

Accélérer Python : lever le verrou GIL de Python

Qu’est-ce que le GIL en Python ?
Le GIL, ou « Global Interpreter Lock », est un terme incontournable dans la communauté Python. C’est une fonctionnalité bien connue de Python. Mais qu’est-ce exactement que le GIL ?
Si vous avez déjà utilisé d’autres langages de programmation, comme Rust par exemple, vous savez probablement ce qu’est un mutex. C’est l’abréviation de « exclusion mutuelle ». Un mutex garantit que les données ne sont accessibles que par un seul thread à la fois. Cela empêche plusieurs threads de modifier les données simultanément. Cela est comparable à un « verrou » qui limite l’accès aux données au seul thread qui en détient la clé.
Le GIL est techniquement un mutex. Il ne laisse qu’un seul thread accéder à l’interpréteur Python à la fois. Je le compare parfois à un volant pour Python. Il ne faut jamais laisser plus d’une personne prendre le volant ! Ceci dit, un groupe d’amis partant en road trip va régulièrement se relayer au volant. C’est un peu comme transférer l’accès à l’interpréteur à un autre thread.
En raison du GIL, Python ne permet pas le véritable multithreading. Cette fonctionnalité est à l’origine de nombreuses discussions au cours de la dernière décennie et de nombreuses tentatives ont été faites pour accélérer Python en supprimant le GIL afin de permettre le multithreading. Récemment, avec Python 3.13, une option permettant d’utiliser Python sans le GIL, parfois appelée no-GIL ou à threads libres, a été mise en place. Cela marque le début d’une nouvelle ère de la programmation en Python.
À quoi servait le GIL à l’origine ?
Si le GIL est si impopulaire, pourquoi l’avoir implémenté ? En fait, le GIL présente plusieurs avantages. Dans d’autres langages de programmation avec un véritable multithreading, la modification des données par plusieurs threads crée des problèmes, car le résultat final dépend du thread ou du processus qui se termine en premier. Cela s’appelle une « condition de course ». Des langages tels que Rust sont souvent difficiles à apprendre, car les programmeurs doivent utiliser des mutex pour éviter les conditions de course.
En Python, chaque objet possède un compteur de références pour suivre combien d’autres objets y font référence. Si le compteur de références tombe à zéro, et dans la mesure où nous savons qu’il n’y a pas de condition de course en Python en raison du GIL, nous savons avec certitude que cet objet n’est plus nécessaire et peut être collecté par le ramasse-miettes.
Lorsque Python est apparu pour la première fois, en 1991, la plupart des ordinateurs n’avaient qu’un seul cœur et la prise en charge du multithreading était peu demandée. La présence d’un GIL résout de nombreux problèmes d’implémentation des programmes et facilite également la maintenance du code. Par conséquent, un GIL a été ajouté par Guido van Rossum (le créateur de Python) en 1992.
Passons à 2025 : les ordinateurs sont équipés de processeurs à plusieurs cœurs et sont par conséquent beaucoup plus puissants. Nous pouvons profiter de cette puissance supplémentaire pour parvenir à une véritable concurrence sans supprimer le GIL.
Plus loin dans cet article, nous allons voir en détail le processus de suppression du GIL. Mais pour l’instant, nous allons regarder comment la concurrence peut véritablement fonctionner avec le GIL en place.
Module multiprocessing de Python
Avant de regarder en détail le processus de suppression du GIL, nous allons voir comment les développeurs Python peuvent parvenir à la concurrence en utilisant le module multiprocessing. Ce module de la bibliothèque standard assure à la fois la concurrence locale et distante, ce qui revient à contourner le GIL en utilisant des sous-processus à la place des threads. De cette façon, le module multiprocessing permet au programmeur d’exploiter pleinement plusieurs processeurs sur une machine donnée.
Cependant, pour réaliser le multitraitement, nous devons concevoir notre programme un peu différemment. Prenons l’exemple suivant d’utilisation du module multiprocessing de Python.
Souvenez-vous de notre exemple de restaurant de burger asynchrone dans la première partie de cette série d’articles de blog :
import asyncio
import time
async def make_burger(order_num):
print(f"Preparing burger #{order_num}...")
await asyncio.sleep(5) # time for making the burger
print(f"Burger made #{order_num}")
async def main():
order_queue = []
for i in range(3):
order_queue.append(make_burger(i))
await asyncio.gather(*(order_queue))
if __name__ == "__main__":
s = time.perf_counter()
asyncio.run(main())
elapsed = time.perf_counter() - s
print(f"Orders completed in {elapsed:0.2f} seconds.")
Nous pouvons utiliser la bibliothèque multiprocessing pour faire la même chose, par exemple :
import multiprocessing
import time
def make_burger(order_num):
print(f"Preparing burger #{order_num}...")
time.sleep(5) # time for making the burger
print(f"Burger made #{order_num}")
if __name__ == "__main__":
print("Number of available CPU:", multiprocessing.cpu_count())
s = time.perf_counter()
all_processes = []
for i in range(3):
process = multiprocessing.Process(target=make_burger, args=(i,))
process.start()
all_processes.append(process)
for process in all_processes:
process.join()
elapsed = time.perf_counter() - s
print(f"Orders completed in {elapsed:0.2f} seconds.")
Comme vous vous en souvenez peut-être, la plupart des méthodes de multiprocessing sont très proches de celles de threading. Pour voir la différence avec multiprocessing, nous allons explorer un scénario plus complexe :
import multiprocessing
import time
import queue
def make_burger(order_num, item_made):
name = multiprocessing.current_process().name
print(f"{name} is preparing burger #{order_num}...")
time.sleep(5) # time for making burger
item_made.put(f"Burger #{order_num}")
print(f"Burger #{order_num} made by {name}")
def make_fries(order_num, item_made):
name = multiprocessing.current_process().name
print(f"{name} is preparing fries #{order_num}...")
time.sleep(2) # time for making fries
item_made.put(f"Fries #{order_num}")
print(f"Fries #{order_num} made by {name}")
def working(task_queue, item_made, order_num, lock):
break_count = 0
name = multiprocessing.current_process().name
while True:
try:
task = task_queue.get_nowait()
except queue.Empty:
print(f"{name} has nothing to do...")
if break_count > 1:
break # stop if idle for too long
else:
break_count += 1
time.sleep(1)
else:
lock.acquire()
try:
current_num = order_num.value
order_num.value = current_num + 1
finally:
lock.release()
task(current_num, item_made)
break_count = 0
if __name__ == "__main__":
print("Welcome to Pyburger! Please place your order.")
burger_num = input("Number of burgers:")
fries_num = input("Number of fries:")
s = time.perf_counter()
task_queue = multiprocessing.Queue()
item_made = multiprocessing.Queue()
order_num = multiprocessing.Value("i", 0)
lock = multiprocessing.Lock()
for i in range(int(burger_num)):
task_queue.put(make_burger)
for i in range(int(fries_num)):
task_queue.put(make_fries)
staff1 = multiprocessing.Process(
target=working,
name="John",
args=(
task_queue,
item_made,
order_num,
lock,
),
)
staff2 = multiprocessing.Process(
target=working,
name="Jane",
args=(
task_queue,
item_made,
order_num,
lock,
),
)
staff1.start()
staff2.start()
staff1.join()
staff2.join()
print("All tasks finished. Closing now.")
print("Items created are:")
while not item_made.empty():
print(item_made.get())
elapsed = time.perf_counter() - s
print(f"Orders completed in {elapsed:0.2f} seconds.")
Voici le résultat obtenu :
Welcome to Pyburger! Please place your order. Number of burgers:3 Number of fries:2 Jane has nothing to do... John is preparing burger #0... Jane is preparing burger #1... Burger #0 made by John John is preparing burger #2... Burger #1 made by Jane Jane is preparing fries #3... Fries #3 made by Jane Jane is preparing fries #4... Burger #2 made by John John has nothing to do... Fries #4 made by Jane Jane has nothing to do... John has nothing to do... Jane has nothing to do... John has nothing to do... Jane has nothing to do... All tasks finished. Closing now. Items created are: Burger #0 Burger #1 Fries #3 Burger #2 Fries #4 Orders completed in 12.21 seconds.
Notez que multiprocessing présente des limitations qui conditionnent le code ci-dessus. Examinons ces points un par un.
D’abord, souvenez-vous que nous utilisions les fonctions make_burger et make_fries pour générer une fonction ayant la bonne valeur order_num :
def make_burger(order_num):
def making_burger():
logger.info(f"Preparing burger #{order_num}...")
time.sleep(5) # time for making burger
logger.info(f"Burger made #{order_num}")
return making_burger
def make_fries(order_num):
def making_fries():
logger.info(f"Preparing fries #{order_num}...")
time.sleep(2) # time for making fries
logger.info(f"Fries made #{order_num}")
return making_fries
Nous ne pouvons pas faire la même chose avec multiprocessing. Sinon, cela crée une erreur comme celle-ci :
AttributeError: Can't get local object 'make_burger..making_burger'
Cela s’explique par le fait que multiprocessing utilise pickle, qui ne peut sérialiser que les fonctions au niveau supérieur du module en général. Il s’agit de l’une des limitations de multiprocessing.
Ensuite, comme vous pouvez le remarquer dans l’extrait de code ci-dessus, qui utilise multiprocessing, nous n’utilisons pas de variables globales pour les données partagées. Par exemple, nous ne pouvons pas utiliser de variables globales pour item_made et order_num. Pour partager les données entre différents processus, des objets de classe spéciaux, tels que Queue et Value, qui proviennent du module multiprocessing, sont utilisés et transférés aux processus en tant qu’arguments.
En général, le partage des données et des états entre différents processus est déconseillé, car cela peut créer de nombreux problèmes. Dans notre exemple ci-dessus, nous devons utiliser un Lock pour nous assurer que la valeur de order_num ne peut être accessible et incrémentée que par un seul processus à la fois. Sans ce Lock, le numéro d’ordre de l’élément risque de ne pas être correct, par exemple :
Items created are: Burger #0 Burger #0 Fries #2 Burger #1 Fries #3
Voici comment utiliser un verrou pour éviter ce problème :
lock.acquire()
try:
current_num = order_num.value
order_num.value = current_num + 1
finally:
lock.release()
task(current_num, item_made)
Pour en savoir plus sur l’utilisation du module multiprocessing de la bibliothèque standard, vous pouvez consulter la documentation ici.
Suppression du GIL
La suppression du GIL est en discussion depuis près d’une décennie. En 2016, au Python Language Summit, Larry Hastings a présenté ses idées sur la manière de pratiquer une « GIL-ectomie » sur l’interpréteur CPython et les progrès qu’il avait réalisés dans ce sens [1]. Ce fut l’une des premières tentatives de suppression du GIL de Python. En 2021, Sam Gross a relancé la discussion sur la suppression du GIL [2] et cela a conduit à la publication du PEP 703 – Making the Global Interpreter Lock Optional in CPython en 2023, qui vise à rendre le GIL facultatif.
Comme nous pouvons le voir, la suppression du GIL n’est pas une décision hâtive et a fait l’objet de nombreux débats au sein de la communauté. Comme démontré par les exemples ci-dessus de multitraitement (et PEP 703, en lien ci-dessus), lorsque la garantie fournie par le GIL est supprimée, les choses se compliquent rapidement.
[1] : https://lwn.net/Articles/689548/
[2] : https://lwn.net/ml/python-dev/CAGr09bSrMNyVNLTvFq-h6t38kTxqTXfgxJYApmbEWnT71L74-g@mail.gmail.com/
Comptage des références
Lorsque le GIL est présent, le comptage des références et la collecte par le ramasse-miettes sont plus simples. Si l’accès aux objets Python est limité à un seul thread, nous pouvons compter sur un comptage des références simple, non atomique, et supprimer l’objet dès que le compteur de références atteint zéro.
La suppression du GIL complique tout. Nous ne pouvons plus utiliser le comptage des références non atomique, car cela ne garantit pas la sécurité des threads. Les choses peuvent mal se passer si plusieurs threads augmentent ou réduisent la valeur du compteur de références sur l’objet Python en même temps. Dans l’idéal, un comptage des références atomique serait préférable pour garantir la sécurité des threads. Toutefois, cette méthode impose une surcharge importante et peut se révéler peu efficace en présence d’un nombre important de threads.
La solution consiste à utiliser un comptage des références biaisé, qui garantit également la sécurité des threads. L’idée consiste à associer chaque objet à un thread propriétaire, à savoir celui qui y accède le plus fréquemment. Les threads propriétaires peuvent exécuter le comptage des références non atomique sur les objets qu’ils possèdent, tandis que les autres threads doivent réaliser un comptage des références atomique sur ces objets. Cette méthode est préférable au comptage des références atomique simple, car la plupart des objets sont uniquement accessibles par un seul thread la plupart du temps. La surcharge d’exécution peut être réduite en autorisant le thread propriétaire à exécuter un comptage des références non atomique.
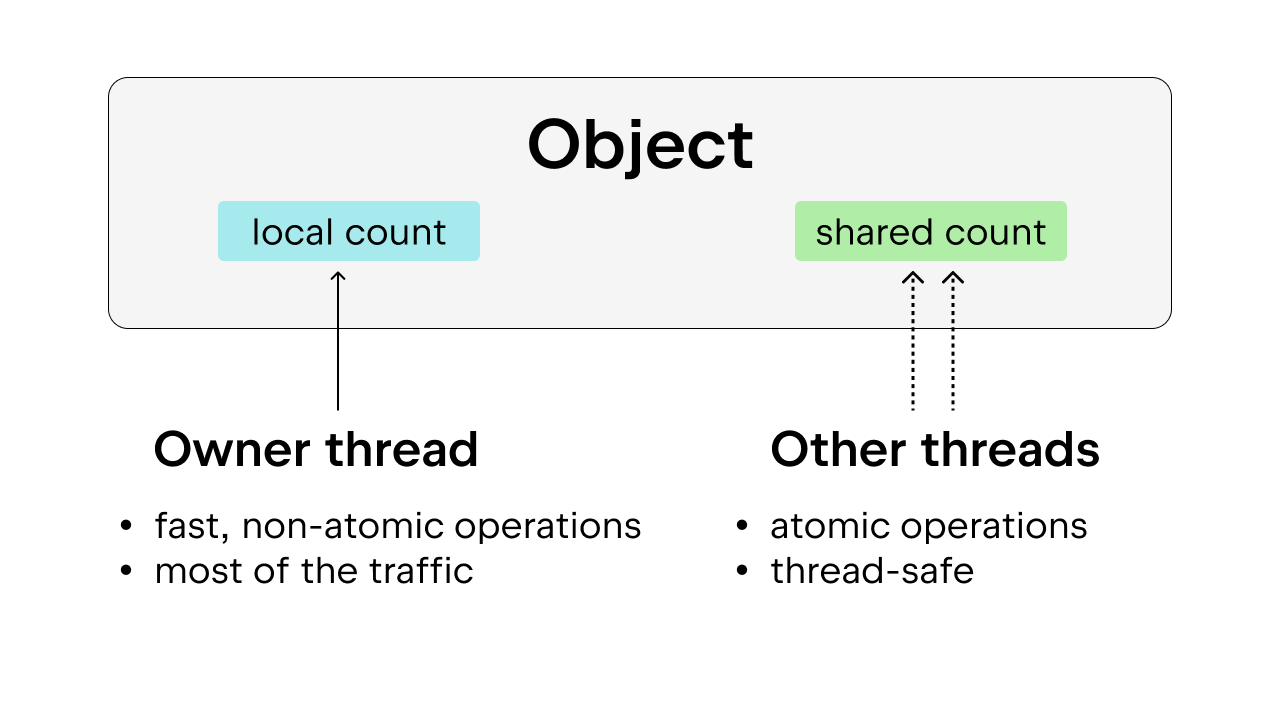
De plus, certains objets Python très utilisés, tels que True, False, les petits entiers et certaines chaînes internées, sont rendus immortels. Dans ce cas, « immortel » signifie seulement que les objets restent dans le programme pendant toute sa durée de vie, ce qui les dispense du comptage des références.
Ramasse-miettes
Nous devons également modifier le fonctionnement du ramasse-miettes. Au lieu de réduire le nombre de références dès qu’une référence est libérée et de retirer l’objet immédiatement lorsque le nombre de références atteint zéro, nous allons utiliser la technique de « comptage des références différé ».
Lorsque le nombre de références doit être réduit, l’objet est stocké dans une table, qui sera revérifiée pour s’assurer que la réduction du nombre de références est correcte. Cela évite de retirer l’objet prématurément, alors qu’il est toujours référencé, ce qui risque de se produire sans le GIL, dans la mesure où le comptage des références n’est pas aussi simple qu’avec le GIL. Cela complique le processus de collecte du ramasse-miettes, car il peut avoir à traverser la pile de chaque thread pour y exécuter un comptage des références.
Un autre point important doit être pris en compte : le nombre de références doit rester stable pendant l’exécution du ramasse-miettes. Si un objet doit être supprimé, mais devient soudain référencé, cela entraîne des problèmes graves. Pour cette raison, le ramasse-miettes devient bloquant (stop the world) pour assurer la sécurité des threads.
Allocation de la mémoire
Lorsque le GIL assure la sécurité du thread, pymalloc, l’allocateur de mémoire interne de Python, est utilisé. Mais sans le GIL, il faut un nouvel allocateur. Sam Gross a proposé mimalloc dans son PEP. Il s’agit d’un allocateur généraliste créé par Daan Leijen et géré par Microsoft. C’est un bon choix, car il n’affecte pas la sécurité des threads et a de bonnes performances sur les petits objets.
Mimalloc remplit sa pile avec des pages et les pages avec des blocs. Chaque page contient des blocs, et les blocs de chaque page sont de la même taille. En ajoutant quelques restrictions d’accès à list et dict, le ramasse-miettes n’a pas à gérer une liste chaînée pour trouver tous les objets et cela permet également d’accéder en lecture aux list et dict sans acquérir le verrou.
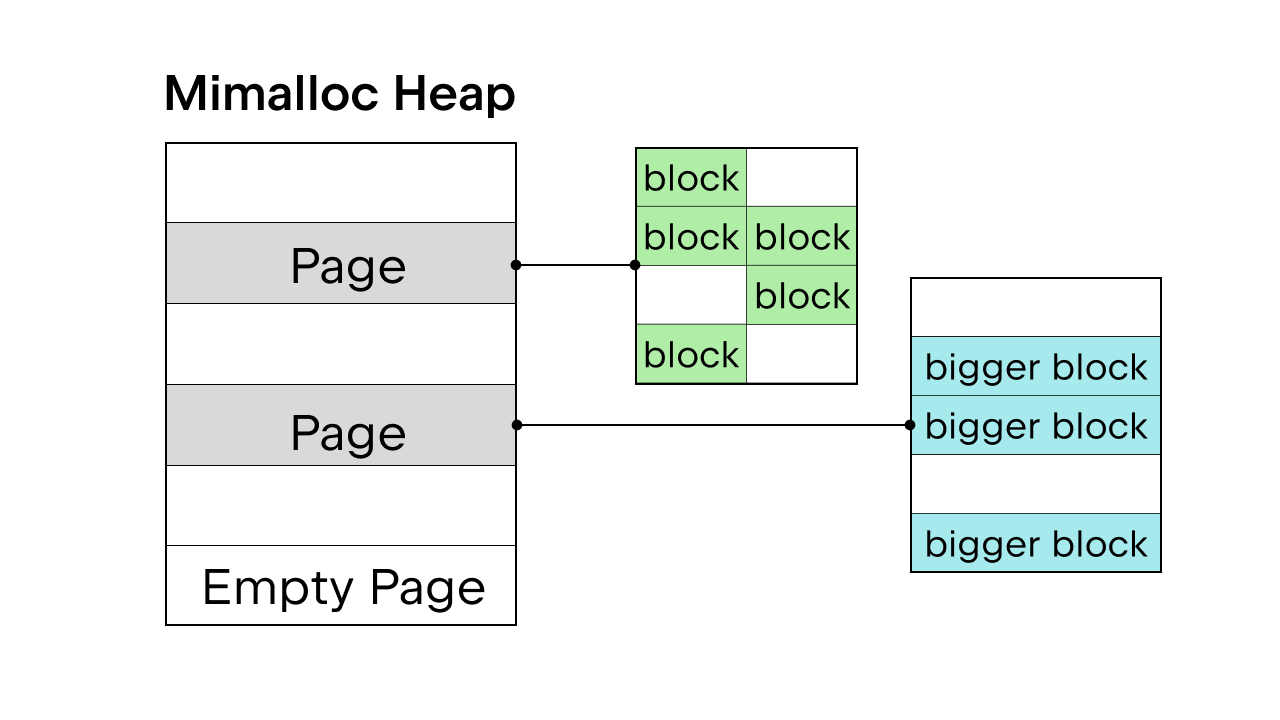
Il faut prendre en compte d’autres détails concernant la suppression du GIL, mais il est impossible de les couvrir tous dans cet article. Vous pouvez consulter la page PEP 703 – Making the Global Interpreter Lock Optional in CPython pour une présentation complète.
Différences de performances avec et sans le GIL
Dans la mesure où Python 3.13 comporte une option à threads libres, il est possible de comparer les performances de la version standard de Python 3.13 à celle à threads libres.
Installation de Python à threads libres
Nous allons utiliser pyenv pour installer les deux versions : la standard (3.13.5) et la version véritablement multithread (3.13.5t).
Par ailleurs, vous pouvez également utiliser les installateurs sur Python.org. Sélectionnez l’option Customize pendant l’installation et cochez la case de la version multithread de Python (voir l’exemple dans cet article de blog).
Une fois les deux versions installées, nous pouvons les ajouter en tant qu’interpréteurs dans un projet PyCharm.
Pour commencer, cliquez sur le nom de votre interpréteur Python dans le coin inférieur droit.
Sélectionnez Add New Interpreter dans le menu, puis Add Local Interpreter.
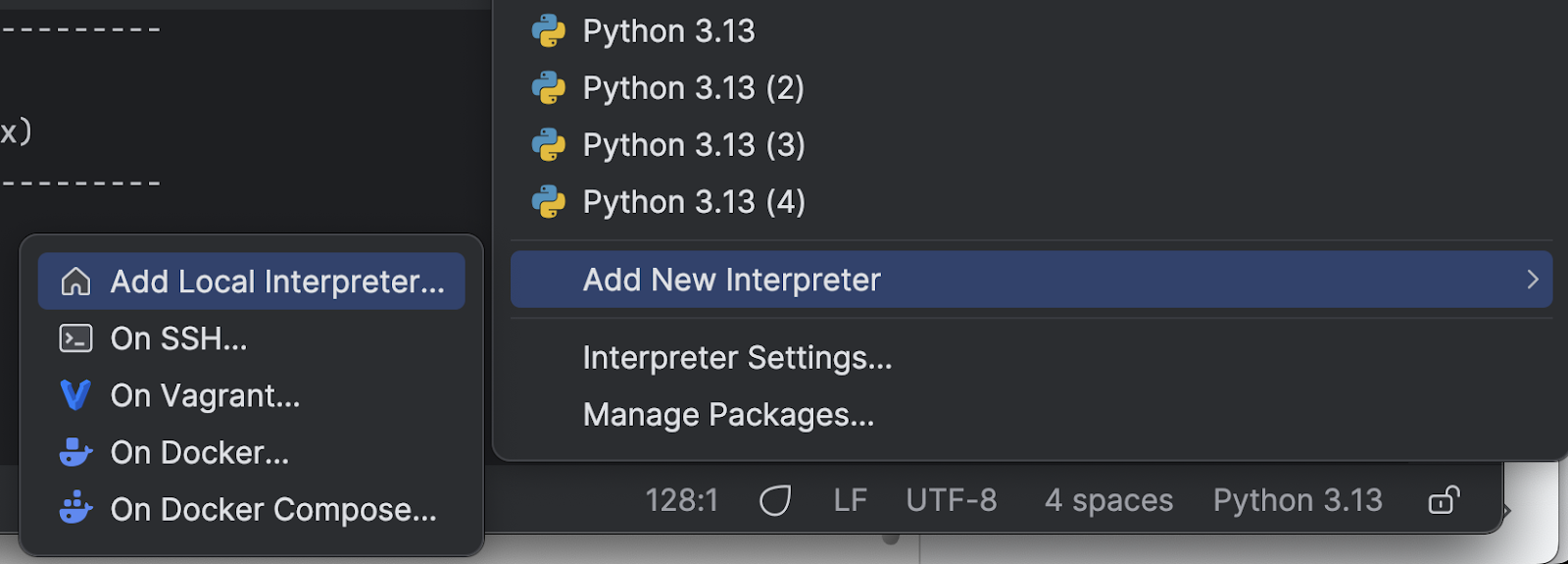
Choisissez Select existing, attendez le chargement du chemin de l’interpréteur (ce qui peut prendre du temps si, comme moi, vous avez beaucoup d’interpréteurs), puis sélectionnez le nouvel interpréteur que vous venez d’installer dans le menu déroulant Python path.
Cliquez sur OK pour l’ajouter. Répétez ces étapes pour l’autre interpréteur. Désormais, lorsque vous cliquez à nouveau sur le nom de l’interpréteur dans le coin inférieur droit, vous verrez plusieurs interpréteurs Python 3.13, comme dans l’illustration ci-dessus.
Test de processus lié au processeur
Il faut maintenant créer un script pour tester les différentes versions. Souvenez-vous, nous avons expliqué dans la première partie de cette série d’articles de blog que pour accélérer les processus liés au processeur, nous devions recourir au multithreading sans restrictions. Pour voir si la suppression du GIL permettra un véritable multithreading et accélérera Python, nous pouvons tester un processus lié au processeur sur plusieurs threads. Voici le script que j’ai demandé à Junie de générer (avec quelques retouches personnelles) :
import time
import multiprocessing # Kept for CPU count
from concurrent.futures import ThreadPoolExecutor
import sys
def is_prime(n):
"""Check if a number is prime (CPU-intensive operation)."""
if n <= 1:
return False
if n <= 3:
return True
if n % 2 == 0 or n % 3 == 0:
return False
i = 5
while i * i <= n:
if n % i == 0 or n % (i + 2) == 0:
return False
i += 6
return True
def count_primes(start, end):
"""Count prime numbers in a range."""
count = 0
for num in range(start, end):
if is_prime(num):
count += 1
return count
def run_single_thread(range_size, num_chunks):
"""Run the prime counting task in a single thread."""
chunk_size = range_size // num_chunks
total_count = 0
start_time = time.time()
for i in range(num_chunks):
start = i * chunk_size + 1
end = (i + 1) * chunk_size + 1 if i < num_chunks - 1 else range_size + 1
total_count += count_primes(start, end)
end_time = time.time()
return total_count, end_time - start_time
def thread_task(start, end):
"""Task function for threads."""
return count_primes(start, end)
def run_multi_thread(range_size, num_threads, num_chunks):
"""Run the prime counting task using multiple threads."""
chunk_size = range_size // num_chunks
total_count = 0
start_time = time.time()
with ThreadPoolExecutor(max_workers=num_threads) as executor:
futures = []
for i in range(num_chunks):
start = i * chunk_size + 1
end = (i + 1) * chunk_size + 1 if i < num_chunks - 1 else range_size + 1
futures.append(executor.submit(thread_task, start, end))
for future in futures:
total_count += future.result()
end_time = time.time()
return total_count, end_time - start_time
def main():
# Fixed parameters
range_size = 1000000 # Range of numbers to check for primes
num_chunks = 16 # Number of chunks to divide the work into
num_threads = 4 # Fixed number of threads for multi-threading test
print(f"Python version: {sys.version}")
print(f"CPU count: {multiprocessing.cpu_count()}")
print(f"Range size: {range_size}")
print(f"Number of chunks: {num_chunks}")
print("-" * 60)
# Run single-threaded version as baseline
print("Running single-threaded version (baseline)...")
count, single_time = run_single_thread(range_size, num_chunks)
print(f"Found {count} primes in {single_time:.4f} seconds")
print("-" * 60)
# Run multi-threaded version with fixed number of threads
print(f"Running multi-threaded version with {num_threads} threads...")
count, thread_time = run_multi_thread(range_size, num_threads, num_chunks)
speedup = single_time / thread_time
print(f"Found {count} primes in {thread_time:.4f} seconds (speedup: {speedup:.2f}x)")
print("-" * 60)
# Summary
print("SUMMARY:")
print(f"{'Threads':<10} {'Time (s)':<12} {'Speedup':<10}")
print(f"{'1 (baseline)':<10} {single_time:<12.4f} {'1.00x':<10}")
print(f"{num_threads:<10} {thread_time:<12.4f} {speedup:.2f}x")
if __name__ == "__main__":
main()
Pour simplifier l’exécution du script avec différents interpréteurs Python, nous pouvons ajouter un script d’exécution personnalisé à notre projet PyCharm.
En haut, sélectionnez Edit Configurations… dans le menu déroulant près du bouton Run (![]() ).
).
Cliquez sur le bouton + dans le coin supérieur gauche, puis choisissez Python dans le menu déroulant Add New Configuration.
Choisissez un nom significatif permettant de savoir quel interpréteur est utilisé, par exemple 3.13.5 et 3.15.3t. Sélectionnez le bon interpréteur et ajoutez ajoutez le nom du script de test de la façon suivante :
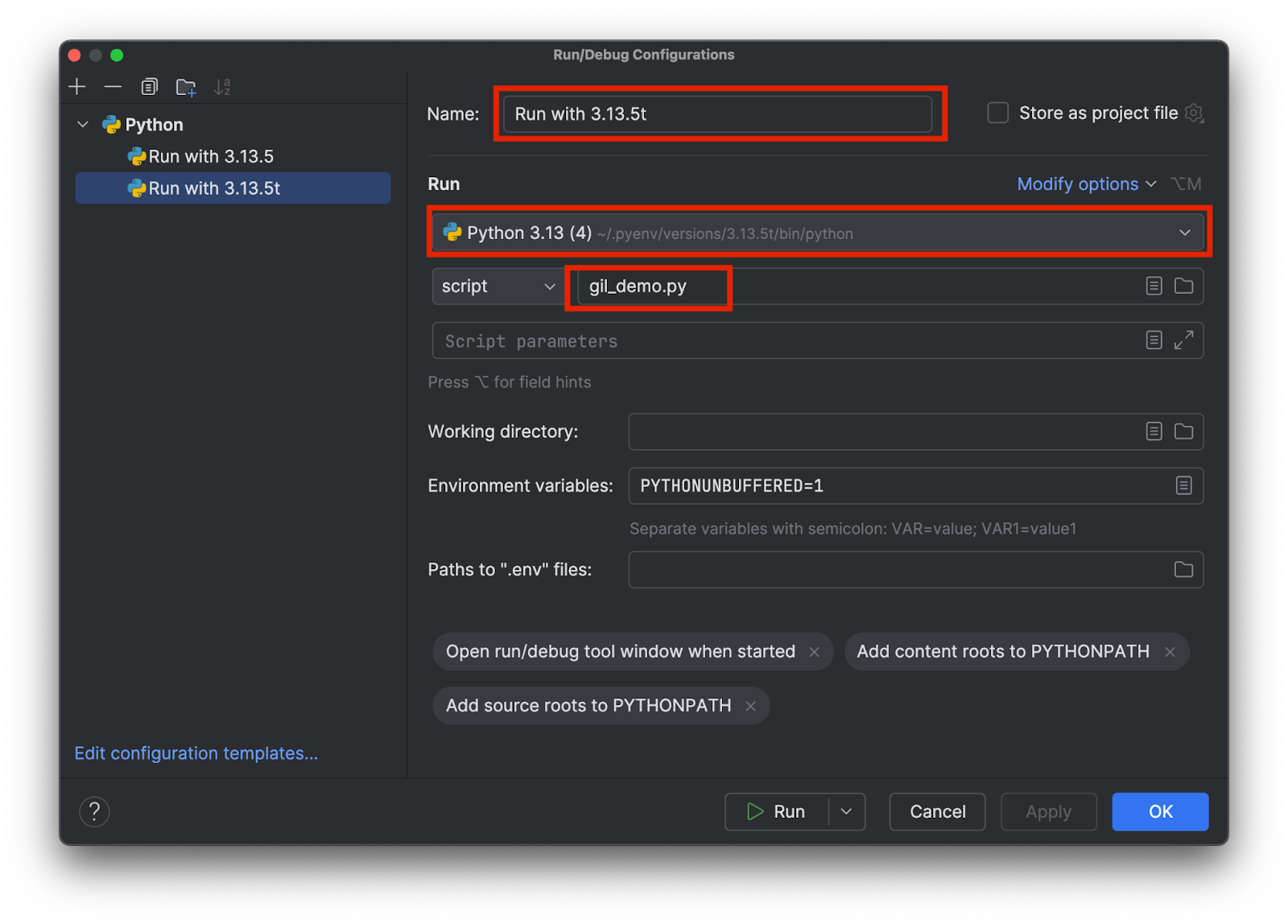
Ajoutez deux configurations, une pour chaque interpréteur. Cliquez ensuite sur OK.
Maintenant, nous pouvons facilement sélectionner et exécuter le script de test avec ou sans le GIL en sélectionnant la configuration et en cliquant sur le bouton Run (![]() ) en haut.
) en haut.
Comparaison des résultats
Voici le résultat que j’ai obtenu avec la version standard 3.13.5, incluant le GIL :
Python version: 3.13.5 (main, Jul 10 2025, 20:33:15) [Clang 17.0.0 (clang-1700.0.13.5)] CPU count: 8 Range size: 1000000 Number of chunks: 16 ------------------------------------------------------------ Running single-threaded version (baseline)... Found 78498 primes in 1.1930 seconds ------------------------------------------------------------ Running multi-threaded version with 4 threads... Found 78498 primes in 1.2183 seconds (speedup: 0.98x) ------------------------------------------------------------ SUMMARY: Threads Time (s) Speedup 1 (baseline) 1.1930 1.00x 4 1.2183 0.98x
Comme vous pouvez le voir, il n’y a pas de changement significatif de la vitesse lorsque j’exécute la version à 4 threads par rapport à la version standard monothread. Voyons maintenant ce qui se produit avec la version véritablement multithread, 3.13.5t :
Python version: 3.13.5 experimental free-threading build (main, Jul 10 2025, 20:36:28) [Clang 17.0.0 (clang-1700.0.13.5)] CPU count: 8 Range size: 1000000 Number of chunks: 16 ------------------------------------------------------------ Running single-threaded version (baseline)... Found 78498 primes in 1.5869 seconds ------------------------------------------------------------ Running multi-threaded version with 4 threads... Found 78498 primes in 0.4662 seconds (speedup: 3.40x) ------------------------------------------------------------ SUMMARY: Threads Time (s) Speedup 1 (baseline) 1.5869 1.00x 4 0.4662 3.40x
Dans ce cas, la vitesse est plus de 3 fois supérieure. Notez que dans les deux cas le multithreading impose une surcharge. Par conséquent, même avec un véritable multithreading, la vitesse n’est pas 4 fois supérieure avec 4 threads.
Conclusion
Dans la deuxième partie de la série d’articles de blog « Accélérer Python », nous avons vu pourquoi il était important d’avoir le GIL dans Python, comment contourner la limitation du GIL avec le multitraitement, ainsi que comment supprimer le GIL et les effets de cette suppression.
À l’heure où j’écris cet article, la version véritablement multithread de Python n’est toujours pas la version par défaut. Cependant, avec l’adoption par la communauté et les bibliothèques tierces, la version véritablement multithread de Python devrait devenir la norme à l’avenir. Il a été annoncé que Python 3.14 inclurait une version véritablement multithread qui serait au-delà du stade expérimental, mais resterait facultative.
PyCharm offre une prise en charge optimale de Python, que ce soit en termes de vitesse ou de précision. Profitez d’une saisie semi-automatique avancée, de vérifications de conformité PEP 8, de refactorisations intelligentes et de toute une gamme d’inspections pour répondre à tous vos besoins de codage. Comme nous l’avons vu dans cet article, PyCharm fournit des paramètres personnalisés pour les interpréteurs Python et les configurations d’exécution, afin de sélectionner l’interpréteur voulu en quelques clics, ce qui le rend utile pour une large gamme de projets Python.
Auteur de l’article original en anglais :





