

L’amélioration de l’IA dépend de la qualité des données : nous avons besoin de votre aide

Mise à jour (10 novembre 2025) :
Nous souhaitons vous communiquer une information importante concernant la mise en œuvre de la fonctionnalité de partage de données détaillées décrite dans cet article. Bien que nous ayons initialement prévu de publier ces fonctionnalités dans la mise à jour mineure 2025.2.X, leur livraison a été reportée à la version 2025.3.1 des JetBrains IDEs.
Nous avons apporté cette modification pour prendre en compte les retours d’expérience que vous, nos utilisateurs, nous avez transmis. Nous affinons les mesures de protection du partage de données en fonction des cas d’utilisation que vous nous avez communiqués, et nous avons introduit plusieurs changements qui nous permettront à l’avenir de mettre en place des contrôles plus précis pour chaque projet.
Nous avons également simplifié le mécanisme de désinscription pour les utilisateurs non commerciaux pour le rendre plus rapide et plus convivial. Merci pour votre collaboration et vos contributions qui nous permettent d’assurer une implémentation plus fluide !
TL;DR
Ces dernières années, l’IA a fait des progrès remarquables, mais elle ne répond pas toujours aux besoins des développeurs professionnels. L’une des principales raisons à cela est que la plupart des modèles sont formés sur des ensembles de données publics, qui ne reflètent pas les scénarios complexes auxquels les développeurs professionnels sont confrontés chaque jour. Sans ces données correspondant à la réalité des développeurs, nos outils d’IA ne pourront pas être perfectionnés. Pour les améliorer, JetBrains, à l’instar d’autres entreprises du secteur, doit apprendre des usages réels.
Nous demandons à nos utilisateurs de nous aider à cette fin. Voici comment :
Ce qui change : les IDE JetBrains peuvent désormais collecter des données détaillées concernant le code. Toutefois, nous ne collectons pas de données auprès de nos utilisateurs sans avoir préalablement obtenu leur consentement explicite et éclairé. L’option peut être désactivée par les utilisateurs individuels dans les paramètres de l’IDE et une protection supplémentaire au niveau de l’organisation empêche le partage de données à partir des machines des utilisateurs individuels et des instances d’IDE en l’absence de l’autorisation d’un administrateur dans le compte JetBrains de l’organisation.
Date d’effet de ce changement : avec la mise à jour 2025.3.1 des JetBrains IDEs.
Qui est concerné :
- Les entreprises désireuses de participer – les administrateurs peuvent autoriser le partage de données au niveau de l’organisation. Afin de soutenir les premières entreprises acceptant de participer à ce programme de collecte de données, nous offrons des abonnements gratuits au All Products Pack.
- Les personnes utilisant une licence gratuite, non commerciale – le partage de données est activé par défaut, mais vous pouvez le désactiver à tout moment dans les paramètres. Une notification concernant la mise à jour s’affichera lors du premier lancement de la version correspondante et aucune donnée ne sera collectée tant que cette notification n’aura pas été affichée.
Qui n’est pas concerné :
- Pour les entreprises qui ne souhaitent pas adhérer au programme, rien ne change et les administrateurs gardent le contrôle.
- Pour les personnes utilisant des licences commerciales, des essais gratuits, des licences community gratuites ou des versions EAP, rien ne change.
Pour en savoir plus, veuillez vous reporter à l’article de blog ci-dessous, à l’avis de collecte de données et à la FAQ sur la collecte des données.
L’IA transforme la façon dont les logiciels sont créés, mais elle n’est encore qu’un outil
Depuis plus de 25 ans, JetBrains crée des outils de développement professionnels qui vous permettent de transformer votre vision en code, tout en rendant le processus de développement plus agréable. Nous considérons l’IA comme un outil révolutionnaire pour faire avancer cette mission, mais bien qu’elle ait considérablement évolué, nous savons qu’elle peut encore s’améliorer. Actuellement, l’IA aide déjà à effectuer de nombreuses tâches et donne des résultats impressionnants pour des cas simples et bien définis. Mais la qualité de ses résultats se dégrade rapidement dans les scénarios complexes généralement observés dans les environnements de développement professionnel, ce qui entraîne des erreurs, des lacunes dans la logique, ou même du code inventé.
Les données d’entrée et les signaux de rétroaction sont essentiels pour améliorer le fonctionnement de l’IA
Toutes les couches d’IA peuvent être entraînées, repensées et améliorées, et les résultats qu’elles fournissent dépendent de la qualité des données d’entrée et des signaux de rétroaction. Aujourd’hui, la plupart des LLM sont entraînés sur les mêmes ensembles de données disponibles publiquement et on commence seulement à voir de grandes entreprises adopter des retours d’informations réels en boucle fermée de la part des utilisateurs pour améliorer davantage les performances des modèles. Le résultat ? Les outils d’IA conviennent très bien pour des tâches simples et des projets entièrement nouveaux, mais ne parviennent pas à résoudre les problèmes réels et à s’adapter correctement aux bases de code existantes. Les prestataires de LLM le reconnaissent et leurs approches en matière de collecte de données ont commencé à évoluer.
En théorie, la réponse est juste devant nos yeux. Nos IDE aident des millions de développeurs professionnels dans leur travail au quotidien, de la réalisation des tâches fastidieuses et routinières à la résolution des problèmes d’ingénierie les plus avancés. Ce sont précisément ces données qui pourraient être utilisées pour affiner nos modèles. Mais nous savons aussi à quel point ces données sont sensibles. Certaines informations doivent rester privées, car vos solutions sont votre propriété intellectuelle et toute votre activité dépend souvent de votre code.
Pour valider l’idée selon laquelle les données réelles peuvent vraiment améliorer les résultats de l’IA, nous avons récemment commencé à collecter ce type de données au sein de notre entreprise et à les utiliser pour entraîner nos modèles. Les résultats obtenus jusqu’à présent ont été prometteurs, mais pour aller plus loin, nous devons augmenter la quantité et la variété des données que nous utilisons.
Nous respectons les politiques de confidentialité, tant personnelles que professionnelles, et nous vous demandons en toute transparence votre autorisation pour collecter ces données. Le partage de données reste toujours votre choix. Ce n’est jamais une obligation. Si vous décidez de nous apporter votre aide, toutes les données que vous partagerez seront traitées de manière responsable, en totale conformité avec les lois de l’Union européenne sur la protection des données. En contribuant, vous nous aiderez à rendre les outils d’IA plus intelligents, plus sûrs et plus utiles pour l’ensemble de la communauté des développeurs. Nous vous serions très reconnaissants de votre coopération.
Ce qui va pouvoir être amélioré
En partageant vos données, vous contribuerez à l’évolution des outils sur lesquels vous comptez au quotidien. Vos données aideront JetBrains à garantir que :
- Le code non sécurisé soit détecté et filtré, afin de réduire le risque qu’il soit introduit dans votre base de code. C’est un point particulièrement important, car de plus en plus d’équipes commencent à déléguer des tâches plus longues à des agents de programmation sans avoir de procédure de sécurité et de test solide.
- Nous puissions gérer des tâches à volume élevé nécessitant peu d’intelligence à des coûts inférieurs à ceux qui seraient possibles en utilisant simplement un modèle de base.
- Vous puissiez bénéficier d’une saisie semi-automatique du code plus intelligente, d’explications plus claires, de moins de faux positifs et d’une IA qui comprenne vraiment vos workflows professionnels, plutôt que d’exemples artificiels élaborés dans des langages surreprésentés du web générant du code de qualité inégale. Nous concevons tout cela pour les développeurs en activité, et vos cas d’utilisation concrets font toute la différence.
Nous nous engageons également à donner en retour. Par exemple, Mellum (notre LLM spécialement conçu pour la saisie semi-automatique du code) est open source et disponible sur Hugging Face et Amazon Bedrock.
Deux couches de données
- Actuellement, nos produits collectent des données télémétriques anonymes : des statistiques anonymes généralisées sur l’utilisation des fonctionnalités (telles que le temps passé, les clics ou les workflows généraux).
- Nous ajoutons à présent une option permettant la collecte de données détaillées concernant le code liées à l’activité de l’IDE, telles que l’historique des modifications, l’utilisation du terminal et vos interactions avec les fonctionnalités d’IA. Cela peut inclure des extraits de code, des textes de prompts et des réponses de l’IA.
Cela semble beaucoup, et ça l’est, mais c’est là que réside le véritable potentiel d’amélioration. Si vous nous autorisez à collecter ces données, nous nous assurerons que :
- Aucune information sensible ou personnelle ne soit partagée.
- Les données soient correctement sécurisées.
- L’accès soit limité au personnel autorisé et aux cas d’utilisation.
En savoir plus sur les données collectées et la manière dont elles sont protégées.
La télémétrie anonyme est essentielle pour évaluer l’utilisation et les performances des fonctionnalités. Les données détaillées relatives au code sont essentielles pour entraîner des modèles spécialisés comme Mellum, qui sont mieux adaptés à l’atteinte d’un objectif spécifique, comme la vitesse de génération, la rentabilité ou la précision sur des tâches professionnelles complexes impliquant de grandes bases de code. Elles sont également fondamentales pour la boucle de rétroaction et pour accélérer les itérations sur toutes les fonctionnalités d’IA que nous créons.
Nous utiliserons ces données pour l’analyse des produits et l’évaluation des modèles, ainsi que pour entraîner nos propres modèles, dans le seul but d’améliorer les performances de nos produits dans votre travail quotidien. Nous ne partagerons pas ces données avec des tiers.
Votre code est votre création et nous le traiterons comme tel : vous en garderez le contrôle total. Vous pouvez modifier vos préférences de partage de données dans l’IDE à tout moment et retirer votre consentement avec effet immédiat.
Vous souhaitez contribuer ?
Afin d’obtenir des données pour améliorer nos produits, notamment pour l’entraînement de l’IA, nous lançons plusieurs programmes de partage de données, tous conçus dans le respect de votre vie privée :
- Pour les utilisateurs non commerciaux : possibilité de refuser le partage
Nous fournissons déjà certains de nos IDE gratuitement pour l’éducation, les projets de loisirs et le travail open source. Dans ces cas, le partage de données sera activé par défaut, mais le partage de données détaillées liées au code peut être désactivé à tout moment dans les paramètres.
- Pour les organisations
Les utilisateurs disposant de licences d’organisation ne pourront partager des données détaillées liées au code que si un administrateur autorise le partage au niveau de l’entreprise, afin d’éviter les fuites de propriété intellectuelle accidentelles. Cette option en étant encore en phase expérimentale, nous offrirons des licences All Products Pack gratuites à un certain nombre d’entreprises désireuses de partager des données. Rejoignez la liste d’attente si vous souhaitez participer et nous vous informerons si votre demande est approuvée.
Pour les personnes utilisant des licences commerciales individuelles, des essais gratuits, des licences community gratuites ou des versions EAP, rien ne change pour le moment. Si vous acceptez de partager vos données avec JetBrains (et que vos administrateurs, le cas échéant, vous y autorisent), vous pouvez activer le partage des données dans les paramètres. Pour les entreprises qui ne souhaitent pas adhérer au programme, rien ne change et les administrateurs gardent le contrôle.
À partir de quand les changements auront lieu
Les nouvelles options de partage de données seront disponibles avec la mise à jour 2025.3.1 des JetBrains IDEs. Les utilisateurs non commerciaux recevront une notification concernant les mises à jour dans les conditions d’utilisation. Pour les titulaires d’autres types de licences, si vous n’avez jamais donné votre consentement, rien ne changera.
Nous avons également apporté des modifications aux Conditions d’utilisation de JetBrains AI pour nous assurer qu’elles prennent en compte les nouveaux mécanismes de collecte de données.
Où trouver les paramètres
Vous trouverez les paramètres concernant le partage de données dans les IDE, dans Settings | Appearance & Behavior | System Settings | Data Sharing :
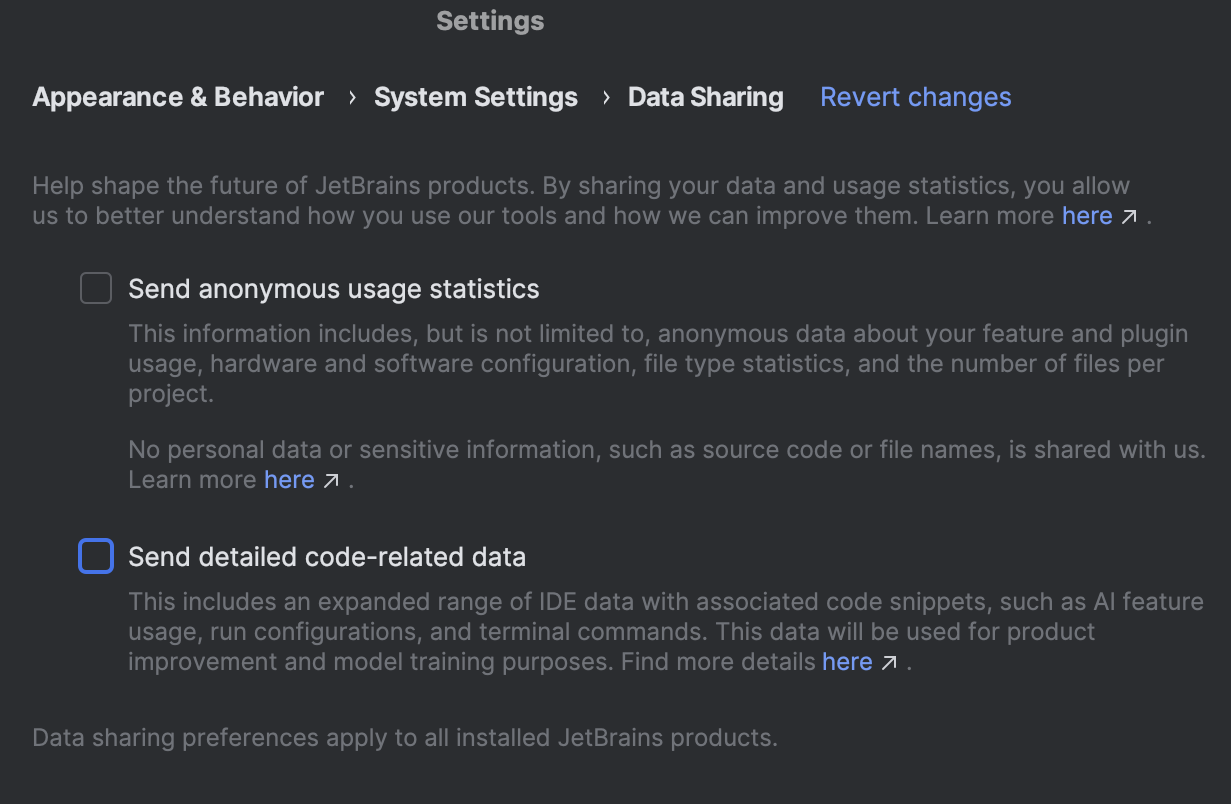
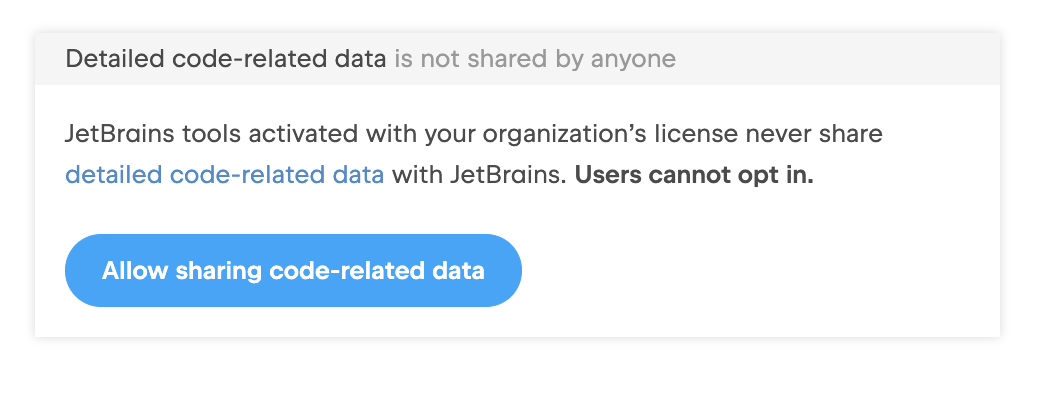
Pour les entreprises qui ne souhaitent pas ou, pour des raisons juridiques, ne peuvent pas adhérer au programme, rien ne change et leurs administrateurs conservent un contrôle total. Les administrateurs peuvent vérifier les paramètres dans leur compte JetBrains :
Un accord équitable, selon vos conditions
Nous savons que ce sujet peut être polarisant, mais nous croyons vraiment à la valeur que ce changement peut apporter à nos outils et à vous. Nous sommes transparents sur nos intentions et nos actions, et le choix final de partager ou non vos données vous appartient.
Si les conditions de votre contribution au programme vous convient, veuillez activer le partage de données dans votre IDE ou demander à votre entreprise de rejoindre la liste d’attente. Merci de nous aider à créer des outils d’IA répondant aux besoins des cas concrets du développement, de manière sécurisée, responsable et sous votre contrôle.
Auteurs de l’article original en anglais :




