Refactoring in C++: Top Techniques and Best Practices

Whether you’re a seasoned C++ developer or just starting out, refactoring is a key way you can make your code cleaner, more efficient, and easier to maintain. In this article, we’ll review common refactoring techniques in C++ and explore their benefits, from improving code readability to reducing technical debt. We’ll also look at the main challenges you’ll need to overcome and best practices to follow in order to ensure that you get the most out of refactoring. So, grab a cup of your favorite beverage, make yourself comfortable, and let’s see how you can make your code sparkle!
What is refactoring?
Refactoring in software development involves reorganizing existing source code to improve it without creating new functionality. It includes various techniques such as renaming variables and methods, deleting unused parameters, extracting functions, and more. Which technique to use in a given situation depends on what you’re trying to achieve, whether fixing performance issues, reducing technical debt, or resolving a combination of several problems.
Refactoring offers the following main benefits:
- More readable code: When you simplify tricky parts of code, use clear names for variables and functions, and organize everything logically, your code becomes easier to read.
- Enhanced performance: When you optimize algorithms, enhance data structures, and cut out extra computations, you get faster and more efficient code that uses fewer resources.
- Easier maintenance: When you split large functions and methods into smaller, more manageable ones and remove any redundant code, you make your codebase easier to maintain.
- Reduced technical debt: When you clean up code smells, such as duplication and overly complicated logic, you make it easier to avoid problems down the line.
Refactoring can be done manually or automatically. Manual refactoring is when, for example, you search for a specific piece of code in an IDE or a simple code editor and then rewrite that code. This works fine if your codebase is small, or if you need to fix a local problem in a specific block of code. However, most modern production-grade codebases contain hundreds of thousands of lines of code and are difficult to refactor manually.
Auto-refactoring, on the other hand, is a feature provided by advanced IDEs such as CLion. It allows you to refactor a codebase of any size quickly and on a large scale. Such IDEs free you from manual work, which is invaluable in large real-world projects.
Specifics of C++ refactoring
Refactoring code in C++ is challenging because there are roughly ten different ways to do one thing. The language has complex grammar, elaborate scoping rules, and a wealth of language constructs and features, making it hard to parse correctly. This means that the IDE you use for refactoring must understand all of these language peculiarities and corner cases well enough to be genuinely helpful and ensure it doesn’t introduce new bugs during refactoring.
Even experienced C++ developers can forget some nuances of the language. A good IDE needs to know C++ inside and out to ensure developers don’t miss something when refactoring their code. This makes auto-refactoring an indispensable IDE feature for every C++ developer.
Common refactoring techniques in C++
Common C++ refactoring techniques include renaming variables and functions, simplifying conditional statements, extracting functions, and removing code duplication. Below is an overview of several refactoring examples performed in CLion with the CLion Nova engine enabled. To try these techniques as you read, download CLion using the link below.
Renaming variables and functions
Changing the names of variables and functions is a basic refactoring technique that improves code clarity and maintainability. You can apply this refactoring locally, such as in one function, or throughout your project, which can include multiple .cpp and .h files.
Here are the main advantages of renaming:
- Improved readability: Clear and descriptive names help you and other developers understand the purpose of variables and functions. For example, renaming a
datavariable touser_datagives more information about the purpose of the variable.
- Ongoing accuracy: As code changes, timely renaming aligns names with their actual functionality, making the codebase more intuitive and easier to understand. So, if a function has calculated a user’s payment and now calculates a user’s fee, it’s better to reflect that in the function name.
- Compliance with naming conventions: Different teams and companies use different naming conventions, such as snake_case or camelCase. Renaming variables and functions to conform to these conventions improves consistency throughout the codebase.
As for renaming in an IDE, the major benefit of this technique is that an IDE updates a symbol – method, function, class, field, etc. – not just text.
You can also use a simple code editor to rename variables or functions by search and replace, but it will break code that uses the same names for different symbols in different scopes. This doesn’t happen in an IDE.
In the example below, we rename a macro from FMT_RTR to FMT_RETRY in order to improve code readability. Notice how the IDE handles this renaming throughout the project: It changes the name in all the scopes and files the macro is used in.
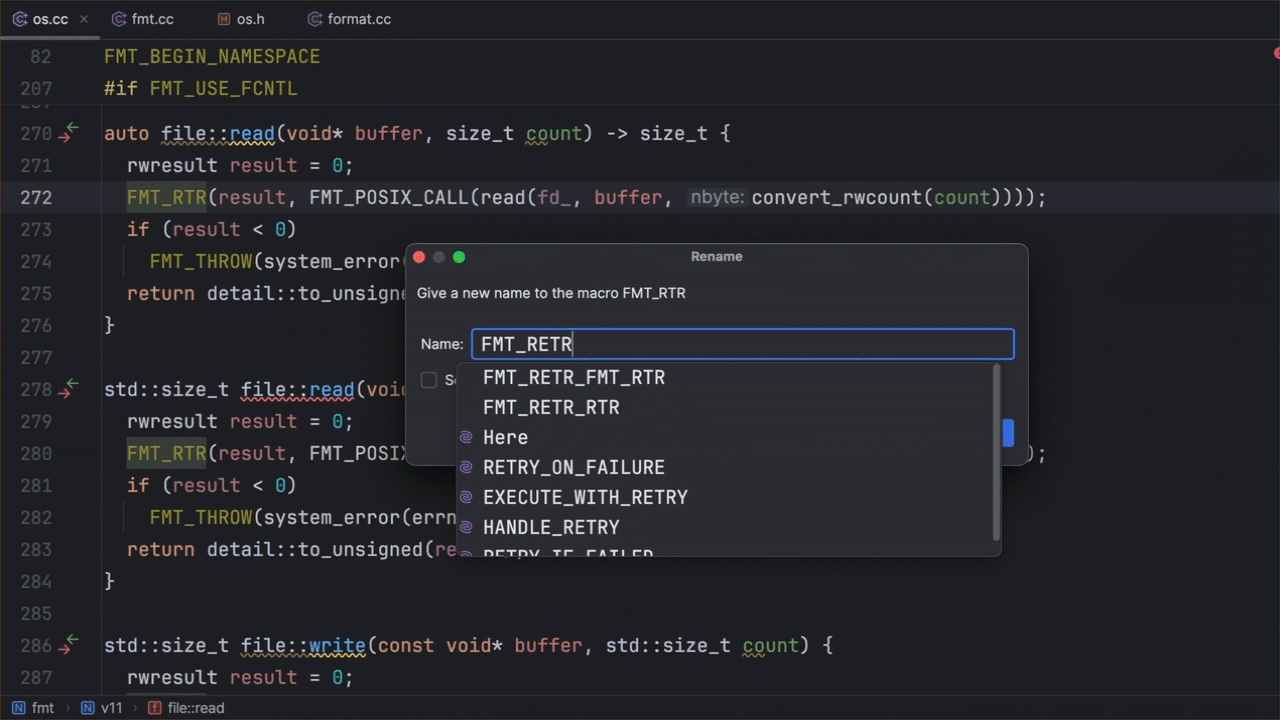
Figure 1: Renaming a macro to improve readability
Extracting functions
Extracting a function entails isolating a block of code that performs a specific task – for example, within a function – and creating another function from it. The main reasons for extracting functions are to:
- Reduce complexity: By breaking large functions into smaller ones, you improve code readability and make it easier to understand program logic.
- Facilitate testing: When you split your code functionality into separate functions, you can create unit tests for each and improve test coverage.
- Simplify maintenance: Encapsulating functionality into individual functions makes it easier to update code. If you need to modify a particular behavior in your code, you change only the relevant function, leaving the rest of the code untouched.
Here is an example of transforming a block of code that performs various math calculations into a separate function, calculate_basic_operations:
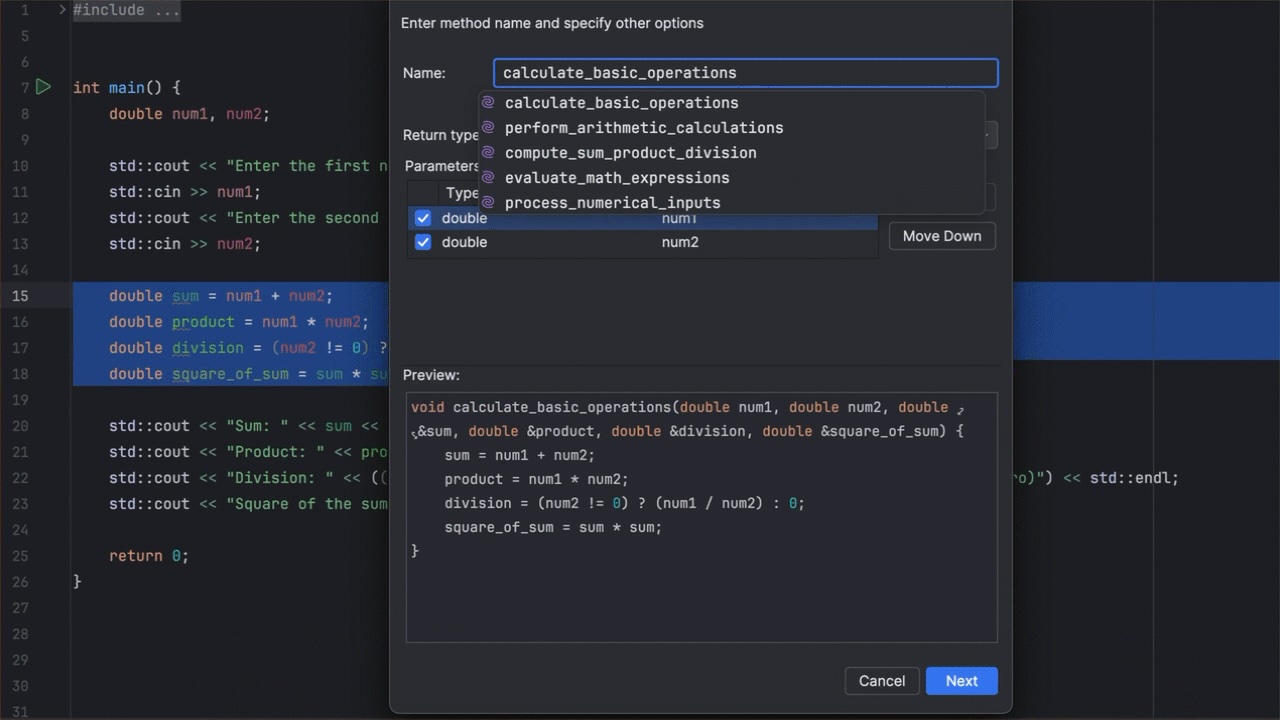
Figure 2: Extracting a code block into a separate function
In CLion Nova, this refactoring feature is called Extract Method, but functionally speaking, it has the same effect as extracting a function.
Simplifying conditional statements
To make conditional statements simpler, we typically refactor if-else and switch statements. Key benefits of such an approach include:
- Improved logic: Sometimes, changing a sequence of
if-elsestatements makes the logic clearer to new developers unfamiliar with a codebase. - Reduced redundancy: If multiple conditional statements give the same result, it’s better to combine them into a single statement. This helps eliminate duplication and reduce code size.
- Enhanced performance: Eliminating calculations on unnecessary statements speeds up code execution. This technique is particularly useful for performance-critical projects.
Here is how to change the order of if-else statements in CLion using the Invert “if” statement action:
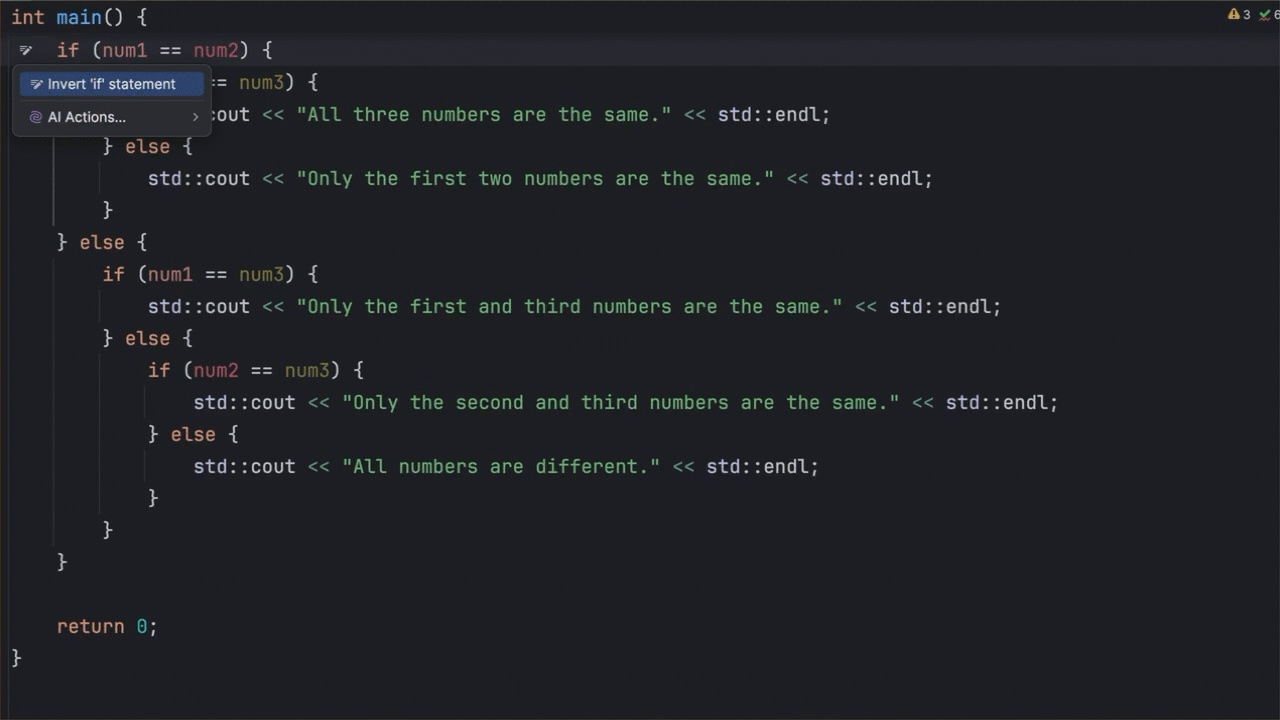
Figure 3: Simplifying an if-else statement
Optimizing loops
When you optimize loops, you usually cut down the number of iterations and simplify internal dependencies. The benefits of this technique are:
- Enhanced performance: Loops, especially nested ones, are common performance sinks. To mitigate this effect, you can reduce loop iterations, simplify conditions, and avoid unnecessary computation.
- Improved readability: Breaking down complex loops into smaller, well-named functions clarifies intent and simplifies management for future developers.
- Reduced code duplication: When you extract common functionality into separate methods or functions, you eliminate code repetition, improve maintainability, and reduce the potential for errors.
In the example below, a for loop is optimized by changing an index-based loop to a more readable range-based loop, removing a redundant else statement, and converting a local variable to a constant:
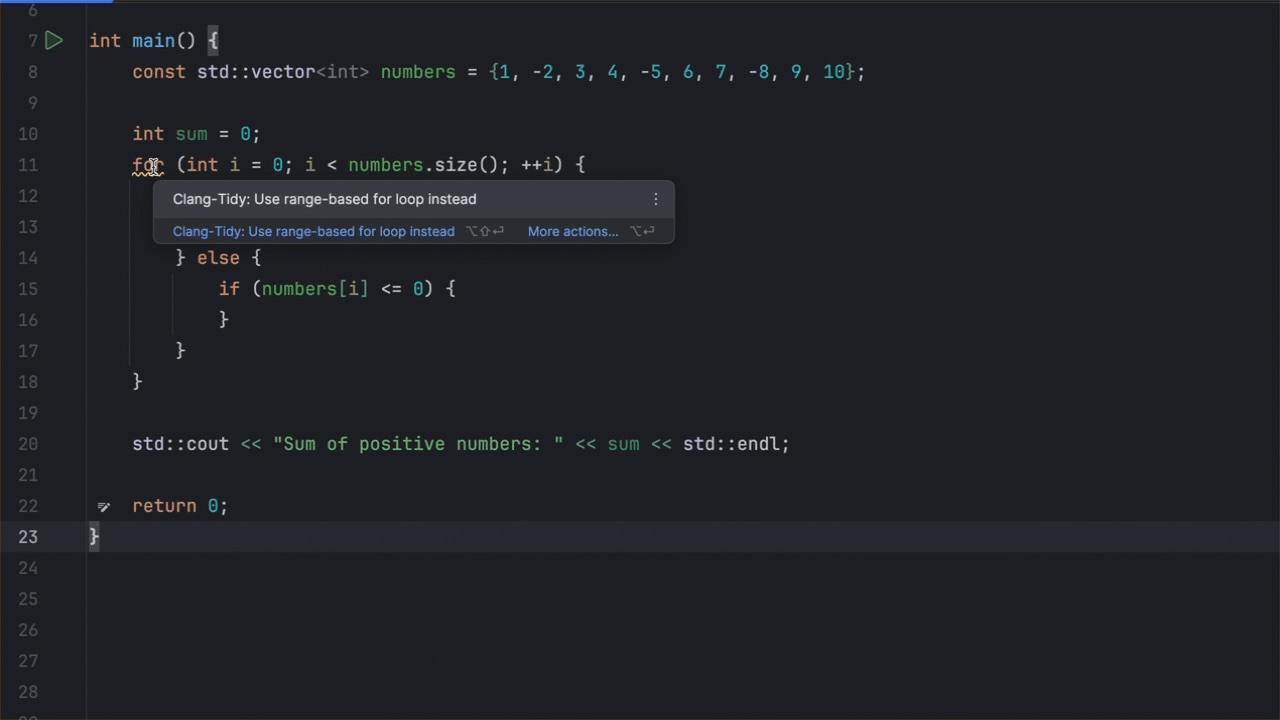
Figure 4: Optimizing a for loop
Removing code duplication
It takes more work to read and understand the logic of a codebase that is full of duplications. Such a codebase is also harder to maintain and more error-prone. When you remove code duplication, you are primarily improving the maintainability and readability of the code.
Developers remove code duplication using a variety of approaches, including by:
- Introducing variables: When you see similar expressions are repeated, for example function calls, you can replace them with a new variable. This will eliminate redundancy and improve code readability. In the case of function calls, it also reduces the number of repetitive calculations.
- Using inheritance: If similar functionality occurs in different classes, you can turn them into subclasses that share the same behavior with the superclass. These subclasses then inherit the attributes and methods of the superclass.
- Extracting methods: Similar to function extraction, this method isolates duplicate code blocks in a separate method for improved clarity and reusability.
Here is an example of eliminating the repetitive use of the same function by introducing a variable:
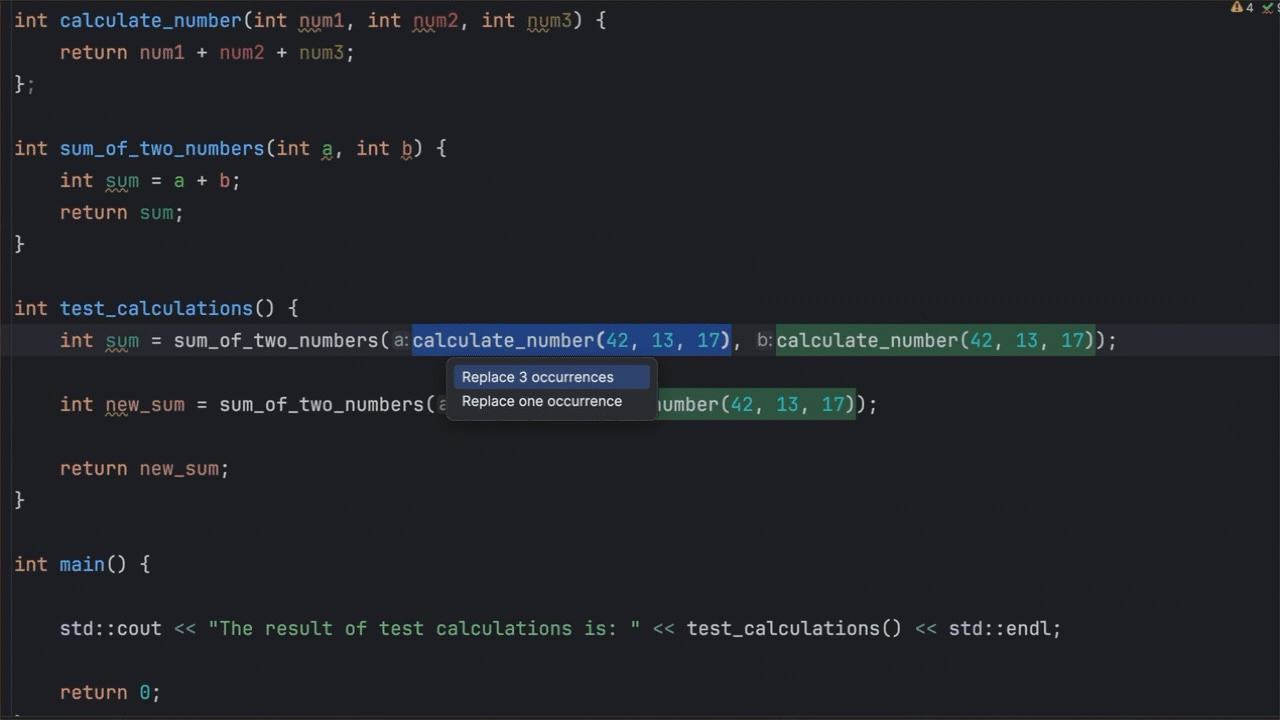
Figure 5: Introducing a variable
Refactoring challenges
While refactoring is helpful, it can also be challenging. There are two cases where it is typically required: with complex, difficult-to-understand code and when working in unreliable IDEs.
Complex code
When working on large, poorly documented projects with thousands of lines of code, it’s hard to refactor them without getting confused. Manual refactoring can be torture: Imagine a developer who has to delete a function parameter used in more than a hundred places in different files. In this case, IDE auto-refactorings are essential.
Unreliable IDEs
An unreliable IDE that performs auto-refactoring incorrectly can introduce new bugs into the code. This puts the burden of refactoring on the developer because these additional bugs have to be caught somehow.
But what makes a reliable IDE? A good definition would be one that is capable of parsing every project file without missing anything. A reliable IDE should know all of the features and particularities of C++, so the developer using it doesn’t need to worry about forgetting some of them.
For example, if you’re using a “safe delete” feature to delete a function parameter, a reliable IDE will check all project files to ensure nothing is broken after the deletion. If the procedure is unsafe, the IDE will warn you of all the places in your code where the parameter is used and the possible consequences. Here is an example of a warning that CLion provides:
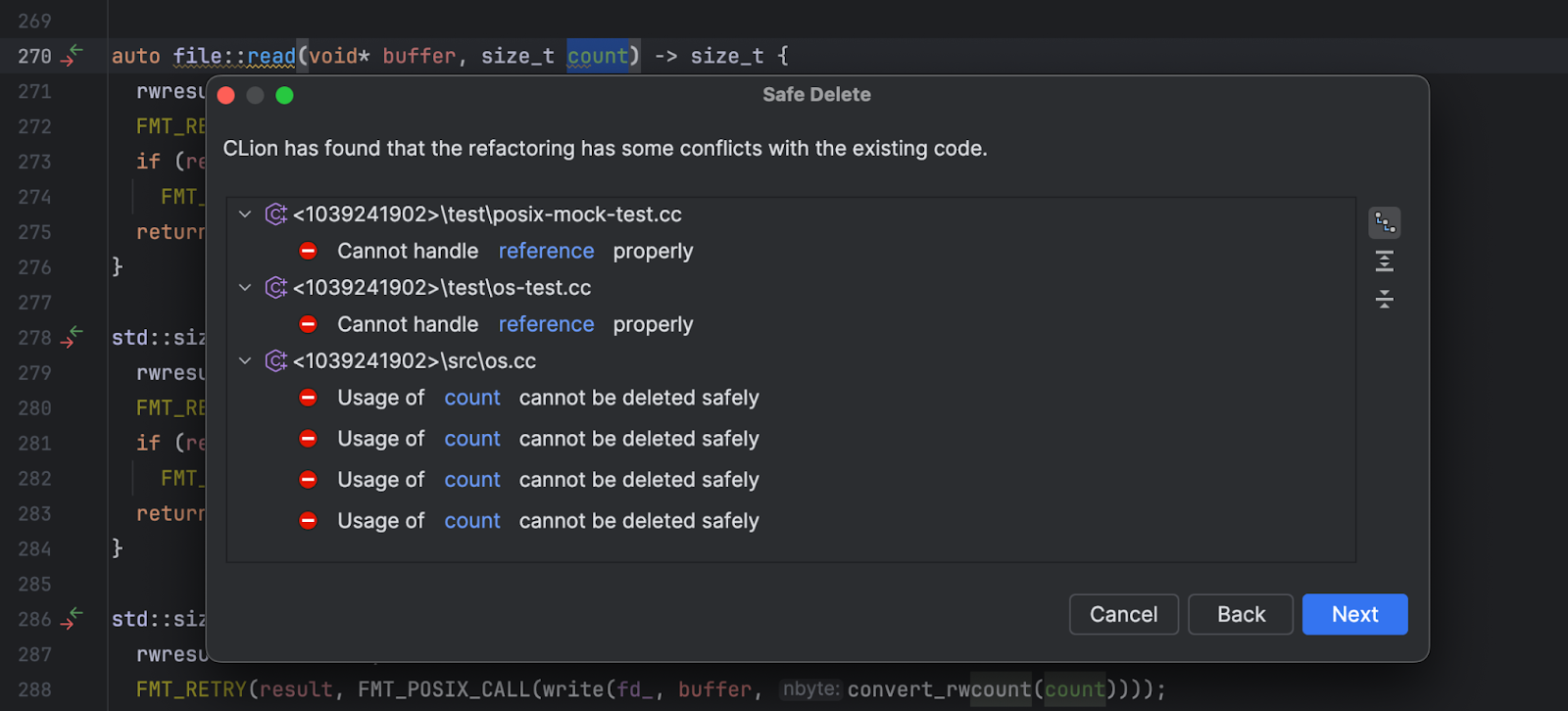
Figure 6: Using the Safe Delete feature in CLion
If an IDE can’t parse all parameter usages and allows unsafe deletion, the consequences can be unpredictable. In the best case, a compiler will catch the error. In the worst case, the program will compile but then behave erratically or crash at runtime.
Best practices for C++ refactoring
Because C++ code refactoring is generally challenging, following best practices makes it easier to improve code quality while avoiding unexpected results and bugs. These practices include refactoring in small steps, using a version control system, automating testing, and more.
Refactoring in small steps
When you make small, incremental changes, it’s easier to debug and track their impact. If a bug appears after refactoring, you can quickly find the problem.
Minor changes are also easier for teams to review than significant ones. This incremental approach takes less time and fewer resources, so a team can allocate its efforts more effectively while still improving the code.
Using a version control system
The benefits of using a version control system (VCS) like Git for refactoring are the same as for collaborative development. These include tracking changes, reviewing code, isolating changes, and facilitating testing. VCS clarifies the decisions made and what areas of the code were affected. It helps team members and future developers better understand the rationale behind refactorings.
In CLion, you can also use Local History, which tracks all of the changes you make to a project independently of a VCS.
Automated testing
Automated tests, especially unit tests, verify that code blocks behave as expected after refactoring. Ideally, you should have unit tests for all major code blocks before you refactor. It’s especially important when refactoring large, complex projects, where a small change can affect multiple files and hundreds of lines of code.
Prioritizing code readability
Improving code readability is one of the main reasons for refactoring, as it directly impacts code quality and maintainability. Readable code with clear logic and functionality is easier for developers to understand. This is critical when working in teams or when reviewing code later. Therefore, prioritizing code readability during refactoring is essential for developing maintainable and high-quality software.
When and why to refactor your C++ code
C++ refactoring can help you improve the quality of your code in a variety of situations, from boosting readability to better managing technical debt.
Unreadable code
If you’re spending too much time trying to understand what code does and feel it would be better to rewrite it, you’re dealing with poor code readability. The exact reasons may be one or a combination of the following:
- Meaningless function and variable names
- Complex conditional logic
- Redundant code
- Inconsistent formatting
All of these and other signs that prevent you from understanding code’s logic indicate that it needs to be refactored to make it more readable.
Non-extensible code
Poor or non-extensible code is challenging to adapt to new requirements, technologies, and other future changes. There are several indicators of such code.
For example, one of the most common problems is tightly coupled components, such as classes, where one class is heavily dependent on another. It’s difficult to add new functionality without untangling all of the dependencies between these classes.
Hard-coded functionality in source code is another common sign of non-extensible code. Examples include various fixed data, such as credentials, timeout values, and out-of-context numeric values (magic numbers) used instead of variables and constants. Code with hard-coded values is difficult to customize, and it’s also easy to add bugs when modifying it.
Poor testability
It’s hard to write tests for code that has excessively long methods and classes, complex conditional logic, tight coupling, and a lack of modularity. This makes it difficult to test a certain functionality and cover the entire codebase with the necessary tests. In the end, it increases the chance that bugs will be missed.
Code duplication
There is a rule of thumb in programming: If you see three pieces of the same code or something repeated three times, you should refactor the code. This also ties in with the DRY (don’t repeat yourself) principle, which helps eliminate redundancy and improve your code quality.
Performance issues
Even though C++ is famed for its excellent performance, it’s still possible to run into performance-related issues. Common reasons for this include the following:
- Excessive memory allocation and deallocation, which can cause slowdowns, especially if there are a lot of complicated loops.
- Passing unnecessary objects by value instead of reference, which can lead to expensive value copying. This becomes critical when working with large objects.
- The use of inappropriate data structures – for example, linking lists for random access instead of vectors – which can result in significant overheads.
We generally improve our code performance by doing more low-level optimizations, such as improving CPU and memory consumption. Occasionally, however, the structure of our code prevents us from optimizing it – in these cases, it’s a good idea to refactor our codebase first. Sometimes, we optimize it first and then refactor it to clean it up afterwards.
Technical debt
Technical debt accumulates gradually through patches, bug fixes, or poor C++ design patterns. It leads to code smells, adds redundancies, reduces performance, and causes other problems.
You can’t avoid technical debt, but by regularly refactoring your code, you can mitigate it and ensure that your codebase is more maintainable.
Conclusion
Regular refactoring of C++ code comes with plenty of perks that boost your code quality and make it easier to maintain. The key gains are improved code readability, maintainability, and performance. If you think your code needs refactoring, try the techniques discussed in this article.
To learn more about the C++ refactoring features available with the new CLion Nova language engine, read our documentation. Check out our blog post about the CLion 2024.3 release to explore all the new IDE features and improvements. And feel free to ask questions and give feedback in the comments section below!