

7 façons d’utiliser les notebooks Jupyter dans PyCharm

Les notebooks Jupyter vous permettent de présenter des analyses en créant et en partageant des données, des équations et des visualisations de façon séquentielle, tout en développant un récit structuré au fil du notebook.
L’utilisation de notebooks Jupyter dans PyCharm Professional donne accès à des fonctionnalités allant bien au-delà de celles dont on peut disposer avec des notebooks basés sur un navigateur, parmi lesquelles la saisie semi-automatique de code, les graphiques dynamiques et les statistiques rapides, qui facilitent l’exploration des données et vous aident à les manipuler rapidement et efficacement.
Nous allons voir 7 façons d’utiliser les notebooks Jupyter dans PyCharm pour atteindre les objectifs suivants :
- Créer un notebook ou se connecter à un notebook existant
- Importer vos données
- Vous familiariser avec les données
- Tirer parti de l’AI Assistant de JetBrains
- Explorer votre code avec PyCharm
- Obtenir des informations sur les données à partir du code
- Partager vos analyses et vos graphiques
Le notebook Jupyter utilisé dans cette démo est disponible sur GitHub.
1. Créer un notebook ou se connecter à un notebook existant
Vous pouvez créer vos notebooks Jupyter et les utiliser localement ou vous connecter à un notebook distant avec PyCharm. Examinons les deux possibilités.
Créer un nouveau notebook Jupyter
Pour travailler localement avec un notebook Jupyter, ouvrez la fenêtre d’outils Project dans PyCharm, naviguez jusqu’à l’emplacement où vous voulez ajouter le notebook et appelez un nouveau fichier. Pour ce faire, vous pouvez utiliser un raccourci clavier ⌘N (macOS) / Alt+Ins (Windows/Linux) ou faire un clic droit et sélectionner New | Jupyter Notebook.
Une fois que vous aurez nommé votre nouveau notebook, PyCharm l’ouvrira et vous pourrez commencer à l’utiliser. Vous pouvez également faire glisser vos notebooks Jupyter enregistrés localement dans PyCharm et l’IDE les reconnaîtra automatiquement.
Se connecter à un notebook Jupyter distant
Pour vous connecter à un notebook Jupyter distant, sélectionnez Tools | Add Jupyter Connection. Vous pouvez ensuite choisir entre démarrer un serveur Jupyter local, vous connecter à un serveur Jupyter local existant ou vous connecter à un serveur Jupyter via une URL – toutes ces options sont prises en charge.
Maintenant que vous disposez de votre notebook Jupyter, il s’agit d’avoir des données !
2. Importer vos données
Les données se présentent généralement dans deux formats, CSV ou base de données. Nous allons commencer par l’importation de données à partir d’un fichier CSV.
Importation depuis un fichier CSV
Polars et Pandas sont les bibliothèques les plus utilisées pour l’importation de données dans des notebooks Jupyter. Dans cette section, je vais vous fournir du code pour les deux. Vous pouvez consulter la documentation afin de comprendre en quoi elles sont différentes.
Vous devez d’abord vous assurer que votre fichier CSV se trouve bien dans votre projet PyCharm, par exemple dans un dossier appelé « data ». Ensuite, vous pouvez appeler Pandas et l’utiliser pour lire le code :
import pandas as pd
df = pd.read_csv("../data/airlines.csv")
Dans cet exemple, airlines.csv est le fichier contenant les données à manipuler. Pour exécuter cette cellule de code ou toute autre cellule de code dans PyCharm, utilisez ⇧⏎ (macOS) / Maj+Entrée (Windows/Linux). Vous pouvez également utiliser les flèches vertes disponibles dans la barre d’outils située en haut.
Si vous préférez utiliser Polars, vous pouvez le faire avec le code suivant :
import polars as pl
df = pl.read_csv("../data/airlines.csv")
Importation depuis une base de données
Si vos données sont dans une base, ce qui est généralement le cas pour les projets internes, leur importation dans un notebook Jupyter ne demande que quelques lignes de code en plus. Commencez par configurer votre connexion à la base de données. Dans cet exemple, nous utilisons PostgreSQL.
Pour pandas, vous devez utiliser le code suivant pour importer les données :
import pandas as pd
engine = create_engine("postgresql://jetbrains:jetbrains@localhost/demo")
df = pd.read_sql(sql=text("SELECT * FROM airlines"),
con=engine.connect())
Pour Polars, utilisez ce code :
import polars as pl
engine = create_engine("postgresql://jetbrains:jetbrains@localhost/demo")
connection = engine.connect()
query = "SELECT * FROM airlines"
df = pl.read_database(query, connection)
3. Vous familiariser avec les données
Maintenant que nous avons importé nos données, nous pouvons examiner le DataFrame ou « df » comme nous l’appellerons dans notre code. L’impression du DataFrame ne requiert qu’une seule ligne de code, quelle que soit la méthode utilisée pour importer les données :
df
DataFrames
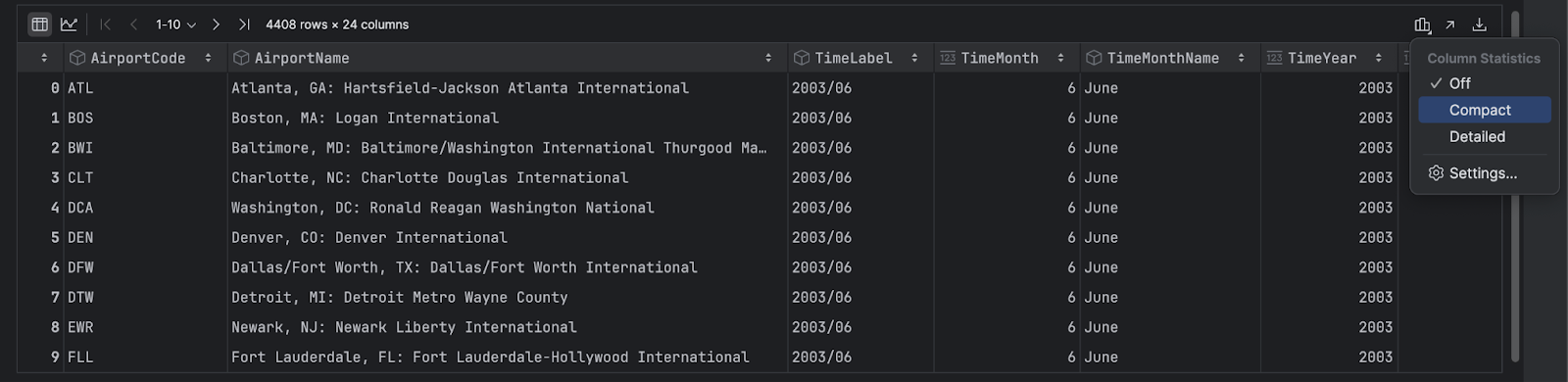
En premier lieu, PyCharm affiche votre DataFrame sous forme de table. Vous pouvez faire défiler le DataFrame horizontalement et cliquer sur n’importe quel en-tête de colonne pour trier les données en fonction de cette colonne. Pour obtenir des statistiques sur chaque colonne de données, cliquez sur l’icône Show Column Statistics située à droite et sélectionnez Compact ou Detailed.
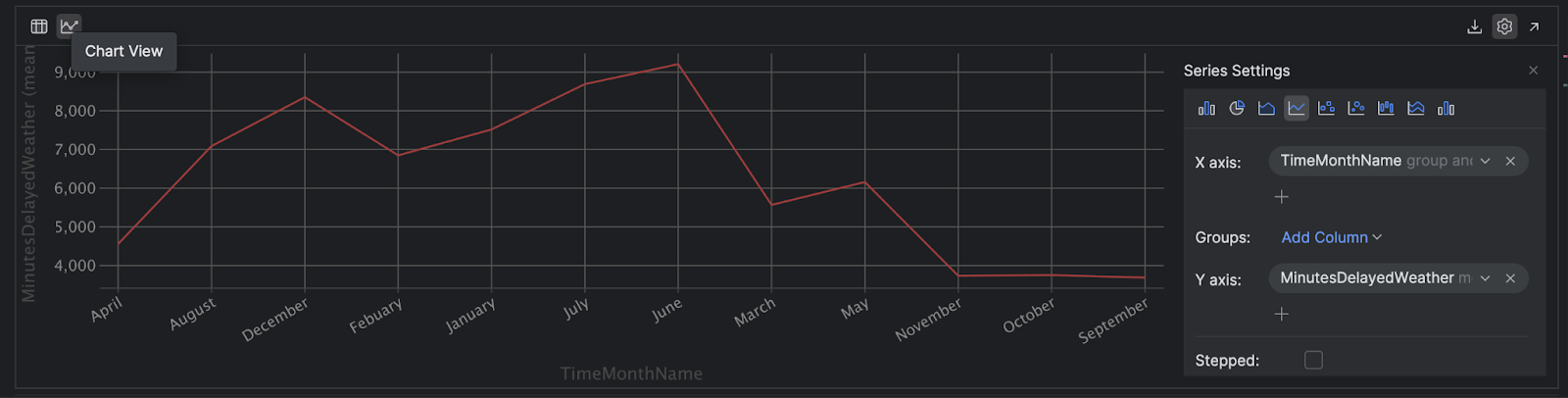
Graphiques dynamiques
PyCharm vous permet de créer un graphique dynamique à partir de votre DataFrame en cliquant sur l’icône Chart View située à gauche. Nous utilisons pandas dans cet exemple, mais la même option est disponible pour les DataFrames Polars.
Cliquez sur l’icône Show Series Settings (rouage) située à droite pour configurer votre graphique en fonction de vos besoins :
Dans cette vue, vous pouvez obtenir plus d’informations sur les données en les survolant et repérer facilement les valeurs aberrantes :
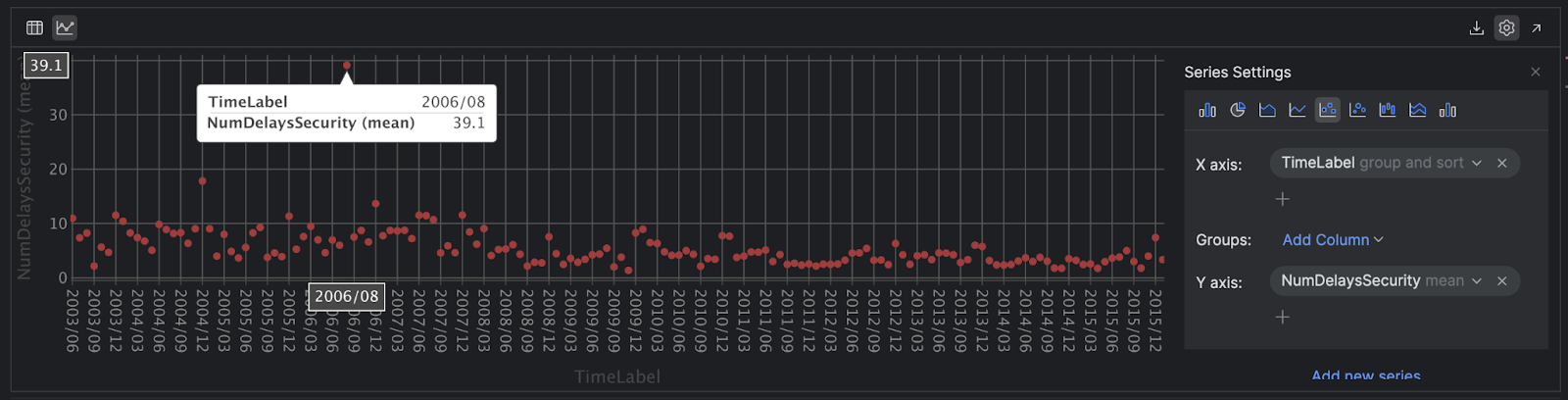
Il est possible de faire de même avec Polars.
4. Tirer parti de l’AI Assistant de JetBrains
L’AI Assistant de JetBrains propose plusieurs fonctionnalités pour améliorer votre productivité lors de l’utilisation des notebooks Jupyter dans PyCharm. Examinons plus en détail comment utiliser l’AI Assistant pour expliquer un DataFrame, écrire du code et même obtenir des explications sur les erreurs.
Expliquer les DataFrames
Si vous avez un DataFrame mais que vous ne savez pas par où commencer, cliquez sur l’icône AI violette dans la partie droite de ce DataFrame et sélectionnez Explain DataFrame. L’AI Assistant utilisera son contexte pour vous fournir une vue d’ensemble du DataFrame :
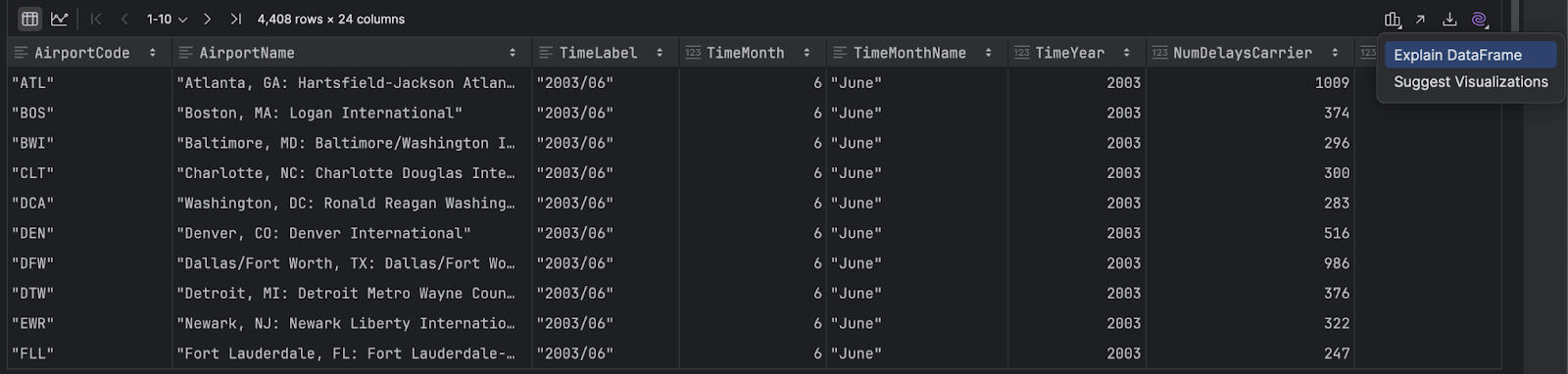
Écrire du code
L’AI Assistant peut aussi vous aider pour l’écriture de code, par exemple, si vous savez quel type de graphique vous voulez mais que vous n’êtes pas totalement sûr du code à utiliser. Supposons que vous souhaitiez utiliser matplotlib pour créer un graphique qui trouvera la relation entre « TimeMonthName » et « MinutesDelayedWeather ». En spécifiant les noms des colonnes, on fournit davantage de contexte à la requête, ce qui augmente la fiabilité du code généré. Essayez avec le prompt suivant :
Give me code using matplotlib to create a chart which finds the relationship between ‘TimeMonthName’ and ‘MinutesDelayedWeather’ for my dataframe df
Si le code généré vous convient, utilisez le bouton Insert Snippet at Caret pour l’insérer et l’exécuter :
import matplotlib.pyplot as plt
# Assuming your data is in a DataFrame named 'df'
# Replace 'df' with the actual name of your DataFrame if different
# Plotting
plt.figure(figsize=(10, 6))
plt.bar(df['TimeMonthName'], df['MinutesDelayedWeather'], color='skyblue')
plt.xlabel('Month')
plt.ylabel('Minutes Delayed due to Weather')
plt.title('Relationship between TimeMonthName and MinutesDelayedWeather')
plt.xticks(rotation=45)
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()
Si vous ne voulez pas ouvrir la fenêtre d’outils de l’AI Assistant, vous pouvez utiliser le prompt de la cellule d’IA pour poser vos questions. Par exemple, nous pouvons poser la même question ici et obtenir le code souhaité :
![]()
Obtenir des explications sur les erreurs
Si vous souhaitez que l’AI Assistant vous fournisse des explications sur une erreur, cliquez simplement sur Explain with AI :

Vous pouvez utiliser le résultat obtenu pour mieux comprendre le problème, voire obtenir du code pour le résoudre !
5. Explorer votre code
PyCharm peut vous aider à obtenir une vue d’ensemble de votre notebook Jupyter, à compléter des parties de votre code pour vous simplifier la tâche, à le refactoriser si nécessaire, à le déboguer, et même à ajouter des intégrations pour enrichir vos projets.
Conseils pour naviguer dans votre code et l’optimiser
Nos notebooks Jupyter peuvent rapidement devenir très volumineux, mais heureusement vous pouvez utiliser la vue Structure de PyCharm pour voir tous vos en-têtes en appuyant sur ⌘7 (macOS) / Alt+7 (Windows/Linux).

Saisie semi-automatique de code
Une autre fonctionnalité dont vous pouvez bénéficier lorsque vous travaillez avec des notebooks Jupyter dans PyCharm est la saisie semi-automatique de code. Vous disposez automatiquement de la saisie semi-automatique de base de PyCharm, et PyCharm Professional propose la saisie semi-automatique du code en ligne entière, qui utilise un modèle d’IA local pour fournir des suggestions. Enfin, l’AI Assistant peut aussi vous aider à écrire du code et à découvrir de nouvelles bibliothèques et de nouveaux frameworks.

Refactoriser
Lorsque vous avez besoin de refactoriser votre code, il vous suffit d’un seul raccourci clavier, ⌃T (macOS) / Maj+Ctrl+Alt+T (Windows/Linux), pour choisir la refactorisation à appeler. Vous pouvez choisir une refactorisation populaire, telle que Rename, Change Signature, ou Introduce Variable, ou une option moins connue comme Extract Method, pour modifier votre code sans modifier la sémantique :
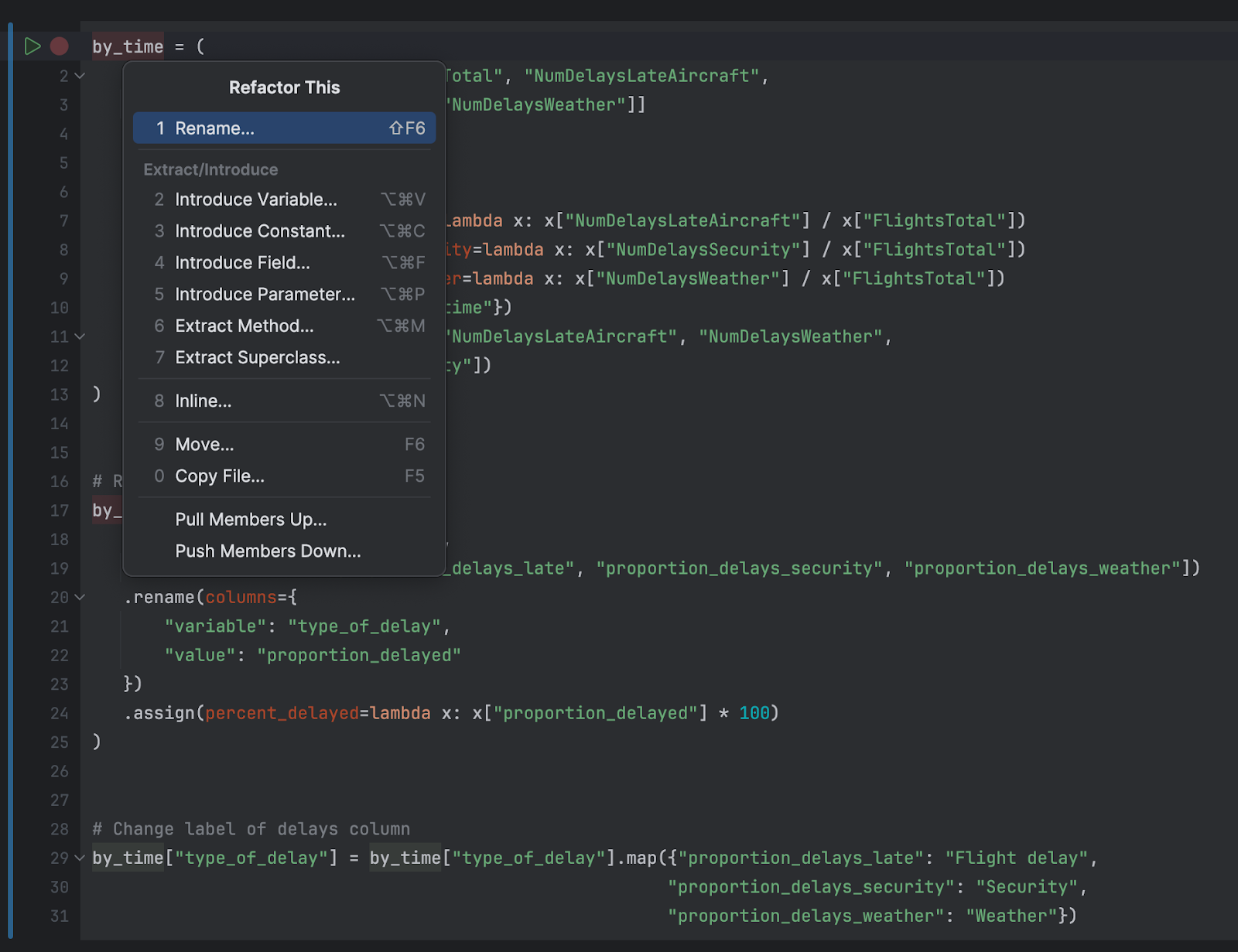
Au fur et à mesure de la croissance de votre notebook Jupyter, il est probable que vos instructions d’importation croissent elles aussi. Il peut arriver d’importer un paquet tel que polars ou numpy, mais d’oublier que numpy est une dépendance transitive de la bibliothèque Polars, et qu’il n’est donc pas nécessaire de l’importer séparément.
Pour identifier ces cas et conserver un code propre, appelez Optimize Imports ⌃⌥O (macOS) / Ctrl+Alt+O (Windows/Linux) afin que PyCharm supprime ce dont nous n’avez pas besoin.
Déboguer votre code
Dans PyCharm, vous pouvez utiliser le débogueur à tout moment pour mieux comprendre certains comportements de votre notebook Jupyter.
Placez un point d’arrêt sur la ligne de votre choix en cliquant sur la gouttière ou en utilisant ⌘F8 (macOS) / Ctrl+F8 (Windows/Linux), puis exécutez votre code avec le débogueur attaché avec l’icône de débogage de la barre d’outils supérieure :

Vous pouvez également appeler le débogueur de PyCharm dans votre notebook Jupyter avec ⌥⇧⏎ (macOS) / Maj+Alt+Entrée (Windows/Linux). Le débogage du code dans un notebook Jupyter est sujet à quelques limitations, mais nous vous invitons à l’essayer et à nous faire part de votre d’expérience.
Ajouter des intégrations dans PyCharm
L’utilisation d’un IDE ne serait pas aussi intéressante si on ne pouvait pas y trouver les intégrations dont on a besoin. PyCharm Professional 2024.2 apporte deux nouvelles intégrations à votre workflow : DataBricks et HuggingFace.
Pour activer l’une ou l’autre de ces intégrations, allez dans Paramètres ⌘ (macOS) / Ctrl+Alt+S (Windows/Linux), sélectionnez Plugins et recherchez le plugin correspondant à l’intégration de votre choix dans l’onglet Marketplace.
6. Obtenir des informations sur les données à partir du code
Lors de l’analyse de vos données, il faut faire une distinction entre les variables catégoriques et les variables continues. Les données catégoriques ont un nombre fini de groupes discrets ou de catégories, tandis que les données continues consistent en une mesure continue. Nous allons voir comment extraire différentes informations des variables catégoriques et des variables dans notre jeu de données sur les compagnies aériennes.
Variables continues
Nous pouvons avoir une idée de la distribution des données continues en examinant les mesures de la valeur moyenne de ces données et la dispersion de ces données autour de la moyenne. Pour les données distribuées normalement, nous pouvons utiliser la moyenne pour mesurer la valeur moyenne et l’écart type pour mesurer la dispersion. Toutefois, lorsque les données ne sont pas distribuées normalement, nous pouvons obtenir des informations plus précises en utilisant la médiane et la plage des quartiles (la différence entre le 75e et le 25e percentile). Nous allons examiner l’une de nos variables continues pour comprendre la différence entre ces mesures.
Dans notre ensemble de données, nous avons beaucoup de variables continues, mais nous allons travailler avec « NumDelaysLateAircraft » pour voir ce que nous pouvons apprendre. Nous allons utiliser le code suivant pour obtenir des statistiques résumant le contenu de cette colonne :
df['NumDelaysLateAircraft'].describe()
En examinant ces données, nous constatons une grande différence entre la « moyenne de l’ensemble de données », qui est d’environ 789, et la « médiane » (notre 5e percentile, soit « 50 % » dans le tableau ci-dessous), d’environ 618.
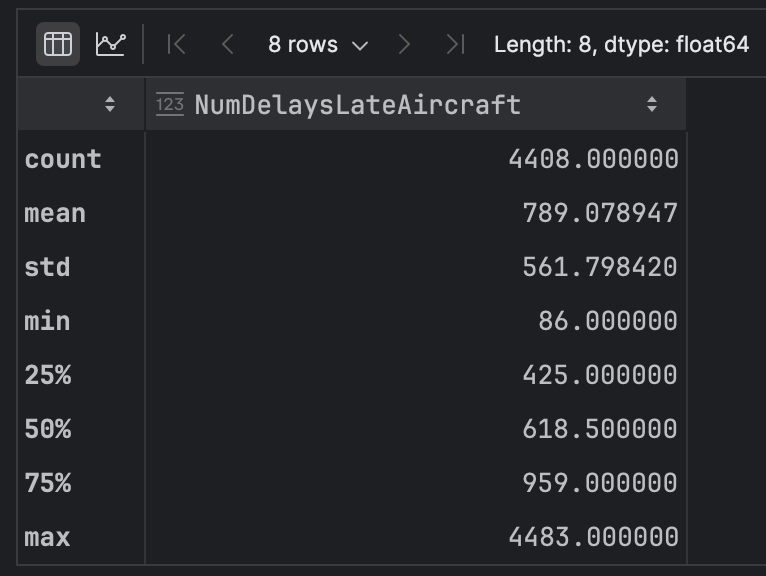
Cela indique une asymétrie dans la distribution de notre variable. Utilisons PyCharm pour l’examiner plus en détail. Cliquez sur l’icône Chart View dans le coin supérieur gauche. Une fois le graphique rendu, nous allons modifier les paramètres de la série représentés par l’e rouage dans le coin supérieur droit de l’écran. Utilisez NumDelaysLateAircraft » pour les axes x et y.
Faites défiler l’axe des y vers le bas à l’aide de la petite flèche et sélectionnez « count ». La dernière étape consiste à définir le type de graphique sur Histogram en utilisant les icônes dans le coin supérieur droit :
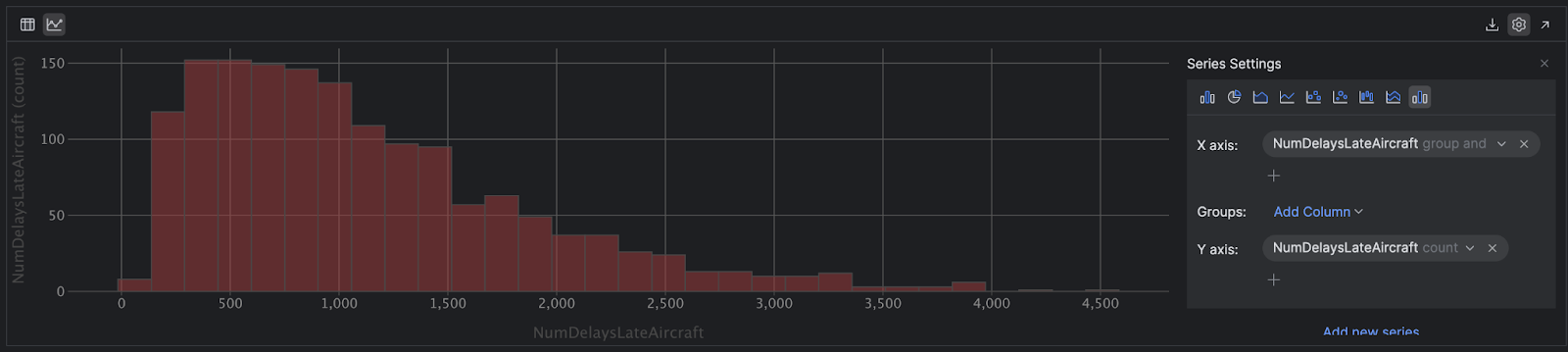
Maintenant que la distorsion est devenue visible, nous pouvons constater que dans la plupart des cas les retards ne sont pas excessifs. Toutefois, nous avons plusieurs retards extrêmes – on voit notamment un point en dehors de la courbe à droite indiquant qu’un avion a été retardé de 4 509 minutes, soit un peu plus de trois jours !
En statistiques, la moyenne est très sensible aux valeurs aberrantes, car il s’agit d’une moyenne géométrique, contrairement à la médiane qui, si vous avez ordonné toutes les observations dans votre variable, se situe exactement au milieu de ces valeurs. Une moyenne supérieure à la médiane est révélatrice de la présence de données aberrantes dans la partie droite des données, la partie supérieure, comme c’est le cas ici. Dans de tels cas, la médiane est un meilleur indicateur du moyen réel, comme on peut le voir dans l’histogramme.
Variables catégoriques
Nous allons voir comment utiliser du code pour extraire des informations exploitables de nos variables catégoriques. Pour obtenir quelque chose d’un peu plus intéressant que « AirportCode », nous allons analyser combien d’avions ont été retardés à cause des conditions météo, « NumDelaysWeather », au cours des différents mois de l’année, « TimeMonthName ».
Utilisez ce code pour grouper « NumDelaysWeather » avec « TimeMonthName » :
result = df[['TimeMonthName', 'NumDelaysWeather']].groupby('TimeMonthName').sum()
result
Cela nous donne de nouveau le DataFrame sous forme de tableau, mais cliquons sur l’icône Chart View situé dans la partie gauche de l’interface utilisateur de PyCharm pour voir ce que nous pouvons apprendre :
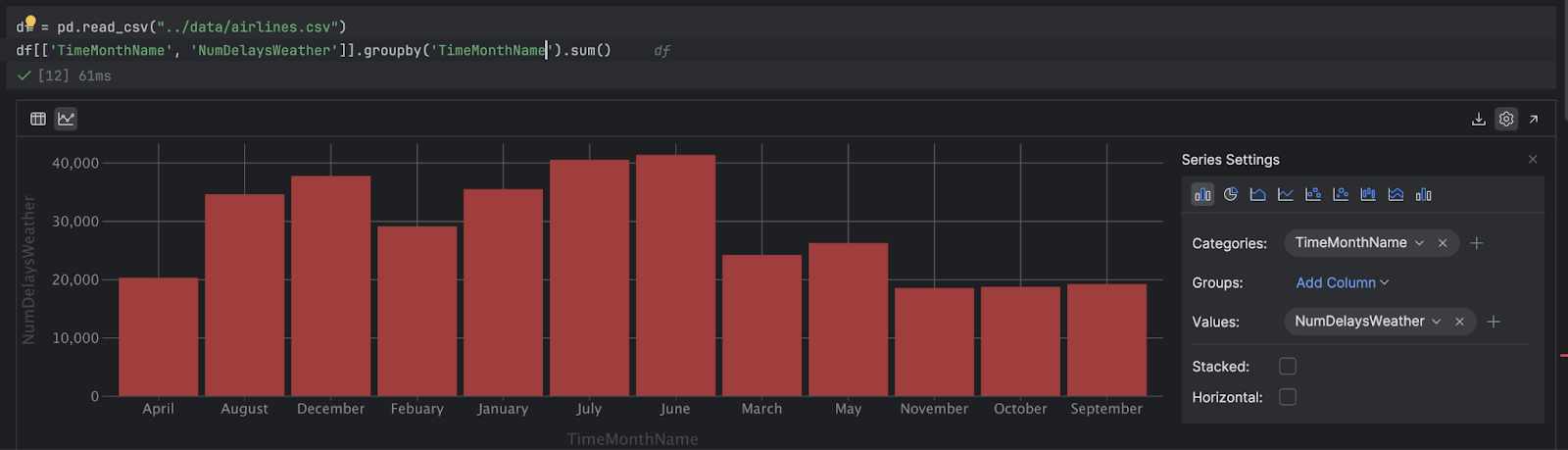
Il serait utile de trier les mois en fonction du calendrier grégorien. Nous allons commencer par créer une valeur pour les mois attendus :
month_order = [ "January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December" ]
Maintenant, nous pouvons demander à PyCharm d’utiliser l’ordre que nous venons de définir dans « month_order » :
# Convert the 'TimeMonthName' column to a categorical type with the specified order
df["TimeMonthName"] = pd.Categorical(df["TimeMonthName"], categories=month_order, ordered=True)
# Now you can group by 'TimeMonthName' and perform sum operation, specifying observed=False
result = df[['TimeMonthName', 'NumDelaysWeather']].groupby('TimeMonthName', observed=False).sum()
result
Puis, nous cliquons de nouveau sur l’icône sur Chart View. Et là, on peut voir que quelque chose ne va pas !
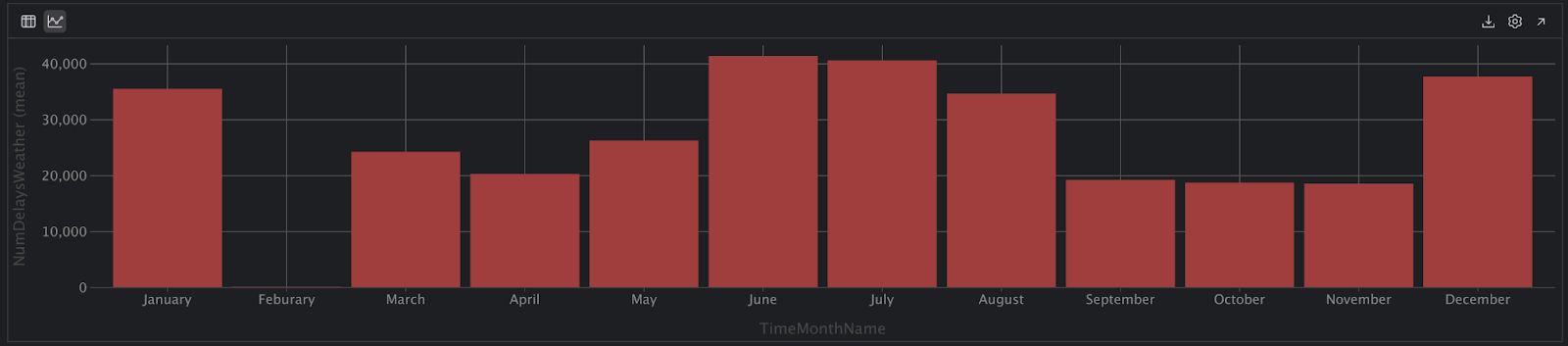
Aucun vol n’aurait eu de retard en février, vraiment ? Ce n’est pas possible. Vérifions notre hypothèse avec du code supplémentaire :
df['TimeMonthName'].value_counts()
Aha ! Nous voyons que « February » était écrit « Febuary » dans notre jeu de données, ce qui a créé une incohérence avec notre nom de variable. Nous allons corriger l’orthographe dans notre jeu de données avec ce code :
df["TimeMonthName"] = df["TimeMonthName"].replace("Febuary", "February")
df['TimeMonthName'].value_counts()
Super, tout semble ok maintenant. Nous devrions maintenant pouvoir exécuter à nouveau le code et obtenir un graphique que nous pourrons interpréter :
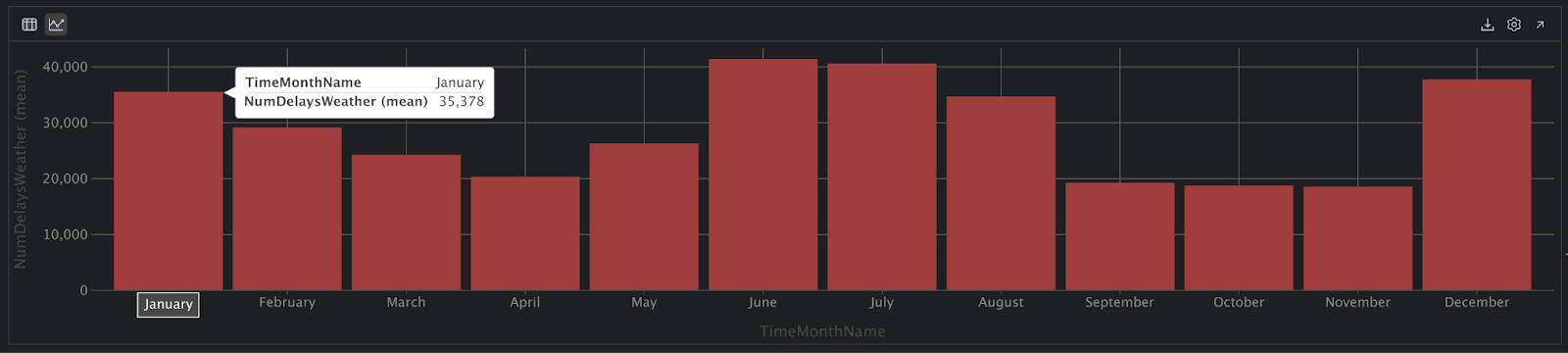
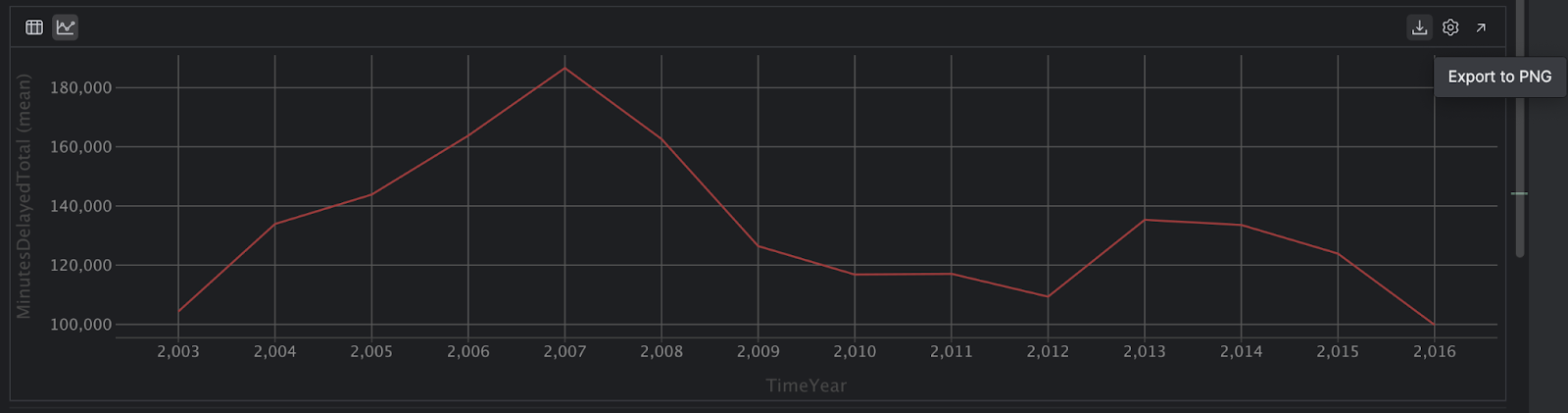
Dans cette vue, nous constatons un nombre supérieur de retards pendant les mois de décembre, janvier et février, puis de nouveau en juin, juillet et août. Toutefois, nous n’avons pas standardisé ces données par rapport au nombre total de vols, il est donc possible qu’il y ait plus de vols pendant ces mois, ce qui pourrait expliquer le nombre plus élevé de retards en été et en hiver.
7. Partager vos analyses et vos graphiques
Une fois votre chef-d’œuvre terminé, vous souhaiterez certainement exporter vos données, ce que vous pouvez faire de différentes façons avec les notebooks Jupyter dans PyCharm.
Exporter un DataFrame
Vous pouvez exporter un DataFrame en cliquant sur la flèche vers le bas dans la partie droite :
De nombreux formats vous sont proposés, parmi lesquels SQL, CSV et JSON :
Exporter des graphiques
Si vous préférez exporter le graphique interactif, cliquez sur l’icône Export to PNG dans la partie droite :
Visualiser votre notebook dans un navigateur
Vous pouvez visualiser l’intégralité de votre notebook Jupyter à tout moment dans un navigateur en cliquant sur l’icône dans le coin supérieur droit de votre notebook :

Enfin, si vous souhaitez exporter votre notebook Jupyter vers un fichier Python, la version 2024.2 de PyCharm vous permet de le faire aussi ! Faites un clic droit sur votre notebook Jupyter dans la fenêtre d’outils Project et sélectionnez Convert to Python File, puis suivez simplement les instructions, et c’est tout !
En résumé
L’utilisation des notebooks Jupyter dans PyCharm Professional donne accès à de nombreuses fonctionnalités qui permettent de créer du code plus rapidement, d’explorer les données facilement et d’exporter vos projets aux formats de votre choix.
Téléchargez PyCharm Professional pour l’essayer et vous faire votre propre idée ! Profitez de l’essai prolongé dès maintenant et découvrez les avantages qu’offre PyCharm Professional pour les travaux de science des données.
Pour activer votre abonnement gratuit de 60 jours à PyCharm Professional, utilisez le code promotionnel « PyCharmNotebooks » à l’étape du paiement. L’abonnement gratuit est réservé aux utilisateurs individuels.
Auteur de l’article original en anglais :





