

Kotlin
A concise multiplatform language developed by JetBrains
KotlinDL 0.5 Has Come to Android!

Version 0.5 of our deep learning library, KotlinDL, is now available!
This release focuses on the new API for the flexible and easy-to-use deployment of ONNX models on Android. We have reworked the Preprocessing DSL, introduced support for ONNX runtime execution providers, and more. Here’s a summary of what you can expect from this release:
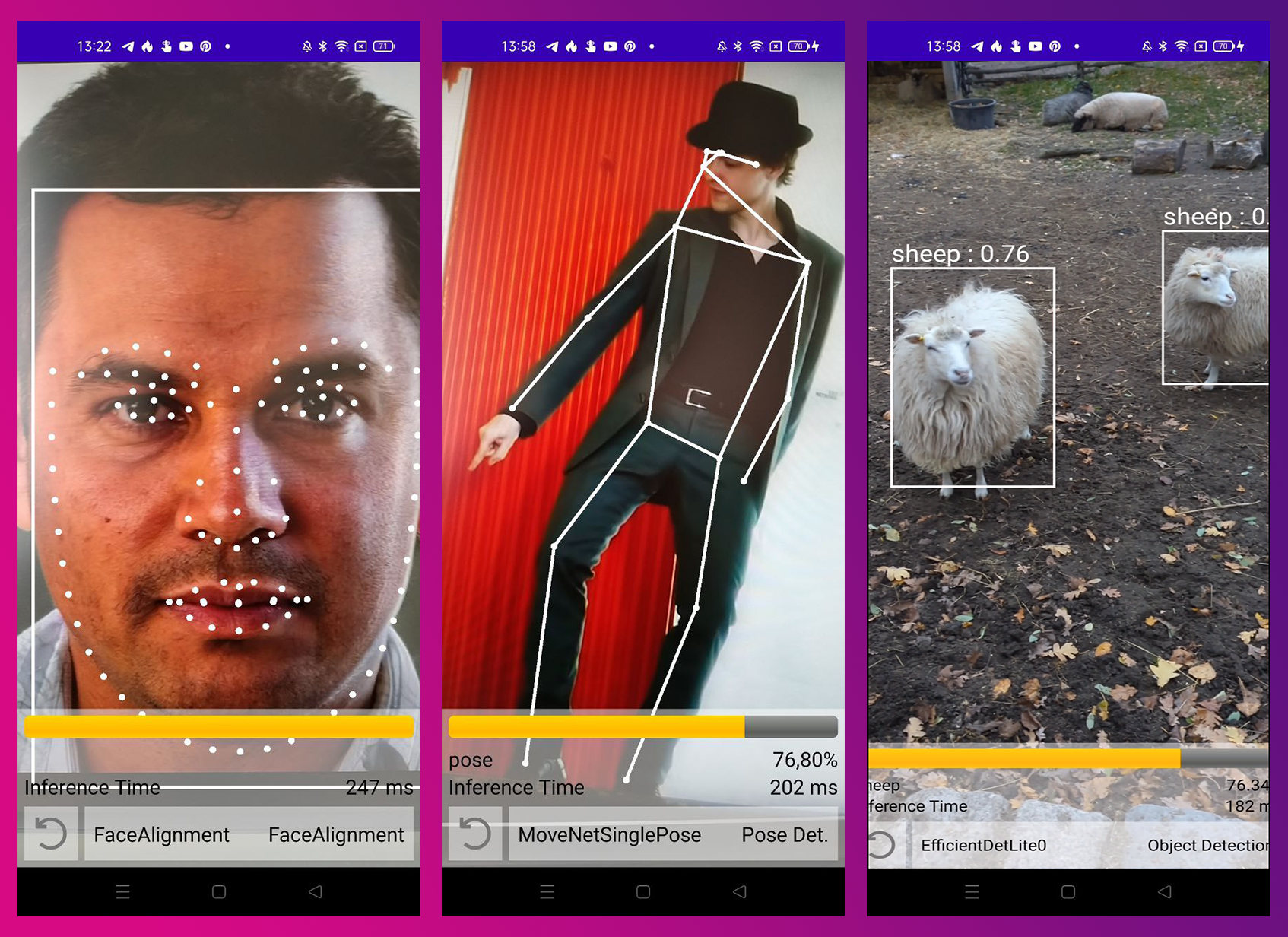
KotlinDL on GitHub Android demo app
Android support
We introduced ONNX support in KotlinDL 0.3. ONNX is an open-source format for representing deep learning models with flexible and extensible specification, and it is supported by many different frameworks. It was designed to be fast, portable, and interoperable with existing toolsets such as TensorFlow or PyTorch. With this release of KotlinDL, you can now run ONNX models on Android devices using the concise Kotlin API!
The most convenient way to start with KotlinDL on Android is to load the model through ModelHub. You can easily instantiate models included in our ModelHub through the ONNXModels API, and then you’ll be ready to run inference on Bitmap or ImageProxy.
Use cases supported by the Android ONNX ModelHub include:
- Object Detection
- Image Classification
- Pose Detection
- Face Detection
- Face Alignment
KotlinDL ONNX is ready to be used with the ImageAnalysis API. This allows you, for example, to directly infer models shipped via ModelHub on the ImageProxy object.
Inference of the EfficientDetLite0 model directly on the ImageProxy input. Check out the demo here.
Note that the orientation of the retrieved camera image will be corrected automatically.
Preprocessing DSL
When working with images, it is often necessary to perform some preprocessing steps before feeding them to the model. KotlinDL provides a convenient DSL for preprocessing, allowing you to apply a sequence of transformations to the input image easily. The DSL is based on the concept of a pipeline, where each transformation is a pipeline stage. Each stage is described by an input and output data type. If the output type of one stage matches the input type of another, you can combine them into a pipeline. In this case, type-checking occurs at compilation time.
This approach allows you to implement different transformations for BufferedImage on the desktop and Bitmap on Android while utilizing a single DSL.
Bitmap preprocessing vs. BufferedImage preprocessing (side by side)
Note that the DSL is not limited to image preprocessing. You can use it to implement any preprocessing pipeline for your data.
We implemented the following set of operations for an Android Bitmap:
- Resize
- Rotate
- Crop
- Rescale
- Normalize
- ConvertToFloatArray
The ConvertToFloatArray operation supports two popular layouts for the low-level representation of a tensor, ChannelFirst (TensorLayout.NCHW), and ChannelsLast (TensorLayout.NHWC).
Inference on accelerated hardware
With KotlinDL 0.5, it is possible to run models on optimized hardware using the ONNX Runtime Execution Providers (EP) framework. This interface provides flexibility for you to deploy their ONNX models in different environments in the cloud and at the edge and optimize execution by taking advantage of the platform’s computational capabilities.
KotlinDL currently supports the following EPs:
- CPU (default)
- CUDA (for the devices with GPU and CUDA support)
- NNAPI (for Android devices with API 27+)
NNAPI is a framework that allows you to run inference on Android devices using hardware acceleration. With NNAPI, resource-intensive computations can be performed up to 9 times as fast as with the CPU execution provider on the same device. However, it is important to note that NNAPI cannot accelerate all models. NNAPI supports only a subset of operators. If the model contains unsupported operators, the runtime falls back to using CPU. Therefore you may not get any performance improvements, and you may even encounter performance degradation due to data transfer between the CPU and the accelerator. The ONNX runtime provides a tool for checking whether NNAPI can accelerate your model inference.
One option for defining execution providers for inference is to use the initializeWith function.
Loading and initialization of the model with NNAPI execution provider
Another option is to use convenience functions.
Custom models inference
KotlinDL ONNX ModelHub is a great way to start with KotlinDL on Android. However, if you have your own ONNX model, you can easily use it with KotlinDL.
Any ONNX model can be loaded and inferred using a lower-level API.
Loading and inference of custom model using the OnnxInferenceModel API. Check out the demo here.
As we see here, it’s possible to instantiate OnnxInferenceModel from the byte representation of the model file. The model file can be stored in the application’s resources or retrieved over the network.
Additional details
Breaking changes in the Preprocessing DSL
Starting with version 0.5, KotlinDL has a new syntax for describing preprocessing pipelines.
The old DSL vs. the new one (side by side)
Before version 0.5, the Preprocessing DSL had several limitations. The DSL described a preprocessing pipeline with a fixed structure, namely the BufferedImage processing stage (transformImage) and the subsequent tensor representation processing stage (transformTensor). We’ve changed this approach in version 0.5. From now on, the Preprocessing DSL allows you to build a pipeline from an arbitrary set of operations.
The save operation is no longer supported, but you can use the onResult operation as an alternative. This operation allows you to apply a lambda to the output of a previous transformation. This method can be useful for debugging purposes.
Another feature of the Preprocessing DSL in KotlinDL 0.5 is the ability to reuse entire chunks of the pipeline in different places using the call function. Many models require input data with identical preprocessing, and the call function can reduce code duplication in such scenarios.
Convenience functions for inference with execution providers
KotlinDL provides convenience extension functions for the inference of ONNX models using different execution providers:
inferUsinginferAndCloseUsing
Those functions explicitly declare the EPs to be used for inference in their scope. Although these two functions have the same goal of explicitly initializing the model with the given execution providers, they behave slightly differently. inferAndCloseUsing has Kotlin’s use scope function semantics, which means that it closes the model at the end of the block; meanwhile, inferUsing is designed for repeated use and has Kotlin’s run scope function semantics.
You can find some examples here.
Implementing custom preprocessing operations
If you need to implement a custom preprocessing operation, you can do so by implementing the Operation interface and corresponding extension functions.
Check out this example implementation of custom operations.
New API for composite output parsing
Most of the models in KotlinDL have a single output tensor. However, some models have multiple outputs.
For example, the SSD model has three output tensors. In KotlinDL 0.5, we introduce a new API for parsing composite outputs and add a bunch of convenience functions for processing the OrtSession.Result, for example:
getFloatArrayWithShapeget2DFloatArraygetByteArrayWithShapegetShortArray
This allows you to write more explicit and readable code and reduces the number of unchecked casts.
For example, this code is used to get the output of the SSD model.
Learn more and share your feedback
We hope you enjoyed this brief overview of the new features in KotlinDL 0.5! Visit the project’s home on GitHub for more information, including the up-to-date Readme file.
If you have previously used KotlinDL, use the changelog to find out what has changed.
We’d be very thankful if you would report any bugs you find to our issue tracker. We’ll try to fix all the critical issues in the 0.5.1 release.
You are also welcome to join the #kotlindl channel in Kotlin Slack (get an invite here). In this channel, you can ask questions, participate in discussions, and receive notifications about new preview releases and models in ModelHub.








