

Python más rápido: desbloqueamos el Global Interpreter Lock de Python

¿Qué es el Global Interpreter Lock (GIL) de Python?
«Global Interpreter Lock» (o «GIL») es un término familiar en la comunidad Python. Se trata de una funcionalidad muy conocida de Python. Pero ¿qué es exactamente un GIL?
Si tiene experiencia con otros lenguajes de programación (Rust, por ejemplo), puede que ya sepa lo que es un mutex. Es la abreviatura de «exclusión mutua». Un mutex asegura que solo puede acceder a los datos un hilo al mismo tiempo. Esto evita que los datos sean modificados por varios hilos a la vez. Puede pensar en ello como un tipo de «bloqueo»: bloquea todos los hilos para que no puedan acceder a los datos, excepto el hilo que tiene la llave.
El GIL es técnicamente un mutex. Permite que solo un hilo tenga acceso al intérprete de Python a la vez. A veces me lo imagino como un volante para Python. ¡Nadie quiere tener a más de una persona al mando del volante! Sin embargo, un grupo de personas en un viaje por carretera cambiará a menudo de conductor. Esto es algo así como transferir el acceso al intérprete a un hilo diferente.
Debido a su GIL, Python no permite verdaderos procesos multihilo. Esta funcionalidad ha suscitado debates en la última década, y ha habido muchos intentos de hacer Python más rápido eliminando el GIL y permitiendo procesos multihilo. Recientemente, en Python 3.13, se ha puesto en marcha una opción que permite utilizar Python sin el GIL, a veces conocido como Python sin GIL, o Python de hilo libre. Así pues, comienza una nueva era de la programación en Python.
¿Por qué se instauró el GIL inicialmente?
Si el GIL es tan impopular, ¿por qué se implementó en primer lugar? En realidad, tener un GIL tiene sus ventajas. En otros lenguajes de programación con multihilo real, a veces se producen problemas porque más de un hilo modifica los datos, y el resultado final depende de qué hilo o proceso termine primero. Esto se denomina «condición de carrera». Los lenguajes como Rust suelen ser difíciles de aprender porque los programadores tienen que utilizar mutex para evitar condiciones de carrera.
En Python, todos los objetos tienen un contador de referencias para llevar la cuenta de cuántos otros objetos requieren información de ellos. Si el contador de referencias llega a cero, como sabemos que no existe ninguna condición de carrera en Python debido al GIL, podemos declarar con confianza que el objeto ya no es necesario y puede ser recogido por el recolector de basura.
Cuando Python se lanzó en 1991, la mayoría de los ordenadores personales solo tenían un núcleo, y no muchos programadores solicitaban compatibilidad con multihilo. Disponer de un GIL resuelve muchos problemas en la implementación de programas, y también puede facilitar el mantenimiento del código. Por ello, Guido van Rossum (el creador de Python) añadió un GIL en 1992.
Avancemos hasta 2025: los ordenadores personales tienen procesadores multinúcleo y, por tanto, mucha más potencia de computación. Podemos aprovechar esta potencia adicional para lograr una verdadera concurrencia sin deshacernos del GIL.
Más adelante en este artículo, desglosaremos el proceso de eliminación. Pero por ahora, veamos cómo funciona la verdadera concurrencia con el GIL en funcionamiento.
Multiprocesamiento en Python
Antes de adentrarnos en el proceso de eliminación del GIL, echemos un vistazo a cómo los desarrolladores de Python pueden lograr una verdadera concurrencia utilizando la biblioteca de multiprocesamiento. La biblioteca de multiprocesamiento estándar ofrece concurrencia tanto local como remota, eludiendo eficazmente el bloqueo global del intérprete mediante el uso de subprocesos en lugar de hilos. De este modo, el módulo de multiprocesamiento permite al programador aprovechar al máximo los múltiples procesadores de una máquina determinada.
Sin embargo, para realizar el multiprocesamiento, tendremos que diseñar nuestro programa de forma un poco diferente. Veamos el siguiente ejemplo de cómo utilizar la biblioteca de multiprocesamiento en Python.
Recuerde nuestra hamburguesería asíncrona de la primera parte de la serie del blog:
import asyncio
import time
async def make_burger(order_num):
print(f"Preparing burger #{order_num}...")
await asyncio.sleep(5) # time for making the burger
print(f"Burger made #{order_num}")
async def main():
order_queue = []
for i in range(3):
order_queue.append(make_burger(i))
await asyncio.gather(*(order_queue))
if __name__ == "__main__":
s = time.perf_counter()
asyncio.run(main())
elapsed = time.perf_counter() - s
print(f"Orders completed in {elapsed:0.2f} seconds.")
Podemos utilizar la biblioteca de multiprocesamiento para hacer lo mismo, por ejemplo:
import multiprocessing
import time
def make_burger(order_num):
print(f"Preparing burger #{order_num}...")
time.sleep(5) # time for making the burger
print(f"Burger made #{order_num}")
if __name__ == "__main__":
print("Number of available CPU:", multiprocessing.cpu_count())
s = time.perf_counter()
all_processes = []
for i in range(3):
process = multiprocessing.Process(target=make_burger, args=(i,))
process.start()
all_processes.append(process)
for process in all_processes:
process.join()
elapsed = time.perf_counter() - s
print(f"Orders completed in {elapsed:0.2f} seconds.")
Como recordará, muchos de los métodos del multiprocesamiento son muy similares a los hilos. Para ver la diferencia en el multiprocesamiento, exploremos un caso de uso más complejo:
import multiprocessing
import time
import queue
def make_burger(order_num, item_made):
name = multiprocessing.current_process().name
print(f"{name} is preparing burger #{order_num}...")
time.sleep(5) # time for making burger
item_made.put(f"Burger #{order_num}")
print(f"Burger #{order_num} made by {name}")
def make_fries(order_num, item_made):
name = multiprocessing.current_process().name
print(f"{name} is preparing fries #{order_num}...")
time.sleep(2) # time for making fries
item_made.put(f"Fries #{order_num}")
print(f"Fries #{order_num} made by {name}")
def working(task_queue, item_made, order_num, lock):
break_count = 0
name = multiprocessing.current_process().name
while True:
try:
task = task_queue.get_nowait()
except queue.Empty:
print(f"{name} has nothing to do...")
if break_count > 1:
break # stop if idle for too long
else:
break_count += 1
time.sleep(1)
else:
lock.acquire()
try:
current_num = order_num.value
order_num.value = current_num + 1
finally:
lock.release()
task(current_num, item_made)
break_count = 0
if __name__ == "__main__":
print("Welcome to Pyburger! Please place your order.")
burger_num = input("Number of burgers:")
fries_num = input("Number of fries:")
s = time.perf_counter()
task_queue = multiprocessing.Queue()
item_made = multiprocessing.Queue()
order_num = multiprocessing.Value("i", 0)
lock = multiprocessing.Lock()
for i in range(int(burger_num)):
task_queue.put(make_burger)
for i in range(int(fries_num)):
task_queue.put(make_fries)
staff1 = multiprocessing.Process(
target=working,
name="John",
args=(
task_queue,
item_made,
order_num,
lock,
),
)
staff2 = multiprocessing.Process(
target=working,
name="Jane",
args=(
task_queue,
item_made,
order_num,
lock,
),
)
staff1.start()
staff2.start()
staff1.join()
staff2.join()
print("All tasks finished. Closing now.")
print("Items created are:")
while not item_made.empty():
print(item_made.get())
elapsed = time.perf_counter() - s
print(f"Orders completed in {elapsed:0.2f} seconds.")
Este es el resultado que obtenemos:
Welcome to Pyburger! Please place your order. Number of burgers:3 Number of fries:2 Jane has nothing to do... John is preparing burger #0... Jane is preparing burger #1... Burger #0 made by John John is preparing burger #2... Burger #1 made by Jane Jane is preparing fries #3... Fries #3 made by Jane Jane is preparing fries #4... Burger #2 made by John John has nothing to do... Fries #4 made by Jane Jane has nothing to do... John has nothing to do... Jane has nothing to do... John has nothing to do... Jane has nothing to do... All tasks finished. Closing now. Items created are: Burger #0 Burger #1 Fries #3 Burger #2 Fries #4 Orders completed in 12.21 seconds.
Tenga en cuenta que existen algunas limitaciones en el multiprocesamiento que hacen que el código anterior se haya diseñado de esta forma. Vamos a repasarlas una por una.
En primer lugar, recuerde que antes teníamos las funciones make_burger y make_fries para generar una función con el orden_num correcto:
def make_burger(order_num):
def making_burger():
logger.info(f"Preparing burger #{order_num}...")
time.sleep(5) # time for making burger
logger.info(f"Burger made #{order_num}")
return making_burger
def make_fries(order_num):
def making_fries():
logger.info(f"Preparing fries #{order_num}...")
time.sleep(2) # time for making fries
logger.info(f"Fries made #{order_num}")
return making_fries
No podemos hacer lo mismo cuando utilizamos el multiprocesamiento. Si lo intentamos, obtendremos un error del tipo:
AttributeError: Can't get local object 'make_burger..making_burger'
La razón es que el multiprocesamiento utiliza pickle, que solo puede serializar funciones de nivel de módulo superior en general. Esta es una de las limitaciones del multiprocesamiento.
En segundo lugar, observe que en el fragmento de código del ejemplo anterior que utiliza el multiprocesamiento no utilizamos ninguna variable global para los datos compartidos. Por ejemplo, no podemos utilizar variables globales para item_made y order_num. Para compartir datos entre distintos procesos, se utilizan objetos de clase especial como Queue y Value de la biblioteca de multiprocesamiento y se pasan a los procesos como argumentos.
En general, no se recomienda compartir datos y estados entre distintos procesos, ya que puede causar muchos más problemas. En nuestro ejemplo anterior, tenemos que utilizar un bloqueo para asegurarnos de que solo puede acceder e incrementar el valor de order_num un proceso a la vez. Sin el bloqueo, el número de pedido del artículo puede desordenarse así:
Items created are: Burger #0 Burger #0 Fries #2 Burger #1 Fries #3
Aquí tenemos cómo utilizar un bloqueo para evitar problemas:
lock.acquire()
try:
current_num = order_num.value
order_num.value = current_num + 1
finally:
lock.release()
task(current_num, item_made)
Para saber más sobre cómo utilizar la biblioteca estándar de multiprocesamiento, puede consultar la documentación aquí.
Eliminación del GIL
La eliminación del GIL ha sido un tema de debate durante casi una década. En 2016, en el Python Language Summit, Larry Hastings presentó sus reflexiones sobre la realización de una «GIL-ectomía» en el intérprete CPython y los progresos que había hecho con esta idea [1]. Este fue un intento pionero de eliminar el GIL de Python. En 2021, Sam Gross reavivó la discusión sobre la eliminación del GIL [2], y eso condujo a la publicación de PEP 703 – Making the Global Interpreter Lock Optional in CPython en 2023.
Como vemos, la supresión del GIL no es en absoluto una decisión precipitada y ha sido objeto de un amplio debate en la comunidad. Como demuestran los ejemplos anteriores de multiprocesamiento (y el PEP 703, enlazado más arriba), cuando se elimina la garantía proporcionada por el GIL, las cosas se complican rápidamente.
[1]: https://lwn.net/Articles/689548/
[2]: https://lwn.net/ml/python-dev/CAGr09bSrMNyVNLTvFq-h6t38kTxqTXfgxJYApmbEWnT71L74-g@mail.gmail.com/
Recuento de referencias
Cuando el GIL está presente, el recuento de referencias y la recogida de basura son más sencillos. Cuando solo un hilo a la vez tiene acceso a objetos Python, podemos confiar en un recuento de referencias no atómico directo y eliminar el objeto cuando el recuento de referencias llegue a cero.
La eliminación del GIL complica las cosas. Ya no podemos utilizar el recuento de referencias no atómico, ya que no garantiza la seguridad de los hilos. Las cosas pueden ir mal si varios hilos están realizando varios incrementos y decrementos de la referencia en el objeto Python al mismo tiempo. Lo ideal sería utilizar el recuento atómico de referencias para garantizar la seguridad de los hilos. Pero este método adolece de una elevada sobrecarga y su eficacia se ve mermada cuando hay muchos hilos.
La solución es utilizar el recuento de referencias sesgado, que también garantiza la seguridad de los hilos. La idea es inclinar cada objeto hacia un hilo propietario, que es el hilo que accede a ese objeto la mayor parte del tiempo. Los hilos propietarios pueden realizar un recuento de referencias no atómico en los objetos que poseen, mientras que los demás hilos deben realizar un recuento de referencias atómico en esos objetos. Este método es preferible al simple recuento atómico de referencias, porque la mayoría de los objetos solo reciben acceso a un hilo la mayor parte del tiempo. Podemos reducir la sobrecarga de ejecución permitiendo que el hilo propietario realice un recuento de referencias no atómico.
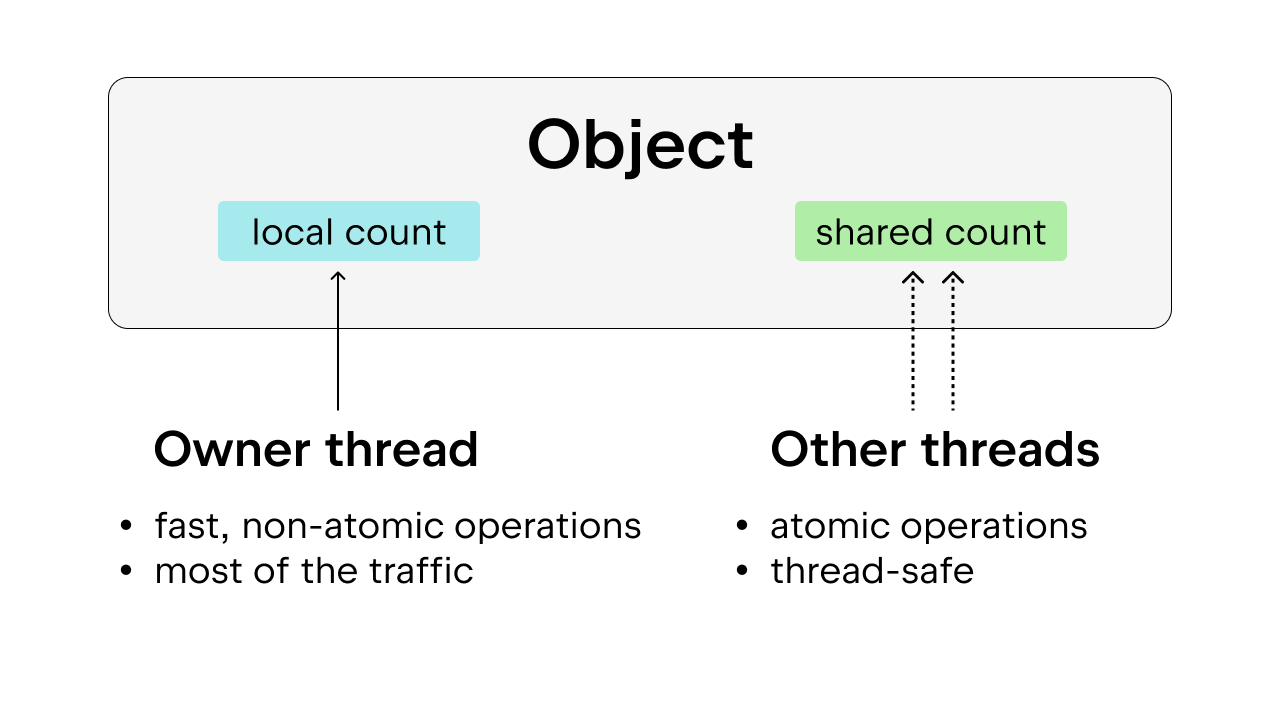
Además, algunos objetos Python de uso común, como True, False, enteros pequeños y algunas cadenas internadas, se hacen inmortales. Aquí, «inmortal» solo significa que los objetos permanecerán en el programa durante toda su vida útil, por lo que no requieren recuento de referencias.
Recolección de basura
También tenemos que modificar la forma en que se realiza la recolección de basura. En lugar de disminuir el recuento de referencias inmediatamente cuando se libera la referencia y eliminar el objeto enseguida cuando el recuento de referencias llega a cero, se utiliza una técnica denominada «recuento de referencias diferido».
Cuando es necesario disminuir el recuento de referencias, el objeto se almacena en una tabla, que se comprobará dos veces para ver si esta disminución en el recuento de referencias es exacta o no. Esto evita eliminar el objeto prematuramente cuando aún está siendo referenciado, lo que puede ocurrir sin el GIL, ya que el recuento de referencias no es tan sencillo como con el GIL. Esto complica el proceso de recolección de basura, ya que esta puede necesitar atravesar la pila de cada hilo para el recuento de referencias propio de cada hilo.
Otra cosa que tener en cuenta: el recuento de referencias debe ser estable durante la recolección de basura. Si un objeto está a punto de ser descartado pero de repente se hace referencia a él, esto causará graves problemas. Por ello, durante el ciclo de recolección de basura, tendrá que «parar el mundo» para ofrecer garantías de seguridad de los hilos.
Asignación de memoria
Cuando existe el GIL para garantizar la seguridad de los hilos, se utiliza el asignador de memoria interno de Python pymalloc. Pero sin el GIL, necesitaremos un nuevo asignador de memoria. Sam Gross propuso mimalloc en el PEP, que es un asignador de uso general creado por Daan Leijen y mantenido por Microsoft. Es una buena elección, porque es seguro para los hilos y tiene un buen rendimiento en objetos pequeños.
Mimalloc llena su montón con páginas y las páginas con bloques. Cada página contiene bloques, y los bloques dentro de cada página tienen todos el mismo tamaño. Al añadir algunas restricciones al acceso a la lista y al diccionario, el recolector de basura no tiene que mantener una lista vinculada para encontrar todos los objetos, y también permite el acceso de lectura a la lista y al diccionario sin adquirir el bloqueo.
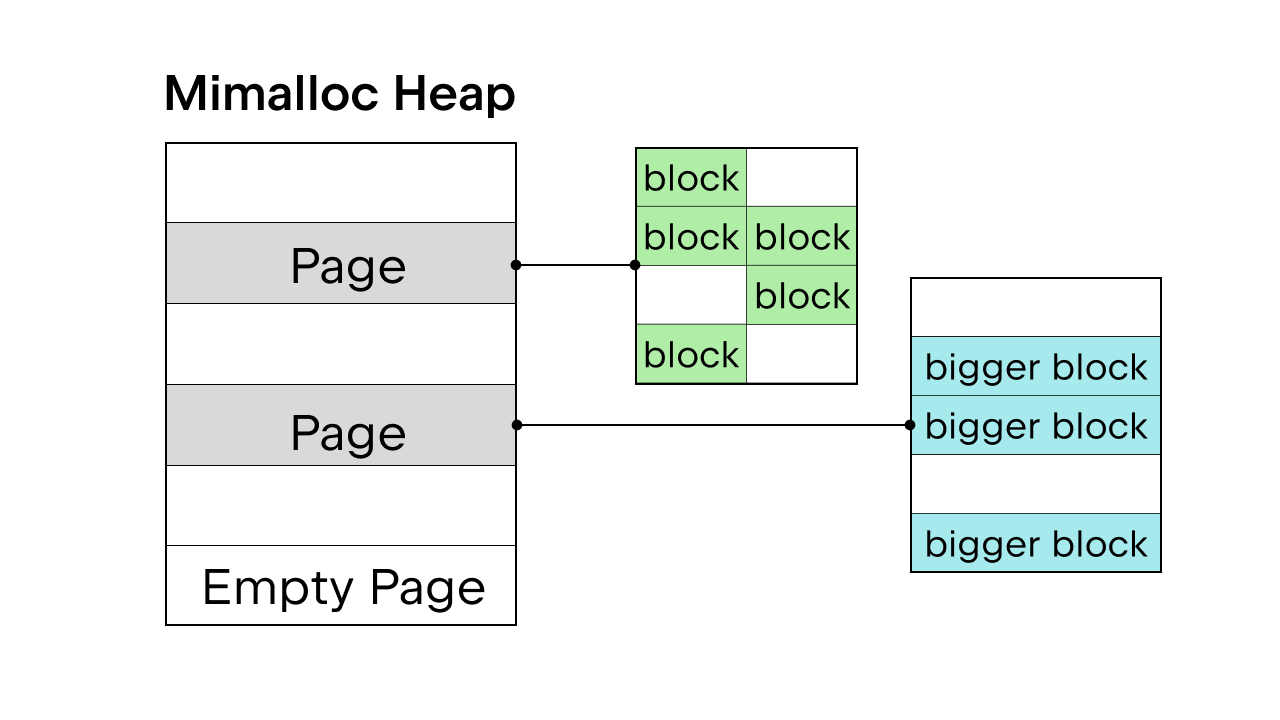
Hay más detalles sobre la eliminación del GIL, pero es imposible abarcarlos todos aquí. Puede consultar PEP 703 – Making the Global Interpreter Lock Optional in CPython para ver un desglose completo.
Diferencia de rendimiento con el GIL y sin él
Como Python 3.13 proporciona una opción de hilo libre, podemos comparar el rendimiento de la versión estándar de Python 3.13 con la versión de hilo libre.
Instalar Python con hilos libres
Utilizaremos pyenv para instalar ambas versiones: la estándar (por ejemplo, 3.13.5) y la versión con hilos libres (por ejemplo, 3.13.5t).
También puede utilizar los instaladores de Python.org. Asegúrese de seleccionar la opción Customize durante la instalación y marque la casilla adicional para instalar Python con hilos libres (consulte el ejemplo de este artículo del blog).
Después de instalar ambas versiones, podemos añadirlas como intérpretes en un proyecto PyCharm.
En primer lugar, haga clic en el nombre de su intérprete de Python en la parte inferior derecha.
Seleccione Add New Interpreter en el menú y, después, Add Local Interpreter.
Elija Select existing, espere a que se cargue la ruta del intérprete (lo que puede tardar un rato si tiene muchos intérpretes como yo) y, a continuación, seleccione el nuevo intérprete que acaba de instalar en el menú desplegable Python path.
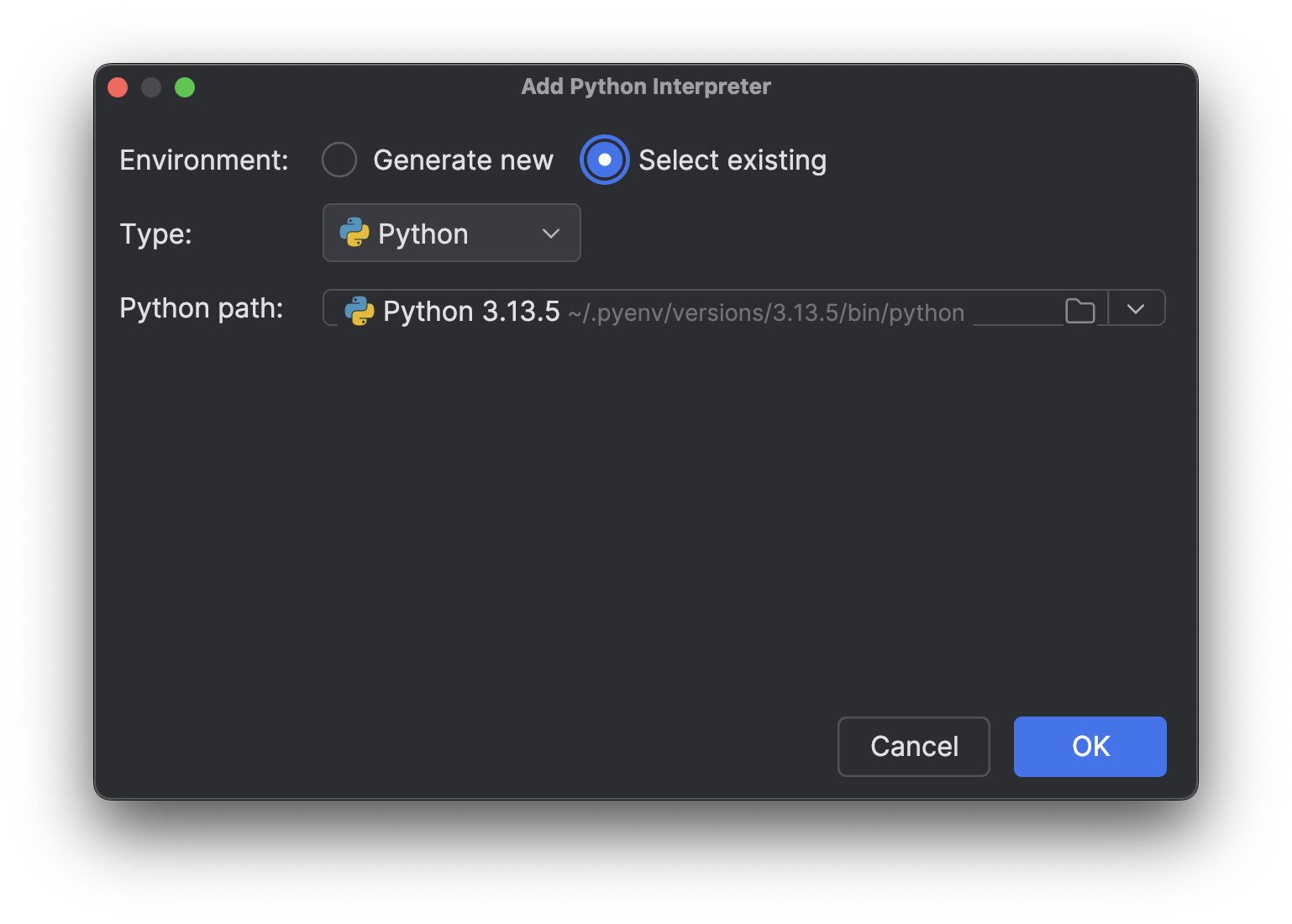
Pulse OK para añadirlo. Repita los mismos pasos para el otro intérprete. Ahora, cuando vuelva a hacer clic en el nombre del intérprete en la parte inferior derecha, verá varios intérpretes de Python 3.13, como en la imagen de arriba.
Pruebas con un proceso limitado por la CPU
A continuación, necesitamos un script para probar las diferentes versiones. Recuerde que en la parte 1 de esta serie de artículos del blog explicamos que para acelerar los procesos limitados por la CPU necesitamos un verdadero multihilo. Para ver si la eliminación del GIL permitirá un verdadero multihilo y hará que Python sea más rápido, podemos hacer una prueba con un proceso limitado por la CPU en varios hilos. Aquí está el guion que le pedí a Junie que generara (con algunos ajustes finales por mi parte):
import time
import multiprocessing # Kept for CPU count
from concurrent.futures import ThreadPoolExecutor
import sys
def is_prime(n):
"""Check if a number is prime (CPU-intensive operation)."""
if n <= 1:
return False
if n <= 3:
return True
if n % 2 == 0 or n % 3 == 0:
return False
i = 5
while i * i <= n:
if n % i == 0 or n % (i + 2) == 0:
return False
i += 6
return True
def count_primes(start, end):
"""Count prime numbers in a range."""
count = 0
for num in range(start, end):
if is_prime(num):
count += 1
return count
def run_single_thread(range_size, num_chunks):
"""Run the prime counting task in a single thread."""
chunk_size = range_size // num_chunks
total_count = 0
start_time = time.time()
for i in range(num_chunks):
start = i * chunk_size + 1
end = (i + 1) * chunk_size + 1 if i < num_chunks - 1 else range_size + 1
total_count += count_primes(start, end)
end_time = time.time()
return total_count, end_time - start_time
def thread_task(start, end):
"""Task function for threads."""
return count_primes(start, end)
def run_multi_thread(range_size, num_threads, num_chunks):
"""Run the prime counting task using multiple threads."""
chunk_size = range_size // num_chunks
total_count = 0
start_time = time.time()
with ThreadPoolExecutor(max_workers=num_threads) as executor:
futures = []
for i in range(num_chunks):
start = i * chunk_size + 1
end = (i + 1) * chunk_size + 1 if i < num_chunks - 1 else range_size + 1
futures.append(executor.submit(thread_task, start, end))
for future in futures:
total_count += future.result()
end_time = time.time()
return total_count, end_time - start_time
def main():
# Fixed parameters
range_size = 1000000 # Range of numbers to check for primes
num_chunks = 16 # Number of chunks to divide the work into
num_threads = 4 # Fixed number of threads for multi-threading test
print(f"Python version: {sys.version}")
print(f"CPU count: {multiprocessing.cpu_count()}")
print(f"Range size: {range_size}")
print(f"Number of chunks: {num_chunks}")
print("-" * 60)
# Run single-threaded version as baseline
print("Running single-threaded version (baseline)...")
count, single_time = run_single_thread(range_size, num_chunks)
print(f"Found {count} primes in {single_time:.4f} seconds")
print("-" * 60)
# Run multi-threaded version with fixed number of threads
print(f"Running multi-threaded version with {num_threads} threads...")
count, thread_time = run_multi_thread(range_size, num_threads, num_chunks)
speedup = single_time / thread_time
print(f"Found {count} primes in {thread_time:.4f} seconds (speedup: {speedup:.2f}x)")
print("-" * 60)
# Summary
print("SUMMARY:")
print(f"{'Threads':<10} {'Time (s)':<12} {'Speedup':<10}")
print(f"{'1 (baseline)':<10} {single_time:<12.4f} {'1.00x':<10}")
print(f"{num_threads:<10} {thread_time:<12.4f} {speedup:.2f}x")
if __name__ == "__main__":
main()
Para facilitar la ejecución del script con diferentes intérpretes de Python, podemos añadir un script de ejecución personalizado a nuestro proyecto PyCharm.
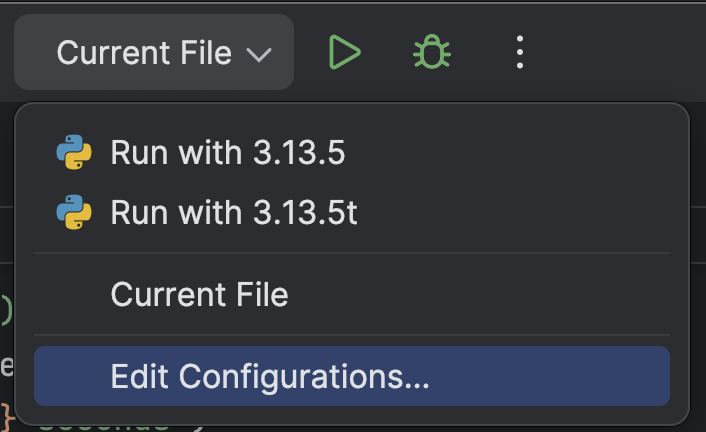
En la parte superior, seleccione Edit Configurations… en el menú desplegable situado junto al botón Run (![]() ).
).
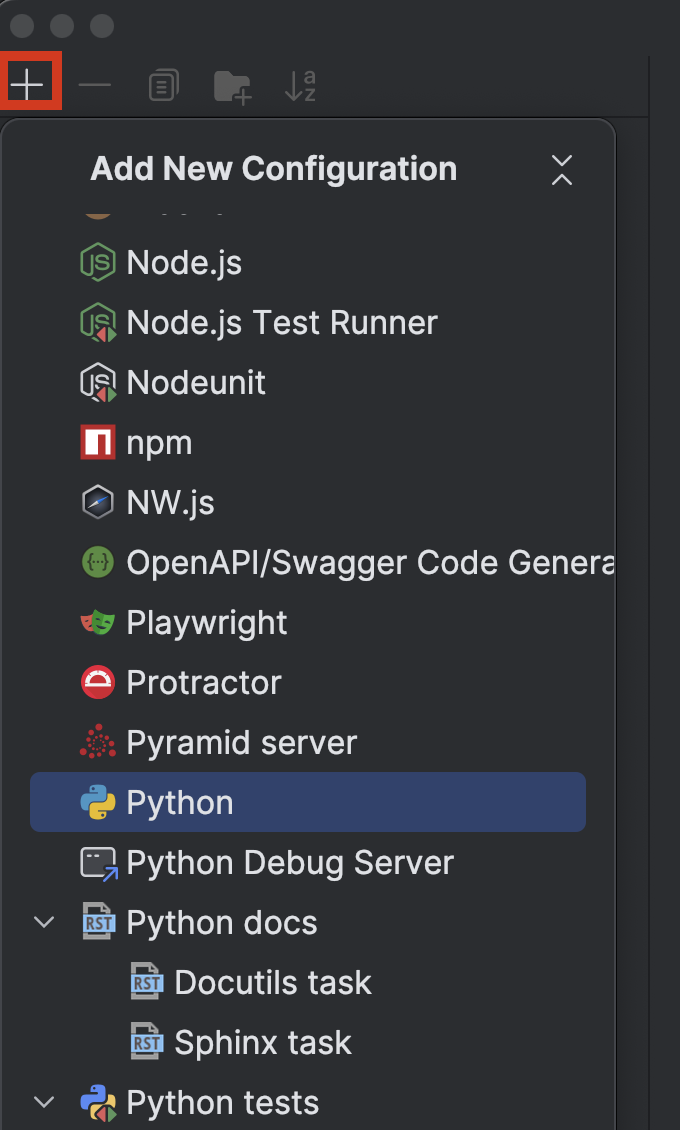
Haga clic en el botón + de la parte superior izquierda y elija Python en el menú desplegable Add New Configuration.
Elija un nombre que le permita saber qué intérprete concreto se está utilizando, por ejemplo, 3.13.5 frente a 3.15.3t. Elija el intérprete adecuado y añada el nombre del script de prueba de esta forma:
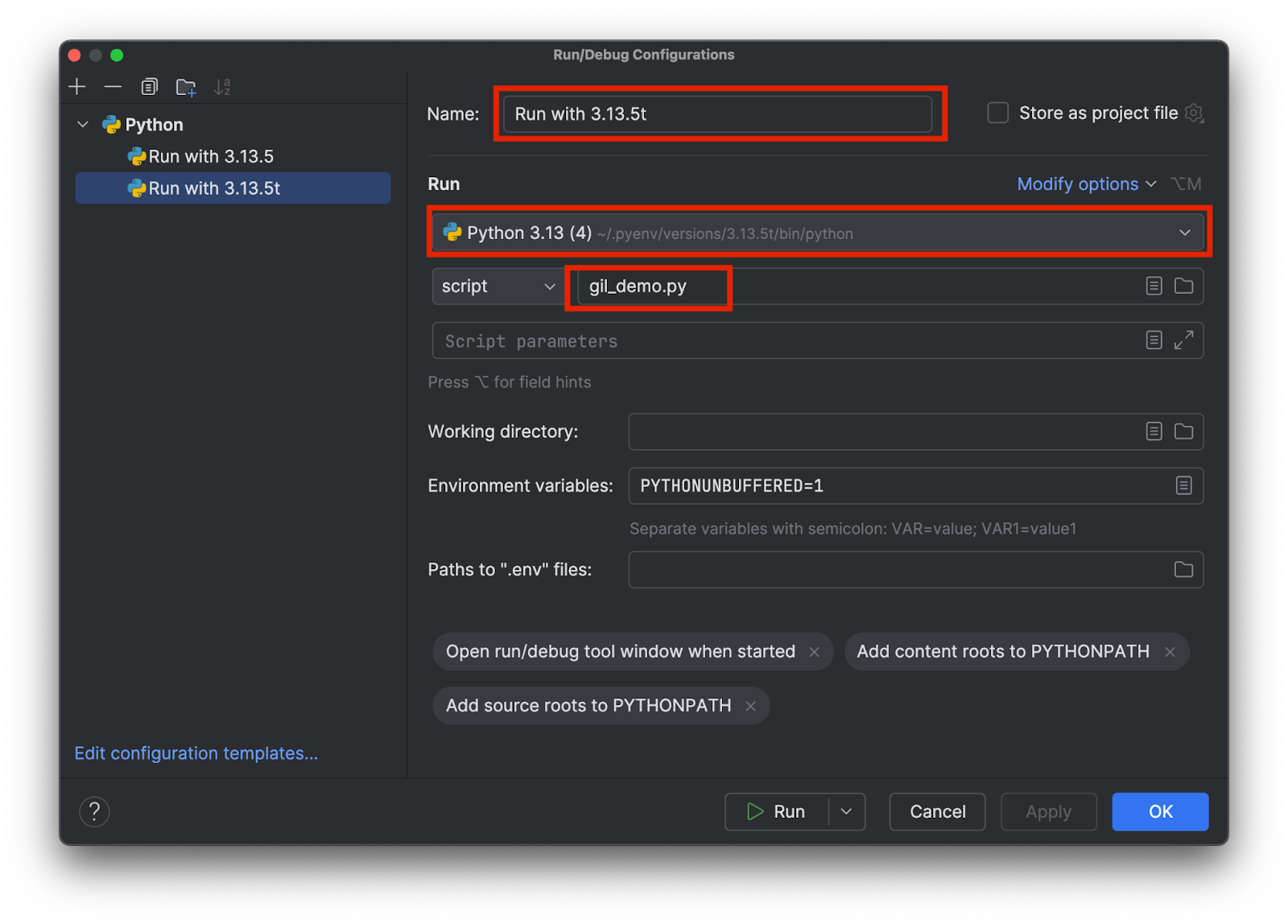
Añada dos configuraciones, una para cada intérprete. A continuación, pulse OK.
Ahora podemos seleccionar y ejecutar fácilmente el script de prueba con el GIL o sin él, seleccionando la configuración y haciendo clic en el botón Run (![]() ) de la parte superior.
) de la parte superior.
Comparación de los resultados
Este es el resultado que obtuve al ejecutar la versión estándar 3.13.5 con el GIL:
Python version: 3.13.5 (main, Jul 10 2025, 20:33:15) [Clang 17.0.0 (clang-1700.0.13.5)] CPU count: 8 Range size: 1000000 Number of chunks: 16 ------------------------------------------------------------ Running single-threaded version (baseline)... Found 78498 primes in 1.1930 seconds ------------------------------------------------------------ Running multi-threaded version with 4 threads... Found 78498 primes in 1.2183 seconds (speedup: 0.98x) ------------------------------------------------------------ SUMMARY: Threads Time (s) Speedup 1 (baseline) 1.1930 1.00x 4 1.2183 0.98x
Como puede ver, no hay ningún cambio significativo en la velocidad cuando se ejecuta la versión con 4 hilos en comparación con la referencia de un solo hilo. Veamos qué obtenemos al ejecutar la versión con hilos libres 3.13.5t:
Python version: 3.13.5 experimental free-threading build (main, Jul 10 2025, 20:36:28) [Clang 17.0.0 (clang-1700.0.13.5)] CPU count: 8 Range size: 1000000 Number of chunks: 16 ------------------------------------------------------------ Running single-threaded version (baseline)... Found 78498 primes in 1.5869 seconds ------------------------------------------------------------ Running multi-threaded version with 4 threads... Found 78498 primes in 0.4662 seconds (speedup: 3.40x) ------------------------------------------------------------ SUMMARY: Threads Time (s) Speedup 1 (baseline) 1.5869 1.00x 4 0.4662 3.40x
Esta vez, la velocidad fue más de 3 veces superior. Observe que en ambos casos existe una sobrecarga por multihilo. Por lo tanto, incluso con un verdadero multihilo, la velocidad no es 4 veces mayor con 4 hilos.
Conclusión
En la parte 2 de la serie de artículos del blog Faster Python, hablamos de la razón de tener el GIL de Python en el pasado, de sortear la limitación del GIL utilizando el multiprocesamiento, y del proceso y efecto de eliminar el GIL.
En el momento de publicar este artículo, la versión de Python con hilos libres aún no es la predeterminada. Sin embargo, con la adopción de la comunidad y de las bibliotecas de terceros, la comunidad espera que la versión de Python con hilos libres sea el estándar en el futuro. Se ha anunciado que Python 3.14 incluirá una versión con hilos libres que habrá superado la fase experimental, pero que seguirá siendo opcional.
PyCharm ofrece la mejor compatibilidad con Python de su clase para garantizar tanto la velocidad como la precisión. Disfrute de la finalización de código más inteligente, las comprobaciones de conformidad PEP 8, las refactorizaciones inteligentes y una gran variedad de inspecciones para satisfacer todas sus necesidades de codificación. Como se demuestra en este artículo, PyCharm ofrece ajustes personalizados para los intérpretes de Python y las configuraciones de ejecución, lo que le permite cambiar entre intérpretes con solo unos clics, por lo que es adecuado para una amplia gama de proyectos de Python.
Artículo original en inglés de:





