JetBrains AI
Supercharge your tools with AI-powered features inside many JetBrains products
Complete the Un-Completable: The State of AI Completion in JetBrains IDEs

Code completion has always been a standout feature in JetBrains IDEs, helping developers code faster, smarter, and with fewer mistakes. But what if it could do even more? What if it could predict not just the next element but entire lines of code – or even complete blocks? That’s exactly what we’ve been working on.
As we’ve invested time and effort into AI, our code completion has evolved into something incredibly powerful – more precise, faster, and smarter than ever.
In this blog post, we decided to share what stands behind AI code completion in JetBrains IDEs, how it has evolved over time, and what exciting developments are on the horizon. Let’s go!
What is JetBrains AI code completion?
JetBrains offers two ways of delivering AI code completion:
- Local Full Line Code Completion built into JetBrains IDEs: This works directly on your machine, providing real-time suggestions without requiring an internet connection, which ensures that the suggestions are quick and cater specifically to your project context.
- Cloud-based AI code completion provided by JetBrains AI Assistant: This uses cloud resources to offer more precise code completion, leveraging greater computational power than local resources can provide.
Together, these two approaches ensure you get both quick, context-aware suggestions locally and more powerful, cloud-driven assistance when needed.
Our approach prioritizes both the quality and speed of the suggestions. We recognize that developers need quick and accurate completions to maintain their flow. As such, we designed our system to be less noisy and distracting. Unlike tools that bombard you with overwhelming multi-line completions, our AI completion is calibrated to offer concise, relevant suggestions right when you need them.
It’s been a year – how is Full Line Code Completion doing?
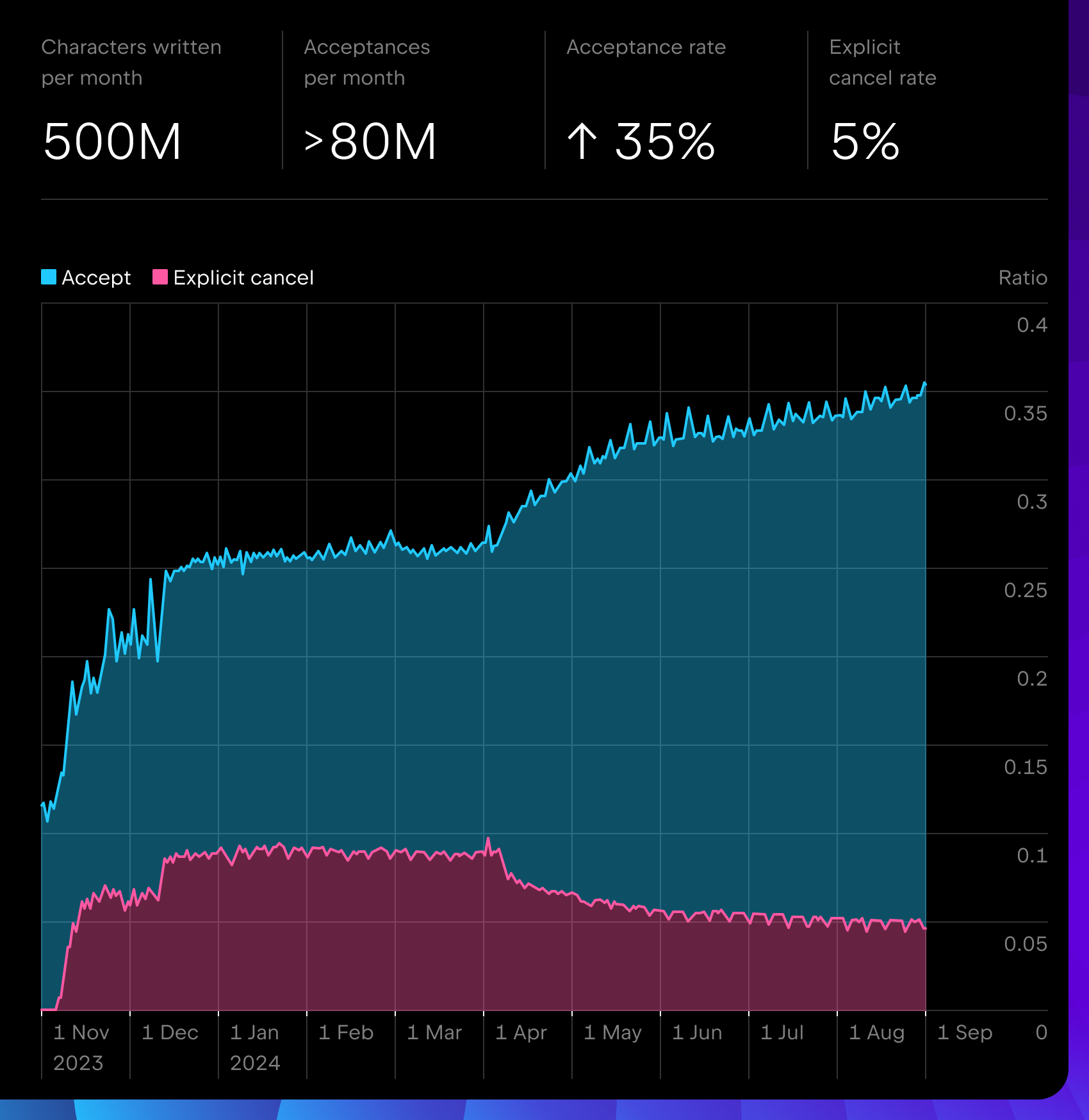
Following the milestone releases in 2023.3 and 2024.1, our metrics have remained stable and continue to grow, showing millions of completions per day, an acceptance rate of 35% or more, and an explicit cancel rate of just 5%, making it one of the best-performing code completion products for IntelliJ-based IDEs. It is available out of the box for more than 11 major languages and multiple frameworks with lightweight local models.
The 2024.2 release was mainly UX-oriented for Full Line Code Completion, extending the whole pipeline. However, we also improved quality and red code filtering. Additionally, we released support for Rider, CLion, RustRover, and Terraform.
What about cloud-based AI code completion?
There’s too much to say about this topic to cover it all, so we’ll just try to summarize the key user feedback we received before discussing how we can overcome the issues they’ve identified.
- Limited suggestion frequency
In the previous release, we took a conservative approach to code completion, triggering it only when the user pressed Enter. This design was due to the demands of an extensive LLM, which required significant processing time. However, we realized that this approach was insufficient because users don’t press Enter frequently during their coding process. Fun fact: On average, a developer only presses Enter ~70 times a day. - Hard to read big chunks of gray multi-line suggestions
Imagine you’re writing a small, simple function, and the completion suggests a very large block of code, making it difficult to see the next line after the caret. Longer completions can take more time to review and integrate, which may disrupt the workflow. - Unpredictable suggestions
In addition to everything mentioned above, the model sometimes produced suggestions that were not fully aligned with user expectations. While many were accurate, there were cases where it offered extended enumeration variable creations, made mistakes in the middle, or responded more conversationally. Extensive LLMs take several seconds to generate suggestions, leading to noticeable delays. Code completion must be rapid and responsive for an efficient experience.
So, how did we fix it?
We went for the good ol’ “rewrite everything from scratch” approach, of course. We are developers, after all! ?

Jokes aside, we did indeed decide to completely rewrite cloud completion using the IDE-side pipeline from our Full Line Code Completion with new JetBrains in-house LLMs specifically trained for code completion. It was a rough ride, but we managed to implement fixes for all of the issues above! ?
Starting from the 2024.2 release of AI Assistant for IntelliJ-based IDEs, we introduced a reworked pipeline and a new in-house LLM:
- For Java, Python, and Kotlin, starting from 2024.2
- For Go, starting from 2024.2.1
- For PHP, JavaScript/TypeScript, CSS, and HTML, starting from 2024.2.2
We’re going to switch all languages to an advanced pipeline and new model in 2024.3.
Here are some of the fundamental changes we’ve implemented:
Highlighting instead of gray text
To simplify reading large blocks generated by our models, we now highlight the suggested code. This change is designed to reduce the cognitive load on developers. By using syntax-aware highlighting, the suggestions now mirror the look and feel of your handwritten code, making them easier to scan and evaluate at a glance.
Smarter and faster JetBrains in-house LLMs
While large models are often better at handling a variety of tasks, a tailored code model will perform better on specialized tasks. They also offer benefits like more control, no need for prompt engineering, and much lower latency. This has proven true for us as well. By training a relatively small, highly specialized model and enhancing inference mechanisms, we’ve significantly improved code completion accuracy and speed. Stay tuned for upcoming posts where we’ll share more details about this model.
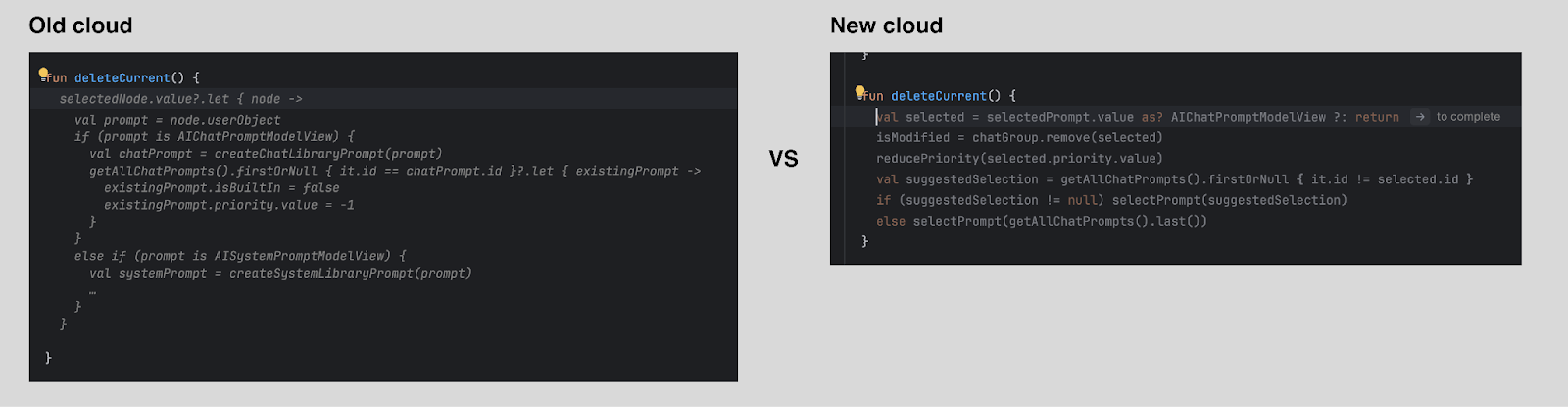
More locations and careful single-/multi-line selection
To increase the number of shown suggestions, completion is now triggered during typing, not only on Enter keystrokes. We’ve also limited locations where multi-line completion can be shown. By adopting a more conservative, language-dependent strategy, we’ve ensured that our cloud-based code completion remains intuitive and user-friendly while keeping the same total amount of generated code. We are committed to refining this strategy and expanding its capabilities in future updates.
Reworked multi-line completion UX
We completely reworked how multi-line suggestions are shown, especially in combination with in-IDE popup completions (previously, this wasn’t even possible).
Partial acceptance
This is something our users have been asking about for a while! You can now accept completion suggestions token by token or line by line.
- Accept word by word – ⌥ → / Alt + Right.
- Accept line by line – ⌘ → / Ctrl + Right.
- As before, you can explicitly call completion with ⇧ ⌥ / / Shift + Alt.

Improved project awareness and reworked context collection
With offline and online evaluations in place to assess different retrieval-augmented generation (RAG) strategies, we chose the one that works stably and predictably. Suggestions now utilize the context of the entire project to offer relevant, high-quality blocks of code. Having full control over inference has allowed us to prevent small inconsistencies like incorrect indentation and to filter out undesirable suggestions.
Is the new cloud completion good?
Pretty good, yeah!
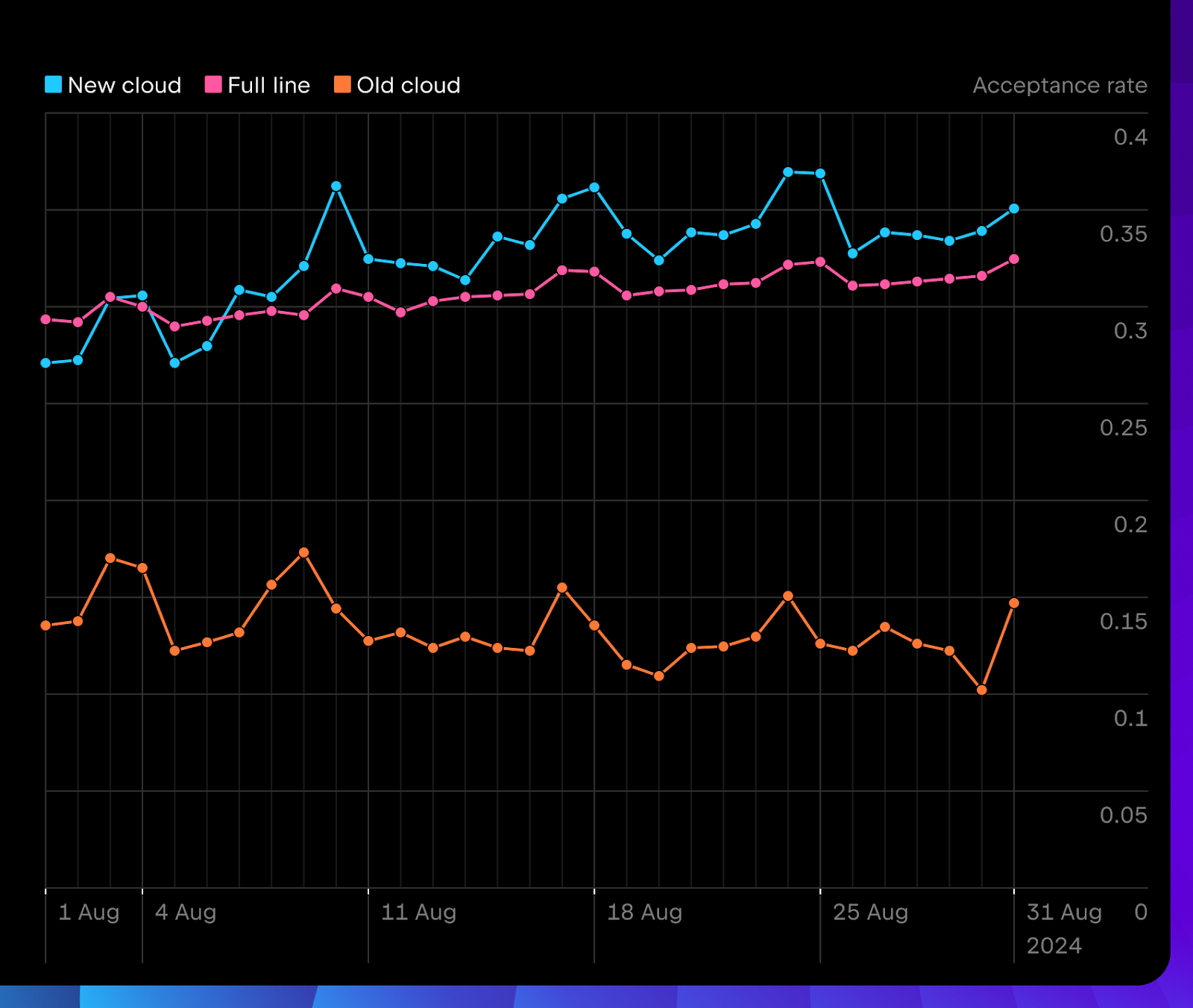
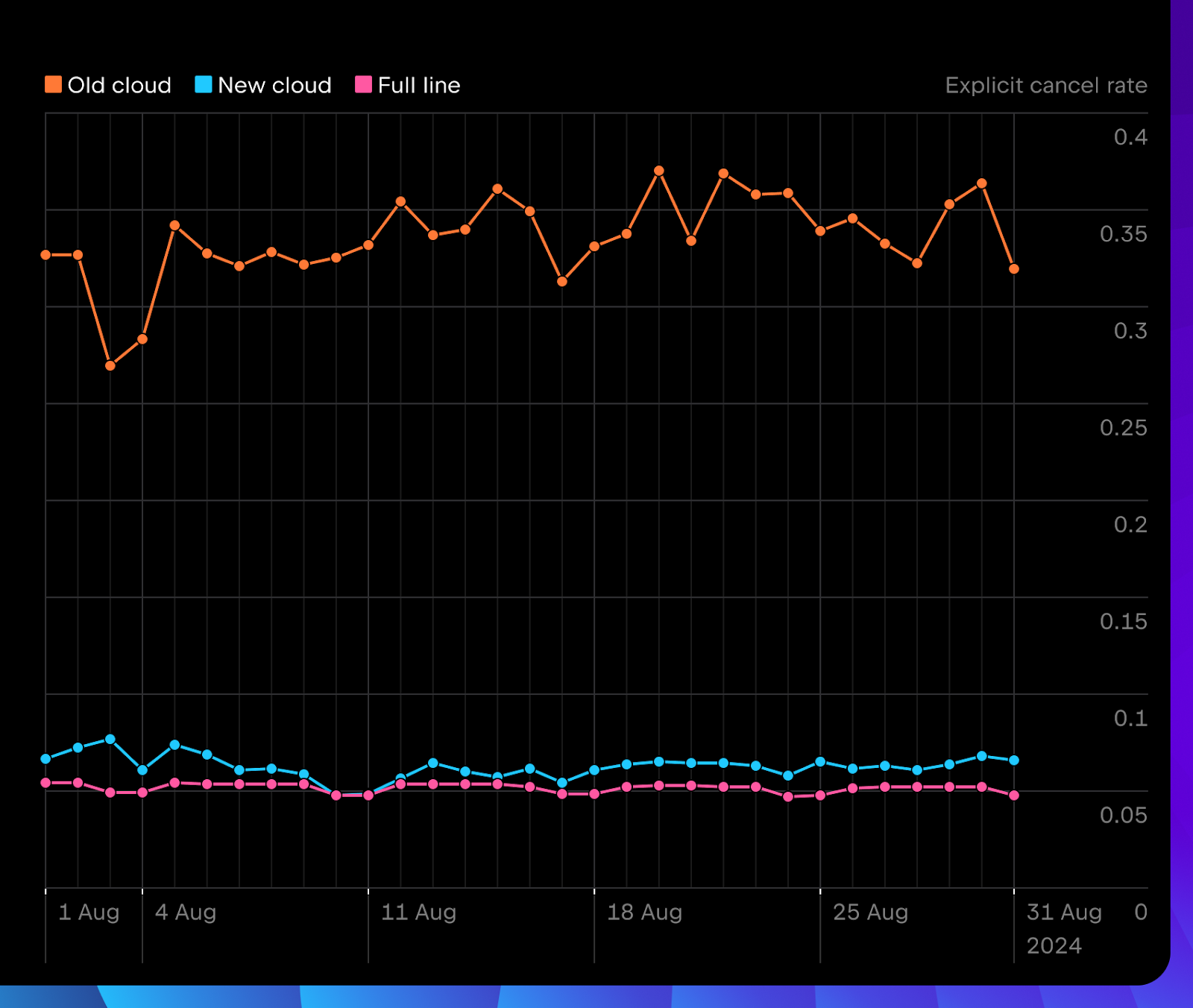
There’s nothing better than online logs. Based on data collected over August 2024, we’re already seeing some positive results through user feedback and usage metrics. Let’s take a look at three different setups for Java, Python, and Kotlin:
- The old version of AI cloud-based code completion in JetBrains AI Assistant 2024.1
- The new version of AI cloud-based code completion in JetBrains AI Assistant 2024.2
- Local Full Line Code Completion in 2024.2
This comparison only gives approximate results. Moreover, full line is single-line only, and AI Assistant is both single- and multi-line.
The acceptance rate for new cloud completion is generally higher than full line, consistently outperforming old cloud completion.
Users explicitly cancel new cloud completion much less often than before.
The overall completion latency, from the moment you start typing to when the suggestion is rendered, has significantly decreased compared to the old system.
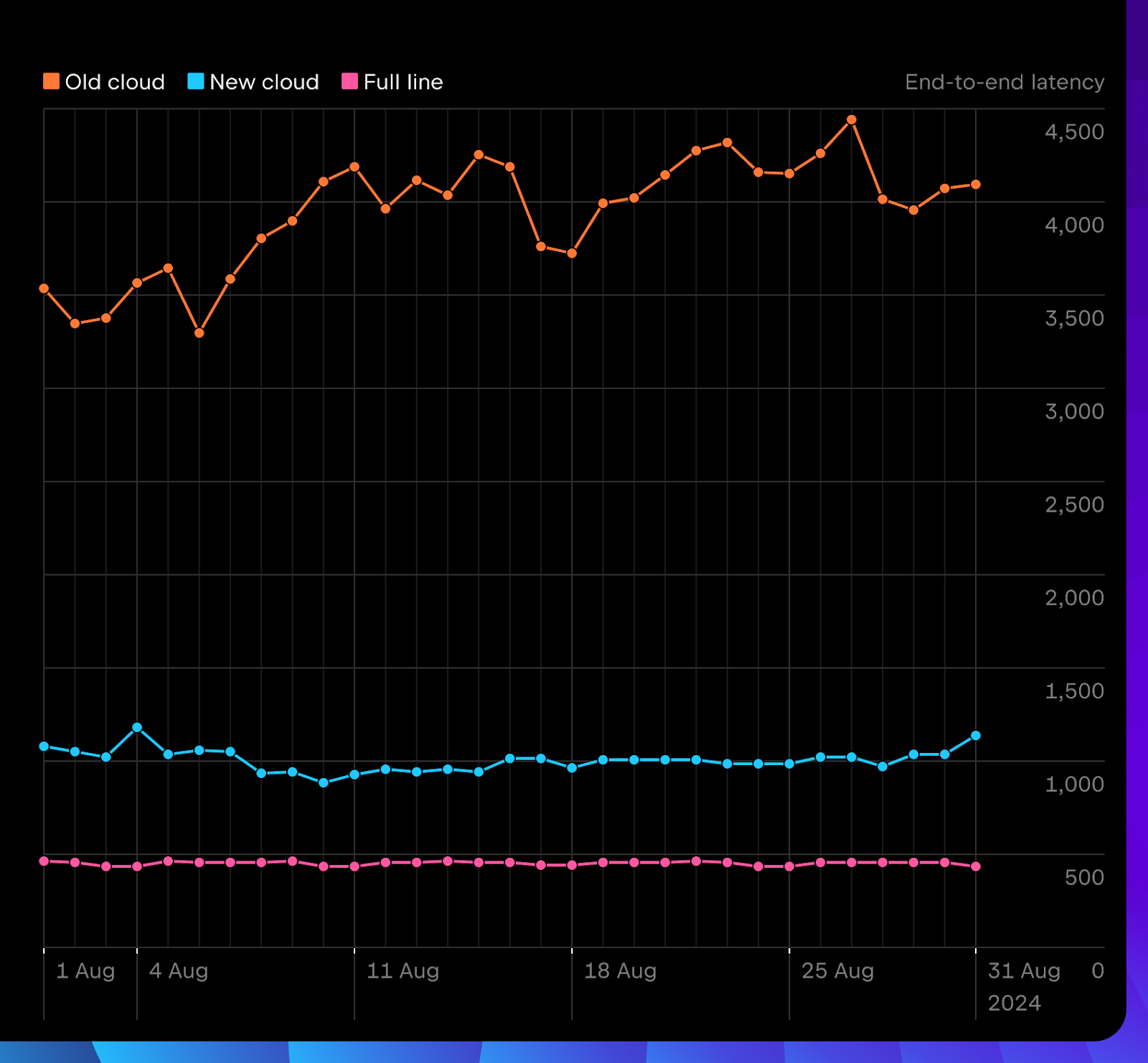
The daily number of shown completions in 2024.2 is already much higher than in the 2024.1 release. It consistently outperforms much faster local models by suggesting more relevant proposals.
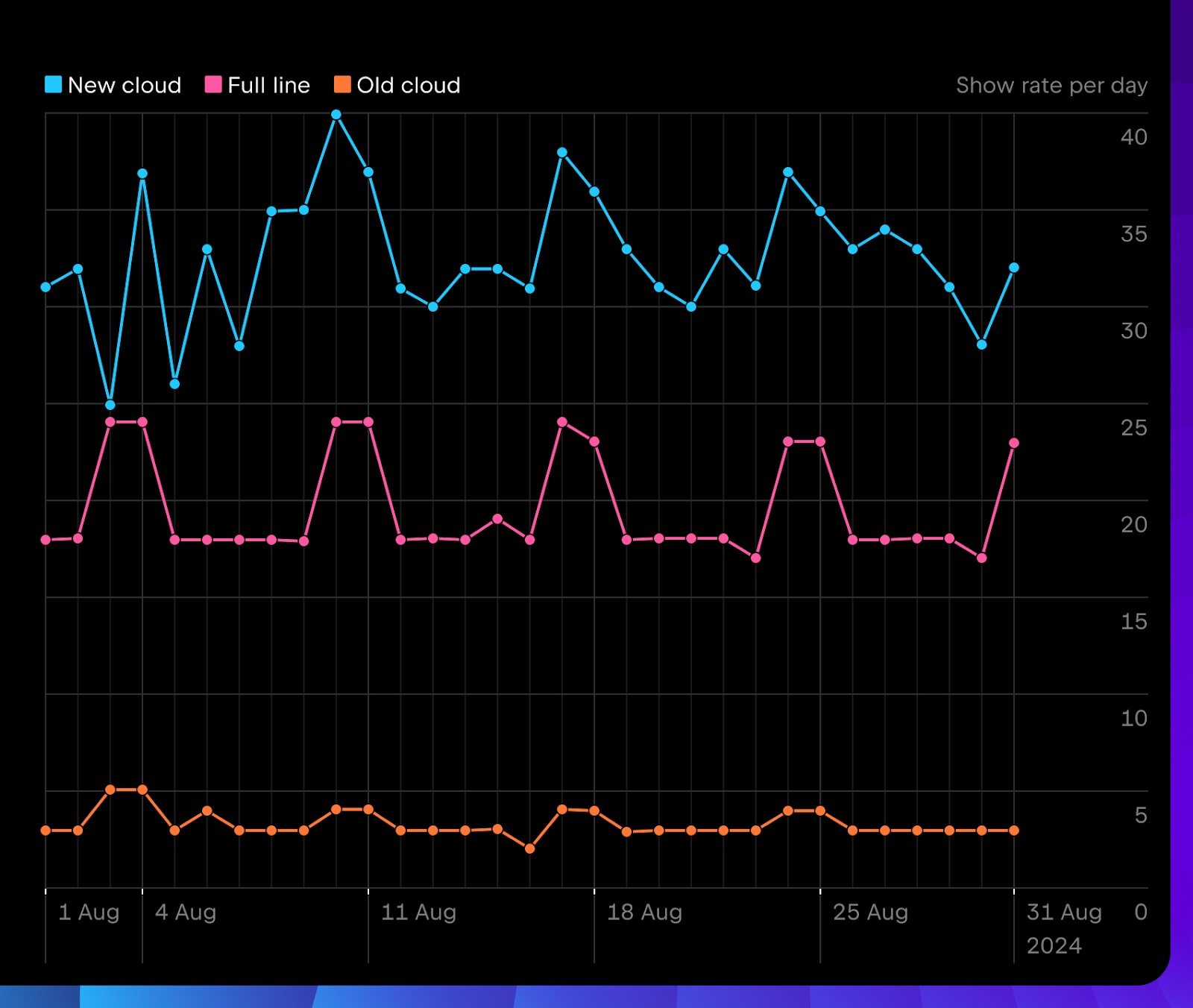
However, the average length of completion was intentionally reduced for the new cloud completion. We suggest multi-line completions much more carefully, ensuring we don’t disturb you while you read the code or think about the solution. We plan to gradually introduce more locations for showing multi-line suggestions after thoroughly confirming they are viewed positively during our testing.
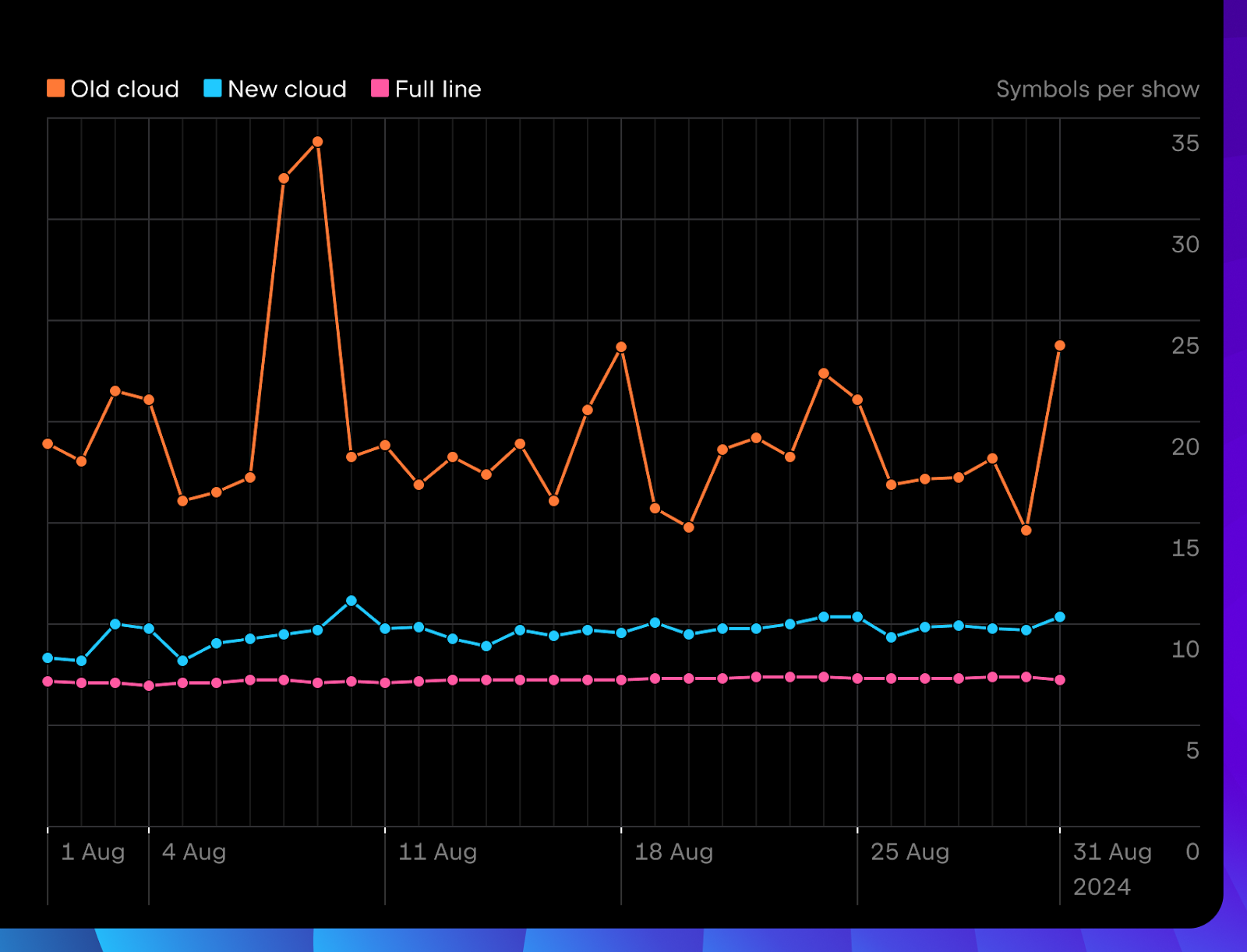
You can already try the new completion in 2024.2 IntelliJ IDEA, PyCharm, WebStorm, and GoLand. In the next release, we’ll focus on solving the “Tab shortcut clash” with non-AI completion, relaxing strict filtering, multi-line quality and quantity, triggering positions, and adapting the amount of code in suggestions. We’ve been hard at work, and you can check out the updates in the EAPs for the 2024.3 release!
What’s next?
We’ll continue to push our local and cloud completions, adding more multi-line suggestions for cloud, introducing multi-lines to local, supporting more languages, improving the quality of models, enhancing the UX, and much more.
I also want to thank everyone who has submitted feedback and reported issues – your contributions have directly shaped the improvements and features. Thank you, and please keep the feedback flowing! You can share your thoughts in the comments to this blog post, on the AI Assistant plugin page, or on YouTrack.
The JetBrains completion crew ❤️