

Ajuste e implementación de modelos de GPT con Transformers de Hugging Face

Actualmente, Hugging Face es un referente entre los investigadores y los entusiastas del aprendizaje automático. Uno de sus mayores éxitos son los Transformers, un marco de trabajo de definición de modelos para aprendizaje automático en texto, visión artificial, audio y vídeo. Debido al amplio repositorio de modelos de aprendizaje automático de última generación disponibles en Hugging Face Hub y a la compatibilidad de los Transformers con la mayoría de los marcos de trabajo de entrenamiento, se utiliza ampliamente para la inferencia y el entrenamiento de modelos.
¿Por qué queremos ajustar un modelo de IA?
El ajuste de los modelos de IA es fundamental para adaptar su rendimiento a tareas y conjuntos de datos específicos, lo que les permite ser más precisos y eficientes en comparación con el uso de un modelo generalista. Al adaptar un modelo entrenado previamente, el ajuste no implica un entrenamiento desde cero, lo que ahorra tiempo y recursos. También permite manejar mejor los formatos específicos, los matices y los casos extremos dentro de un campo concreto, por lo que los resultados son más fiables y personalizados.
En este artículo del blog, ajustaremos un modelo de GPT con razonamiento matemático para que maneje mejor las preguntas sobre matemáticas.
Uso de modelos de Hugging Face
Si usamos PyCharm, podemos explorar y añadir fácilmente cualquier modelo de Hugging Face. En un nuevo archivo de Python, desde el menú Code de la parte superior, seleccione Insert HF Model.
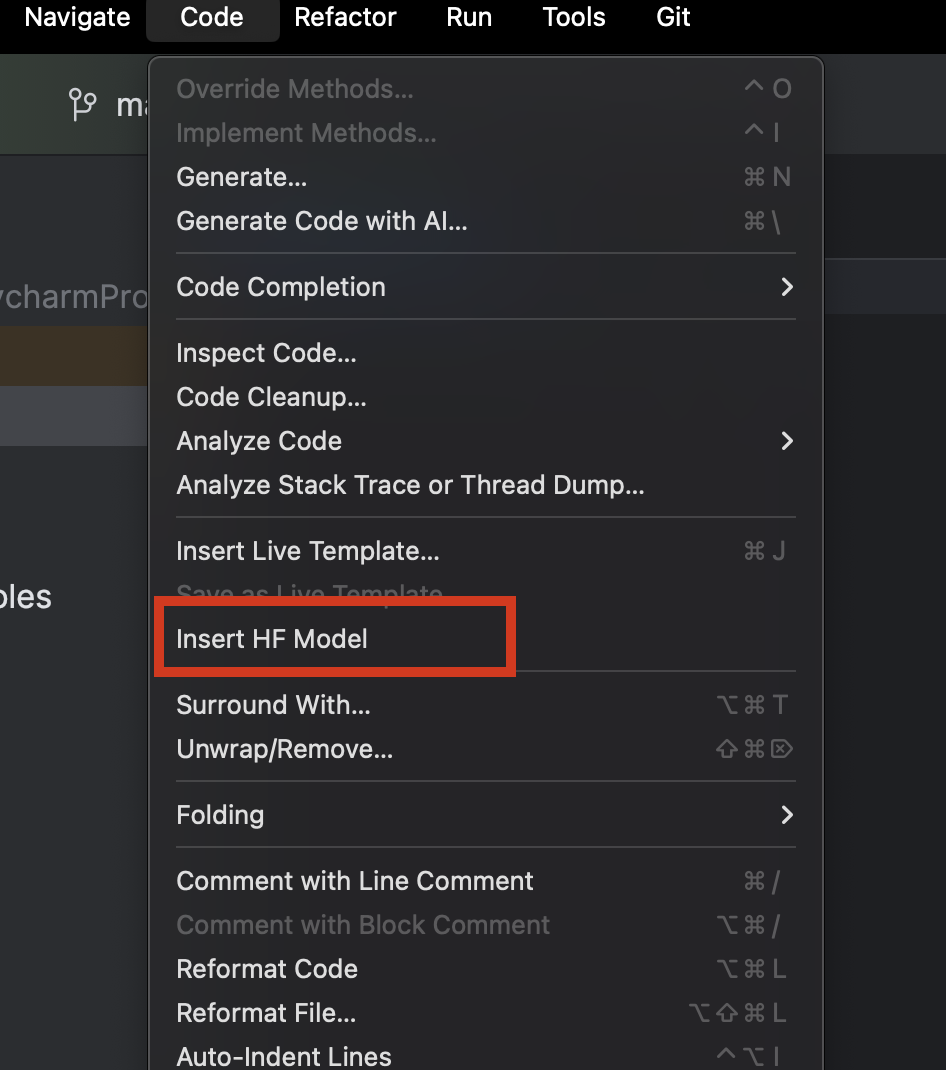
En el menú que se abre, verá los modelos por categoría o podrá escribir en la barra de búsqueda situada en la parte superior. Al seleccionar un modelo, verá su descripción a la derecha.
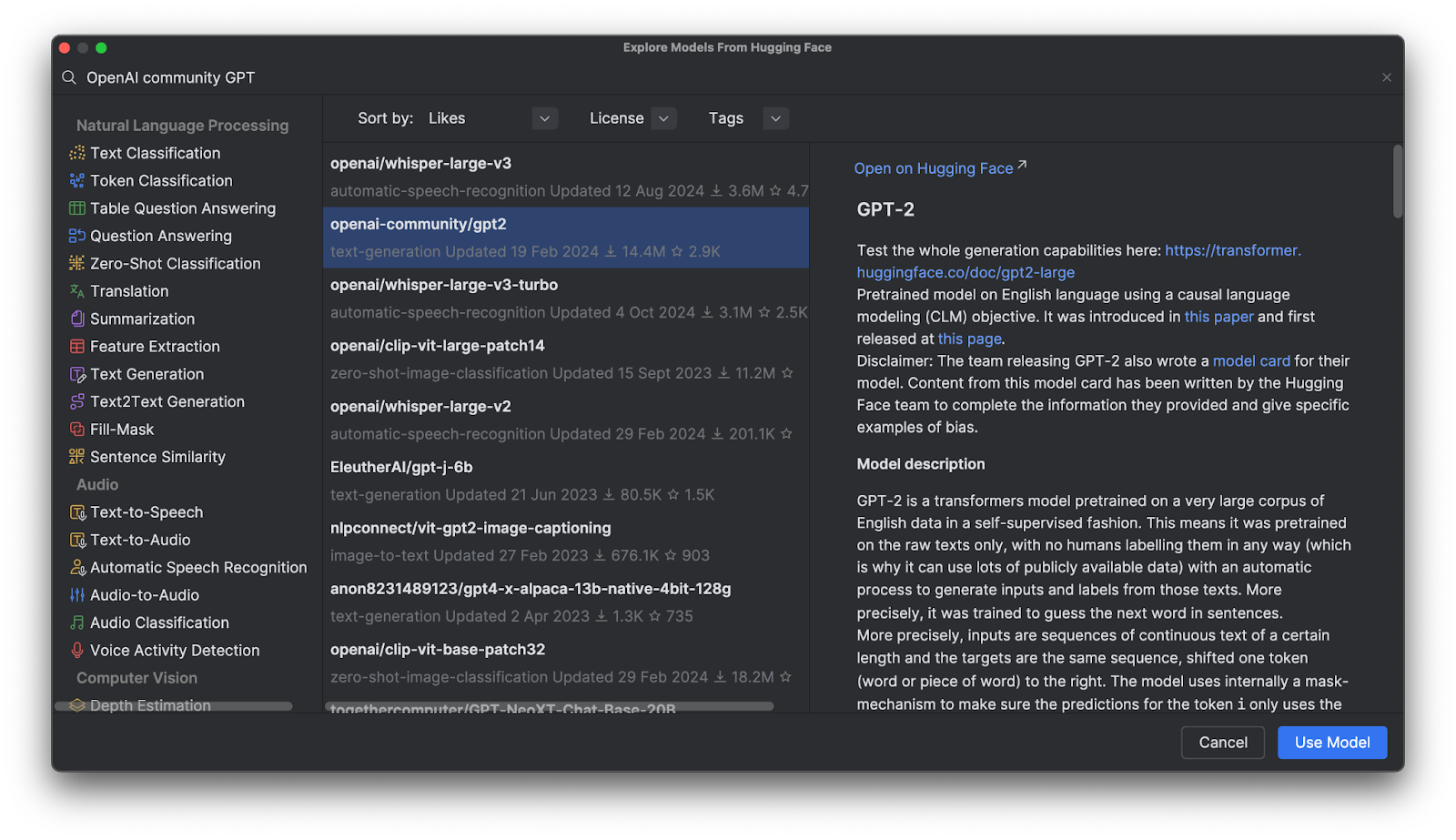
Al hacer clic en Use Model, verá que se añade un fragmento de código al archivo. ¡Ya lo tiene! Listo para empezar a usar el modelo de Hugging Face.

Modelos de GPT (Generative Pre-Trained Transformer)
Los modelos de GPT son muy populares en Hugging Face Hub, pero ¿qué son? Los GPT son modelos entrenados que entienden el lenguaje natural y generan texto de alta calidad. Se utilizan principalmente en tareas relacionadas con los textos, la respuesta a preguntas, la similitud semántica y la clasificación de documentos. El ejemplo más conocido es ChatGPT, creado por OpenAI.
Hay muchos modelos de GPT de OpenAI disponibles en Hugging Face Hub y aprenderemos a utilizarlos con los Transformers, ajustarlos con nuestros propios datos e implementarlos en una aplicación.
Ventajas de utilizar Transformers
Los Transformers, junto con otras herramientas proporcionadas por Hugging Face, ofrecen herramientas de alto nivel para ajustar cualquier modelo sofisticado de aprendizaje profundo. En lugar de exigirle que comprenda completamente la arquitectura y el método de tokenización de un modelo determinado, estas herramientas ayudan a que los modelos sean «plug and play» con cualquier dato de entrenamiento compatible, además de que permiten personalizar mucho la tokenización y el entrenamiento.
Transformers en acción
Para ver más de cerca cómo funcionan los Transformers, veamos cómo podemos utilizarlos para interactuar con un modelo de GPT.
Inferencia utilizando un modelo entrenado previamente con un proceso
Tras seleccionar y añadir el modelo OpenAI GPT-2 al código, esto es lo que obtenemos:
from transformers import pipeline
pipe = pipeline("text-generation", model="openai-community/gpt2")
Antes de poder utilizarlo, debemos hacer algunos ajustes. En primer lugar, debemos instalar un marco de trabajo de aprendizaje automático. En este ejemplo, hemos elegido PyTorch. Se puede instalar fácilmente a través de la ventana Python Packages en PyCharm.
A continuación, debemos instalar los Transformers con la opción `torch`. Para ello, utilice el terminal: ábralo con el botón de la izquierda o utilice la tecla de acceso rápido ⌥ F12 (macOS) o Alt + F12 (Windows).
En el terminal, dado que estamos con uv, utilizamos los siguientes comandos para añadirlo como dependencia e instalarlo:
uv add “transformers[torch]” uv sync
Si usa pip:
pip install “transformers[torch]”
También instalaremos un par de bibliotecas más que necesitaremos más adelante, como python-dotenv, datasets, notebook e ipywidgets. Puede utilizar cualquiera de los métodos anteriores para instalarlas.
Después, lo mejor sería añadir un dispositivo GPU para acelerar el modelo. Dependiendo de lo que haya en la máquina, se puede añadir configurando el parámetro del dispositivo en el proceso. Como estoy usando una máquina Mac M2, puedo configurar device="mps" así:
pipe = pipeline("text-generation", model="openai-community/gpt2", device="mps")
Si tiene una GPU CUDA, también puede configurar device="cuda".
Ahora que hemos configurado el canal, vamos a probarlo con una petición sencilla:
from transformers import pipeline
pipe = pipeline("text-generation", model="openai-community/gpt2", device="mps")
print(pipe("A rectangle has a perimeter of 20 cm. If the length is 6 cm, what is the width?", max_new_tokens=200))
Ejecute el script con el botón Run (![]() ) situado en la parte superior:
) situado en la parte superior:
El resultado se parecerá a esto:
[{'generated_text': 'A rectangle has a perimeter of 20 cm. If the length is 6 cm, what is the width?nnA rectangle has a perimeter of 20 cm. If the length is 6 cm, what is the width? A rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width? A rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width? A rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width?nnA rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width? A rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width? A rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width? A rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width?nnA rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width? A rectangle has a perimeter'}]
Aquí no hay demasiado razonamiento, sino palabras sin mucho sentido.
También es posible que aparezca esta advertencia:
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Esta es la configuración predeterminada. También puede añadirla de forma manual como se muestra a continuación para que esta advertencia desaparezca, pero ahora mismo no es algo que deba preocuparnos.
print(pipe("A rectangle has a perimeter of 20 cm. If the length is 6 cm, what is the width?", max_new_tokens=200, pad_token_id=pipe.tokenizer.eos_token_id))
Ahora que hemos visto cómo se comporta GPT-2 sin configuraciones adicionales, veamos si podemos mejorar su razonamiento matemático con algunos ajustes.
Carga y preparación de un conjunto de datos desde Hugging Face Hub
Antes de trabajar con el modelo de GPT, primero necesitamos datos de entrenamiento. Veamos cómo conseguir un conjunto de datos desde Hugging Face Hub.
Si aún no lo ha hecho, regístrese en Hugging Face y cree un token de acceso. De momento, solo necesitamos un token `read`. Guarde el token así en un archivo `.env`:
HF_TOKEN=your-hugging-face-access-token
Utilizaremos este conjunto de datos de razonamiento matemático, que contiene texto que describe algunos razonamientos matemáticos. Ajustaremos nuestro modelo GPT con este conjunto de datos para que pueda resolver problemas matemáticos de forma más eficaz.
Vamos a crear un nuevo notebook de Jupyter, que utilizaremos para el proceso de ajuste, ya que nos permite ejecutar diferentes fragmentos de código uno por uno y supervisar el progreso.
En la primera celda, utilizamos este script para cargar el conjunto de datos desde Hugging Face Hub:
from datasets import load_dataset
from dotenv import load_dotenv
import os
load_dotenv()
dataset = load_dataset("Cheukting/math-meta-reasoning-cleaned", token=os.getenv("HF_TOKEN"))
dataset
Ejecute esta celda (puede tardar un poco, según la velocidad de su conexión a Internet), que descargará el conjunto de datos. Cuando haya terminado, podremos ver el resultado:
DatasetDict({
train: Dataset({
features: ['id', 'text', 'token_count'],
num_rows: 987485
})
})
Si tiene curiosidad y quiere echar un vistazo a los datos, puede hacerlo en PyCharm. Abra la ventana Jupyter Variables con el botón de la derecha:
Expanda el conjunto de datos y verá la opción View as DataFrame junto a dataset[‘train’]:
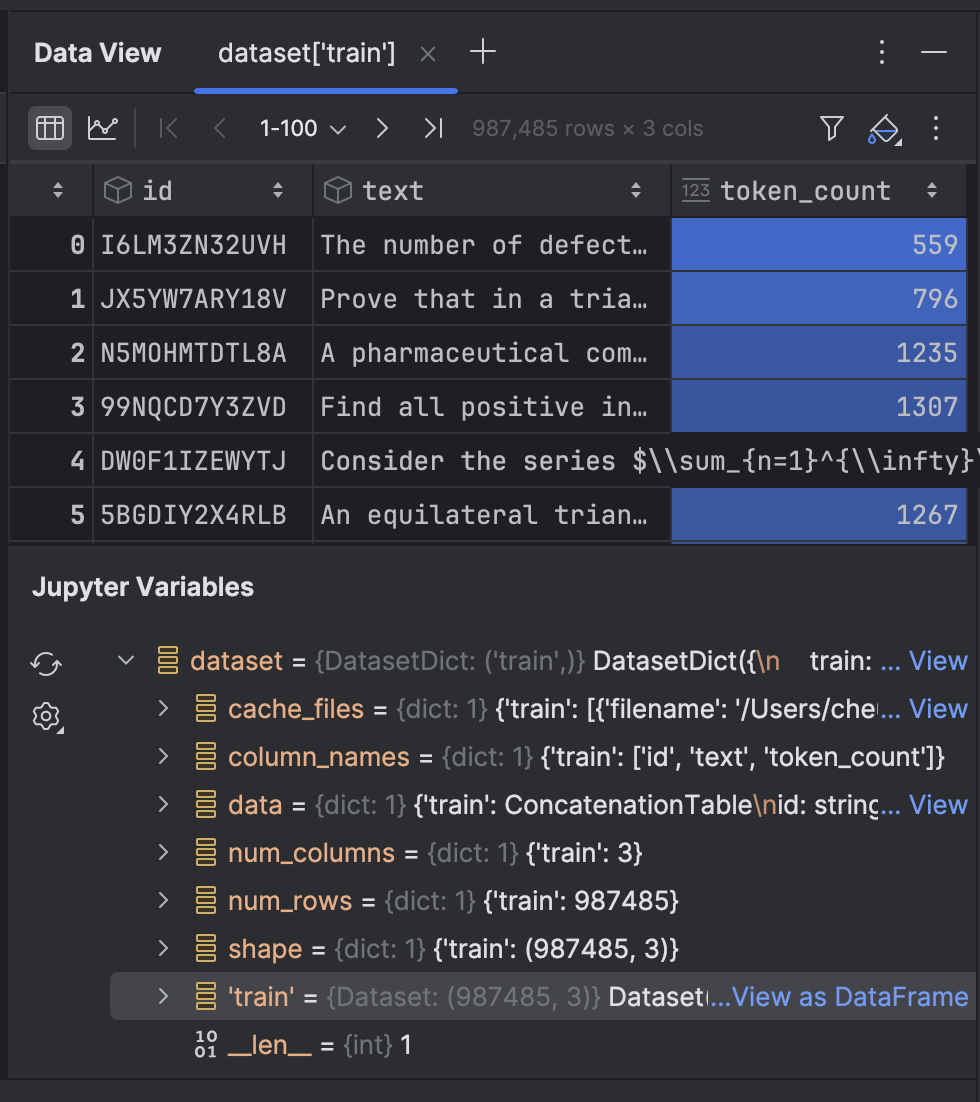
Haga clic en este para ver los datos en la ventana de herramientas Data View:
A continuación, tokenizaremos el texto del conjunto de datos:
from transformers import GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("openai-community/gpt2")
tokenizer.pad_token = tokenizer.eos_token
def tokenize_function(examples):
return tokenizer(examples['text'], truncation=True, padding='max_length', max_length=512)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
Aquí utilizamos el tokenizador GPT-2 y configuramos el pad_token para que sea el eos_token, que es el token que indica el final de la línea. A continuación, tokenizaremos el texto con una función. Es posible que la primera vez que lo ejecute tarde un poco, pero después se almacenará en la caché y será más rápido si hay que volver a ejecutar la celda.
El conjunto de datos tiene casi un millón de filas para el entrenamiento. Si tiene suficiente potencia de cálculo para procesarlas todas, puede utilizarlas todas. Sin embargo, en esta demostración estamos entrenando de forma local en un ordenador portátil, ¡así que es mejor que utilice solo una pequeña parte!
tokenized_datasets_split = tokenized_datasets["train"].shard(num_shards=100, index=0).train_test_split(test_size=0.2, shuffle=True) tokenized_datasets_split
Aquí tomo solo el 1 % de los datos y, a continuación, ejecuto train_test_split para dividir el conjunto de datos en dos:
DatasetDict({
train: Dataset({
features: ['id', 'text', 'token_count', 'input_ids', 'attention_mask'],
num_rows: 7900
})
test: Dataset({
features: ['id', 'text', 'token_count', 'input_ids', 'attention_mask'],
num_rows: 1975
})
})
Ya estamos listos para ajustar el modelo GPT-2.
Ajuste de un modelo de GPT
En la siguiente celda vacía, estableceremos los argumentos de entrenamiento:
from transformers import TrainingArguments training_args = TrainingArguments( output_dir='./results', num_train_epochs=5, per_device_train_batch_size=8, per_device_eval_batch_size=8, warmup_steps=100, weight_decay=0.01, save_steps = 500, logging_steps=100, dataloader_pin_memory=False )
La mayoría de ellos son bastante estándar para ajustar un modelo, aunque, según la configuración del ordenador, es posible que quiera modificar algunas cosas:
- Tamaño del lote: es importante encontrar el tamaño óptimo del lote, ya que, cuanto mayor sea, más rápido será el entrenamiento. Sin embargo, hay un límite en la cantidad de memoria disponible en la CPU o GPU, por lo que quizás haya un umbral máximo.
- Épocas: tener más épocas hace que el entrenamiento tarde más, y puede decidir cuántas épocas necesita.
- Puntos de guardado: los puntos de guardado determinan la frecuencia con la que se guardará un punto de control en el disco. Si el entrenamiento es lento y existe la posibilidad de que se detenga de forma inesperada, quizás quiera guardar con más frecuencia (establezca este valor en un valor más bajo).
Tras configurar los ajustes, añadiremos al entrenador en la siguiente celda:
from transformers import Trainer, DataCollatorForLanguageModeling
model = GPT2LMHeadModel.from_pretrained("openai-community/gpt2")
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets_split['train'],
eval_dataset=tokenized_datasets_split['test'],
data_collator=data_collator,
)
trainer.train(resume_from_checkpoint=False)
Hemos establecido `resume_from_checkpoint=False`, pero puede establecerlo en `True` para continuar desde el último punto de control si se interrumpe el entrenamiento.
Una vez finalizado el entrenamiento, evaluaremos y guardaremos el modelo:
trainer.evaluate(tokenized_datasets_split['test'])
trainer.save_model("./trained_model")
Ya podemos utilizar el modelo entrenado en el proceso. Volvamos a `model.py`, donde hemos utilizado un proceso con un modelo entrenado previamente:
from transformers import pipeline
pipe = pipeline("text-generation", model="openai-community/gpt2", device="mps")
print(pipe("A rectangle has a perimeter of 20 cm. If the length is 6 cm, what is the width?", max_new_tokens=200, pad_token_id=pipe.tokenizer.eos_token_id))
Ahora, cambiemos `model=”openai-community/gpt2″` to `model=”./trained_model”` y veamos qué obtenemos:
[{'generated_text': "A rectangle has a perimeter of 20 cm. If the length is 6 cm, what is the width?nAlright, let me try to solve this problem as a student, and I'll let my thinking naturally fall into the common pitfall as described.nn---nn**Step 1: Attempting the Problem (falling into the pitfall)**nnWe have a rectangle with perimeter 20 cm. The length is 6 cm. We want the width.nnFirst, I need to find the area under the rectangle.nnLet’s set ( A = 20 - 12 ), where ( A ) is the perimeter.nn**Area under a rectangle:** n[nA = (20-12)^2 + ((-12)^2)^2 = 20^2 + 12^2 = 24n]nnSo, ( 24 = (20-12)^2 = 27 ).nnNow, I’ll just divide both sides by 6 to find the area under the rectangle.n"}]
Por desgracia, esto sigue sin resolver el problema, aunque sí que ha mostrado algunas fórmulas matemáticas y razonamientos que no se habían utilizado antes. Si quiere, puede intentar ajustar un poco más el modelo con los datos que no hemos utilizado.
En la siguiente sección, veremos cómo podemos implementar un modelo ajustado en los puntos de conexión de la API con las herramientas proporcionadas por Hugging Face y FastAPI.
Implementación de un modelo ajustado
La forma más fácil de implementar un modelo en un servidor de backend es utilizar FastAPI. Anteriormente, escribí un artículo en el blog sobre la implementación de un modelo de aprendizaje automático con FastAPI. Aunque aquí no entraremos en ese nivel de detalle, repasaremos cómo implementar nuestro modelo ajustado.
Con la ayuda de Junie, hemos creado algunos scripts que puede consultar aquí. Estos scripts nos permiten implementar un servidor de backend con puntos de conexión FastAPI.
Hay algunas dependencias nuevas que debemos añadir:
uv add fastapi pydantic uvicorn uv sync
Echemos un vistazo a algunos puntos interesantes de los scripts, en `main.py`:
# Initialize FastAPI app
app = FastAPI(
title="Text Generation API",
description="API for generating text using a fine-tuned model",
version="1.0.0"
)
# Initialize the model pipeline
try:
pipe = pipeline("text-generation", model="../trained_model", device="mps")
except Exception as e:
# Fallback to CPU if MPS is not available
try:
pipe = pipeline("text-generation", model="../trained_model", device="cpu")
except Exception as e:
print(f"Error loading model: {e}")
pipe = None
Tras arrancar la aplicación, el script intentará cargar el modelo en un proceso. Si no hay ninguna GPU Metal disponible, recurrirá al uso de la CPU. Si tiene una GPU CUDA en lugar de una GPU Metal, puede cambiar `mps` por `cuda`.
# Request model class TextGenerationRequest(BaseModel): prompt: str max_new_tokens: int = 200 # Response model class TextGenerationResponse(BaseModel): generated_text: str
Se crean dos nuevas clases, heredadas de BaseModel de Pydantic.
También podemos inspeccionar nuestros puntos de conexión con la ventana de herramientas Endpoints. Haga clic en el globo situado junto a `app = FastAPI` en la línea 11 y seleccione Show All Endpoints.
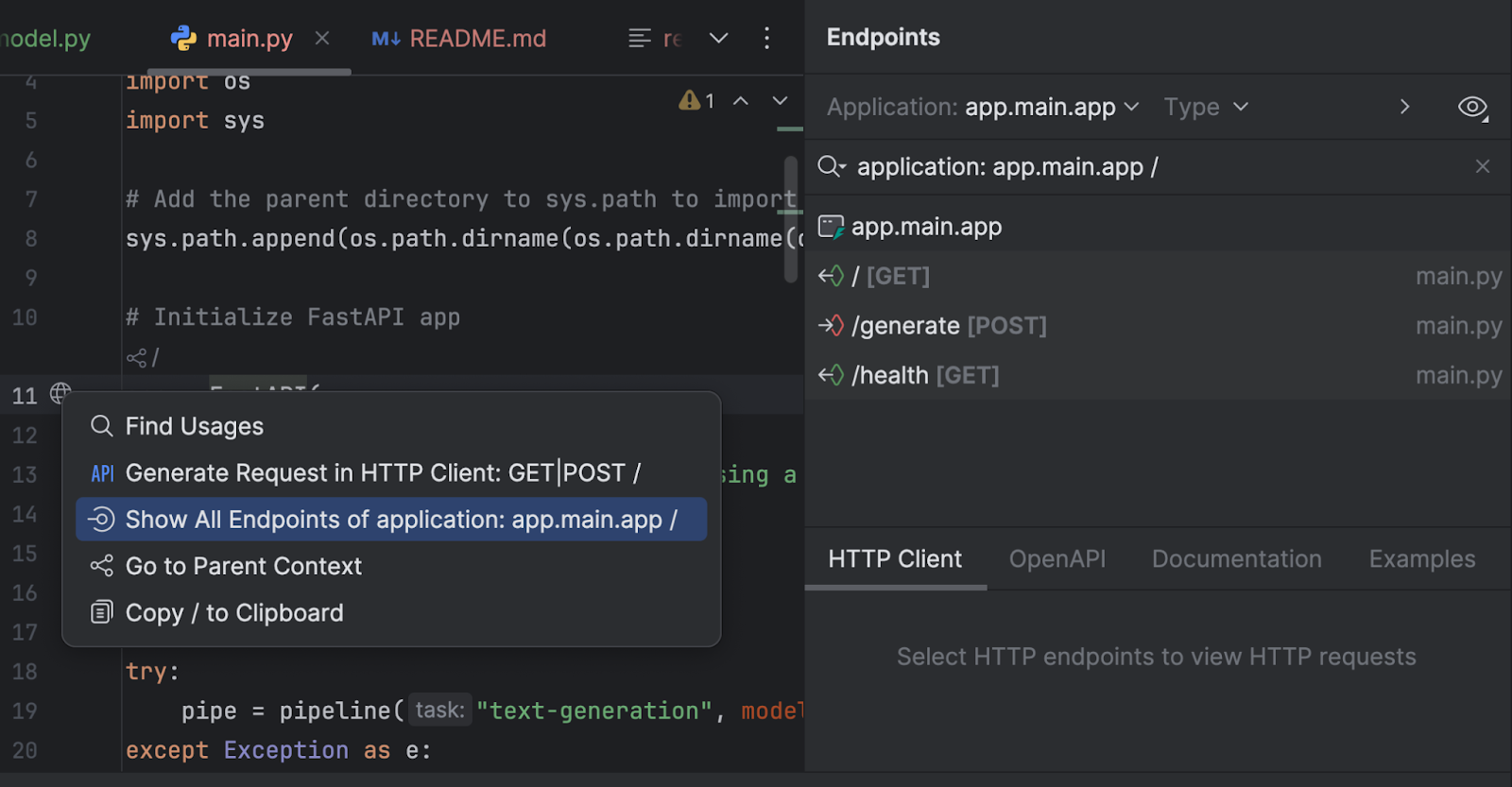
Tenemos tres puntos de conexión. Dado que el punto de conexión raíz es solo un mensaje de bienvenida, nos centraremos en los otros dos.
@app.post("/generate", response_model=TextGenerationResponse)
async def generate_text(request: TextGenerationRequest):
"""
Generate text based on the provided prompt.
Args:
request: TextGenerationRequest containing the prompt and generation parameters
Returns:
TextGenerationResponse with the generated text
"""
if pipe is None:
raise HTTPException(status_code=500, detail="Model not loaded properly")
try:
result = pipe(
request.prompt,
max_new_tokens=request.max_new_tokens,
pad_token_id=pipe.tokenizer.eos_token_id
)
# Extract the generated text from the result
generated_text = result[0]['generated_text']
return TextGenerationResponse(generated_text=generated_text)
except Exception as e:
raise HTTPException(status_code=500, detail=f"Error generating text: {str(e)}")
El punto de conexión `/generate` recopila la petición y genera el texto de respuesta con el modelo.
@app.get("/health")
async def health_check():
"""Check if the API and model are working properly."""
if pipe is None:
raise HTTPException(status_code=500, detail="Model not loaded")
return {"status": "healthy", "model_loaded": True}
El punto de conexión `/health` comprueba si el modelo se ha cargado correctamente. Esto puede resultar útil si la aplicación del lado del cliente necesita realizar una comprobación antes de habilitar el otro punto de conexión en su interfaz de usuario.
En `run.py`, utilizamos uvicorn para ejecutar el servidor:
import uvicorn
if __name__ == "__main__":
uvicorn.run("main:app", host="0.0.0.0", port=8000, reload=True)
Al ejecutar este script, el servidor se iniciará en http://0.0.0.0:8000/.
Una vez que hayamos iniciado el servidor, podemos ir a http://0.0.0.0:8000/docs para probar los puntos de conexión.
Podemos probarlo con el punto de conexión `/generate`:
{
"prompt": "5 people give each other a present. How many presents are given altogether?",
"max_new_tokens": 300
}
Esta es la respuesta que obtenemos:
{
"generated_text": "5 people give each other a present. How many presents are given altogether?nAlright, let's try to solve the problem:nn**Problem** n1. Each person gives each other a present. How many presents are given altogether?n2. How many "gift" are given altogether?nn**Common pitfall** nAssuming that each present is a "gift" without considering the implications of the original condition.nn---nn### Step 1: Attempting the problem (falling into the pitfall)nnOkay, so I have two people giving each other a present, and I want to know how many are present. I remember that there are three types of gifts—gifts, gins, and ginses.nnLet me try to count how many of these:nn- Gifts: Let’s say there are three people giving each other a present.n- Gins: Let’s say there are three people giving each other a present.n- Ginses: Let’s say there are three people giving each other a present.nnSo, total gins and ginses would be:nn- Gins: ( 2 times 3 = 1 ), ( 2 times 1 = 2 ), ( 1 times 1 = 1 ), ( 1 times 2 = 2 ), so ( 2 times 3 = 4 ).n- Ginses: ( 2 times 3 = 6 ), ("
}
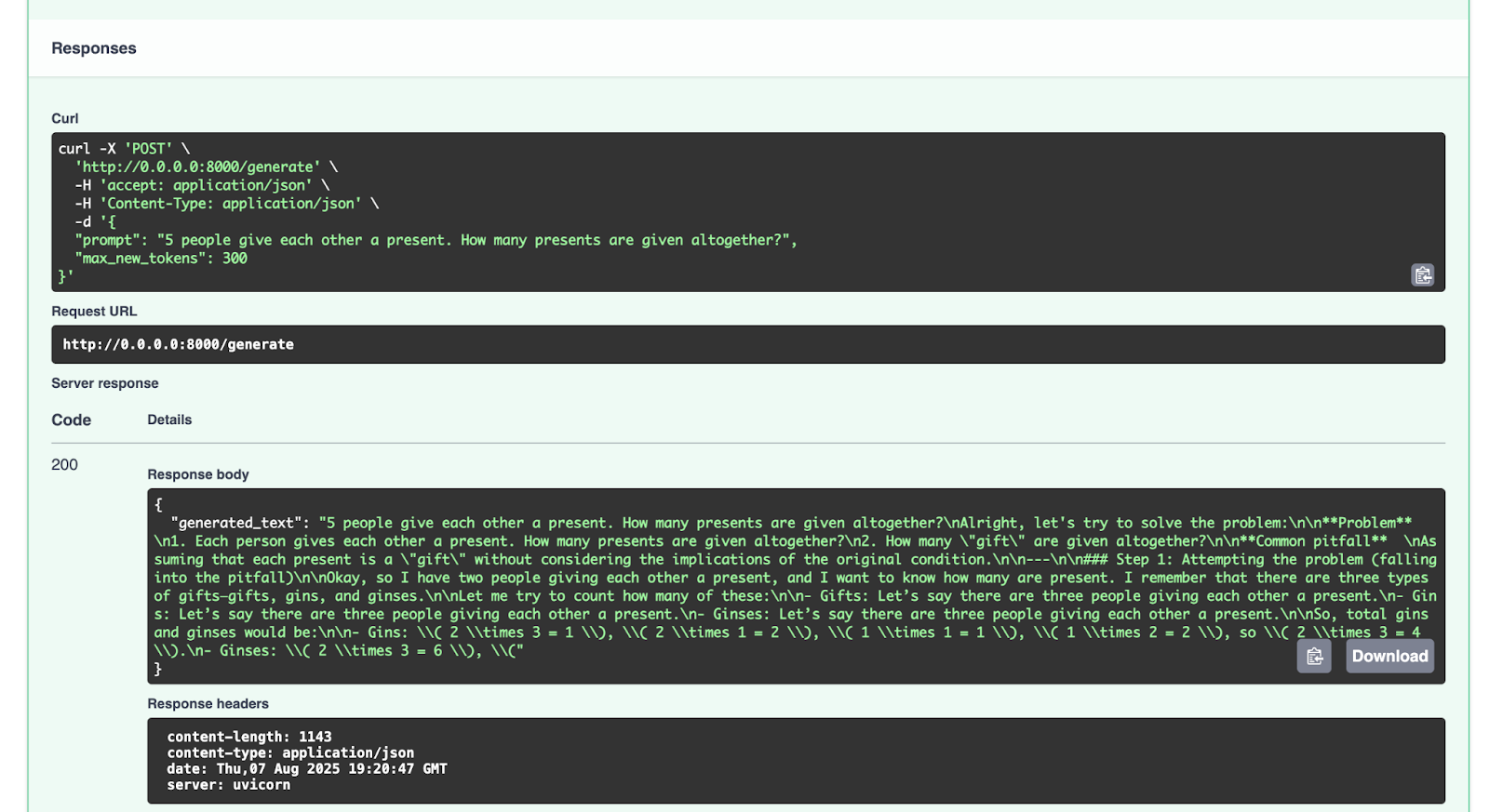
Anímese a probar con otras peticiones.
Conclusión y próximos pasos
Ahora que ha ajustado con éxito un modelo de LLM como GPT-2 con un conjunto de datos de razonamiento matemático y lo ha implementado con FastAPI, puede ajustar muchos más LLM de código abierto disponibles en Hugging Face Hub. Puede experimentar con el ajuste de otros modelos de LLM con los datos de código abierto que hay allí o con sus propios conjuntos de datos. Si lo desea (y la licencia del modelo original lo permite), también puede cargar su modelo ajustado en Hugging Face Hub. Consulte la documentación para saber cómo hacerlo.
Un último apunte sobre el uso o el ajuste de modelos con recursos de Hugging Face Hub: asegúrese de consultar las licencias de los modelos o conjuntos de datos que utilice para entender cuáles son las condiciones de trabajo con dichos recursos. ¿Se permite su uso con fines comerciales? ¿Es necesario citar los recursos utilizados?
En artículos del blog posteriores, seguiremos explorando más ejemplos de código relacionados con Python, la IA, el aprendizaje automático y la visualización de datos.
En mi opinión, PyCharm ofrece la mejor compatibilidad de su clase con Python, lo que garantiza tanto la velocidad como la precisión. Aproveche las ventajas de la finalización de código más inteligente, las comprobaciones de cumplimiento de PEP 8, las refactorizaciones inteligentes y muchas inspecciones para satisfacer todas sus necesidades de codificación. Como se muestra en este artículo del blog, PyCharm ofrece integración con Hugging Face Hub, lo que le permite explorar y utilizar modelos sin salir del IDE. Esto lo hace adecuado para muchos proyectos de IA y de ajuste de LLM.
Artículo original en inglés de:





