

Kotlin
A concise multiplatform language developed by JetBrains
The State of Kotlin Support in Spring

This is a transcript of “The State of Kotlin Support in Spring” talk by Sebastian Deleuze from KotlinConf:
Do you find this format useful? Please share your feedback with us!
TOC:
- Why Kotlin? (1:30)
- Spring❤️Kotlin. How much? (3:17)
- Coroutines (10:44)
- Spring Boot (28:04)
- GraalVM Native (38:10)
- More resources (41:05)
Why Kotlin? (1:30)
First, I think that Kotlin improves the signal-to-noise ratio compared to Java. It’s super important to express our ideas and algorithms with something that is easier to understand.
Second, safety, and especially the nullability. Kotlin has turned Java’s one-billion–dollar mistake into a powerful feature that has allowed it to deal with the absence of value. The trick is to deal with “null” in the type system. Java is not doing that and it makes a lot of difference.
Third, discoverability. You’re using APIs and new APIs are coming and it’s super important to make these APIs discoverable. I’m lazy and I like to use Ctrl + Space to discover new things! I prefer this way rather than using conventions, or things that you need to know before using the framework.
Pleasure is important as well! We mostly use Kotlin for work, but since we spend so much time doing it, I think it’s really important for it to be a pleasurable experience. And I enjoy using Kotlin much more than Java.
The Android ecosystem is huge and it’s coming to Kotlin very fast. Obviously the server side is moving slower, but I think the Android ecosystem could have an impact on the server side ecosystem, just given the number of developers. Sometimes mobile developers do server side things, not that much, but it happens. Maybe later we could see similar stories with the front end.
Spring❤️Kotlin. How much? (3:13)
Framework documentation in Kotlin
At Spring, we decided to translate all of the framework reference documentation from Java into Kotlin. That means that for each code sample in the Spring reference documentation, you have two tabs. One is the Java tab, which is obviously still selected by default, but now there is also a Kotlin tab:
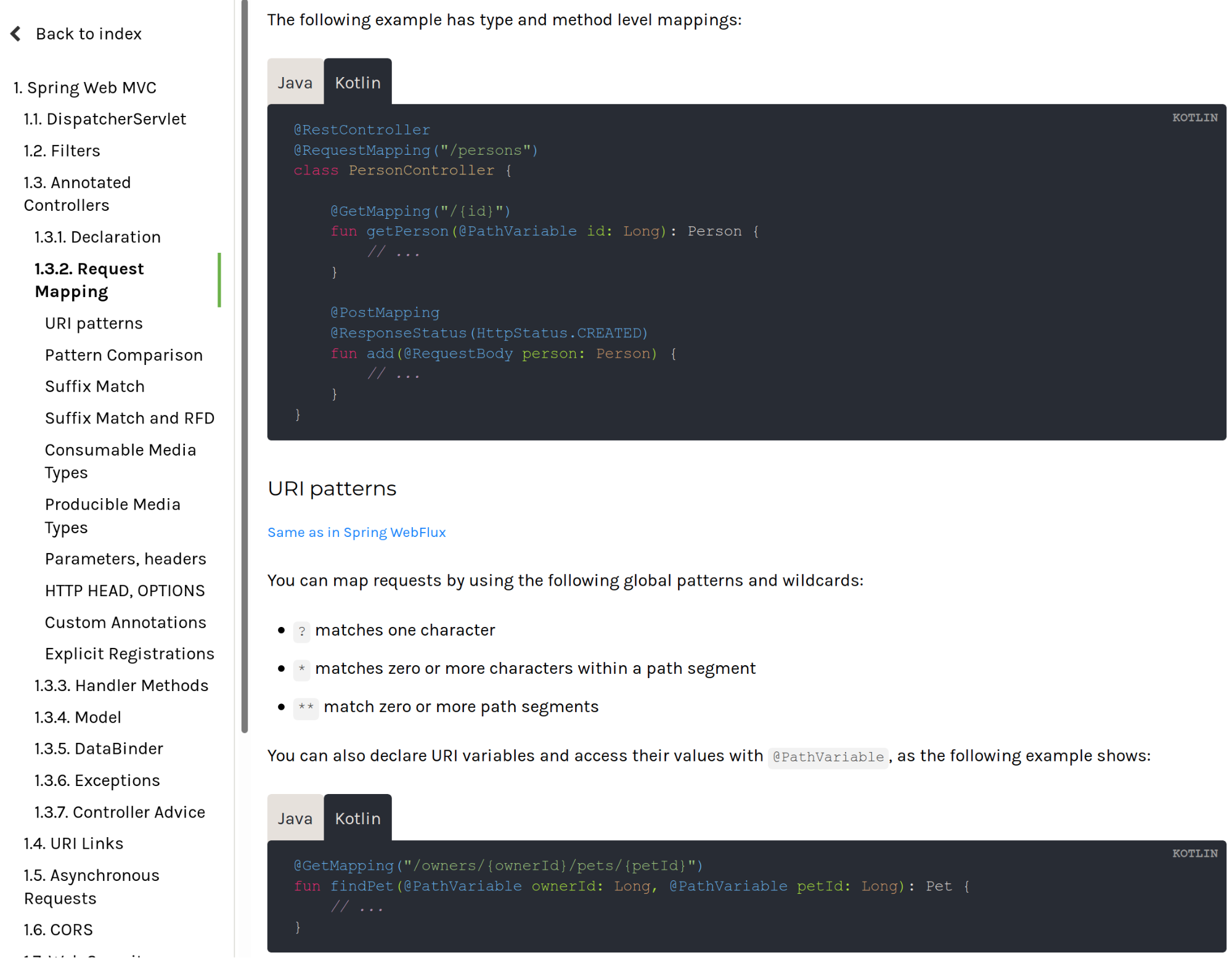
And it’s not a line-by-line or an automated translation! When an extension or a DSL is available, it is shown in the Kotlin code sample. I did the translation sample by sample and it’s idiomatic Kotlin using Spring.
I think that’s a good way to learn Kotlin and the idiomatic way of using Kotlin in the context of Spring. This is available in Spring framework 5.2 documentation. You can go to the current reference docs and you’ll see it!
I’ve tried to summarize the current status and the next steps in this table:

Obviously, translating the Spring framework documentation was a huge undertaking, it took many hours!
Next year we should be able to provide translated Spring Boot documentation as well. And if you want to help – feel free to do so! That would let me focus on other features :) Translating the Spring Boot documentation is not that huge, it’s smaller than the Spring framework documentation and the work has already started via community contributions.
Spring security will have Kotlin documentation as well. And Spring Data is a pretty huge project with 17 sub-projects. Some parts of Spring Data will have Kotlin documentation and some parts won’t.
Gradle Kotlin DSL on start.spring.io (5:04)
Another thing that we have done to increase Kotlin support in the Spring ecosystem is to provide Gradle Kotlin DSL support on start.spring.io:
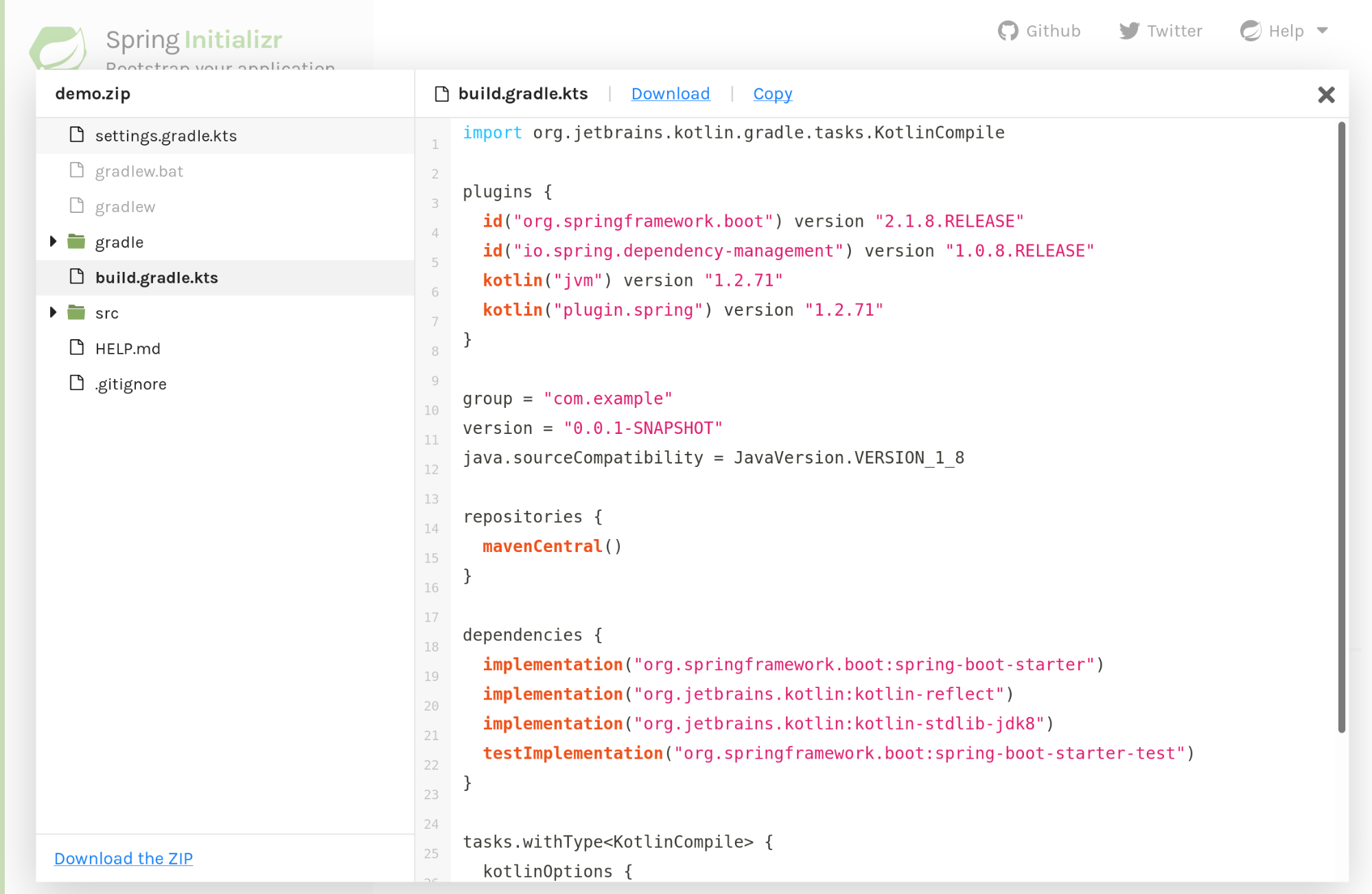
When you start a Kotlin project with the Gradle build system, we now automatically use the new Kotlin DSL in the project that you generated. Feel free to use that!
More DSLs (5:28)
Spring MVC is provided with a mock MVC DSL which is pretty nice, but it’s not easily discoverable and it employs a lot of static imports – it’s “Java-ish”.
MockMvc DSL by Clint Checketts and JB Nizet (5:28)
Thanks to community contributions again, specifically to Clint Checketts and Jean-Baptiste Nizet, we now have a mock MVC Kotlin DSL which you can trigger by using these kinds of MockMvc.request
When you use these kinds of extensions, it triggers the use of the MockMvc DSL and allows you to describe that in a more Kotlin way. We tried to stay pretty close to the Java way. So if you know MockMVC in Java, it’s not a totally different thing with Kotlin idioms. We have tried to find the right balance between something idiomatic in Kotlin and something which is still close to the Java API.
Spring Cloud Contract DSL by Tim Ysewyn (6:32)
The team from Pivotal has also contributed to the Spring Cloud Contract DSL, so feel free to use that if you’re using Spring Cloud Contract to test your APIs:
Spring Security DSL by Eleftheria Stein (6:45)
I’m always happy when someone other than me creates some Kotlin features in the Spring ecosystem. Big thanks to the Spring Security team and especially Eleftheria Stein who has done an amazing job to introduce Spring Security Kotlin DSL:
Spring security is configurable with the Java DSL which is pretty extensive. Also, Spring security has created an official Spring Security Kotlin DSL which is currently in experimental mode. It’s available at this URL, and next year it should be integrated by default with Spring security 5.3.
Spring MVC DSL and functional API (7:21)
Another big part of the work in Spring framework 5.2 has been to introduce the router DSL and the functional API for the Spring MVC. I don’t know if you have seen the previous presentation I did, but basically with Spring framework 5 we have introduced a new way to add controller @RequestMapping to write your web components via functional API and Kotlin DSL. It was previously available only with WebFlux. So basically to use this kind of DSL, you have to switch directives. Now we provide this DSL for both Spring Mvc and Spring WebFlux.
Defining Handler & Router (8:02)
The DSL is very similar to the WebFlux version. You are writing your handlers with a ServerRequest input parameter and a ServerResponse return value:
You have this API to define the status codes, the body, and use converters. Everything that you can do with Spring MVC and Annotations, you can do with this kind of API:
You can define the router. Here we have a distinct router and handler. And the router usually refers to the handler using credible references:
Then you can expose the router to Spring Boot simply by returning the router DSL value and exposing it as a Bean. Spring Boot will automatically take these routes into account:
More realistic Handler & Router (8:52)
If we take a look at a more realistic handler, you will create a dedicated class where you will inject your repositories and your services. Obviously, in Kotlin we always use constructor-based injection:
You create values by using handlers. And you create your router, defining your routes and using credible references to reference these handlers:
You can create as many routers as you want. It’s not monolithic.
It supports nested predicates. You can create your own request predicate; the whole mechanism is very extensible.
Creating routes dynamically (9:35)
You can even create routes dynamically:
It’s not just syntactic sugar or a more Kotlin-ish way to write your web components. It also provides new capabilities because annotations are statically defined. So if you need to create routes depending on something which is in your database – which is not uncommon if you create CMS or e-commerce.
Obviously, you need to take care of caching and stuff like that. It’s not as easy as it is here, but it opens up new capabilities and I think that’s a pretty interesting way of writing your web components.
Status Update (10:10)

Beans DSL and WebFlux router DSL have been supported for quite a long time now. Spring Boot 2.2 brings the Coroutines router DSL – we are going to see it just after that. The WebMvc router DSL, MockMvc DSL, and the Spring Security DSL are available in experimental mode. Next year all of these components should be available in production.
Obviously, that’s an estimation and it’s possible that not all of these features will get done in time.
Coroutines (10:44)
I guess you have heard quite a lot about coroutines. There are talks by Roman Elizarov and various other talks. I will not go into too much detail, but I would like to share my view of coroutines from the Spring point of view and the server side point of view.
Coroutines are lightweight threads; you can create hundreds of thousands of them, whereas you cannot create that many threads. They provide you with building blocks that allow better scalability and allow new constructs, especially if you deal with asynchronous calls and applications with a lot of I/O, which is typically the case on the server side.
The foundations are in the Kotlin language. However, only a very small part is at the language level, and most of the implementation is on the library side in kotlinx.coroutines
When you talk about coroutines, be careful about defining what you are talking about. Maybe you are talking about these lightweight threads. Maybe you are talking about the language feature. Maybe you are talking about the library which is pretty extensive and contains a lot of things.
I have seen that usually people talk about coroutines but sometimes refer to different things.
From the Spring point of view, Coroutines let you consume the Spring Reactive stack with a nice balance between imperative and declarative styles. Obviously we have a huge investment in reactive APIs in Spring, but there are two levels. There is the whole stack that we are building, so that’s the whole reactive infrastructure. We have built WebFlux, and we are currently working on R2DBC which is reactive SQL and the GA has been released just a few days ago. We are working on RSocket, which is a way to bring reactive outside of Java, outside of the JVM, and this can be used for mobile and frontend in a reactive way. We have a really huge investment in Reactive, and coroutines compete with Reactor at the API level, but that’s not an issue. Our Reactive core is already designed to be exposed to RxJava, for example, or other reactive/asynchronous APIs. Coroutines is just a new way to consume our reactive stack.
With coroutines, operations are sequential by default. Concurrency is possible but explicit.
With Coroutines 1.3 there are three main building blocks you need to know. There are in fact more pieces in Coroutines, but if you just need to learn three things, this is the first one I’m going to show.
The first one is the suspending function. This is the basic block from the beginning:
You are writing your function, you add this suspend
An important design point is that suspending functions “color” your API (as explained by Bob Nystrom in his great blog post What Color is Your Function?). That means that you have regular functions and suspending functions. Other outgoing technologies, like Loom for example, take a different approach, but here we have a distinct kind of function. Suspending functions can call regular functions, but regular functions can’t call suspending functions directly. You would need to use some dedicated capabilities in order to do that. That’s not necessarily a bad thing in terms of design, but that’s a thing you need to know. In that aspect it’s pretty similar to reactive and asynchronous APIs where you are using wrappers like Flux/Mono compatible features. You have two different worlds – regular functions and Coroutine functions.
Structured concurrency
Another building block is structured concurrency. Structured concurrency allows you to define asynchronous boundaries:
When you are writing asynchronous code in an imperative fashion like this – in this example we are loading two remote images – we want to take care of cases where loading the image fails.
The behavior that we want is that both image loading processes are cancelled and we throw an exception.
We have to define these kinds of asynchronous boundaries like we define transactions with databases. Structured concurrency provides building blocks like CoroutineScope that allow us to define asynchronous boundaries to make coroutines aware of what to do when there is an error, and define this kind of behavior.
Flow<T> (15:58)
A big feature of coroutines 1.3 – I have pushed a lot to get this type and I will explain why – is called Flow. Flow is a new type available in experimental mode for Coroutine 1.2, and available in non-experimental mode for the base API in Coroutine 1.3. And here I’m referring to "kotlinx.coroutines.flow.Flow", not the flow type which is in Java 9+ which is a kind of container type for a reactive stream interface. It might be a little bit confusing, but “Flow” is a very attractive name, so both Oracle and JetBrains like it.
Coroutines 1.3 introduces a new Reactive type and it’s super important because Flow is the equivalent of Flux in the Reactor world or Flowable in the RxJava world but for coroutines.
When we do the exercise to see if we can translate our Reactive API to coroutines, the suspending functions are great for translating Mono, but we were really missing something for the streams. And I don’t like Channel; I don’t think that’s a good building block for building server side applications so we really miss that. I’m thankful to the coroutines team who did an amazing job providing Flow in time for the Spring Framework 5.2.
Flow does not implement Reactive Streams directly because it is based on the Coroutines building block instead of regular Java constructs. But it kind of sums up the semantics and behavior of Reactive Streams, even if not completely, and it provides some support for back pressure.
Basically, “back pressure” is a way for a consumer not to be overwhelmed by a very fast producer. It’s a way for the consumer to say: “OK, you can send me 10 chunks of data and I will process that”. And the sender will only send 10 chunks of data, not more. Which allows us to have scalable applications at the architecture level.
That’s the flow API:
The Flow API provides a “collect” suspending method with a FlowCollector that itself provides a suspending “emit” method and that’s it.
The building blocks, the router API, is really constrained.
Operators – I mean operators which are similar to what’s available in the RxJava/Reactor world like filter, map, zip etc – are provided as extensions, and some of them are pretty easy to implement:
This is the real implementation of the filter operator that is built-in in the coroutines API.
In the reactive world of RxJava and Reactor, if you want to implement a reactive operator you need to have some special skills. I don’t have them myself. It’s pretty hard to implement a reactive operator.
In coroutines – it depends. It’s not always easy. But if you don’t have any concurrency involved, I would say that it’s pretty easy. If you are implementing an operator with concurrency, it’s much easier to do that if you’re in the Kotlin team :)
When you want to create a Flow, you will use this kind of a Flow Builder. You can see that the code inside it is pretty imperative – you just use a for loop:
You can call any kind of a suspending function inside the flow builder. If you want to request remote data from your HTTP client or a database – you can do that. Because this flow builder takes a suspending lambda. Basically, it’s a lambda that is suspending and inside the lambda you can call any kind of suspending function. Here I’m just emitting a number each 100 ms and that’s it.
When you consume a Flow it’s more declarative, more functional:
I don’t like it when people say that with coroutines 1.3 Reactive is declarative and coroutines are imperative. I think that’s wrong. I think that coroutines 1.3 provide a nice balance between imperative and declarative. Inside operators like “map” you can use more imperative constructs. I like this balance where you can use imperative code where you retrieve a single asynchronous value and you can use a declarative-functional approach when you want to describe how you process streams of data and things like that. I think that’s the perfect balance.
What about Spring support for coroutines? (21:15)
Spring provides official Coroutines support for Spring WebFlux, Spring Data (Redis, MongoDB, Cassandra, R2DBC), Spring Vault, and RSocket.
On the Spring Data side, we support Redis, MongoDB, Cassandra, and R2DBC. R2DBC is regular SQL, so we provide support for SQL, H2, MySQL, and Microsoft SQL as well.
There are no new types introduced, because I’m lazy and I don’t want to duplicate the whole Spring API!
WebFlux suspending methods (21:55)
And we provide seamless support with the annotation programming model. That means with WebFlux (not Spring Mvc, not for now – that will come later) you can add the suspend keyword under methods annotated with @RequestMapping, @GetMapping, etc. and that will enable you to call any suspending function or any kind of coroutines API inside this handler:
Conceptually this is like a function that returns a Mono<Banner> if you are using Reactor. Or a compatible feature of Banner. It’s just that you don’t have to use this wrapper, you can just use the suspend keyword.
It also works for suspending view rendering:
Reactive types extensions for Coroutines APIs (22:35)
And for functional APIs we provide Coroutines support via extensions.
We provide various reactive APIs. WebClient is our reactive web client and it natively provides methods like bodyToFlux to return the Flux of something, and bodyToMono to return the Mono of something. What we have done in order to avoid duplicating the whole API is to provide extensions like bodyToFlow which is like a “wait body” which allows you to provide the coroutines API without involving any reactive parts – in other words, without exposing the reactive API directly:
That allows you to get Flow or suspending functions and deal with all of the reactive capabilities underneath in a “coroutines” way. That’s our strategy.
We provide this kind of support for WebFlux Router with these kinds of extensions:
RSocket (23:35)
We provide support for RSocket. RSocket is a way to be reactive between, for example, your server side and your mobile application:
I think RSocket has a huge potential on Android, but that will be another talk, maybe next year.
You have this kind of reactive flow, you can use all of the Flow operators. You can think of it as all of the reactive capabilities in Spring being exposed in Coroutines, in addition to being exposed as a Reactor API.
Spring Data R2DBC with transactions (24:12)
We even support Coroutines transactions with databases:
We have worked a lot on the R2DBC support. R2DBC is reactive SQL. The database client is a kind of a fluent API for R2DBC. It’s totally possible to have a part of the Kotlin ecosystem that uses R2DBC, because R2DBC has no dependencies except reactive streams. Which makes it possible for an exposed or any kind of a pure Kotlin API to leverage R2DBC API without involving any part of Spring.
Here I’m using Spring Data R2DBC, which is our way to expose R2DBC by default. However, R2DBC is really designed as a very low-level thing that is usable in another context, and I really hope that the Coroutines Kotlin ecosystem will leverage all the work we have done at the driver level. Because exposing R2DBC as Coroutines is just using a single extension. There is almost no performance loss and I think that’s a good opportunity for the Kotlin and Coroutines ecosystem.
But here I am using Spring capabilities. I have this transactional operator which is kind of a functional transaction. It allows me to define the transaction boundaries using a reactive stack. There is a transactional extension which is applied to Flow in order to use transactions on top of the Flow type.
We provide support for Spring Data reactive MongoDB and various other things:
Coroutines are now the default way to go Reactive in Kotlin (26:00)
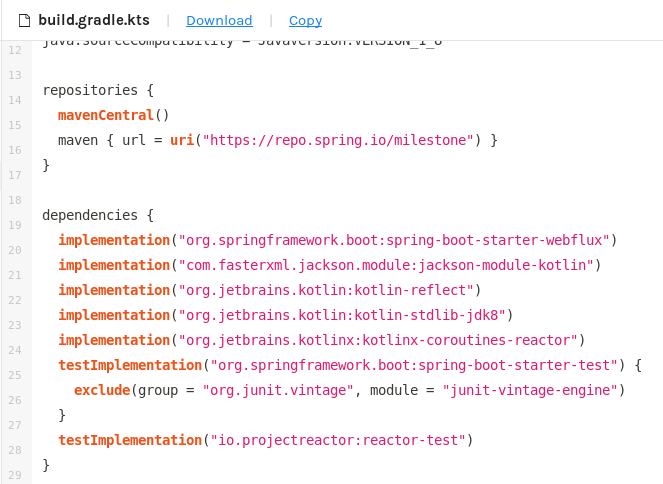
Coroutines dependency added by default on start.spring.io:
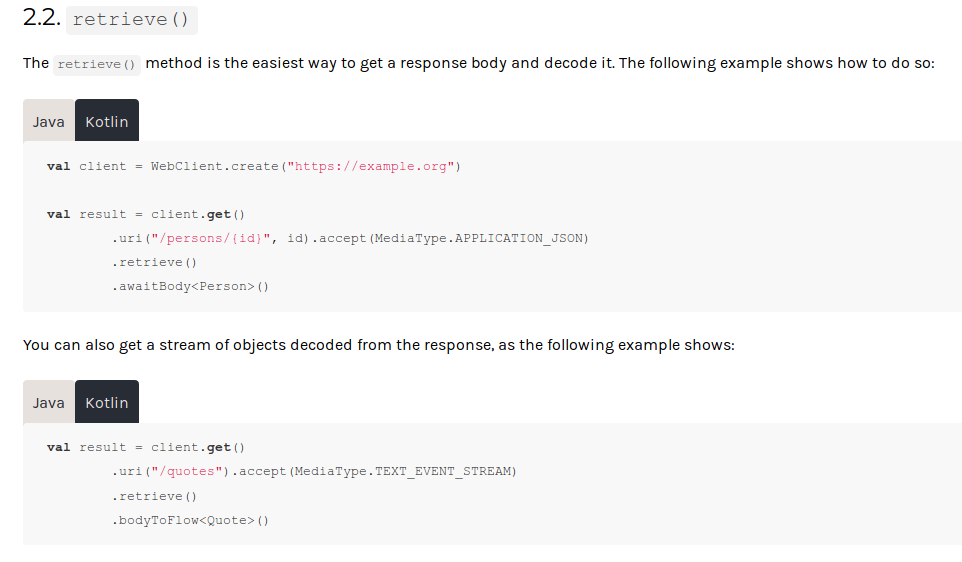
WebFlux & RSocket Kotlin code samples provided with Coroutines API:
Coroutines are now the default way to go Reactive in Kotlin. It’s perfectly fine to use the Reactor API if you want, but I think that people are waiting for some kind of a guideline and opinions. And my thinking is that when you are using the Reactive stack in Kotlin, it’s very likely that you would like to use this Coroutines API.
When you select Kotlin and one of the Reactive dependencies on start.spring.io, the Coroutines dependency will be automatically added. You don’t have to add another dependency manually.
Also, in the reference documentation all of the examples are written using Coroutines and not exposed with Flex. Basically, this is a different way to consume, if you agree, and I hope you do.
Status (26:55)

In terms of scope, we have plenty of things that are already supported: Spring WebFlux functional APIs, WebClients, the annotational programming model with @RequestMapping, RSocket @MessageMapping, Spring Data Reactive APIs, and functional transactions.
What is missing is Spring MVC @RequestMapping. That’s because Spring MVC has some support for Mono and Flux. It’s less advanced than WebFlux, but it’s usable.
I think that in the Spring framework 5.3, Spring MVC will support Coroutines as well. That’s pretty useful when you want to use WebClient in Spring MVC and obviously that is a missing part.
Spring Data repositories will be supported seeing as they have already been implemented in less than one day. So, hopefully that has been taken care of. @Transactional is not supported yet, but I hope we will be able to support it as well. For now you have to use functional transactions.
Spring Boot (28:04)
What are the new features on the Spring Boot side?
@ConfigurationProperties
These are the kind of configuration properties that I was writing last year.
ConfigurationProperties
Now we have this @ConstructorBinding annotation that allows us to instantiate ConfigurationProperties via the constructor with full mutability support with read-only properties:
We don’t need properties and we don’t have this kind of crappy lateinit var, and we can just use a class or a data class with read-only properties. Feel free to use it.
start.spring.io helps to share Kotlin projects (29:01)
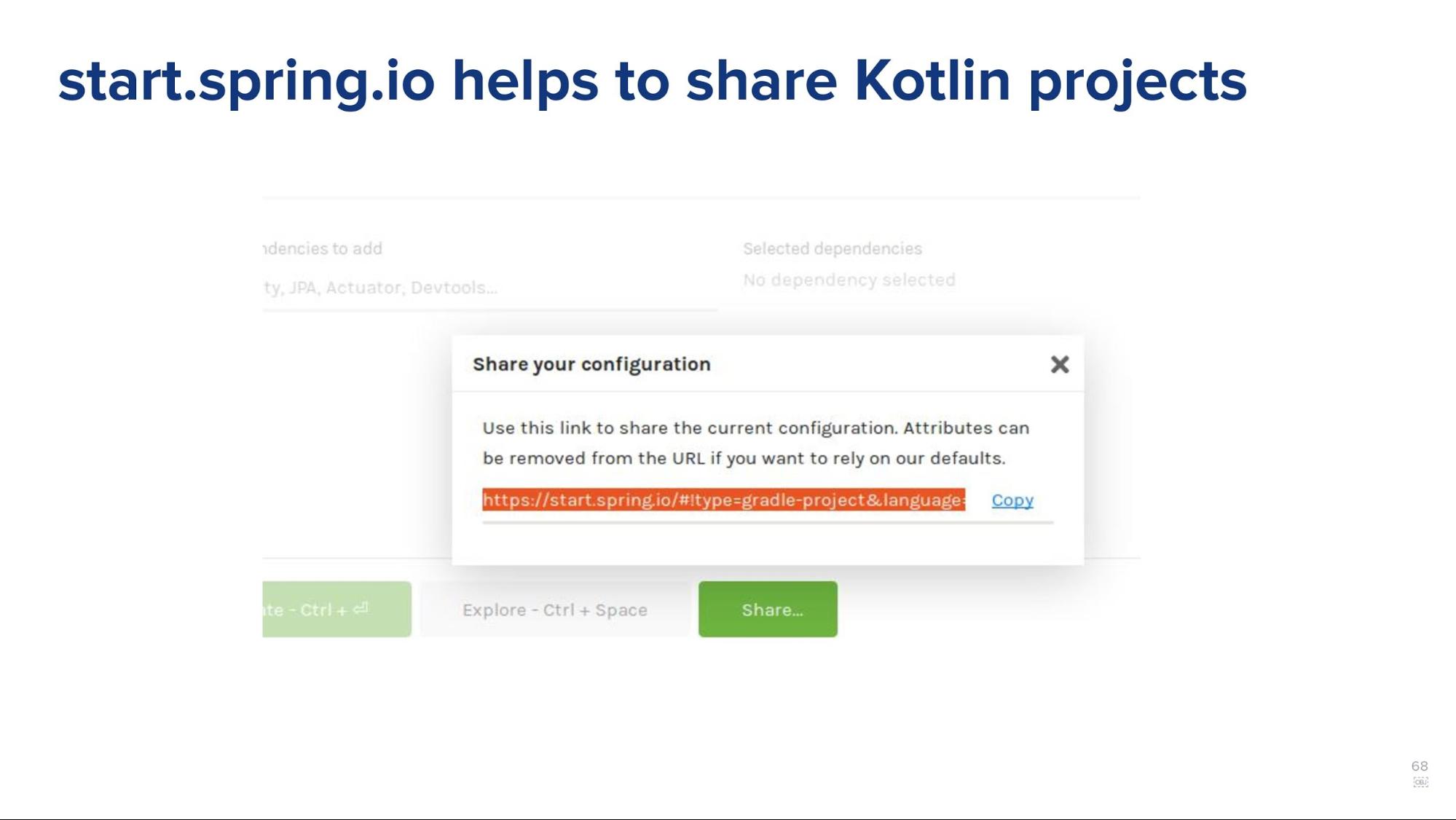
Another useful thing in the context of Kotlin is that start.spring.io now has two new buttons.
An “Explore” button that lets you peek at the information of the generated project directly in the UI. This avoids the overhead of generating the zip, extracting, etc. This is pretty useful.
The other one is “Share” which allows you to share the current configuration. If you go to start.spring.io, select Kotlin Gradle and you want to share it with your co-workers to increase Kotlin reach – feel free to use that. I keep forgetting about this URL which has been supported for two years now. Anyway, now you have a way to get this kind of customized link.
Kofu: the mother of all DSL (29:43)
Kofu is another topic and Kofu is experimental. Up until now I was speaking about production-ready stuff, but now we’re entering the dangerous land of experimental stuff.
Kofu is basically the application DSL. We have seen the Router DSL, there is a Beans DSL, and there is MockMvc. We try not to overdo it with DSL, but it was tempting to do an application one and I will explain why.
Explicit configuration for Spring Boot using Kotlin DSLs
Spring Boot’s main design is centered around conventions. Basically, with Spring in Java we have two variables to explicitly define things, and so Spring Boot provides conventions. I think that’s a pretty widely used and accepted model to configure Spring Boot, and that’s perfectly fine. There is nothing wrong with using that in Kotlin.
However, since we have this great DSL support and since we have all these other DSLs, it kind of makes sense to try and see what it means for Spring Boot to have a configuration with a DSL. The interesting thing is that it’s explicit configuration. That means you won’t have Jackson support because you have a transitive dependency that brings Jackson and that’s how Spring Boot currently behaves. It’s based on conditions that could trigger on properties and classes present on the class path. If you are a control freak like me, it’s possible that you will like this kind of thing. It’s experimental, so don’t use it in production yet!
It leverages existing DSLs like Beans, Router, and Security. It also provides composable configuration and discoverability via auto-complete instead of convention.
To me that’s just a detail, because I think that with the upcoming Spring Boot version we should be close to Kofu’s performance even with annotations. It currently provides faster startup and less memory consumption:
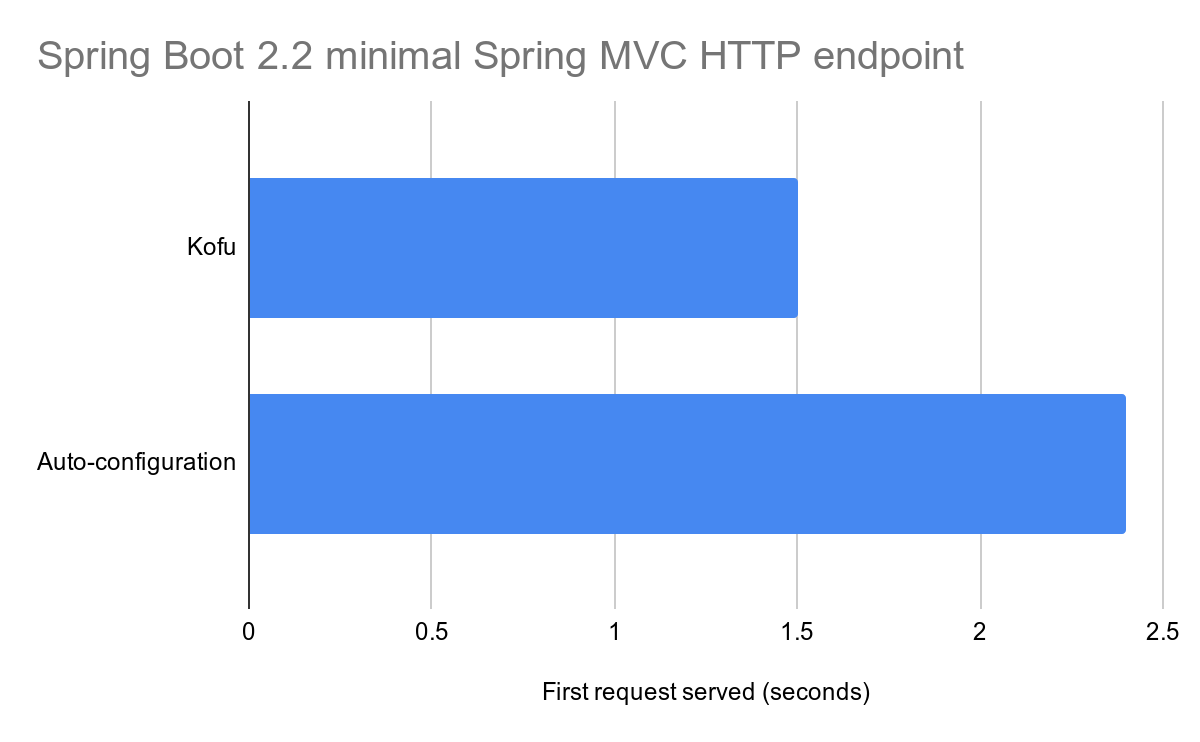
Currently we have a decrease of 40% in startup time and less memory consumption when you configure your Spring Boot application with Kofu instead of Auto-configuration.
But again, I tend to think that this gap will be reduced by the work that we are currently doing so that is not the main point. The main point is getting explicit configuration.
Demo (32:05)
Here’s a quick demo. I’m just going to create a regular Spring Boot application. It’s important to understand that a Spring Boot application configured with Kofu is just a regular Spring Boot application. You still create it via start.spring.io.
I’m going to the spring-fu website. It’s on spring-projects-experimental. I’m going to just copy and paste that. I’m adding the milestone repository. I’m adding the Kofu dependency and it’s just a regular dependency that provides application DSL. We need to import the changes, and if everything goes fine, I should be able to use my application DSL.
Here I’m going to create a Spring MVC application. So, I’ll select the “SERVLET” type and then I’ll have access to a DSL where I can configure things. For example I am going to add SpringMvc support, I am going to use my router, and I’m going to create a route which will just return an “OK” status and return a body with “Hello KotlinConf”.
Everything is explicit so we then need to run this application. So it’s really a way to use existing things. This router is exactly the one that is provided with the Spring framework, but here I’m reusing it in the context of an application configured in a functional style.
Then if I want to add some kind of Jackson support, for example, let’s say I’m creating a class “Sample”, “val_title”. I want to return this class and use it with Jackson. In Spring Boot it’s automatically configured here. Since the support is explicit I will have to declare, but that’s on purpose.
When I talk in terms of discoverability, here I can see what values are converted without having to read the documentation. Here I’m using Jackson. If I want to configure pretty print – again I’m lazy, I don’t have a very good memory – I just need to use my autocomplete to enable the pretty print option and I can also discover all the great options in Spring Boot that are available to configure Jackson. It’s a way to expose what you can do in Spring Boot as a discoverable DSL.
A very important point is that you can create modular configurations and that is one of the main purposes of this kind of construct – it is not monolithic, otherwise it would not be very interesting.
We are going to create a web configuration, we are going to define a logging configuration, and then you select explicitly what you enable because, again, everything is explicit. And if, let’s say, you only want to select the web config, but not the data config for your tests, and mock other things, you will just declare a new customized application just for your tests that will trigger and run just what you need, which means faster integration testing and things like that.
I don’t have the time to describe everything today, but I guess you can understand the potential in the philosophy. You can find more on the spring-fu project, and I will continue to evolve it. Feel free to give feedback! Not so much about the scope of the support, but more on the root principles.
My goal is to make Kofu the Spring Boot Kotlin DSL integrated in a production-ready way. We are not there yet. I think the current step is to have more Kotlin market share in regular Spring Boot applications. Which is kind of a chicken and egg issue, but I need more people using Spring Boot in Kotlin in order to trigger the major task of exposing every Spring Boot configuration feature as a DSL.
GraalVM Native (38:10)
The last topic is GraalVM native support. There was a nice talk by Oleg in this room just before me. GraalVM Native in one slide:
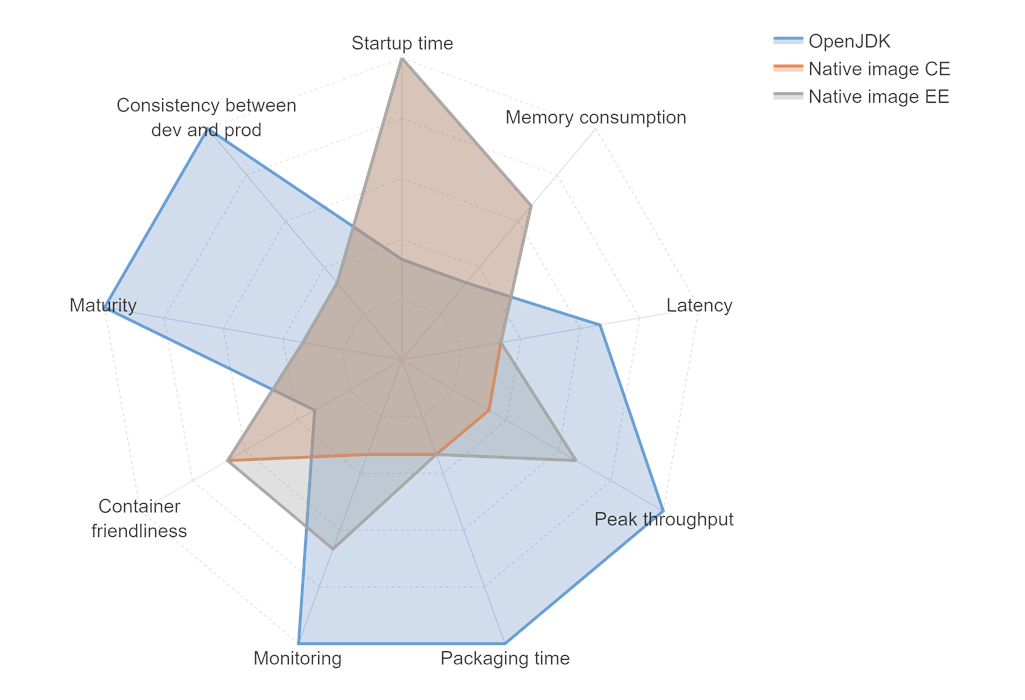
That’s a way to compile your Java, your JVM application into a static executable. It provides different characteristics: instant startup time, very low memory consumption for small applications, smaller container image because it allows you to create Docker container images from scratch thanks to the feature which lets you create statically linked executables. But it still requires you to use OpenJDK on the development side, so it’s not hugely consistent between the input. In terms of maturity, in terms of throughput, we are not at the same level as OpenJDK. What I want to say is that it’s an interesting platform with very different characteristics – it could make it possible to lower cloud hosting costs, but it also comes with a lot of drawbacks and different characteristics, so be careful and evaluate all of the criteria.
Spring Framework 5.3 should be able to configure reflection, proxies, resources, etc. dynamically with GraalVM native: https://github.com/spring-projects-experimental/spring-graal-native.
Kotlin with Spring MVC or Spring WebFlux works on GraalVM native Coroutines support is broken becse of graal#366.
We are going to work on some out of-the-box setup capabilities for the Spring framework 5.3, and Kotlin is supported. The work is currently being done on spring-graal-native, so feel free to take a look.
It allows you to start your application pretty fast; basically you can start your application almost instantly.
It allows you to create scale-to-zero applications. Imagine that you have a back office application that is used 10% of the time and you deploy that with 20 microservices that are running every time and 40 instances because you want high availability. With this kind of mechanism, each microservice instance will consume less and you can basically shut down the service when it is not used.
This comes at the cost of a lot of other constraints, and not all of the ecosystem is supported and it’s still super-super early, so be careful. But we are interested in that and we’re working on such support.
It works with Kotlin except for Coroutines. There is an issue with Coroutines that should be fixed in the upcoming months. We have discussed that last week with the GraalVM team and it should be possible to fix it in the upcoming releases.
More resources (41:05)
https://spring.io/guides/tutorials/spring-boot-kotlin/
I have covered a lot of topics, but if you want to start things more slowly, in the beginning there is the official Kotlin Spring Boot tutorial which is continuously updated. This is regular Spring Boot, Spring MVC, Annotation, GPA – nothing fancy. So you can start with that – I think that’s a good resource.
There also is my talk at devoxx. The first one is a two or three hour deep dive into Coroutines with Spring, RSocket, R2DBC which is much more detailed than I was able to show today.
There is a dedicated GitHub repository with the front end in Kotlin.js which is another interesting topic. I was not able to go into details, but this topic is covered in more detail in my talk.
The other talk is about running Spring Boot applications, as well as running it via native images. If you want more detailed information about that or to learn more about GraalVM native in a kind of a neutral approach, meaning I try to show the advantages of the platform and the drawbacks in kind of a balanced way, you should take a look at that talk.
Thank you a lot!






