

Ajustando e implantando modelos GPT usando o Transformers do Hugging Face

Hugging Face é atualmente um nome conhecido entre pesquisadores e entusiastas do machine learning. Um dos seus maiores sucessos é o Transformers, um framework de definição de modelos para modelos de machine learning em texto, visão computacional, áudio e vídeo. Devido ao vasto repositório de modelos de machine learning de última geração disponíveis no Hugging Face Hub e a compatibilidade do Transformers com a maioria dos frameworks de treinamento, ele é amplamente utilizado para inferência e treinamento de modelos.
Por que fazer o ajuste-fino de um modelo de IA?
A otimização de modelos de IA é crucial para adaptar seu desempenho a tarefas e conjuntos de dados específicos, permitindo que eles alcancem maior precisão e eficiência em comparação com o uso de um modelo de uso geral. Ao adaptar um modelo pré-treinado, o ajuste fino reduz a necessidade de treinar do zero, economizando tempo e recursos. Ele também permite um melhor tratamento de formatos específicos, nuances e casos extremos dentro de um determinado domínio, gerando resultados mais confiáveis e personalizados.
Neste post do nosso blog, vamos otimizar um modelo GPT com raciocínio matemático para que ele lide melhor com questões matemáticas.
Usando modelos da Hugging Face
Ao usarmos o PyCharm, podemos facilmente navegar e adicionar qualquer modelo da Hugging Face. Em um novo arquivo Python, no menu Code, na parte superior, selecione Insert HF Model.
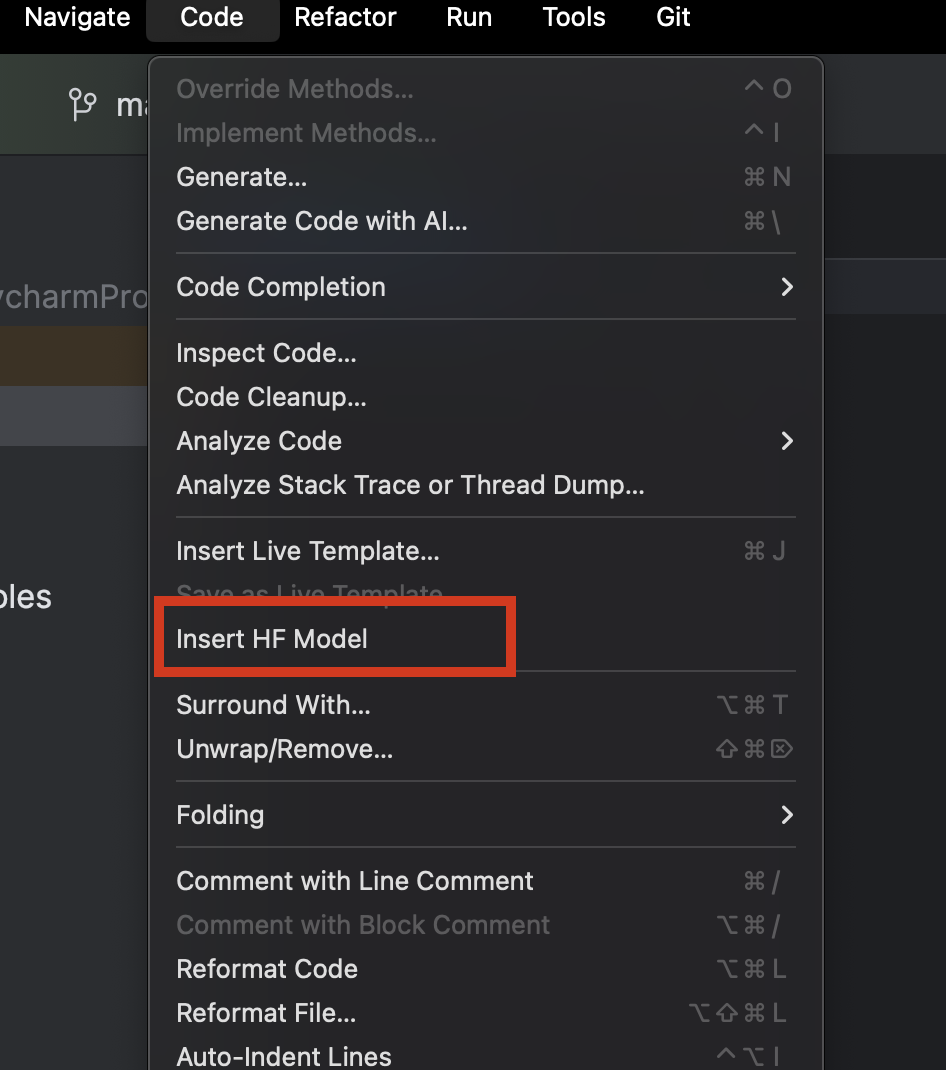
No menu que é aberto, você pode navegar pelos modelos por categoria ou começar a digitar na barra de pesquisa na parte superior. Ao selecionar um modelo, você pode ver sua descrição à direita.
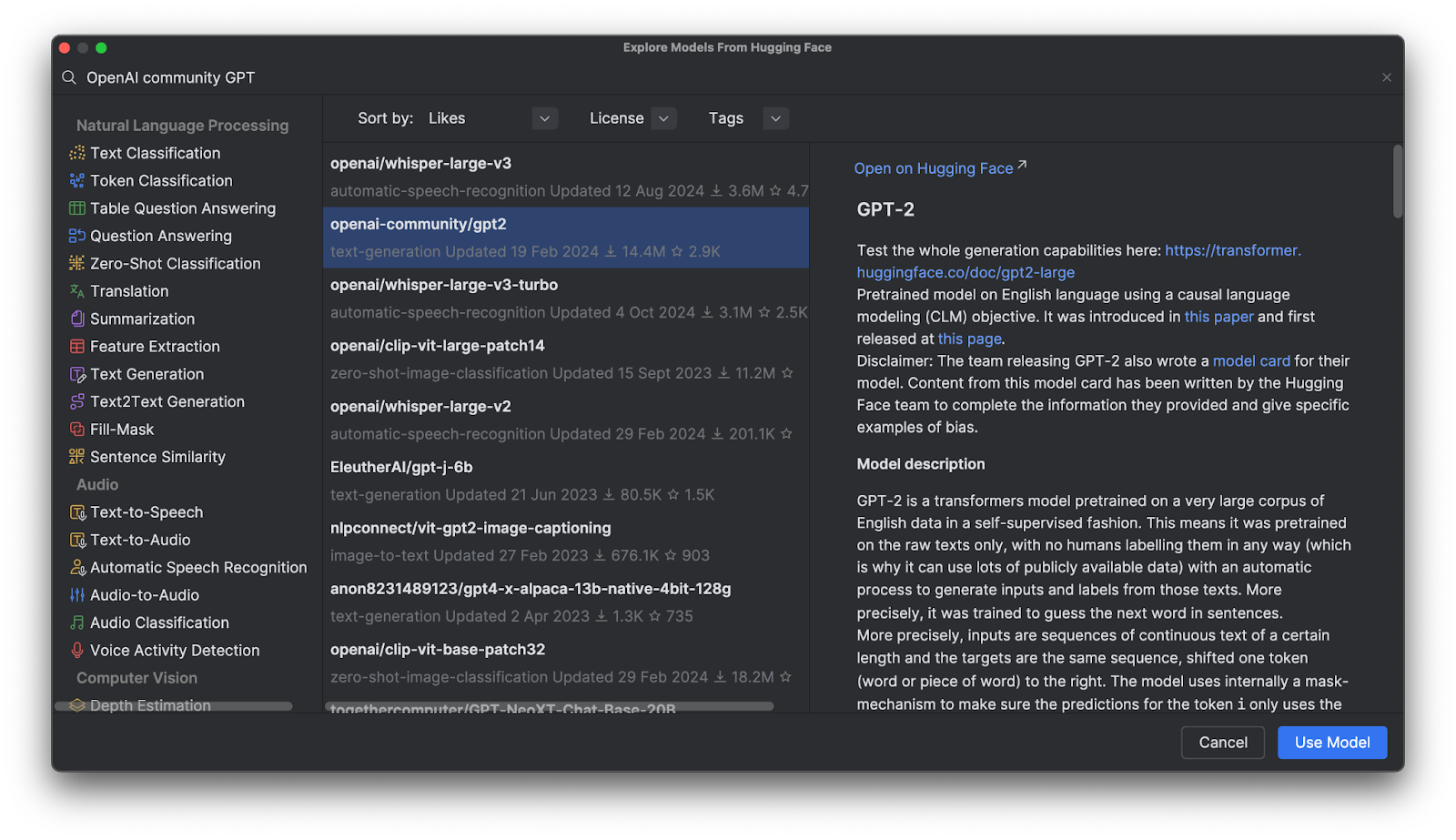
Ao clicar em Use Model, você verá um trecho de código adicionado ao seu arquivo. E é isso – agora está tudo pronto para você começar a usar seu modelo da Hugging Face.

Modelos GPT (Generative Pre-Trained Transformer)
Os modelos GPT são muito populares no Hugging Face Hub, mas o que são? Os GPTs são modelos treinados que compreendem a linguagem natural e geram textos de alta qualidade. Eles são usados principalmente em tarefas relacionadas a associação textual, resposta a perguntas, similaridade semântica e classificação de documentos. O exemplo mais famoso é o ChatGPT, criado pela OpenAI.
Muitos modelos GPT da OpenAI estão disponíveis no Hugging Face Hub, e aprenderemos como usar esses modelos com o Transformers, ajustá-los com nossos próprios dados e implantá-los em um aplicativo.
Benefícios do uso do Transformers
O Transformers, juntamente com outras ferramentas fornecidas pela Hugging Face, oferece ferramentas de alto nível para o ajuste fino de qualquer modelo sofisticado de aprendizado profundo. Em vez de exigir que você compreenda totalmente a arquitetura e o método de tokenização de um determinado modelo, essas ferramentas ajudam a tornar os modelos “plug and play” com quaisquer dados de treinamento compatíveis, ao mesmo tempo em que oferecem uma grande quantidade de personalização em tokenização e treinamento.
Transformers em ação
Para ver mais de perto o Transformers em ação, vamos ver como podemos usá-lo para interagir com um modelo GPT.
Inferência usando um modelo pré-treinado com um pipeline
Após selecionar e adicionar o modelo GPT-2 da OpenAI ao código, este é o resultado obtido:
from transformers import pipeline
pipe = pipeline("text-generation", model="openai-community/gpt2")
Antes de podermos usá-lo, precisamos fazer alguns preparativos. Primeiro, precisamos instalar um framework de machine learning. Neste exemplo, escolhemos o PyTorch. Você pode instalá-lo facilmente através da janela Python Packages no PyCharm.
Em seguida, precisamos instalar o Transformers usando a opção `torch`. Você pode fazer isso usando o terminal – abra-o usando o botão à esquerda ou use a tecla de atalho ⌥ F12 (macOS) ou Alt + F12 (Windows).
No terminal, como estamos usando o uv, usamos os seguintes comandos para adicioná-lo como dependência e instalá-lo:
uv add “transformers[torch]” uv sync
Se você estiver usando o pip:
pip install “transformers[torch]”
Também instalaremos mais algumas bibliotecas que precisaremos posteriormente, incluindo python-dotenv, datasets, notebook e ipywidgets. Você pode usar qualquer um dos métodos acima para instalá-los.
Depois disso, talvez seja melhor adicionar um dispositivo GPU para acelerar o modelo. Dependendo do que você tem na sua máquina, você pode adicioná-lo definindo o parâmetro do dispositivo no pipeline.. Como estou usando um computador Mac M2, posso definir device="mps" desta maneira:
pipe = pipeline("text-generation", model="openai-community/gpt2", device="mps")
Se você tiver GPUs CUDA, também poderá definir device="cuda".
Agora que configuramos nosso pipeline, vamos testá-lo com um prompt simples:
from transformers import pipeline
pipe = pipeline("text-generation", model="openai-community/gpt2", device="mps")
print(pipe("A rectangle has a perimeter of 20 cm. If the length is 6 cm, what is the width?", max_new_tokens=200))
Execute o script com o botão Run (![]() ) na parte superior:
) na parte superior:
O resultado será semelhante a este:
[{'generated_text': 'A rectangle has a perimeter of 20 cm. If the length is 6 cm, what is the width?nnA rectangle has a perimeter of 20 cm. If the length is 6 cm, what is the width? A rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width? A rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width? A rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width?nnA rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width? A rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width? A rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width? A rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width?nnA rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width? A rectangle has a perimeter'}]
Não há muito raciocínio nisso, apenas um monte de coisas sem sentido.
Você também poderá receber este aviso:
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Esta é a configuração padrão. Você também pode adicioná-la manualmente, conforme mostrado abaixo, para que este aviso desapareça, mas não precisamos nos preocupar muito com isso nesta fase.
print(pipe("A rectangle has a perimeter of 20 cm. If the length is 6 cm, what is the width?", max_new_tokens=200, pad_token_id=pipe.tokenizer.eos_token_id))
Agora que vimos como o GPT-2 se comporta imediatamente após a implantação, vamos ver se conseguimos melhorá-lo no raciocínio matemático com alguns ajustes.
Carregue e prepare um conjunto de dados do Hugging Face Hub
Antes de trabalharmos no modelo GPT, precisamos primeiro de dados de treinamento. Vejamos como obter um conjunto de dados do Hugging Face Hub.
Se ainda não o fez, inscreva-se para obter uma conta Hugging Face e criar um token de acesso. Por enquanto, só precisamos de um token `read`. Armazene seu token em um arquivo `.env`, desta forma:
HF_TOKEN=your-hugging-face-access-token
Usaremos este Conjunto de dados de raciocínio matemático, que contém texto descrevendo alguns raciocínios matemáticos. Ajustaremos nosso modelo GPT com este conjunto de dados para que ele possa resolver problemas matemáticos de maneira mais eficaz.
Vamos criar um novo notebook Jupyter, que usaremos para o ajuste fino, pois ele nos permite executar diferentes trechos de código, um por um, e monitorar o progresso.
Na primeira célula, usamos este script para carregar o conjunto de dados do Hugging Face Hub:
from datasets import load_dataset
from dotenv import load_dotenv
import os
load_dotenv()
dataset = load_dataset("Cheukting/math-meta-reasoning-cleaned", token=os.getenv("HF_TOKEN"))
dataset
Execute esta célula (pode demorar um pouco, dependendo da velocidade da sua internet), que irá baixar o conjunto de dados. Quando estiver pronto, podemos dar uma olhada no resultado:
DatasetDict({
train: Dataset({
features: ['id', 'text', 'token_count'],
num_rows: 987485
})
})
Se você estiver curioso e quiser dar uma olhada nos dados, pode fazer isso no PyCharm. Abra a janela Jupyter Variables usando o botão à direita:
Expanda dataset, e você verá a opção View as DataFrame ao lado de dataset[‘train’]:
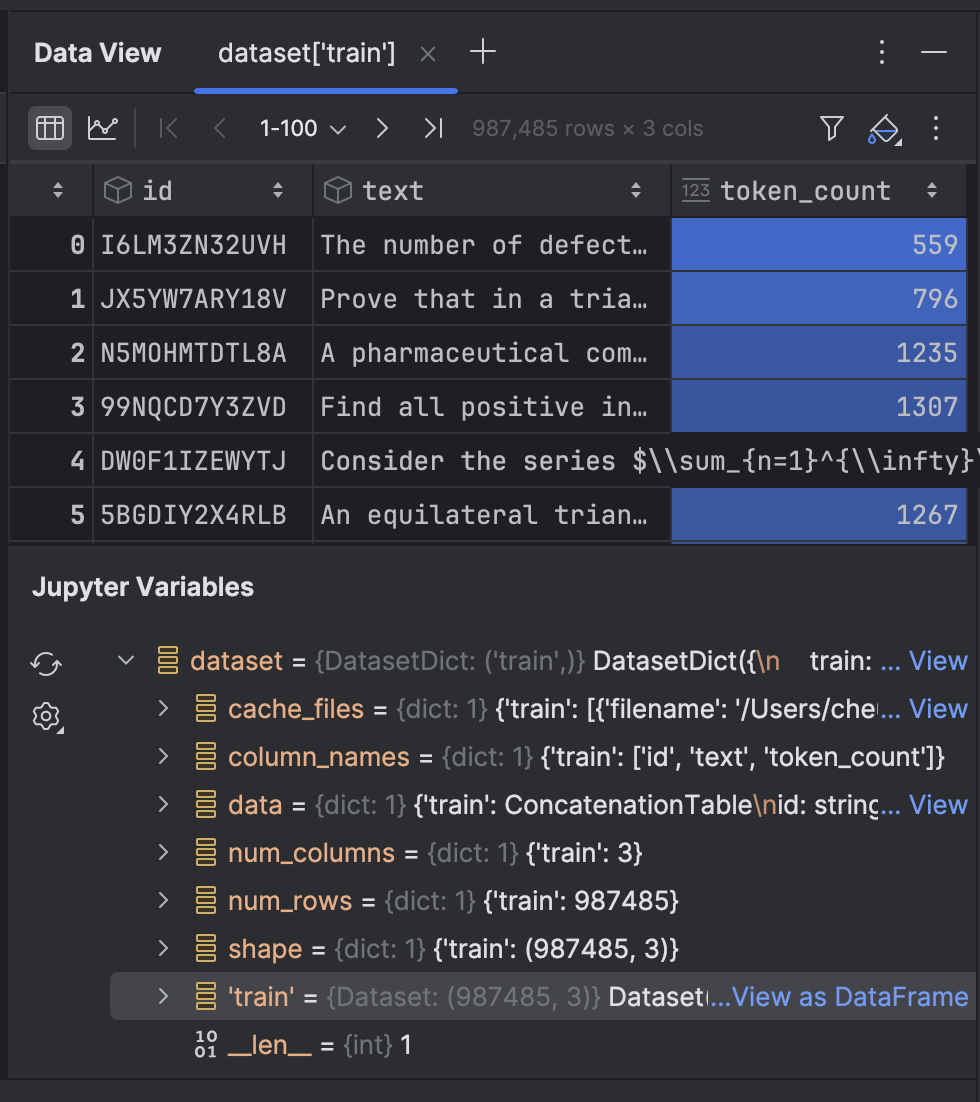
Clique nele para ver os dados na janela de ferramentas Data View:
Em seguida, vamos tokenizar o texto no conjunto de dados:
from transformers import GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("openai-community/gpt2")
tokenizer.pad_token = tokenizer.eos_token
def tokenize_function(examples):
return tokenizer(examples['text'], truncation=True, padding='max_length', max_length=512)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
Aqui, usamos o tokenizador GPT-2 e definimos o pad_token para ser o eos_token, que é o símbolo que indica o fim da linha. Depois disso, vamos tokenizar o texto com uma função. Pode demorar um pouco na primeira vez que você executá-lo, mas depois disso ele será armazenado em cache e ficará mais rápido se você precisar executar a célula novamente.
O conjunto de dados tem quase 1 milhão de linhas para treinamento. Se você tiver capacidade computacional suficiente para processar tudo, poderá utilizá-los todos. No entanto, nesta demonstração, estamos treinando localmente em um laptop, então é melhor usar apenas uma pequena parte!
tokenized_datasets_split = tokenized_datasets["train"].shard(num_shards=100, index=0).train_test_split(test_size=0.2, shuffle=True) tokenized_datasets_split
Aqui, uso apenas 1% dos dados e, em seguida, executo train_test_split para dividir o conjunto de dados em dois:
DatasetDict({
train: Dataset({
features: ['id', 'text', 'token_count', 'input_ids', 'attention_mask'],
num_rows: 7900
})
test: Dataset({
features: ['id', 'text', 'token_count', 'input_ids', 'attention_mask'],
num_rows: 1975
})
})
Agora estamos prontos para fazer o ajuste fino do modelo GPT-2.
Ajuste-fino de um modelo GPT
Na próxima célula vazia, definiremos nossos argumentos de treinamento:
from transformers import TrainingArguments training_args = TrainingArguments( output_dir='./results', num_train_epochs=5, per_device_train_batch_size=8, per_device_eval_batch_size=8, warmup_steps=100, weight_decay=0.01, save_steps = 500, logging_steps=100, dataloader_pin_memory=False )
A maioria deles é bastante comum para o ajuste fino de um modelo. No entanto, dependendo da configuração do seu computador, talvez seja necessário ajustar algumas coisas:
- Tamanho do lote: é importante encontrar o tamanho ideal do lote, pois quanto maior ele for, mais rápido será o treinamento. No entanto, há um limite para a quantidade de memória disponível para sua CPU ou GPU, portanto, você poderá descobrir um valor máximo.
- Epochs – Ter mais epochs faz com que o treinamento demore mais. Você pode decidir quantos epochs são necessários.
- Save steps – Determina a frequência com que um checkpoint será salvo no disco. Se o treinamento for lento e houver a possibilidade de ele parar inesperadamente, talvez seja melhor salvar com mais frequência (defina esse valor como menor).
Depois de configurarmos nossas definições, montaremos o treinador na próxima célula:
from transformers import Trainer, DataCollatorForLanguageModeling
model = GPT2LMHeadModel.from_pretrained("openai-community/gpt2")
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets_split['train'],
eval_dataset=tokenized_datasets_split['test'],
data_collator=data_collator,
)
trainer.train(resume_from_checkpoint=False)
Definimos `resume_from_checkpoint=False`, mas você pode defini-lo como `True` para continuar a partir do último checkpoint se o treinamento for interrompido.
Após o término do treinamento, avaliaremos e salvaremos o modelo:
trainer.evaluate(tokenized_datasets_split['test'])
trainer.save_model("./trained_model")
Agora podemos usar o modelo treinado no pipeline. Vamos voltar para `model.py`, onde usamos um pipeline com um modelo pré-treinado:
from transformers import pipeline
pipe = pipeline("text-generation", model="openai-community/gpt2", device="mps")
print(pipe("A rectangle has a perimeter of 20 cm. If the length is 6 cm, what is the width?", max_new_tokens=200, pad_token_id=pipe.tokenizer.eos_token_id))
Agora vamos alterar `model=”openai-community/gpt2″` para `model=”./trained_model”` e ver o que obtemos:
[{'generated_text': "A rectangle has a perimeter of 20 cm. If the length is 6 cm, what is the width?nAlright, let me try to solve this problem as a student, and I'll let my thinking naturally fall into the common pitfall as described.nn---nn**Step 1: Attempting the Problem (falling into the pitfall)**nnWe have a rectangle with perimeter 20 cm. The length is 6 cm. We want the width.nnFirst, I need to find the area under the rectangle.nnLet’s set ( A = 20 - 12 ), where ( A ) is the perimeter.nn**Area under a rectangle:** n[nA = (20-12)^2 + ((-12)^2)^2 = 20^2 + 12^2 = 24n]nnSo, ( 24 = (20-12)^2 = 27 ).nnNow, I’ll just divide both sides by 6 to find the area under the rectangle.n"}]
Infelizmente, isso ainda não resolve o problema.
No entanto, foi possível chegar a algumas fórmulas matemáticas e raciocínios até então não utilizados. Se quiser, você pode tentar otimizar um pouco mais o modelo com os dados que não usamos.
Na próxima seção, veremos como podemos implantar um modelo otimizado acessível via endpoints da API usando as ferramentas fornecidas pela Hugging Face e FastAPI.
Implantação de um modelo otimizado
A maneira mais fácil de implantar um modelo em um backend de servidor é através da FastAPI. Anteriormente, escrevi um post no nosso blog sobre a implantação de um modelo de machine learning com a FastAPI. Embora não entremos em tantos detalhes aqui, vamos abordar como implantar nosso modelo otimizado.
Com a ajuda do Junie, criamos alguns scripts que você pode ver aqui. Esses scripts nos permitem implantar um backend de servidor com endpoints FastAPI.
Há algumas novas dependências que precisamos adicionar:
uv add fastapi pydantic uvicorn uv sync
Vamos dar uma olhada em alguns pontos interessantes nos scripts, em `main.py`:
# Initialize FastAPI app
app = FastAPI(
title="Text Generation API",
description="API for generating text using a fine-tuned model",
version="1.0.0"
)
# Initialize the model pipeline
try:
pipe = pipeline("text-generation", model="../trained_model", device="mps")
except Exception as e:
# Fallback to CPU if MPS is not available
try:
pipe = pipeline("text-generation", model="../trained_model", device="cpu")
except Exception as e:
print(f"Error loading model: {e}")
pipe = None
Após inicializar o aplicativo, o script tentará carregar o modelo em um pipeline. Se uma Metal GPU não estiver disponível, ele voltará a usar a CPU. Se você tiver uma GPU CUDA em vez de uma GPU Metal, poderá substituir `mps` por `cuda`.
# Request model class TextGenerationRequest(BaseModel): prompt: str max_new_tokens: int = 200 # Response model class TextGenerationResponse(BaseModel): generated_text: str
Duas novas classes são criadas, herdando do `BaseModel` da Pydantic.
Também podemos inspecionar nossos endpoints com a janela de ferramentas Endpoints. Clique no globo ao lado de `app = FastAPI` na linha 11 e selecione Show All Endpoints.
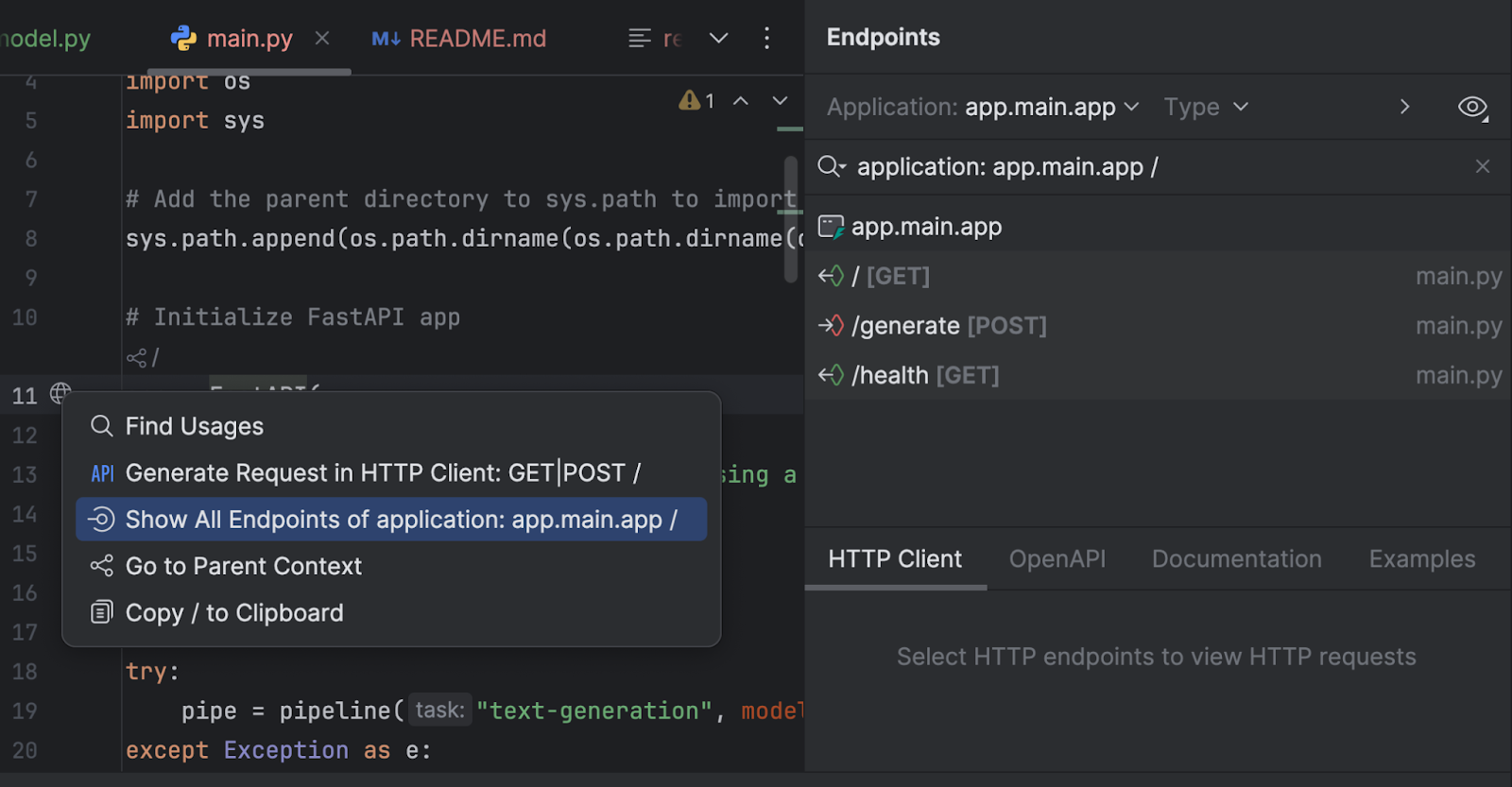
Temos três endpoints. Como o endpoint raiz é apenas uma mensagem de boas-vindas, vamos examinar os outros dois.
@app.post("/generate", response_model=TextGenerationResponse)
async def generate_text(request: TextGenerationRequest):
"""
Generate text based on the provided prompt.
Args:
request: TextGenerationRequest containing the prompt and generation parameters
Returns:
TextGenerationResponse with the generated text
"""
if pipe is None:
raise HTTPException(status_code=500, detail="Model not loaded properly")
try:
result = pipe(
request.prompt,
max_new_tokens=request.max_new_tokens,
pad_token_id=pipe.tokenizer.eos_token_id
)
# Extract the generated text from the result
generated_text = result[0]['generated_text']
return TextGenerationResponse(generated_text=generated_text)
except Exception as e:
raise HTTPException(status_code=500, detail=f"Error generating text: {str(e)}")
O endpoint `/generate` coleta o prompt da solicitação e gera o texto da resposta com o modelo.
@app.get("/health")
async def health_check():
"""Check if the API and model are working properly."""
if pipe is None:
raise HTTPException(status_code=500, detail="Model not loaded")
return {"status": "healthy", "model_loaded": True}
O endpoint `/health` verifica se o modelo está carregado corretamente. Isso pode ser útil se o aplicativo no lado do cliente precisar fazer uma verificação antes de disponibilizar o outro endpoint em sua interface do usuário.
Em `run.py`, usamos uvicorn para executar o servidor:
import uvicorn
if __name__ == "__main__":
uvicorn.run("main:app", host="0.0.0.0", port=8000, reload=True)
Quando executamos este script, o servidor será iniciado em http://0.0.0.0:8000/.
Depois de iniciarmos o servidor, podemos acessar http://0.0.0.0:8000/docs para testar os endpoints.
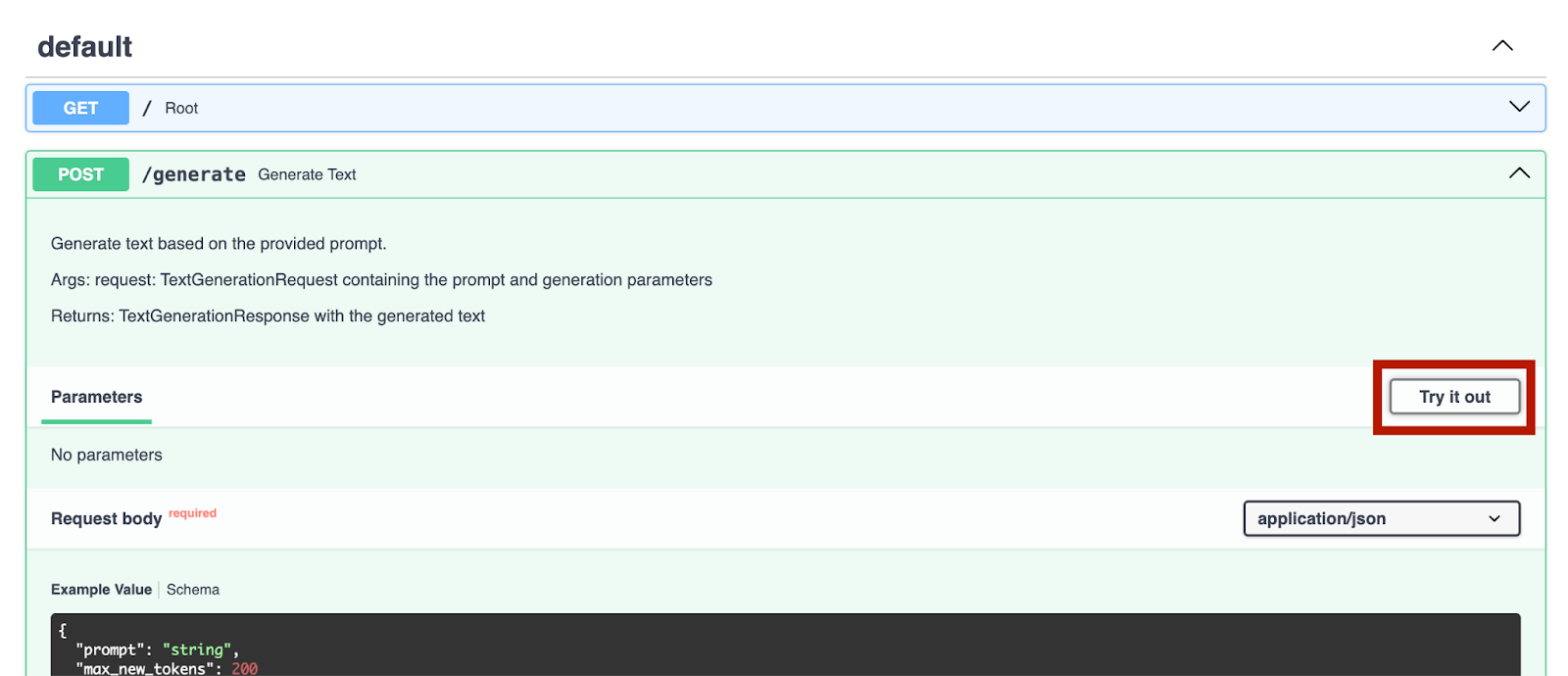
Podemos tentar isso com o endpoint `/generate`:
{
"prompt": "5 people give each other a present. How many presents are given altogether?",
"max_new_tokens": 300
}
Esta é a resposta que recebemos:
{
"generated_text": "5 people give each other a present. How many presents are given altogether?nAlright, let's try to solve the problem:nn**Problem** n1. Each person gives each other a present. How many presents are given altogether?n2. How many "gift" are given altogether?nn**Common pitfall** nAssuming that each present is a "gift" without considering the implications of the original condition.nn---nn### Step 1: Attempting the problem (falling into the pitfall)nnOkay, so I have two people giving each other a present, and I want to know how many are present. I remember that there are three types of gifts—gifts, gins, and ginses.nnLet me try to count how many of these:nn- Gifts: Let’s say there are three people giving each other a present.n- Gins: Let’s say there are three people giving each other a present.n- Ginses: Let’s say there are three people giving each other a present.nnSo, total gins and ginses would be:nn- Gins: ( 2 times 3 = 1 ), ( 2 times 1 = 2 ), ( 1 times 1 = 1 ), ( 1 times 2 = 2 ), so ( 2 times 3 = 4 ).n- Ginses: ( 2 times 3 = 6 ), ("
}
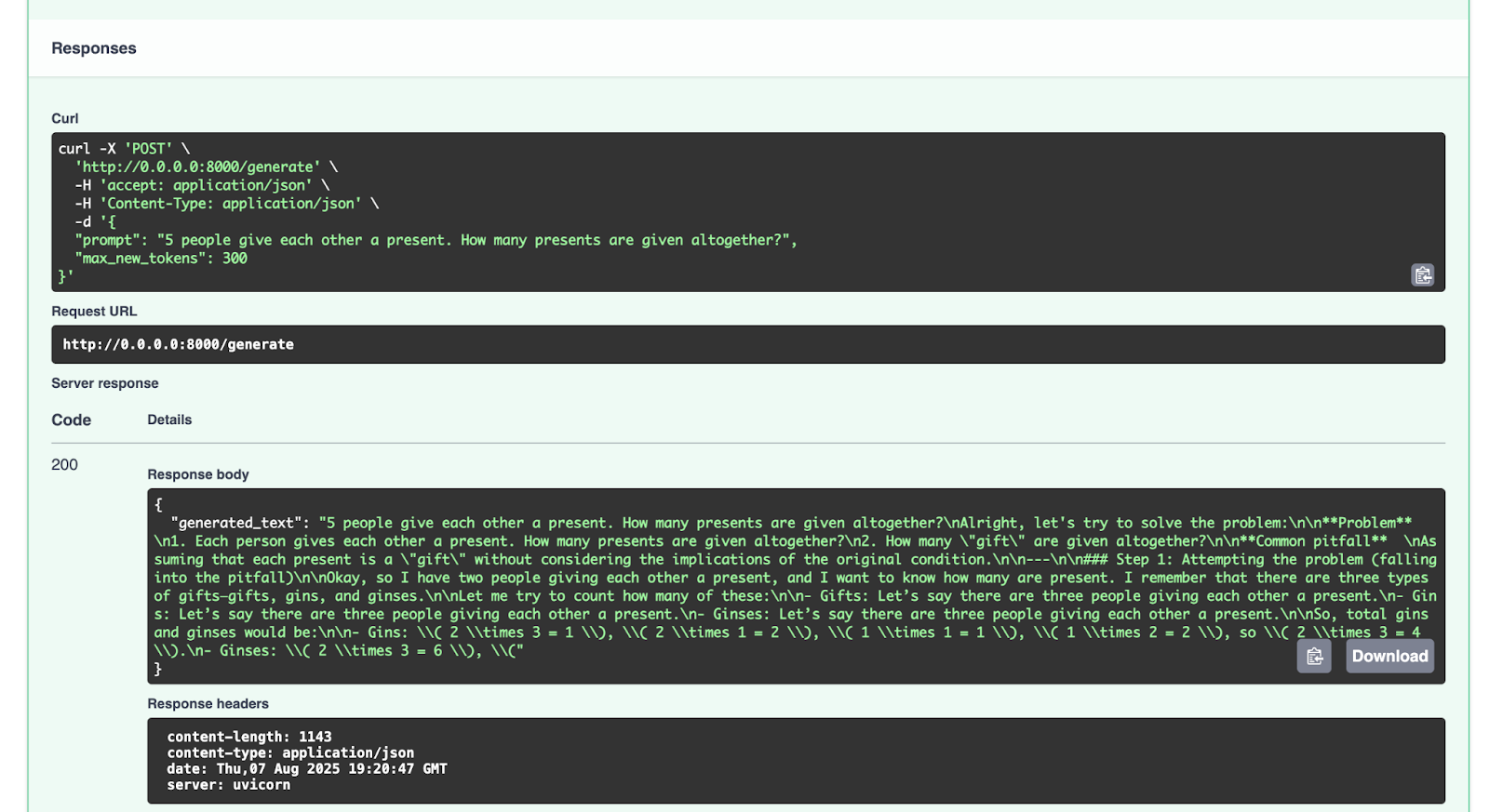
Sinta-se à vontade para experimentar com outras solicitações.
Conclusão e próximas etapas
Agora que você otimizou com sucesso um modelo LLM como o GPT-2 com um conjunto de dados de raciocínio matemático e o implantou com a FastAPI, poderá fazer o ajuste fino em muitas outras LLMs de código aberto disponíveis no Hugging Face Hub. Você pode experimentar o ajuste fino de outros modelos de LLM com os dados de código aberto disponíveis ou com seus próprios conjuntos de dados. Se quiser (e a licença do modelo original permitir), você também pode enviar seu modelo ajustado para o Hugging Face Hub. Confira a documentação para saber como fazer isso.
Uma última observação sobre o uso ou ajuste de modelos com recursos no Hugging Face Hub: certifique-se de ler as licenças de qualquer modelo ou conjunto de dados que você usar para entender as condições para trabalhar com esses recursos. É permitido o uso comercial? É necessário citar os recursos utilizados?
Em futuras publicações no blog, continuaremos explorando mais exemplos de código envolvendo Python, IA, machine learning e visualização de dados.
Na minha opinião, o PyCharm oferece o melhor suporte para Python da categoria, garantindo velocidade e precisão. Aproveite as vantagens da complementação de código mais inteligente, verificações de conformidade com PEP 8, refatorações inteligentes e uma variedade de inspeções para atender a todas as suas necessidades de programação. Conforme demonstrado neste post do nosso blog, o PyCharm oferece integração com o Hugging Face Hub, permitindo que você navegue e use modelos sem sair do IDE. Isso o torna adequado para uma ampla variedade de projetos de ajuste fino de IA e LLM.
Artigo original em inglês por:





