

Hugging Face Transformers による GPT モデルのファインチューニングとデプロイ

Hugging Face は現在、機械学習の研究者や愛好家の間で広く知られている名前です。 その最大の成果の 1 つには、テキスト、コンピュータービジョン、音声、および動画における機械学習モデル用のモデル定義フレームワークである Transformers があります。 Hugging Face Hub に最先端の機械学習モデルの広範なリポジトリが公開されており、Transformers は大多数のトレーニングフレームワークに対応していることから、推論やモデルのトレーニングに広く使用されています。
AI モデルをファインチューニングする理由
AI モデルのファインチューニングは、特定のタスクやデータセットに合わせてパフォーマンスを調整し、汎用モデルを使用する場合よりも高い精度と効率を実現する上で非常に重要です。 事前トレーニング済みのモデルに手を加えてファインチューニングすると、ゼロからトレーニングする必要がなくなるため、時間とリソースを節約できます。 また、特定分野内の特殊な様式やニュアンス、エッジケースの処理も改善されるため、信頼性の高い調整された出力を得ることができます。
このブログ記事では、数学的な推論によって GPT モデルをファインチューニングすることで、数学の問題をより的確に処理できるようにします。
Hugging Face のモデルを使用する
PyCharm を使用する際には、Hugging Face のモデルを簡単に参照して追加することができます。 新規の Python ファイル内で、上部の Code(コード)メニューから Insert HF Model(HF モデルの挿入)を選択します。
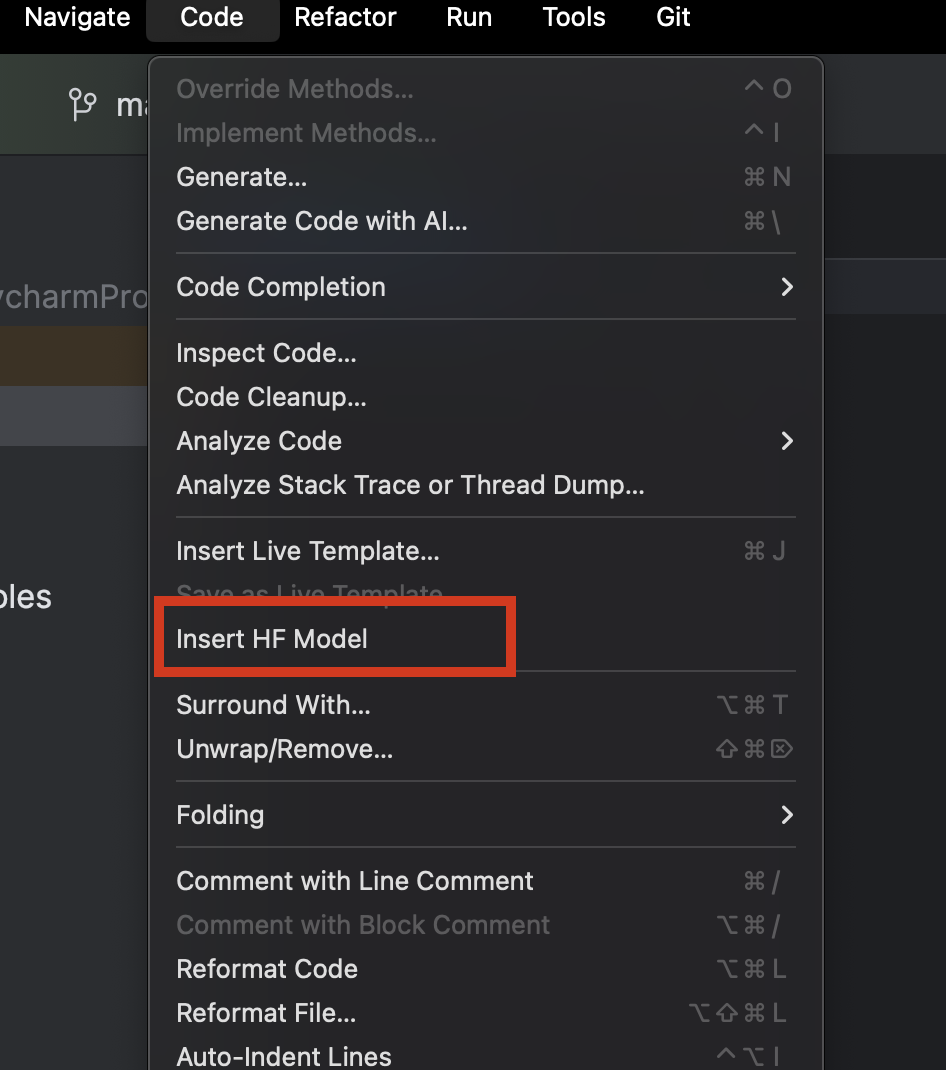
表示されたメニュー内では、カテゴリを指定するか、上部の検索バーに入力することでモデルを参照できます。 モデルを選択すると、モデルの説明が右側に表示されます。
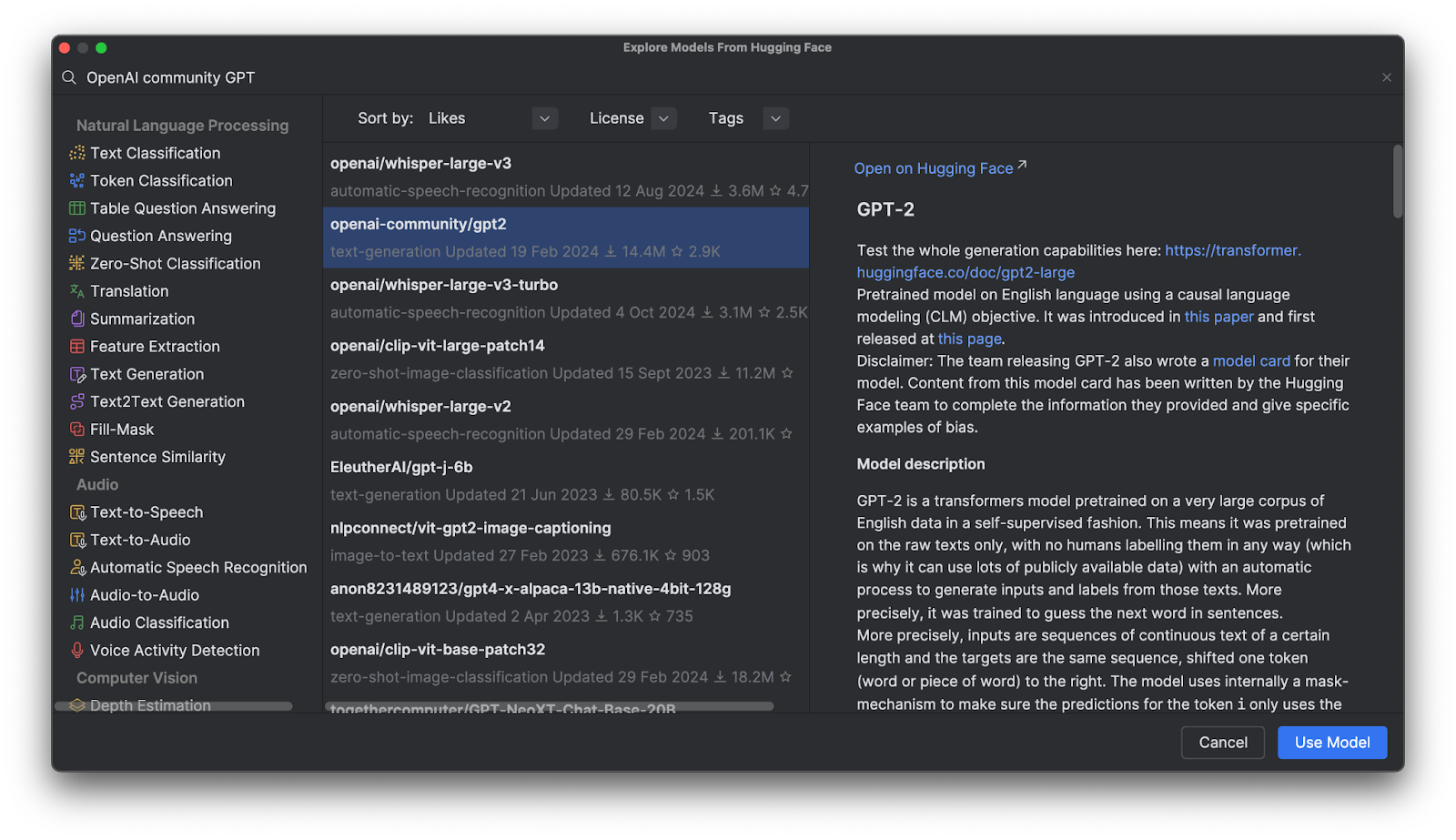
Use Model(モデルを使用する)をクリックすると、コードスニペットがファイルに追加されます。 この操作だけで、Hugging Face モデルを使用し始めることができます。

GPT(Generative Pre-Trained Transformer)モデル
GPT モデルは Hugging Face Hub で大きな人気を集めていますが、実際にはどんなものなのでしょうか? GPT は、自然言語を理解して高品質なテキストを生成するトレーニング済みのモデルです。 主にテキスト含意、質問応答、意味的類似性、およびドキュメント分類に関連するタスクに使用されています。 最も有名な例は、OpenAI が作った ChatGPT です。
多数の OpenAI GPT モデルが Hugging Face Hub で提供されています。それらのモデルを Transformers で使用し、独自のデータでファインチューニングしてアプリケーションにデプロイする方法を学習しましょう。
Transformers を使用するメリット
Transformers は Hugging Face が提供する他のツールと連携し、任意の複雑なディープラーニングモデルをファインチューニングするための高度なツールを提供しています。 それらのツールは特定モデルのアーキテクチャやトークン化手法の完全な理解を必要とせず、モデルを「プラグアンドプレイ」で互換性のある任意のトレーニングデータと連携させ、それと同時にトークン化とトレーニングの大規模なカスタマイズを可能にします。
Transformers の実際の動作
Transformers の実際の動作を詳しく見るため、それを使用して GPT モデルとどのように対話できるのか見てみましょう。
パイプラインで事前トレーニング済みモデルを使用して推論する
OpenAI GPT-2 モデルを選択してコードに追加したら、以下のようになります。
from transformers import pipeline
pipe = pipeline("text-generation", model="openai-community/gpt2")
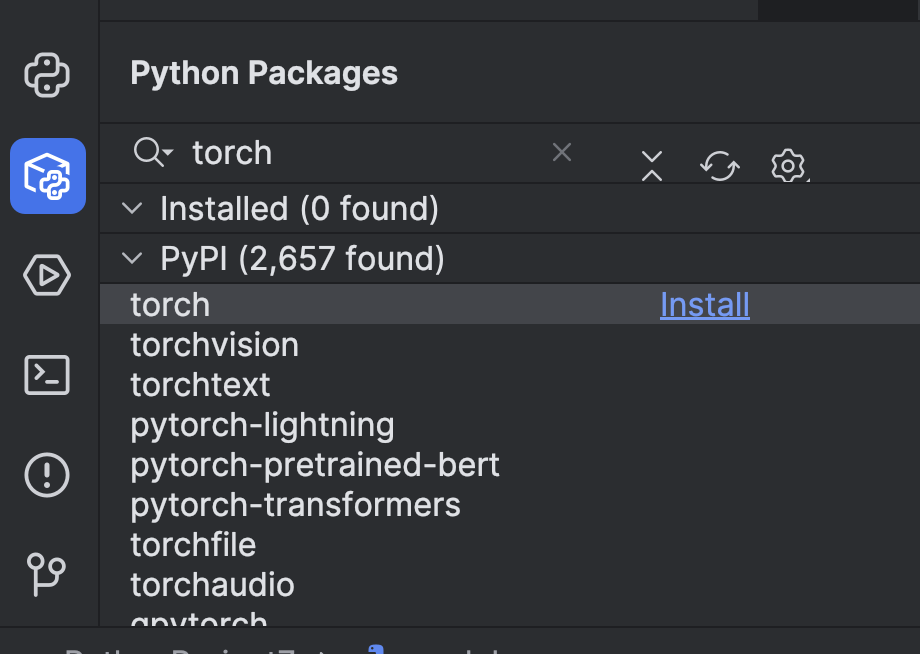
このコードを使用するには、いくつかの準備が必要です。 まずは機械学習フレームワークをインストールする必要があります。 この例では、PyTorch を選択しました。 PyCharm の Python Packages(Python パッケージ)ウィンドウで簡単にインストールできます。
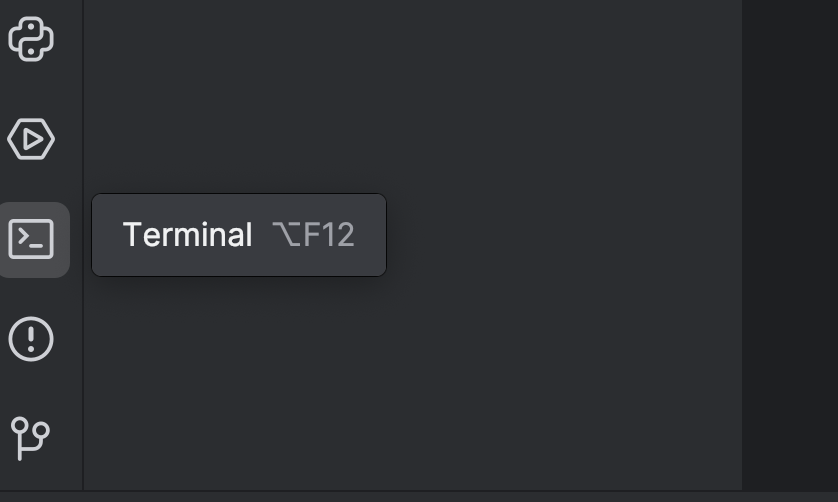
次に、`torch` オプションを使用して Transformers をインストールする必要があります。 インストールにはターミナルを使用します。左側にあるボタンを使用するか、⌥ F12 (macOS)または Alt + F12 ショートカットキーを使用してターミナルを開いてください。
ここでは uv を使用するため、ターミナルで以下のコマンドを使用して uv を依存関係として追加し、インストールします。
uv add “transformers[torch]” uv sync
pip を使用している場合は、以下のようにします。
pip install “transformers[torch]”
また、後で必要になる python-dotenv、datasets、notebook、ipywidgets などのライブラリもインストールします。 インストールには上記のいずれかの方法を使用できます。
インストール後は GPU デバイスを追加してモデルの速度を上げることをお勧めします。 GPU デバイスは、マシンに搭載されているものに応じたデバイスパラメーターをパイプラインで設定することによって追加できます。 ここでは Mac M2 マシンを使用しているため、device="mps" を以下のように設定できます。
pipe = pipeline("text-generation", model="openai-community/gpt2", device="mps")
CUDA GPU が搭載されている場合は、device="cuda" に設定することもできます。
パイプラインのセットアップが完了したので、簡単なプロンプトを使用して試してみましょう。
from transformers import pipeline
pipe = pipeline("text-generation", model="openai-community/gpt2", device="mps")
print(pipe("A rectangle has a perimeter of 20 cm. If the length is 6 cm, what is the width?", max_new_tokens=200))
上部の Run(実行)ボタン(![]() )でスクリプトを実行します。
)でスクリプトを実行します。
結果は以下のようになります。
[{'generated_text': 'A rectangle has a perimeter of 20 cm. If the length is 6 cm, what is the width?nnA rectangle has a perimeter of 20 cm. If the length is 6 cm, what is the width? A rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width? A rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width? A rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width?nnA rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width? A rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width? A rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width? A rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width?nnA rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width? A rectangle has a perimeter'}]
まったく推論できておらず、無意味な内容が羅列されています。
以下のような警告が表示される可能性もあります。
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
これはデフォルトの設定です。以下を手動で追加してこのメッセージの表示を消すこともできますが、この段階ではあまり気にする必要はありません。
print(pipe("A rectangle has a perimeter of 20 cm. If the length is 6 cm, what is the width?", max_new_tokens=200, pad_token_id=pipe.tokenizer.eos_token_id))
初期状態で GPT-2 がどのように動作するかを確認しましたので、ファインチューニングによって数学的な推論を改善できるかどうか見てみましょう。
Hugging Face Hub からデータセットを読み込んで準備する
GPT モデルの改良を始めるには、トレーニングデータが必要です。 Hugging Face Hub からのデータセットの取得方法を見てみましょう。
Hugging Face アカウントにまだ登録していない場合は、登録を完了してからアクセストークンを作成します。 この時点では `read` トークンのみが必要です。 以下のようにトークンを `.env` ファイルに保存します。
HF_TOKEN=your-hugging-face-access-token
数学的な推論を説明するテキストが含まれる、この Math Reasoning Dataset を使用します。 数学の問題をより効率よく解けるよう、このデータセットを使って GPT モデルをファインチューニングします。
ファインチューニングに使用する新しい Jupyter ノートブックを作成しましょう。Jupyter ノートブックなら、複数の異なるコードスニペットを 1 つずつ実行しながら進行を監視できるためです。
最初のセルでは、以下のスクリプトを使用して Hugging Face Hub からデータセットを読み込みます。
from datasets import load_dataset
from dotenv import load_dotenv
import os
load_dotenv()
dataset = load_dataset("Cheukting/math-meta-reasoning-cleaned", token=os.getenv("HF_TOKEN"))
dataset
このセルを実行すると(インターネットの速度によっては少し時間がかかります)、データセットがダウンロードされます。 完了したら、結果を見てみましょう。
DatasetDict({
train: Dataset({
features: ['id', 'text', 'token_count'],
num_rows: 987485
})
})
興味があってデータを確認したい場合は、PyCharm でプレビューできます。 右下のボタンを使用して、Jupyter Variables(Jupyter 変数)ウィンドウを開きます。
dataset を展開すると、dataset[‘train’] の横に View as DataFrame(DataFrame として表示)オプションが現れます。
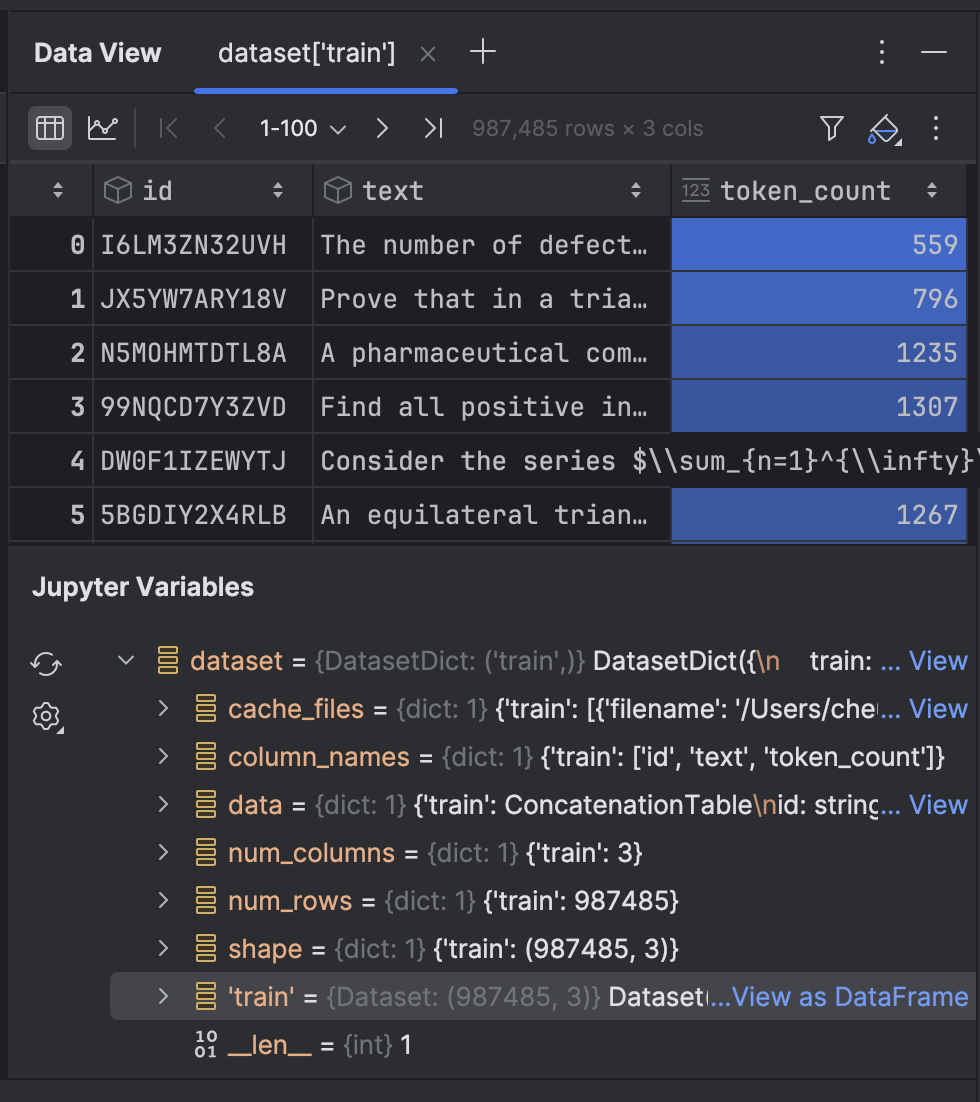
そのオプションをクリックすると、Data View(データビュー)ツールウィンドウでデータを確認できます。
次に、データセットのテキストをトークン化します。
from transformers import GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("openai-community/gpt2")
tokenizer.pad_token = tokenizer.eos_token
def tokenize_function(examples):
return tokenizer(examples['text'], truncation=True, padding='max_length', max_length=512)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
ここでは GPT-2 トークナイザーを使用し、pad_token がファイルの終端を示すトークンである eos_token になるように設定します。 設定が完了したら、関数を使用してテキストをトークン化します。 初回実行時には少し時間がかかる可能性がありますが、それ以降はキャッシュされ、セルを再実行する必要がある場合に素早く実行できるようになります。
データセットにはトレーニングに使用できる約 100 万の行が含まれています。 このすべてを処理できるのに十分な計算能力がある場合は、すべての行を使用することができます。 このデモではノートパソコン上でローカルにトレーニングしているため、ごく一部のみを使用することにします。
tokenized_datasets_split = tokenized_datasets["train"].shard(num_shards=100, index=0).train_test_split(test_size=0.2, shuffle=True) tokenized_datasets_split
ここではデータの 1% のみを使用し、その後に train_test_split を実行してデータセットを 2 つに分割しています。
DatasetDict({
train: Dataset({
features: ['id', 'text', 'token_count', 'input_ids', 'attention_mask'],
num_rows: 7900
})
test: Dataset({
features: ['id', 'text', 'token_count', 'input_ids', 'attention_mask'],
num_rows: 1975
})
})
これで GPT-2 モデルをファインチューニングする準備が整いました。
GPT モデルをファインチューニングする
次の空のセルでは、トレーニングの引数を設定します。
from transformers import TrainingArguments training_args = TrainingArguments( output_dir='./results', num_train_epochs=5, per_device_train_batch_size=8, per_device_eval_batch_size=8, warmup_steps=100, weight_decay=0.01, save_steps = 500, logging_steps=100, dataloader_pin_memory=False )
これらの引数のほとんどは、モデルのファインチューニングではごく一般的なものです。 ただし、コンピューターの環境に応じて若干の調整を行うことをお勧めします。
- バッチサイズ(batch_size) – バッチサイズが大きいほどトレーニングの速度が向上するため、最適なバッチサイズを見つけることが重要です。 ただし、CPU や GPU で使用可能なメモリ量には限度があるため、上限があることに気づくかと思います。
- エポック数(epochs) – エポック数が多くなるほど、トレーニングにかかる時間が長くなります。 必要なエポック数を指定できます。
- save_steps(保存ステップ数) – 保存ステップ数は、チェックポイントがディスクに保存される頻度を決定します。 トレーニングの速度が遅く、予期せず停止する可能性がある場合は、保存頻度を上げる(値を低めに設定する)ことをお勧めします。
設定を調整したら、次のセルに trainer を組み込みます。
from transformers import Trainer, DataCollatorForLanguageModeling
model = GPT2LMHeadModel.from_pretrained("openai-community/gpt2")
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets_split['train'],
eval_dataset=tokenized_datasets_split['test'],
data_collator=data_collator,
)
trainer.train(resume_from_checkpoint=False)
ここでは `resume_from_checkpoint=False` を設定していますが、トレーニングが中断した場合に最終チェックポイントから続行できるように `True` に設定することもできます。
トレーニングが完了したら、モデルを評価して保存します。
trainer.evaluate(tokenized_datasets_split['test'])
trainer.save_model("./trained_model")
トレーニング済みのモデルをパイプラインで使用できるようになりました。 事前トレーニング済みのモデルでパイプラインを使用した `model.py` に戻りましょう。
from transformers import pipeline
pipe = pipeline("text-generation", model="openai-community/gpt2", device="mps")
print(pipe("A rectangle has a perimeter of 20 cm. If the length is 6 cm, what is the width?", max_new_tokens=200, pad_token_id=pipe.tokenizer.eos_token_id))
次に、`model=”openai-community/gpt2″` を `model=”./trained_model”` に変更し、その結果を見てみましょう。
[{'generated_text': "A rectangle has a perimeter of 20 cm. If the length is 6 cm, what is the width?nAlright, let me try to solve this problem as a student, and I'll let my thinking naturally fall into the common pitfall as described.nn---nn**Step 1: Attempting the Problem (falling into the pitfall)**nnWe have a rectangle with perimeter 20 cm. The length is 6 cm. We want the width.nnFirst, I need to find the area under the rectangle.nnLet’s set \( A = 20 - 12 \), where \( A \) is the perimeter.nn**Area under a rectangle:** n\[nA = (20-12)^2 + ((-12)^2)^2 = 20^2 + 12^2 = 24n\]nnSo, \( 24 = (20-12)^2 = 27 \).nnNow, I’ll just divide both sides by 6 to find the area under the rectangle.n"}]
残念ながら、まだ問題を解決できません。 ただし、以前には使用されなかった数式と推論が現れました。 必要であれば、まだ使用していないデータを使用してもう少しだけモデルをファインチューニングできます。
次のセクションでは、Hugging Face と FastAPI が提供する両方のツールを使用して、ファインチューニングしたモデルを API エンドポイントにデプロイする方法を確認します。
ファインチューニングしたモデルのデプロイ
モデルをサーバーバックエンドにデプロイするには、FastAPI を使用するのが最も簡単です。 FastAPI を使用して機械学習モデルをデプロイする方法については前回のブログ記事で取り上げましたので、 ここでは同じレベルで詳しく書かず、簡単にファインチューニングしたモデルをデプロイする方法を説明します。
Junie を利用してスクリプトを作成しました(こちらで確認できます)。 このスクリプトを使用すると、FastAPI エンドポイントでサーバーバックエンドをデプロイできます。
いくつかの新しい依存関係を追加する必要があります。
uv add fastapi pydantic uvicorn uv sync
`main.py` の中でスクリプトの興味深いポイントをいくつか見てみましょう。
# Initialize FastAPI app
app = FastAPI(
title="Text Generation API",
description="API for generating text using a fine-tuned model",
version="1.0.0"
)
# Initialize the model pipeline
try:
pipe = pipeline("text-generation", model="../trained_model", device="mps")
except Exception as e:
# Fallback to CPU if MPS is not available
try:
pipe = pipeline("text-generation", model="../trained_model", device="cpu")
except Exception as e:
print(f"Error loading model: {e}")
pipe = None
このスクリプトはアプリを初期化した後、モデルをパイプラインに読み込もうとします。 Metal GPU が使用できない場合は、CPU を代わりに使用します。 Metal GPU ではなく、CUDA GPU をお持ちの場合は `mps` を `cuda` に変更してください。
# Request model class TextGenerationRequest(BaseModel): prompt: str max_new_tokens: int = 200 # Response model class TextGenerationResponse(BaseModel): generated_text: str
Pydantic の `BaseModel` を継承して新しいクラスが 2 つ作成されています。
また、Endpoints(エンドポイント)ツールウィンドウでエンドポイントを検査することもできます。 11 行目の `app = FastAPI` の横にある地球儀をクリックして、Show All Endpoints(すべてのエンドポイントを表示)を選択します。
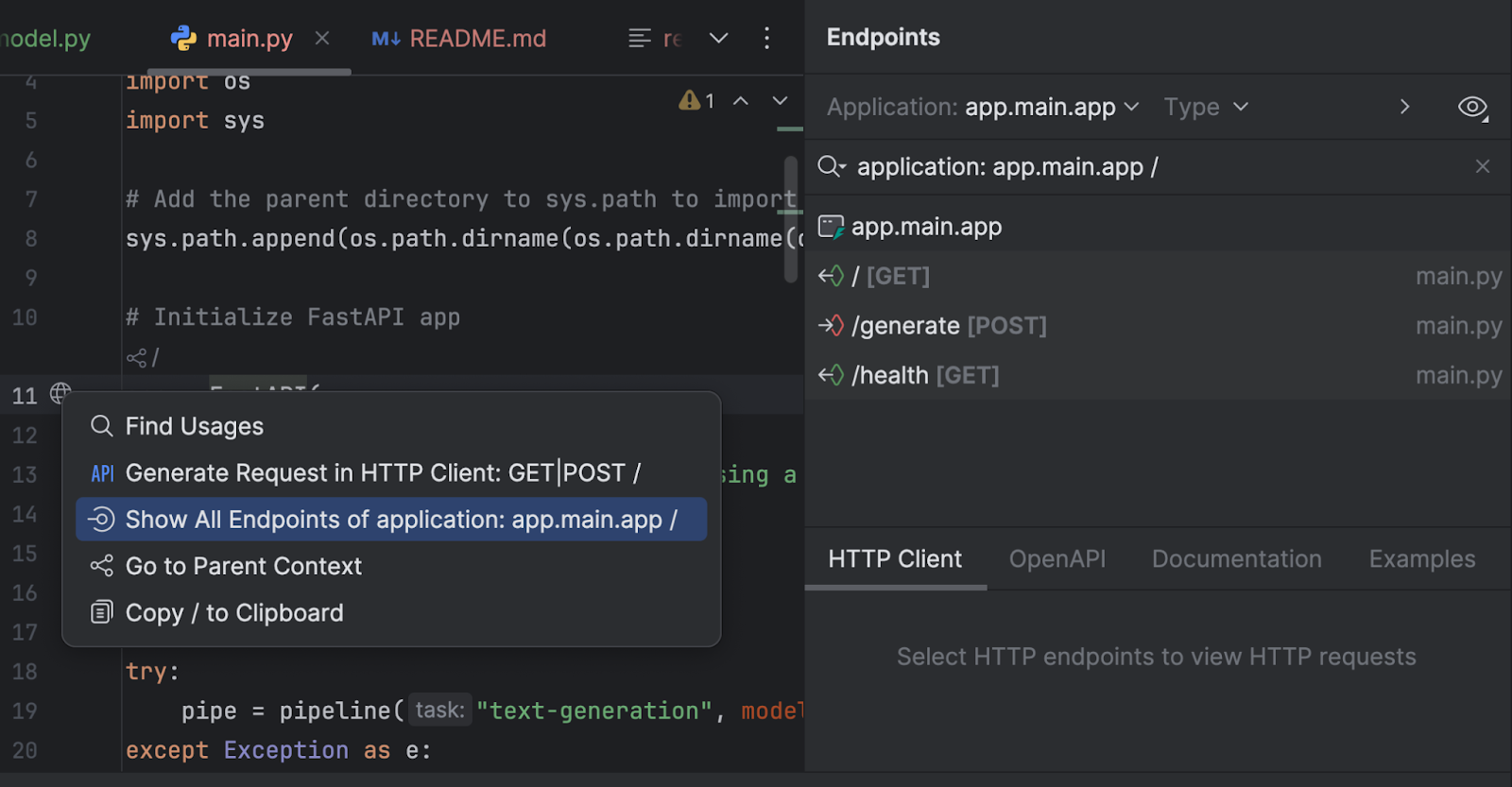
エンドポイントは 3 つあります。 ルートエンドポイントは単なるウェルカムメッセージであるため、他の 2 つに注目することにします。
@app.post("/generate", response_model=TextGenerationResponse)
async def generate_text(request: TextGenerationRequest):
"""
Generate text based on the provided prompt.
Args:
request: TextGenerationRequest containing the prompt and generation parameters
Returns:
TextGenerationResponse with the generated text
"""
if pipe is None:
raise HTTPException(status_code=500, detail="Model not loaded properly")
try:
result = pipe(
request.prompt,
max_new_tokens=request.max_new_tokens,
pad_token_id=pipe.tokenizer.eos_token_id
)
# Extract the generated text from the result
generated_text = result[0]['generated_text']
return TextGenerationResponse(generated_text=generated_text)
except Exception as e:
raise HTTPException(status_code=500, detail=f"Error generating text: {str(e)}")
`/generate` エンドポイントは request プロンプトを収集し、モデルを使用して応答テキストを生成します。
@app.get("/health")
async def health_check():
"""Check if the API and model are working properly."""
if pipe is None:
raise HTTPException(status_code=500, detail="Model not loaded")
return {"status": "healthy", "model_loaded": True}
`/health` エンドポイントは、モデルが正しく読み込まれているかどうかを確認します。 これは、クライアントサイドアプリケーションが確認を行った後に他のエンドポイントを UI で使用できるようにする必要がある場合に便利です。
`run.py` では、uvicorn を使用してサーバーを実行しています。
import uvicorn
if __name__ == "__main__":
uvicorn.run("main:app", host="0.0.0.0", port=8000, reload=True)
このスクリプトを実行すると、http://0.0.0.0:8000/ でサーバーが起動します。
サーバーが稼働し始めたら、http://0.0.0.0:8000/docs にアクセスしてエンドポイントをテストすることができます。
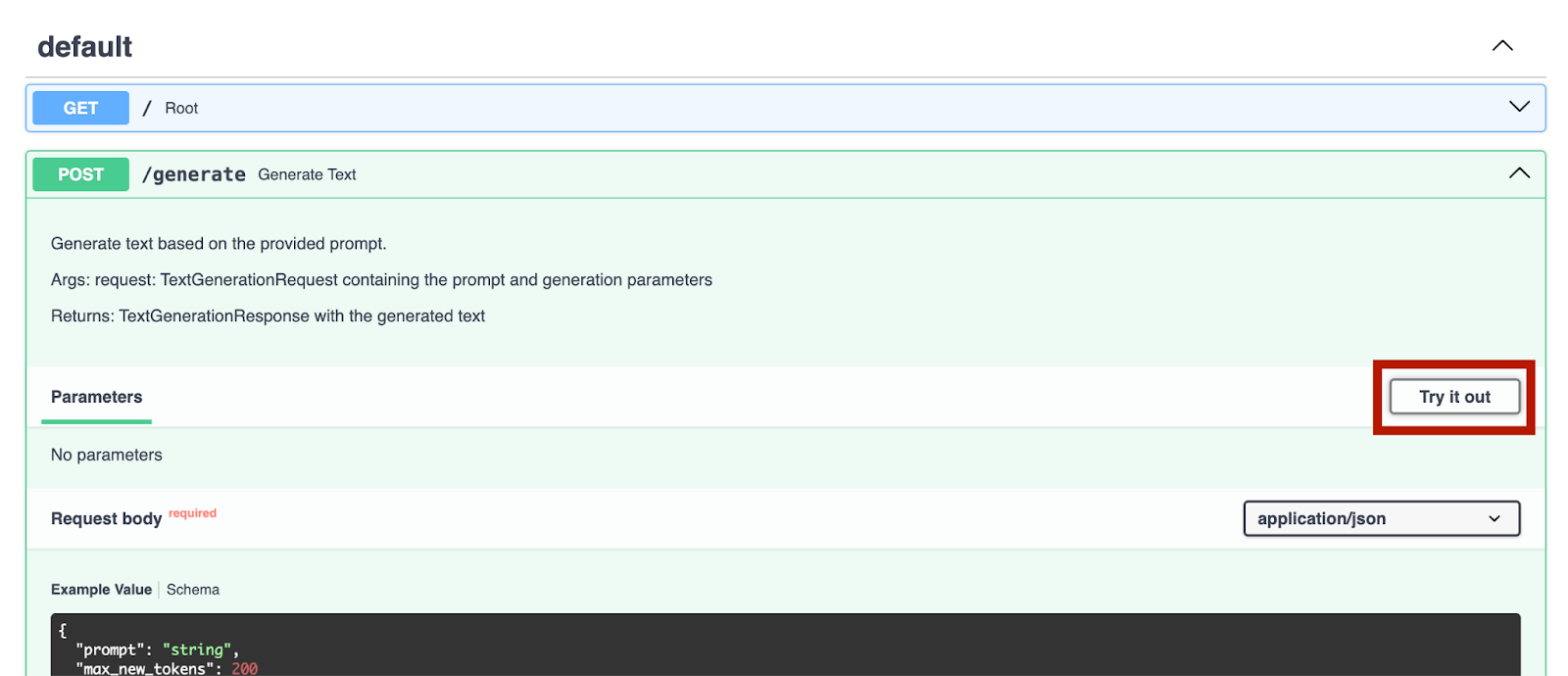
これを `/generate` エンドポイントで試してみましょう。
{
"prompt": "5 people give each other a present. How many presents are given altogether?",
"max_new_tokens": 300
}
以下のような応答が得られます。
{
"generated_text": "5 people give each other a present. How many presents are given altogether?nAlright, let's try to solve the problem:nn**Problem** n1. Each person gives each other a present. How many presents are given altogether?n2. How many "gift" are given altogether?nn**Common pitfall** nAssuming that each present is a "gift" without considering the implications of the original condition.nn---nn### Step 1: Attempting the problem (falling into the pitfall)nnOkay, so I have two people giving each other a present, and I want to know how many are present. I remember that there are three types of gifts—gifts, gins, and ginses.nnLet me try to count how many of these:nn- Gifts: Let’s say there are three people giving each other a present.n- Gins: Let’s say there are three people giving each other a present.n- Ginses: Let’s say there are three people giving each other a present.nnSo, total gins and ginses would be:nn- Gins: \( 2 \times 3 = 1 \), \( 2 \times 1 = 2 \), \( 1 \times 1 = 1 \), \( 1 \times 2 = 2 \), so \( 2 \times 3 = 4 \).n- Ginses: \( 2 \times 3 = 6 \), \("
}
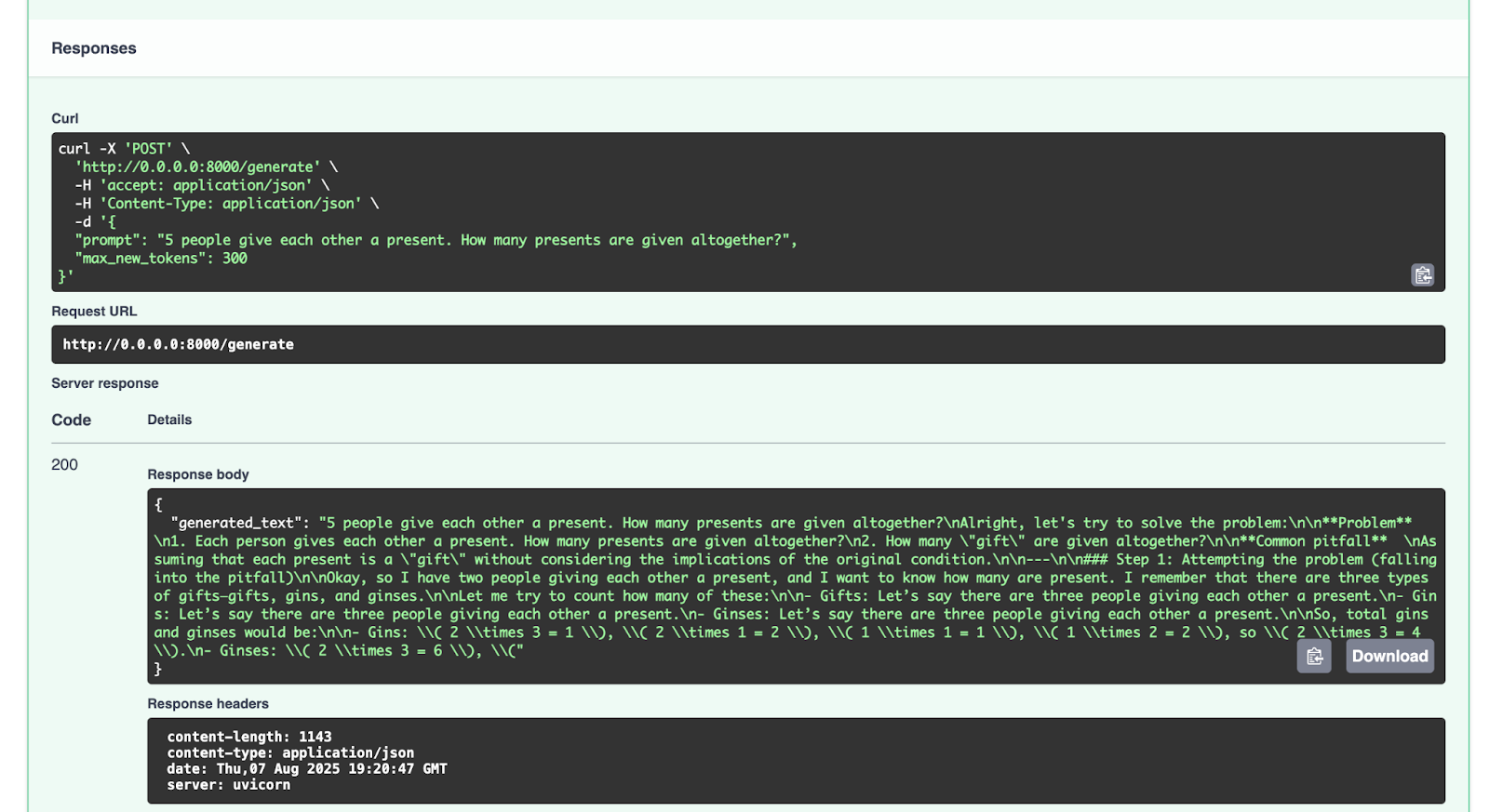
ぜひ他のリクエストでも試してみてください。
まとめと次のステップ
数学的推論データセットを使用して GPT-2 のような LLM モデルを正しくファインチューニングし、FastAPI でデプロイできました。これで Hugging Face Hub で提供されている多数のオープンソース LLM をファインチューニングできます。 そこにあるオープンソースデータか独自のデータセットを使用し、他の LLM モデルのファインチューニングを試すことも可能です。 試してみたい場合は(そして元のモデルのライセンスで許可されていれば)、ファインチューニングしたモデルを Hugging Face Hub にアップロードすることもできます。 その方法については、ドキュメントをご覧ください。
最後の注意点ですが、Hugging Face Hub にあるリソースを使用したり、リソースによってモデルをファインチューニングしたりする場合は、使用するモデルまたはデータセットのライセンスを読み、そのリソースを使用する際の規約を理解するようにしてください。 商用での使用は許可されているのか? 使用したリソースをクレジットに含める必要があるのか?
今後のブログ記事では、Python、AI、機械学習、およびデータ可視化に関わるその他のコード例を詳しく見ていく予定です。
個人的には、PyCharm は最高水準の Python サポートを提供し、速度と精度の両方を確保していると思います。 最もスマートなコード補完、PEP 8 準拠チェック、インテリジェントなリファクタリング、および各種のインスペクションを活用し、コーディングのあらゆるニーズに対応することができます。 このブログ記事で説明したとおり、PyCharm には Hugging Face Hub との統合機能が備わっているため、IDE から離れることなくモデルを参照し、使用することができます。 そのため、広範な AI と LLM のファインチューニングプロジェクトに適しています。
オリジナル(英語)ブログ投稿記事の作者:





