

Nettoyage des données en science des données

Dans cette série d’articles consacrés à la science des données, nous avons parlé de la source des données et vu comment explorer ces données avec pandas, mais s’il s’agit d’un excellent exercice, il ne reflète pas tout à fait ce qu’il convient d’appeler les données réelles. Les données utilisées au cours des formations sont généralement nettoyées et préparées pour se concentrer sur l’apprentissage sans avoir à se pencher sur le processus de nettoyage, mais les données de production contiennent souvent des problèmes et sont parfois mal organisées. Ces données doivent être nettoyées pour produire des informations exploitables, et c’est le sujet de cet article de blog.
Les problèmes de données peuvent être liés au comportement des données en tant que telles, à la manière dont elles ont été collectées, ou même à la façon dont elles ont été saisies. Des erreurs ou des oublis peuvent se produire à tous les stades du parcours.
Nous allons voir ici le nettoyage des données et non pas leur transformation. Le nettoyage des données permet de s’assurer que les conclusions que vous en tirez peuvent être généralisées à la population que vous définissez. Par contraste, la transformation des données implique notamment la conversion des formats, la normalisation et l’agrégation.
Pourquoi le nettoyage des données est-il important ?
Il faut commencer par comprendre ce que représentent les ensembles de données. La plupart des ensembles de données constituent un échantillon représentatif d’une population plus large et, en travaillant avec cet échantillon, vous êtes en mesure d’extrapoler (ou de généraliser) vos conclusions au reste de la population. Par exemple, nous avons utilisé un ensemble de données dans les deux articles précédents. Cet ensemble de données porte essentiellement sur les ventes de maisons, mais il ne couvre qu’une petite zone géographique, une courte période de temps et potentiellement pas toutes les maisons dans cette zone et cette période. Il s’agit d’un échantillon d’une population plus large.
Vos données doivent constituer un échantillon représentatif de l’ensemble de la population. Par exemple, toutes les ventes de maisons dans cette zone pendant une période donnée. Pour s’assurer que les données constituent bien un échantillon représentatif de la population dans son ensemble, nous devons d’abord définir les limites de cette population.
Comme vous le savez, il est souvent difficile de travailler avec l’ensemble de la population, à l’exception peut-être des données de recensement, et vous devez donc poser des limites. Ces limites peuvent être géographiques, démographiques, temporelles, basées sur des actions (notamment transactionnelles) ou propres à un domaine. La population peut être définie de nombreuses façons, mais pour généraliser vos données de façon fiable, vous devez la définir avant de procéder au nettoyage des données.
En résumé, si vous prévoyez d’utiliser vos données à des fins d’analyse, quelle qu’elle soit, ou de machine learning, vous devez prendre le temps de nettoyer les données, afin d’obtenir des informations fiables et de les extrapoler au monde réel. Le nettoyage des données permet de réaliser des analyses plus précises et, concernant le machine learning, des gains de performances.
Si vous ne nettoyez pas les données, vous risquez de ne pas pouvoir généraliser de façon fiable vos conclusions au reste de la population, de produire des statistiques biaisées et des visualisations incorrectes. Si vous utilisez vos données pour entraîner des modèles de machine learning, cela risque également d’entraîner des erreurs et des prédictions incorrectes.
Essayez PyCharm Professional gratuitement
Exemples de nettoyage des données
Nous allons voir quelles sont les cinq tâches à exécuter pour nettoyer vos données. Cette liste n’est pas exhaustive, mais elle constitue un excellent point de départ pour aborder des données réelles.
Déduplication des données
Les doublons sont un problème parce qu’ils peuvent biaiser vos données. Imaginez que vous tracez un histogramme représentant la fréquence des prix de vente. Les doublons de valeurs faussent l’histogramme représentant la distribution des prix.
Pour être plus précis, lorsque nous parlons de duplication dans les ensembles de données, nous parlons de doublons de lignes de données, chacune d’entre elles correspondant à une observation unique. Les colonnes comportent aussi des doublons, ce qui est prévisible. Nous parlons uniquement des doublons d’observations.
Heureusement pour nous, une méthode pandas permet de détecter la présence de doublons dans nos données. Nous pouvons utiliser la fonction de chat de JetBrains AI pour créer un rappel avec un prompt tel que :
Code to identify duplicate rows
Voici le code résultant :
duplicate_rows = df[df.duplicated()] duplicate_rows
Ce code suppose que votre DataFrame s’appelle df et il est donc important de le remplacer par le nom de votre DataFrame s’il est différent.
Il n’y a pas de doublons de données dans l’ensemble de données Ames Housing que nous utilisons, mais si vous recherchez un exemple qui en comporte, utilisez l’ensemble de données CITES Wildlife Trade Database et voyez si vous pouvez trouver les doublons au moyen de la méthode pandas ci-dessus.
Une fois les doublons identifiés, vous devez les éliminer pour ne pas fausser vos résultats. Vous pouvez également obtenir le code requis pour cela avec JetBrains AI en utilisant un prompt tel que :
Code to drop duplicates from my dataframe
Le code résultant élimine les doublons, réinitialise l’index de votre DataFrame, puis l’affiche sous la forme d’un nouveau DataFrame appelé df_cleaned :
df_cleaned = df.drop_duplicates() df_cleaned.reset_index(drop=True, inplace=True) df_cleaned
Il existe d’autres fonctions pandas que vous pouvez utiliser pour une gestion de doublons plus avancée, mais la fonction indiquée ci-dessus est suffisante pour amorcer la déduplication de votre ensemble de données.
Gestion des valeurs non plausibles
Les valeurs non plausibles apparaissent généralement lorsque les données sont saisies de façon incorrecte ou lorsque quelque chose ne se déroule pas correctement pendant le processus de collecte de données. Pour notre ensemble de données Ames Housing, une valeur non plausible peut prendre la forme d’une valeur négative pour SalePrice ou d’une valeur numérique pour Roof Style.
L’identification de valeurs non plausibles dans votre ensemble de données repose sur une approche plus large qui inclut l’examen des statistiques de résumé, afin de vérifier les règles de validation des données qui ont été définies par le collecteur pour chaque colonne, et en notant les points de données qui tombent en dehors de cette validation, ainsi qu’en utilisant des visualisations pour identifier des schémas et tout ce qui peut constituer une anomalie.
Il est recommandé de gérer les valeurs non plausibles, car elles peuvent ajouter du bruit et créer des problèmes au niveau de vos analyses. Toutefois, l’approche à utiliser est sujette à différentes interprétations. Si vous n’avez pas beaucoup de valeurs non plausibles par rapport à la taille de votre ensemble de données, il est recommandé de supprimer les enregistrements correspondants. Par exemple, si vous avez identifié une valeur non plausible à la ligne 214 de votre ensemble de données, vous pouvez utiliser la fonction drop de pandas pour supprimer cette ligne de votre ensemble de données.
Ici aussi, JetBrains AI peut générer le code nécessaire avec un prompt tel que :
Code that drops index 214 from #df_cleaned
Il est à noter que dans les notebooks Jupyter de PyCharm je peux ajouter le préfixe # devant les mots pour indiquer à l’AI Assistant de JetBrains que je fournis du contexte supplémentaire et, dans ce cas, que mon DataFrame s’appelle df_cleaned.
Le code de sortie supprime cette observation de votre DataFrame, réinitialise l’index et l’affiche :
df_cleaned = df_cleaned.drop(index=214) df_cleaned.reset_index(drop=True, inplace=True) df_cleaned
Une autre stratégie courante de traitement des valeurs non plausibles consiste à les imputer, ce qui veut dire que vous les remplacez par une valeur plausible sur la base d’une stratégie définie. L’une des stratégies les plus communes consiste à utiliser la valeur médiane au lieu de la valeur non plausible. Dans la mesure où la valeur médiane n’est pas affectée par les valeurs aberrantes, elle est souvent retenue par les data scientists à cet effet, tout comme la moyenne ou la valeur de mode de vos données peut être plus pertinente dans certaines situations.
D’autre part, si vous connaissez le domaine relatif à l’ensemble de données et la façon dont les données ont été réunies, vous pouvez remplacer la valeur non plausible par une valeur qui est plus significative. Si vous participez à ce processus de collecte de données ou le connaissez, cette option peut être faite pour vous.
Le choix du traitement des valeurs non plausibles dépend de leur prédominance dans votre ensemble de données, de la façon dont les données sont collectées et de comment vous envisagez de définir votre population, ainsi que d’autres facteurs, tels que votre connaissance du domaine étudié.
Formatage des données
Vous pouvez identifier les problèmes de formatage avec vos statistiques résumées ou des visualisations anticipées pour avoir une idée de la qualité de vos données. Le formatage incohérent peut se manifester sous forme de valeurs numériques qui ne sont pas toutes définies sur la même décimale ou des variations typographiques, telles que « premier » et « 1er ». Le formatage incorrect des données peut également avoir des implications sur l’empreinte mémoire de vos données.
Lorsque vous identifiez des problèmes de formatage dans votre ensemble de données, vous devez standardiser les valeurs. Selon le problème en cause, cela implique la définition de vos propres références et l’application du changement. Encore une fois, la bibliothèque pandas dispose de fonctions utiles, telles que round. Par exemple, pour arrondir la colonne SalePrice à 2 chiffres après la virgule, il est possible de demander le code suivant à JetBrains AI :
Code to round #SalePrice to two decimal places
Le code résultant arrondit la valeur et imprime les 10 premières lignes pour vous permettre de les vérifier :
df_cleaned['SalePrice'] = df_cleaned['SalePrice].round(2) df_cleaned.head()
Pour prendre un autre exemple, vous pouvez être confronté à des variantes orthographiques, avec une colonne HouseStyle qui contiendrait à la fois « 1Story » et « OneStory », alors que vous savez que les deux sont identiques. Vous pouvez utiliser le prompt suivant pour obtenir le code faisant cela :
Code to change all instances of #OneStory to #1Story in #HouseStyle
Le code résultant fait ce qui lui est demandé et remplace toutes les instances de OneStory par 1Story :
df_cleaned[HouseStyle'] = df_cleaned['HouseStyle'].replace('OneStory', '1Story')
Traitement des valeurs aberrantes
Les valeurs aberrantes sont très courantes dans les ensembles de données, mais leur traitement, s’il y en a un, dépend essentiellement du contexte. L’une des solutions les plus simples pour identifier les valeurs anormales consiste à utiliser un diagramme en boîte qui utilise les bibliothèques seaborn et matplotlib. J’ai parlé plus en détail des diagrammes en boîte dans mon article précédent sur l’exploration des données avec les pandas si vous avez besoin d’un rappel rapide.
Nous allons examiner SalePrice dans notre ensemble de données immobilières Ames pour ce diagramme en boîte. À nouveau, je vais utiliser JetBrains AI pour générer du code avec un prompt tel que :
Code to create a box plot of #SalePrice
Voici le code résultant que nous devons exécuter :
import seaborn as sns
import matplotlib.pyplot as plt
# Create a box plot for SalePrice
plt.figure(figsize=(10, 6))
sns.boxplot(x=df_cleaned['SalePrice'])
plt.title('Box Plot of SalePrice')
plt.xlabel('SalePrice')
plt.show()
Le diagramme en boîte nous dit que nous avons une inclinaison positive, car la ligne médiane de la boîte bleue est à gauche du centre. Une inclinaison positive nous dit que la distribution du prix des maisons tend à refléter majoritairement les prix les plus faibles, ce qui n’est pas surprenant. Le diagramme en boîte nous donne un indicateur visuel du nombre élevé de valeurs aberrantes dans la partie droite. Il s’agit dans cet exemple du petit nombre de propriétés qui sont très au-dessus du prix médian.
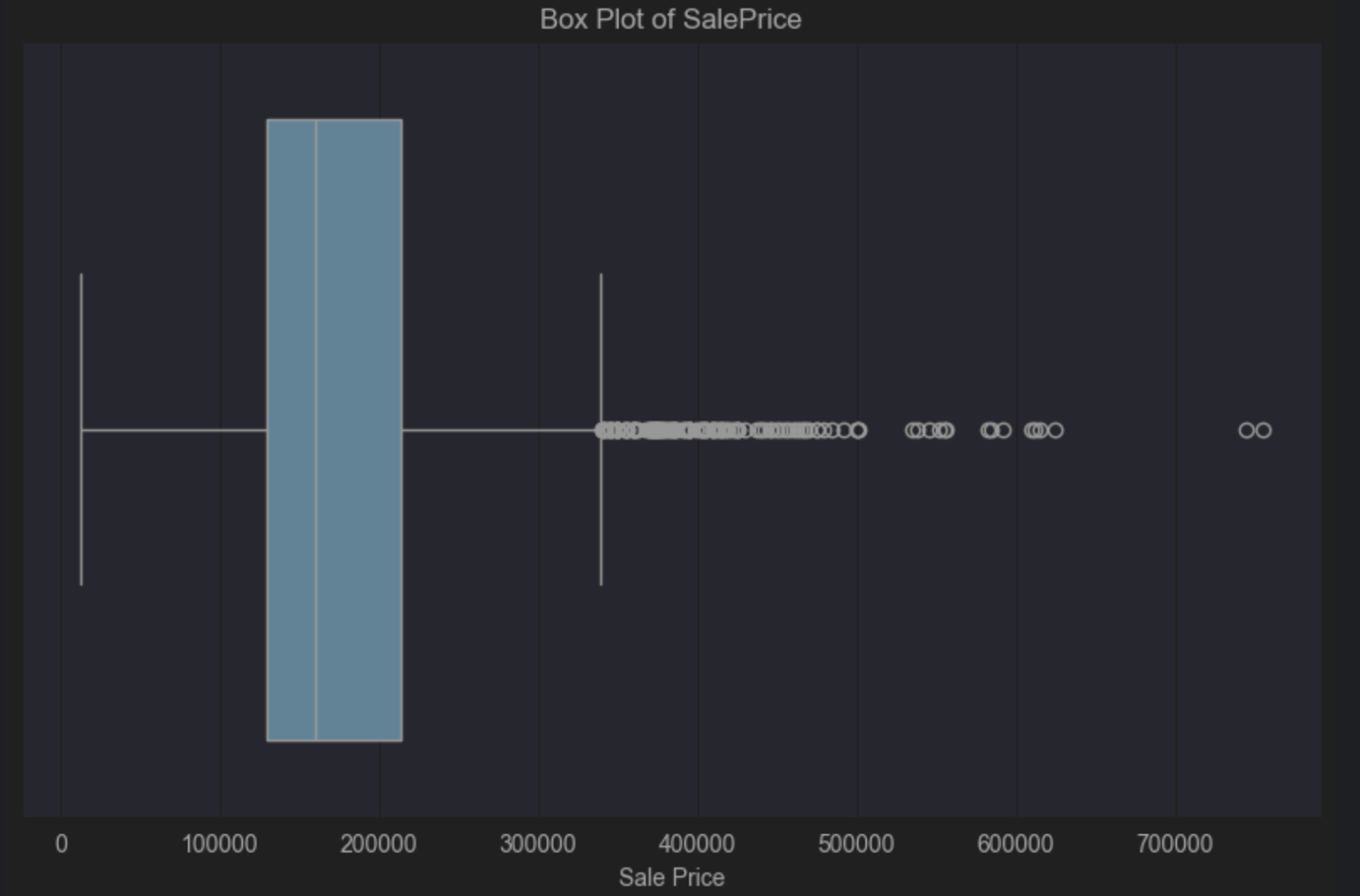
Vous pouvez accepter ces valeurs aberrantes, dans la mesure où il est tout à fait logique qu’un petit nombre de propriétés soit plus cher que la majorité. Cependant, tout dépend de la population à généraliser et des conclusions à tirer de vos données. Une définition claire du périmètre de la population permet de déterminer sur la base de données fiables si les valeurs aberrantes de vos données vont poser problème.
Par exemple, si votre population comporte des gens qui ne peuvent pas acheter des villas de luxe, il peut être judicieux de supprimer ces valeurs aberrantes. Par contre, si elle inclut des gens qui en ont les moyens, il est préférable de les conserver.
Nous avons vu dans cet article que les diagrammes en boîte permettent d’identifier les valeurs aberrantes, mais d’autres options, telles que les nuages de points et les histogrammes, permettent aussi de visualiser rapidement ce type de valeur et de prendre une décision en conséquence.
Le traitement des valeurs aberrantes tombe généralement dans deux catégories, à savoir leur suppression ou l’utilisation de statistiques moins sensibles à ce type de valeur. Dans le premier cas, nous devons savoir exactement dans quelles lignes elles se trouvent.
Jusqu’à présent, nous avons uniquement parlé de l’identification visuelle. Il existe différentes façons de déterminer quelles observations sont des valeurs aberrantes. L’approche la plus commune est une méthode appelée score Z modifié. Avant de voir comment et pourquoi il est modifié, le score Z est défini ainsi :
Score Z = (valeur du point de données – moyenne) / écart type
Nous modifions ensuite le score Z parce que la moyenne et l’écart type sont influencés par les valeurs aberrantes en raison de leur mode de calcul. Le score Z modifié est défini sous la forme :
Score Z modifié = (valeur du point de données – médiane) / écart absolu médian
Comme nous l’avons vu dans la section statistiques résumées, la médiane n’est pas impactée par les valeurs aberrantes. L’écart absolu médian correspond à la valeur médiane des écarts absolus de l’ensemble de données par rapport à la médiane. Par exemple, si votre ensemble de données contient les valeurs suivantes :
1, 2, 2, 2, 3, 3, 3, 5,9
La médiane est égale à 3, car il s’agit de la valeur au milieu de l’ensemble de données. Les écarts par rapport à la médiane de 3 sont les suivants dans l’ordre présenté ci-dessus :
2, 1, 1, 1, 0, 0, 0, 2, 5
En triant ces valeurs par ordre croissant, nous obtenons :
0, 0, 0, 1, 1, 1, 2, 2, 5
Cela signifie que l’écart absolu médian serait 1 dans cet exemple.
Comment calculer le score Z modifié pour notre ensemble de données pour SalePrice ? Soumettons ce prompt à JetBrains AI :
Given:
Modified Z-score = (data point value – median) / median absolute deviation
Calculate the Modified Z-score for #SalePrice
Cela produit le code suivant :
import pandas as pd from scipy.stats import median_abs_deviation # Assuming 'data' is your DataFrame and it contains the 'SalePrice' column # Calculate the median for the SalePrice column median_sale_price = data['SalePrice'].median() # Calculate the Median Absolute Deviation (MAD) for the SalePrice column mad_sale_price = median_abs_deviation(data['SalePrice'], scale='normal') # Calculate the Modified Z-scores for the SalePrice column data['Modified_Z_Score'] = (data['SalePrice'] - median_sale_price) / mad_sale_price # Display the first few rows with the Modified Z-scores print(data[['SalePrice', 'Modified_Z_Score']].head())
Lorsque nous installons les paquets nécessaires et exécutons ce code, nous pouvons voir que nous avons progressé, mais maintenant nous devons établir ce qu’est une valeur aberrante pour SalePrice en fonction du score Z modifié. À première vue, une valeur aberrante est ici tout nombre >=3 ou <=-3. Il faut toutefois noter que, comme pour la plupart des décisions statistiques, elle peut et doit être adaptée à votre jeu de données. <=-3 however, it’s worth noting that like most statistical decisions, it can and should be tailored to your dataset.
Nous allons soumettre un autre prompt à JetBrains AI pour obtenir un résultat plus pertinent :
Just list those that have a #Modified_Z_Score of 3 or above or -3 or below
Je vais prendre cet extrait de code et utiliser les lignes ci-dessus qui m’intéressent :
# Filter the rows where the Modified Z-score is 3 or above, or -3 or below outliers = data[(data['Modified_Z_Score'] >= 3) | (data['Modified_Z_Score'] <= -3)] # Print all the filtered rows, showing their index and SalePrice outliers = (outliers[['SalePrice', 'Modified_Z_Score']]) outliers
J’ai modifié ce code pour enregistrer les valeurs dans un nouveau DataFrame appelé « outliers » et je les ai imprimées pour les lire.
L’étape suivante consiste à retirer ces valeurs aberrantes du DataFrame. Encore une fois, il est possible d’utiliser JetBrains AI pour générer du code avec un prompt tel que :
Create a new dataframe without the outliers
data_without_outliers = data.drop(index=outliers.index) # Display the new DataFrame without outliers print(data_without_outliers)
Le nouveau DataFrame, data_without_outliers, exclut ces valeurs lorsque la variable SalePrice est considérée comme une valeur aberrante.
Il est alors possible de mettre à jour le code du diagramme en boîte pour examiner le nouveau DataFrame. Il affiche toujours l’inclinaison positive, comme cela est prévisible, mais les valeurs considérées comme aberrantes ont été supprimées :
import seaborn as sns
import matplotlib.pyplot as plt
# Create a box plot for SalePrice
plt.figure(figsize=(10, 6))
sns.boxplot(x=data_without_outliers['SalePrice'])
plt.title('Box Plot of SalePrice')
plt.xlabel('SalePrice')
plt.show()
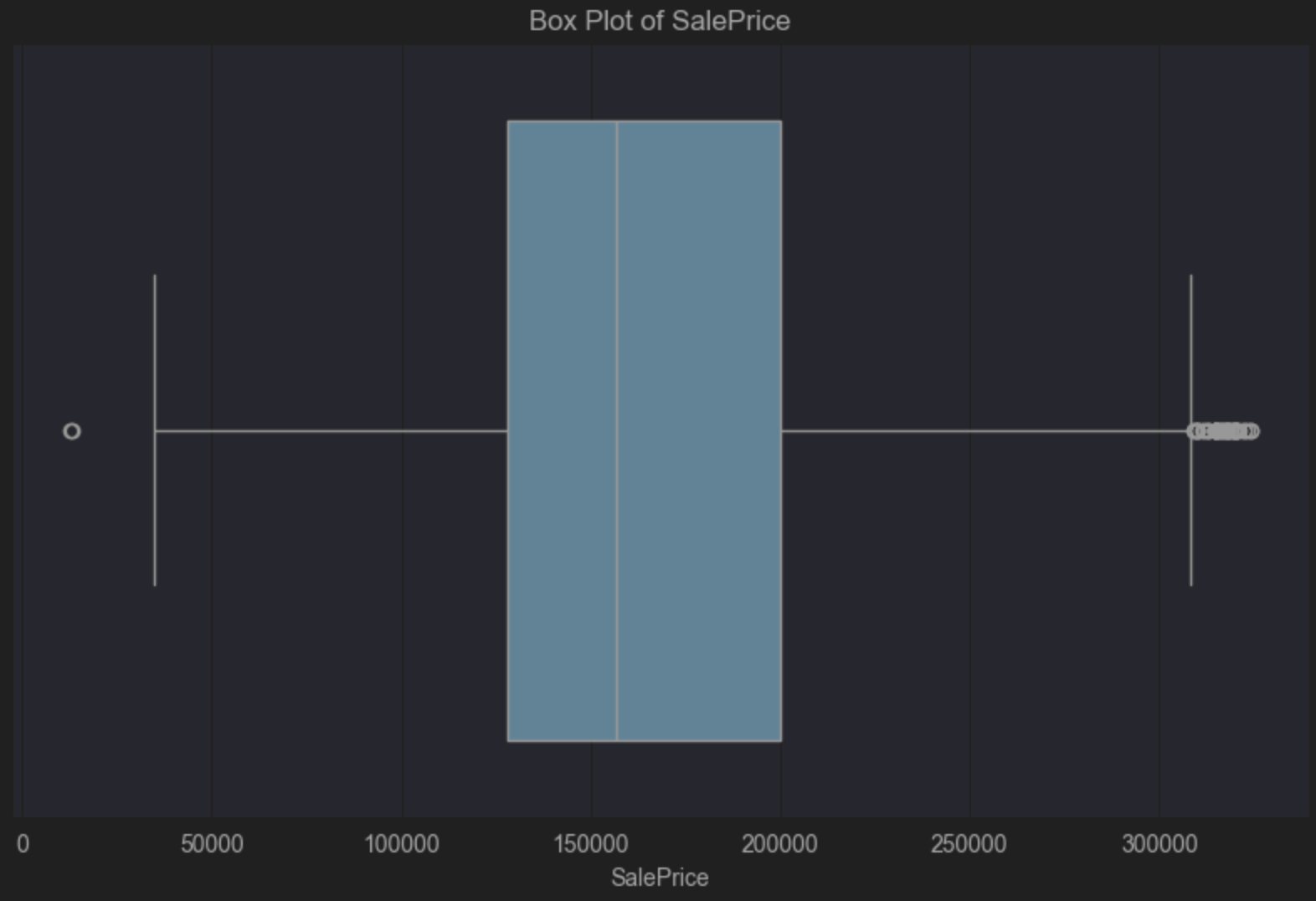
Avant de conclure pour cette partie, voyons quel pourcentage d’observations a été retiré de notre DataFrame parce qu’elles sont considérées comme des valeurs aberrantes par rapport à SalePrice.
Nous pouvons utiliser un prompt tel que :
Calculate the percentage of observations removed between #data and #data_without_outliers
# Calculate the number of observations in the original and filtered DataFrames
original_count = len(data)
filtered_count = len(data_without_outliers)
# Calculate the number of removed observations
removed_count = original_count - filtered_count
# Calculate the percentage of observations removed
percentage_removed = (removed_count / original_count) * 100
# Display the percentage
print(f"Percentage of observations removed: {percentage_removed:.2f}%")
PyCharm indique que 5,67 % des observations ont été supprimées.
Comme indiqué plus haut, si vous conservez vos valeurs aberrantes, envisagez d’utiliser des valeurs résumées qui sont moins susceptibles d’être affectées, telles que la médiane et l’écart interquartile. Vous pouvez envisager d’utiliser ces mesures pour formuler vos conclusions lorsque vous travaillez sur des ensembles de données que vous savez contenir des valeurs extrêmes pertinentes pour la population que vous avez définie et vos conclusions.
Valeurs manquantes
Le moyen le plus rapide d’identifier les valeurs manquantes de votre ensemble de données consiste à utiliser vos statistiques résumées. Pour rappel, dans votre DataFrame, cliquez sur Show Column Statistics dans la partie droite et sélectionnez Compact. Les valeurs manquantes dans les colonnes s’affichent en rouge, comme vous pouvez le voir ici, pour Lot Frontage, dans notre ensemble de données Ames Housing :

Trois types de données manquantes sont à prendre en compte pour nos données :
- Manquant de façon totalement aléatoire (MCAR)
- Manquant de façon aléatoire (MAR)
- Manquant de façon non aléatoire (MNAR)
Manquant de façon totalement aléatoire (MCAR)
Les données manquantes de façon totalement aléatoire indiquent que l’absence de données est due uniquement au hasard et que cela n’a aucun lien avec les autres variables de l’ensemble de données. Cela peut se produire lorsque quelqu’un omet de répondre à l’une des questions d’un formulaire, par exemple.
Les données manquantes de façon totalement aléatoire sont rares, mais sont aussi les plus faciles à gérer. Si vous avez un nombre relativement faible d’observations manquantes de façon totalement aléatoire, l’approche la plus courante consiste à supprimer ces observations, car cela ne devrait pas avoir d’impact sur l’intégrité de votre ensemble de données et, par conséquent, les conclusions que vous pouvez en tirer.
Manquant de façon aléatoire (MAR)
Les données manquantes de façon aléatoire ne semblent pas suivre d’ordre précis, mais les autres variables mesurées permettent d’identifier un fil conducteur. Par exemple, quelqu’un n’a pas répondu à une question du formulaire en raison du mode de collecte des données.
Si l’on garde comme exemple l’ensemble de données Ames Housing, la variable Lot Frontage peut manquer plus fréquemment pour les propriétés vendues par certaines agences immobilières. Dans ce cas, les données manquantes peuvent être dues à des pratiques différentes de saisie des données par certaines agences. Dans ce cas, l’absence de données pour Lot Frontage s’explique par la façon dont l’agence qui a vendu la propriété a collecté les données, ce qui est une caractéristique observée et ne concerne pas Lot Frontage en tant que tel.
Lorsque des données manquent de façon aléatoire, il faut essayer de comprendre pourquoi ces données sont manquantes, ce qui implique souvent de revenir sur la façon dont les données ont été collectées. Une fois que vous avez identifié la raison de l’absence de données, vous pouvez choisir quoi faire. L’une des approches les plus courantes dans ce cas consiste à imputer les valeurs. Nous avons déjà vu cela pour les valeurs non plausibles, mais c’est également une stratégie valide pour les données manquantes. Vous avez le choix entre différentes options selon la population définie et les conclusions auxquelles vous souhaitez parvenir, avec notamment l’utilisation de variables corrélées, telles que la taille de la propriété, son année de construction et son prix de vente, comme dans cet exemple. Si vous comprenez les raisons pour lesquelles des données manquent, vous pouvez généralement utiliser des informations contextuelles pour entrer les valeurs, ce qui permet de s’assurer que les relations entre les données de votre ensemble sont préservées.
Manquant de façon non aléatoire (MNAR)
Enfin, les données manquantes de façon non aléatoire signifient que la probabilité de données manquantes est liée à des données qui n’ont pas été observées. Cela signifie que les données manquantes dépendent des données non observées.
Nous allons revenir une dernière fois à notre ensemble de données Ames Housing et aux données manquantes dans Lot Frontage. L’un des scénarios possibles pour les données manquant de façon non aléatoire est que les vendeurs choisissent de ne pas déclarer « Lot Frontage » s’ils le trouvent petit et pensent que la mention de la taille réduirait le prix de vente. Si la probabilité de données « Lot Frontage » manquantes dépend de la taille du terrain (qui n’est pas observée), il est peu probable que cette taille soit sous-estimée, ce qui signifie que les données manquantes sont liées directement à la valeur manquante.
Visualisation des données manquantes
Lorsque des données manquent, vous devez établir si cela suit un schéma particulier. Si vous observez un schéma particulier, cela signifie qu’il existe un problème que vous devez résoudre avant de généraliser vos données.
L’une des façons les plus simples de visualiser cela est de créer une carte thermique. Avant de passer à la partie code, nous allons exclure les variables sans données manquantes. Pour cela nous pouvons créer un prompt pour JetBrains AI :
Code to create a new dataframe that contains only columns with missingness
Voici notre code :
# Identify columns with any missing values columns_with_missing = data.columns[data.isnull().any()] # Create a new DataFrame with only columns that have missing values data_with_missingness = data[columns_with_missing] # Display the new DataFrame print(data_with_missingness)
Avant d’exécuter ce code, modifiez la dernière ligne pour profiter de la mise en forme élégante du DataFrame par PyCharm :
data_with_missingness
Il est maintenant temps de créer une carte thermique. Ici également, nous allons utiliser un prompt destiné à JetBrains AI :
Create a heatmap of #data_with_missingness that is transposed
Voici le code résultant :
import seaborn as sns
import matplotlib.pyplot as plt
# Transpose the data_with_missingness DataFrame
transposed_data = data_with_missingness.T
# Create a heatmap to visualize missingness
plt.figure(figsize=(12, 8))
sns.heatmap(transposed_data.isnull(), cbar=False, yticklabels=True)
plt.title('Missing Data Heatmap (Transposed)')
plt.xlabel('Instances')
plt.ylabel('Features')
plt.tight_layout()
plt.show()
Notez que j’ai retiré cmap=’viridis’ des arguments de la carte thermique, car je ne le trouve pas très visible.
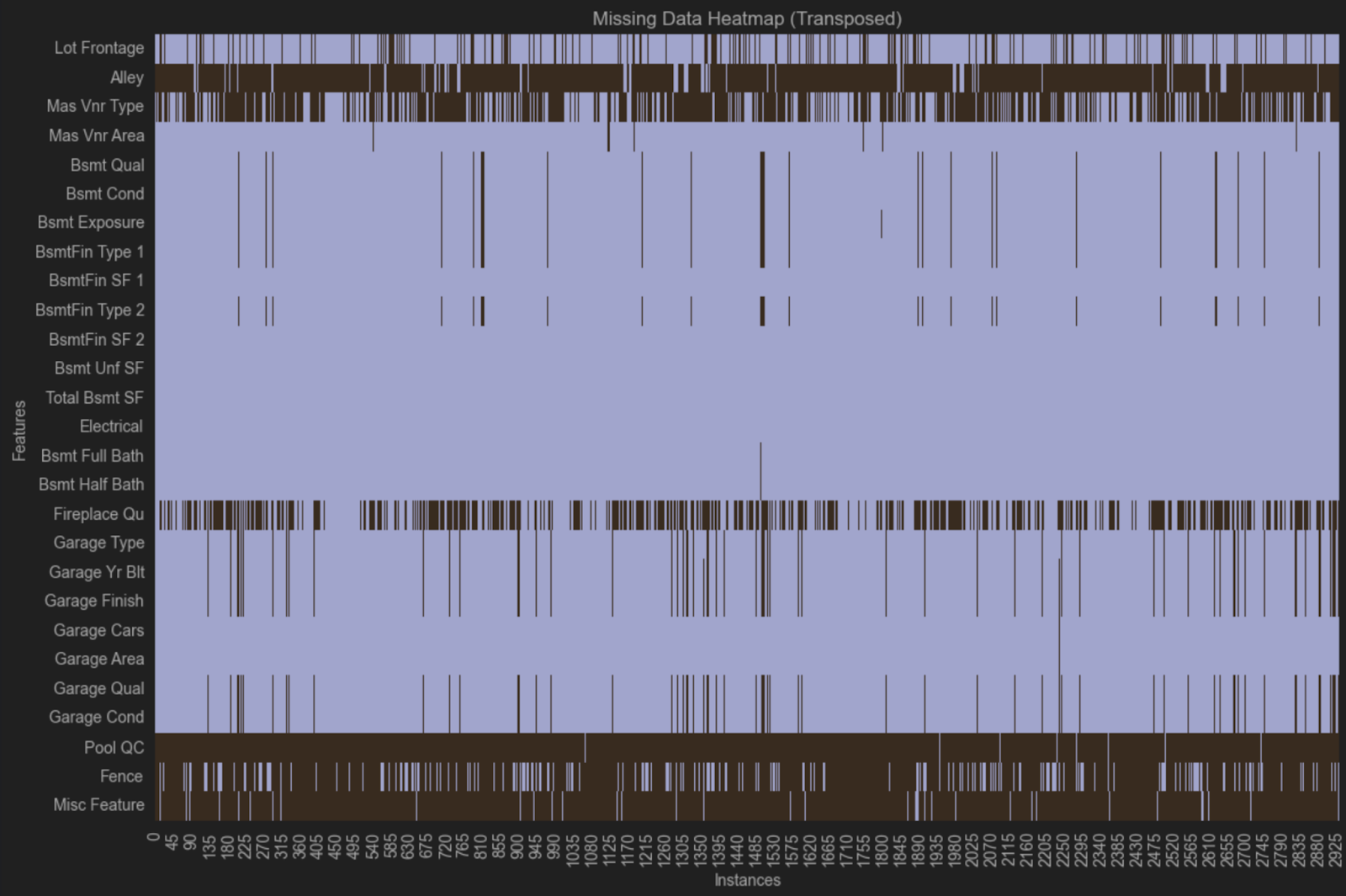
Cette carte thermique laisse supposer que les données manquantes suivent un schéma, car les mêmes variables manquent dans plusieurs lignes. Dans un groupe, les variables Bsmt Qual, Bsmt Cond, Bsmt Exposure, BsmtFin Type 1 et Bsmt Fin Type 2 sont toutes absentes des mêmes observations. Dans un autre groupe, les variables Garage Type, Garage Yr Bit, Garage Finish, Garage Qual et Garage Cond sont aussi toutes manquantes des mêmes observations.
Ces variables se rapportent toutes aux sous-sols et garages, mais il existe d’autres variables liées aux garages ou aux sous-sols qui ne sont pas manquantes. L’une des explications possibles est que des questions différentes ont été posées sur les garages et les sous-sols dans différentes agences immobilières lorsque les données ont été collectées, et que toutes n’ont pas été enregistrées de façon aussi détaillée que dans l’ensemble de données. Ces scénarios sont courants pour les données que vous ne collectez pas vous-même, et vous pouvez explorer la façon dont les données ont été collectées pour en savoir plus sur les données manquantes de votre ensemble de données.
Bonnes pratiques de nettoyage des données
Comme je l’ai indiqué, la définition de votre population est en haut de la liste de bonnes pratiques de nettoyage des données. Définissez ce que vous voulez accomplir et comment généraliser vos données avant de les nettoyer.
Vous devez vous assurer que toutes vos méthodes sont reproductibles, car cela est déterminant pour nettoyer les données. Les situations qui ne sont pas reproductibles peuvent avoir un impact significatif en aval. Par conséquent, je vous recommande de veiller à l’ordonnancement séquentiel de vos notebooks Jupyter et d’utiliser les fonctionnalités Markdown pour documenter systématiquement vos décisions, notamment concernant le nettoyage.
Lors du nettoyage des données, vous devez travailler de façon incrémentale, afin de modifier le DataFrame au lieu du fichier CSV ou de la base de données d’origine, et vous assurer que vous procédez avec un code reproductible et bien documenté.
En résumé
Le nettoyage des données est un vaste sujet, qui présente de nombreuses difficultés. Plus l’ensemble de données est important, plus son processus de nettoyage est difficile. Vous devez garder votre population à l’esprit pour généraliser vos conclusions de façon plus large tout en recherchant un équilibre entre le retrait et l’entrée des valeurs manquantes, et déterminer pour quelles raisons ces données sont manquantes.
Vous devenez en quelque sorte la voix des données. Vous savez quel est le parcours des données et comment vous avez assuré leur intégrité à tous les niveaux. Vous êtes la meilleure personne pour documenter ce parcours et le faire connaître aux autres personnes.
Essayez PyCharm Professional gratuitement
Auteur de l’article original en anglais :





