
JetBrains Research
Research is crucial for progress and innovation, which is why at JetBrains we are passionate about both scientific and market research
Step Rejection Fine-Tuning: Squeezing More Signal from Noisy Agent Trajectories

If you want to dive straight into the technical details, you can read our full paper here.
Imagine you are mentoring a junior developer. If they make a single logical error on line 42 of a 100-line script, do you throw away the entire file and tell them they learned nothing? Of course not. You point out the specific mistake and acknowledge what they got right.
Yet, when training large language model (LLM) agents, the standard practice is exactly that: We opt to discard the entire attempt if the final outcome isn’t perfect. In complex tasks, agents fail a lot, meaning we are constantly throwing away a massive amount of potentially valuable data.
Why is this data so valuable? Even when an agent fails to solve a task, many of its steps – such as exploring the directory structure, reading relevant files, and writing initial test scripts – are completely correct. By discarding the entire run, we throw away all of those high-quality examples of correct behavior.
To bring order to this inefficiency, our team at JetBrains Research developed Step Rejection Fine-Tuning (SRFT). It is a simple, practical technique to help models learn from their failed attempts without picking up bad habits. Our paper introducing this work has been accepted to the Deep Learning 4 Code (DL4C) workshop, co-located with ICML in South Korea this July.
In this blog post, we will:
- Unpack traditional LLM agent training and see why standard methods waste data..
- Uncover the hidden value inside unsuccessful trajectories.
- Introduce SRFT and explain how it uses a “critic” to mask harmful steps.
- Share our experimental results showing how SRFT boosts performance.
The problem with perfect trajectories
There are two main approaches to training LLM-based agents. The first is reinforcement learning, most commonly implemented using algorithms like Group Relative Policy Optimization (GRPO). In this approach, the model learns through trial and error. It receives a reward if the entire trajectory leads to a successful resolution, and is penalized if it fails.
The second approach involves knowledge distillation from a stronger teacher model. Here, a powerful (and usually expensive) model generates solutions, and a smaller student model learns to imitate its behavior. When using the distillation approach, the standard practice is Rejection-sampling Fine-Tuning (RFT). You generate a bunch of trajectories from the teacher to solve a task, throw away the ones that failed, and then train your student model only on the successful ones.
To give you an idea, a single trajectory is essentially the full conversation history of an agent trying to solve a problem. It consists of a sequence of steps where the agent reasons, takes an action (like running a command or editing a file), and receives an observation from the environment. On average, a trajectory in complex coding tasks contains dozens of such steps.
Crucially, we can usually only determine whether a trajectory was successful at its very end, as a typical trajectory concludes with the generation of a code patch. In standard benchmarks, pre-written test suites are run to verify whether this final patch resolves the original issue. Consequently, while we obtain complete, binary feedback on the success of the trajectory as a whole, we lack any test-level information regarding which specific steps taken by the agent were actually helpful, and which ones led to the incorrect patch.
Below is an example of what a stepwise-labeled trajectory looks like in practice. In the third column, SP represents system prompt, UP represents user prompt (which contains the issue description), the rows labeled with the letter A and a number represent the AI assistant step, and those labeled with the letter O and a number represent the corresponding output.
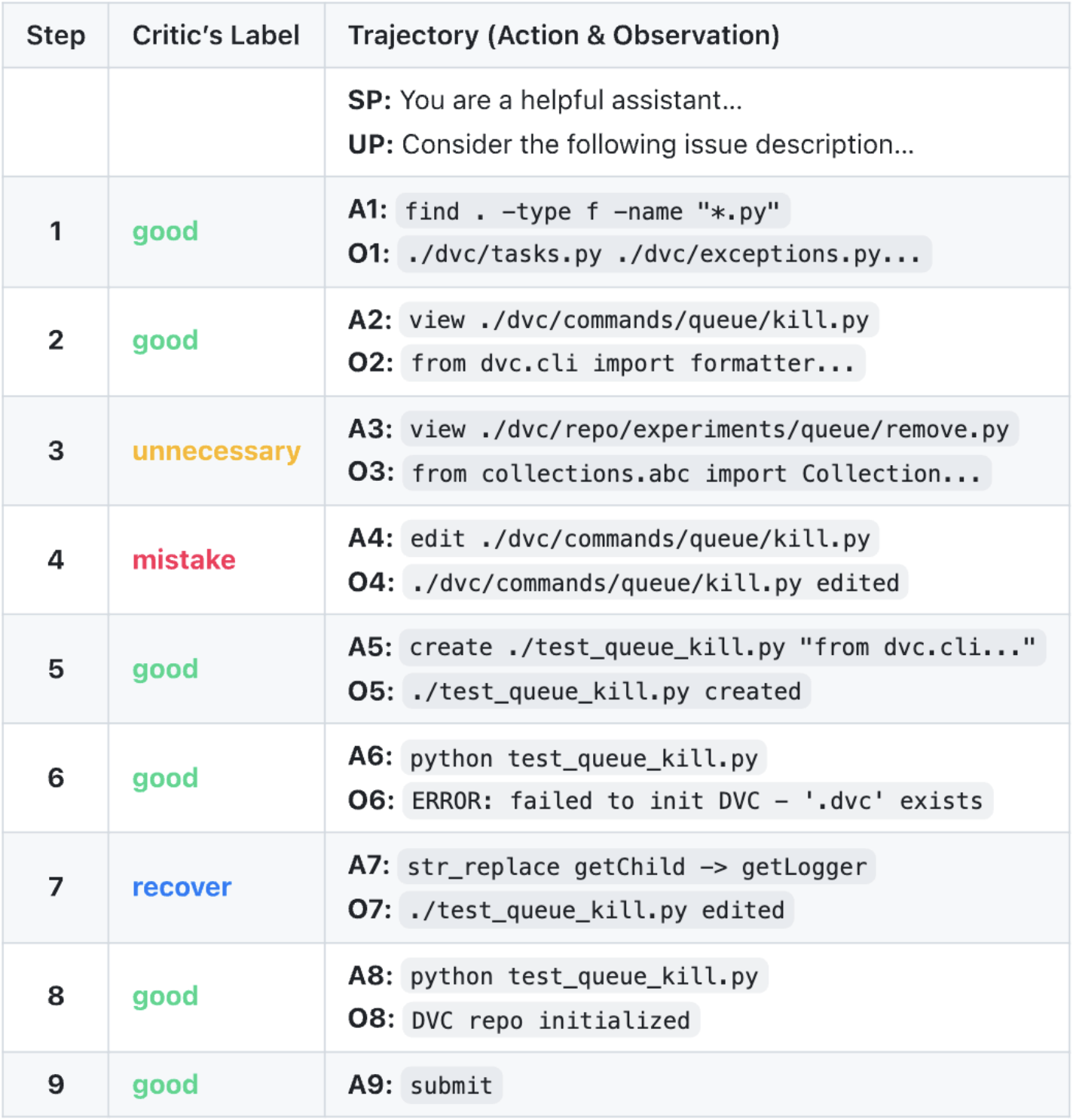
In this example, assistant Step #3 (A3) was marked as unnecessary because the agent viewed a file that wasn’t related to the bug introduced in the issue description. Step #4 (A4) was marked as a mistake because the agent started fixing code before reproducing the bug, which directly contradicts the instruction given in the system prompt (SP). Additionally, Step #7 (A7) was labeled as “recover” because it corrects an error made in Step #5 (A5) during the agent’s attempt to reproduce the bug. We chose not to label Step #5 as a mistake because the replication script created in that step was otherwise completely correct, with only a single line containing an error.
It is worth noting that this specific trajectory was successful because it ultimately resolved the bug correctly, despite doing so in a suboptimal manner. While even successful trajectories are not always completely free of errors, unsuccessful trajectories always contain harmful steps that we may identify and label as mistakes.
Because standard RFT uses only successful trajectories, it discards tons of data. For instance, the recent SWE-smith project generated a large-scale dataset of agent trajectories for software engineering tasks. This dataset was then used to train an agentic model. Because they used standard RFT, they had to discard approximately 61% of all collected runs for training. That is a huge amount of potentially informative data lost just because the final outcome wasn’t perfect.
The hidden value of unsuccessful trajectories
Our core hypothesis is that these unsuccessful trajectories are not entirely erroneous – rather, they often consist of correct and useful steps interspersed with errors.
To test this, we conducted a manual analysis of 20 failed trajectories from the SWE-smith dataset.
We discovered that even in completely failed runs, only up to 24% of the steps could actually be classified as going in the wrong direction. The remaining 76% of the steps consisted of productive exploration, codebase navigation, or harmless tool actions.
To understand how these unsuccessful trajectories can be valuable, we first need to understand why distillation, within which RFT is standard practice, works at all. When we train a student model on a teacher’s trajectories, the performance boost comes from two distinct sources:
- Learning “smart” tokens: The student learns from a much smarter, more capable model. It absorbs better ways to reason, to understand tasks, and to use the provided tools.
- Learning the path to success: By filtering only successful trajectories (as in standard RFT), we bias the model to choose actions that actually lead to a resolved task.
As mentioned above, standard RFT throws away unsuccessful trajectories because they lack that second source of improvement. In other words, they would teach the model to imitate the mistakes that led to failure.
But what if we train only on unsuccessful trajectories generated by a strong teacher model? Will it boost the model’s performance?
Before we answer this question, let’s set the stage with our experimental setup. To make things easier, we’ll present the complete table with all our results right after the experiment’s preliminaries, and then we will walk you through each experiment, starting with the answer to this very question.
We tested our approach on SWE-bench Verified, a challenging benchmark that tasks AI agents with solving real-world GitHub issues in large Python repositories. It thoroughly tests an agent’s ability to navigate codebases, edit files, and run tests.
For the training data, we used trajectories from the SWE-smith dataset to fine-tune the Qwen2.5-Coder-32B-Instruct model, running all the experiments on the SWE-agent scaffold. To filter out the random noise of individual runs and ensure our conclusions are reliable, we repeated each experiment seven times. For more details on the methodology, see our paper.
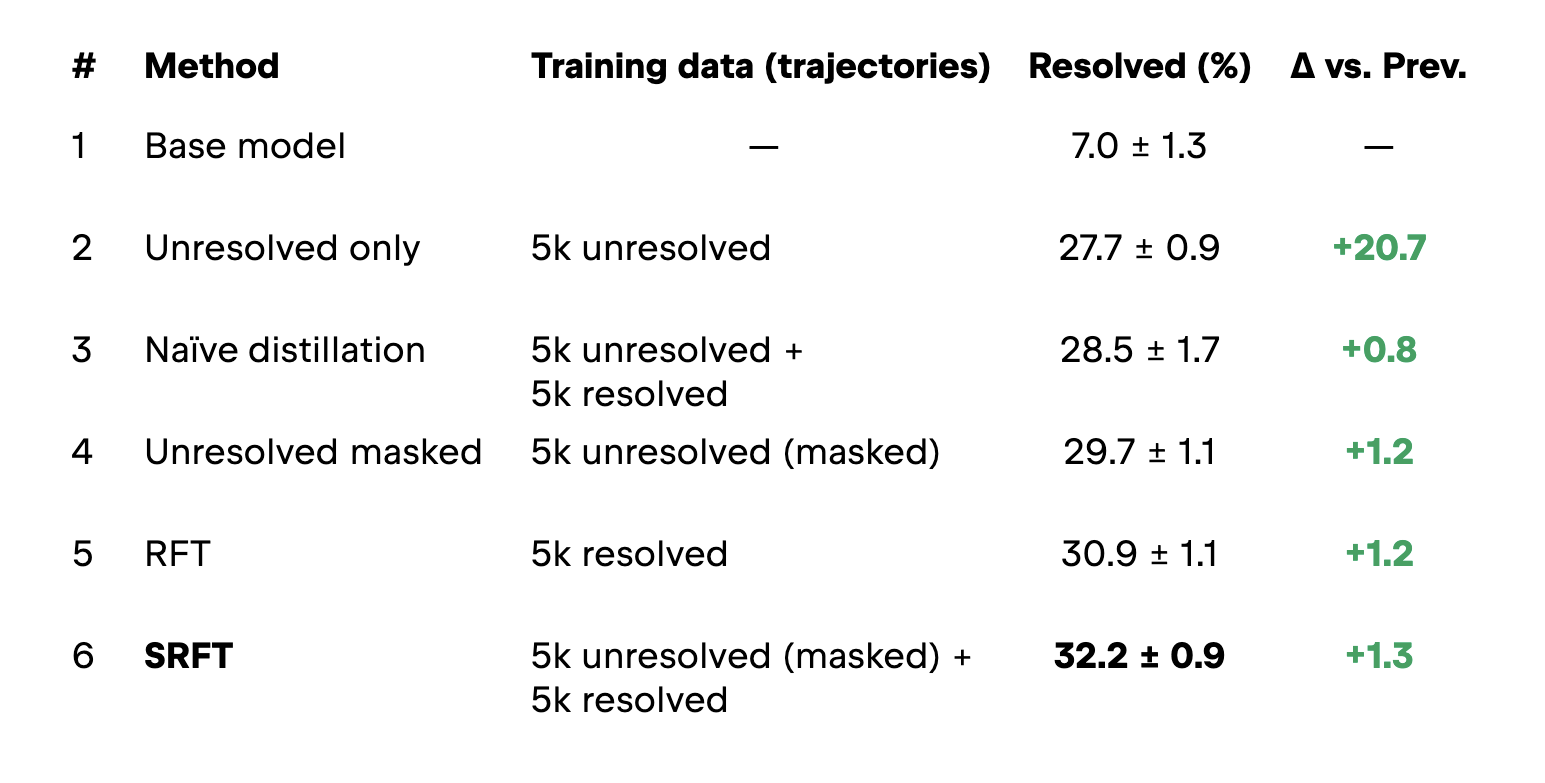
The table below shows the results of our experiments. The Training data column indicates which part of the SWE-smith dataset was used to fine-tune the model; each subset is built from pools of 5,000 resolved, unresolved, or unresolved (masked) trajectories, used either individually or combined. The Resolved column shows the resolved rate across 500 SWE-bench Verified tasks averaged over the seven consecutive runs, along with the standard deviation. The experiments are sorted in ascending order of this main metric. Consequently, the Δ vs. Prev. column represents the improvement in the main score over the previous row.
Now, let’s look at the results to answer our question about whether training on unsuccessful trajectories actually helps.
As it turns out, yes! Because of the first source of improvement (learning “smart” tokens), even unsuccessful trajectories significantly boost the model’s performance! As you can see in the table above, when training only on unsuccessful trajectories (Experiment #2) the resolution rate jumps from the base model’s 7.0% up to 27.7%. The student is still learning how to use tools like the smart teacher, even if the final patch of a failed run didn’t resolve the issue.
Okay, so we got 27.7% using only unresolved trajectories. But we also have resolved trajectories at our disposal. What happens if we add them to the mix?
As you can see in Experiment #3 (Naïve Distillation), simply combining 5,000 unresolved and 5,000 resolved trajectories increases the resolution rate to 28.5% (a modest 0.8% boost). While there is a slight improvement, the added benefit is quite small.
Now, look at Experiment #5 (RFT, or Rejection-sampling Fine-Tuning), where we train the model only on the 5,000 resolved trajectories. It achieves 30.9%, which is better than mixing them with unresolved ones. This is the core philosophy behind standard RFT: You should only train on successful, high-quality trajectories and discard the unsuccessful ones, because adding failed attempts back into the mix actually degrades the model’s performance.
Yet, we can clearly see that unsuccessful trajectories still hold massive potential. They genuinely teach the model useful skills, as demonstrated by the huge boost in Experiment #2. Is there a way to extract this valuable information from failed runs while avoiding steering the model toward making mistakes?
As it turns out, there is! This is exactly what Experiment #6 (SRFT) is all about. As you can see in the table, SRFT outperforms standard RFT (32.2% vs. 30.9%), yet it relies on a remarkably simple trick.
Step Rejection Fine-Tuning
So, how do we extract the good parts of a failed attempt without having the model learn the bad parts?
Our solution, Step Rejection Fine-Tuning (SRFT), works as follows. We use another LLM as a “critic” to analyze unsuccessful trajectories step by step. The critic’s job is to diagnose each action and flag which steps were actually harmful (like introducing a bug or going down a completely wrong path) and which steps were productive.
Labeling these steps with a critic model is incredibly cheap compared to the massive compute and API costs required to generate the agent trajectories in the first place. This is because the critic analyzes the entire trajectory in a single pass (requiring just one model call), and its output is extremely concise – simply a list of step numbers with their corresponding labels: good, unnecessary, mistake, or recover.
Now that we have labels for each step, how do we actually use them?
In theory, there are several ways to handle this. We could take a prefix of the trajectory – training the model only on the initial good steps and cutting it off at the first mistake. Alternatively, we could modify and transform the trajectory by completely removing the mistake steps to create synthetic, “clean” trajectories.
But there is a much simpler and more elegant approach: we can just skip calculating the training loss on the mistake steps.
Why is this method superior? First, we don’t generate any synthetic data, which means we avoid inventing artificial scenarios that never actually happened. Second, the model still sees the entire trajectory and learns from the full context, but we simply don’t train it to predict the tokens inside the mistake steps.
This means the model sees the mistake happen in the context, but it isn’t trained to reproduce it. Furthermore, if the agent managed to recover from that mistake later in the trajectory, the model will actually learn how to perform that recovery!
From a technical perspective, during training, we “mask” the tokens inside these mistake steps so they don’t contribute to the training loss. If you are familiar with standard next-token prediction training, masking is a very common technique. For example, user messages (prompts) are usually masked so the model doesn’t learn to predict them, while the assistant’s responses are not masked. We aren’t doing anything overly complex here; we are simply applying this standard masking technique to specific, harmful steps of the assistant. During training, we mask the loss for this specific mistake step, while keeping the rest of the steps intact.
Referring back to our example trajectory above, this means that while Step #4 (A4) will not have its loss calculated, it will still remain in the context when the model calculates the training loss for the subsequent Steps #5, #6, #7, #8, and #9.
It is also worth noting that this masking approach works incredibly well even if you apply it only to unsuccessful trajectories. This brings us to the only remaining experiment in our table that we haven’t discussed yet: Experiment #4 (unresolved masked).
As you can see, training only on 5,000 unresolved trajectories with masked mistake steps yields a 29.7% resolution rate. This is actually better than naïvely mixing 5,000 unresolved and 5,000 resolved trajectories together (28.5%)! This means you can take purely unsuccessful trajectories, filter them with a critic, and still get a massive performance boost. Of course, if you already have successful trajectories, you should definitely include them in the training mix. But it was highly encouraging to see that our step-masking approach delivers such strong results even in a failed-runs-only scenario.
Conclusion
Step Rejection Fine-Tuning (SRFT) offers a practical way to squeeze more value out of your training data. Instead of throwing away hard-earned trajectories just because they didn’t perfectly solve the task, we can use a critic to filter out the noise and learn from the signal.
Of course, the exact benefit depends on your specific task, the ratio of successful to unsuccessful trajectories you have, and how well your critic model can identify the harmful steps. The strictness of your critic is a crucial balance to strike:
- If the critic is too lenient, you might leave harmful steps in the training data, which will degrade the model’s quality (similar to the naïve mixing approach).
- If the critic is too strict, you throw away too many potentially useful steps, losing the benefit of including unresolved trajectories in the first place.
This strictness is usually determined by the critic’s prompt. Alternatively, you can ask the critic to output a confidence score for its judgment and filter steps based on a specific threshold. Either way, this balance needs to be tuned for each specific dataset. But overall, once tuned, it’s a straightforward technique that can noticeably improve your agent’s performance.







