

JetBrains AI
Supercharge your tools with AI-powered features inside many JetBrains products
AI エージェントを Kotlin で構築する – 第 5 回:エージェントが情報を忘れる仕組みの実装

この連載の過去記事:
- AI エージェントを Kotlin で構築する - 第 1 回:ミニマルなコーディングエージェントの実装
- AI エージェントを Kotlin で構築する - 第 2 回:ツールの深掘り
- AI エージェントを Kotlin で構築する - 第 3 回:観測
- AI エージェントを Kotlin で構築する - 第 4 回:委譲とサブエージェント
エージェントは最終的にコンテキストを使い果たしてしまいます。そうなるとエージェントはクラッシュし、処理中のタスクがすべて失われてしまいます。
パート 1 から GPT-5 Codex をずっと実行してきましたが、 このモデルは SWE-bench Verified では 0.58 というスコアを出しました。次に試した Claude Sonnet 4.5 は 0.6 のスコアを出し、ほとんどのタスクで実行速度が向上しましたが、 複雑な問題により、Claude の 200,000 というコンテキストウィンドウに比較的早く到達してしまいました。
皆さんもパフォーマンス改善、低コスト化、あるいはローカルでの実行を目的にモデルを切り替えるのではないかと思いますが、 それによってコンテキストウィンドウが小さくなることもあります。これは、特に高価なメモリに制約されるローカルモデルでは特に顕著です。しかし、コンテキストウィンドウがどんなに大きくても、複雑で長時間にわたるタスクでは失敗します。さらにコンテキストに費用をかけ続けるわけにはいきません。
問題なのは、エージェントが個々のファイル、コマンド出力、検索結果、ユーザーメッセージといったすべての情報を保持することです。最終的にはこれらを保持する容量がなくなります。
ここで出番となるのが圧縮です。ただし、容量切れになったときに単に古いメッセージを削除するという後追いのやり方ではありません。あるタスクを他の開発者に引き継ぐ状況を想像してください。自分がやったことをすべて記した文書を渡すことはないでしょう。目標、変更したファイル、作業内容、そしてやらなかったことを伝えるはずです。それがまさにスマート圧縮であり、処理を継続させるために必要なコンテキストを維持し、無駄な履歴を削除する手法なのです。
これを Koog で実装する方法を考えてみましょう。まず、パート 1 から strategy = singleRunStrategy() が行ってきたことを理解する必要があります。それにより、戦略を通じてエージェントのループをどのように制御し、開発者がどのようにそのループを変更して独自のフローを作成できるのるかが見えてきます。まずは singleRunStrategy() を確認し、その後で自動的に圧縮するバージョンをビルドしましょう。
strategy 行の処理内容
これまでの記事では、コーディングエージェントをビルドしました。そのエージェントにツールを与え、以下の行を追加しました。
strategy = singleRunStrategy()
この strategy(戦略)はエージェントループを実行するコードです。すべての戦略は LLM の呼び出し、ツールの実行、結果の送り返し、その繰り返しという同じ基本要素を共有していますが、 停止のタイミングと反復処理の間に実行する内容は異なります。
singleRunStrategy() は最大限に単純なバージョンです。LLM がツールの呼び出しを返す限り、反復処理を続けます。言い換えると、LLM の呼び出し → ツールの呼び出しが返されたか? → 実行 → 再呼び出し → テキストが返されたか? → 完了、という一連の処理です。
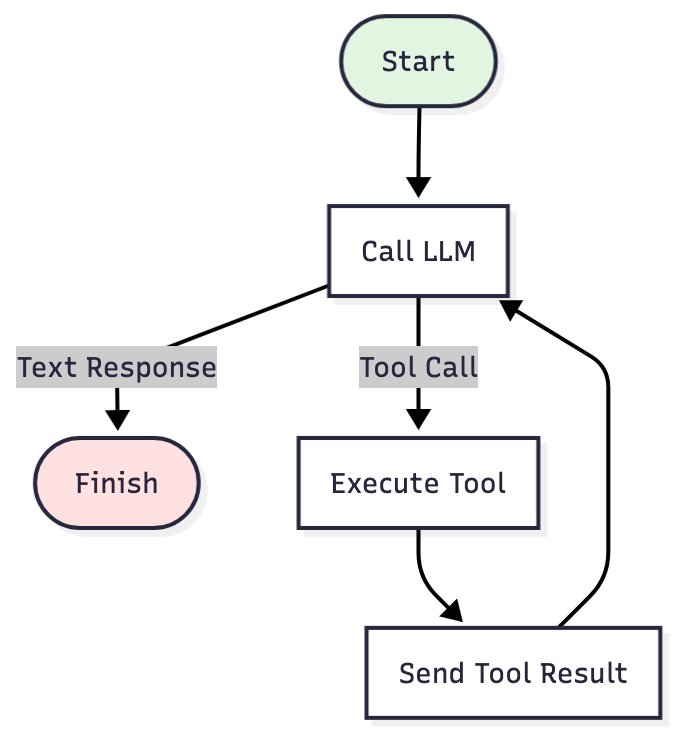
単純なタスクではこれでも十分に機能しますが、 複雑な問題では履歴が増大し続けます。個々のコマンド出力、ファイルの読み取り、検索結果がすべてコンテキストに留まるためです。最終的には上限に達し、タスクの処理の途中でクラッシュしてしまいます。
代わりに必要なのは、同じループを実行すると同時に、履歴のサイズをチェックし、過度に増大している場合に圧縮する戦略です。
圧縮を追加する
以下の行を
strategy = singleRunStrategy()
このように置き換えましょう。
strategy = singleRunStrategyWithHistoryCompression()
ループは同じですが、Execute Tool と Send Tool の結果の間にチェックポイントが追加されています。この戦略ではツールを実行した後、常に以下の確認が行われます。
- チェック: 履歴のサイズはしきい値を上回っているか?
- 上回っている場合は? 圧縮する: 重要な情報を抽出し、 残りは削除する。
- 上回っていない場合は? 通常通り続行する。
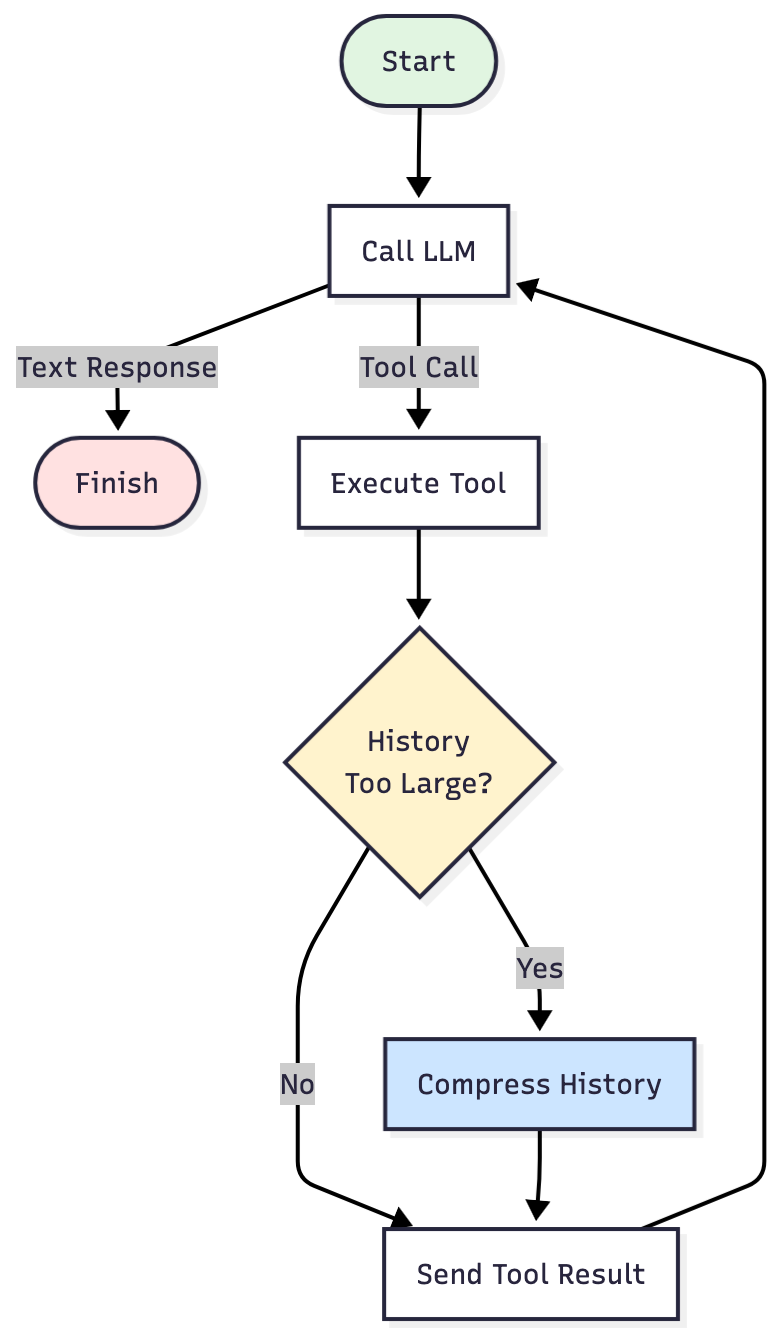
このチェックポイントがあることで、エージェントに実行時間の長いタスクをより厳しいトークン予算内で完了させ、「コンテキストウィンドウを超過しました」というエラーを回避できます。
ただし、チェックポイントの構成は必要です。この戦略では履歴が肥大化する時期や、どのような情報がタスクに重要であるかを推測することはできません。戦略には圧縮のタイミングと保持する情報の 2 つを指示する必要があります。
圧縮のタイミング
まず、圧縮が開始されるまでに許容するメッセージ数か文字数をしきい値として設定します。
val CODE_AGENT_HISTORY_TOO_BIG = { prompt ->
prompt.messages.size > 200 || prompt.messages.sumOf { it.content.length } > 200_000}
なぜこれらの数値が選ばれたのでしょうか? エラー発生箇所を確認した後、さまざまなしきい値で実験を行いました。

このエージェントは 220,000 トークンに達した時点でクラッシュしました。Claude の上限は 200,000 トークンです。そこに達する前に圧縮する必要がありました。
メッセージ 200 件か 200,000 文字のいずれかに達した場合に圧縮するように設定します。このコードはトークン数ではなく、文字数を計測することに注意してください。これらの数値は異なってはいるものの、このしきい値によってトークンの上限内に維持することができます。過度の圧縮を回避するのに十分に高い値であり、上限に達さない程度に低い値でもあります。
これらの数値は固定ではありません。エージェントが上限に達するのが早ければ、しきい値を低くしてください。それでもタスクの完了までにしきい値を超えてしまう場合は、 しきい値を上げましょう。どのような選択をするかは、ファイルサイズ、メッセージの長さ、ツールの出力の詳細度、タスクの複雑度など、ユースケースによって異なります。試行錯誤を繰り返して適切な値を見つけましょう。
保持する情報
圧縮が発動するタイミングを設定しました。次に、保持する情報を選択しましょう。
これには、重要な情報の判断を LLM に任せる方法と抽出すべき情報を LLM に正確に指示する方法の 2 つがあります。
オプション 1: LLM に要約を任せる
LLM は WholeHistory を使用してどの情報が重要かを判断します。
compressionStrategy = WholeHistory
圧縮が発動すると、Koog は LLM に会話履歴全体の要約を作成するように要求します。
圧縮前:
- しきい値に至るまでのすべてのメッセージ: システムプロンプト、ユーザーメッセージ、アシスタントの応答、ツールの呼び出し、ツールの結果
圧縮後:
- システムプロンプト(維持される)
- 最初のユーザーメッセージ(維持され、エージェントが本来の目標を記憶している)
- 1 つの概要メッセージ(LLM によって作成される)
トレードオフ: これはシンプルで手っ取り早いものの、何が重要な情報なのかの判断を LLM に任せる方法です。適切な情報が正確に維持される場合もありますが、 重要な内容が省略されることもあります。
オプション 2: 抽出すべき情報を LLM に正確に指示する
モデルにすべてを要約するように指示するのではなく、RetrieveFactsFromHistory を使用してどの情報を抽出すべきかを正確に指示する方法です。
compressionStrategy = RetrieveFactsFromHistory( Concept(...), Concept(...), ... )
今後の流れ:
Concept オブジェクトを使用し、エージェントが記憶すべきタスクに関する具体的な質問を定義します。圧縮が発動すると、Koog は Concept ごとに 1 つの LLM 呼び出しを行いますが、会話履歴全体を毎回送信し、その 1 つの質問だけを尋ねています。
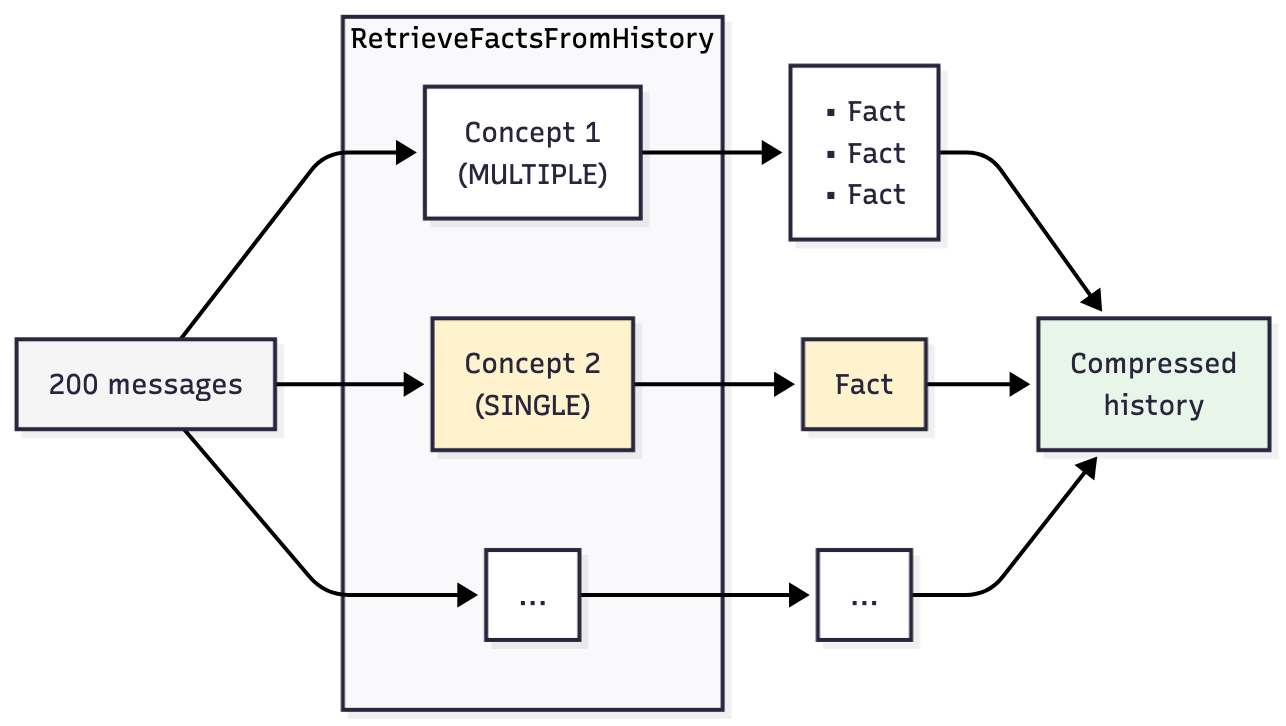
呼び出しを分離するのはなぜでしょうか? LLM は一度に複数の質問を行った場合、うまく答えられなくなります。これは 8 個の Concept を 1 個のプロンプトにまとめたテストで確認されたことですが、一部の回答があいまいな状態か不完全な状態で返されてしまいました。一度に 1 つずつ質問すれば、個々の応答の信頼性が高まります。
Concept の定義
各 Concept のインスタンスには以下の 3 つの要素があります。
keyword: ログのラベルdescription: LLM が回答する必要のある実際の質問または指示factType: 期待される回答の形式- リストの場合は
MULTIPLE - 単一値の場合は
SINGLE
- リストの場合は
Concept(
keyword = "project-structure",
description = "What is the project structure?",
factType = FactType.MULTIPLE
)
適切な Concept の選択
このコーディングエージェントの場合、主な疑問は「どんな情報が失われた場合にエージェントは処理を最初からやり直すのか?」ということです。
圧縮によって重要な情報が削除された場合、以下が発生します。
- エージェントが同じファイルを以前に読み取られたことがないかのように二度開いてしまう。
- すでに存在するテストを書き直してしまう。
- 当初指示していたタスクから逸脱してしまう。
失敗するたびに、圧縮過程で保持されるべき情報が示されます。
- ファイルが繰り返し調査されている →
project-structureConcept が必要です。 - 完了した作業をやり直している →
important-achievementsConcept が必要です。 - 方向性を見失っている →
agent-goalConcept が必要です。
この記事のコーディングエージェントの Concept
SWE-bench-Verified でテストした際には 8 個の Concept が得られました。以下はそのうちの 3 個です。
val CODE_AGENT_COMPRESSION_STRATEGY = RetrieveFactsFromHistory(
Concept(
"project-structure",
"What is the structure of this project?",
FactType.MULTIPLE
),
Concept(
"important-achievements",
"What has been achieved during the execution of this current agent?",
FactType.MULTIPLE
),
Concept(
"agent-goal",
"What is the primary goal or task the agent is trying to accomplish in this session?",
FactType.SINGLE
),
...
作成するエージェントによっては、異なる Concept が必要となる場合があります。目標はこのリストをコピーすることではなく、エージェントが動作を継続するために必要な状態を特定し、その情報を保持する Concept を定義することです。
GitHub にある 8 個の Concept の実装全体をご覧ください。
使用するモデル
サブエージェントと同様に(パート 4)、プロセスの別々の箇所で異なるモデルを使用できます。retrievalModel パラメーターを使用すると、履歴圧縮を処理する LLM を指定できます。このパラメーターは必須ではなく、指定されていない場合はエージェントのメインのモデルが圧縮に使用されます。
retrievalModel = OpenAIModels.Chat.GPT4_1Mini
以下はコーディングエージェントの戦略用の完成な構成です。
strategy = singleRunStrategyWithHistoryCompression(
config = HistoryCompressionConfig(
isHistoryTooBig = CODE_AGENT_HISTORY_TOO_BIG,
compressionStrategy = CODE_AGENT_COMPRESSION_STRATEGY,
retrievalModel = OpenAIModels.Chat.GPT4_1Mini
)
)
圧縮のタイミング(isHistoryTooBig)、保持する情報(compressionStrategy)、使用されるモデル(retrievalModel)の 3 つのパラメーターが指定されています。
まとめ
この時点でエージェントがコンテキストの上限に達することなく、より長いタスクを実行できるようになりました。圧縮の問題が解決しました。エージェントが容量切れになったときにクラッシュせず、判断と結果を保持して無駄な出力を削除することで履歴を圧縮し、割り当てられたトークン予算内で処理を継続するようになりました。
この連載のパート 1 では、基本的なコーディングエージェントから着手しました。その後、ツール、可観測性、サブエージェント、そして履歴圧縮を追加しました。これらの 5 つの要素により、実際のモデルの制約内で運用できる実用的な AI エージェントを Kotlin でビルドするために必要なものが得られます。
これらのパターンのビルドと実践を続ける場合は、エージェントが複数ターンで何をすべきかをどのように判断するのか、複雑な問題をどのように細分化するのかといった計画と推論の領域を詳しく調べると面白いでしょう。それらはここでは取り上げませんでしたが、上記の要素が動作するようになったら実践してみるとよいでしょう。
完全なコードは GitHub にあります。問題が発生した場合は、コメント欄でお知らせください。喜んでお手伝いいたします ?
オリジナル(英語)ブログ投稿記事の作者:




