

Faster Python: Python グローバルインタープリターロックの解消

Python のグローバルインタープリターロック(GIL)とは?
「グローバルインタープリターロック」(別名「GIL」)は Python コミュニティでは一般的な用語であり、 よく知られている Python の機能です。 では、GIL とは実際には何なのでしょうか?
他のプログラミング言語(Rust など)をご経験の方は、ミューテックスという用語はすでにご存知かもしれません。 「相互排他制御(Mutual Exclusion)」の略です。 ミューテックスは一度に 1 つのスレッドのみがデータにアクセスすることを許可し、 同時に複数のスレッドがデータを変更することを防ぐ仕組みです。 これは、キーを持つ 1 つのスレッドを除き、すべてのスレッドのデータへのアクセスをブロックするという「ロック」のように考えるとよいでしょう。
GIL は技術的にはミューテックスそのものです。 一度に 1 つのスレッドのみが Python インタープリターにアクセスすることを許可します。 私はこの仕組みを Python における車のハンドルだと考えることがあります。 ハンドル操作は複数の人には任せられませんよね! とは言え、グループで車旅をするときは運転を交代することもよくあるでしょう。 これは、インタープリターへのアクセスを別のスレッドに引き渡すのと同じことです。
Python はこの GIL が原因で真のマルチスレッドプロセスを実現できません。 この機能は過去 10 年間にわたって議論を巻き起こしており、GIL を排除してマルチスレッドプロセスを可能にすることにより、Python を高速化しようとする多くの試みが行われてきました。 最近の Python 3.13 では、GIL を使わずに Python を使用するオプション(別名: no-GIL または free-threaded Python)が公開されました。 つまり、Python プログラミングの新しい時代の幕が開いたのです。
GIL が導入されたそもそもの理由とは?
GIL の人気がそれほど低いのなら、それが導入されたそもそもの理由は何なのでしょうか? GIL には実際にメリットがあります。 真のマルチスレッド処理を実現している他のプログラミング言語では、複数のスレッドがデータ変更を試みた際に先に終了するスレッドやプロセスによって最終的な結果が変わり、問題が発生する場合があります。 このような競合状態は「レースコンディション」と呼ばれています。 Rust のような言語が往々にして習得困難なのは、プログラマーがミューテックスを使用してレースコンディションを防ぐ必要があるためです。
Python ではすべてのオブジェクトが参照カウンターを保持しており、個々のオブジェクトの情報を必要としている他のオブジェクトの数が追跡されます。 Python には GIL があるためレースコンディションが存在しないことが分かっているため、参照カウンターがゼロに達しているオブジェクトは不要であり、ガベージコレクションの対象にできることを自信をもって宣言することができます。
Python が 1991 年に初めてリリースされた頃、ほとんどのパソコンには 1 つのコアしかなかったため、マルチスレッド処理のサポートをリクエストするプログラマーもあまりいませんでした。 GIL があればプログラムの実装上の多くの問題が解決され、コードも保守しやすくなります。 そのような理由により、GIL は 1992 年に Guido van Rossum(Python の開発者)によって追加されました。
2025 年まで時を進めましょう。今ではパソコンにマルチコアプロセッサーが搭載されており、計算能力も大幅に向上しています。 この有り余る能力を活用すれば、GIL を排除することなく真の並行性を実現できます。
この記事の後半では GIL を排除するプロセスを詳しく説明しますが、 まずは GIL がある前提で真の並行性がどのように機能するかを見てみましょう。
Python でのマルチプロセス処理
GIL の排除プロセスを詳しく見る前に、Python 開発者が multiprocessing ライブラリを使用して真の並行性をどのように実現しているのかを確認しましょう。 multiprocessing 標準ライブラリはローカルとリモートの両方の並行性を提供し、サブプロセスをスレッドの代わりに使用することで、グローバルインタープリターロックを効果的に回避できるようにします。 このようにすることで、multiprocessing モジュールはプログラマーが特定マシンの複数のプロセッサーをフル活用できるようにします。
ただし、マルチプロセス処理を実行するにはプログラムの設計を少しだけ変える必要があります。 Python で multiprocessing ライブラリを使用する以下の例を見てみましょう。
このブログ連載記事のパート 1 で見た非同期のバーガーショップを思い出してください。
import asyncio
import time
async def make_burger(order_num):
print(f"Preparing burger #{order_num}...")
await asyncio.sleep(5) # time for making the burger
print(f"Burger made #{order_num}")
async def main():
order_queue = []
for i in range(3):
order_queue.append(make_burger(i))
await asyncio.gather(*(order_queue))
if __name__ == "__main__":
s = time.perf_counter()
asyncio.run(main())
elapsed = time.perf_counter() - s
print(f"Orders completed in {elapsed:0.2f} seconds.")
これと同じ処理を以下のように multiprocessing ライブラリを使用して実現できます。
import multiprocessing
import time
def make_burger(order_num):
print(f"Preparing burger #{order_num}...")
time.sleep(5) # time for making the burger
print(f"Burger made #{order_num}")
if __name__ == "__main__":
print("Number of available CPU:", multiprocessing.cpu_count())
s = time.perf_counter()
all_processes = []
for i in range(3):
process = multiprocessing.Process(target=make_burger, args=(i,))
process.start()
all_processes.append(process)
for process in all_processes:
process.join()
elapsed = time.perf_counter() - s
print(f"Orders completed in {elapsed:0.2f} seconds.")
ご存知かもしれませんが、multiprocessing の多くのメソッドは threading に非常によく似ています。 multiprocessing での違いを確認するため、より複雑なユースケースを見てみましょう。
import multiprocessing
import time
import queue
def make_burger(order_num, item_made):
name = multiprocessing.current_process().name
print(f"{name} is preparing burger #{order_num}...")
time.sleep(5) # time for making burger
item_made.put(f"Burger #{order_num}")
print(f"Burger #{order_num} made by {name}")
def make_fries(order_num, item_made):
name = multiprocessing.current_process().name
print(f"{name} is preparing fries #{order_num}...")
time.sleep(2) # time for making fries
item_made.put(f"Fries #{order_num}")
print(f"Fries #{order_num} made by {name}")
def working(task_queue, item_made, order_num, lock):
break_count = 0
name = multiprocessing.current_process().name
while True:
try:
task = task_queue.get_nowait()
except queue.Empty:
print(f"{name} has nothing to do...")
if break_count > 1:
break # stop if idle for too long
else:
break_count += 1
time.sleep(1)
else:
lock.acquire()
try:
current_num = order_num.value
order_num.value = current_num + 1
finally:
lock.release()
task(current_num, item_made)
break_count = 0
if __name__ == "__main__":
print("Welcome to Pyburger! Please place your order.")
burger_num = input("Number of burgers:")
fries_num = input("Number of fries:")
s = time.perf_counter()
task_queue = multiprocessing.Queue()
item_made = multiprocessing.Queue()
order_num = multiprocessing.Value("i", 0)
lock = multiprocessing.Lock()
for i in range(int(burger_num)):
task_queue.put(make_burger)
for i in range(int(fries_num)):
task_queue.put(make_fries)
staff1 = multiprocessing.Process(
target=working,
name="John",
args=(
task_queue,
item_made,
order_num,
lock,
),
)
staff2 = multiprocessing.Process(
target=working,
name="Jane",
args=(
task_queue,
item_made,
order_num,
lock,
),
)
staff1.start()
staff2.start()
staff1.join()
staff2.join()
print("All tasks finished. Closing now.")
print("Items created are:")
while not item_made.empty():
print(item_made.get())
elapsed = time.perf_counter() - s
print(f"Orders completed in {elapsed:0.2f} seconds.")
次のような出力が得られます。
Welcome to Pyburger! Please place your order. Number of burgers:3 Number of fries:2 Jane has nothing to do... John is preparing burger #0... Jane is preparing burger #1... Burger #0 made by John John is preparing burger #2... Burger #1 made by Jane Jane is preparing fries #3... Fries #3 made by Jane Jane is preparing fries #4... Burger #2 made by John John has nothing to do... Fries #4 made by Jane Jane has nothing to do... John has nothing to do... Jane has nothing to do... John has nothing to do... Jane has nothing to do... All tasks finished. Closing now. Items created are: Burger #0 Burger #1 Fries #3 Burger #2 Fries #4 Orders completed in 12.21 seconds.
multiprocessing にはいくつかの制限があり、上記のコードはそれを理由にこのように設計されていることに注意してください。 それでは、1 つずつ説明していきましょう。
まず、正しい order_num で関数を生成する make_burger 関数と make_fries 関数があったことを思い出してください。
def make_burger(order_num):
def making_burger():
logger.info(f"Preparing burger #{order_num}...")
time.sleep(5) # time for making burger
logger.info(f"Burger made #{order_num}")
return making_burger
def make_fries(order_num):
def making_fries():
logger.info(f"Preparing fries #{order_num}...")
time.sleep(2) # time for making fries
logger.info(f"Fries made #{order_num}")
return making_fries
multiprocessing を使用する限り、同じことは行えません。 そうしようとすると、以下のようなエラーが発生します。
AttributeError: Can't get local object 'make_burger..making_burger'
これは、multiprocessing が概してトップモジュールレベルの関数しかシリアル化できない pickle を使用していることが原因です。 multiprocessing の制限の 1 つです。
次に、multiprocessing を使用する上記のサンプルコード片では共有対象のデータにグローバル変数を使用していないことに注意してください。 たとえば、item_made と order_num にグローバル変数を使用することはできません。 異なるプロセス間でデータを共有するには、multiprocessing ライブラリの Queue や Value などの特別なクラスオブジェクトが使用され、引数としてプロセスに渡されます。
プロセス間でのデータと状態の共有は、一般的には推奨されていません。それにより、多くの問題が発生する可能性があるためです。 上記の例では、Lock を使用して order_num の値が一度に 1 つのプロセスによってのみアクセスされ、増分されるようにしています。 Lock を使用しない場合、商品の注文番号は以下のように乱雑になる可能性があります。
Items created are: Burger #0 Burger #0 Fries #2 Burger #1 Fries #3
以下のように lock を使用すると、この問題を回避することができます。
lock.acquire()
try:
current_num = order_num.value
order_num.value = current_num + 1
finally:
lock.release()
task(current_num, item_made)
multiprocessing 標準ライブラリの使用方法についての詳細は、こちらのドキュメントをご覧ください。
GIL の排除
GIL の排除は約 10 年間にわたって議論されてきました。 2016 年の Python Language Summit では、Larry Hastings が CPython インタープリターで「GIL の廃止」を実行する考えとその構想の進捗を発表しました[1]。 これは Python の GIL を排除する先駆的な試みでした。 2021 年 には Sam Gross が GIL の排除に関する議論に再び火をつけ[2]、これが 2023 年の PEP 703 – Making the Global Interpreter Lock Optional in CPython(CPython でグローバルインタープリターロックをオプションにする)のきっかけになりました。
このように、GIL の排除は決して急に決まったものではなく、コミュニティ内では大きな議論の的となってきたものです。 上記のマルチプロセス処理の例(および上記でリンクされている PEP 703)で示されているように、GIL による保証がなくなると、事態は急速に複雑化します。
[1]: https://lwn.net/Articles/689548/
[2]: https://lwn.net/ml/python-dev/CAGr09bSrMNyVNLTvFq-h6t38kTxqTXfgxJYApmbEWnT71L74-g@mail.gmail.com/
参照カウント
GIL がある場合、参照カウントとガベージコレクションはもっと単純明快です。 一度に 1 つのスレッドのみが Python オブジェクトにアクセスできる場合は単純な非アトミック参照カウントを使用し、参照カウントがゼロに達したときにオブジェクトを除去することができます。
GIL を排除すると、事態は複雑化します。 スレッドの安全性を保証しない非アトミック参照カウントを使用できなくなるのです。 同時に複数のスレッドが Python オブジェクトに対して複数の参照の増分と減分を実行している場合、問題が発生する可能性があります。 アトミック参照カウントによってスレッドの安全性が保証されるのが理想的ですが、 この方法はオーバーヘッドが大きく、スレッド数が多い場合に効率が低下してしまいます。
この問題は、スレッドの安全性も保証するバイアス参照カウントを使用すると解決できます。 アイデアとしては、各オブジェクトをオーナースレッド(ほとんどの場合に特定のオブジェクトにアクセスしているスレッド)に偏らせるというものです。 オーナースレッドは自身が所有するオブジェクトに対して非アトミック参照カウントを実行できますが、他のスレッドはそのようなオブジェクトにアトミック参照カウントを実行する必要があります。 この方法が普通のアトミック参照カウントよりも望ましいのは、ほとんどのオブジェクトはほとんどの場合に 1 つのスレッドからのみアクセスされるためです。 オーナースレッドが非アトミック参照カウントを実行できるようにすることで、実行のオーバーヘッドを削減することができます。
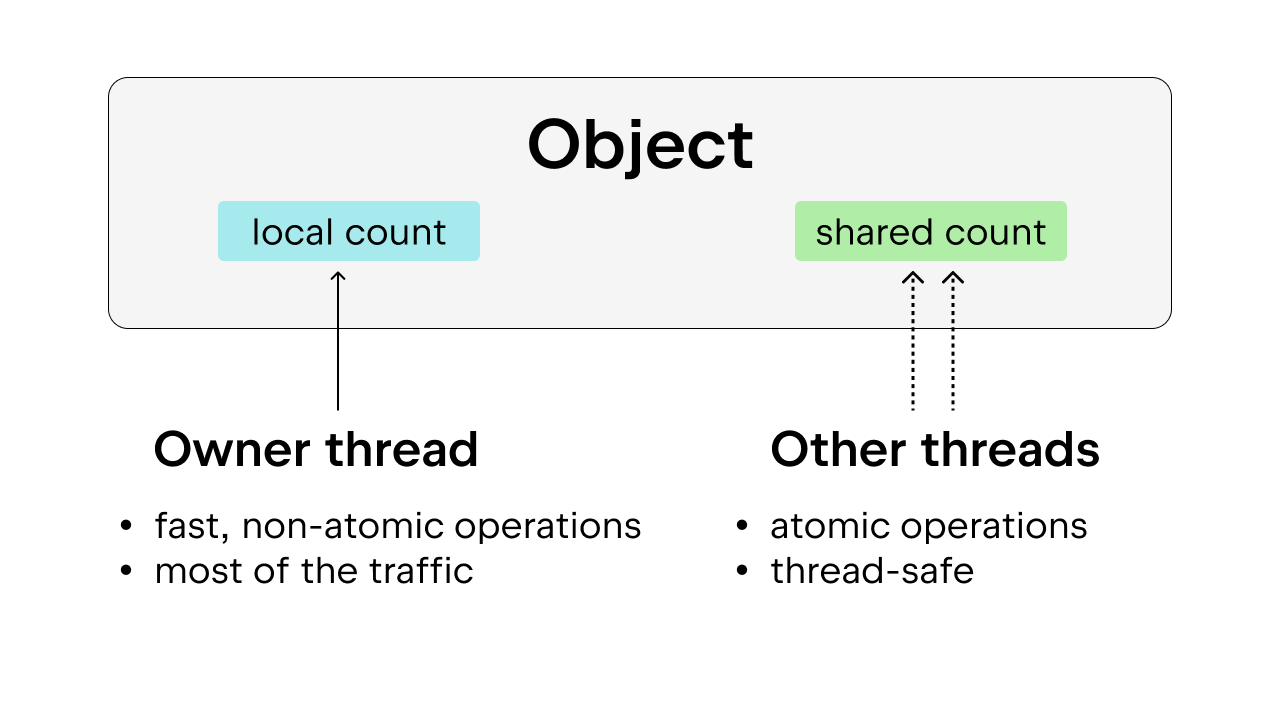
また、よく使用される一部の Python オブジェクト(True、False、小さな整数、一部の intern された文字列など)は永続化されます。 ここで、「永続」とはオブジェクトがその生存時間中にプログラムに留まるという意味であるため、参照カウントは必要としません。
ガベージコレクション
ガベージコレクションの実行方法も変更する必要があります。 参照が解放されたらすぐに参照カウントを減らし、参照カウントがゼロに到達したら直ちにオブジェクトを除去する代わりに、「遅延参照カウント」という手法が使用されます。
参照カウントを減らす必要がある場合、オブジェクトはテーブルに格納され、この参照カウントの減少が正確であるかどうかが再確認されます。 こうすることで、GIL がない場合にまだ参照されているオブジェクトが途中で除去される状況を回避しています。参照カウントが GIL がある場合ほど単純明快ではないためです。 これにより、ガベージコレクションのプロセスが複雑化します。ガベージコレクションは各スレッドのスタックごとに独自の参照カウントを全探索する必要になる場合があるためです。
もう 1 つ考慮すべきなのは、ガベージコレクション中は参照カウントが安定している必要があるということです。 破棄されようとしているオブジェクトが不意に参照された場合、深刻な問題が発生します。 そのため、ガベージコレクションのサイクル中にカウントを停止し、スレッドの安全性を保証する必要があります。
メモリの割り当て
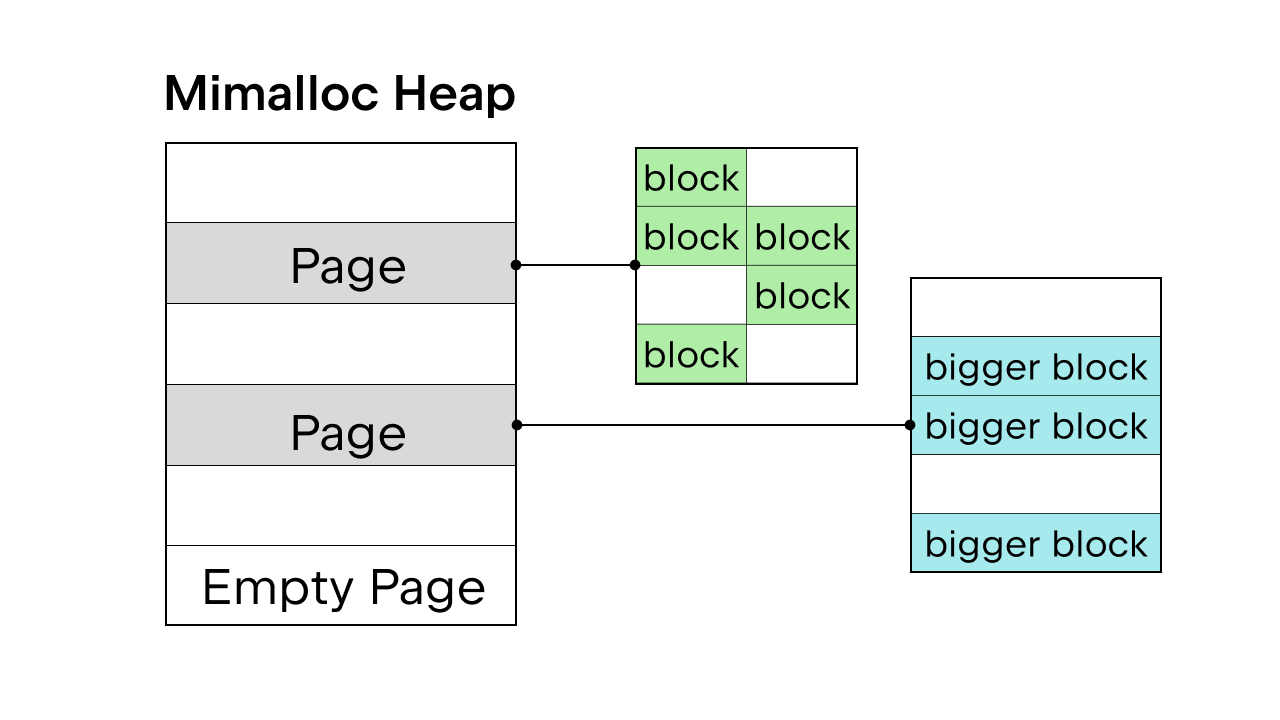
GIL がスレッド安全性を保証しているときは Python の内部メモリアロケーターである pymalloc が使用されます。 しかし、GIL がない場合は新しいメモリアロケーターが必要となります。 Sam Gross は Daan Leijen が開発し、Microsoft が保守する汎用アロケーターである mimalloc を PEP で提案しました。 これはスレッドセーフであり、小さなオブジェクトで良好なパフォーマンスを発揮するため、有効な選択肢です。
Mimalloc はそのヒープをページで埋め、ページをブロックで埋めます。 各ページにはブロックが含まれ、各ページ内のブロックはすべて同じサイズです。 リストと辞書のアクセスに制限を加えることで、ガベージコレクターが連結リストを維持してすべてのオブジェクトを検索する必要がなくなり、ロックを取得することなくこのリストと辞書を読み取れるようになります。
GIL の排除に関する詳細な情報は存在しますが、そのすべてをこの記事で説明するのは不可能です。 完全な内容については、PEP 703 – Making the Global Interpreter Lock Optional in CPython(CPython でグローバルインタープリターロックをオプションにする)をご覧ください。
GIL の有無によるパフォーマンスの違い
Python 3.13 には free-threaded オプションがあるため、Python 3.13 の標準バージョンのパフォーマンスを free-threaded バージョンと比較することができます。
free-threaded Python のインストール
pyenv を使用し、標準バージョン(3.13.5 など)と free-threaded バージョン(3.13.5t など)の両方のバージョンをインストールします。
または、Python.org のインストーラーを使用することもできます。 インストール中は必ず Customize オプションを選択し、free-threaded Python をインストールするオプションのボックスをオンにしてください(こちらのブログ記事の例をご覧ください)。
両方のバージョンがインストールされたら、それらを PyCharm プロジェクト内でインタープリターとして追加できます。
まず、右下の Python インタープリターの名前をクリックします。
メニューから Add New Interpreter(新規インタープリターの追加)と Add Local Interpreter(ローカルインタープリターの追加)を続けて選択します。
Select existing(既存の選択)を選択し、インタープリターパスが読み込まれるのを待ちます(インタープリターが多い場合は読み込みに時間がかかる場合があります)。その後、Python path (Python のパス)ドロップダウンメニューからインストールしたばかりの新しいインタープリターを選択します。
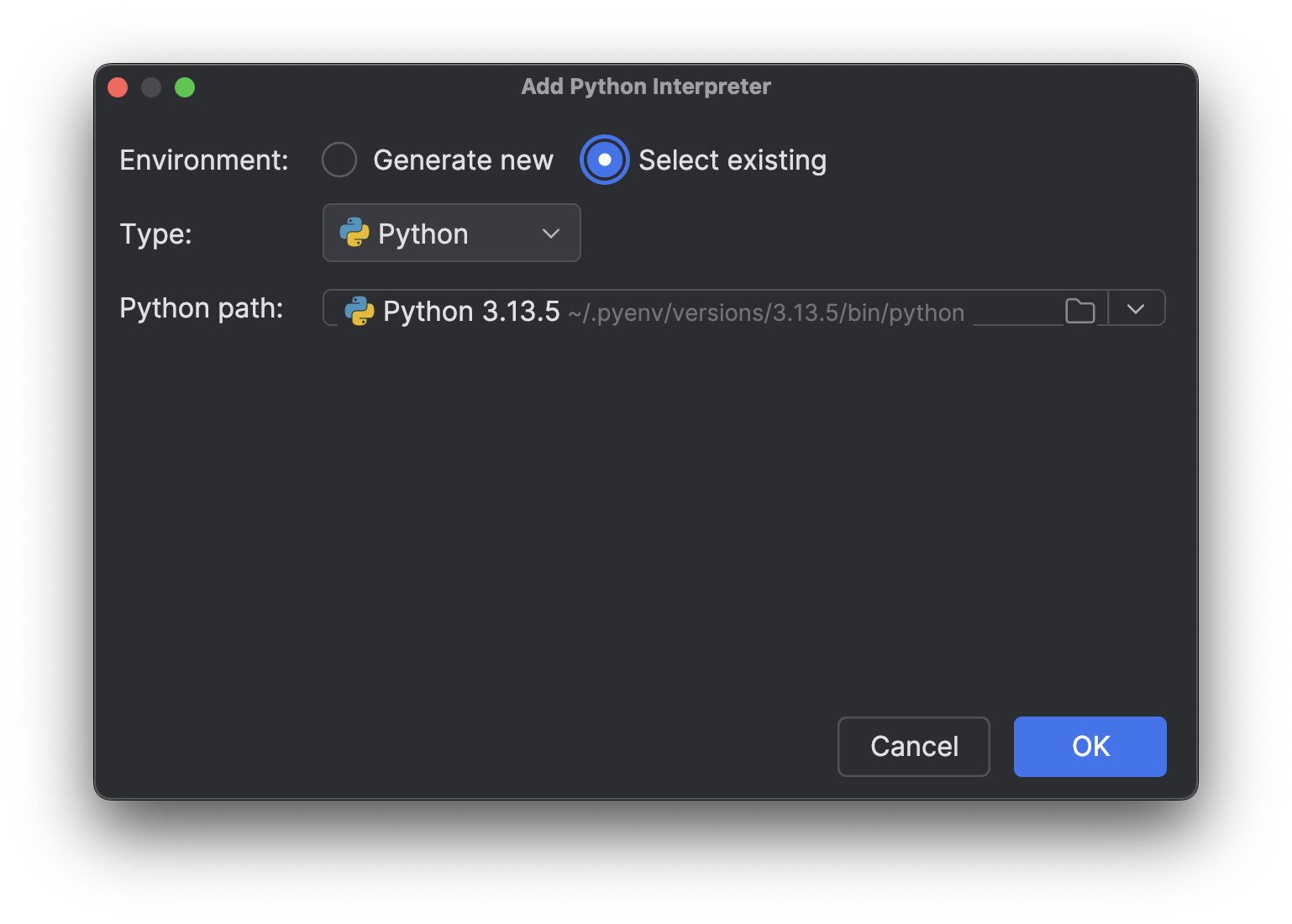
OK をクリックして追加します。 もう 1 つのインタープリターでも同じ手順を繰り返します。 右下のインタープリター名をもう一度クリックすると、上記の画像のように複数の Python 3.13 インタープリターが表示されます。
CPU バウンドなプロセスを使用したテスト
次に、複数の異なるバージョンをテストするためのスクリプトが必要です。 このブログ連載記事のパート 1 では、CPU バウンドなプロセスを高速化するには真のマルチスレッド処理が必要だと説明しました。 GIL を排除することで真のマルチスレッド処理が可能になり、Python が高速化されるかどうかを確認するには、複数のスレッドで CPU バウンドなプロセスを使用してテストすることができます。 以下は、Junie に生成してもらったスクリプトです(最終調整は私が行いました)。
import time
import multiprocessing # Kept for CPU count
from concurrent.futures import ThreadPoolExecutor
import sys
def is_prime(n):
"""Check if a number is prime (CPU-intensive operation)."""
if n <= 1:
return False
if n <= 3:
return True
if n % 2 == 0 or n % 3 == 0:
return False
i = 5
while i * i <= n:
if n % i == 0 or n % (i + 2) == 0:
return False
i += 6
return True
def count_primes(start, end):
"""Count prime numbers in a range."""
count = 0
for num in range(start, end):
if is_prime(num):
count += 1
return count
def run_single_thread(range_size, num_chunks):
"""Run the prime counting task in a single thread."""
chunk_size = range_size // num_chunks
total_count = 0
start_time = time.time()
for i in range(num_chunks):
start = i * chunk_size + 1
end = (i + 1) * chunk_size + 1 if i < num_chunks - 1 else range_size + 1
total_count += count_primes(start, end)
end_time = time.time()
return total_count, end_time - start_time
def thread_task(start, end):
"""Task function for threads."""
return count_primes(start, end)
def run_multi_thread(range_size, num_threads, num_chunks):
"""Run the prime counting task using multiple threads."""
chunk_size = range_size // num_chunks
total_count = 0
start_time = time.time()
with ThreadPoolExecutor(max_workers=num_threads) as executor:
futures = []
for i in range(num_chunks):
start = i * chunk_size + 1
end = (i + 1) * chunk_size + 1 if i < num_chunks - 1 else range_size + 1
futures.append(executor.submit(thread_task, start, end))
for future in futures:
total_count += future.result()
end_time = time.time()
return total_count, end_time - start_time
def main():
# Fixed parameters
range_size = 1000000 # Range of numbers to check for primes
num_chunks = 16 # Number of chunks to divide the work into
num_threads = 4 # Fixed number of threads for multi-threading test
print(f"Python version: {sys.version}")
print(f"CPU count: {multiprocessing.cpu_count()}")
print(f"Range size: {range_size}")
print(f"Number of chunks: {num_chunks}")
print("-" * 60)
# Run single-threaded version as baseline
print("Running single-threaded version (baseline)...")
count, single_time = run_single_thread(range_size, num_chunks)
print(f"Found {count} primes in {single_time:.4f} seconds")
print("-" * 60)
# Run multi-threaded version with fixed number of threads
print(f"Running multi-threaded version with {num_threads} threads...")
count, thread_time = run_multi_thread(range_size, num_threads, num_chunks)
speedup = single_time / thread_time
print(f"Found {count} primes in {thread_time:.4f} seconds (speedup: {speedup:.2f}x)")
print("-" * 60)
# Summary
print("SUMMARY:")
print(f"{'Threads':<10} {'Time (s)':<12} {'Speedup':<10}")
print(f"{'1 (baseline)':<10} {single_time:<12.4f} {'1.00x':<10}")
print(f"{num_threads:<10} {thread_time:<12.4f} {speedup:.2f}x")
if __name__ == "__main__":
main()
複数の異なる Python インタープリターでスクリプトを実行しやすくするため、Python プロジェクトにカスタム実行スクリプトを追加することができます。
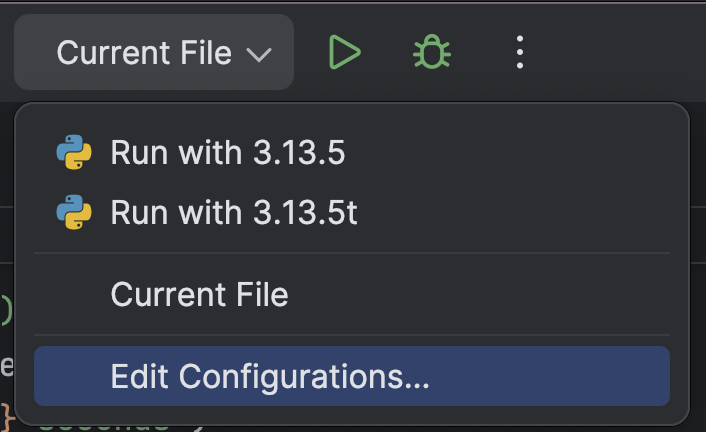
最上部の Run(実行、![]() )ボタンの横にあるドロップダウンから Edit Configurations…(構成の編集…)を選択します。
)ボタンの横にあるドロップダウンから Edit Configurations…(構成の編集…)を選択します。
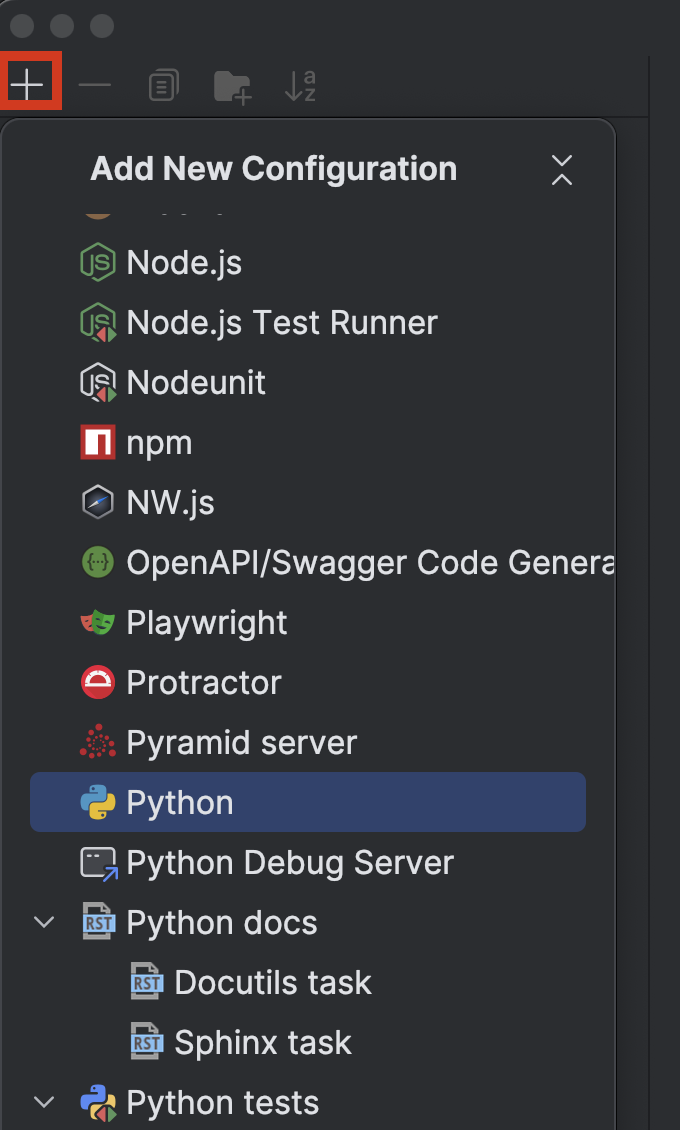
左上の + ボタンをクリックし、Add New Configuration(新規構成の追加)ドロップダウンメニューから Python を選択します。
具体的にどちらのインタープリター(3.13.5、3.15.3t など)が使用されているのか分かるような名前を決めます。 以下のように、適切なインタープリターを選択してテストスクリプトの名前を追加します。
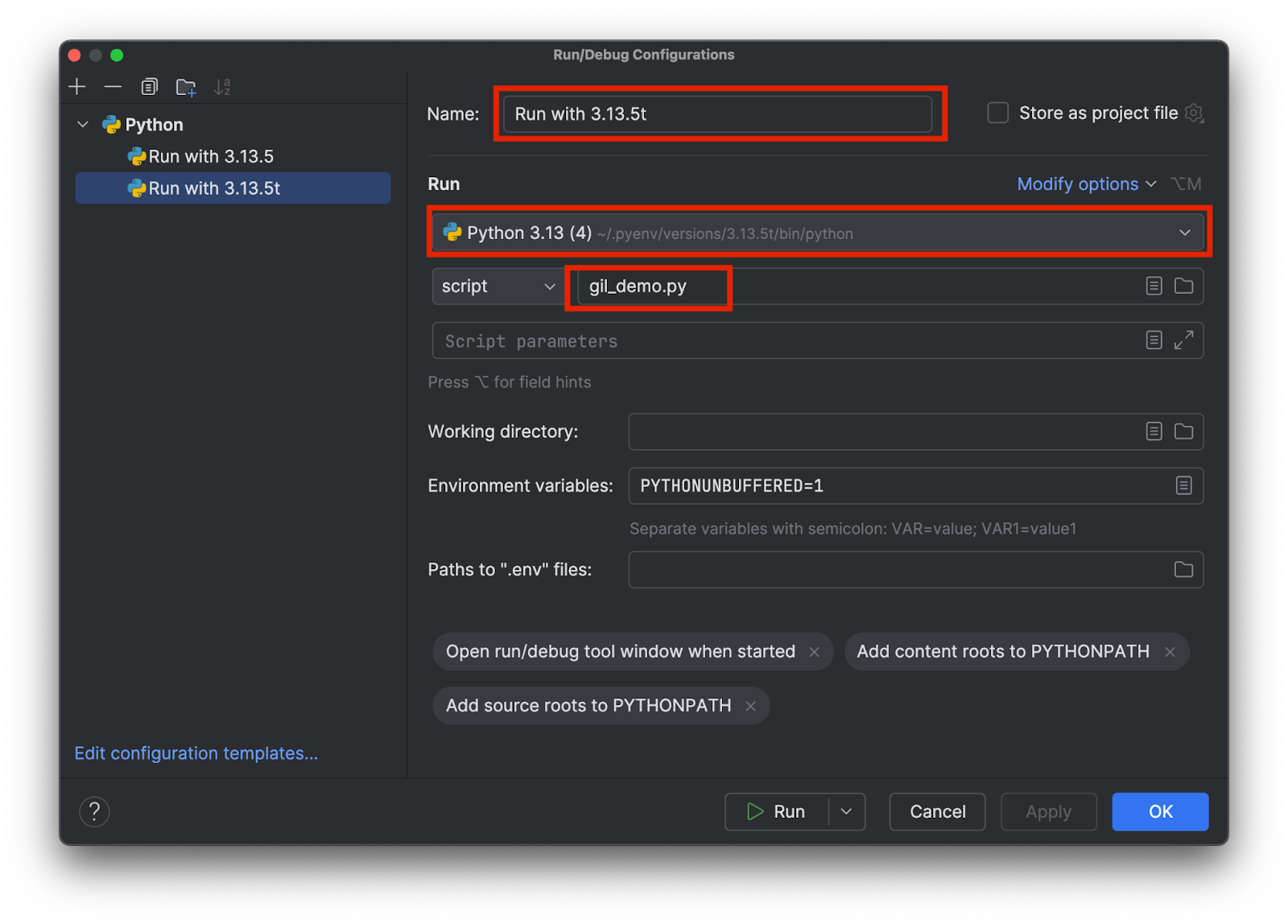
インタープリターごとに 1 つずつ、合計で 2 つの構成を追加します。 そして OK をクリックします。
構成を選択して上部の Run(実行、![]() )ボタンをクリックすることで、GIL の有無を問わずテストスクリプトを簡単に選択して実行できるようになりました。
)ボタンをクリックすることで、GIL の有無を問わずテストスクリプトを簡単に選択して実行できるようになりました。
結果の比較
GIL のある標準バージョンの 3.13.5 を実行すると、以下の結果が得られました。
Python version: 3.13.5 (main, Jul 10 2025, 20:33:15) [Clang 17.0.0 (clang-1700.0.13.5)] CPU count: 8 Range size: 1000000 Number of chunks: 16 ------------------------------------------------------------ Running single-threaded version (baseline)... Found 78498 primes in 1.1930 seconds ------------------------------------------------------------ Running multi-threaded version with 4 threads... Found 78498 primes in 1.2183 seconds (speedup: 0.98x) ------------------------------------------------------------ SUMMARY: Threads Time (s) Speedup 1 (baseline) 1.1930 1.00x 4 1.2183 0.98x
ご覧のように、このバージョンを 4 スレッドで実行した場合はシングルスレッドの基準から大きな変化はありません。 free-threaded バージョンの 3.13.5t を実行した場合を見てみましょう。
Python version: 3.13.5 experimental free-threading build (main, Jul 10 2025, 20:36:28) [Clang 17.0.0 (clang-1700.0.13.5)] CPU count: 8 Range size: 1000000 Number of chunks: 16 ------------------------------------------------------------ Running single-threaded version (baseline)... Found 78498 primes in 1.5869 seconds ------------------------------------------------------------ Running multi-threaded version with 4 threads... Found 78498 primes in 0.4662 seconds (speedup: 3.40x) ------------------------------------------------------------ SUMMARY: Threads Time (s) Speedup 1 (baseline) 1.5869 1.00x 4 0.4662 3.40x
今度は 3 倍以上の速度になりました。 どちらの場合もマルチスレッド処理のオーバーヘッドがあることに注意してください。 そのため、真のマルチスレッド処理であっても、4 スレッドでの速度は 4 倍になりません。
まとめ
Faster Python ブログ連載記事のパート 2 では、過去に Python GIL が導入された背景、multiprocessing を使用した GIL の制限の回避、およびGIL の排除プロセスとその効果について説明しました。
このブログ記事を投稿した時点では、Python の free-threaded バージョンはまだデフォルトになっていません。 ただし、コミュニティとサードパーティのライブラリの採用により、コミュニティでは Python の free-threaded バージョンが将来的に標準となることが期待されています。 Python 3.14 には実験的段階を終えた free-threaded バージョンが含まれると発表されてはいますが、現時点ではオプションです。
PyCharm は最高水準の Python のサポートを提供し、速度と精度の両方を確保しています。 最もスマートなコード補完、PEP 8 準拠チェック、インテリジェントなリファクタリング、および各種のインスペクションを活用し、コーディングのあらゆるニーズに対応することができます。 このブログ記事で紹介したように、PyCharm は Python インタープリターと実行構成の設定をカスタマイズ可能なため、数回クリックするだけでインタープリターを切り替え、幅広い Python プロジェクトに最適な環境にすることができます。
オリジナル(英語)ブログ投稿記事の作者:





