

Best Practices for Secure Error Handling in Go

When you’re new to Go, error handling is definitely a paradigm shift that you need to come to terms with. Unlike in other popular languages, in Go, errors are values, not exceptions. What this means for developers is that you can’t just hide from them – you have to handle errors explicitly and at the point of the call. That equals a lot of if err != nil { return err }. But more importantly for us now, since errors are values, they can also be passed around, inspected, and composed like any other variable. This opens the door to many security issues if you’re not careful.
This guide walks you through best practices for secure error handling in Go. We’ll look at the reasons why it’s so important, how it affects security, and how to securely create, wrap, propagate, contain, and log errors. We’ll also provide a checklist on how to handle specific Go errors securely.
Bear in mind that this is an article on the security aspect of error handling in Go, so it focuses on best practices and user-facing messages. If you’re looking for a primer on general error handling mechanics in Go, check out our exhaustive How to Handle Errors in Go tutorial.
Why does secure error handling matter in Go?
To be precise, secure error handling matters in all programming languages, but with Go, errors carry particular weight.
For one thing, Go services often run in highly security-sensitive and distributed environments. A lot of Go is used for writing APIs, cloud services, and microservices – types of infrastructure with significant potential for security breaches that carry severe consequences and, due to their distributed nature, can have a rippling effect.
On the other hand, as already hinted in the introduction, the error-handling paradigm in Go makes developers somewhat vulnerable to disclosing sensitive information, such as paths, SQL queries, credentials, identifiers, or stack traces. Meanwhile, if you look at typical guides on error handling in Go, they seem to overlook the critical security aspect of containing and sanitizing your errors. Instead, they will teach you how to be specific and explicit, so that errors can be logged properly and debugged efficiently. But what happens if you expose these verbose errors to clients at runtime?
That’s how Go errors leak internal information
Errors in Go are values like any other, just with the error type. You decide what to do with that value, and so your program’s security depends entirely on how you create and expose errors.
If you fail to contain and sanitize them, you expose your app to a torrent of security issues, ranging from the disclosure of personally identifiable data to enumeration attacks. Take the recent example of CVE-2025-7445, a vulnerability in Kubernetes that allowed actors with access to the secrets-store-sync-controller logs to observe service account tokens in specific error-marshalling scenarios.
This shows that error handling in Go requires caution and sound design choices. But when done right, it pays off with improved API safety, clean logs, and better resistance to hacks.
Secure patterns for error creation and wrapping in Go
Now that we’ve covered why secure error handling is so important, let’s see how to design errors in Go without exposing sensitive information.
To have secure code, you need to treat errors as data objects that require sanitization. But to have practical code, you need enough information to debug it when problems arise. By adhering to the following three principles, you can achieve both.
Split brain (but a good one)
The most effective way to prevent accidental information leaks is to formalize the distinction between what the system sees and what the user sees. Relying on ad-hoc string manipulation at the level of HTTP handlers? I think you’ll agree that approach is prone to human error. So, instead, you need to define a custom error type that enforces this separation at the compile level.
It can look something like this: You create a struct that encapsulates both the Internal (unsafe) and the Public (safe) message.
package secure
// SafeError implements the error interface but keeps secrets internal.
type SafeError struct {
// Machine-readable code for clients (e.g., "RESOURCE_NOT_FOUND")
Code string
// Human-readable message safe for public consumption
UserMsg string
// The raw, upstream error (DO NOT expose this via API)
Internal error
// Context map for structured logging (sanitized)
Metadata map[string]string
}
// Error satisfies the stdlib interface.
// CRITICAL: This returns the SAFE message, not the internal one.
// This prevents accidental leaks if the error is printed directly to an HTTP response.
func (e *SafeError) Error() string {
return e.UserMsg
}
// LogString returns the detailed string for your SRE team.
func (e *SafeError) LogString() string {
return fmt.Sprintf("Code: %s | Msg: %s | Cause: %v | Meta: %v",
e.Code, e.UserMsg, e.Internal, e.Metadata)
}
You can check out this Go error library by Cockroach Labs to see a real-life implementation of this principle and read an interesting article on how they approach logging and error redaction for additional inspiration.
Why is this more secure?
Let’s say a developer accidentally passes the above error to http.Error(w, err.Error(), 500). The user will only see the sanitized UserMsg, but the sensitive SQL syntax error or upstream timeout token will remain hidden inside the struct. They’re accessible through the LogString() method used by your logging middleware.
Contextual sanitization
Errors rarely happen in a vacuum, so you need context (variables, IDs, inputs) to debug. But blindly adding context is how sensitive data leaks into the logs.
This is what you don’t do:
// DANGEROUS: Logging raw input structures
if err != nil {
return fmt.Errorf("login failed for request %v: %w", authRequest, err)
}
// If authRequest contains a 'Password' field, you just wrote it to disk.
And this is what you do instead – use a builder pattern or helper function that explicitly allows lists of safe metadata fields:
func NewAuthFailed(public string, internal error, safeMeta map[string]string) *SafeError {
return &SafeError{
Code: "AUTH_FAILED",
UserMsg: public,
Internal: internal,
Metadata: safeMeta,
}
}
// Usage:
if err != nil {
return NewAuthFailed(
"Invalid credentials.",
err,
map[string]string{
"username": req.Username,
"ip_addr": req.RemoteIP,
"attempt_id": GenerateRequestID(),
},
)
}
Why is this more secure?
By using an explicit builder pattern or helper function, you force yourself to inspect everything and choose what gets logged rather than defaulting to “everything”.
Opaque wrapping
Standard wrapping using fmt.Errorf("... %w", err) creates a chain. While excellent for debugging, this allows errors.Is and errors.As (from version 1.26 errors.AsType as well) to traverse down to the root cause. In high-security contexts, you may want to prevent the caller from introspecting the underlying library entirely.
For that, you wrap the error in a way that captures the stack trace and context, but breaks the dependency chain for the caller.
func GetUserProfile(id string) (*Profile, error) {
// Imagine this returns a specific database error containing table names
// e.g., "pq: relation 'users_v2' does not exist"
user, err := db.QueryUser(id)
if err != nil {
// BAD: returns raw DB error.
// return nil, err
// BAD: wraps, but exposes the underlying type via Unwrap().
// return nil, fmt.Errorf("db error: %w", err)
// GOOD: Opaque wrapping.
// We log the raw error here or wrap it in a type that doesn't
// expose the cause via Unwrap() to the external world.
return nil, &SafeError{
Code: "FETCH_ERROR",
UserMsg: "Unable to retrieve user profile.",
Internal: err, // Stored for logs, hidden from Unwrap logic if needed
}
}
return user, nil
}
Why is this more secure?
By explicitly controlling how your custom error type implements (or doesn’t implement) Unwrap(), you act as a firewall. You ensure that a vulnerability in a third-party XML parser or SQL driver cannot be introspected or triggered by a malicious user manipulating inputs to check for specific error types.
Safe error propagation
Go is one of the most popular choices for distributed systems, like microservices, cloud functions, and APIs. In an environment like that, an error is not just a local event – it usually bubbles up somewhere upstream.
One of the most dangerous “security” habits in Go is letting errors bubble up unfiltered. Like when an error originating in the database layer is returned up the stack, function by function, until it’s serialized directly to the user’s screen. Then, instead of a simple File not found, unauthorized actors get access to your internal architecture – file paths, library versions, IP addresses, and schema details.
That’s why when working with distributed architectures, proper error containment is a top priority for security. Depending on which trust boundary the data crosses, we can distinguish three distinct levels of containment and patterns to deal with it.
Crossing subsystem boundaries
Sanitize your data when it crosses subsystem boundaries, like when it moves from a data access layer (DAL) to a business logic layer (BLL). If your database fails, the BLL doesn’t need to know why it happened, only that it did. Wrap the raw error in a domain-specific one, for example:
- Raw:
pq: duplicate key value violates unique constraint "users_email_key" - Sanitized:
domain.ErrDuplicateUser(wrapping the raw cause)
Otherwise, you’re risking leaking implementation details, such as revealing that you’re using PostgreSQL rather than MongoDB.
Crossing API boundaries
Translate your error in service-to-service communication, like billing calling your auth service. Convert Go error types into standardized protocol errors (gRPC status codes or standard JSON error responses). The upstream service only needs to know how to react, not which line of code broke.
Not translating errors can result in cascading failures and risks exposing stack traces to other services that don’t need to know the ins and outs of your code.
// BillingService → AuthService call
resp, err := s.auth.ValidateToken(ctx, token)
if err != nil {
var authErr *secure.SafeError
if errors.As(err, &authErr) {
// Translate domain error → protocol
return nil, &secure.SafeError{
Code: "AUTH_UNAVAILABLE",
UserMsg: "Authentication service is temporarily unavailable.",
Internal: err, // keep original cause for logs
Metadata: map[string]string{"svc": "auth"},
}
}
// Unknown error → generic translation
return nil, &secure.SafeError{
Code: "INTERNAL",
UserMsg: "Internal service error.",
Internal: err,
}
}
Crossing public boundaries
Wrap your errors in generic messages when crossing public boundaries, like from your public API gateway to the end user. They should never see a generated error message, only a static, pre-defined string or code (like Service temporarily unavailable. Request ID: abc-123, not Connection timeout to redis-cluster-01 at 10.0.1.5:6379). Otherwise, you risk giving attackers hints for SQL injection, path traversal, or denial of service (DoS) attacks.
// Handler serves the HTTP request
func (s *Server) HandleCreateOrder(w http.ResponseWriter, r *http.Request) {
// 1. Execute Logic
// Errors bubble up, containing stack traces and SQL details
err := s.orders.Create(r.Context(), reqBody)
if err != nil {
// 2. Log the "Truth"
// We log the FULL internal error for the security/dev team
s.logger.Error("failed to create order", "error", err, "stack", stack.Trace(err))
// 3. Contain and Translate for the User
// We never just write 'err.Error()' to the response writer.
translateAndRespond(w, err)
return
}
w.WriteHeader(http.StatusCreated)
}
func translateAndRespond(w http.ResponseWriter, err error) {
var status int
var publicMsg string
// We inspect the error type or sentinel value to decide the "Public Face" of the error
switch {
case errors.Is(err, domain.ErrInvalidInput):
status = http.StatusBadRequest
publicMsg = "The provided order details are invalid."
case errors.Is(err, domain.ErrConflict):
status = http.StatusConflict
publicMsg = "This order has already been processed."
case errors.Is(err, context.DeadlineExceeded):
status = http.StatusGatewayTimeout
publicMsg = "The request timed out."
default:
// CATCH-ALL: The most important security catch.
// If we don't recognize the error, we assume it's sensitive internal state.
status = http.StatusInternalServerError
publicMsg = "An internal error occurred. Please contact support."
}
http.Error(w, publicMsg, status)
}
Logging errors without leaking sensitive data
Even internal logs should be sanitized in anticipation of a possible leak. You should move from the mindset of “logging everything” to only “logging safe context that’s needed.” Here are some key rules when it comes to logging errors securely:
1. Use structured logging
Stop using fmt.Printf or string concatenation. Use a structured logger (like Go’s standard log/slog or libraries like zap and zerolog). Structured logging treats log parameters as typed data, not raw strings. This significantly reduces the risk of log injection attacks because the logger handles the escaping of special characters.
2. Sanitize before logging
Never log a struct directly unless you have verified it contains no personal data. Instead, use a pattern where you explicitly map only the fields required for debugging (see the Contextual sanitization section above).
3. Redact at middleware
For data that must be logged but contains sensitive parts (like a full HTTP request for debugging), implement a Redactor interface.
type Redactor interface {
Redact() any
}
type LoginRequest struct {
Username string
Password string
}
func (r LoginRequest) Redact() any {
return struct {
Username string `json:"username"`
Password string `json:"password"`
}{
Username: r.Username,
Password: "***REDACTED***",
}
}
// logger usage:
logger.Info("login attempt", "req", req.Redact())
func LogRequest(r *http.Request) {
// Basic scrubbing of common sensitive headers
safeHeaders := r.Header.Clone()
safeHeaders.Del("Authorization")
safeHeaders.Del("Cookie")
slog.Info("incoming request",
slog.String("path", r.URL.Path),
slog.Any("headers", safeHeaders), // Safe to log now
)
}
4. Check everything
Security relies on consistency, but we humans are notoriously inconsistent. Use your IDE to catch the insecure logging patterns before they compile. Some features that are helpful for secure error handling in GoLand are:
- Printf validation: GoLand detects if the arguments passed to a formatting function don’t match the verbs, reducing the risk of accidental data leaks through malformed strings.
- Taint analysis: Through data flow analysis, GoLand can track variables from untrusted sources (like HTTP bodies) and warn you if they are being used in dangerous sinks (like raw string concatenation in logs) without sanitization.
Time to check your codebase
If you feel like any of these golden rules are news to you, maybe it’s time to do a security audit of your codebase. To make it easier for you, here’s a checklist of some questions that you may ask yourself about how your application handles errors with best practices for different scenarios.
Security audit checklist
| Question | If yes → use | If no → then |
| Is the caller external or untrusted? | Translate error to generic response | Propagate/wrap internally |
| Does the error contain sensitive data? | Redact and sanitize before logging | Log normally (structured) |
| Did the error come from an upstream service or library? | Wrap and sanitize | Propagate internally |
| Will the error cross a trust boundary (API/gateway)? | Replace with a safe message | Keep internal context |
| Is the error caused by malformed or unsafe input? | Fail fast and stop processing | Validate and continue |
| Is this a recoverable business error? | Return a safe user-facing message | Consider fail-fast behavior |
| Is the system in an inconsistent or corrupted state? | Fail secure (panic and recover safely) | Continue only if certain that the system is not corrupted |
| Does the error need to be logged? | Log sanitized version | Avoid logging unnecessary details |
| Will developers need internal details for debugging? | Store internal details in logs only | Keep client response generic |
| Is the error part of a recurring security pattern (auth/permission)? | Use standard codes/responses | Avoid making new response formats |
Frequently asked questions
Can I return err.Error() directly to API clients?
No. err.Error() is designed for debugging by developers. It can leak implementation and structure information to hackers.
What is the safest way to return errors in Go APIs?
You should return structured, sanitized protocol errors that provide just enough information for the client to react, while keeping technical details hidden.
How do I prevent Go errors from leaking sensitive information?
First and foremost, decouple system information from user-facing messaging and never provide raw errors to end users. Know when data crosses boundaries and only provide as much context as needed to resolve the issue. If sensitive data must be logged, redact it.
How can Go services safely log errors without exposing secrets?
Shift your mindset from “log everything” to “sanitize everything”. You should make sure that your logs are rich enough to debug issues, but sterile enough that the system and users won’t be compromised if leaked.
What is the difference between propagating and translating errors in Go?
When you propagate an error, you run it up the call stack (usually wrapped in context with %w). This preserves the details and stack trace for easier debugging.
Translating an error means catching and replacing it with a different, domain-specific error (like swapping an sql.ErrNoRows for a UserNotFound) to hide implementation details from the caller.
A good rule of thumb for security is propagating errors internally between subsystems and translating them at the API boundary to prevent leaks.
When should a Go application fail fast for security reasons?
An app should fail fast for security reasons if it detects conditions that compromise trust, integrity, or confidentiality. Some scenarios where this might be applicable are: authentication failure, insecure input (like known SQL injection patterns), resource exhaustion (early sign of DoS attack) – fail fast, don’t panic; integrity check failure or tampered configuration – panic.
How do you design secure user-facing error messages in Go?
Use a custom error type that holds both private error details and safe public messages. Only return public messages to the client. Make sure they are generic, opaque, and standardized. Never provide specific technical details and only provide safe context to the extent that it’s necessary for tracing.
How should upstream service or database errors be handled securely in Go?
Upstream service and database errors must be handled securely by containing and translating them at the service boundary to prevent information leakage.
Containment means that raw errors should not be propagated across service or API trust boundaries. Translation means that raw errors should be mapped to generic, domain-specific errors defined in the service.
What are common security mistakes in Go error handling?
Most security mistakes when it comes to error handling in Go boil down to over-exposure of internal details. Common mistakes include:
- Propagation of raw errors across trust boundaries.
- Accidentally logging secrets.
- Exposing raw stack traces or verbose internal error messages to end users.
- Relying on a generic handler that returns
err.Error(), instead of custom error types.
How can GoLand help detect insecure error patterns?
GoLand can help you detect insecure error patterns primarily through static code analysis (inspections) and data flow analysis. Here are some key detection features you might be interested in:
- Detection of unhandled errors: GoLand automatically flags functions that return an
errorbut have been called without checking it.
Proceeding with an operation when a check has failed (or didn’t occur at all) might result in an authentication bypass – the program serving sensitive data to an unauthenticated user.
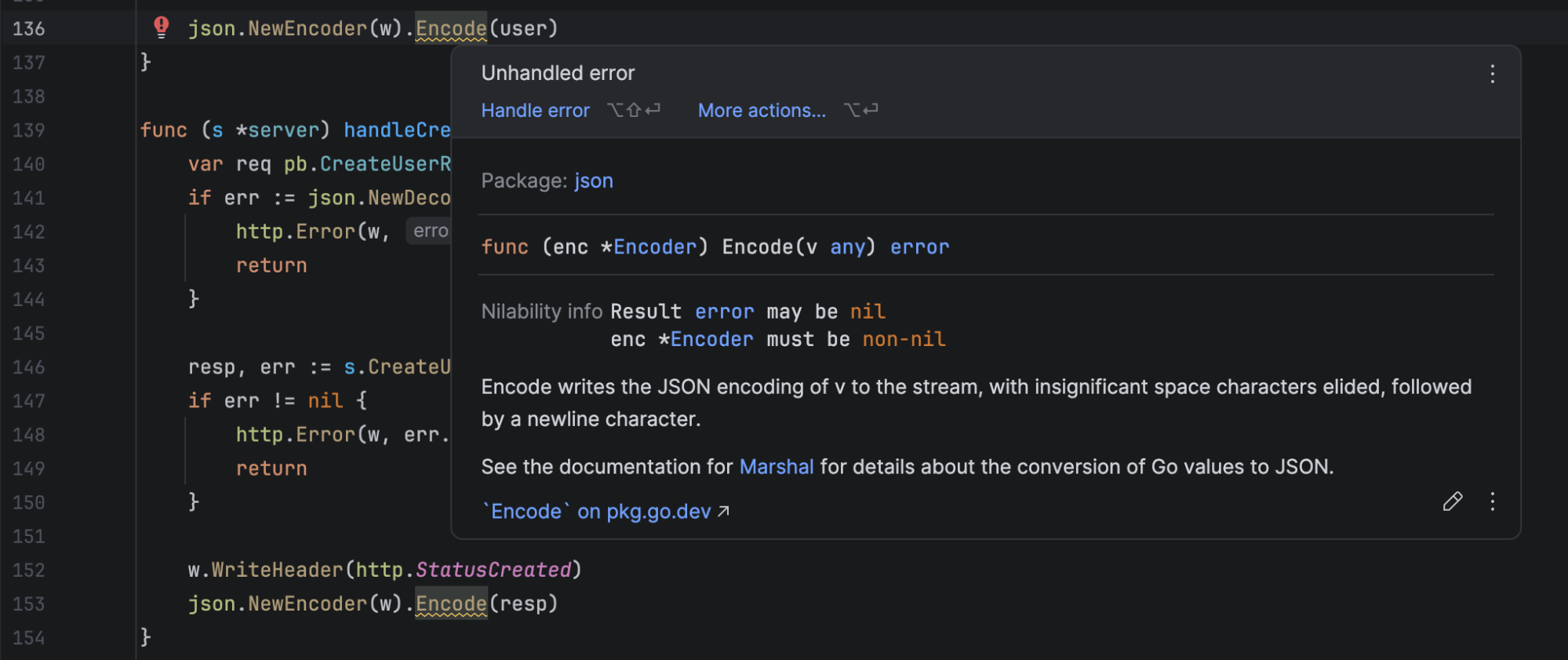
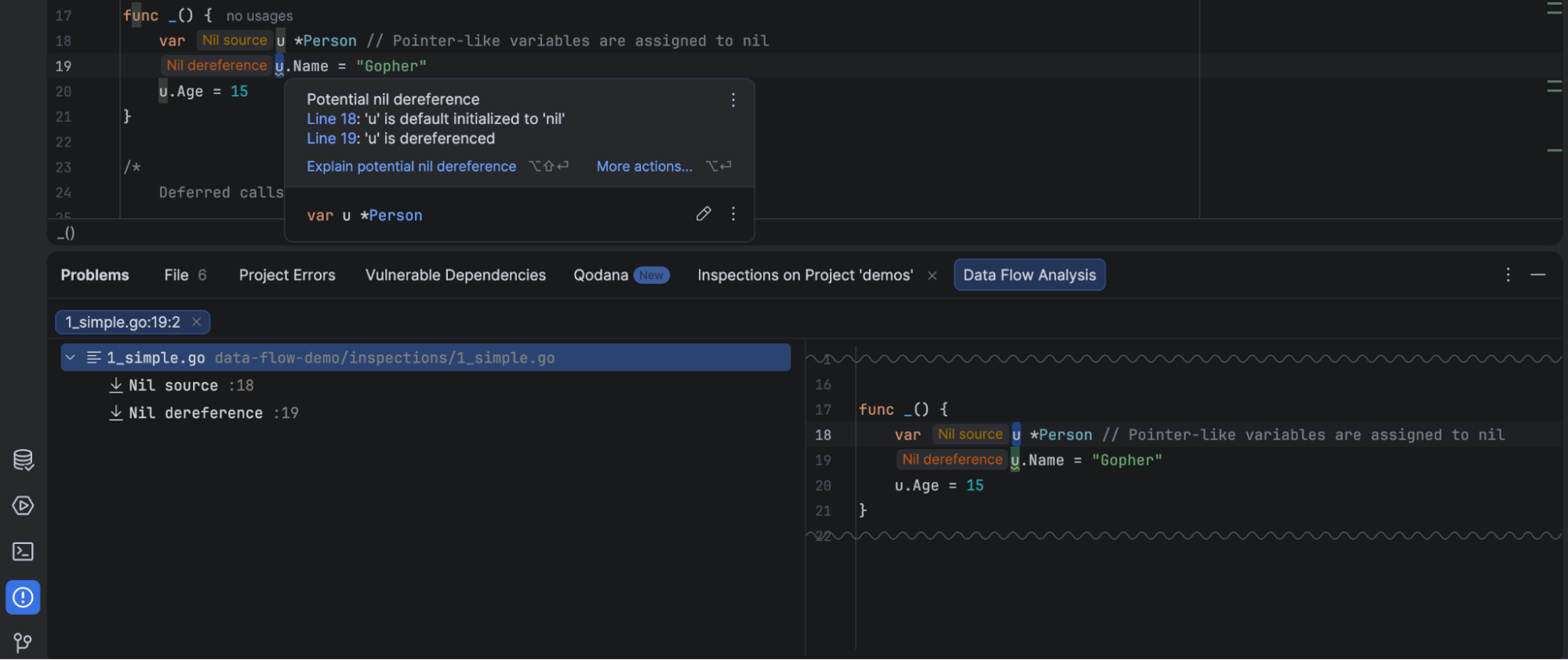
- Detection of nil pointer deference and data flow analysis: GoLand tracks how
nilvalues move across functions and files to warn you about a potentialnilvariable. It also reports instances where variables might havenilor an unexpected value because an associated error was not checked for being non-nil.
Uncheckednilvariables can cause a panic that results in an inconsistent state or be exploited in DoS attacks.
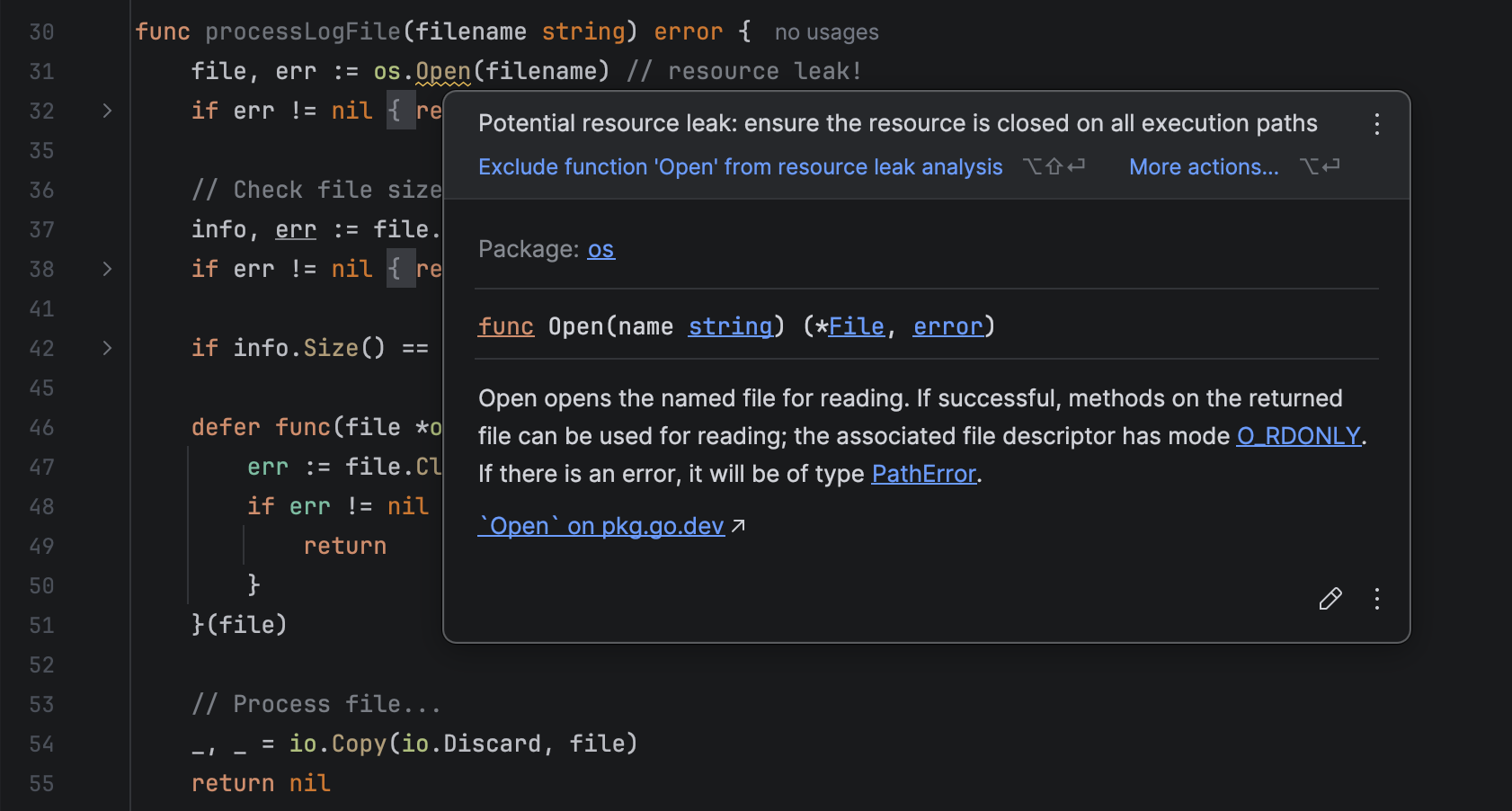
- Resource leak inspection: Resource leak analysis in GoLand analyzes your code locally to ensure that any object implementing
io.Closeris properly closed.
Resource leaks pose a security threat because, when exploited, they are a gateway for DoS attacks.
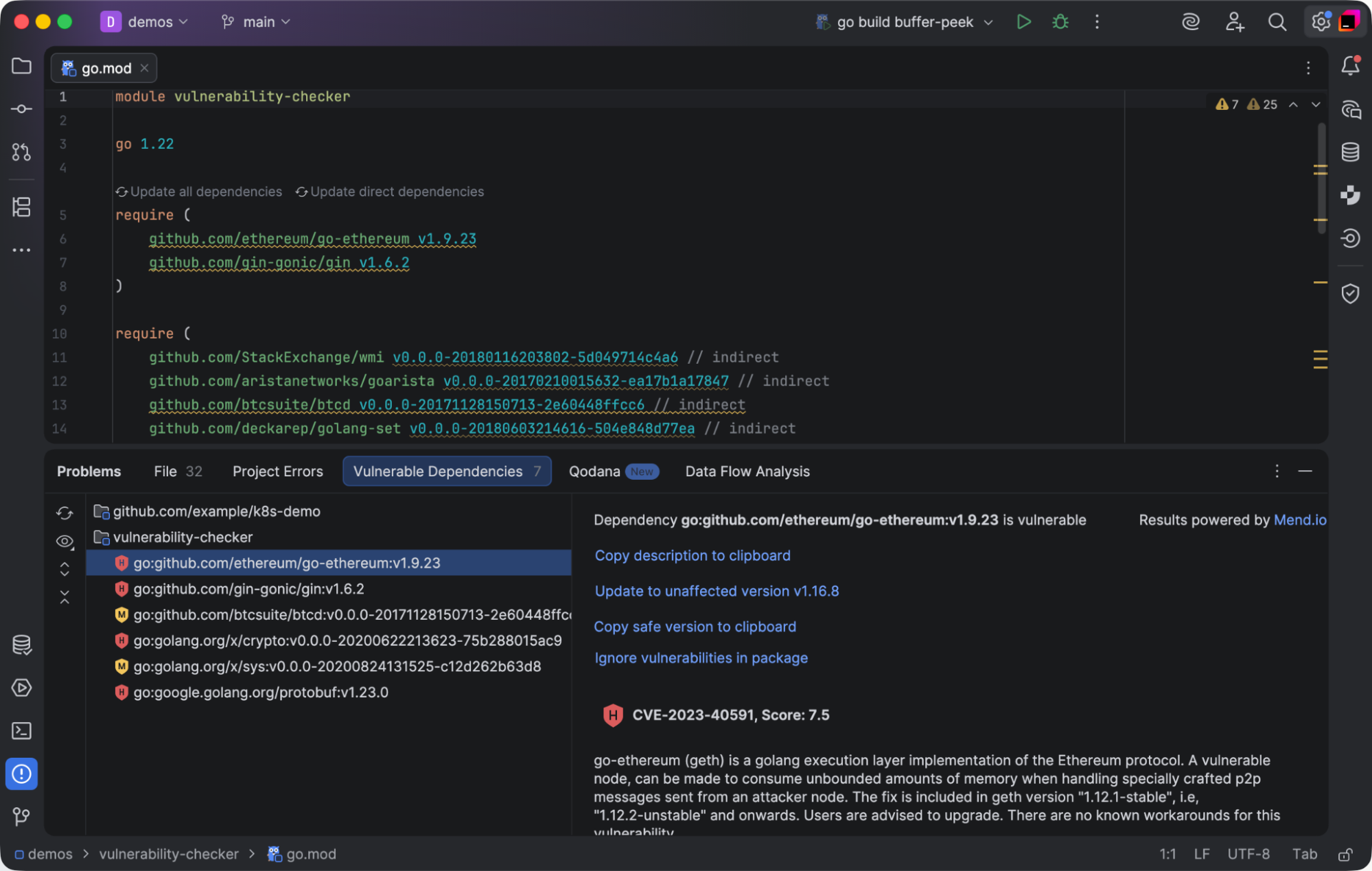
- Package Checker: This plugin analyzes third-party dependencies for known vulnerabilities and updates them to the latest released version.
This protects you from known exploits and helps you remain compliant with regulatory requirements.
- Type assertion on errors: GoLand reports type assertion or type switch on errors, for example,
err.(*MyErr)or switcherr.(type), and suggests usingerrors.Asinstead.
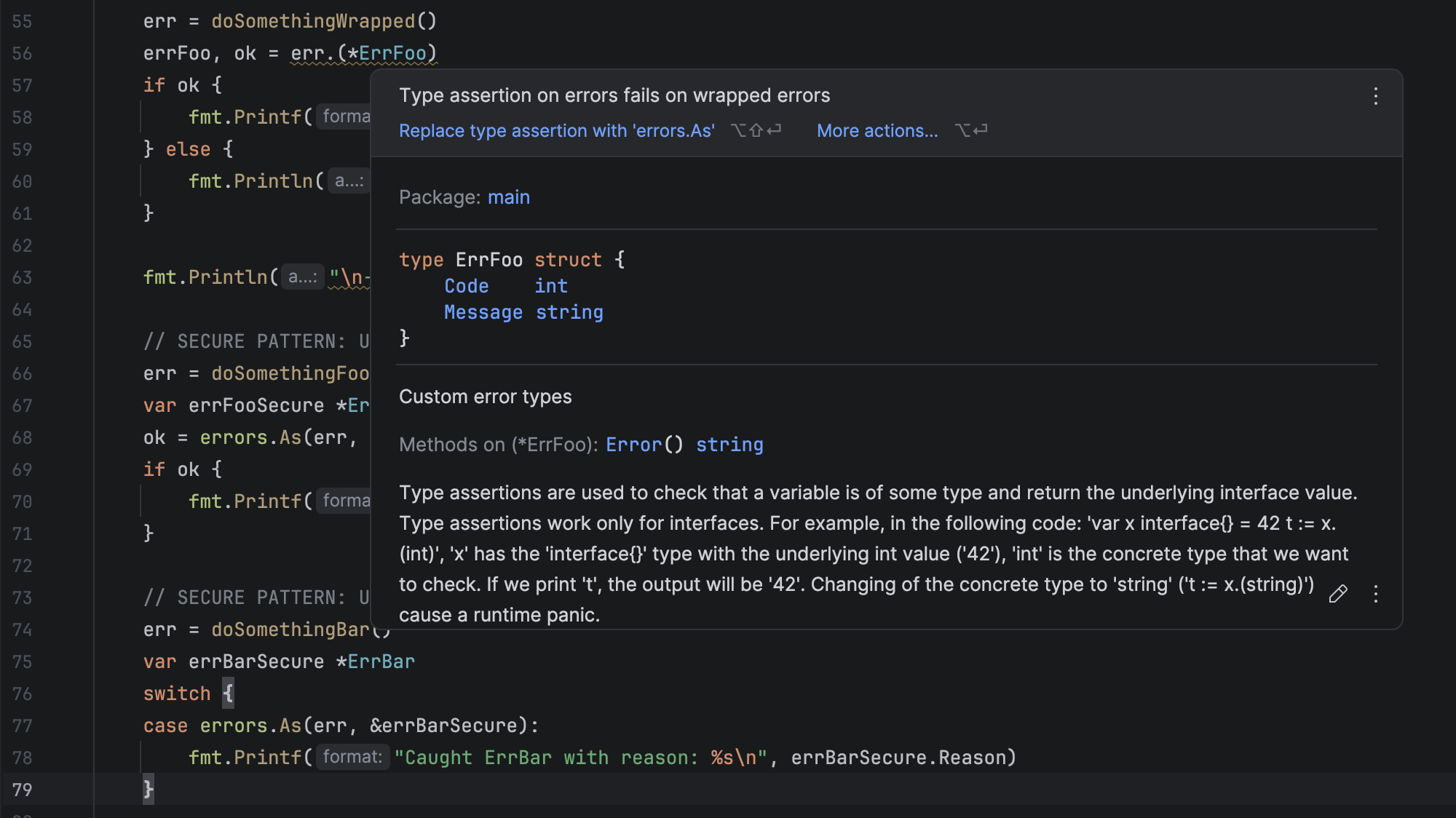
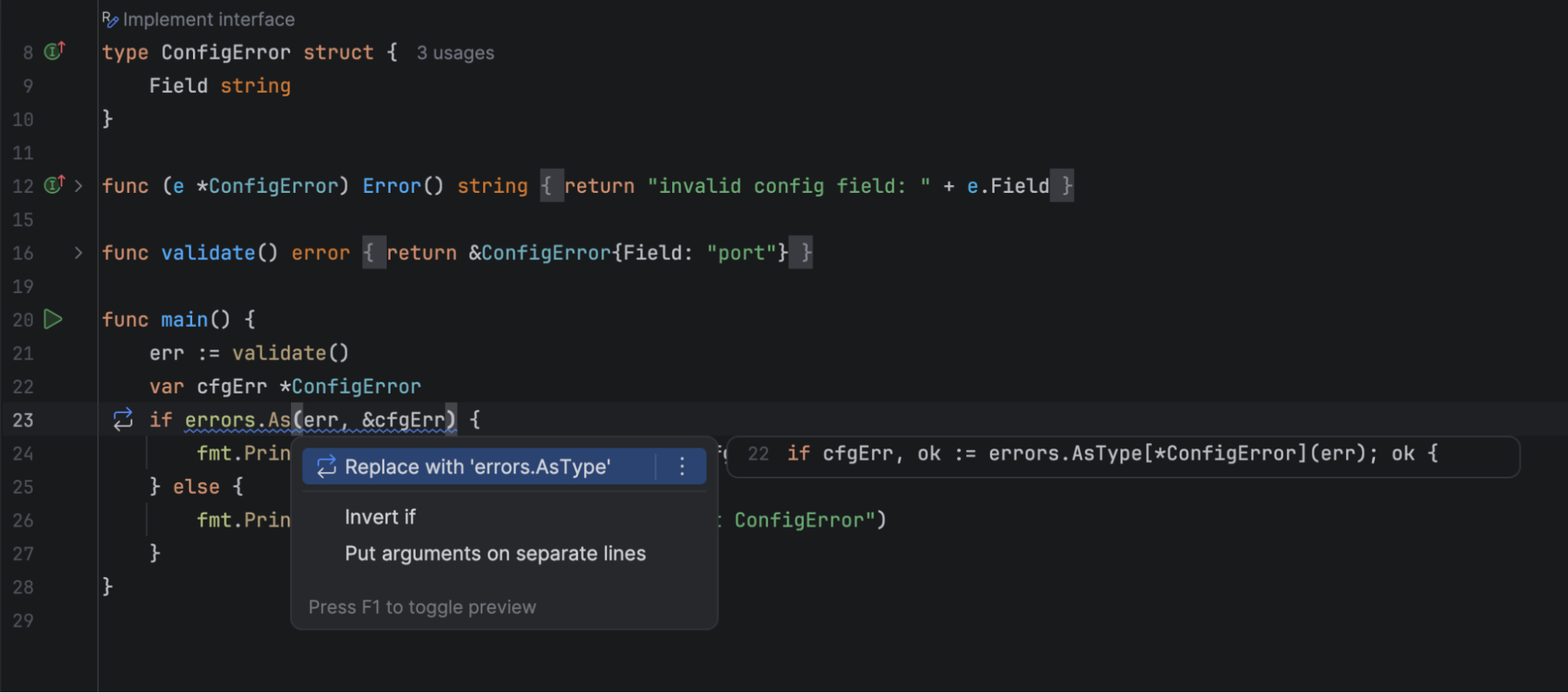
errors.AsType: After the introduction oferrors.AsTypein Go 1.26, GoLand reports usages oferrors.Asthat can be replaced with this generic function that unwraps errors in a type-safe way and returns a typed result directly.
The GoLand team






