

PyCharm
The only Python IDE you need.
Affiner et déployer des modèles GPT avec Hugging Face Transformers

Hugging Face est devenu une référence aussi bien pour les chercheurs en machine learning que pour les amateurs. L’un de leurs plus grands succès est Transformers, un framework de définition de modèles pour le machine learning, que ce soit pour le texte, la vision par ordinateur, l’audio ou la vidéo. En raison du vaste référentiel de modèles de machine learning de pointe disponibles sur Hugging Face Hub et de la compatibilité de Transformers avec la majorité des frameworks d’entraînement, il est largement utilisé pour l’inférence et l’entraînement de modèles.
Pourquoi ajuster un modèle d’IA ?
L’ajustement des modèles d’IA est essentiel pour adapter leurs performances à des tâches et à des ensembles de données spécifiques, afin de les rendre plus précis et efficaces par rapport à un modèle à usage général. En adaptant un modèle pré-entraîné, l’ajustement réduit la nécessité de procéder à un entraînement à partir de zéro, ce qui permet d’économiser du temps et des ressources. Il permet également d’améliorer le traitement de formats spécifiques, de nuances et de cas atypiques dans un domaine donné, ce qui donne des résultats plus fiables et mieux adaptés.
Dans cet article, nous allons optimiser un modèle GPT avec un raisonnement mathématique afin qu’il puisse mieux répondre aux questions du domaine des mathématiques.
Utiliser des modèles de Hugging Face
Lorsque vous utilisez PyCharm, vous pouvez facilement parcourir et ajouter de nouveaux modèles provenant de Hugging Face. Dans un nouveau fichier Python, dans le menu Code en haut, sélectionnez Insert HF Model.
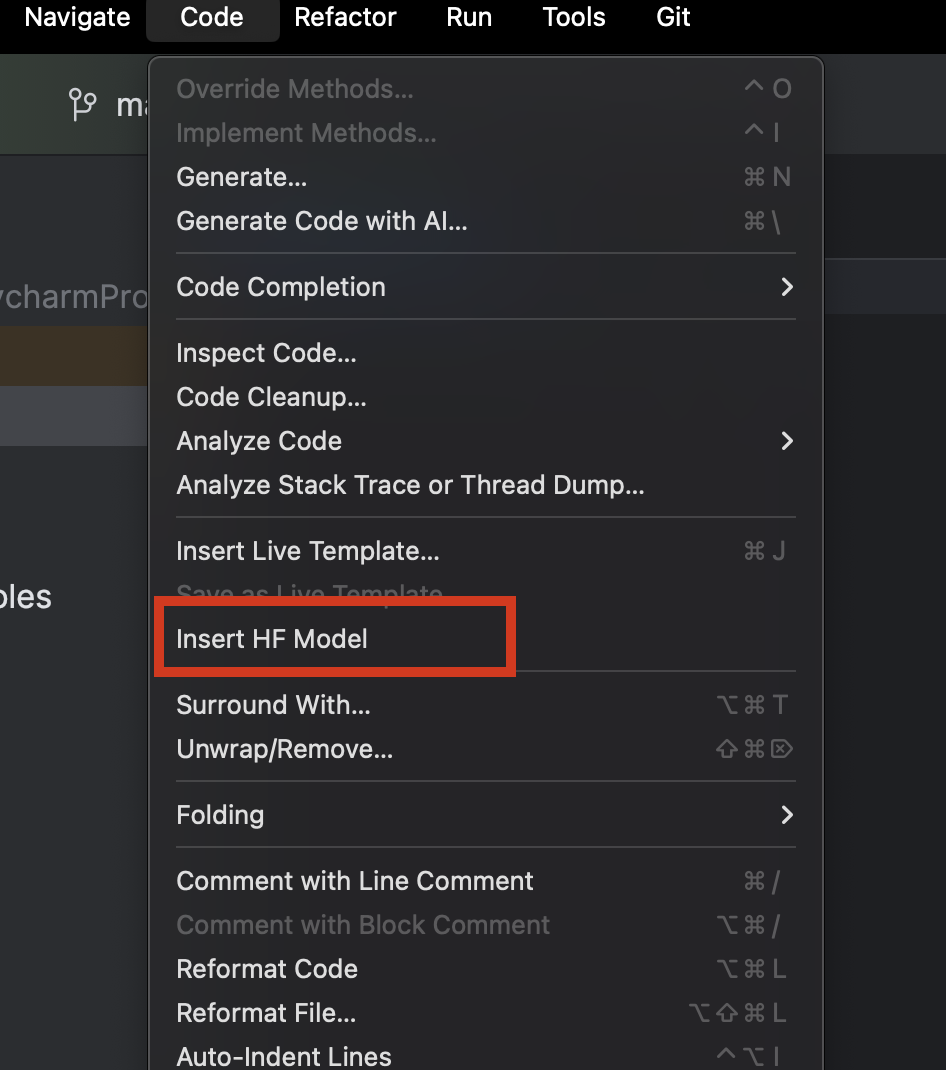
Dans le menu qui s’ouvre, vous pouvez parcourir les modèles par catégorie ou saisir votre recherche dans la barre prévue à cet effet en haut. Lorsque vous sélectionnez un modèle, sa description s’affiche à sa droite.
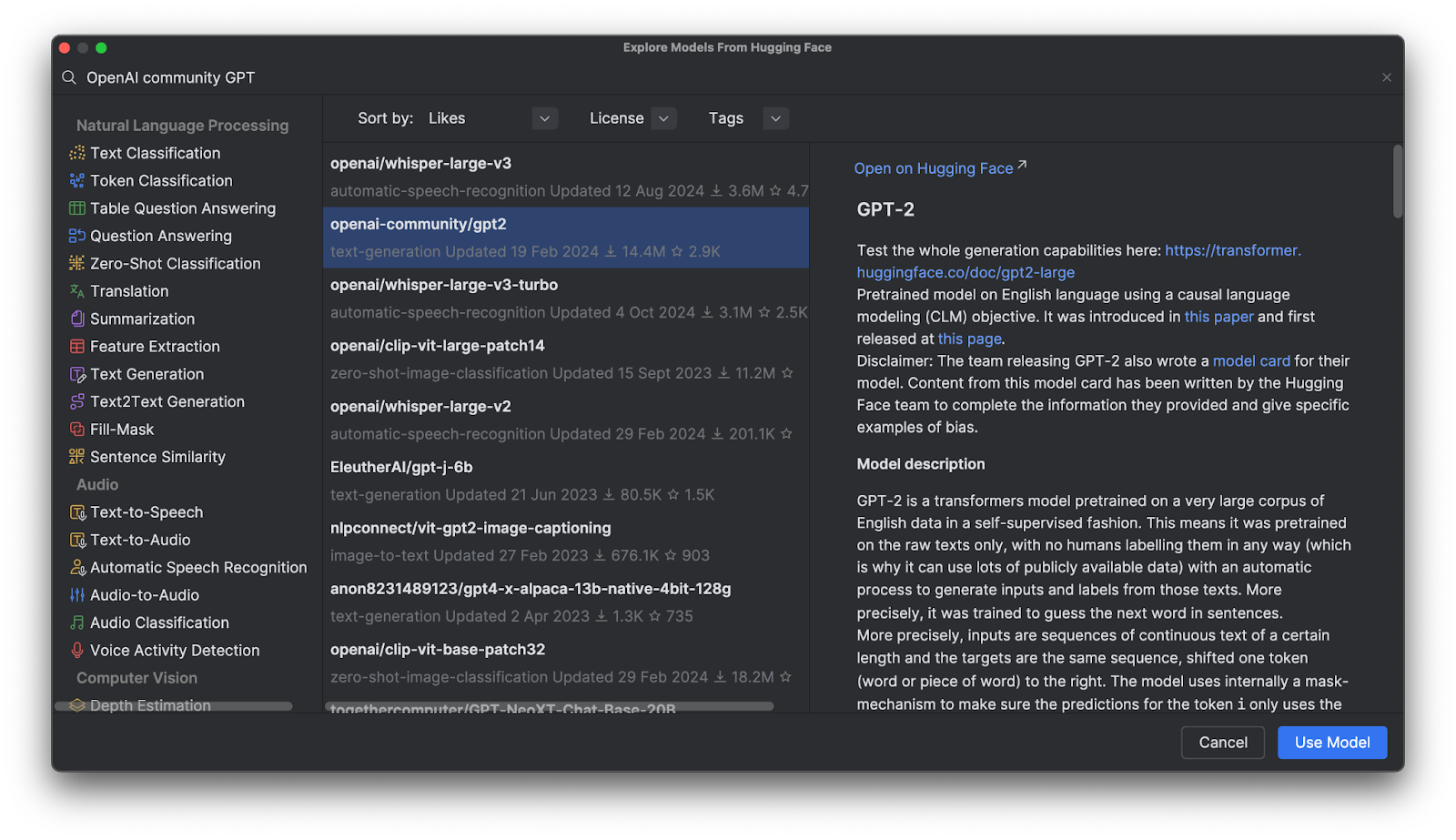
Cliquez sur Use Model pour ajouter un extrait de code à votre fichier. Et voilà, il ne vous reste plus qu’à utiliser votre modèle Hugging Face.

Modèles GPT (Generative Pre-Trained Transformer – Transformer génératif pré-entraîné)
Les modèles GPT sont très populaires sur Hugging Face Hub, mais de quoi s’agit-il ? Les modèles GPT désignent des modèles entraînés capables de comprendre le langage naturel et de générer du texte de haute qualité. Ils sont principalement utilisés dans des tâches liées à l’implication textuelle, à la réponse à des questions, à la similarité sémantique et à la classification de documents. L’exemple le plus célèbre est ChatGPT, créé par OpenAI.
De nombreux modèles OpenAI GPT sont disponibles sur Hugging Face Hub. Nous allons voir comment les utiliser avec Transformers, les ajuster avec nos propres données et les déployer dans une application.
Avantages de l’utilisation de Transformers
Transformers, associé à d’autres outils de Hugging Face, offre des outils avancés permettant d’ajuster n’importe quel modèle sophistiqué de deep learning. Si vous ne souhaitez pas vous pencher sur les détails de l’architecture d’un modèle donné et de sa méthode de tokenisation, utilisez ces outils pour créer des modèles « plug and play » à partir des données d’entraînement compatibles. Ils offrent par ailleurs de nombreuses possibilités de personnalisation de la tokenisation et de l’entraînement.
Transformers en action
Pour voir de plus près comment fonctionne Transformers, regardons comment l’utiliser pour interagir avec un modèle GPT.
Inférence au moyen d’un modèle pré-entraîné avec un pipeline
Après avoir sélectionné et ajouté le modèle GPT-2 d’OpenAI au code, nous obtenons ce qui suit :
from transformers import pipeline
pipe = pipeline("text-generation", model="openai-community/gpt2")
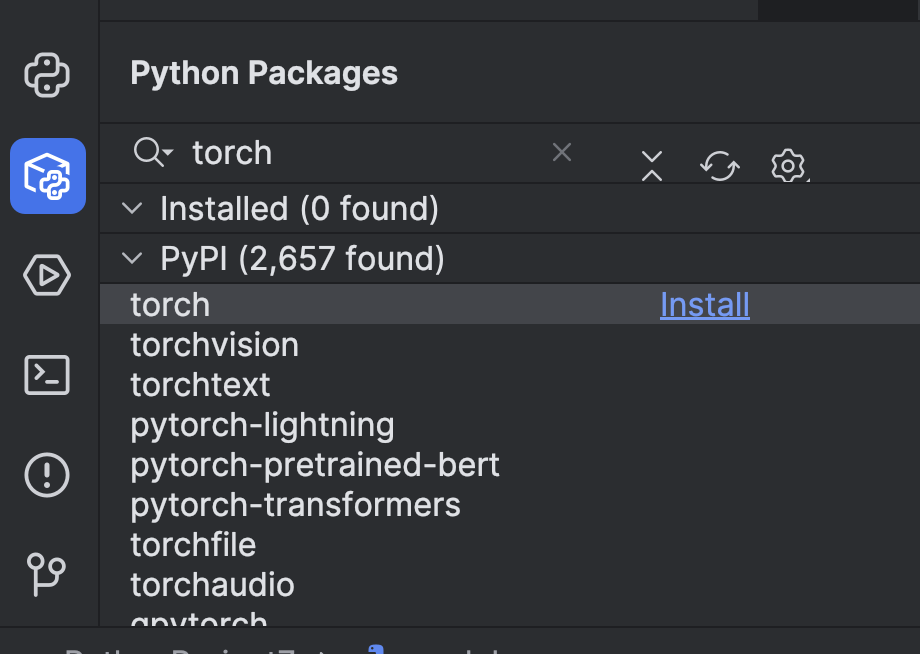
Avant de l’utiliser, nous devons effectuer quelques préparatifs. Tout d’abord, nous devons installer un framework de machine learning. Dans cet exemple, nous avons choisi PyTorch. Vous pouvez l’installer facilement via la fenêtre Python Packages dans PyCharm.
Ensuite, nous devons installer Transformers avec l’option `torch`. Pour ce faire, utilisez le terminal. Ouvrez-le en utilisant le bouton de gauche ou utilisez les touches de raccourci ⌥ F12 (macOS) ou Alt + F12 (Windows).
Dans le terminal, dans la mesure où nous utilisons uv, nous devons utiliser les commandes suivantes pour ajouter l’ensemble en tant que dépendance et l’installer :
uv add “transformers[torch]” uv sync
Si vous utilisez pip :
pip install “transformers[torch]”
Nous allons également installer quelques autres bibliothèques dont nous aurons besoin par la suite, avec notamment python-dotenv, datasets, notebook et ipywidgets. Vous pouvez utiliser l’une des méthodes ci-dessus pour les installer.
Ensuite, il peut être préférable d’ajouter un GPU pour accélérer le modèle. Selon la configuration de votre ordinateur, vous pouvez l’ajouter en définissant le paramètre device dans le pipeline. Puisque j’utilise un Mac M2, je peux définir device="mps" de la façon suivante :
pipe = pipeline("text-generation", model="openai-community/gpt2", device="mps")
Si vous avez des GPU CUDA, vous pouvez également utiliser device="cuda".
Maintenant que le pipeline est configuré, nous allons faire un essai avec un prompt simple :
from transformers import pipeline
pipe = pipeline("text-generation", model="openai-community/gpt2", device="mps")
print(pipe("A rectangle has a perimeter of 20 cm. If the length is 6 cm, what is the width?", max_new_tokens=200))
Cliquez sur le bouton Run, en haut, pour exécuter le script (![]() ) :
) :
Le résultat prend la forme suivante :
[{'generated_text': 'A rectangle has a perimeter of 20 cm. If the length is 6 cm, what is the width?nnA rectangle has a perimeter of 20 cm. If the length is 6 cm, what is the width? A rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width? A rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width? A rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width?nnA rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width? A rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width? A rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width? A rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width?nnA rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width? A rectangle has a perimeter'}]
Il n’y a pratiquement aucun raisonnement, juste une suite de mots.
Vous verrez peut-être également cet avertissement :
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Il s’agit du paramètre par défaut. Vous pouvez également l’ajouter manuellement comme indiqué ci-dessous, pour faire disparaître l’avertissement, mais nous n’avons pas vraiment à nous en préoccuper à ce stade.
print(pipe("A rectangle has a perimeter of 20 cm. If the length is 6 cm, what is the width?", max_new_tokens=200, pad_token_id=pipe.tokenizer.eos_token_id))
Maintenant que nous avons vu comment GPT-2 fonctionne tel quel, nous allons essayer d’améliorer son raisonnement mathématique.
Chargement et préparation d’un ensemble de données depuis Hugging Face Hub
Avant de travailler sur le modèle GPT, nous avons d’abord besoin de données d’entraînement. Voyons comment obtenir un ensemble de données depuis Hugging Face Hub.
Si ce n’est pas déjà fait, créez un compte Hugging Face, ainsi qu’un jeton d’accès. Nous n’avons besoin que d’un jeton `read` pour l’instant. Stockez votre jeton dans un fichier `.env` de la façon suivante :
HF_TOKEN=your-hugging-face-access-token
Nous allons utiliser Math Reasoning Dataset, qui comporte du texte décrivant des raisonnements mathématiques. Nous allons ajuster notre modèle GPT avec cet ensemble de donnée afin qu’il puisse résoudre plus efficacement les problèmes mathématiques.
Nous allons créer un notebook Jupyter, que nous utiliserons pour l’ajustement, car il permet d’exécuter différents extraits de code un par un et de suivre la progression.
Dans la première cellule, nous allons utiliser ce script pour charger l’ensemble de données depuis Hugging Face Hub :
from datasets import load_dataset
from dotenv import load_dotenv
import os
load_dotenv()
dataset = load_dataset("Cheukting/math-meta-reasoning-cleaned", token=os.getenv("HF_TOKEN"))
dataset
Exécutez cette cellule (cela peut prendre du temps selon le débit de votre connexion Internet) pour télécharger l’ensemble de données. Une fois cette opération terminée, nous pouvons examiner les résultats :
DatasetDict({
train: Dataset({
features: ['id', 'text', 'token_count'],
num_rows: 987485
})
})
Si vous êtes curieux et souhaitez jeter un œil sur les données, vous pouvez le faire dans PyCharm. Ouvrez la fenêtre Jupyter Variables en utilisant le bouton de droite :
Développez la section dataset pour voir l’option View as DataFrame près de dataset[‘train’] :
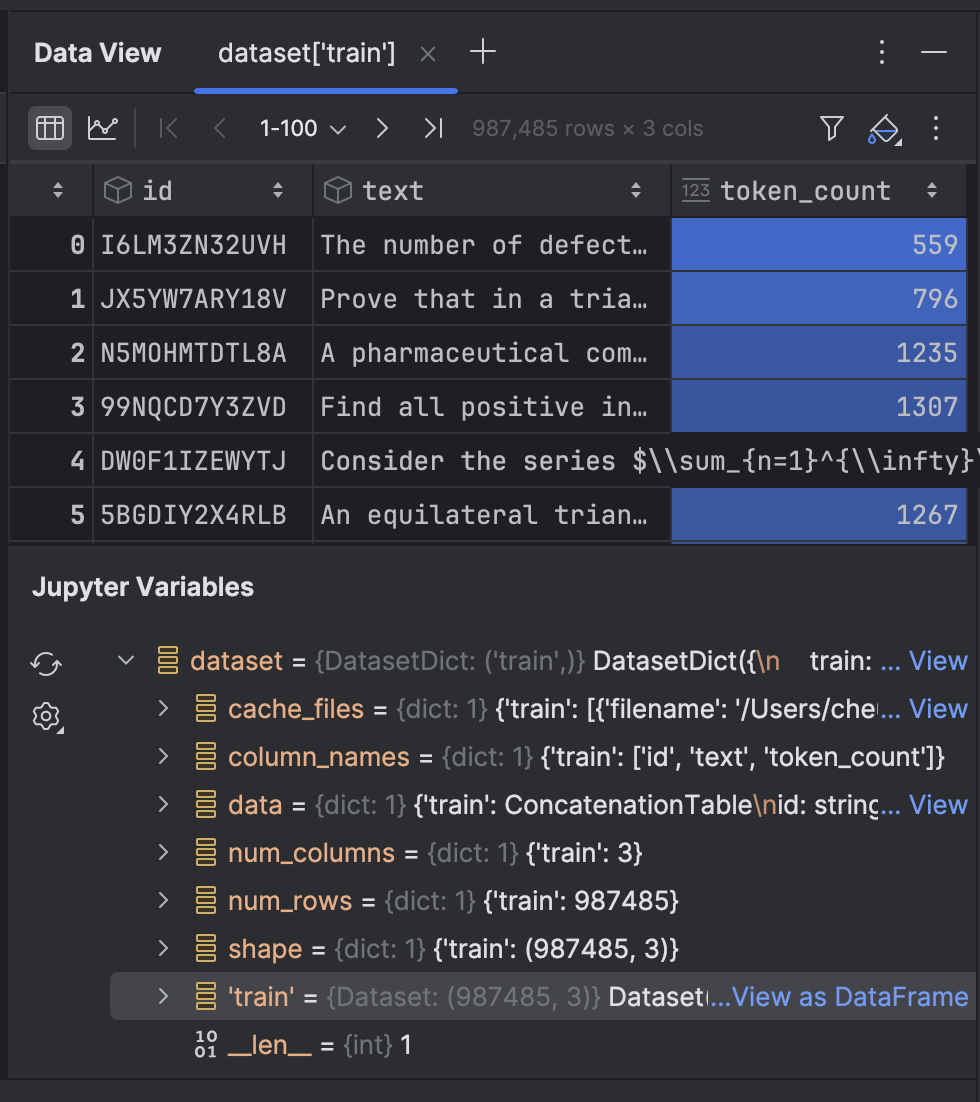
Cliquez dessus pour examiner les données dans la fenêtre d’outils Data View :
Ensuite, nous allons tokeniser le texte de l’ensemble de données :
from transformers import GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("openai-community/gpt2")
tokenizer.pad_token = tokenizer.eos_token
def tokenize_function(examples):
return tokenizer(examples['text'], truncation=True, padding='max_length', max_length=512)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
Ici, nous utilisons le tokenizer GPT-2 et définissons pad_token sur eos_token : il s’agit du jeton de fin de ligne. Ensuite, nous allons tokeniser le texte avec une fonction. La première exécution risque d’être laborieuse, mais ensuite, les données seront en mémoire cache et permettront de réexécuter la cellule plus rapidement.
Le jeu de données comporte plus de 1 million de lignes pour l’entraînement. Si vous disposez de suffisamment de puissance de calcul pour les traiter toutes, vous pouvez toutes les utiliser. Dans la mesure où la présente démonstration consiste en un entraînement local sur un ordinateur portable, je n’en utiliserai qu’une petite partie !
tokenized_datasets_split = tokenized_datasets["train"].shard(num_shards=100, index=0).train_test_split(test_size=0.2, shuffle=True) tokenized_datasets_split
Ici, je ne prends que 1 % des données, puis j’exécute train_test_split pour diviser l’ensemble de données en deux :
DatasetDict({
train: Dataset({
features: ['id', 'text', 'token_count', 'input_ids', 'attention_mask'],
num_rows: 7900
})
test: Dataset({
features: ['id', 'text', 'token_count', 'input_ids', 'attention_mask'],
num_rows: 1975
})
})
Nous sommes désormais prêts à ajuster le modèle GPT-2.
Ajuster un modèle GPT
Nous allons utiliser la cellule vide suivante pour définir nos arguments d’entraînement :
from transformers import TrainingArguments training_args = TrainingArguments( output_dir='./results', num_train_epochs=5, per_device_train_batch_size=8, per_device_eval_batch_size=8, warmup_steps=100, weight_decay=0.01, save_steps = 500, logging_steps=100, dataloader_pin_memory=False )
La plupart d’entre eux sont assez standards pour l’ajustement d’un modèle. Toutefois, selon la configuration de votre ordinateur, il peut être nécessaire d’ajuster plusieurs choses :
- Taille de lot : déterminer la taille de lot optimale est important, car plus elle est grande, plus l’entraînement sera rapide. Toutefois, la mémoire disponible de votre CPU ou GPU est limitée, ce qui crée donc un seuil maximal.
- Époques : l’augmentation du nombre d’époques prolonge l’entraînement. Vous pouvez définir le nombre d’époques dont vous avez besoin.
- Étapes d’enregistrement : les étapes d’enregistrement conditionnent la fréquence d’enregistrement d’un point de contrôle sur un disque. Si l’entraînement est lent et qu’il y a un risque d’arrêt impromptu, il peut être nécessaire de faire des enregistrements plus fréquents (en diminuant cette valeur).
Une fois l’ensemble de nos paramètres configurés, nous allons mettre en place le module d’entraînement (trainer) dans la cellule suivante :
from transformers import Trainer, DataCollatorForLanguageModeling
model = GPT2LMHeadModel.from_pretrained("openai-community/gpt2")
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets_split['train'],
eval_dataset=tokenized_datasets_split['test'],
data_collator=data_collator,
)
trainer.train(resume_from_checkpoint=False)
Nous avons défini `resume_from_checkpoint=False`, mais vous pouvez remplacer cela par `True` pour reprendre depuis le dernier point de contrôle si l’entraînement a été interrompu.
Une fois l’entraînement terminé, nous allons évaluer et enregistrer le modèle :
trainer.evaluate(tokenized_datasets_split['test'])
trainer.save_model("./trained_model")
Nous pouvons désormais utiliser le modèle entraîné dans le pipeline. Revenons pour cela à `model.py`, où nous avons utilisé un pipeline avec un modèle pré-entraîné :
from transformers import pipeline
pipe = pipeline("text-generation", model="openai-community/gpt2", device="mps")
print(pipe("A rectangle has a perimeter of 20 cm. If the length is 6 cm, what is the width?", max_new_tokens=200, pad_token_id=pipe.tokenizer.eos_token_id))
Nous allons maintenant remplacer `model=”openai-community/gpt2″` par model=”./trained_model”` et voir le résultat :
[{'generated_text': "A rectangle has a perimeter of 20 cm. If the length is 6 cm, what is the width?nAlright, let me try to solve this problem as a student, and I'll let my thinking naturally fall into the common pitfall as described.nn---nn**Step 1: Attempting the Problem (falling into the pitfall)**nnWe have a rectangle with perimeter 20 cm. The length is 6 cm. We want the width.nnFirst, I need to find the area under the rectangle.nnLet’s set ( A = 20 - 12 ), where ( A ) is the perimeter.nn**Area under a rectangle:** n[nA = (20-12)^2 + ((-12)^2)^2 = 20^2 + 12^2 = 24n]nnSo, ( 24 = (20-12)^2 = 27 ).nnNow, I’ll just divide both sides by 6 to find the area under the rectangle.n"}]
Malheureusement, cela ne résout toujours pas le problème. Cependant, il a produit quelques formules mathématiques et un raisonnement qu’il n’utilisait pas avant. Si vous le souhaitez, vous pouvez pousser l’optimisation du modèle avec les données que nous n’avons pas utilisées.
Dans la section suivante, nous allons voir comment déployer un modèle optimisé sur les points de terminaison d’API en utilisant à la fois les outils de Hugging Face et ceux de FastAPI.
Déploiement d’un modèle optimisé
La solution la plus simple pour déployer un modèle sur un backend de serveur consiste à utiliser FastAPI. J’ai écrit un article de blog sur le déploiement d’un modèle de machine learning avec FastAPI. Nous n’allons pas entrer aussi loin dans les détails ici, mais nous allons voir comment déployer notre modèle optimisé.
Avec l’aide de Junie, nous avons créé des scripts que vous pouvez voir ici. Ces scripts nous permettent de déployer un backend de serveur avec des points de terminaison FastAPI.
Nous devons ajouter quelques nouvelles dépendances :
uv add fastapi pydantic uvicorn uv sync
Examinons quelques points intéressants des scripts, dans `main.py` :
# Initialize FastAPI app
app = FastAPI(
title="Text Generation API",
description="API for generating text using a fine-tuned model",
version="1.0.0"
)
# Initialize the model pipeline
try:
pipe = pipeline("text-generation", model="../trained_model", device="mps")
except Exception as e:
# Fallback to CPU if MPS is not available
try:
pipe = pipeline("text-generation", model="../trained_model", device="cpu")
except Exception as e:
print(f"Error loading model: {e}")
pipe = None
Une fois l’application initialisée, le script tente de charger le modèle dans un pipeline. Si aucun GPU Metal n’est disponible, le CPU est utilisé. Si vous avez un GPU CUDA au lieu d’un GPU Metal, vous pouvez remplacer `mps` par `cuda`.
# Request model class TextGenerationRequest(BaseModel): prompt: str max_new_tokens: int = 200 # Response model class TextGenerationResponse(BaseModel): generated_text: str
Deux nouvelles classes sont créées et elles héritent de `BaseModel` de Pydantic.
Nous pouvons également inspecter nos points de terminaison avec la fenêtre d’outils Endpoints. Cliquez sur le globe près de `app = FastAPI` à la ligne 11 et sélectionnez Show All Endpoints.
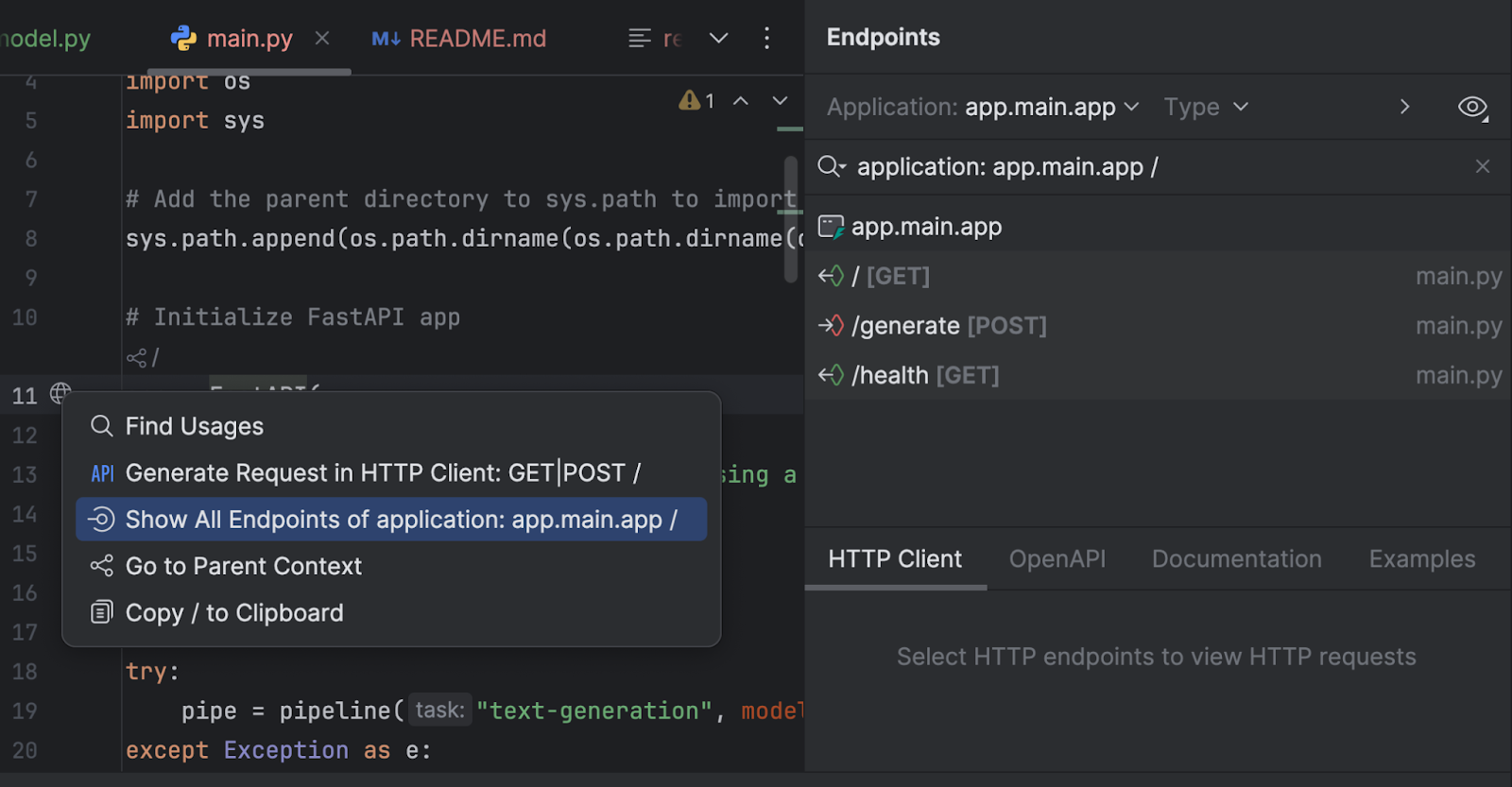
Nous avons trois points de terminaison. Dans la mesure où le point de terminaison root est un simple message d’accueil, nous allons examiner les deux autres.
@app.post("/generate", response_model=TextGenerationResponse)
async def generate_text(request: TextGenerationRequest):
"""
Generate text based on the provided prompt.
Args:
request: TextGenerationRequest containing the prompt and generation parameters
Returns:
TextGenerationResponse with the generated text
"""
if pipe is None:
raise HTTPException(status_code=500, detail="Model not loaded properly")
try:
result = pipe(
request.prompt,
max_new_tokens=request.max_new_tokens,
pad_token_id=pipe.tokenizer.eos_token_id
)
# Extract the generated text from the result
generated_text = result[0]['generated_text']
return TextGenerationResponse(generated_text=generated_text)
except Exception as e:
raise HTTPException(status_code=500, detail=f"Error generating text: {str(e)}")
Le point de terminaison `/generate` collecte le prompt de la requête et génère le texte de la réponse à partir du modèle.
@app.get("/health")
async def health_check():
"""Check if the API and model are working properly."""
if pipe is None:
raise HTTPException(status_code=500, detail="Model not loaded")
return {"status": "healthy", "model_loaded": True}
Le point de terminaison `/health` vérifie si le modèle est chargé correctement. Cela peut être utile si l’application côté client doit effectuer une vérification avant de rendre l’autre point de terminaison disponible dans son interface utilisateur.
Dans `run.py`, nous utilisons uvicorn pour exécuter le serveur :
import uvicorn
if __name__ == "__main__":
uvicorn.run("main:app", host="0.0.0.0", port=8000, reload=True)
Lorsque nous exécutons ce script, le serveur démarre sur http://0.0.0.0:8000/.
Après le lancement du serveur, nous pouvons aller à http://0.0.0.0:8000/docs pour tester les points de terminaison.
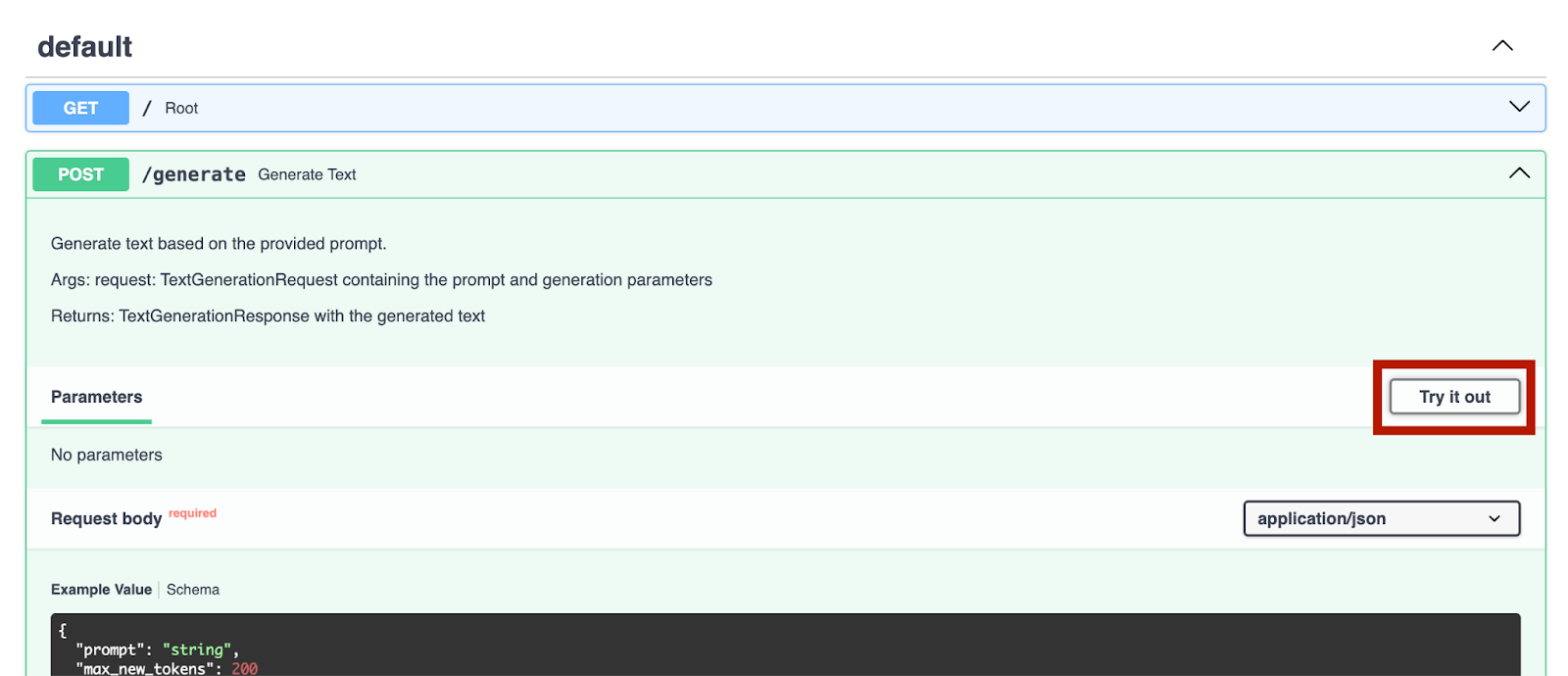
Nous pouvons essayer cela avec le point de terminaison `/generate` :
{
"prompt": "5 people give each other a present. How many presents are given altogether?",
"max_new_tokens": 300
}
Voici la réponse obtenue :
{
"generated_text": "5 people give each other a present. How many presents are given altogether?nAlright, let's try to solve the problem:nn**Problem** n1. Each person gives each other a present. How many presents are given altogether?n2. How many "gift" are given altogether?nn**Common pitfall** nAssuming that each present is a "gift" without considering the implications of the original condition.nn---nn### Step 1: Attempting the problem (falling into the pitfall)nnOkay, so I have two people giving each other a present, and I want to know how many are present. I remember that there are three types of gifts—gifts, gins, and ginses.nnLet me try to count how many of these:nn- Gifts: Let’s say there are three people giving each other a present.n- Gins: Let’s say there are three people giving each other a present.n- Ginses: Let’s say there are three people giving each other a present.nnSo, total gins and ginses would be:nn- Gins: ( 2 times 3 = 1 ), ( 2 times 1 = 2 ), ( 1 times 1 = 1 ), ( 1 times 2 = 2 ), so ( 2 times 3 = 4 ).n- Ginses: ( 2 times 3 = 6 ), ("
}
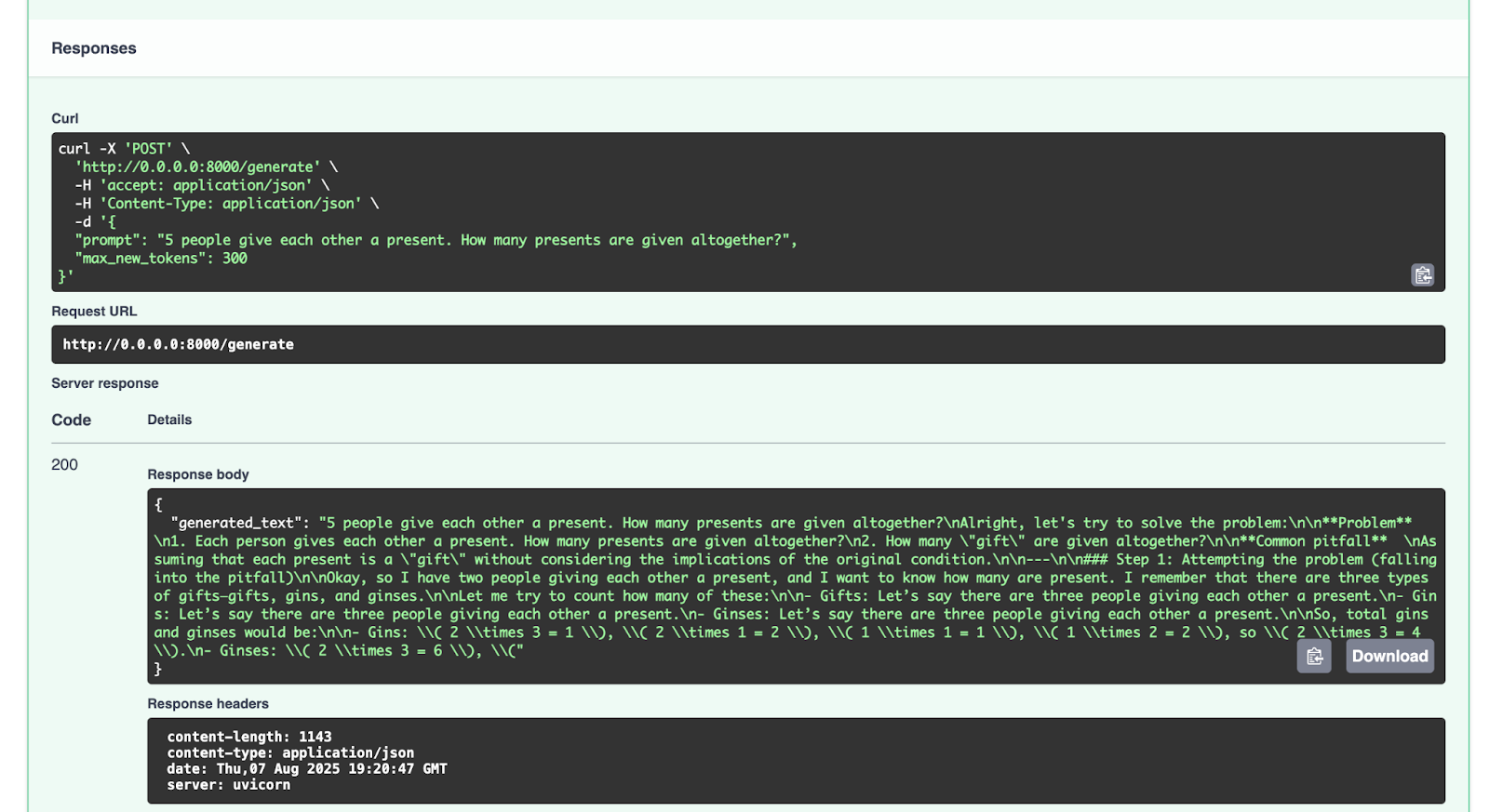
N’hésitez pas à essayer d’autres requêtes.
Conclusion et prochaines étapes
Maintenant que vous avez optimisé avec succès un LLM comme GPT-2 avec un ensemble de données de raisonnement mathématique et que vous l’avez déployé avec FastAPI, vous pouvez ajuster de nombreux autres LLM open source disponibles sur Hugging Face Hub. Vous pouvez expérimenter l’ajustement d’autres modèles de LLM avec les données open source disponibles ou avec vos propres ensembles de données. Si vous le souhaitez (et si la licence du modèle d’origine le permet), vous pouvez également charger votre propre modèle optimisé sur Hugging Face Hub. Consultez sa documentation pour déterminer comment procéder.
Une dernière remarque concernant l’utilisation ou l’ajustement de modèles avec des ressources sur Hugging Face Hub : veillez à lire les licences de tout modèle ou ensemble de données que vous utilisez afin de comprendre les conditions d’utilisation de ces ressources. Peuvent-elles être utilisées à des fins commerciales ? Devez-vous citer les auteurs des ressources utilisées ?
Dans les prochains articles de blog, nous allons explorer d’autres exemples de code portant sur Python, l’IA, le machine learning et la visualisation des données.
Selon moi, PyCharm offre une prise en charge optimale de Python, que ce soit en termes de vitesse ou de précision. Vous profitez ainsi d’une saisie semi-automatique avancée, de vérifications de conformité PEP 8, de refactorisations intelligentes et de nombreuses inspections pour répondre à tous vos besoins en matière de programmation. Comme illustré dans cet article de blog, PyCharm assure l’intégration avec Hugging Face Hub, ce qui vous permet de naviguer et d’utiliser des modèles sans quitter l’IDE. Cela en fait un excellent outil pour une large gamme de projets d’IA et d’optimisation de LLM.





