

データクリーニングとは?データサイエンスで重要な手順とベストプラクティス

データサイエンスに関するこのブログ連載記事では、データの入手場所と pandas を使用してそのようなデータを探索する方法について説明してきました。そのようなデータは学習用途に最適ですが、現実世界のデータとはまったく異なっています。 学習用のデータはデータクリーニングとキュレーションが完了した状態で提供されることが多いため、データクリーニングの世界を経験しなくてもすぐに学習に取り掛かることができます。一方、現実世界のデータは問題があり、整理されていないものです。 現実世界のデータの場合、有用なインサイトを得るためには事前にクリーニングを行う必要があります。それが今回のブログ記事のトピックです。
データの問題は、データ自体の挙動、データの収集方法、さらにはデータの入力方法によって発生する可能性があります。 ミスや見過ごしは、これらのどの段階においても発生しうるものです。
ここではデータ変換ではなく、データクリーニングに限定して説明しています。 データクリーニングでは、データから導き出した結論を定義した母集団に一般化することができます。 対照的に、データ変換ではデータ形式の変換、データの正規化、データの集計などのタスクが伴います。
なぜデータクリーニングが重要なのか?データ分析の精度を向上させる理由
データベースについて最初に理解する必要があるのは、それが何を代表しているかということです。 ほとんどのデータセットはより幅広い母集団を代表するサンプルであり、このサンプルを処理して得られた結果をその母集団に外挿する(または一般化)できるようになります。 たとえば、前の 2 つのブログ記事では、あるデータセットを使用しました。 そのデータセットは大まかには住宅販売に関するものですが、小さな地理的なエリアと短い期間のみを網羅しているもので、そのエリアと期間内のすべての住宅を網羅していない可能性があります。これが、より大きな母集団のサンプルです。
データはより幅広い母集団を代表するサンプルである必要があります。たとえば、定義した期間における対象エリアのすべての住宅販売が挙げられます。 使用するデータを確実により幅広い母集団を代表するサンプルにするには、最初に母集団の境界を定義する必要があります。
ご想像の通り、おそらく国勢調査データを除けば、母集団全体を使って作業するのは往々にして現実的ではありません。そのため、境界をどこに置くのかを決める必要があります。 そのような境界は、地理、人口統計、期間、行動や活動(取引など)、または業界固有のものなどにすることができます。 母集団の定義には多数の方法がありますが、データを確実に一般化するには、データをクリーニングする前に定義しておく必要があります。
要するに、分析や機械学習などの目的でデータを使用する場合は時間をかけてデータをクリーニングし、インサイトを信頼して現実世界に一般化できるようにする必要があります。 データをクリーニングすると分析の正確性が増し、機械学習においてはパフォーマンスも改善されます。
データをクリーニングしなければ学習結果を幅広い母集団に確実に一般化できず、要約統計が不正確になり、不正に可視化されるなどの問題が発生する可能性があります。 データを使用して機械学習モデルをトレーニングしようとしている場合は、それがエラーや不正確な予測の原因になる可能性もあります。
データクリーニングの具体例 – 5 つの主要手順
データのクリーニングに使用できる 5 つのタスクを見てみましょう。 このリストは網羅的なものではありませんが、初めて現実世界のデータに取り掛かる際には役に立つはずです。
データの重複排除
重複はデータを歪める可能性があるため、問題です。 販売価格の出現頻度を使用してヒストグラムを作成していると想像してください。 同じ値が重複している場合、重複した価格に基づいて不正確なパターンのあるヒストグラムが作成されてしまいます。
補足しておきますが、ここでデータセットの重複が問題であると言う場合は、各行が単一の観測値になっている行そのものが重複していることを指しています。 列には重複した値があっても、それは予想されることです。 ここでは、重複した観測値についてのみ取り上げています。
幸いにも、データ内の重複を検出するのに役立つ pandas メソッドがあります。 必要であれば、JetBrains AI チャットで以下のようなプロンプトを入力すると、その使用方法を調べることができます。
Code to identify duplicate rows
以下の結果が出力されます。
duplicate_rows = df[df.duplicated()] duplicate_rows
このコードでは DataFrame が "df" という名前である想定になっているため、必要に応じて使用している DataFrame の名前に合わせて変更してください。
これまで使用してきた Ames Housing データセットには重複データはありませんが、上記の pandas メソッドを試してみたい方は CITES Wildlife Trade Database データセットに対して使用し、重複の有無を確認してみてください。
データセット内に重複が見つかったら、それを除去して結果に歪みが生じないようにする必要があります。 そのためのコードも JetBrains AI で次のプロンプトを使用して得られます。
Code to drop duplicates from my dataframe
出力されたコードでは重複が排除され、DataFrame のインデックスがリセットされ、その後に df_cleaned という名前の新しい DataFrame としてデータセットが表示されます。
df_cleaned = df.drop_duplicates() df_cleaned.reset_index(drop=True, inplace=True) df_cleaned
より高度な重複管理に使用できる pandas 関数は他にもありますが、データセットの重複排除が初めての方にはこれで十分です。
あり得ない値の処理
データが誤って入力された場合やデータ収集プロセスで何らかのエラーが発生した場合、あり得ない値が発生する場合があります。 Ames Housing データセットの場合は、マイナスの SalePrice や Roof Style に使用されている数値があり得ない値になるでしょう。
データセット内のあり得ない値を特定するには、要約統計を確認する、列ごとに収集者によって定義されたデータ検証ルールを確認する、その検証から外れているデータポイントを記録する、可視化によって異常だと思われるパターンやその他の特徴を特定する、といった多様な手法があります。
あり得ない値はノイズの混入や分析時の問題の原因となり得るため、処理する必要があります。 ただし、処理方法にはさまざまな解釈があります。 データセットのサイズに比べてあり得ない値の数が多くなければ、そのような値を含むレコードを除去するとよいでしょう。 たとえば、データセットの 214 行目にあり得ない値を見つけた場合、pandas drop 関数でその行をデータセットから除去することができます。
ここでも JetBrains AI で以下のようなプロンプトを使用し、必要なコードを生成できます。
Code that drops index 214 from #df_cleaned
PyCharm の Jupyter ノートブックでは、単語の前に # 記号を付けることで、JetBrains AI Assistant に追加のコンテキストを提供していることを示すことができます。ここでは、DataFrame が "df_cleaned" という名前であることを示しています。
生成されたコードでは対象の観測値が DataFrame から除去され、インデックスがリセットされてから表示されます。
df_cleaned = df_cleaned.drop(index=214) df_cleaned.reset_index(drop=True, inplace=True) df_cleaned
あり得ない値を処理する戦略としては、代入を使用するのも一般的です。つまり、あり得ない値を定義された戦略に基づいて別のあり得る値に置き換えるのです。 最も一般的な戦略の 1 つは、あり得ない値の代わりに中央値を使用することです。 中央値は外れ値の影響を受けないため、データサイエンティストにこの目的でよく選ばれていますが、それと同様にデータの平均値やモード値の方が適している場合もあります。
データセットとそのデータの収集方法に関する専門知識がある場合は、あり得ない値をより意味のある値に置き換えることもできます。 データ収集プロセスに関わっている場合やそのプロセスを理解している場合は、こちらの方法が適しているかもしれません。
どの方法を選択してあり得ない値を処理するかは、データセット内でのその値の出現頻度、データの収集方法、母集団の定義方法、および専門知識などの他の要因によって異なります。
データの書式
多くの場合、要約統計や早い段階で可視化を行ってデータの形状に関する概要を把握することで、書式の問題を特定できます。 書式が矛盾している例には、小数点以下の桁数の定義が統一されていない数値や、”first” や “1st” のようなスペルのばらつきが挙げられます。 データの書式が誤っている場合、データのメモリ使用量にも問題が生じる可能性があります。
データセット内で書式の問題が見つかった場合は、値を標準化する必要があります。 発生している問題によりますが、通常は独自の標準を定義して変更を適用する必要があります。 これについても、pandas ライブラリには round のような便利な関数が用意されています。 SalesPrice 列を小数点以下 2 桁に丸める場合は、以下のようにして JetBrains AI にそのコードを問い合わせることができます。
Code to round #SalePrice to two decimal places
生成されるコードでは丸めが実行され、それを確認できるように最初の 10 行が出力されます。
df_cleaned['SalePrice'] = df_cleaned['SalePrice].round(2) df_cleaned.head()
スペルに矛盾がある場合の例も見てみましょう。たとえば、HouseStyle 列に “1Story” と “OneStory” の両方が存在しており、これらが同じものを意味していることが分かっているとします。 以下のプロンプトを使用すると、この矛盾を解決するためのコードを取得できます。
Code to change all instances of #OneStory to #1Story in #HouseStyle
生成されるコードはまさにこの矛盾を解消し、すべての “OneStory” を “1Story” に置き換えます。
df_cleaned[HouseStyle'] = df_cleaned['HouseStyle'].replace('OneStory', '1Story')
外れ値の解決
外れ値はデータセットではよく発生しますが、その対処方法はコンテキストによって大きく異なります。 外れ値を最も簡単に特定するには箱ひげ図を使用する方法がありますが、これには seaborn ライブラリと matplotlib ライブラリを使用します。 箱ひげ図については、pandas でデータを探索する方法に関する前のブログ記事で説明しています。簡単なおさらいが必要であれば、そちらをご覧ください。
この箱ひげ図を使用するため、Ames Housing データセットの SalesPrice を見てみましょう。 ここでも JetBrains AI で以下のようなプロンプトを使ってコードを生成します。
Code to create a box plot of #SalePrice
実行すべきコードが以下のように生成されます。
import seaborn as sns
import matplotlib.pyplot as plt
# Create a box plot for SalePrice
plt.figure(figsize=(10, 6))
sns.boxplot(x=df_cleaned['SalePrice'])
plt.title('Box Plot of SalePrice')
plt.xlabel('SalePrice')
plt.show()
箱ひげ図から、青い箱の内側にある縦の中央値の線が中心より左側にあるため、正の歪みがあることが分かります。 正の歪みはより比較的安価な住宅価格が多いことを示していますが、これは驚くべきことではありません。 箱ひげ図からは、右側に外れ値が多いことも視覚的に分かります。 これは、中央価格よりもはるかに高価な少数の住宅があることを示しています。
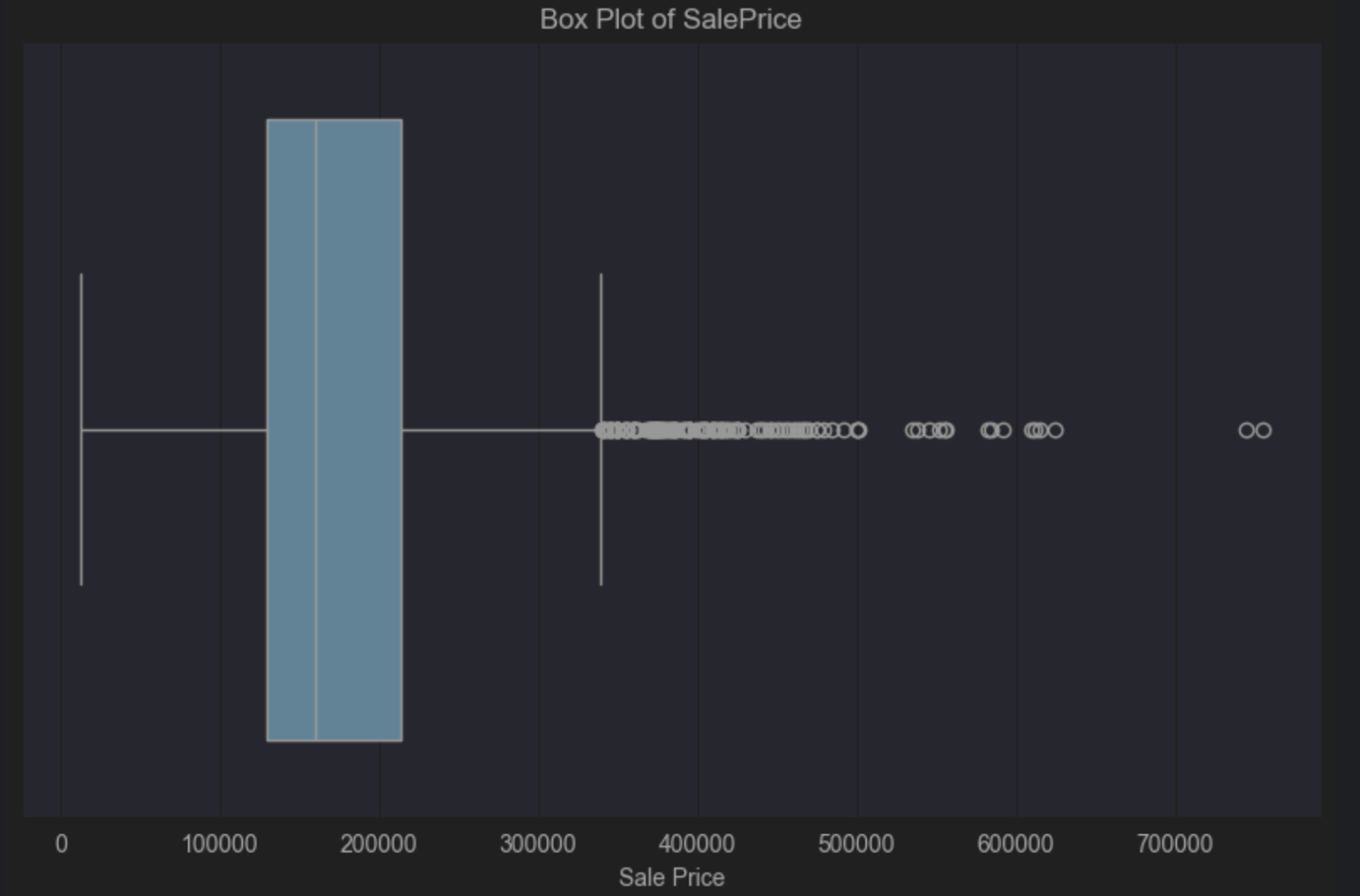
大多数の住宅よりも高価な小数の住宅があることはよくあることなので、このような外れ値があることは受け入れられるかと思いますが、 すべては一般化する母集団とデータから導き出す結論によって決まります。 母集団に含まれるものと含まれないものに明確な境界を引くことで、データ内の外れ値が問題となるかどうかを情報に基づいて判断できるようになります。
たとえば、母集団を構成するのが高価な豪邸を購入しない人々なら、そのような外れ値を削除できるかもしれません。 しかし、母集団にこのような高価な住宅を購入する可能性があると合理的に考えられる人が含まれているのなら、このような外れ値は母集団に関連性があるため、残すべきかもしれません。
ここでは箱ひげ図を外れ値の特定方法として取り上げていますが、散布図やヒストグラムなどの他の方法でもデータに外れ値が含まれるかどうかを素早く確認し、外れ値に対処すべきかどうかを情報に基づいて判断できます。
外れ値の解決方法は一般的に 2 つに分類されます。外れ値を削除するか、外れ値にあまり影響を受けない要約統計を使用するかの 2 つです。 前者の場合、外れ値が実際にどの行であるかを知る必要があります。
これまでは外れ値を視覚的に特定する方法について説明してきました。 どの観測値が外れ値であるかどうかを判断するにはさまざまな方法があります。 一般的な方法の 1 つは、修正 Z スコアという手法を使用することです。 Z スコアがどのような理由でどう修正されているのかを見る前に、その基本的な定義が以下であることを知っておきましょう。
Z スコア = (データポイントの値 – 平均値) / 標準偏差
外れ値を検出するために Z スコアを修正する理由は、平均値も標準偏差もその計算方法によっては外れ値の影響を受けやすいためです。 修正 Z スコアは以下のように定義されています。
修正 Z スコア = (データポイントの値 – 中央値) / 中央絶対偏差
要約統計を取り上げた際に学習したように、中央値は外れ値の影響を受けません。 中央絶対偏差は、データセットの中央値からの絶対偏差の中央値です。 たとえば、データセットに以下の値が含まれているとします。
1, 2, 2, 2, 3, 3, 3, 5,9
この場合、中央値はデータセットの中央にある値である 3 になります。 中央値である 3 からの偏差は、上記の順では以下のようになります。
2, 1, 1, 1, 0, 0, 0, 2, 5
これらの値を昇順に並べ替えます。
0, 0, 0, 1, 1, 1, 2, 2, 5
したがって、この例での中央絶対偏差は 1 となります。
この記事の例に使用しているデータセットでは、SalePrice の修正 Z スコアをどのように求められるでしょうか? JetBrains AI に以下のプロンプトを使用してみましょう。
Given:
Modified Z-score = (data point value – median) / median absolute deviation
Calculate the Modified Z-score for #SalePrice
以下のコードが生成されます。
import pandas as pd from scipy.stats import median_abs_deviation # Assuming 'data' is your DataFrame and it contains the 'SalePrice' column # Calculate the median for the SalePrice column median_sale_price = data['SalePrice'].median() # Calculate the Median Absolute Deviation (MAD) for the SalePrice column mad_sale_price = median_abs_deviation(data['SalePrice'], scale='normal') # Calculate the Modified Z-scores for the SalePrice column data['Modified_Z_Score'] = (data['SalePrice'] - median_sale_price) / mad_sale_price # Display the first few rows with the Modified Z-scores print(data[['SalePrice', 'Modified_Z_Score']].head())
必要なパッケージをインストールしてこのコードを実行すると、目的を途中まで果たすことができます。しかし、次は SalePrice の外れ値が何であるかを修正 Z スコアに基づいて判断する必要があります。 ここでは一般常識に従って外れ値を >=3 または <=-3 としますが、ほとんどの統計的決定と同様に、外れ値は使用しているデータセットに合わせて調整でき、そうする必要があることに留意してください。 <=-3 however, it’s worth noting that like most statistical decisions, it can and should be tailored to your dataset. 出力をさらにカスタマイズするため、JetBrains AI に別のプロンプトを渡しましょう。 Just list those that have a #Modified_Z_Score of 3 or above or -3 or below
このコードスニペットを採用し、上記の関連する行に置き換えます。
# Filter the rows where the Modified Z-score is 3 or above, or -3 or below outliers = data[(data['Modified_Z_Score'] >= 3) | (data['Modified_Z_Score'] <= -3)] # Print all the filtered rows, showing their index and SalePrice outliers = (outliers[['SalePrice', 'Modified_Z_Score']]) outliers
“outliers” という新しい DataFrame に外れ値を格納し、その値を出力して内容を確認できるようにこのコードを修正しました。
次のステップでは、これらの外れ値を DataFrame から削除します。 ここでも JetBrains AI で以下のようなプロンプトを使用し、コードを生成できます。
Create a new dataframe without the outliers
data_without_outliers = data.drop(index=outliers.index) # Display the new DataFrame without outliers print(data_without_outliers)
“data_without_outliers” という新しい DataFrame では、SalePrice の変数が外れ値と見なされる値が除外されています。
箱ひげ図のコードを更新して新しい DataFrame を確認してみましょう。 予想していた通り、正の歪みは依然として示されていますが、外れ値として見なされる値は除去されています。
import seaborn as sns
import matplotlib.pyplot as plt
# Create a box plot for SalePrice
plt.figure(figsize=(10, 6))
sns.boxplot(x=data_without_outliers['SalePrice'])
plt.title('Box Plot of SalePrice')
plt.xlabel('SalePrice')
plt.show()
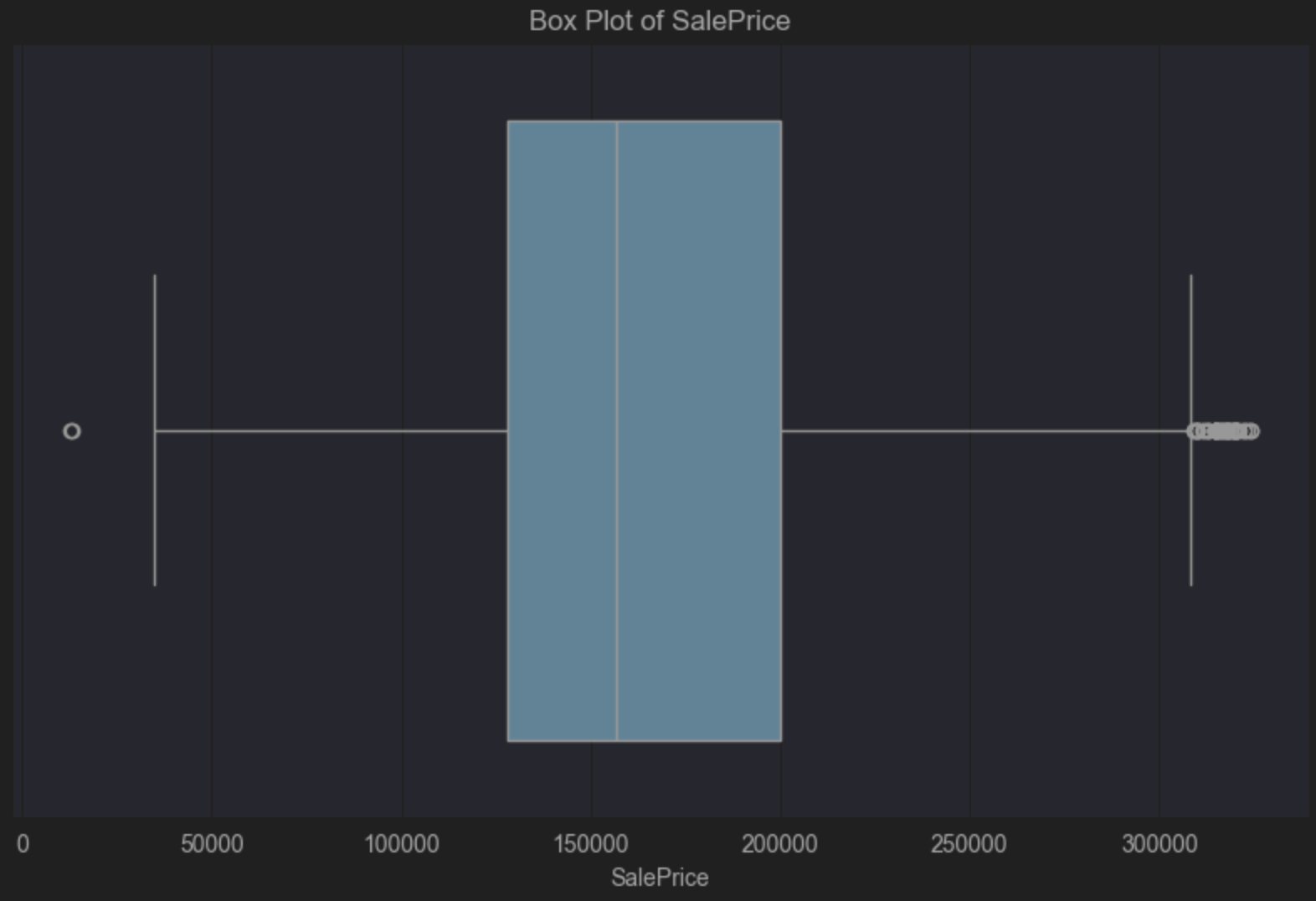
ここで終わる前に、SalePrice に基づいて外れ値と見なしたことで DataFrame から除去された観測値の数をパーセント率でみてみましょう。
以下のようなプロンプトを使用できます。
Calculate the percentage of observations removed between #data and #data_without_outliers
# Calculate the number of observations in the original and filtered DataFrames
original_count = len(data)
filtered_count = len(data_without_outliers)
# Calculate the number of removed observations
removed_count = original_count - filtered_count
# Calculate the percentage of observations removed
percentage_removed = (removed_count / original_count) * 100
# Display the percentage
print(f"Percentage of observations removed: {percentage_removed:.2f}%")
PyCharm により、5.67% の観測値が除去されたことが示されています。
前述のように、外れ値を残す場合は、外れ値の影響を受けにくい中央値や四分位範囲などの要約値を使用してみてください。 定義した母集団と導き出す結論に関連性があるために除去していない外れ値が含まれていることが分かっているデータセットを処理する場合は、それらの測定値を使用して結論を出すことを検討するとよいでしょう。
欠損値
データセット内の欠損値を最も素早く特定する方法は、要約統計を使用することです。 念のため、DataFrame 内で右側にある Show Column Statistics(列統計の表示)をクリックしてから Compact(コンパクト)を選択してください。 Ames housing データセットの Lot Frontage で分かるように、列の欠損値は赤色で示されます。

このデータに関して検討すべき欠損には以下の 3 種類があります。
- 完全にランダムな欠損
- ランダムな欠損
- ランダムでない欠損
完全にランダムな欠損
完全にランダムな欠損とは、完全に偶発的にデータが欠落しており、欠落の原因がデータセット内の他の変数と無関係であることを指します。 これは、アンケートの質問に回答漏れがある場合などに発生することがあります。
完全にランダムな欠損データはまれにしか発生しませんが、最も対処しやすいものでもあります。 完全にランダムに欠損している観測値の数が比較的少数である場合は、そのような観測値を削除するのが最も一般的な対処法です。そのような観測値は削除してもデータセットの整合性に影響することはなく、導き出そうとしている結論にも影響しないためです。
ランダムな欠損
ランダムな欠損には欠損のパターンがなさそうに見えても、測定した他の変数からパターンを説明できる欠損を指します。 たとえば、データの収集方法が原因でアンケートの質問に回答漏れがあった場合が挙げられます。
Ames housing データセットをもう一度見てみましょう。Lot Frontage 変数は、特定の不動産会社が販売した住宅では欠損の頻度が高くなっているはずです。 この場合、この欠損は不動産会社が入力したデータに整合性がないことが原因だと考えられます。 それが事実である場合、Lot Frontage データが欠損していることは Lot Frontage そのものではなく、物件を販売した不動産会社によるデータ収集方法(観測対象の特性)に関連していることになります。
データがランダムに欠損している場合は、データが欠損している理由を理解することをお勧めします。これには多くの場合、データの収集方法を調べる作業が伴います。 データが欠損している理由を理解したら、対処法を選択できます。 比較的よく選択されているランダムな欠損の対処法には、値の代入があります。 この対処法はあり得ない値に関してすでに触れましたが、欠損にも有効です。 この例で言えば、住宅の規模、建築年、販売価格などの相関変数を使用することも含め、定義された母集団と導き出したい結論に応じてさまざまな選択肢があります。 欠損データの原因となっているパターンを理解するには、コンテキスト情報を使用して値を代入できることもしばしばです。それにより、データセット内のデータ間の関連が維持されます。
ランダムでない欠損
最後に取り上げるランダムでない欠損は、データが欠損する可能性が観測対象外のデータに関連している場合に発生します。 つまり、欠損が未観測のデータに依存しているということです。
最後にもう一度 Ames housing データセットに戻り、Lot Frontage に欠損データがある事実に目を向けましょう。 データの欠損がランダムでない状況としては、販売者が Lot Frontage を小さいと見なし、それを報告することで住宅の販売価格が下がってしまうことを恐れて意図的に報告しなかった場合が挙げられます。 Lot Frontage データが欠損している可能性が間口そのものの規模(観測対象外)に依存しているのであれば、間口が小さいほど報告される可能性が低く、欠損が直接欠損値に関連していることになります。
欠損の可視化
データが欠損している場合は、パターンがあるかどうかを確認する必要があります。 パターンがある場合は、データを一般化する前に対処しなければならない可能性のある問題が存在することになります。
パターンを最も簡単に探すには、ヒートマップ可視化を使用する方法があります。 そのコードに着手する前に、欠損のない変数を除外しましょう。 JetBrains AI に以下のプロンプトを送ると、必要なコードが得られます。
Code to create a new dataframe that contains only columns with missingness
以下のコードが出力されます。
# Identify columns with any missing values columns_with_missing = data.columns[data.isnull().any()] # Create a new DataFrame with only columns that have missing values data_with_missingness = data[columns_with_missing] # Display the new DataFrame print(data_with_missingness)
このコードを実行する前に、最後の行を変更して PyCharm の素晴らしい DataFrame レイアウトを利用できるようにします。
data_with_missingness
では、ヒートマップを作成しましょう。ここでも JetBrains AI に以下のプロンプトを送信してコードを取得します。
Create a heatmap of #data_with_missingness that is transposed
以下の結果が出力されます。
import seaborn as sns
import matplotlib.pyplot as plt
# Transpose the data_with_missingness DataFrame
transposed_data = data_with_missingness.T
# Create a heatmap to visualize missingness
plt.figure(figsize=(12, 8))
sns.heatmap(transposed_data.isnull(), cbar=False, yticklabels=True)
plt.title('Missing Data Heatmap (Transposed)')
plt.xlabel('Instances')
plt.ylabel('Features')
plt.tight_layout()
plt.show()
なお、heatmap の引数から cmap=’viridis’ を除去しました。それを使うと見にくくなるためです。
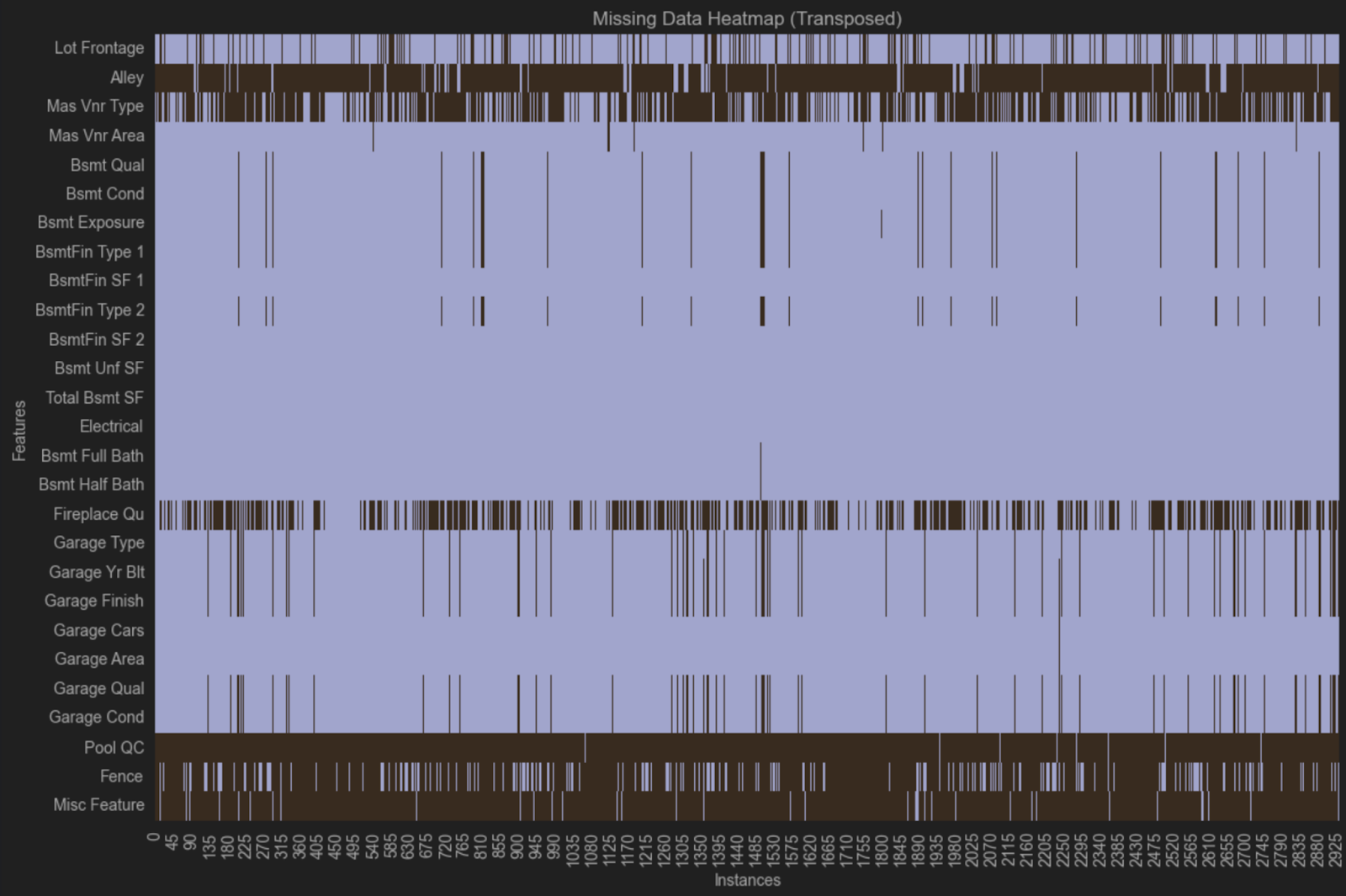
このヒートマップでは、同じ変数が複数の行にわたって欠損しているため、欠損のパターンがあると考えられます。 あるグループでは、Bsmt Qual、Bsmt Cond、Bsmt Exposure、BsmtFin Type 1、およびBsmt Fin Type 2 が同じ観測値からすべて欠損しているのが分かります。 別のグループでは、Garage Type、Garage Yr Bit、Garage Finish、Garage Qual、Garage Cond が同じ観測値からすべて欠損しています。
これらの変数はすべて地下室と車庫に関連していますが、欠損していない、車庫または地下室に関連する他の変数もあります。 この欠損を説明するとすれば、データが収集された際に別々の不動産会社で車庫と地下室に関する別々の質問が問われたものの、その中にデータセットにあるものほど詳しく記録されていないデータがある場合が挙げられます。 このような状況は自分で収集していないデータを扱う場合にはよく発生するため、データセット内の欠損を詳しく知る必要がある場合は、データの収集方法を調べることをお勧めします。
データクリーニングのベストプラクティス – 効率的な前処理のコツ
前述のように、母集団の定義はデータクリーニングのベストプラクティスの中でも特に優先すべき事項です。 クリーニングを始める前に、何を達成したいのか、どのようにデータを一般化したいのかを知っておくことが重要です。
すべての方法が再現可能であることを確認する必要があります。なぜなら、再現性はクリーンなデータにも関連しているからです。 再現できない状況だと、後続の作業に大きな影響を与えかねません。 このため、Jupyter ノートブックを整理して順序を維持し、すべてのステップで(特にクリーニングでは)Markdown 機能を活用して意思決定を文書化することをお勧めします。
データをクリーニングする際には段階的に作業を進め、元の CSV ファイルやデータベースではなく DataFrame を修正するようにし、再現可能で十分に文書化されたコードですべてを実施することをお勧めします。
まとめ – データサイエンスにおけるデータクリーニングの重要性
データクリーニングは大きなテーマであり、多くの課題に直面する可能性があります。 データセットが大きくなるほど、クリーニングプロセスも困難になります。 母集団を念頭に置き、欠損値の除去と代入のどちらを優先すべきかを考慮してそれらのバランスを保ち、データが元々欠損している理由を理解しながら、結論をより広範に一般化する必要があります。
自分自身をデータの声として考えましょう。 データがたどってきた過程や、あらゆる段階でデータの整合性をどのように維持してきたかを理解しているのはあなた自身です。 その過程を文書化し、他の人に共有するのに最適な人物はあなたです。
オリジナル(英語)ブログ投稿記事の作者:





