
JetBrains Research
Research is crucial for progress and innovation, which is why at JetBrains we are passionate about both scientific and market research
Our Research on Membership Inference Attacks and Preventing Privacy Leaks


Imagine there’s a stranger out there who has nothing but API access to your chatbot. They are interested in knowing whether a specific patient, employee, or customer appears in the data you trained it on. Without breaching the database or stealing backups, this person can theoretically figure out this information with carefully crafted prompts and a bit of patience.
Depending on model size and susceptibility to overfitting, this approach can pose a severe risk to user privacy. We think that this privacy risk is greatly underestimated, especially for fine-tuned models, and that current detection methods are insufficient. And at JetBrains, we take user data and privacy very seriously.
In this post, we discuss this important privacy risk. In particular, we:
- Present the background information important for understanding the extent of the risk.
- Give a current picture of this sort of attack on LLMs, including the current state of the art in research.
- Propose our own attack method and argue that it is simple, yet effective for identifying user privacy risks.
Membership inference attacks: Preliminaries
A membership inference attack s a type of privacy attack in which, simply put, someone can use a data sample and a model to find out whether particular data points were used to train a model. That is, the attackers are not directly stealing data, but rather exploiting the information they find. The perpetrators of such attacks might be motivated by finding:
- Sensitive information
- An opportunity to tamper with the model
- Competitive advantage in their own model
For LLMs, this matters because they are trained on vast corpora that can include personal, confidential, or regulated information. And these attacks are usually not limited to someone finding out a single datapoint; they are often scaled up to reveal entire datasets of private information.
Researchers are looking into these attacks and their possible variations because they reveal privacy risks in models. This is also helpful for model developers to proactively identify vulnerabilities in their models and to minimize important risks as much as possible.
To better understand the technical aspects of a membership inference attack on an LLM, we have to think about how models are trained and how a model’s performance is evaluated during training. This is important because the attacks exploit the data from these LLM evaluation metrics, which are not the same as those used for all types of models.
The rest of this section covers the basics of LLMs and their evaluation metrics, how these metrics are exploited in the attacks, and related privacy risks. After these fundamentals, we move on to more advanced ideas from the current state of the research field.
Training LLMs
In this subsection, we will sketch the fundamentals of training a model, which involves building the model’s general capabilities from scratch or near-scratch on a very large corpus. In addition, there is fine-tuning, which is a process used for improving the capabilities of a pre-trained model on a specific task by using a domain-specific dataset for further training after the initial general-purpose training is completed. As fine-tuning also involves training, just with a smaller dataset, the concepts introduced here about evaluating predictions apply to both training and fine-tuning.
Basically, a model is trained on large amounts of data with various parameters, sometimes called weights, that map connections between the data. The training data can comprise any sort of data; that choice depends on the end goal for the specific model. The model makes predictions based on inputs, and these predictions are evaluated during training.
In LLMs, the predictions are text-based and comprise sequences of tokens. Sometimes tokens are words, as is depicted in the image below.
Sometimes tokens are parts of words, single characters, or even punctuation; the length depends on the chosen tokenizer and its own training. Either way, even when the output contains a very long text, the model only generates texts one token at a time.
For each output (i.e. each prediction), the model produces a list of many probabilities for the next possible token and randomly selects a token with a high probability. Based on the training data and the training weights, the model will have “learned” whether certain tokens are better suited, and these are the ones with higher probabilities attached to them. That selected token is the end output.
Throughout the training, the parameters are adjusted to improve the prediction accuracy of the model. But how can we define the accuracy of predictions?
Evaluating LLMs’ predictions
Similar to statistics, in machine learning we use different loss functions to quantify the difference between the output, or the predicted value, for a given input and the actual value for that input. This difference can be expressed in raw probabilities. In the model’s training algorithm, the loss value helps to guide the optimization process and assists in balancing issues such as oversimplification and overfitting.
Large language models typically use negative log likelihoods as their loss functions; these are sometimes referred to as NLL or log probabilities. The reason that the probability values are transformed into logs has to do with the nature of probabilities combined with the nature of LLM predictions, namely:
- The probabilities will always be numbers between 0 and 1.
- The joint probabilities of a text sequence must be calculated by multiplying the token probabilities.
- The outputted text sequences contain many predictions.
- The products of many small numbers will quickly become very small, leading to numerical instability.
Based on the above list, it is clear that a loss function based solely on raw probabilities would quickly run into problems with LLMs. A simple fix involves transforming the raw probabilities into a log-likelihood, log(p).
For our purposes, it is sufficient to understand that the log transformation of raw probabilities renders the loss function more stable, particularly for the overall calculation of a text sequence’s probability. According to the rules of logs, the mathematical function for calculating the overall probability of many predictions is no longer multiplication, but addition: log(p*q) = log(p) + log(q).
We use the negative log probability, not the positive log probability because:
- Raw probabilities in loss functions are always between 0 and 1.
- Log transformations of values less than 1 will always be negative.
- Adding many negative values together results in a very large negative number
- We are trying to minimize error and the log probability does not gives the error but indicates how good the prediction is.
By multiplying the log probability by -1, we can transform the function into one that tells us the error (i.e. how bad the prediction is) instead of the bare log probability (i.e. how good the prediction is). Overall, the lower the loss function (i.e. the negative log-likelihood), the fewer errors the model makes in its predictions.
Another relevant evaluation metric to mention is perplexity. This metric, sometimes shortened to PPL, is used to quantify the uncertainty – not the accuracy – of the model’s predictions. While it depends on the corpus, we can roughly say that the score indicates how many likely options there are for each next token, and therefore lower perplexity scores suggest lower uncertainty. Higher perplexity scores for a simple text, on the other hand, are associated with highly uncertain models that are prone to hallucinations.
The mathematics behind perplexity scores is related to the log probability: perplexity is the exponential of the average negative log probability. The perplexity score is an aggregated score, as it provides the model’s average for each predicted token, based on the model’s total log probability average.
To summarize the two evaluation metrics covered here, they measure the following:
- Negative log likelihood: the accuracy of a token’s prediction
- Perplexity: the confidence of the model in its predictions
Membership inference attacks exploit signals like log likelihoods and perplexity, because both expose how much the model “likes” a sequence. If a specific text was included in training, the model may assign it an unusually high probability, which can show up as lower loss (i.e. log probability). Similarly, lower perplexity scores, which indicate lower uncertainty, can be a clue that the model has seen the token before.
LLM privacy risks
Beyond membership inference attacks, LLMs face a similar privacy risk: data extraction attacks. These two types of attacks are related but not the same, and they are sometimes conflated in online content about privacy risks.
The following table compares data extraction and membership inference attacks in more detail.

We can also connect the two types of attacks through memorization. As suggested by its name, this concept refers to how a model can learn large chunks of its training data and then regurgitate them.
As membership inference attacks concern attempts to determine membership, and because models often behave differently on familiar or memorized examples, these types of attacks treat memorization as a signal of membership. That means that models susceptible to memorization are more vulnerable to membership inference attacks.
Data extraction attacks, which aim to recover specific data, go further by leveraging memorization rather than just detecting it. That is, when there is strong enough memorization, the model will output sequences verbatim, and the specific data can be extracted by an attacker.
Overall, we can say that memorization creates ripe conditions for both attacks, but the strength of memorization affects whether both can actually happen. And in practice, membership inference can be the first step in a larger data-extraction scheme, as in this case.
We know from recent research that models pre-trained on large datasets are not very susceptible to attacks, thanks to low memorization. This comes from the very large training set and the very low number of training iterations. In contrast, fine-tuned models, trained on much smaller datasets, exhibit stronger memorization and are therefore more vulnerable to attacks. Recent studies, like this one, have proven that fine-tuned models are at much higher risk of privacy attacks and that memorization plays a role.
For that reason, understanding and measuring memorization, especially in fine-tuned models, is essential for assessing LLM privacy risks. In particular, it is important to understand when membership leakage remains a theoretical concern and when it becomes a potential attack surface.
Membership inference attacks on LLMs
There are not yet many examples of in-the-wild membership inference attacks on LLMs; they are thus far mostly seen in the research domain, such as this recent study on copyright auditing using real data. In the study, researchers used membership-inference techniques to try to find out whether copyrighted books from a specific company were in OpenAI’s training data. This work is an example of using the attack methods not to reveal confidential data, but to unveil breaches of corporate transparency.
In the rest of this section, we will look at various attacks that have been identified in the study of privacy risks. In addition, we will discuss the current state of research, and propose our method for reducing membership leakage.
Different types of membership inference attacks
Although membership inference as a theoretical concept has been around for a bit longer, the beginnings of this research direction in machine learning specifically can be traced to 2017. This is when Cornell researchers formally identified the shadow model approach.
The term shadow model refers to any model trained to imitate the target model. With such models, one can observe how they behave on data they have seen versus data they haven’t. Based on these observations, it is possible to train a separate classifier that predicts whether a specific data point was part of the original training set. This work established a key insight that still holds today, and which we talked about above: models tend to respond differently to familiar data than they do to unseen data. A big downside is that this method is resource-heavy. An additional challenge is that these methods usually assume the attacker has access to data similar to the model’s original training set, something that is not always possible.
The shadow model approach is what we call a reference-based attack. These types involve a reference model, i.e. the shadow model. Beyond the original shadow model paper, examples include:
- Likelihood Ratio Attack (LiRA) is known in the field for its high precision. For this method, hundreds of shadow models need to be trained, and these models help to calibrate a sample’s score.
- SPV-MIA involves constructing a reference dataset by prompting the target model and then fine-tuning a reference model on its generated outputs. A pro here is that the number of data assumptions is reduced. That being said, it needs more than 40 passes per sample to determine membership.
On the other end of the spectrum, we have reference-free attacks (sometimes referred to as threshold-based attacks). These types do not rely on an external model; instead, comparisons are made only against the target model’s output. That is, somebody can look at a data point’s confidence value and compare that value to those of other data points in the output. Examples include the following:
- LOSS attack operates on the assumption, mentioned above, that training samples have lower loss values than non-members. This approach is computationally leaner than the reference-based ones, but it also comes with high false-positive rates.
- Neighborhood Attack involves creating synthetic neighbor texts based on the original sample’s output. The loss functions of these texts are compared with the original samples, with the assumption being that if the original text has a high log-likelihood, it is more likely to be a member of the training data.
- MIN-K% PROB shifts the focus to which tokens have the lower likelihoods, assuming that these lower probabilities are most likely associated with non-members.
Unlike a reference-based attack, there are no resources lost in creating an imitation model in a reference-free attack. That being said, these types of attacks need a lot of computing power to make the comparisons within the output, and they are not always precise.
Having outlined the main types of membership inference attacks currently in the research domain, in the next subsection, we return to the underlying property that makes these attacks possible in language models: memorization. Understanding how to measure this property, where it appears in model outputs, and how it can be reduced is essential for privacy research.
Current approaches to mitigating memorization in LLMs
As mentioned above, fine-tuned LLMs are a higher-risk case. Although trained on large datasets initially, fine-tuning is performed on much smaller datasets, often for several epochs, so individual examples can leave a strong memorization signal. While this is well-known, what is less clear is how we can accurately measure the amount of memorization in a model – and how we can reduce it. Here are a couple of recent studies looking at this.
Beginning with recent work on quantifying memorization, the authors point out that studying LiRa-style attacks on LLMs can be prone to misinterpretation of memorization amounts, because it usually collapses a sequence into a single average loss and ignores correlations between token-level losses. They argue that as the tokens in language models are inherently not independent of other elements in the sequence, ignoring these correlations can lead to serious miscalculations. When they adapted LiRA to consider these correlations, they found up to 87.5 times more memorization.
The particular adaptation that these researchers used is to model per-token losses as a multivariate, rather than a univariate distribution over average sequence loss. A multivariate analysis means that multiple variables are analyzed separately, instead of reducing the whole sequence to a single, average value. This change in approach allows the analysis to capture “within-sequence correlations,” or how a loss at one token position is statistically related to losses at nearby or dependent positions.
While this is an important contribution to the field, they adapt LiRA within the shadow-model paradigm. As we know from above, this is heavy on resource costs due to the high amount of shadow model training.
Another recent study has proposed a parameter-efficient method called Low-Rank Adaptation (LoRA) to reduce memorization during fine-tuning. Instead of updating all the weights of a pretrained model, LoRA freezes the original model and adds small trainable “adapter” matrices to selected layers, usually attention or feed-forward layers. These adapters learn a low-rank update to the original weight matrix.
The practical effect is that LoRA makes fine-tuning cheaper, faster, and easier to store. Instead of saving a full copy of a fine-tuned model, you can save only the small LoRA adapter weights. It can also reduce memorization because the model has less capacity to encode fine-grained details from the fine-tuning set, although this depends on the rank, dataset size, number of epochs, and task.
Taken together, these findings motivate a closer look at both how memorization is measured and how fine-tuning choices affect privacy exposure. In our paper, we study the especially sensitive case of fine-tuned language models and compare the leakage induced by full-model updates with that of LoRA. Rather than relying on shadow models or treating sequence loss as a single aggregate quantity, our method targets the points in the output where the model makes mistakes, i.e., where the membership signal is most concentrated – at the positions where the model failed to predict correctly.
Our proposal for more accurately measuring memorization in fine-tuned LLMs
To better understand how memorization creates privacy risks in fine-tuned LLMs, we need an accurate way to measure it. As discussed in the previous section, existing membership inference methods often rely on aggregate signals, such as the model’s average loss over a sequence, or on expensive procedures that require training many shadow models. Both choices are limiting: average loss can wash out the token-level patterns where memorization actually appears, while shadow-model approaches can be too costly to use as a practical audit tool.
In our paper, we ask whether there is a simpler and more targeted way to detect membership leakage in fine-tuned language models. In this section, we will describe our proposed method and use it to measure memorization of fine-tuning datasets. More technical details are available in Sections 3-6 and in the appendices of the paper; here you can find the code.
Our attack method
A driving intuition behind our method is that memorization is not spread evenly across a sequence. When the model already correctly predicts a token, both the fine-tuned model and the pre-trained reference model may assign it a high probability, so there is little useful membership signal. But when the model predicts the wrong token, fine-tuning may still raise the probability of the true token for training examples, even if not enough to make it the top prediction.
Recognizing this informativity in error positions is key to our method, which we call Error Zone Membership Inference Attack (EZ MIA). For a formal explanation of this idea, see §6.1 of our paper.
Our threat model assumes that an attacker:
- Can query the fine-tuned target model.
- Compute token-level log probabilities.
- Have access to the original pre-trained model or a comparable public reference model.
What the attacker does not require access to are samples from the training distribution, shadow-model training, or auxiliary model fitting.
We compared the target model’s token-level log probabilities with those of a reference model. The reference model is the pre-trained base model checkpoint from before fine-tuning. The advantage of such a baseline is that it can capture the modeling capabilities without exposure to the training data.
At the error positions, we analyzed probability shifts as upward (positive) changes and downward (negative) changes relative to the reference model. Then we have the Error Zone score, which is calculated as the ratio between the two directions of the probability shift. A higher score means that, in parts of the sequence where the model is uncertain or wrong, fine-tuning has pushed more probability toward the observed tokens, providing evidence that the sequence may have appeared in training.
The Error Zone score is scale-invariant. That is, if all token-level shifts increase or decrease by the same factor, the ratio remains unchanged.
A threshold for membership is also determined for each attack. If the Error Zone score exceeds the threshold, then it is considered to be a member.
A full attack requires only two forward passes per sequence: one through the target model and one through the reference model. This makes it much cheaper than attacks such as the reference-based ones described above, as they require many more model evaluations.
For an attack, the procedure is the following for each query sequence:
- Compute token-level log probabilities for the target and reference models.
- Identify the error positions where the target’s top prediction differs from the ground truth.
- Compute the Error Zone score.
- Classify an item as a member if that score exceeds the respective threshold.
In short, EZ MIA turns membership inference into a more targeted and practical measurement problem. In this way, the attack method is both lightweight and informative, offering a practical way to audit memorization in fine-tuned language models while keeping computational costs low.
We evaluated our method, EZ MIA, across several text types to determine whether it works beyond a single narrow setting, and compared the results with common baselines. An initial experiment evaluated memorization across various datasets spanning different domains (methodology can be found in §4 of the paper); all baselines were implemented by our team under identical conditions as EZ MIA.
We found that focusing on error positions provides a stronger signal than using aggregate loss or other sequence-level statistics. EZ MIA outperformed common baselines, such as LOSS, Min-K++, and SPV-MIA. EZ MIA could detect up to nine times better than these baselines.
The following figure compares the detection rates for the baselines and EZ MIA for TPR@0.1%FPR; EZ MIA is represented by the blue bars. For more detailed results, see §5.2 in the paper.
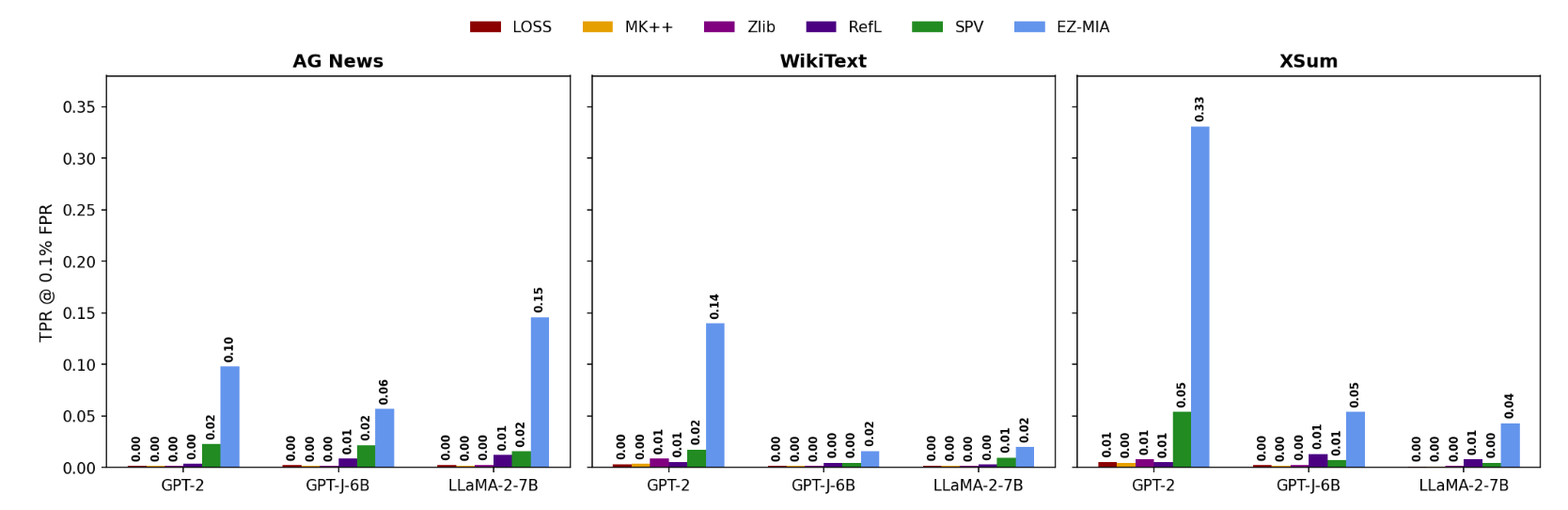
Overall, those results support the main intuition behind EZ MIA: memorization is easier to detect when we look at the model’s mistakes rather than averaging across the whole sequence. We take this to mean that our method is both more accurate and more practical for auditing fine-tuned language models than previously existing methods.
Applying our membership inference attack method to evaluate the effect of fine-tuning
Following the initial evaluations, we wanted to isolate the effect of fine-tuning. This subsection describes these experimental setups and their results. For more details on this investigation, see §5.3ff of our paper; in §6 of the paper, we additionally evaluate EZ MIA’s performance.
Experimental set-up
In this experiment, we evaluated three models: GPT-2 (124M), GPT-2-XL (1.5B), and Llama-2 (7B). All three models were evaluated separately as fully fine-tuned and as fine-tuned with LoRA on XSum, a dataset containing formal journalistic prose.
For each dataset, we constructed 10,000 member sequences, 10,000 non-member sequences, and a separate 500-sequence validation set. All sequences were fixed at 128 tokens, constructed by concatenating consecutive texts.
Our reference model for all attacks was the respective pre-trained model checkpoint. That is, before any fine-tuning and requiring no additional computation.
For evaluation, we report the area under the curve (AUC) as a general discrimination metric, but we place special emphasis on true positive rate (TPR) at very low false positive rates (FPRs). This matters because privacy auditing is most useful when false accusations are rare, so metrics like TPR@1%FPR and TPR@0.1%FPR are more informative than average-case performance alone.
Experimental results
One of the clearest findings is the contrast between full fine-tuning and LoRA. When we evaluated the same models under both settings, full fine-tuning produced far more membership leakage, while LoRA sharply reduced the signal. However, the leakage did not disappear entirely, especially for larger models. This suggests that LoRA can help reduce memorization risk, but should not be treated as a complete privacy protection. The following table displays the results for all three models.
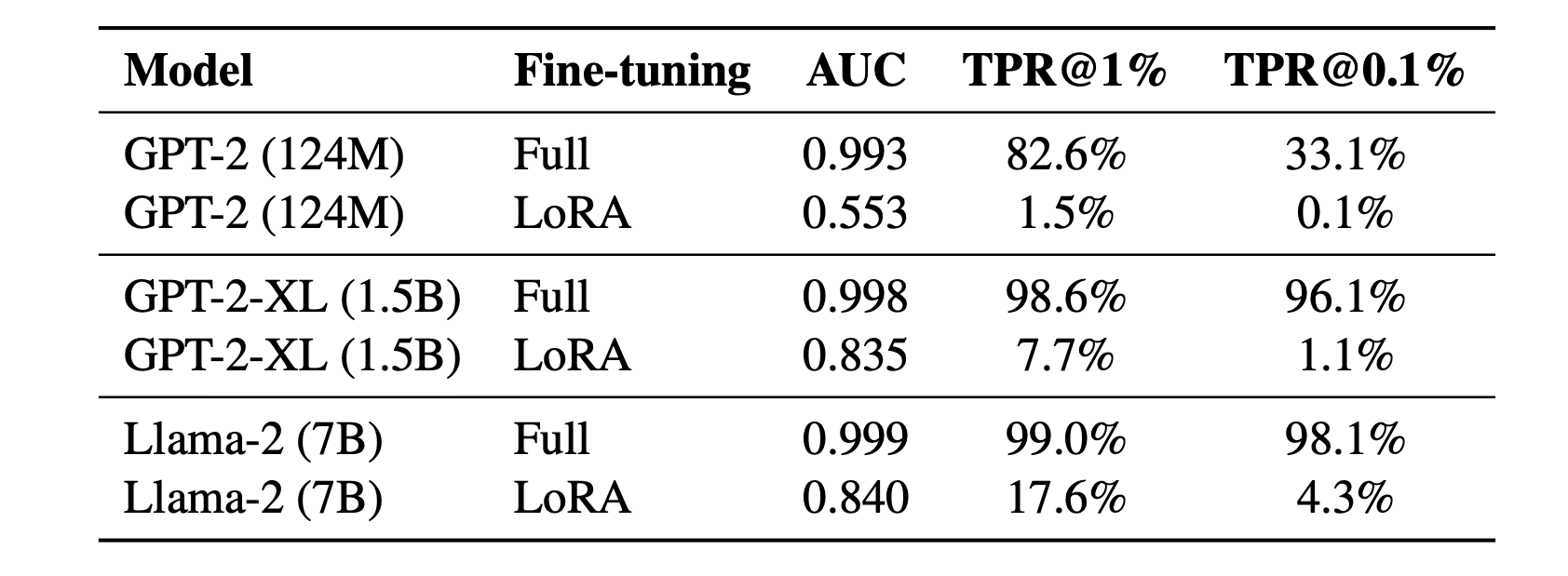
The table above shows that when comparing full fine-tuning with LoRA across GPT-2, GPT-2-XL, and Llama-2, full fine-tuning consistently leads to a much higher membership inference risk. Furthermore, LoRA substantially reduced this leakage at every model size. The effect was especially dramatic for smaller models: on GPT-2, the attack success rate dropped from 82.6% with full fine-tuning to just 1.5% with LoRA. Larger LoRA-tuned models still appeared to memorize more than smaller ones, but LoRA remained far safer than full fine-tuning overall.
These results confirm the membership inference risk of full fine-tuning, as well as show that parameter-efficient fine-tuning like LoRA can provide ample protection. Our attack method, EZ MIA, is a new and improved evaluation method for measuring memorization, able to detect membership signals with low false-positive rates.
The importance of studying membership inference and other LLM privacy risks
The broader takeaway here is that privacy auditing for LLMs needs to become more targeted, especially with fine-tuned models. LoRA can reduce leakage compared with full fine-tuning, but it does not make memorization disappear.
At the same time, stronger attacks like EZ MIA give researchers and practitioners a sharper tool for measuring when fine-tuning has crossed from useful adaptation into risky retention. If we want to build LLMs that learn from sensitive data without exposing it, we first need reliable ways to see where memorization is hiding.







