

JetBrains AI
Supercharge your tools with AI-powered features inside many JetBrains products
Kotlin으로 AI 에이전트 구축하기 – 3부: 관찰 가능성 확보

이전 시리즈:
2개의 글을 거치면서 코딩 에이전트가 꽤 일을 수행할 수 있게 되었습니다. 프로젝트 구조를 파악하고 코드를 작성하며 셸 명령어 및 테스트를 실행할 수 있습니다. 지난 글에서는 완료 정의(DoD)를 추가한 덕분에 에이전트가 완성도 높은 피드백 루프까지 갖추게 되어 이제 임의의 시점에 프로세스를 종료하지 않고 모든 테스트가 통과할 때까지 반복 처리합니다.
그럼 이제 다 된 걸까요? 꼭 그렇지만은 않습니다.
에이전트의 능력이 확장될수록 디버그도 복잡해집니다. 도구가 추가될 때마다 관리할 부분도 늘어나기 때문입니다. DoD 루프는 호출과 토큰의 증가로 이어집니다. 평가 실행은 몇 시간씩 걸릴 수 있으며, 문제가 발생했을 때 무엇이 실패했는지 또는 어디에서 문제가 시작되었는지를 파악하기 어려운 경우가 많습니다.
에이전트는 이제 작업을 처리할 수 있게 되었습니다. 하지만 그 처리 방법은 보이지 않습니다.
이러한 불투명성은 에이전트의 성능을 개선하고, 실패를 디버그하며, 비용을 정확히 추정할 때 문제가 됩니다. 이번 글에서는 이 가시성 격차를 해소해 보겠습니다. 먼저 가장 쉽게 떠올릴 수 있는 방법(완벽한 해결책은 아님)부터 살펴보고, LLM 애플리케이션을 위한 일반적인 관찰 가능성 도구를 검토한 뒤, Langfuse를 사용해 추적을 통합해 보겠습니다. 이렇게 하면 에이전트의 액션을 액션별 발생 비용과 함께 단계별로 파악할 수 있습니다. 이 과정에서 에이전트의 행동 패턴을 파악하는 것은 물론, 미처 몰랐던 버그까지 잡아낼 수 있습니다.
먼저 놓치고 있었던 부분이 무엇인지 짚어보겠습니다.
에이전트의 여정
에이전트는 코딩 작업을 수행하며 파일 읽기, 함수 분석, 코드 수정, 테스트 실행 등 수많은 결정과 액션을 취합니다. 이러한 체인은 에이전트의 궤적이 되어, 에이전트가 실제로 어떻게 업무를 처리하는지 생생하게 보여줍니다.
이 궤적을 추적하면 에이전트가 어디서 시간을 허비하고, 어느 지점에서 의도와 다르게 작동하는지 명확히 알 수 있습니다. 이 궤적을 통해 에이전트가 동일한 파일을 47번이나 읽는 시점이나 단순한 버그 수정 요청에 코드베이스의 절반을 다시 작성하는 이유를 알 수 있습니다. 요컨대, 관찰할 수 없는 것은 개선할 수 없습니다.
지금까지는 다음과 같은 단순한 설정으로 운영해 왔습니다.
handleEvents {
onToolCallStarting { ctx ->
println("Tool '${ctx.tool.name}' called with args: ${ctx.toolArgs.toString().take(100)}")
}
}
초기 단계에서는 이 정도로도 충분했습니다. 활동 여부만 알면 됐으니까요. 하지만 이제는 그 단계를 넘어섰습니다. 전체 매개변수와 관찰 없이는, 에이전트의 동작을 충분히 상세하게 이해할 수 없습니다. 그리고 모든 것을 출력해 버리면, 콘솔은 객체 덤프, 파일 내용, 오류 메시지가 뒤섞인 노이즈 상태가 됩니다.
이제는 더 나은 무언가가 필요합니다.
‘일단 로깅부터 켜기’
우선 당연해 보이는 해결책부터 시도해 봅시다. Koog에는 디버그 로깅이 내장되어 있으므로 다음과 같이 Logback을 ERROR에서 DEBUG로 전환하고 다시 실행합니다.
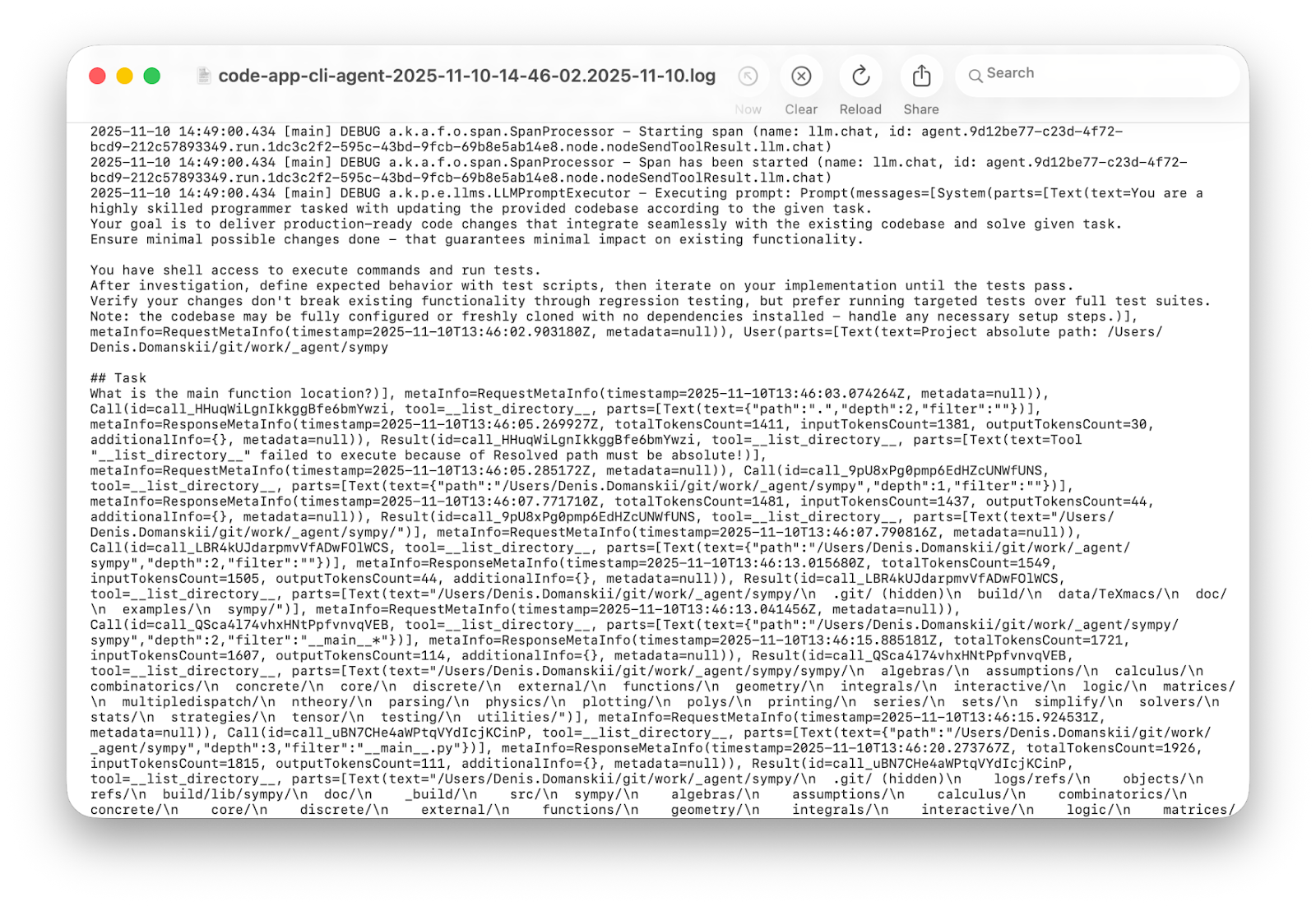
3분이 지나고 수천 줄의 로그가 쌓였습니다. 과연 유용할까요? 예. 매우 편리하죠? 아니요!
상세 로그에도 나름의 쓰임새는 있습니다. 프로덕션 환경에서는 사후 분석에 도움이 됩니다. 또한 여러 번의 실행에 걸쳐 인사이트를 추출하고 행동 패턴을 분석하고 싶을 때도 도움이 됩니다. 하지만 단일 실행을 디버그하면서 에이전트가 왜 루프에 빠졌는지를 이해하려는 상황에서는, 통계 분석용이 아닌 사람을 위해 설계된 무언가가 필요합니다.
비용 추적
이러한 로그는 디버그에는 적합하지 않지만, 추적해야 할 또 다른 요소가 있다는 점을 상기시켜 주었습니다. 바로 사용량 통계입니다. OpenAI 대시보드는 키별 API 소비 내역을 상세하게 보여줍니다. 예산이 빠르게 소진되고 있는지 여부를 빠르게 파악할 수 있죠.
그러나 개발에서 중요한 질문인 한 번 실행할 때 발생하는 비용에 대한 답은 여전히 알 수 없습니다.
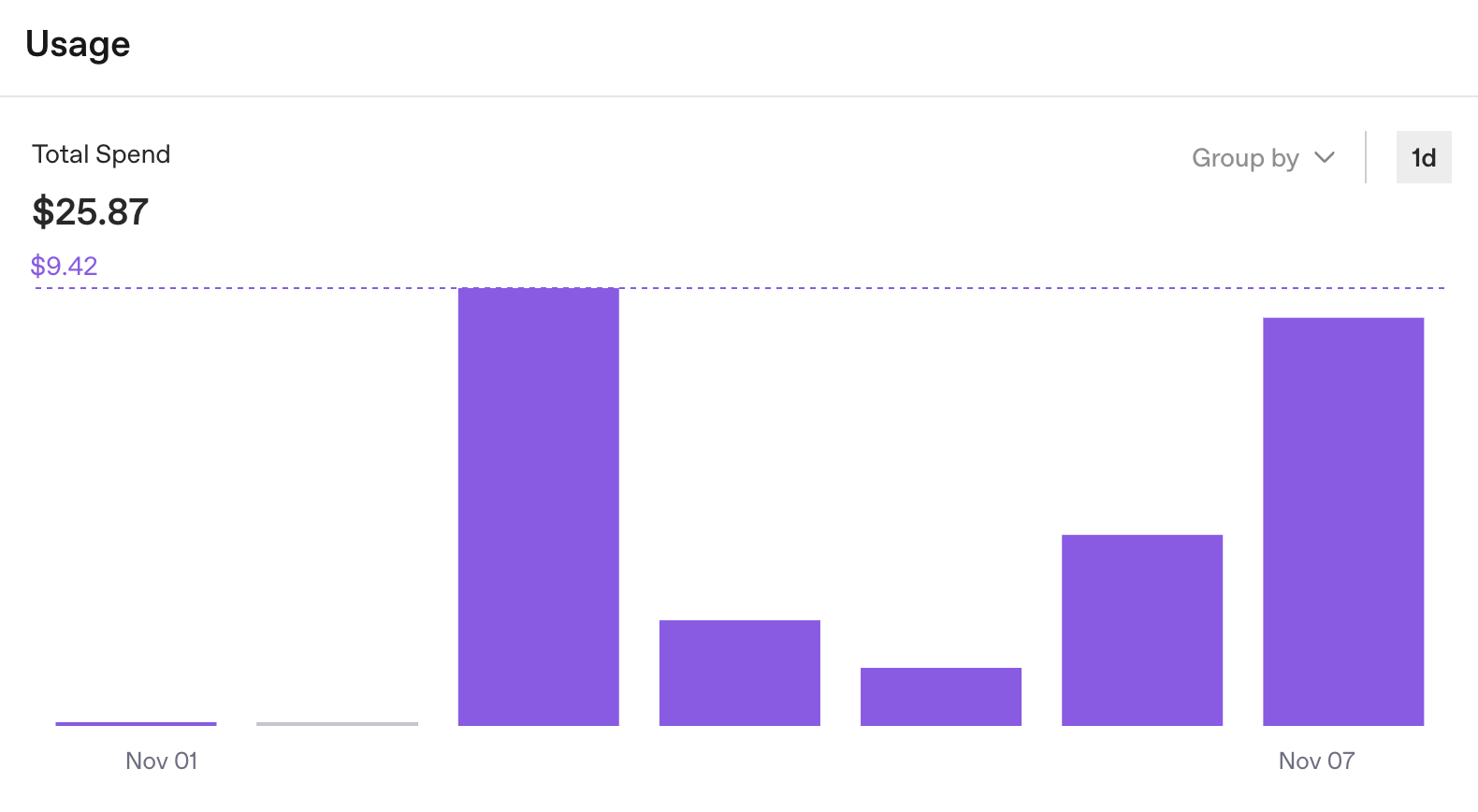
일주일에 25달러가 들었다는 정보는 유용하지만, 이것만으로는 충분하지 않습니다. OpenAI 대시보드는 본연의 목적에 충실하게 조직 차원의 API 사용량을 추적합니다. 하지만 에이전트 개발을 위해서는 실행 수준의 인사이트가 필요합니다. 총 비용은 있지만, 어떤 작업에 0.50달러가 들고 어떤 작업에 5.00달러가 드는지는 알 수 없습니다.
이제 더 많은 변동 요소를 추가해 보겠습니다. 작업을 서브 에이전트로 분리하고 특정 단계마다 서로 다른 공급자를 사용하면(이는 이후 글에서 다룰 예정입니다), 여러 대시보드가 생기고 단일 실행의 실제 비용을 한눈에 파악할 수 없게 됩니다. 그리고 여러 사람이 동일한 에이전트 설정을 공유하면, 누가, 어디에, 무엇을 썼는지 확인하기가 더욱 어려워집니다.
API 키 접근 방식은 하나의 에이전트, 하나의 공급자, 제한된 실행 횟수일 때는 작동합니다. 이것은 시작이지만 확장성은 없습니다. 따라서 관찰 가능성이 필요합니다.
네 줄의 통합
이 문제를 겪은 것은 우리가 처음이 아닙니다. 지난 몇 년 동안 LLM 앱과 에이전트를 중심으로 관찰 가능성 도구 에코시스템이 형성되었습니다. Weights & Biases Weave, LangSmith와 같은 상용 도구가 있고 Langfuse, Opik, Arize Phoenix, OpenLLMetry, Helicone, OpenLIT, Lunary처럼 오픈소스 옵션도 있습니다. 일부는 클라우드 기반이고, 일부는 셀프 호스팅을 지원하며, 어떤 것들은 두 가지를 모두 제공합니다. 도구는 저마다의 장점과 단점을 가지고 있습니다.
다양한 솔루션을 검토한 끝에, JetBrains 팀은 Langfuse를 선택했습니다. 결정은 실용적 요인 때문이었습니다. 셀프 호스팅 옵션을 제공하는 오픈소스여서 추적을 직접 통제할 수 있고, 시작하기 좋은 무료 클라우드 등급이 있으며, 추적을 살펴보기 쉬운 UI를 갖추고 있고, 문의 시 팀의 대응도 빠르다는 점 역시 고려 사항이었습니다.
통합 자체도 간단합니다. Koog에서 Langfuse를 연결하려면 다음 네 줄의 코드가 필요합니다.
) {
+ install(OpenTelemetry) {
+ setVerbose(true)
+ addLangfuseExporter()
+ }
handleEvents {
// existing handlers remain
}
}
이게 끝입니다.
setVerbose(true)에 대해 한 가지 말씀드리면, Koog는 보안을 위해 기본적으로 텔레메트리 메타데이터만 전송합니다. 전체 상세 데이터는 상세 모드를 활성화할 때만 전송됩니다. 추적 데이터에는 고객 정보가 포함될 수 있으므로 프롬프트와 응답을 기본적으로 비공개 처리하는 것이 맞습니다. 하지만 에이전트 개발 단계에서는 전체 가시성이 필요할 때가 많고 상세 모드로 이를 해결할 수 있습니다.
Langfuse 설정은 5분이면 충분합니다. 이 글에서는 해당 서비스의 무료 클라우드 인스턴스를 사용하지만, Docker에서 풀 스택을 로컬로 실행할 수도 있습니다.
- cloud.langfuse.com에서 계정을 생성합니다.
- 조직을 생성합니다.
- 프로젝트 생성.
- Create API Key(API 키 생성)를 클릭합니다.
그러면 다음 세 가지 값을 얻을 수 있습니다.
export LANGFUSE_HOST="https://cloud.langfuse.com" export LANGFUSE_PUBLIC_KEY="" export LANGFUSE_SECRET_KEY=""
Koog는 실행 환경에서 이 값을 읽습니다. 코드에서 이를 전달해야 하는 경우, addLangfuseExporter에 직접 전달할 수 있습니다. 이제 관찰 가능성이 완벽하게 갖춰진 에이전트가 준비되었습니다.
val executor = simpleOpenAIExecutor(System.getenv("OPENAI_API_KEY"))
val agent = AIAgent(
promptExecutor = executor,
llmModel = OpenAIModels.Chat.GPT5Codex,
toolRegistry = ToolRegistry {
tool(ListDirectoryTool(JVMFileSystemProvider.ReadOnly))
tool(ReadFileTool(JVMFileSystemProvider.ReadOnly))
tool(EditFileTool(JVMFileSystemProvider.ReadWrite))
tool(ExecuteShellCommandTool(JvmShellCommandExecutor(), PrintShellCommandConfirmationHandler()))
},
systemPrompt = """
You are a highly skilled programmer tasked with updating the provided codebase according to the given task.
Your goal is to deliver production-ready code changes that integrate seamlessly with the existing codebase and solve given task.
Ensure minimal possible changes done - that guarantees minimal impact on existing functionality.
You have shell access to execute commands and run tests.
After investigation, define expected behavior with test scripts, then iterate on your implementation until the tests pass.
Verify your changes don't break existing functionality through regression testing, but prefer running targeted tests over full test suites.
Note: the codebase may be fully configured or freshly cloned with no dependencies installed - handle any necessary setup steps.
""".trimIndent(),
strategy = singleRunStrategy(ToolCalls.SEQUENTIAL),
maxIterations = 400
) {
install(OpenTelemetry) {
setVerbose(true) // Send full strings instead of HIDDEN placeholders
addLangfuseExporter()
}
handleEvents {
onToolCallStarting { ctx ->
println("Tool '${ctx.tool.name}' called with args: ${ctx.toolArgs.toString().take(100)}")
}
}
}
첫 번째 트레이싱 결과 확인하기
간단한 작업부터 시작해 봅시다. 프로젝트에서 main() 함수를 찾으세요. 이를 실행해 완료될 때까지 기다린 다음, Langfuse 프로젝트에서 Tracing(추적) 탭을 여세요.
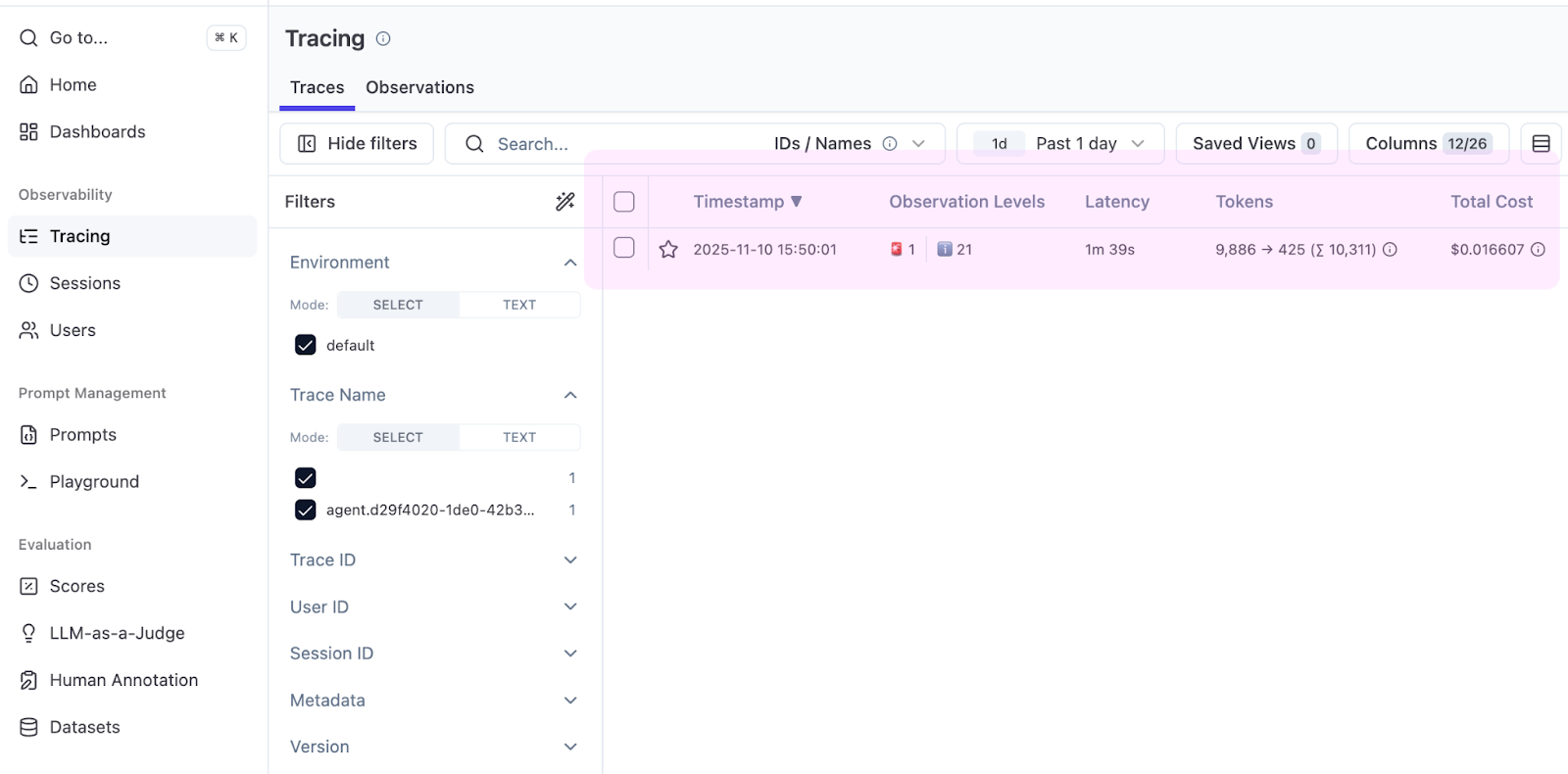
즉시 표에 유용한 정보가 표시됩니다. 바로 Total Cost(총 비용) 열입니다. Koog는 토큰 수를 보고하고, Langfuse는 가격을 적용하며, 그 결과 main() 함수를 찾는 데 드는 비용이 $0.016임을 확인할 수 있습니다.
추적을 열어 전체 실행을 살펴봅니다.
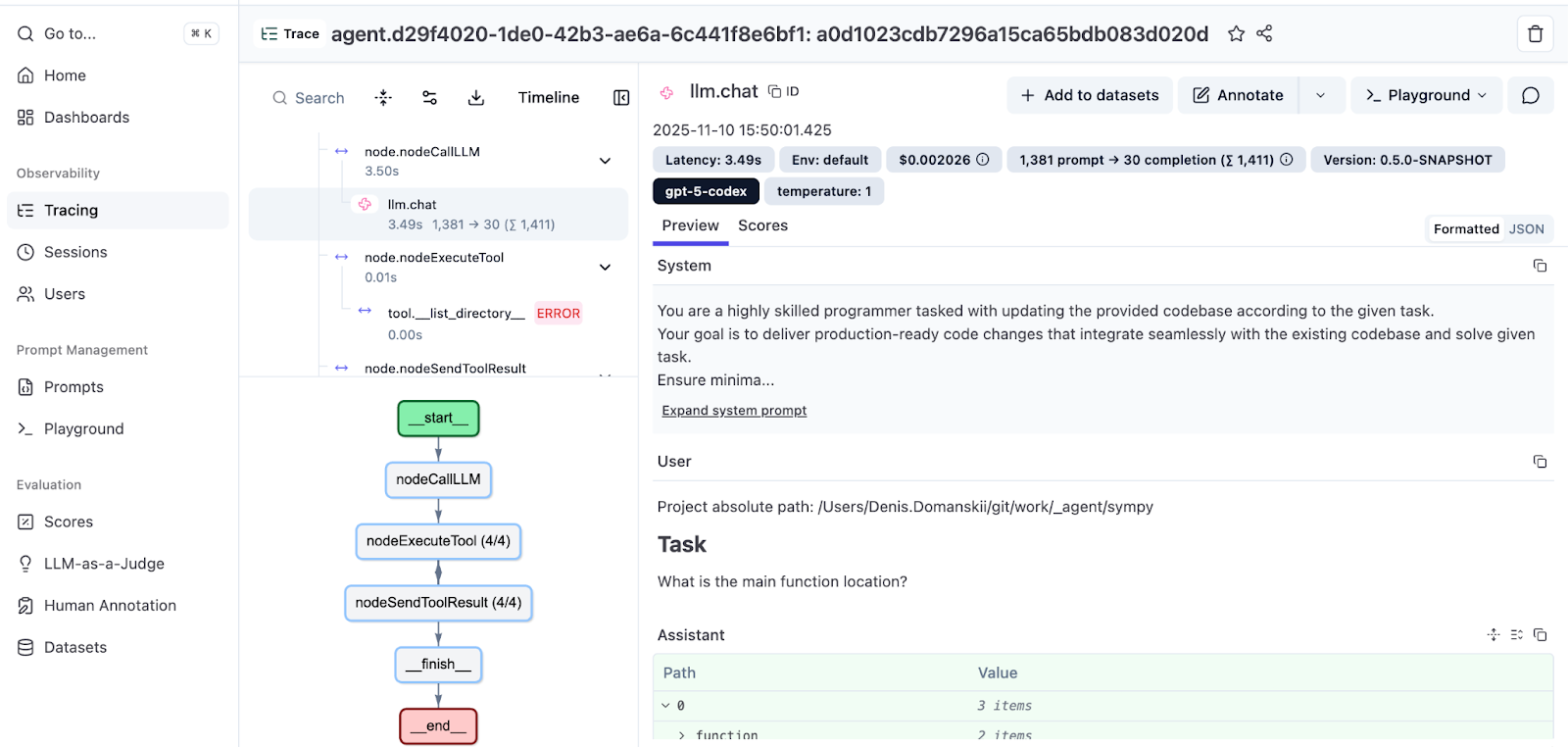
왼쪽 패널에는 에이전트의 궤적이 표시됩니다. 메시지, 도구 호출, 관찰 결과가 순서대로 나열되며, 들여쓰기를 통해 호출 계층 구조가 나타납니다. 오른쪽 패널에는 각 단계의 세부 정보가 표시됩니다. 프롬프트, 응답, 도구 매개변수, 그리고 범위별 비용 내역이 포함됩니다.
하단에서는 흐름을 시각화한 실행 그래프를 확인할 수 있습니다. Koog의 그래프 기반 전략에 대한 자세한 내용은 문서를 참조하세요. 또한 Koog 기술 책임자가 작성한 심층 분석 글인 Mixing the Secret AI Sauce: How to Design a Flexible, Graph-Based Strategy in Koog(AI 비밀 소스 섞기: Koog에서 유연한 그래프 기반 전략을 설계하는 방법)도 읽어보세요.
관찰 가능성을 통해 문제 발견하기
이 글을 위한 예제를 준비하는 과정에서, 빨간색으로 강조 표시된 실패한 도구 호출을 발견했습니다.
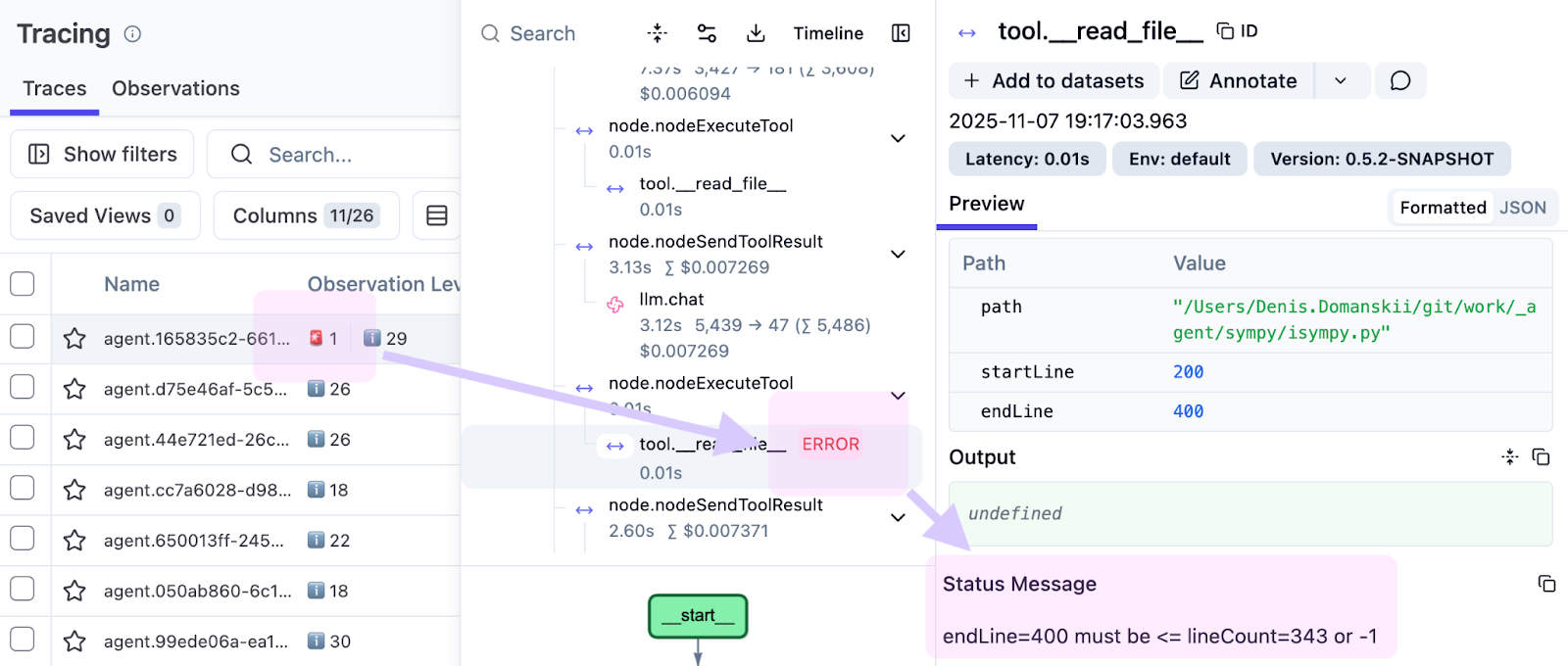
관찰 내용은 다음과 같습니다.
endLine=400 must be <= lineCount=394 or -1
에이전트는 0~400줄을 요청했으나 파일에는 394줄밖에 없었습니다. 이는 현재 도구 구현의 부족함을 보여줍니다. 단순 오류로 종료하기보다, 범위를 가용한 범위 내로 보정하여 에이전트가 중단 없이 작업을 이어가도록 개선이 필요합니다. 추적 기능이 없다면 이러한 문제는 로그에 묻혀 버립니다. 추적 기능을 사용하면 정확히 어떤 실행의 어느 단계에서 어떤 입력값 때문에 문제가 발생했는지 파악할 수 있습니다.
이것이 바로 관찰 가능성이 중요한 이유입니다. 단순히 오류 발생 여부를 넘어, 어떻게 그리고 왜 발생했는지를 명확히 보여주어 디버그 효율을 극대화합니다.
평가 실행 처리
단일 추적은 디버그에 유용하지만 평가 실행 시에는 배치 뷰가 필요합니다.
여러 개의 SWE-bench Verified 작업(코딩 에이전트의 표준 벤치마크)에서 에이전트를 실행할 때는 그룹화된 추적과 집계된 비용이 필요합니다.
Langfuse는 세션을 통해 이를 완벽하게 지원합니다. 추적 속성으로 세션 ID를 추가하세요.
install(OpenTelemetry) {
setVerbose(true)
addLangfuseExporter(
traceAttributes = listOf(
CustomAttribute("langfuse.session.id", "eval-run-1"),
)
)
}
이렇게 구성하면 평가에서 추적이 하나의 세션 ID를 공유하게 됩니다. Langfuse에서 Session(세션) 탭으로 이동하면 집계된 시간과 총 비용을 확인할 수 있습니다.
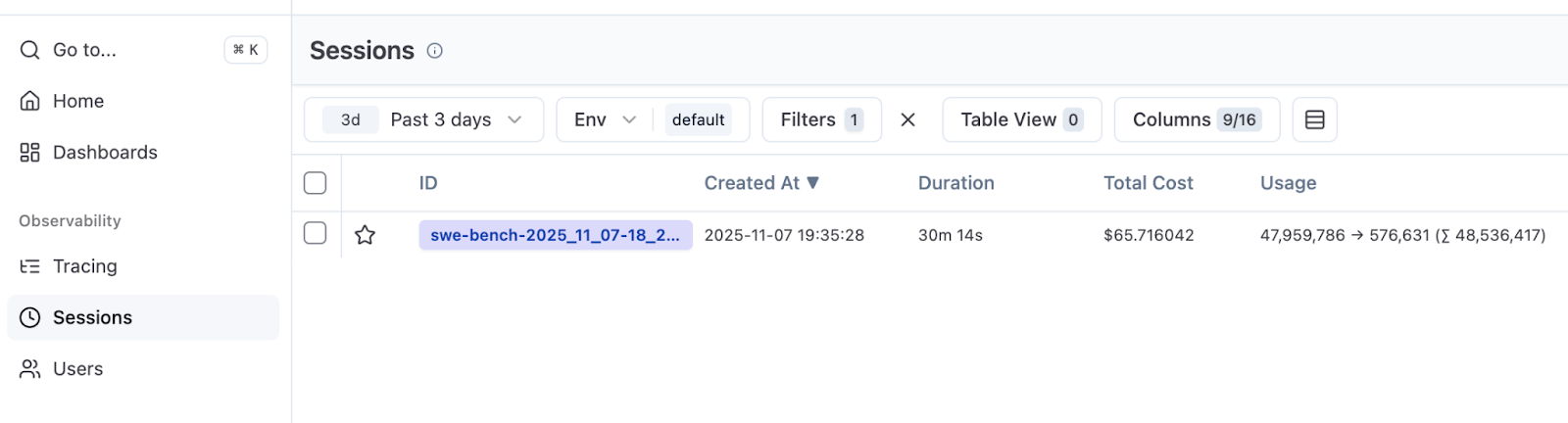
여기에서는 총 500개의 SWE-bench Verified 작업 중 50개를 실행해 보았습니다. 10개의 인스턴스를 동시에 실행하여 30분이 소요되고 66달러가 들었습니다. 이 결과는 향후 실험에서 성공률, 런타임, 비용의 기준점이 됩니다.
Langfuse는 기본적으로 성공 점수를 표시하지 않습니다. 이는 의도된 설계입니다. 추적은 무슨 일이 발생했는지를 기록할 뿐, 실행이 성공했는지 여부를 판단하지는 않습니다. Langfuse에서 성공 메트릭을 확인하고 싶다면, 평가를 활용해 각 시도를 채점한 뒤 사용자 지정 점수로 보고하도록 설정해야 합니다. 인프라 여건이 허락한다면 충분히 구현해 볼 만합니다.
마치며
관찰 가능성은 단순히 디버그에 대한 것이 아니라 에이전트의 동작을 이해할 수 있는 방법이기도 합니다.
몇 줄의 코드만으로 에이전트를 블랙박스에서 직접 들여다볼 수 있는 대상으로 바꿀 수 있었습니다. 놓칠 뻔했던 줄 범위 오류를 잡아낼 수 있었고 50개 작업을 평가하는 데 66달러의 비용이 든다는 사실을 확인했습니다. 그리고 토큰이 소비되는 작업과 효율적으로 실행되는 작업도 파악할 수 있게 되었습니다.
다음 글에서는 특정 작업을 더 작고 경제적인 모델에 맡기는 서브 에이전트 패턴을 소개해 드리겠습니다. 추적 기능을 갖추면, 각 실행에서 에이전트가 무엇을 하는지를 기준으로 어떤 작업을 위임할지 결정할 수 있습니다. 더 이상 추측할 필요가 없는 것이죠.
리소스
읽어주셔서 감사합니다! 여러분이 추적 분석을 활용하는 방법을 알려주세요. 에이전트의 동작에서 어떤 패턴을 발견하셨나요? 어떤 부분이 흥미로우셨나요? 여러분의 소중한 경험을 댓글로 자유롭게 남겨주시기 바랍니다!
게시물 원문 작성자



