JetBrains AI
Supercharge your tools with AI-powered features inside many JetBrains products
Aller plus loin avec la complétion de code : l’état de la saisie semi-automatique par IA dans les IDE de JetBrains

La saisie semi-automatique du code a toujours compté parmi les fonctionnalités clés des IDE de JetBrains, car elle aide les développeurs à coder plus rapidement et efficacement, et permet de réduire le nombre d’erreurs. Et s’il était possible d’aller encore plus loin ? Si on pouvait non seulement prédire l’élément suivant, mais aussi des lignes entières de code, voire des blocs entiers ? C’est précisément ce sur quoi nous avons travaillé.
Aujourd’hui, nous sommes en mesure d’offrir une fonctionnalité de saisie semi-automatique de code puissante, plus précise, rapide et intelligente qu’auparavant.
Dans cet article, nous vous emmenons dans les coulisses de la saisie semi-automatique de code générée par IA des IDE de JetBrains, afin de vous montrer comment elle a évolué et d’évoquer ses améliorations à venir. C’est parti !
En quoi consiste la saisie semi-automatique de code générée par IA de JetBrains ?
JetBrains fournit la semi-automatique de code générée par IA de deux façons :
- La saisie semi-automatique de ligne entière de code locale intégrée aux IDE JetBrains : cette fonctionnalité s’exécute directement sur votre machine et fait des suggestions en temps réel sans requérir de connexion Internet, ce qui garantit des réponses rapides et adaptées au contexte de votre projet.
- La saisie semi-automatique basée sur le cloud et générée par l’AI Assistant de JetBrains : cette fonctionnalité utilise les ressources cloud pour fournir des suggestions plus précises en utilisant une puissance de calcul supérieure à celle des ressources locales.
Ainsi, vous bénéficiez de suggestions locales rapides et contextuelles, et d’une assistance plus puissante basée sur le cloud lorsque vous en avez besoin.
Notre approche privilégie la qualité et la rapidité des suggestions. Nous savons que les développeurs doivent pouvoir compter sur une saisie semi-automatique rapide et précise pour maintenir leur flow. C’est pourquoi nous avons conçu notre système en veillant à réduire autant que possibles les sources de distraction. Contrairement aux outils qui vous submergent de lignes de complétion, notre saisie semi-automatique par IA est calibrée pour vous proposer des suggestions concises et pertinentes au moment où vous en avez besoin.
Bilan après 1 an : où en est la saisie semi-automatique de ligne entière de code ?
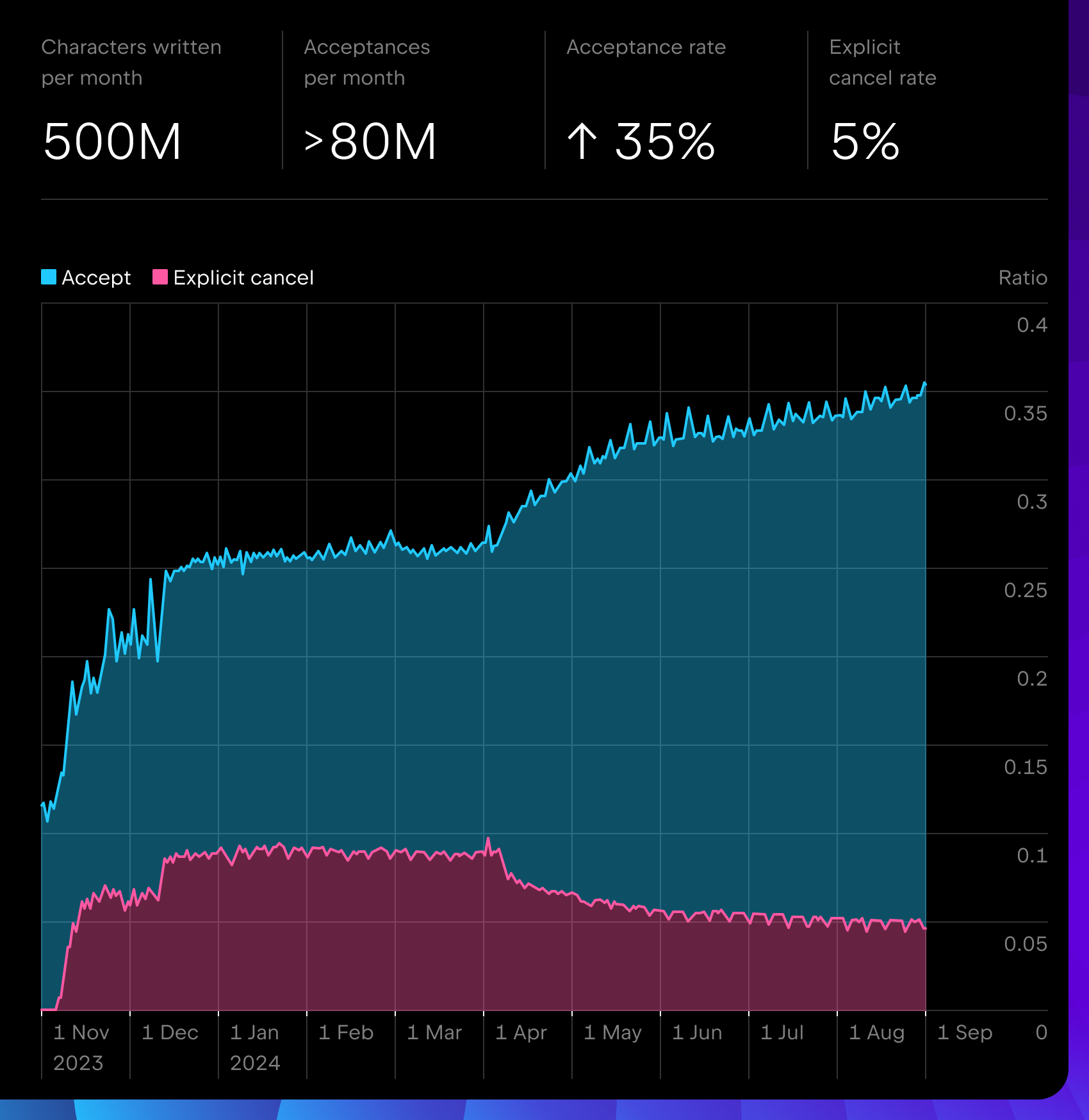
Suite à la publication des versions clés 2023.3 et 2024.1, nos métriques ont révélé une croissance de son utilisation, avec plusieurs millions de suggestions de complétions par jour, un taux d’acceptation de 35 % minimum et un taux d’annulation explicite de seulement 5 %, ce qui en fait l’un des outils de saisie semi-automatique les plus performants pour les IDE basés sur IntelliJ. Il est directement disponible pour plus de 11 langages majeurs et pour plusieurs frameworks avec des modèles locaux légers.
La version 2024.2 portait principalement sur l’expérience utilisateur avec la saisie semi-automatique de code en ligne entière. Toutefois, nous avons également amélioré la qualité et le filtrage du code rouge. De plus, nous avons implémenté sa prise en charge par Rider, CLion, RustRover et Terraform.
Qu’en est-il de la saisie semi-automatique assistée par IA basée sur le cloud ?
Il y a beaucoup de choses à dire sur ce sujet, mais nous allons nous limiter ici aux principaux retours que nous avons reçus de nos utilisateurs, avant d’expliquer comment nous avons résolu les problèmes identifiés.
- Fréquence des suggestions limitée
Dans la précédente mise à jour majeure, nous avions adopté une approche classique de la saisie semi-automatique de code, qui se déclenchait uniquement lorsque l’utilisateur appuyait sur Entrée. Ce fonctionnement était dû à un LLM dont le temps de traitement était significatif. Nous avons réalisé que cette approche était insuffisante, car les utilisateurs n’appuient pas souvent sur Entrée pendant le processus d’écriture de code. En fait, un développeur appuie seulement 70 fois par jour en moyenne sur Entrée . - Difficultés à lire les gros blocs gris de suggestions multilignes
Imaginons que vous écriviez une petite fonction simple et que la saisie semi-automatique vous suggère un gros bloc de texte, rendant difficile de voir la ligne après le curseur. Les suggestions longues demandent plus de temps à vérifier et à et intégrer, ce qui interrompt le workflow. - Suggestions imprévisibles
En plus des problèmes mentionnés ci-dessus, il arrivait que le modèle fasse des suggestions qui ne correspondaient pas totalement aux attentes des utilisateurs. Même si la plupart étaient pertinentes, il y a eu par exemple eu des cas de suggestions de créations de variables d’énumération étendues ou de réponses d’ordre conversationnel. Les grands LLM prennent plusieurs secondes pour générer des suggestions, ce qui peut entraîner des retards. La saisie semi-automatique du code doit être rapide et réactive pour une expérience efficace.
Comment avons-nous résolu ces problèmes ?
Nous avons tout naturellement appliqué la bonne vieille approche du « tout reprendre à zéro ». Nous sommes des développeurs après tout ! ?

Nous avons bien décidé de réécrire intégralement la saisie semi-automatique basée sur le cloud en utilisant le pipeline côté IDE de notre fonctionnalité de saisie semi-automatique de code en ligne entière avec les noubeaux LLM de JetBrains spécialement entraînés pour la complétion. Ce fut difficile, mais nous sommes parvenus à corriger tous les problèmes mentionnés ci-dessus ! ?
À partir de la version 2024.2 de l’AI Assistant pour les IDE basés sur IntelliJ, nous avons introduit un pipeline remanié et un nouveau LLM :
- Pour Java, Python, et Kotlin, à partir de la version 2024.2
- Pour Go, à partir de la version 2024.2.1
- Pour PHP, JavaScript/TypeScript, CSS et HTML, à partir de la version 2024.2.2
Nous allons faire passer tous les langages vers un pipeline avancé et un nouveau modèle dans la version 2024.3.
Voici quelques-unes des principales modifications que nous avons implémentées :
Surlignage au lieu du texte en gris
Afin de simplifier la lecture des gros blocs générés par nos modèles, désormais le texte suggéré est surligné. Cette modification a pour objectif de réduire la charge cognitive. Le surlignage tenant compte de la syntaxe permet d’obtenir des suggestions comparables à du code écrit manuellement, ce qui les rend plus faciles à lire et à évaluer rapidement.
LLM de JetBrains plus intelligents et rapides
Si les grands modèles sont souvent plus efficaces pour traiter des tâches généralistes, un modèle de code personnalisé est plus performant pour des tâches spécialisées. Il offre également davantage de contrôle, une latence bien inférieure et ne requiert pas d’ingénierie de requête. Cela s’est vérifié pour nous également. En entraînant un modèle relativement petit et hautement spécialisé, et en améliorant les mécanismes d’inférence, nous avons significativement amélioré la précision et la vitesse de la saisie semi-automatique de code. Nous donnerons plus de détails sur ce modèle dans de prochains articles de blog.
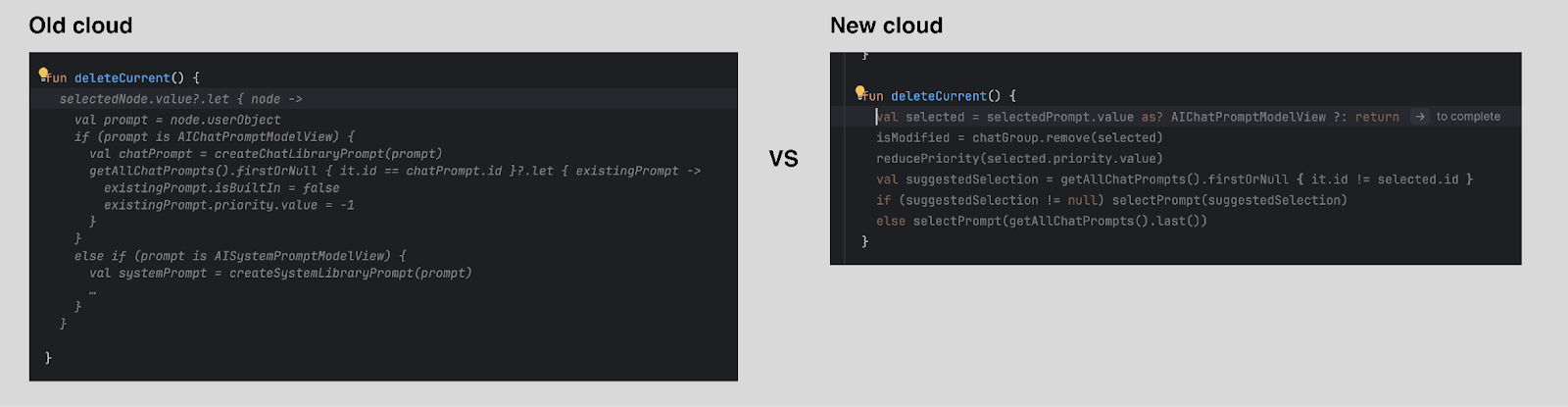
Sélection des emplacements des suggestions et du nombre de lignes suggérées plus rigoureuse
Afin d’augmenter le nombre de suggestions proposées, la complétion est désormais déclenchée pendant que l’utilisateur effectue sa saisie, et non plus seulement en fonction de l’utilisation de la touche Entrée. Nous avons également limité les emplacements où la saisie semi-automatique multiligne peut s’afficher. En adoptant une stratégie plus classique, en fonction du langage, nous avons veillé à ce que la saisie semi-automatique basée sur le cloud reste intuitive et conviviale, tout en générant le même volume total de code. Nous allons affiner cette stratégie et étendre ses capacités lors des prochaines mises à jour.
Amélioration de l’expérience utilisateur pour la saisie semi-automatique multiligne
Nous avons totalement remanié la façon dont les suggestions multilignes sont affichées, notamment en association avec la complétion pour les fenêtres contextuelles dans l’IDE, ce qui n’était pas possible auparavant.
Acceptation partielle
C’est une amélioration que nos utilisateurs attendaient depuis un moment ! Il est désormais possible d’accepter les suggestions de saisie semi-automatique jeton par jeton ou ligne par ligne.
- Accepter mot par mot : ⌥ → / Alt + flèche droite.
- Accepter ligne par ligne : ⌘ → / Ctrl + flèche droite.
- Comme auparavant, vous pouvez appeler explicitement la complétion avec ⇧ ⌥ / / Maj + Alt.

Meilleure prise en compte du projet et collecte des informations contextuelle remaniée
Avec les évaluations hors ligne et en ligne pour évaluer différentes stratégies de génération augmentée pour méthode de récupération (RAG) en place, nous avons choisi celle qui fonctionnait de la façon la plus stable et prévisible. Les suggestions utilisent désormais le contexte de l’ensemble du projet pour proposer des blocs de code pertinents et de haute qualité. Disposer d’un contrôle complet sur l’inférence nous a permis d’éviter de petites incohérences, comme une indentation incorrecte, ainsi que de filtrer les suggestions indésirables.
La nouvelle saisie semi-automatique basée sur le cloud est-elle performante ?
Oui, elle est plutôt efficace !
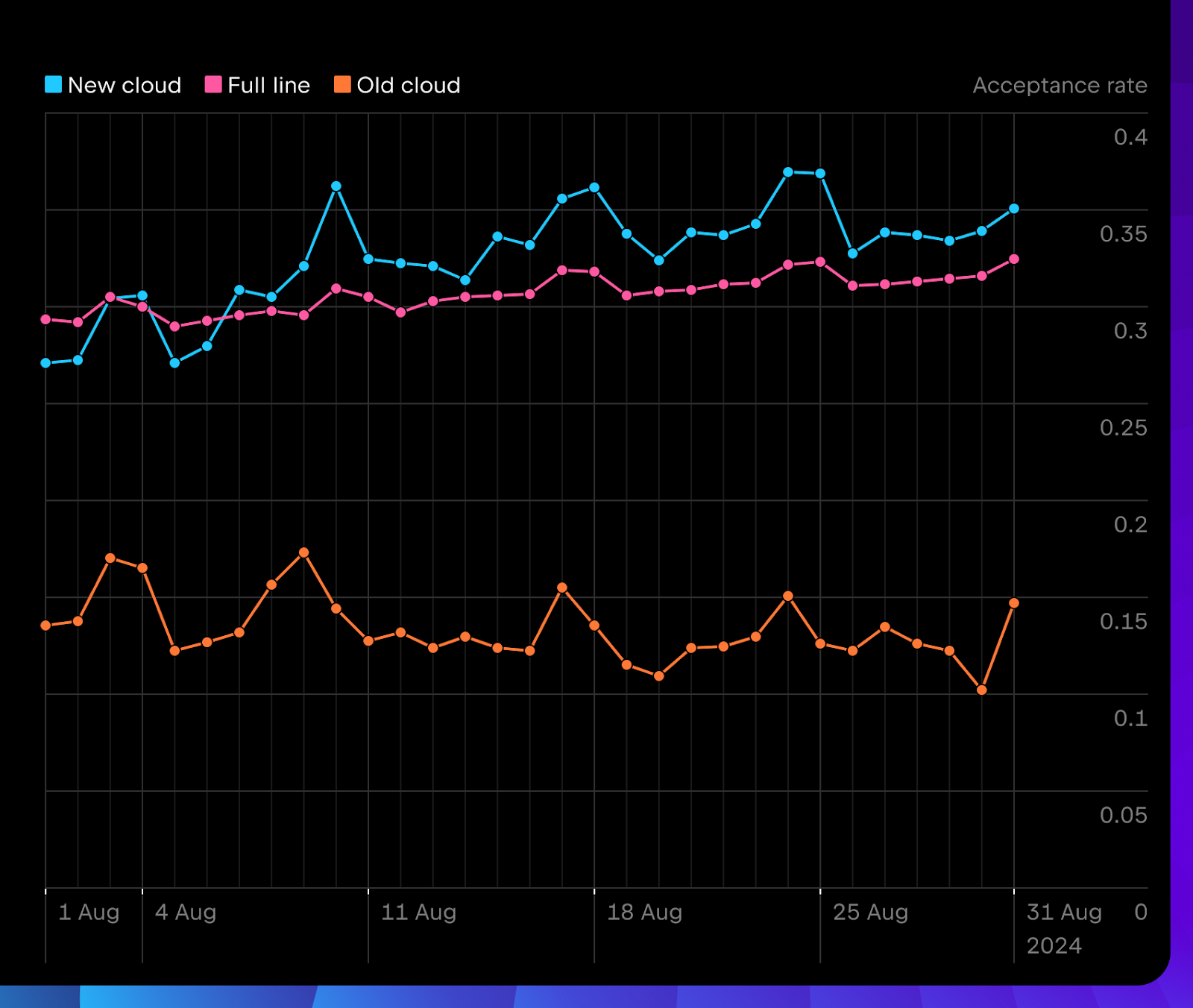
Il n’y a rien de mieux que les fichiers logs en ligne. Sur la base de données collectées en août 2024, nous avons constaté que les retours des utilisateurs et les métriques d’utilisation étaient assez positifs. Examinons trois configurations différentes pour Java, Python et Kotlin :
- L’ancienne version de la saisie semi-automatique assistée par lA et basée sur le cloud et dans la version 2024.1 de l’AI Assistant
- La nouvelle version de la saisie semi-automatique assistée par IA et basée sur le cloud dans la version 2024.2 de l’AI Assistant
- La saisie semi-automatique de ligne entière de code dans la version 2024.2
Cette comparaison donne seulement des résultats approximatifs. De plus, la saisie semi-automatique de ligne entière ne se fait qu’une seule ligne à la fois, alors que l’AI Assistant permet des suggestions à la fois sur une ligne et multilignes.
Le taux d’acceptation pour la nouvelle saisie semi-automatique basée sur le cloud est généralement supérieur à celui de la saisie semi-automatique de code en ligne entière et toujours supérieur à celui de l’ancienne version basée sur le cloud.
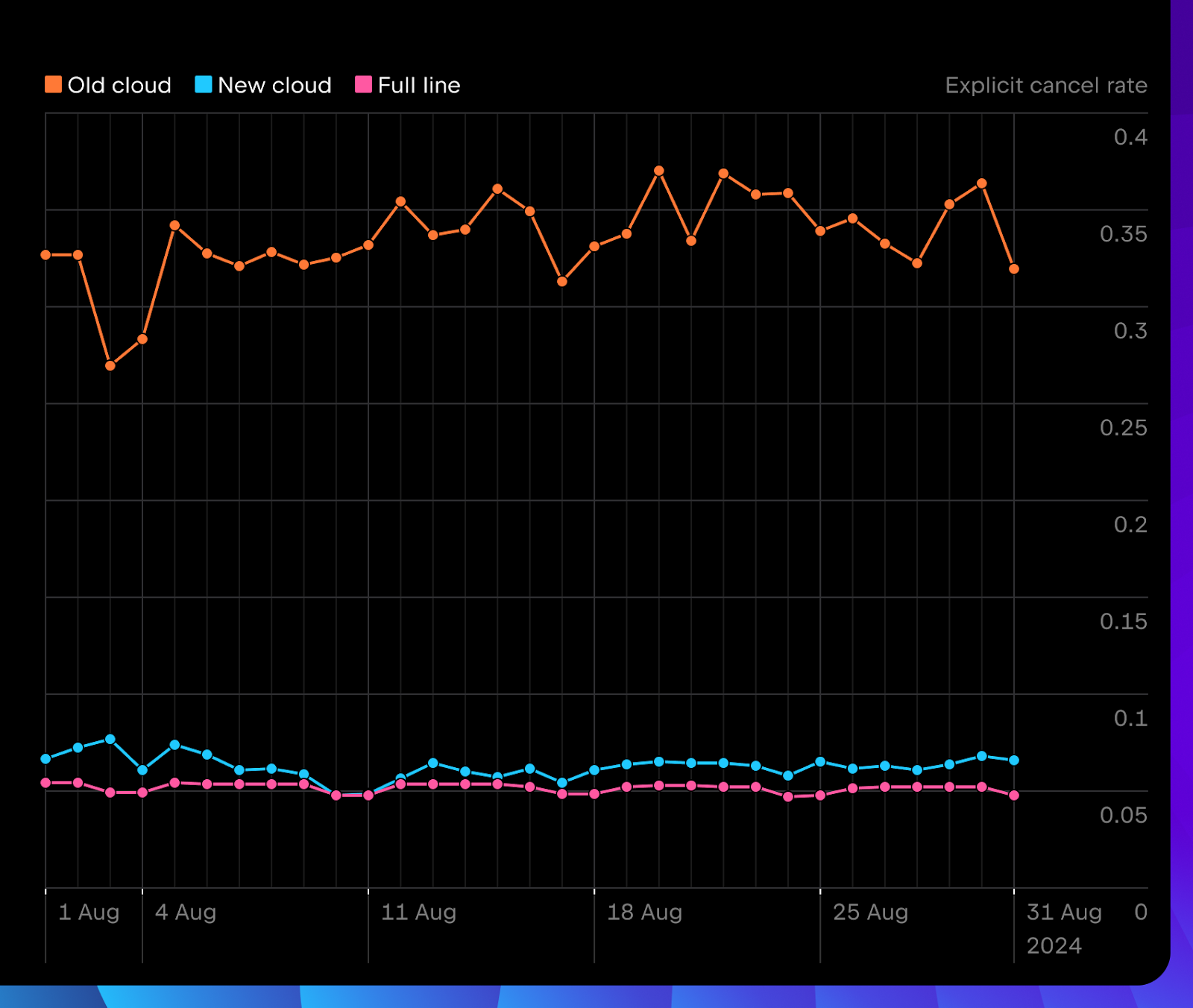
Les utilisateurs annulent explicitement la nouvelle saisie semi-automatique basée sur le cloud beaucoup moins souvent qu’avant.
La latence de complétion globale, soit le temps entre le moment où vous commencez à écrire et le moment où vous recevez la suggestion, est largement inférieure à celle de l’ancien système.
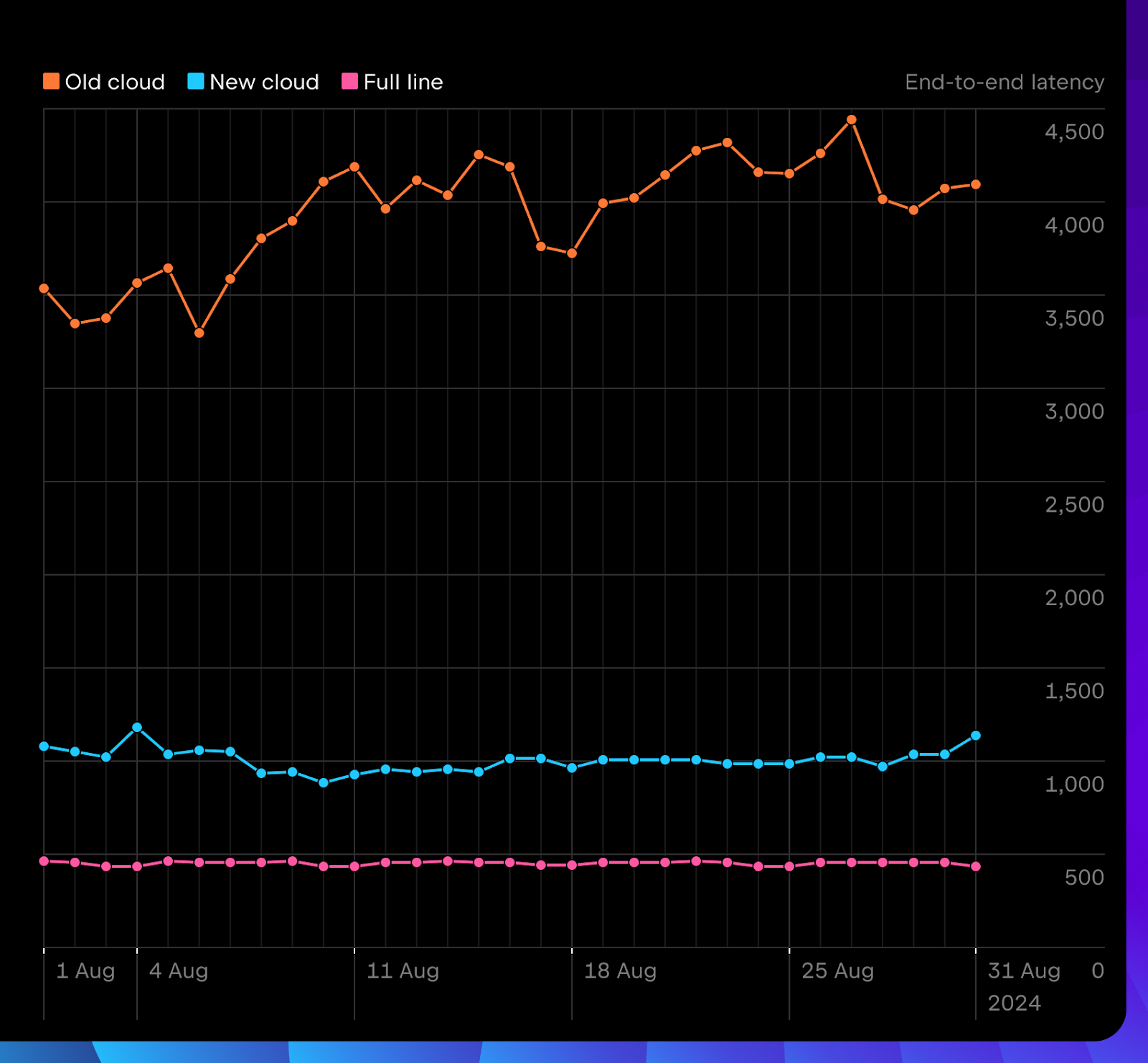
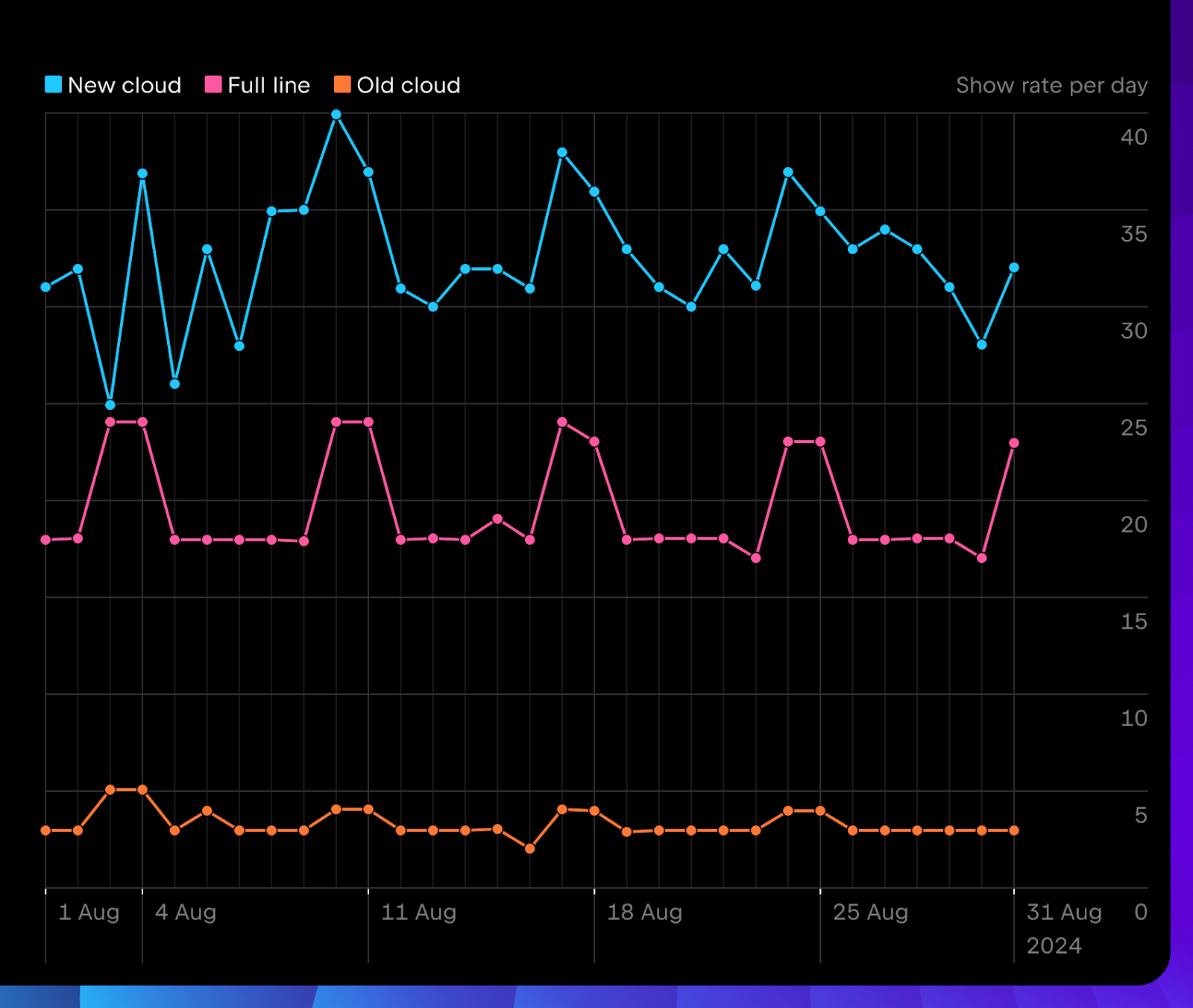
Le nombre quotidien de suggestions de complétion affichées dans la version 2024.2 est déjà nettement supérieur à celui de la version 2024.1. Elle offre de meilleures performances que les modèles locaux en ce qui concerne la pertinence des propositions.
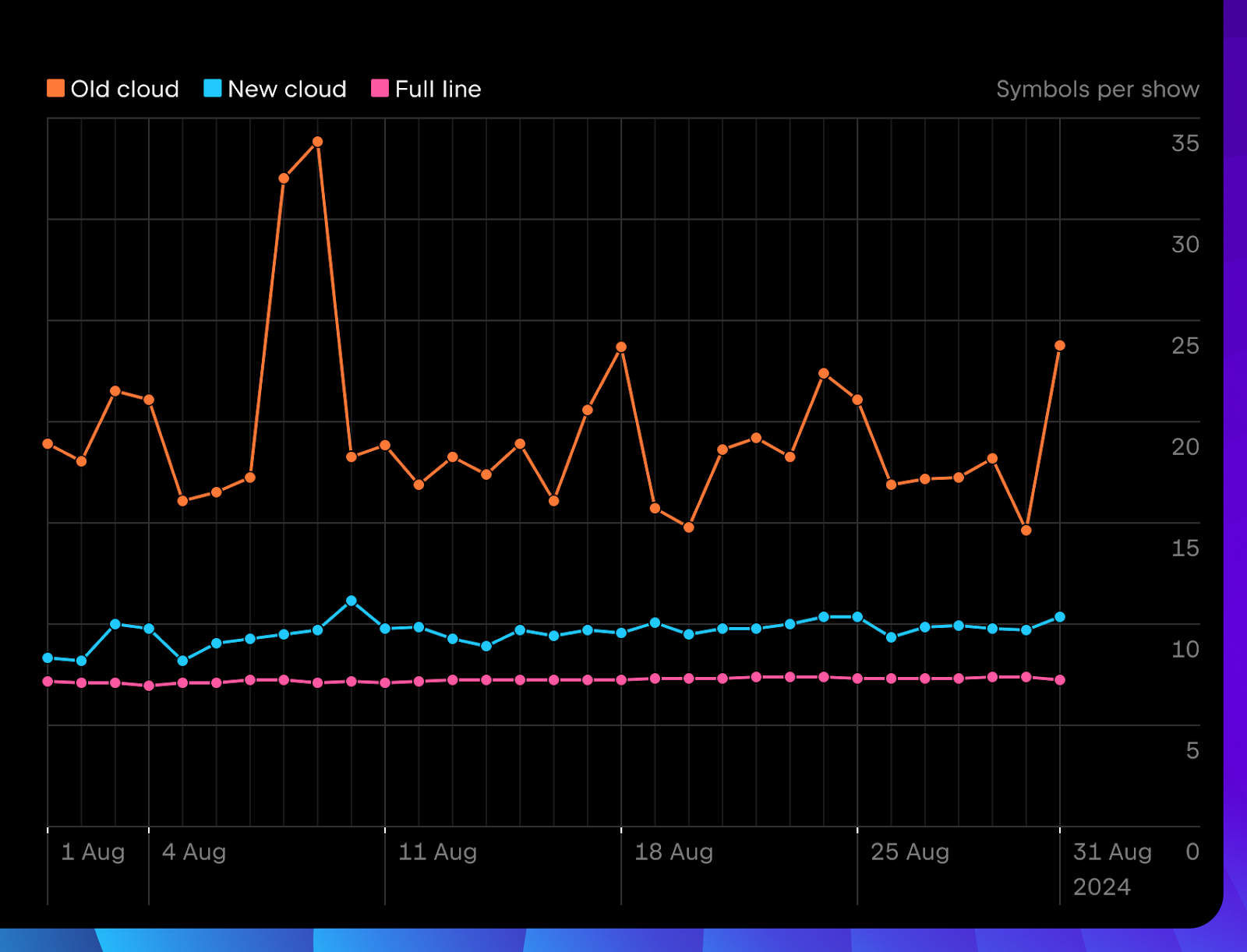
Toutefois, la longueur moyenne de la complétion a été intentionnellement réduite pour la nouvelle version cloud. Nous proposons des complétions multilignes avec beaucoup plus de parcimonie, afin de ne pas perturber l’utilisateur durant la lecture du code ou la réflexion sur la solution. Nous prévoyons d’introduire graduellement de nouveaux emplacements pour afficher les suggestions multilignes, après avoir effectué des tests confirmant qu’elles sont perçues favorablement.
Vous pouvez déjà essayer la nouvelle fonctionnalité de saisie semi-automatique dans les versions 2024.2 d’IntelliJ IDEA, de PyCharm, de WebStorm et de GoLand. Pour la prochaine version, nous nous focaliserons sur le « problème concernant le raccourci Tab » avec la saisie semi-automatique sans IA, sur l’assouplissement du filtrage, sur l’amélioration de la qualité et de la quantité pour les suggestions multilignes, sur les emplacements de déclenchement et sur l’adaptation de la quantité de code dans les suggestions. Nous avons déjà bien avancé et vous pouvez suivre les mises à jour dans les programmes d’accès anticipé des versions 2024.3 !
Quoi de prévu pour la suite ?
Nous allons continuer de travailler sur les saisies semi-automatiques cloud et locales, d’ajouter des suggestions multilignes pour le cloud, d’introduire la saisie semi-automatique multiligne dans la version locale, de prendre en charge davantage de langages, d’améliorer la qualité des modèles et l’expérience utilisateur, et plus.
Je tiens à remercier toutes les personnes qui ont fait part de leurs retours et signalé des problèmes, car leurs contributions ont eu un impact direct sur les améliorations et les fonctionnalités sur lesquelles nous avons travaillé. Merci, et continuez à nous faire part de vos retours ! Vous pouvez donner votre avis dans la section commentaires de cet article, sur la page du plugin AI Assistant ou sur YouTrack.
L’équipe en charge de la complétion chez JetBrains ❤️
Auteur de l’article original en anglais :