

JetBrains AI
Supercharge your tools with AI-powered features inside many JetBrains products
AI エージェントを Kotlin で構築する - 第 4 回:委譲とサブエージェント

この連載の過去記事:
- AI エージェントを Kotlin で構築する - 第 1 回:ミニマルなコーディングエージェントの実装
- Kotlin による AI エージェントのビルド - パート 2: ツールの深掘り
- AI エージェントを Kotlin で構築する - 第 3 回:観測
前回の記事でトレースのセットアップ方法を確認しましたが、これによって新しい疑問が生まれました。このツールが提供する情報に基づいて何を実験すればよいのか? また、観測した結果を利用してエージェントのどの部分を改善できるのか?の 2 つです。
最初に浮かんだアイデアは、サブエージェントの実験(より具体的には find サブエージェントの実験)を行うことでした。それにより、Koog でサブエージェントのような共通パターンの実装がどの程度簡単になるかを確認することができます。ここでは、find サブエージェントがパフォーマンスを維持または向上させながら全体的なコストを削減する可能性があると仮定しています。
そのように考える理由は、 コストに影響する主な要因がコンテキストの増加にあるからです。各 LLM リクエストには最初から最後までの完全なコンテキストが含まれるため、後続の各リクエストは先行するリクエストよりも(少なくとも入力トークンの観点では)コストが高くなります。(特にエージェント実行の早い段階で)コンテキストの増加を制限できれば、コストを大幅に削減できる可能性があります。必要以上に大量のコンテキストがあると、エージェントが本質的なタスクに集中できない可能性もあります。そのため、コンテキストを絞り込めば(予測困難であっても)パフォーマンスが改善される可能性もあります。
find 機能は特に有効期間の長いコンテキストからの除去に特に適しています。何かを検索する場合、皆さんが往々にして目的の内容が含まれない多数のファイルを開いています。目的の内容が含まれないものを記憶するのは有益ではありませんが、 実際に見つかったファイルを記憶しておくことは有益です。これは、エージェントの履歴を圧縮する自然な手段と考えることができます(実際の圧縮については後の記事で説明します)。
このタスクは比較的単純であるため、サブエージェントのタスクにも適しています。単純であるということは、別の LLM モデルを使用するサブエージェントの機能を活用できる可能性もあるということです。その場合、より高速で安価なモデルを使用すると、 通常の圧縮では得られない柔軟性がもたらされます。
もちろん、これを実現できる従来の手続き型ツールをビルドすることは可能です。実際、JetBrains は RegexSearchTool というツールをビルドしましたが、この実験の目的上はツールを main エージェントに直接組み込まず、find エージェントに組み込みました。それにより、インテリジェンスを強化しながら、柔軟にモデルを選択できるようにしています。
find エージェント
サブエージェントのパターンを得られるようにするには、まずは 2 つ目のエージェントが必要です。エージェントの作成については、すでにこの連載のパート 1 で取り上げていますので、そこにはあまり時間をかけません。ただし、いくつかの詳細については触れておく価値があります。
まず、重要度の低いことから触れておきます。このサブエージェントには GPT4.1 Mini を使用しています。なぜなら、タスクがはるかに単純であり、main エージェントが使用するモデルほど機能性のあるモデルが必要でないためです。
また、このエージェントがアクセスできるツールを確認しておくと役に立ちます。このエージェントは main エージェントと同様に ListDirectoryTool と ReadFileTool にアクセスできますが、EditFileTool と ExecuteShellCommandTool にはアクセスできません。また、前述の新しい手続き型検索ツールである RegexSearchTool にもアクセスできるようにもなっています。そのため、正規表現パターンでフォルダーとそのサブフォルダー内のファイルを網羅的に検索できます。
ToolRegistry {
tool(ListDirectoryTool(JVMFileSystemProvider.ReadOnly))
tool(ReadFileTool(JVMFileSystemProvider.ReadOnly))
tool(RegexSearchTool(JVMFileSystemProvider.ReadOnly))
}
詳細については、こちらで完全な実装をご覧ください。
find サブエージェントをビルドする
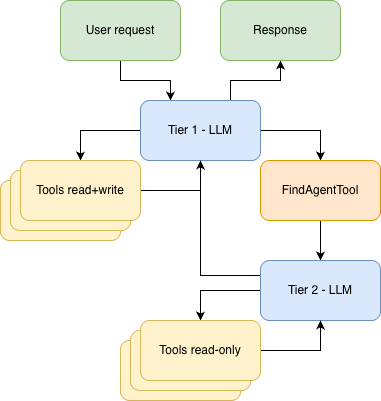
そもそもサブエージェントとは何でしょうか? サブエージェントとはごく単純なもので、別のエージェントによって制御されるエージェントを指します。この具体的な例では、ツールとしてのエージェントのサブエージェントパターン(サブエージェントが main エージェントに提供されたツール内で実行されるパターン)を扱っています。
サブエージェントの作成は単純明快です。私たちの認識では、ツールというものは基本的にある関数と対になる記述子(エージェントがその関数を呼び出すタイミングとその方法を理解するために読み取るもの)を指しています。ここでは、自身の .execute() 関数がサブエージェントを呼び出すツールを単に定義できます。ただし、Koog にはこのようなボイラープレートすらも排除できるツールが備わっています。
fun createFindAgentTool(): Tool {
return AIAgentService
.fromAgent(findAgent as GraphAIAgent)
.createAgentTool(
agentName = "__find_in_codebase_agent__",
agentDescription = """
""".trimIndent(),
inputDescription = """
""".trimIndent()
)
}
これは、以下とほぼ同等であると考えられます。
public class FindAgentTool(): Tool() {
override val name: String = "__find_in_codebase_agent__"
override val description: String = """
"""
@Serializable
public data class Args(
@property: LLMDescription(
"""
"""
)
val input: String
)
@Serializable
public data class Result(
val output: String
)
override suspend fun execute(args: Args): Result = when {
output = findAgent.run(args.input)
Result(output)
}
}
どちらの場合も、必要なのは以下の作業だけです。
- サブエージェントを作成する。
agentNameを指定する。agentDescriptionプロンプトを通じてエージェントの呼び出しタイミングを指定する。inputDescriptionプロンプトを通じてエージェントの呼び出し方法を指定する。
最も苦労するのはプロンプトの部分かと思います。ファインチューニングを実施する余地はたくさんありますが、 比較的新しい LLM ではあまり綿密にチューニングされたプロンプトは必要ないと言われているため、今やプロンプトを完璧にファインチューニングする手間をかける価値はないかもしれません。このトピックについては JetBrains 社内で調査中ですが、確固たる結論を得るにはさらなる実験が必要になりそうです。
私たちが 1 つ気づいたことがあります。それは、プロンプトを慎重に扱わなければ、main エージェントが find エージェントを単なる Ctrl+F / ⌘F 機能と混乱し、エージェントが検索しようとするトークンのみを送信してしまうということです。それは明らかに最適とは言えません。コンテキストが不足している場合、find エージェントは実際に検索すべき内容を推論できません。この問題を解決するには、main エージェントに検索する理由を指定するように要求する指示を含めます。そうすることで、find エージェントがそのインテリジェンスを最大限に活用し、main エージェントが実際に探しているものを検出できます。
""" このツールには、コードのコンテキストを解析して理解し、コードベース内の特定要素を検出するインテリジェントなマイクロエージェントが使用されています。単純なテキスト検索(Ctrl+F / ⌘F)とは異なり、クエリをインテリジェントに解釈し、ユーザーの意図に最も適合したクラス、関数、変数、またはファイルの場所を特定します。検索する情報、その情報が必要な理由、検索範囲を定義した絶対パスを記述した詳細なクエリが必要です。... """
| 明示ありのクエリ(Ctrl+F /⌘F ではない) | 明示なしのクエリ(Ctrl+F /⌘F ではない) |
|---|---|
不要な joins に関する get_search_results の変更を検索して、不要な joins に関するコメントやロジックがあるかどうかを確認してください。 |
get_search_results |
SKLEARN_ALLOW や同様のものを含む環境変数の使用箇所をリポジトリ内で検索し、check_build が回避されている可能性のある箇所を検出してください。 |
SKLEARN_ALLOW |
また、main エージェントが find エージェントではなく、なおも grep コマンドを使用してシェルツールを呼び出すことで、専用のサブエージェントを持つ目的自体が損なわれてしまう場合があることにも気づきました。このパターンを回避するため、メインのシステムプロンプトに以下のセクションを追加して find エージェントを強く推奨するようにしました。
""" ... コードのコンポーネントやその他の構成要素を自力で探すよりも低コストで検出できるインテリジェントな find マイクロエージェントも使用できます。このエージェントはあらゆる検索処理に使用できます。検索タスクにはシェル実行コマンドを使用しないでください。... """
これが、冒頭で述べた「自然な圧縮」です。find エージェントは多数のファイルを開き、目的の内容を含まないファイルをたどり、コードベースを探索します。一方、main エージェントは関連性のあるファイルパス、スニペット、および説明といった結果のみを認識します。探索されたすべての内容は find エージェントのコンテキスト内に留まり、それが返された後は消滅するため、 本当に重要な情報のみが main エージェントのコンテキストに追加されます。
デメリット
サブエージェントを使用することにはメリットがありますが、デメリットもあります。このような変更は、多くを犠牲にすることなく、求めているメリットを提供できるかどうかを示す実験が確実に必要です。
最初のトレードオフはコストと時間です。メインのスレッドのコンテキストを減らすことで、そこにかかるコストと時間を短縮できますが、サブエージェントでの多数の LLM 呼び出しにコストを支払って待機する必要が出てきました。全体的なコストと所要時間が少なくなることが期待されますが、それは main エージェントがどのようにサブエージェントを使用するか次第です。小さなクエリを大量に実行することになった場合、このメリットは得られない可能性があります。コストについては、後のセクションでもう一度ベンチマークを実行する際に確認しましょう。また、ここでは単にそのコストと時間が相関していると仮定します。
ツールを何回か実行したところ、この状況が発生することに気付きました。そこで、ツールの agentDescription に main エージェントに問題を説明し、大量の小さなクエリを実行する頻度を制限するように試みることを説明する部分を追加しました。
""" ... このエージェントは検索実行時のコスト効率がシェルコマンドを使用する場合よりもはるかに優れていますが、検索を繰り返しているうちにコンテキストが失われてしまいます。そのため、このツールを複数回呼び出すのではなく、類似する検索を 1 つの呼び出しにまとめることを優先してください。... """
2 つ目のトレードオフは、この手法ではコンテキストの保持方法が人間よりもはるかに白黒はっきりしているという点です。人間は過去に起きたすべての出来事を有効な記憶に引き出すことはできませんが、出来事の漠然とした印象は保持しており、必要に応じて補足的な前後の状況を思い出すことができます。このような挙動をモデル化する方法はありますが、それはこのエージェントの現時点でのイテレーションの範囲から大きく逸脱しますし、どちらかと言えば深淵で複雑なエージェントメモリのテーマに関連する内容です。
もう 1 つの課題は、トレースがより複雑化することです。Langfuse では、1 つのエージェントのトレースのみを確認するだけでは済みません。実際、全体と各エージェントの両方を個別に確認し、複数の観点で動作を見る必要があるかもしれません。
視野を広げた考察: エンジニアリングチームに例える
このサブエージェントを使用する手法は、find エージェントのような単純な例に制限されるものではありません。たとえば、解析、実装、テスト、および計画を別々のサブエージェントに割り当てることで、チーム構造内での役割分担を再現することができます。
これらすべての機能を備えたエージェントがサブエージェント間で機能を割り振ったシステムよりも優れているか劣っているかはまだ答えが出ていませんが、潜在的なメリットを想像するのは難しいことではありません。「組織は自らのコミュニケーション構造をそのまま反映したシステムを設計する」というコンウェイの法則について考えてみましょう。ある見方では、そのようなコミュニケーション構造が維持する価値のある効率的なパターンを発見するように進化したとされています。逆コンウェイ戦略ではそれが望ましいとさえされ、推奨されています。
同じことが役割分担にも当てはまるのでしょうか? ソフトウェアチーム内の複数の異なる専門分野でタスクを分割することも、効率的な業務の遂行方法を発見するように進化したのかもしれません。LLM もそれと同じ恩恵を受けられるかもしれません。
とは言え、その保証はありません。この効率性は主に人間の学習プロセスを分散させることに端を発している可能性がありますが、これは LLM には当てはまらない可能性があります。しかし、『Clean Code』という書籍では、ライター(クリエイター)、リーダー(メンテナー)、テスター(テスター)というさまざまな肩書きを持たせることが書かれています。他の役割の視点に惑わされることなく、1 つの役割に専念するという考え方です。このことから、タスク分割は単なる学習効率よりも深い意図があり、実際に LLM に関連している可能性があることが窺えます。
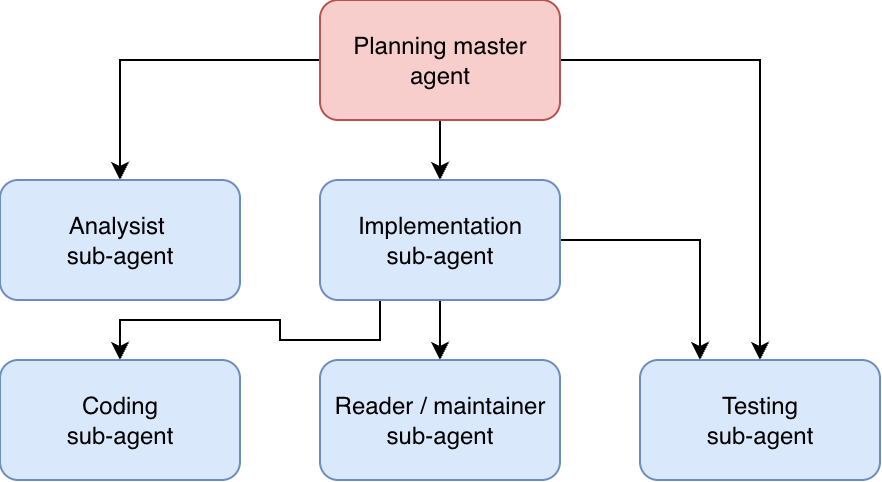
つまり、サブエージェントをさらに活用できるということです。しかし、これが有益な手法であるかどうかはまだ証明されていません。現時点ではテクニックに過ぎず、科学的根拠のあるものではありません。
ベンチマークの結果: 仮説をテストする
find サブエージェントを使用しないバージョンのコストは $814、インスタンスあたり $1.63 であったのに対し、このサブエージェントを使用したバージョンでは、コストが $733、インスタンスあたり $1.47 という結果が出ました。これは 10% のコスト削減であり、間違いなく注目に値する結果です。
興味深い観測結果の 1 つには、結果がサブエージェントの LLM の選択に強く左右されているという点があります。比較的小規模な実験ではサブエージェントと GPT-5 Codex との接続を維持するよう試みましたが、これにより、50 サンプル以上の平均コストがサンプルあたり $3.30 と大幅に増加しました。
| 実験 | 成功率 | インスタンスあたりのコスト |
| パート 03(Langfuse) | 56%(278/500) | $1.63 ($814/500) |
| パート 04(サブエージェント: GPT4.1 mini) | 58%(290/500) | $1.47 ($733/500) |
| パート 04(サブエージェント: GPT-5 Codex) | 58%(29/50) | $3.30 ($165/50) |
ただし、コストを削減するために 2 つの方法を仮定したことはお伝えしておきます。1 つ目はタスクを委譲することで実現される自然な圧縮を通じてコンテキストサイズを縮小すること、そして 2 つ目は作業をより安価なモデルにオフロードすることです。このデータではサブエージェントを分割(そして GPT-5 Codex モデルを維持)するだけで、実際にコストが大幅に増加したことが示されています。そのため、1 つ目の方法はうまくいかず、2 つ目(安価なモデル)が効果的に見えます。ただし、これは厳密な証明にはならないかもしれません。
パフォーマンスの改善については、56% から 58% へと若干の上昇が見られています。これは統計的な変動の許容範囲内である可能性がありますが、少なくともパフォーマンスが安定しており、コストが削減されたことは励みと言えます。
まとめ
サブエージェントの作成は簡単であり、非常に効果的な可能性があることを見てきました。Koog にはこのプロセスをさらに合理化するための便利なツールが備わっており、開発者はツールとしてのエージェントに対するプロンプトのみを定義することができます。
この手法は明らかに有益なコスト削減となります。ここでは約 10% の削減を達成しました。これは明確かつ評価可能な改善です。パフォーマンスへの影響はそれほど明確ではありませんが、ある程度の改善はあったように思われます。
それと同時に、このような評価には高いコストがかかります。コストが削減されたにしても、ベンチマークのコストは合計 $730 がかかりました。そこで、次の記事では別のコスト削減戦略(より汎用的な圧縮手)を詳しく見ていきたいと思います。その中で「コンテキストの無限増大とそれに伴うコストの増加をどのように防げばよいのか?」という疑問にお答えします。
オリジナル(英語)ブログ投稿記事の作者:




