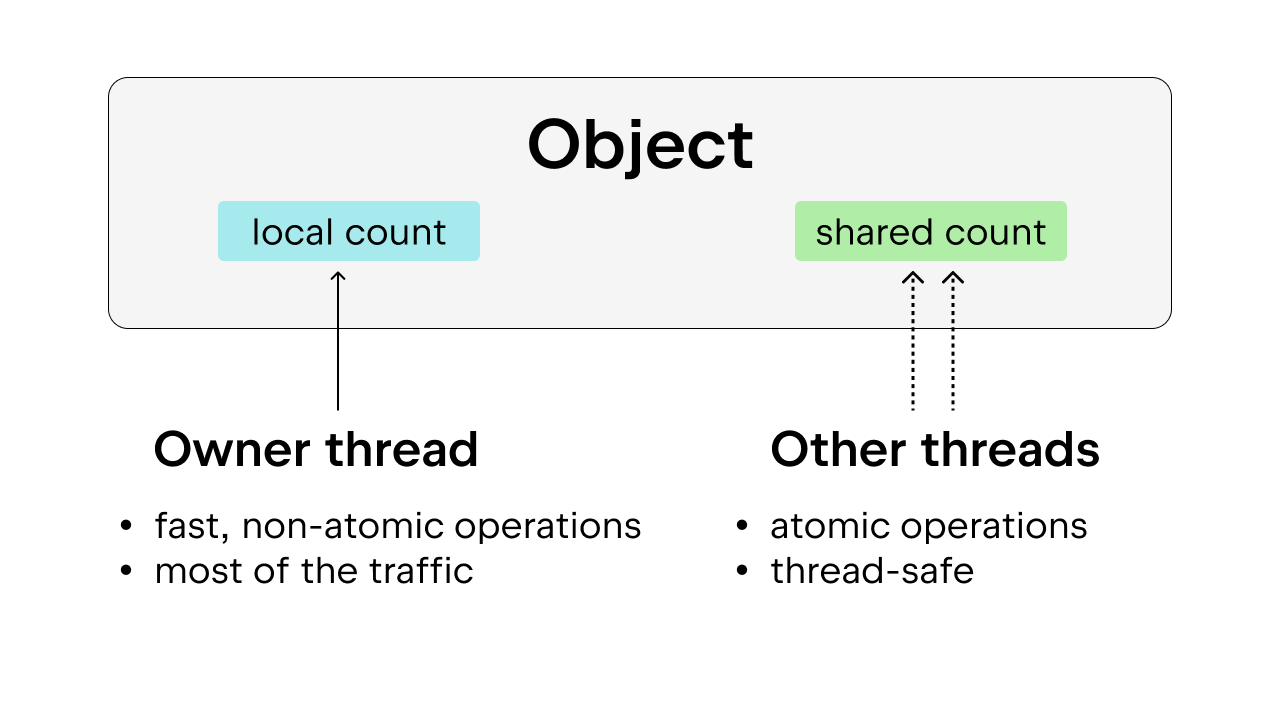
Além disso, alguns objetos Python usados comumente, como True, False, pequenos inteiros e algumas strings internas, são imortais. Aqui, “imortal” significa apenas que os objetos permanecerão no programa durante todo o seu tempo de vida e, portanto, não requerem contagem de referências.
Coleta de lixo
Também temos que modificar a forma como a coleta de lixo é feita. Em vez de diminuir a contagem de referências imediatamente quando a referência é liberada e remover o objeto imediatamente quando essa contagem chega a zero, é usada uma técnica chamada de “contagem de referências diferida”.
Quando a contagem de referências precisa ser diminuída, o objeto é armazenado em uma tabela, que será verificada duas vezes para saber se essa diminuição na contagem de referências é precisa ou não. Isso evita a remoção prematura do objeto quando ele ainda está sendo referenciado, o que pode acontecer sem o GIL, já que a contagem de referências não é tão simples quanto com o GIL. Isso complica o processo de coleta de lixo, já que a coleta de lixo pode precisar percorrer a pilha de cada thread para a realizar contagem de referências de cada thread.
Outro aspecto a ser considerado é que a contagem de referências precisa ser estável durante a coleta de lixo. Se um objeto estiver prestes a ser descartado e, de repente, for referenciado, isso causará sérios problemas. Por esse motivo, durante o ciclo de coleta de lixo, ele terá que “parar o mundo” para oferecer garantias de segurança de thread.
Alocação de memória
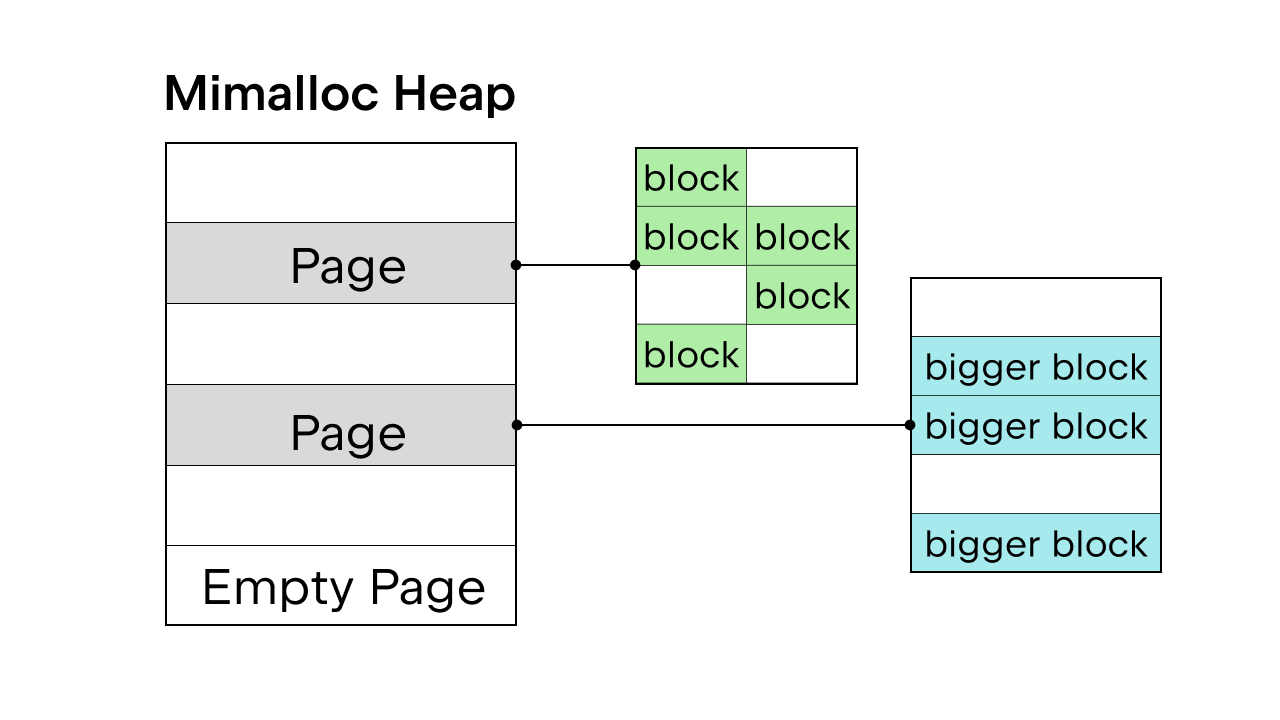
Quando o GIL está presente para garantir a segurança do thread, o alocador de memória interno do Python, pymalloc, é utilizado. Mas, sem o GIL, precisaremos de um novo alocador de memória. Sam Gross propôs o mimalloc no PEP, que é um alocador de uso geral criado por Daan Leijen e mantido pela Microsoft. É uma boa escolha porque ele é seguro para threads e tem boa performance em objetos pequenos.
O mimalloc preenche seu heap com páginas e páginas com blocos. Cada página contém blocos, e os blocos dentro de cada página são todos do mesmo tamanho. Ao adicionar algumas restrições ao acesso à lista e ao dict, o coletor de lixo não precisa manter uma lista vinculada para descobrir todos os objetos e também permite o acesso de leitura à lista e ao dict sem adquirir o bloqueio.
Há mais detalhes sobre a remoção do GIL, mas é impossível abordar todos eles aqui. Você pode consultar PEP 703 – Tornando o Global Interpreter Lock opcional no CPython para obter uma análise completa.
Diferença de performance com e sem o GIL
Como o Python 3.13 oferece uma opção de threads livres, podemos comparar a performance da versão padrão do Python 3.13 com a versão com threads livres.
Instalar o Python com threads livres
Usaremos o pyenv para instalar as duas versões: a padrão (por exemplo, 3.13.5) e a versão com threads livres (por exemplo, 3.13.5t).
Como alternativa, você também pode usar os instaladores no site Python.org. Certifique-se de selecionar a opção Customize durante a instalação e marque a caixa adicional para instalar o Python com threads livres (veja o exemplo nesta postagem do nosso blog).
Depois de instalar as duas versões, podemos adicioná-las como interpretadores em um projeto do PyCharm.
Primeiro, clique no nome do seu interpretador Python no canto inferior direito.
Selecione Add New Interpreter no menu e, em seguida, Add Local Interpreter.
Escolha Select existing, aguarde o carregamento do caminho do interpretador (o que pode demorar um pouco se você tiver muitos interpretadores, como eu tenho) e, em seguida, selecione o novo interpretador que acabou de instalar no menu suspenso Python path.
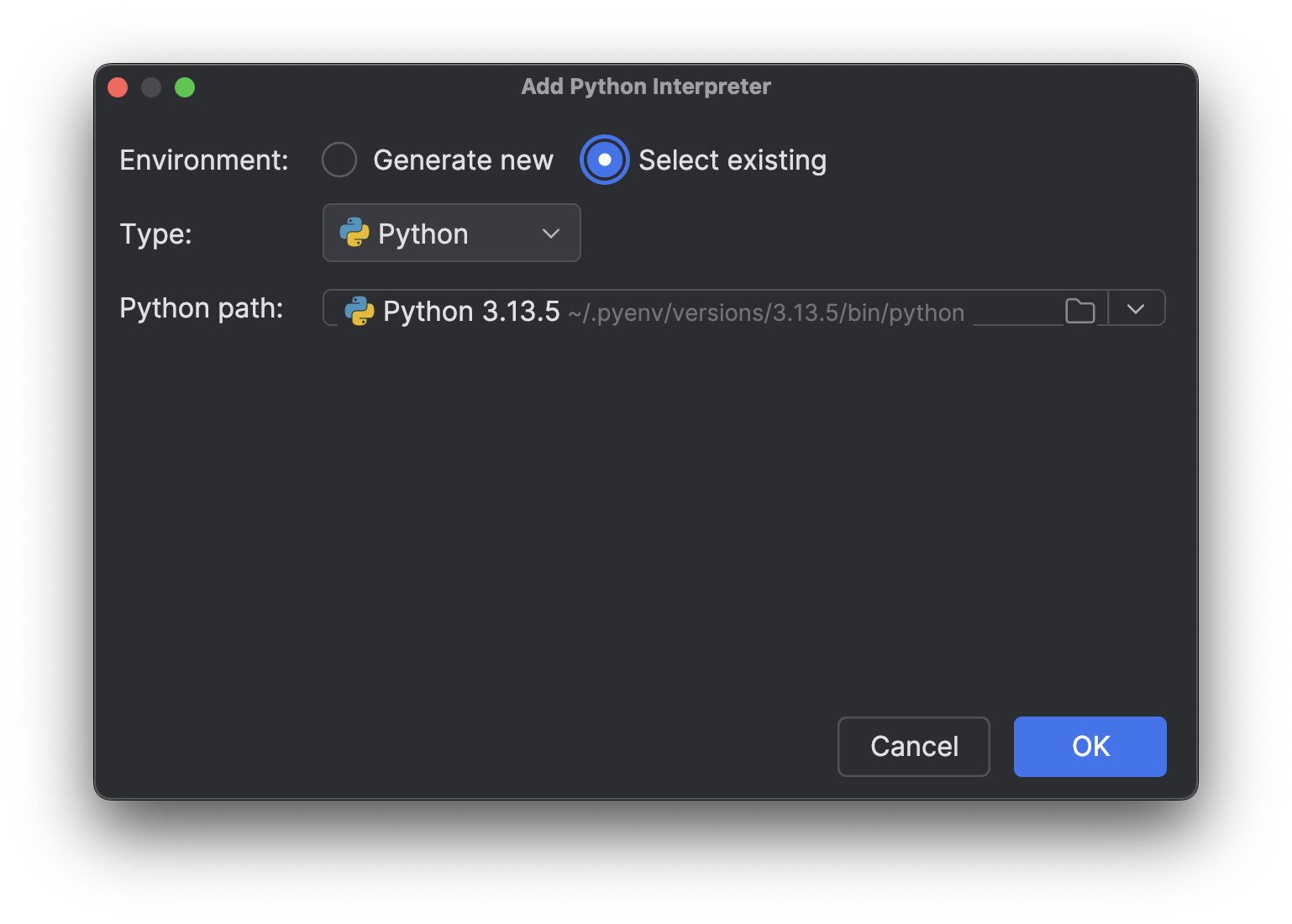
Clique em OK para adicioná-lo. Repita as mesmas etapas para o outro interpretador. Agora, quando você clicar novamente no nome do interpretador no canto inferior direito, verá vários interpretadores Python 3.13, como na imagem acima.
Testes com um processo limitado por CPU
Em seguida, precisamos de um script para testar as diferentes versões. Lembre-se de que explicamos na parte 1 desta série de postagens do nosso blog que, para acelerar processos limitados por CPU, precisamos de um verdadeiro multithread. Para ver se a remoção do GIL permitirá um multithread verdadeiro e tornará o Python mais rápido, podemos testar com um processo limitado por CPU em vários threads. Aqui está o script que pedi para o Junie gerar (com alguns ajustes finais feitos por mim):
import time
import multiprocessing # Kept for CPU count
from concurrent.futures import ThreadPoolExecutor
import sys
def is_prime(n):
"""Check if a number is prime (CPU-intensive operation)."""
if n <= 1:
return False
if n <= 3:
return True
if n % 2 == 0 or n % 3 == 0:
return False
i = 5
while i * i <= n:
if n % i == 0 or n % (i + 2) == 0:
return False
i += 6
return True
def count_primes(start, end):
"""Count prime numbers in a range."""
count = 0
for num in range(start, end):
if is_prime(num):
count += 1
return count
def run_single_thread(range_size, num_chunks):
"""Run the prime counting task in a single thread."""
chunk_size = range_size // num_chunks
total_count = 0
start_time = time.time()
for i in range(num_chunks):
start = i * chunk_size + 1
end = (i + 1) * chunk_size + 1 if i < num_chunks - 1 else range_size + 1
total_count += count_primes(start, end)
end_time = time.time()
return total_count, end_time - start_time
def thread_task(start, end):
"""Task function for threads."""
return count_primes(start, end)
def run_multi_thread(range_size, num_threads, num_chunks):
"""Run the prime counting task using multiple threads."""
chunk_size = range_size // num_chunks
total_count = 0
start_time = time.time()
with ThreadPoolExecutor(max_workers=num_threads) as executor:
futures = []
for i in range(num_chunks):
start = i * chunk_size + 1
end = (i + 1) * chunk_size + 1 if i < num_chunks - 1 else range_size + 1
futures.append(executor.submit(thread_task, start, end))
for future in futures:
total_count += future.result()
end_time = time.time()
return total_count, end_time - start_time
def main():
# Fixed parameters
range_size = 1000000 # Range of numbers to check for primes
num_chunks = 16 # Number of chunks to divide the work into
num_threads = 4 # Fixed number of threads for multi-threading test
print(f"Python version: {sys.version}")
print(f"CPU count: {multiprocessing.cpu_count()}")
print(f"Range size: {range_size}")
print(f"Number of chunks: {num_chunks}")
print("-" * 60)
# Run single-threaded version as baseline
print("Running single-threaded version (baseline)...")
count, single_time = run_single_thread(range_size, num_chunks)
print(f"Found {count} primes in {single_time:.4f} seconds")
print("-" * 60)
# Run multi-threaded version with fixed number of threads
print(f"Running multi-threaded version with {num_threads} threads...")
count, thread_time = run_multi_thread(range_size, num_threads, num_chunks)
speedup = single_time / thread_time
print(f"Found {count} primes in {thread_time:.4f} seconds (speedup: {speedup:.2f}x)")
print("-" * 60)
# Summary
print("SUMMARY:")
print(f"{'Threads':<10} {'Time (s)':<12} {'Speedup':<10}")
print(f"{'1 (baseline)':<10} {single_time:<12.4f} {'1.00x':<10}")
print(f"{num_threads:<10} {thread_time:<12.4f} {speedup:.2f}x")
if __name__ == "__main__":
main()
Para facilitar a execução do script com diferentes interpretadores Python, podemos adicionar um script de execução personalizado ao nosso projeto PyCharm.
Na parte superior, selecione Edit Configurations… no menu suspenso ao lado do botão Run (![]() ).
).
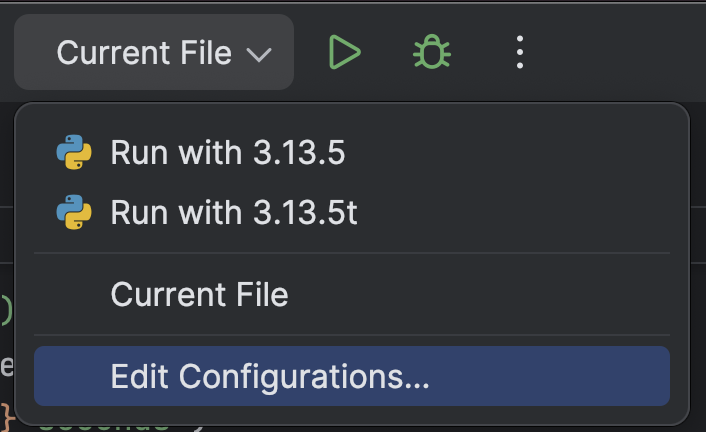
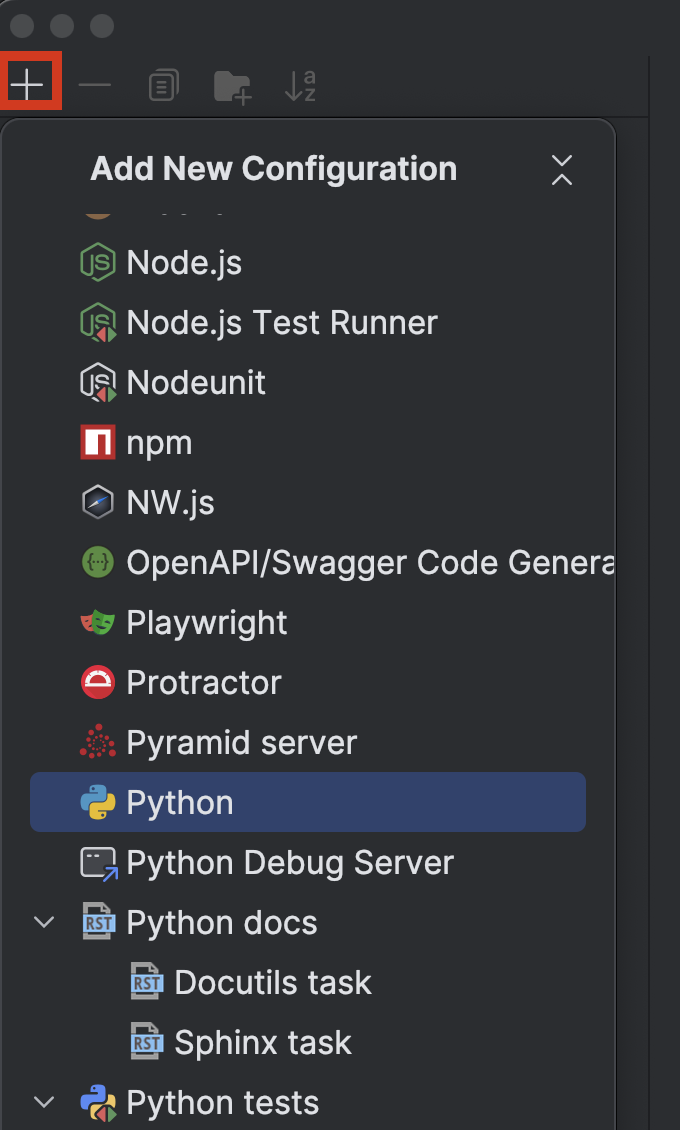
Clique no botão + no canto superior esquerdo e, em seguida, escolha Python no menu suspenso Add New Configuration.
Escolha um nome que permita saber qual interpretador específico está sendo usado, por exemplo, 3.13.5 em vez de 3.15.3t. Escolha o interpretador correto e adicione o nome do script de teste, da seguinte forma:
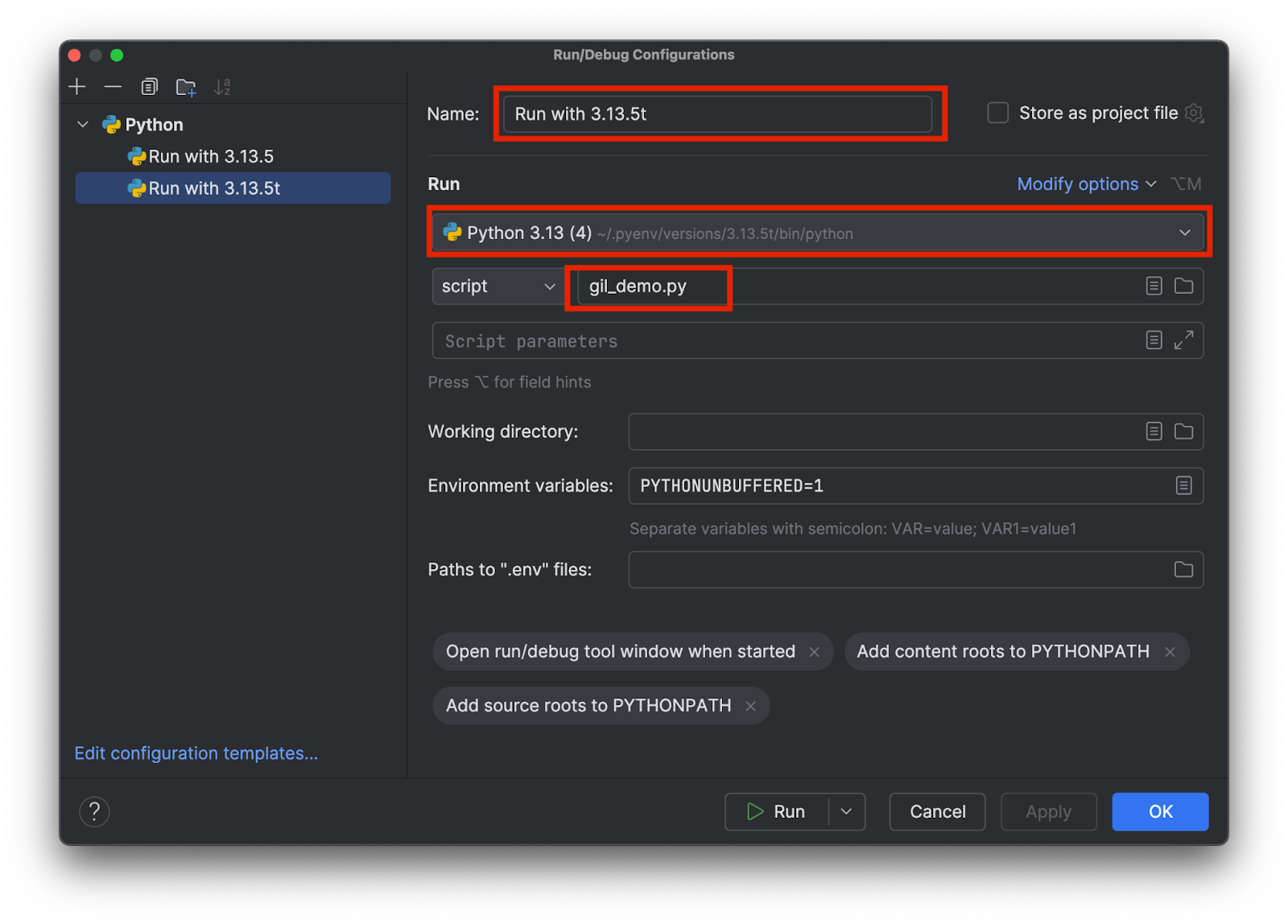
Adicione duas configurações, uma para cada interpretador. Em seguida, clique em OK.
Agora, podemos selecionar e executar facilmente o script de teste com ou sem o GIL, selecionando a configuração e clicando no botão Run (![]() ) na parte superior.
) na parte superior.
Comparando os resultados
Este é o resultado que obtive ao executar a versão padrão 3.13.5 com o GIL:
Python version: 3.13.5 (main, Jul 10 2025, 20:33:15) [Clang 17.0.0 (clang-1700.0.13.5)] CPU count: 8 Range size: 1000000 Number of chunks: 16 ------------------------------------------------------------ Running single-threaded version (baseline)... Found 78498 primes in 1.1930 seconds ------------------------------------------------------------ Running multi-threaded version with 4 threads... Found 78498 primes in 1.2183 seconds (speedup: 0.98x) ------------------------------------------------------------ SUMMARY: Threads Time (s) Speedup 1 (baseline) 1.1930 1.00x 4 1.2183 0.98x
Como você pode ver, não há alteração significativa na velocidade ao executar a versão com 4 threads em comparação com a linha de base de thread único. Vejamos o que obtemos ao executar a versão com threads livres 3.13.5t:
Python version: 3.13.5 experimental free-threading build (main, Jul 10 2025, 20:36:28) [Clang 17.0.0 (clang-1700.0.13.5)] CPU count: 8 Range size: 1000000 Number of chunks: 16 ------------------------------------------------------------ Running single-threaded version (baseline)... Found 78498 primes in 1.5869 seconds ------------------------------------------------------------ Running multi-threaded version with 4 threads... Found 78498 primes in 0.4662 seconds (speedup: 3.40x) ------------------------------------------------------------ SUMMARY: Threads Time (s) Speedup 1 (baseline) 1.5869 1.00x 4 0.4662 3.40x
Dessa vez, a velocidade foi três vezes maior. Observe que, em ambos os casos, há uma sobrecarga para multithread. Portanto, mesmo com o verdadeiro multithread, a velocidade não é 4 vezes maior com 4 threads.
Conclusão
Na parte 2 da série de postagens do nosso blog sobre o Python mais rápido, discutimos o motivo de termos o GIL do Python no passado, contornando a limitação do GIL usando multiprocessamento, bem como o processo e o efeito da remoção do GIL.
Até o momento desta postagem do nosso blog, a versão com threads livres do Python ainda não é o padrão. No entanto, com a adoção da comunidade e de bibliotecas de terceiros, a comunidade espera que a versão com threads livres do Python seja o padrão no futuro. Foi anunciado que o Python 3.14 incluirá uma versão com threads livres que passará do estágio experimental, mas ainda será opcional.
O PyCharm fornece o melhor suporte ao Python da categoria para garantir velocidade e precisão. Aproveite o recurso mais inteligente de complementação de código, as verificações de conformidade com o PEP 8, as refatorações inteligentes e uma variedade de inspeções para atender a todas as suas necessidades de programação. Conforme demonstrado nesta postagem do nosso blog, o PyCharm fornece configurações personalizadas para interpretadores Python e configurações de execução, permitindo que você alterne entre interpretadores com apenas alguns cliques, o que o torna adequado para uma ampla gama de projetos Python.
Artigo original em inglês por:





