

IntelliJ IDEA
IntelliJ IDEA – the Leading IDE for Professional Development in Java and Kotlin
AWS, Serverless, Developer Experience, and More

Hooray!
Last week we had the pleasure of hosting a live webinar in partnership with AWS, presented by Mike Deck, Principal Solutions Architect at AWS. Mike gave a comprehensive overview of what serverless is all about and what the serverless developer experience feels like. Mike explained the AWS Serverless Application Model (AWS SAM) and how it integrates with IntelliJ IDEA to provide a rich development environment.
In case you missed the webinar, here’s the video recording:
If you prefer reading, please find below a detailed transcript of the webinar.
Building web services prior to the serverless paradigm
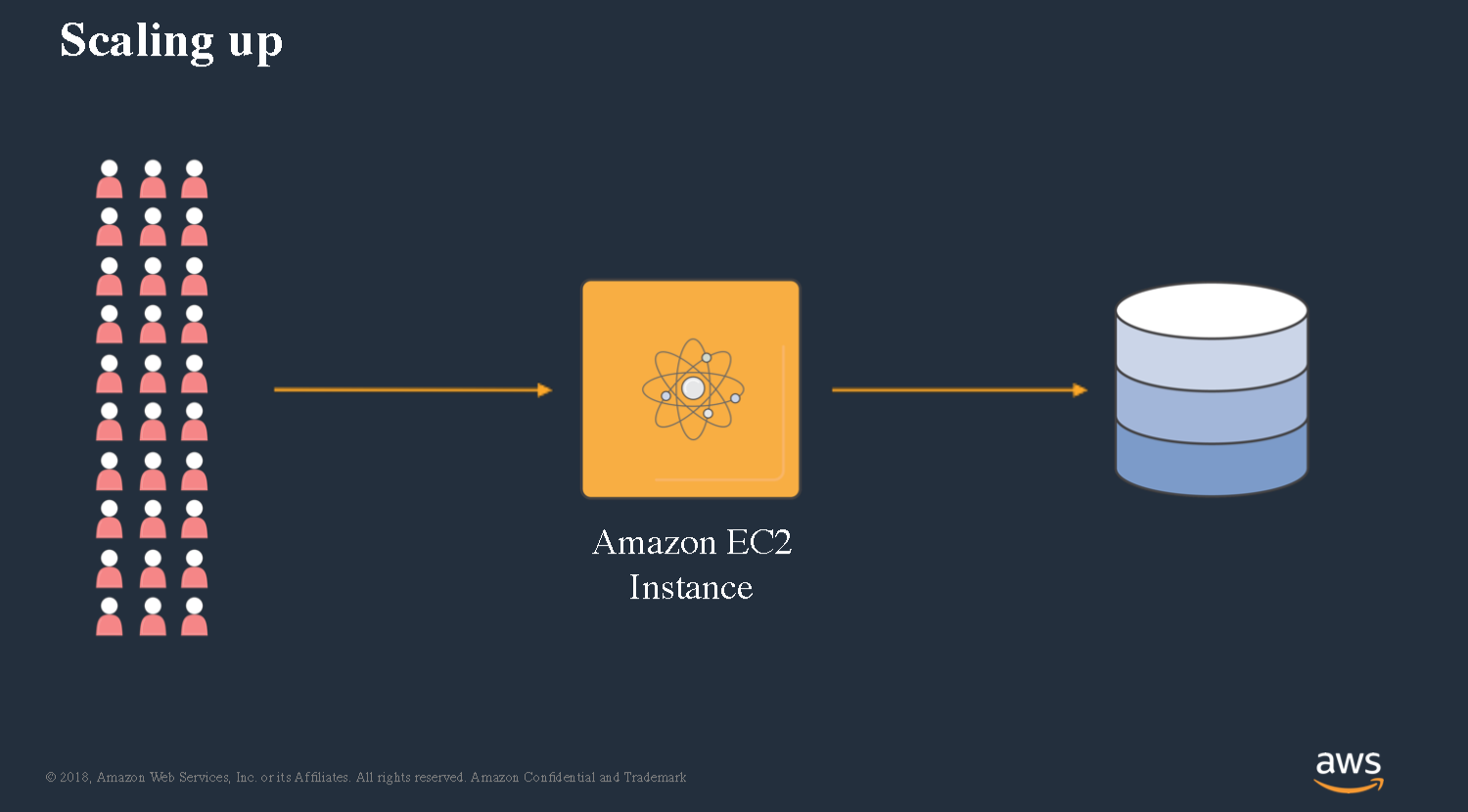
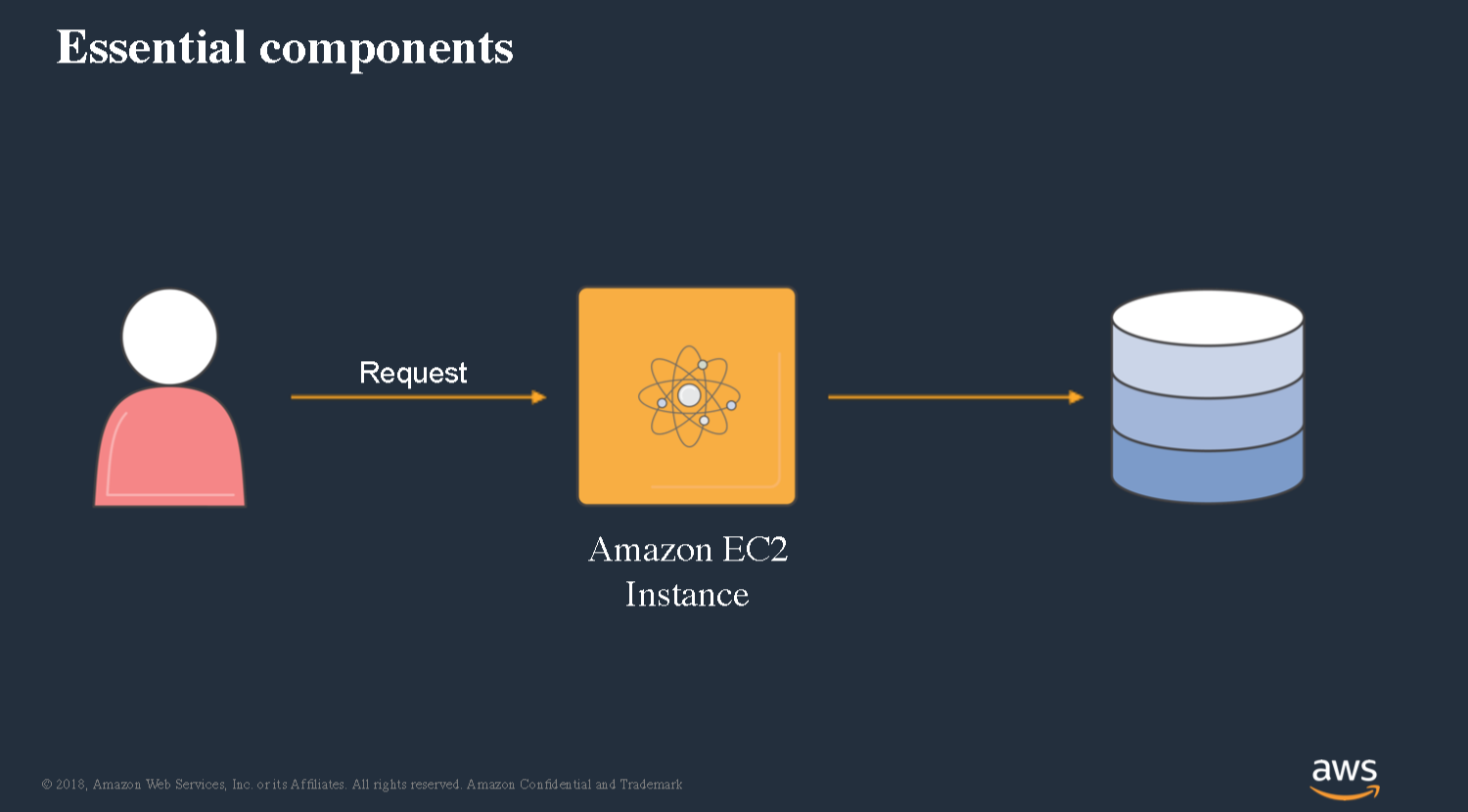
Let’s take a look at what does it take today to build a simple web service. We’ve got clients that are gonna send us HTTP requests and we’ve got to write some code to be able to fulfill this. I’m gonna write some code and in my framework of choice. I’m gonna deploy it out to an EC2 instance. I’ll probably have a database as well. It’s pretty simple and straightforward, I’m sure everyone has built something like this in the past.’
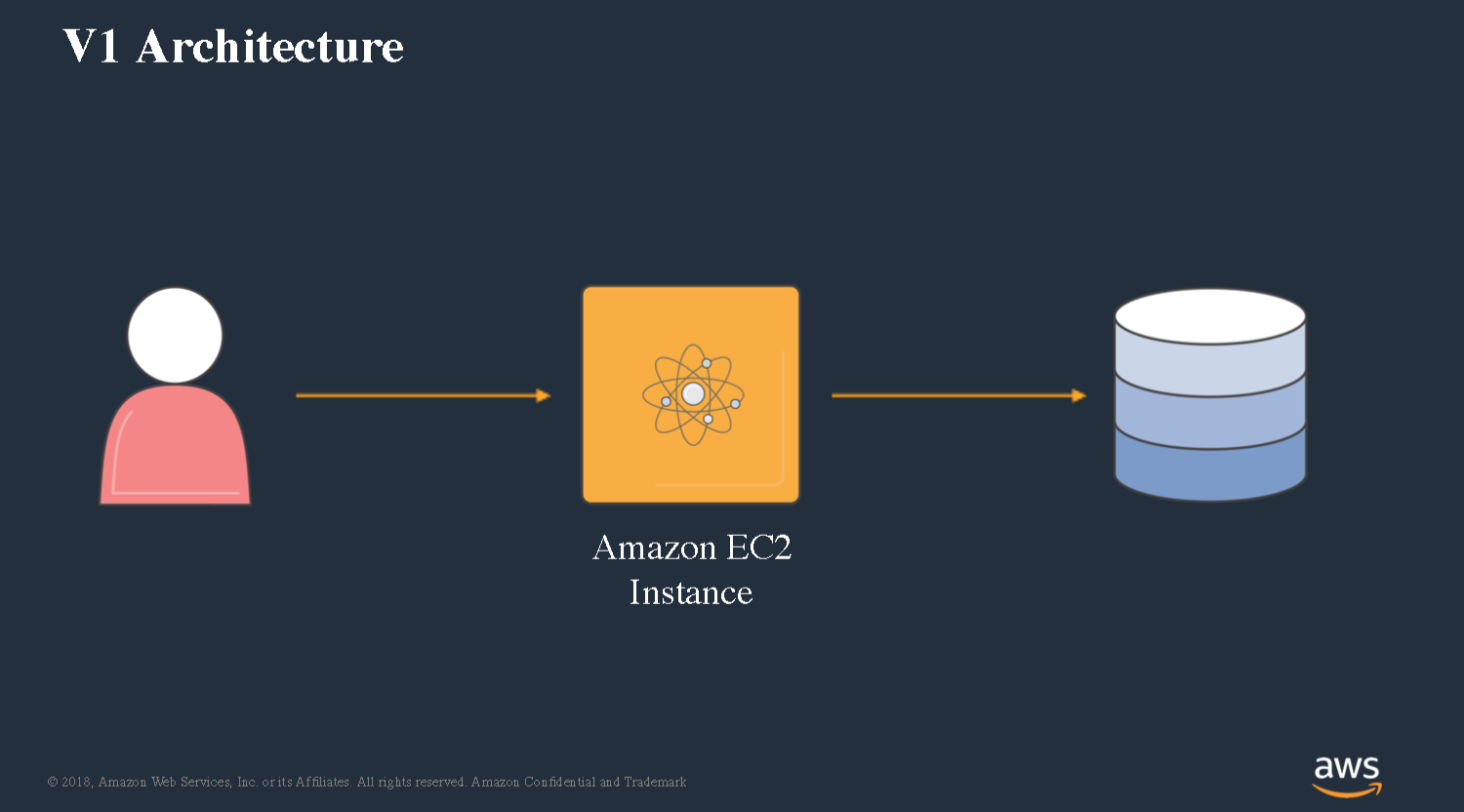
Then kind of the final step would be making this highly available.
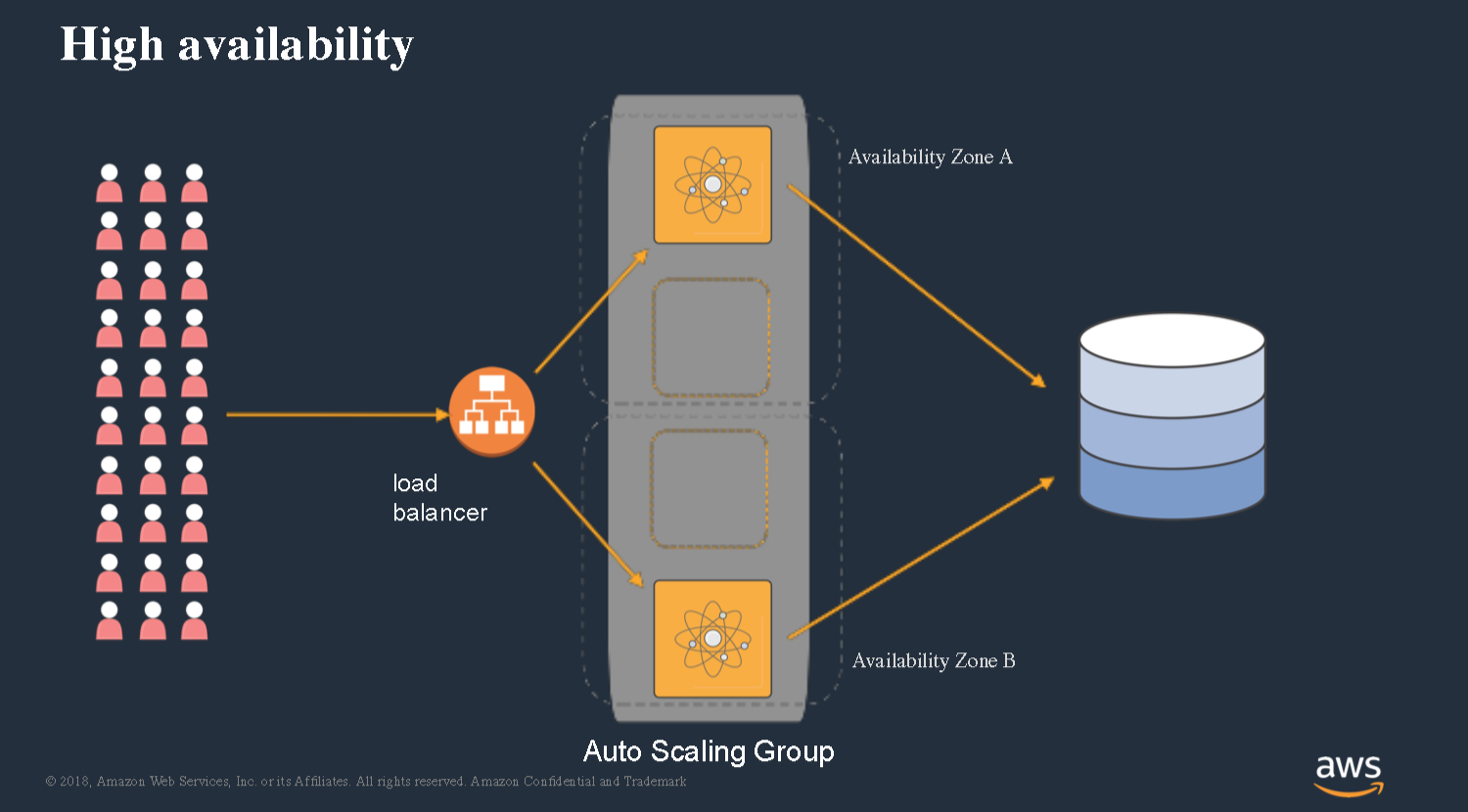
We can spread our instances across availability zones. You can configure that through auto scaling groups.
We end up with this architecture where we’ve got a load balancer, we’ve got auto scaling groups, we’ve got instances and we’ve got our database.
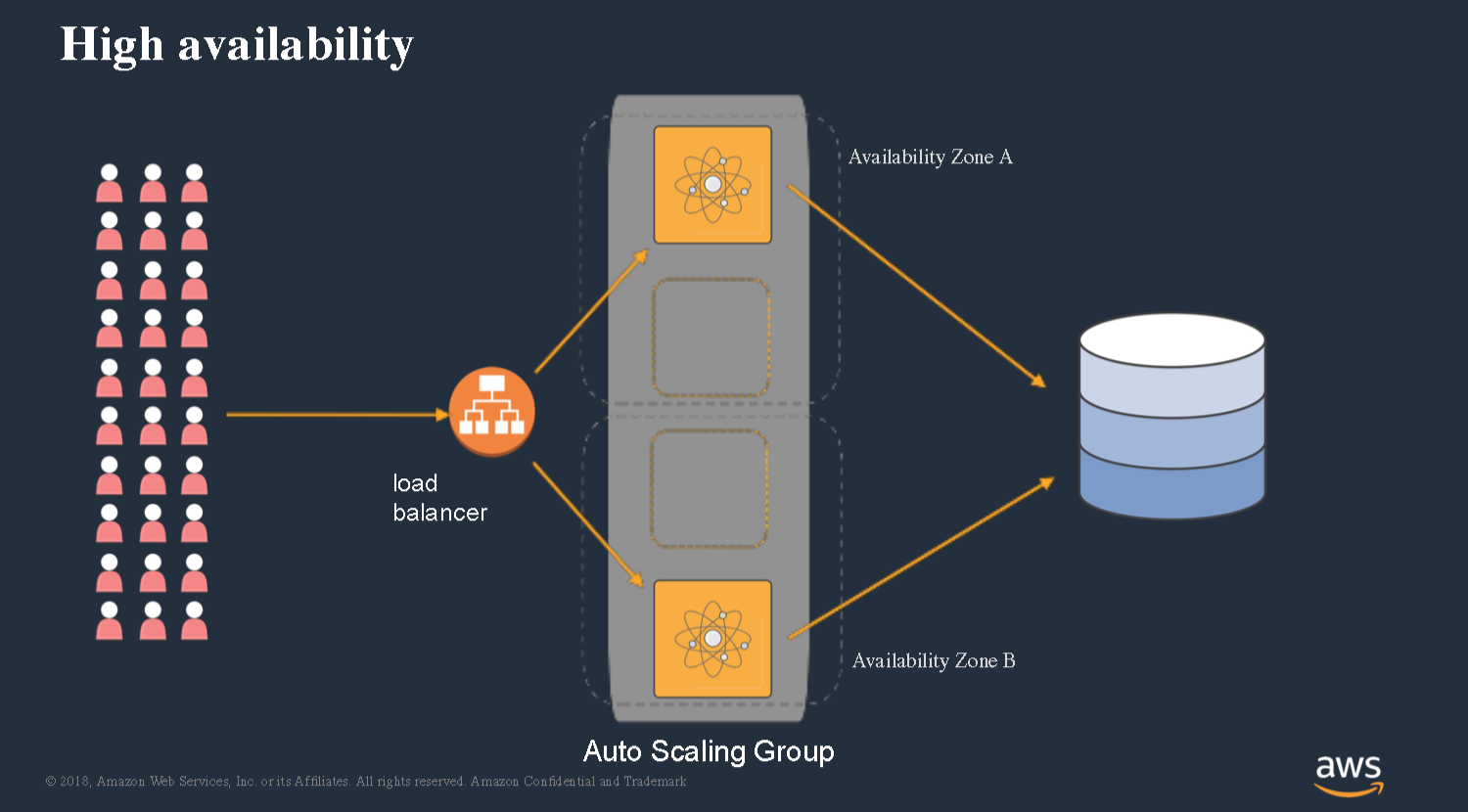
In addition to building the application that you really care about, there’s all of these other considerations you have to think about when designing this application and deploying it. You gotta figure out how are we gonna check the health of our nodes, how are we going to define the policies that decide when to scale out and scale in. We’ve got to deal with operating system and runtime patching and all of these other kind of things.
Serverless applications with AWS Lambda
First of all you’ve got an event. In our case this event is an HTTP request, but basically this is just something that happened in the world that we now need to be able to respond to. Additionally we have a back-end; in our case it was a database. The core of our
application is this code that’s kind of marrying those two pieces together.
This is the exact same kind of architecture that AWS Lambda uses.
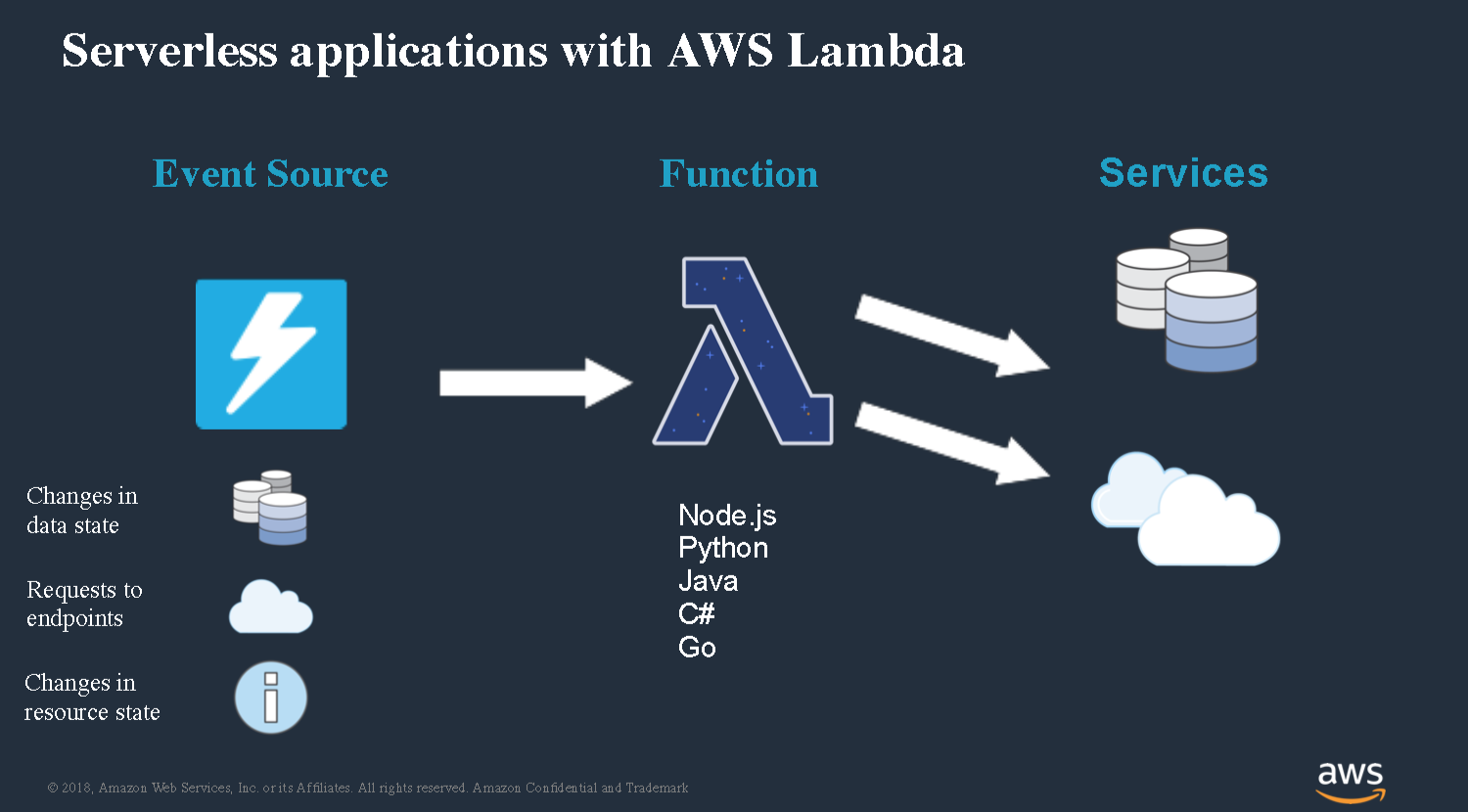
AWS Lambda is a service that allows you to run code in response to events and connect to any any different a broad variety of different back-end services. You can write code in a number of different languages and then hook that code up to a number of different event sources.
What serverless actually means
We’ve taken a look at Lambda specifically but I think it’s useful to really go in and define what we mean by service. So, service is kind of a buzzword; these days there’s a lot of
different people that talk about what it means and what it doesn’t mean. But when AWS says something is service, there’s really kind of four key characteristics that we’re really
talking about.

No server management
First of all there’s no servers to manage. The idea there is you never have to worry about provisioning or maintaining the actual underlying operating system itself, so you’re never gonna have to do operating system patching, you don’t have to worry about updating the version of the runtime or the JRE or what-have-you. All of that’s kind of taking care for you and you work at an abstraction layer that is above the concept of an individual server.
Flexible scaling
The next is flexible scaling. This idea is that you’re able to scale your application in
according to the units of work that are relevant to the workload itself. Instead of having to think about CPUs in memory and disk space and these kind of server base concepts, now you can think about things in terms of the total number of requests or the amount of time it takes you to serve a single request, and your application will scale in those terms. It’s going to scale completely automatically for you.
Automated high availability
When you’re using services like AWS Lambda, you don’t have to think about availability zones or configuring that. It is highly available out of the box and there’s really no way to turn that off.
No idle capacity
Finally is the concept of no idle capacity. This is really where you start seeing major cost savings from an infrastructure perspective when you move to a service architecture compared to a traditional server based one. Instead of having servers that are sitting around idle waiting for work to do all of that capacity is now shifted onto AWS and you only pay for the amount of compute time that you’re actually using. This means that you no longer have to think about sort of capacity planning in a traditional sense you don’t have to worry about monitoring CPU utilization and sort of planning for how are we going to manage the traffic that that were anticipating to our website or to our service.
Serverless development
Let’s talk a little bit about what it looks like to build service apps and to write
the code associated with that.
Console limitations (or why you need an IDE integration)
If anyone has kind of played around around with lambda before you probably have started off using the AWS management console to write write beat your first function. There’s a nice pretty text box right there that you can just enter code into you can write code you can run it you can deploy it all right there from the console. When you think about it that’s essentially an equivalent in the server based world to SSH into your production hosts editing some files on on the fraud server itself saving them and then bouncing the process. I don’t recommend using this model of development whether you’re doing server based or serverless development and instead you really need to think about moving into a different model so you know when you’re using the console there’s there are a lot of limitations. There’s no real kind of build automation mechanisms it’s difficult to manage environments in terms of having separate sort of dev tests and prod environments that you can easily deploy across there’s no integration with version control systems it’s difficult to collaborate with teammate.
Deployment
Let’s talk a little bit about how do we get code from our IDE out to AWS Lambda and how do we deploy it to AWS.
- First of all you got to build it you got to compile it into a JAR or whatever kind of build artifact do you need for your language then you zip that code up along with all of its dependencies upload that bundle to S3.
- Then you need to create or update an IAM role. This is what kind of gives lambda the security permissions it needs in order to to access other resources.
- Then you make a call to the create function API in the lambda in the lambda API.
- Then finally kind of set up any any events or event source mappings that you want to configure in order to have your your function run in response to various events.
Infrastructure as code
Now if you add in things like Amazon API gateway or DynamoDB, there’s even more steps that you’ve got to deal with in terms of creating the actual API setting up additional kind of resources and methods within your API and and creating all of the mapping there. There’s a lot of different and a lot of different steps that need to happen in order to get kind of code moved into my AWS account and it would be nice if there was a way to more easily automate this and make it a repeatable process for deploying across various environments.
Whenever we talk about kind of how do we repeatedly create these types of cloud environments across various different accounts and in different regions potentially we use this term called infrastructure as code. Infrastructure as code is really about being able to define a declarative template that defines exactly all of your cloud resources need to be created and then using a service that can that can kind of generate the actual physical
resources for you from that definition.

AWS CloudFormation, for example, is the service that you would use to kind of implement this type of model. CloudFormation allows you to define a template in either JSON or YAML that defines all of the different resources that you want to create.
Meet SAM
Using just raw CloudFormation becomes tedious and verbose. In order to address that issue we’ve created an additional kind of tool that sits on top of CloudFormation called the AWS Serverless Application Model.

SAM provides this higher level of abstraction where you can define the functions and the events and all of the pieces that go along with that in a much more concise syntax.
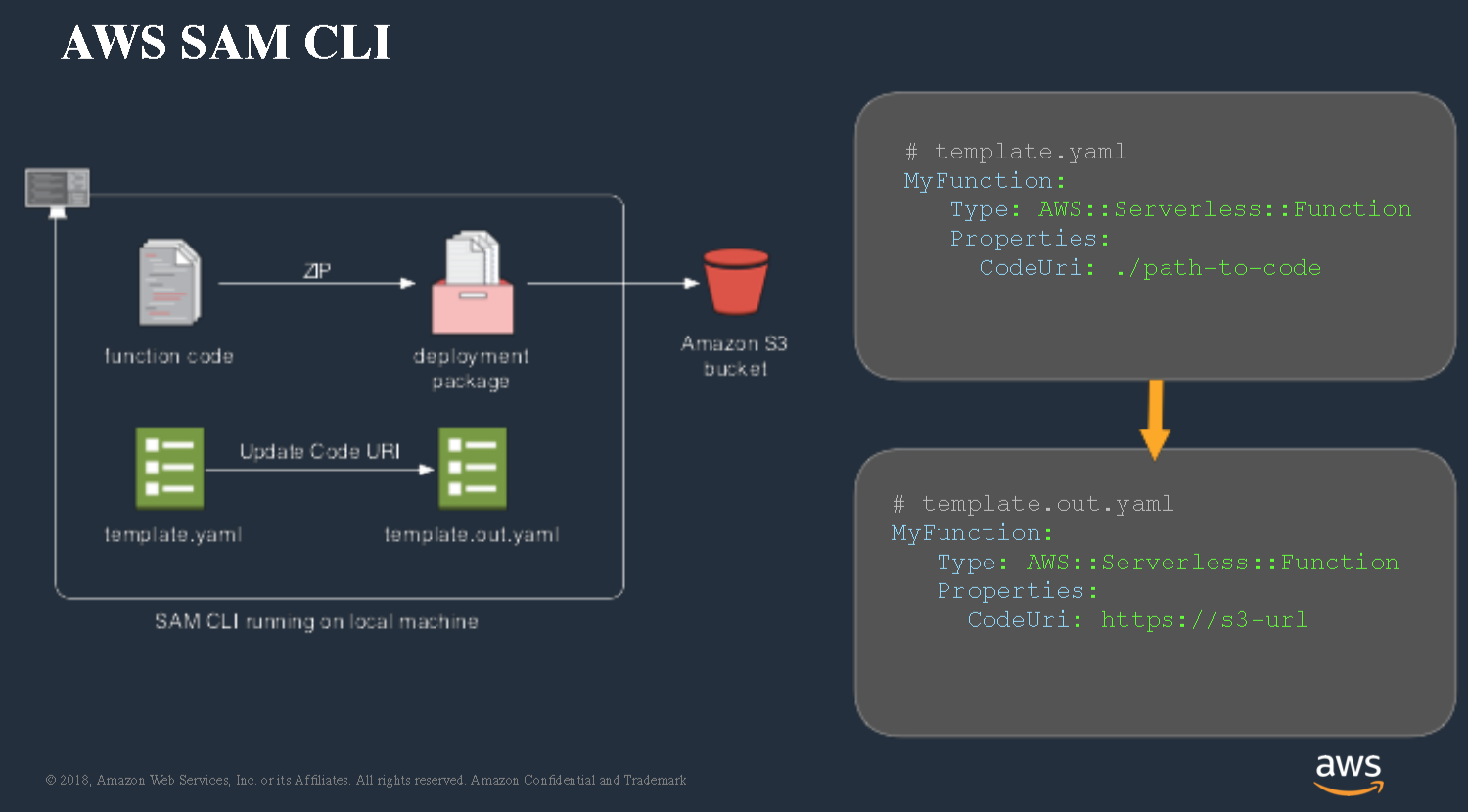
When you think about SAM, think about a declarative model for defining how your service application is structured and how it gets deployed. There’s two kind of core components to
the service application model: the first is a CLI that runs locally, and the second is kind of an extension to CloudFormation itself that allows CloudFormation to understand these higher-level resources and translate them into those underlying kind of raw templates.
Developer environment options
Speaking of developer environments, it’s very important that you have the ability as a developer to deploy into a sandbox account yourself. One of the key components of the serverless paradigm is that there is no idle cost to deploying. You’re only going to pay for it when it gets run. As a result, it’s very feasible now to have dozens of different application stacks that are deployed out into various sandbox accounts, so that every developer and their team has the ability to go out and build and run kind of the
full stack in an environment that mirrors production very closely.
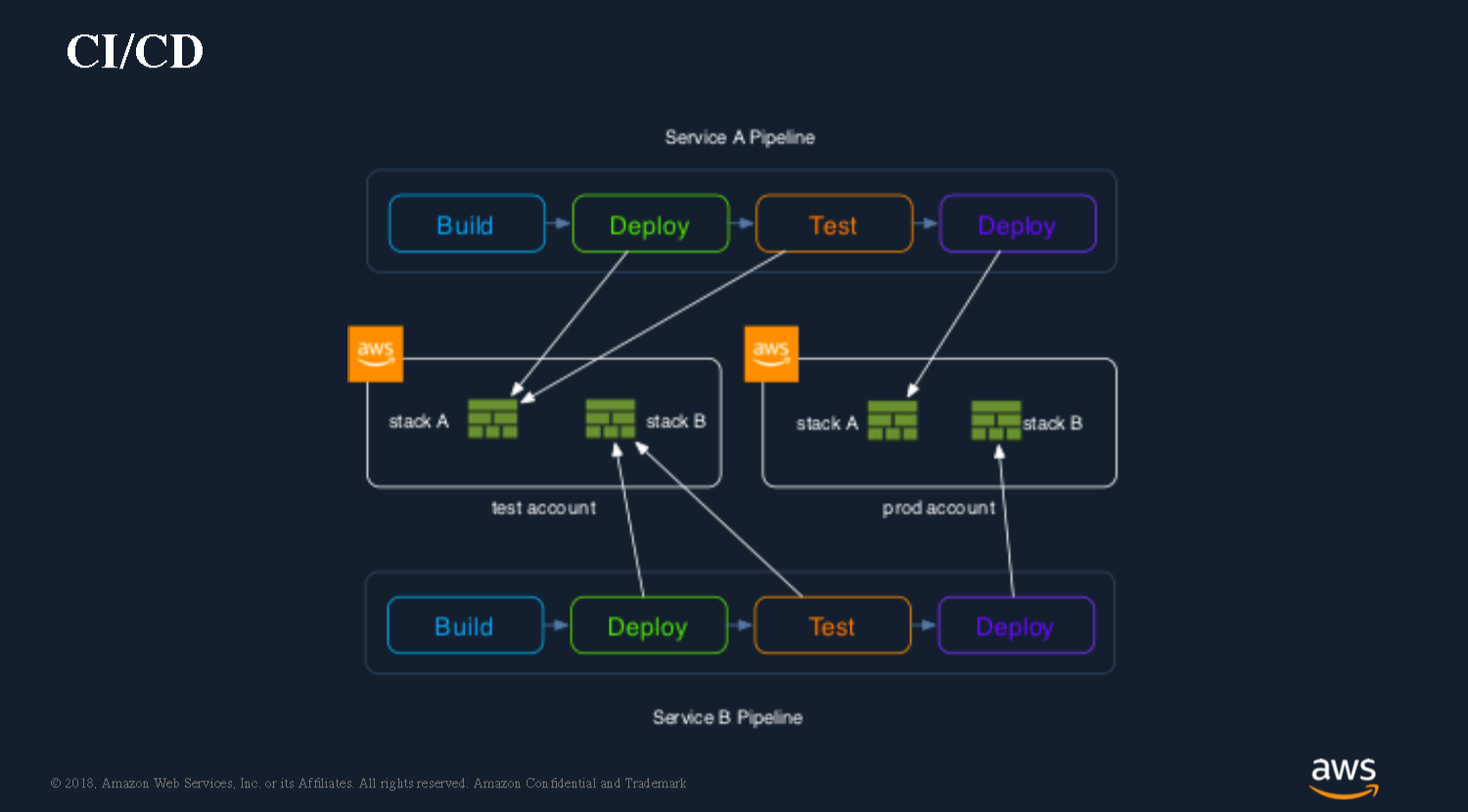
CI/CD
When we talk about shifting from a traditional development environment into a service world, the same principles of building a continuous delivery pipeline still apply. The only difference is that now instead of using Chef, Ansible or some other deployment tool, you’re going to use SAM (CloudFormation, Terraform or other code-as-infrastructure tool) to do the actual deployments of your application and update the various environments.
Testing
Let’s talk a little bit about testing.
Whenever we talk about testing and software it’s important to think through kind of the different hierarchy, if you will, of tests.
- First of all there’s going to be some amount of local testing that we want to do when we make a little bit of a code change and see it run locally.
- Then there’s also going to be this kind of remote integration testing. At some point you’re going to want to actually deploy this out into an environment that more closely mimics production.
- Then we also have an entire kind of automated integration test suite that’s going to be part of our build pipeline. This covers everything from automated tests to any kind of smoke tests.
The only thing that needs to change fundamentally about your test strategy when it comes to serverless is how you’re doing your local testing. You need to think how you are
going to structure emulating your cloud environment. Once you’ve deployed your application out to AWS, you’re actually running a real AWS Lambda service. You’re just interacting with your system via standard API calls or sending messages to a queue, etc.
Debugging
What happens when I want to be able to step through all of the lines of code to
figure out what’s going wrong there? This can be somewhat challenging within the
context of AWS Lambda. We’re used to this kind of model where we’re able to
deploy code out to some remote server and then use our IDE to connect to a
remote debugging port and step through the code regardless of where it’s
running. The problem is, when you move to a platform like AWS Lambda, it doesn’t allow you to open up those ports. Even if you could bootstrap the runtime environment itself
and open up some kind of port like this, the Lambda service itself would actually block any incoming TCP traffic that’s trying to hit a non-standard port. The SAM CLI gives you this ability to emulate lambda locally.
You author your code inside of your IDE the standard way. Then this code can be run inside of a Docker container that’s actually managed by SAM. The SAM CLI takes care of managing all of the event mapping and makes sure that your function is getting run the same way that it would be run if you were running on top of the actual Lambda service. Then you can run an entire system locally that’s emulating the standard Lambda runtime, and then connect the debugger to that. Now your function is just a Docker container that’s running on your local environment.
Last but by no means least, a developer preview of the AWS IntelliJ plugin that was featured in the webinar is now available at https://github.com/aws/aws-toolkit-jetbrains. Please give it a try and share your feedback with the plugin’s developers.
That’s it. Again, for more details, make sure to watch the actual recording.
Would like us to do a webinar on a different topic or a different speaker? Let us know in the comments!
Your JetBrains Team
The Drive to Develop






