

Faster Python: Unlocking the Python Global Interpreter Lock

What is Python’s Global Interpreter Lock (GIL)?
“Global Interpreter Lock” (or “GIL”) is a familiar term in the Python community. It is a well-known Python feature. But what exactly is a GIL?
If you have experience with other programming languages (Rust, for example), you may already know what a mutex is. It’s an abbreviation for “mutual exclusion”. A mutex ensures that data can only be accessed by one thread at a time. This prevents data from being modified by multiple threads at once. You might think of it as a type of “lock” – it blocks all threads from accessing data, except for the one thread that holds the key.
The GIL is technically a mutex. It lets only one thread have access to the Python interpreter at a time. I sometimes imagine it as a steering wheel for Python. You never want to have more than one person in control of the wheel! Then again, a group of people on a road trip will often switch drivers. This is kind of like handing off interpreter access to a different thread.
Because of its GIL, Python does not allow true multithreaded processes. This feature has sparked debates in the past decade, and there have been many attempts to make Python faster by removing the GIL and allowing multithreaded processes. Recently in Python 3.13, an option to have a way to use Python without the GIL, sometimes known as no-GIL or free-threaded Python, has been put in place. Thus begins a new era of Python programming.
Why was the GIL there in the first place?
If the GIL is so unpopular, why was it implemented in the first place? There are actually benefits to having a GIL. In other programming languages with true multithreading, sometimes issues are caused by more than one thread modifying data, with the final outcome depending on which thread or process finishes first. This is called a “race condition”. Languages like Rust are often hard to learn because programmers have to use mutexes to prevent race conditions.
In Python, all objects have a reference counter to keep track of how many other objects require information from them. If the reference counter reaches zero, since we know there is no race condition in Python due to the GIL, we can confidently declare that the object is no longer needed and can be garbage-collected.
When Python was first released in 1991, most personal computers only had one core, and not many programmers were requesting support for multithreading. Having a GIL solves many problems in program implementation and can also make code easy to maintain. Therefore, a GIL was added by Guido van Rossum (the creator of Python) in 1992.
Fast-forward to 2025: Personal computers have multicore processers and thus way more computing power. We can take advantage of this extra power to achieve true concurrency without getting rid of the GIL.
Later in this post, we’ll break down the process of removing it. But for now, let’s look at how true concurrency works with the GIL in place.
Pros and cons of the GIL
Pros
- Simpler non-atomic reference counting
- Reduced risk of race conditions when accessing Python objects
- Straightforward CPython implementation
- Predictable performance characteristics for code that doesn’t rely on true parallelism
Cons
- CPU-bound threads cannot run in parallel
- Limited scaling on multicore processors
- Requires workarounds such as multiprocessing or native extensions
Multiprocessing in Python
Before we take a deep dive into the process of removing the GIL, let’s have a look at how Python developers can achieve true concurrency using the multiprocessing library. The multiprocessing standard library offers both local and remote concurrency, effectively side-stepping the Global Interpreter Lock by using subprocesses instead of threads. In this way, the multiprocessing module allows the programmer to fully leverage multiple processors on a given machine.
However, to perform multiprocessing, we’ll have to design our program a bit differently. Let’s have a look at the following example of how to use the multiprocessing library in Python.
Remember our async burger restaurant from part 1 of the blog series:
import asyncio
import time
async def make_burger(order_num):
print(f"Preparing burger #{order_num}...")
await asyncio.sleep(5) # time for making the burger
print(f"Burger made #{order_num}")
async def main():
order_queue = []
for i in range(3):
order_queue.append(make_burger(i))
await asyncio.gather(*(order_queue))
if __name__ == "__main__":
s = time.perf_counter()
asyncio.run(main())
elapsed = time.perf_counter() - s
print(f"Orders completed in {elapsed:0.2f} seconds.")
We can use the multiprocessing library to do the same, for example:
import multiprocessing
import time
def make_burger(order_num):
print(f"Preparing burger #{order_num}...")
time.sleep(5) # time for making the burger
print(f"Burger made #{order_num}")
if __name__ == "__main__":
print("Number of available CPU:", multiprocessing.cpu_count())
s = time.perf_counter()
all_processes = []
for i in range(3):
process = multiprocessing.Process(target=make_burger, args=(i,))
process.start()
all_processes.append(process)
for process in all_processes:
process.join()
elapsed = time.perf_counter() - s
print(f"Orders completed in {elapsed:0.2f} seconds.")
As you may recall, a lot of the methods in multiprocessing are very similar to threading. To see the difference in multiprocessing, let’s explore a more complex use case:
import multiprocessing
import time
import queue
def make_burger(order_num, item_made):
name = multiprocessing.current_process().name
print(f"{name} is preparing burger #{order_num}...")
time.sleep(5) # time for making burger
item_made.put(f"Burger #{order_num}")
print(f"Burger #{order_num} made by {name}")
def make_fries(order_num, item_made):
name = multiprocessing.current_process().name
print(f"{name} is preparing fries #{order_num}...")
time.sleep(2) # time for making fries
item_made.put(f"Fries #{order_num}")
print(f"Fries #{order_num} made by {name}")
def working(task_queue, item_made, order_num, lock):
break_count = 0
name = multiprocessing.current_process().name
while True:
try:
task = task_queue.get_nowait()
except queue.Empty:
print(f"{name} has nothing to do...")
if break_count > 1:
break # stop if idle for too long
else:
break_count += 1
time.sleep(1)
else:
lock.acquire()
try:
current_num = order_num.value
order_num.value = current_num + 1
finally:
lock.release()
task(current_num, item_made)
break_count = 0
if __name__ == "__main__":
print("Welcome to Pyburger! Please place your order.")
burger_num = input("Number of burgers:")
fries_num = input("Number of fries:")
s = time.perf_counter()
task_queue = multiprocessing.Queue()
item_made = multiprocessing.Queue()
order_num = multiprocessing.Value("i", 0)
lock = multiprocessing.Lock()
for i in range(int(burger_num)):
task_queue.put(make_burger)
for i in range(int(fries_num)):
task_queue.put(make_fries)
staff1 = multiprocessing.Process(
target=working,
name="John",
args=(
task_queue,
item_made,
order_num,
lock,
),
)
staff2 = multiprocessing.Process(
target=working,
name="Jane",
args=(
task_queue,
item_made,
order_num,
lock,
),
)
staff1.start()
staff2.start()
staff1.join()
staff2.join()
print("All tasks finished. Closing now.")
print("Items created are:")
while not item_made.empty():
print(item_made.get())
elapsed = time.perf_counter() - s
print(f"Orders completed in {elapsed:0.2f} seconds.")
Here’s the output we get:
Welcome to Pyburger! Please place your order. Number of burgers:3 Number of fries:2 Jane has nothing to do... John is preparing burger #0... Jane is preparing burger #1... Burger #0 made by John John is preparing burger #2... Burger #1 made by Jane Jane is preparing fries #3... Fries #3 made by Jane Jane is preparing fries #4... Burger #2 made by John John has nothing to do... Fries #4 made by Jane Jane has nothing to do... John has nothing to do... Jane has nothing to do... John has nothing to do... Jane has nothing to do... All tasks finished. Closing now. Items created are: Burger #0 Burger #1 Fries #3 Burger #2 Fries #4 Orders completed in 12.21 seconds.
Note that there are some limitations in multiprocessing that lead to the above code being designed this way. Let’s go over them one by one.
First, remember that we previously had make_burger and make_fries functions to generate a function with the correct order_num:
def make_burger(order_num):
def making_burger():
logger.info(f"Preparing burger #{order_num}...")
time.sleep(5) # time for making burger
logger.info(f"Burger made #{order_num}")
return making_burger
def make_fries(order_num):
def making_fries():
logger.info(f"Preparing fries #{order_num}...")
time.sleep(2) # time for making fries
logger.info(f"Fries made #{order_num}")
return making_fries
We cannot do the same while using multiprocessing. An attempt to do so will give us an error along the lines of:
AttributeError: Can't get local object 'make_burger.<locals>.making_burger'
The reason is that multiprocessing uses pickle, which can only serialize top-module-level functions in general. This is one of the limitations of multiprocessing.
Second, notice in the example code snippet above using multiprocessing, we do not use any global variables for shared data. For example, we can’t use global variables for item_made and order_num. To share data between different processes, special class objects like Queue and Value from the multiprocessing library are used and passed to the processes as arguments.
Generally speaking, sharing data and states between different processes is not encouraged, as it can cause a lot more issues. In our example above, we have to use a Lock to ensure the value of order_num can only be accessed and incremented by one process at a time. Without the Lock, the order number of the item can be messed up like this:
Items created are: Burger #0 Burger #0 Fries #2 Burger #1 Fries #3
Here’s how you’d use a lock to avoid trouble:
lock.acquire()
try:
current_num = order_num.value
order_num.value = current_num + 1
finally:
lock.release()
task(current_num, item_made)
To learn more about how to use the multiprocessing standard library, you can peruse the documentation here.
Will Python remove the GIL?
Python has not removed the GIL, but PEP 703 makes it optional and introduces a free-threaded build in Python 3.13. The standard build still uses the GIL, and this will remain the case until the ecosystem fully supports free-threaded operation. Work on the free-threaded path is continuing, and Python 3.14 will advance it beyond the experimental stage. Full removal depends on library compatibility and community adoption in the future.
Removing the GIL
The removal of the GIL has been a topic for almost a decade. In 2016, at the Python Language Summit, Larry Hastings presented his thoughts on performing a “GIL-ectomy” on the CPython interpreter and the progress he’d made with this idea [1]. This was a pioneering attempt to remove the Python GIL. In 2021, Sam Gross reignited the discussion about removing the GIL [2], and that led to PEP 703 – Making the Global Interpreter Lock Optional in CPython in 2023.
As we can see, the removal of the GIL is by no means a rushed decision and has been the subject of considerable debate within the community. As demonstrated by the above examples of multiprocessing (and PEP 703, linked above), when the guarantee provided by the GIL is removed, things get complicated fast.
[1]: https://lwn.net/Articles/689548/
[2]: https://lwn.net/ml/python-dev/CAGr09bSrMNyVNLTvFq-h6t38kTxqTXfgxJYApmbEWnT71L74-g@mail.gmail.com/
Reference counting
When the GIL is present, reference counting and garbage collection are more straightforward. When only one thread at a time has access to Python objects, we can rely on straightforward non-atomic reference counting and remove the object when the reference count reaches zero.
Removing the GIL makes things tricky. We can no longer use non-atomic reference counting, as that does not guarantee thread safety. Things can go wrong if multiple threads are performing multiple increments and decrements of the reference on the Python object at the same time. Ideally, atomic reference counting would be used to guarantee thread safety. But this method suffers from high overhead, and efficiency is hampered when there are a lot of threads.
The solution is to use biased reference counting, which also guarantees thread safety. The idea is to bias each object towards an owner thread, which is the thread accessing that object most of the time. Owner threads can perform non-atomic reference counting on the objects they own, while other threads are required to perform atomic reference counting on those objects. This method is preferable to plain atomic reference counting because most objects are only accessed by one thread most of the time. We can cut down on execution overhead by allowing the owner thread to perform non-atomic reference counting.
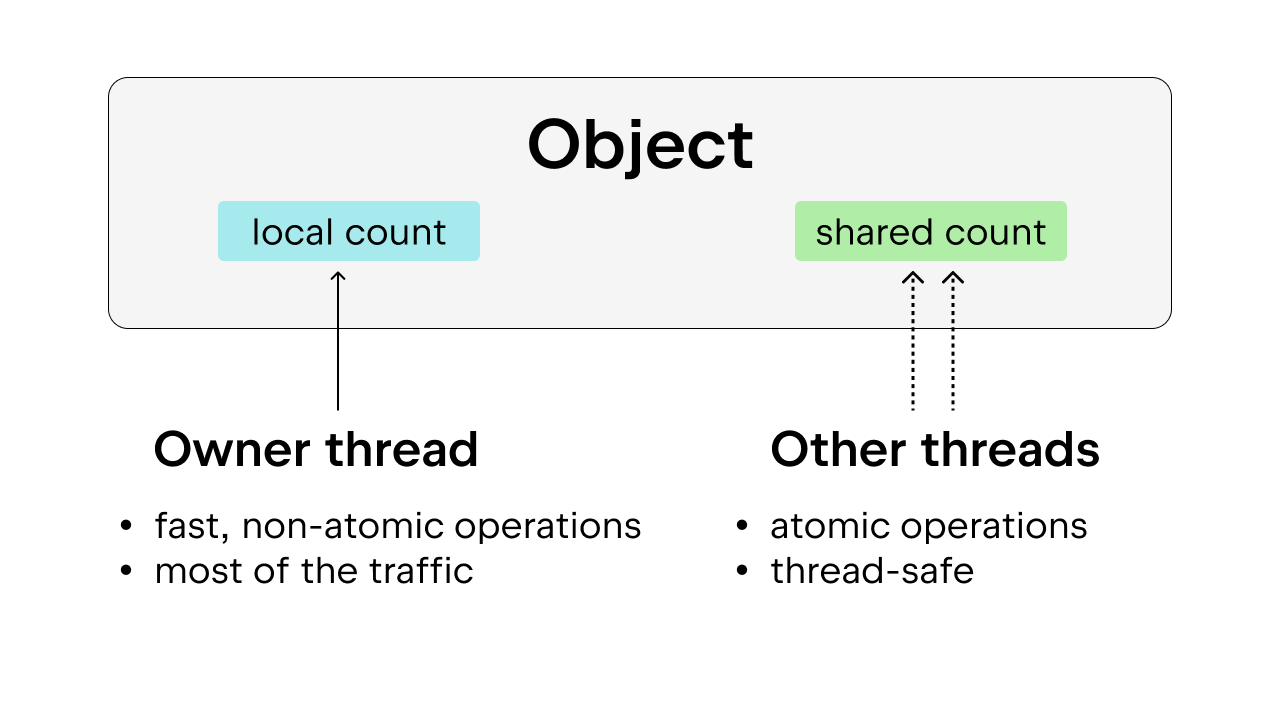
In addition, some commonly used Python objects, such as True, False, small integers, and some interned strings, are made immortal. Here, “immortal” just means the objects will remain in the program for its entire lifetime, thus they don’t require reference counting.
Garbage collection
We also have to modify the way garbage collection is done. Instead of decreasing the reference count immediately when the reference is released and removing the object immediately when the reference count reaches zero, a technique called “deferred reference counting” is used.
When the reference count needs to be decreased, the object is stored in a table, which will be double-checked to see whether this decrement in the reference count is accurate or not. This avoids removing the object prematurely when it is still being referenced, which can happen without the GIL, since reference counting is not as straightforward as with the GIL. This complicates the garbage collection process, as garbage collection may need to traverse each thread’s stack for each thread’s own reference counting.
Another thing to consider: The reference count needs to be stable during garbage collection. If an object is about to be discarded but then suddenly gets referenced, this will cause serious issues. Because of that, during the garbage collection cycle, it will have to “stop the world” to provide thread-safety guarantees.
Memory allocation
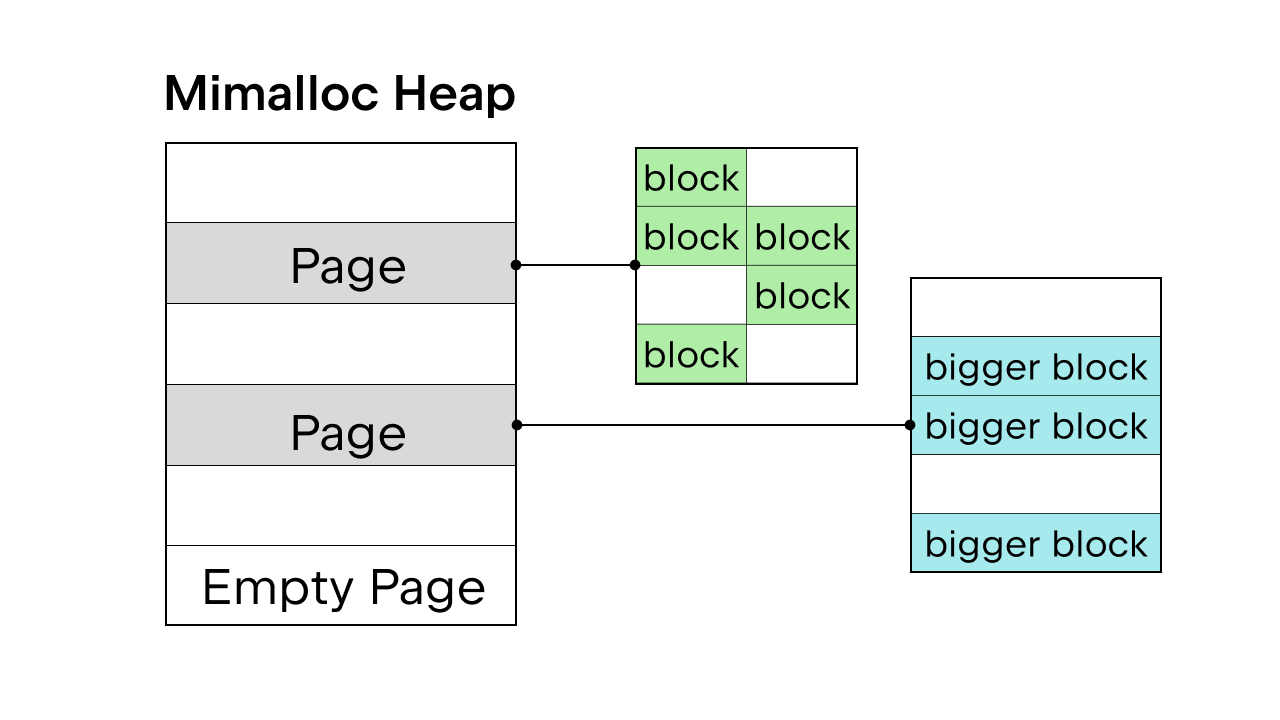
When the GIL is there to ensure thread safety, the Python internal memory allocator pymalloc is used. But without the GIL, we’ll need a new memory allocator. Sam Gross proposed mimalloc in the PEP, which is a general-purpose allocator created by Daan Leijen and maintained by Microsoft. It’s a good choice because it’s thread-safe and has good performance on small objects.
Mimalloc fills its heap with pages and pages with blocks. Each page contains blocks, and the blocks within each page are all the same size. By adding some restrictions on the list and dict access, the garbage collector does not have to maintain a linked list to find all objects and it also allows read access to the list and dict without acquiring the lock.
There are more details about removing the GIL, but it is impossible to cover them all here. You can check out PEP 703 – Making the Global Interpreter Lock Optional in CPython for a complete breakdown.
Difference in performance with and without the GIL
As Python 3.13 provides a free-threaded option, we can compare the performance of the standard version of Python 3.13 to the free-threaded version.
Install thread-free Python
We’ll use pyenv to install both versions: the standard (e.g. 3.13.5) and the free-threaded version (e.g. 3.13.5t).
Alternatively, you can also use the installers on Python.org. Make sure you select the Customize option during installation and check the additional box to install free-threaded Python (see the example in this blog post).
After installing both versions, we can add them as interpreters in a PyCharm project.
First, click on the name of your Python interpreter on the bottom right.
Select Add New Interpreter in the menu and then Add Local Interpreter.
Choose Select existing, wait for the interpreter path to load (which may take a while if you have a lot of interpreters like I do), and then select the new interpreter you just installed from the drop-down Python path menu.
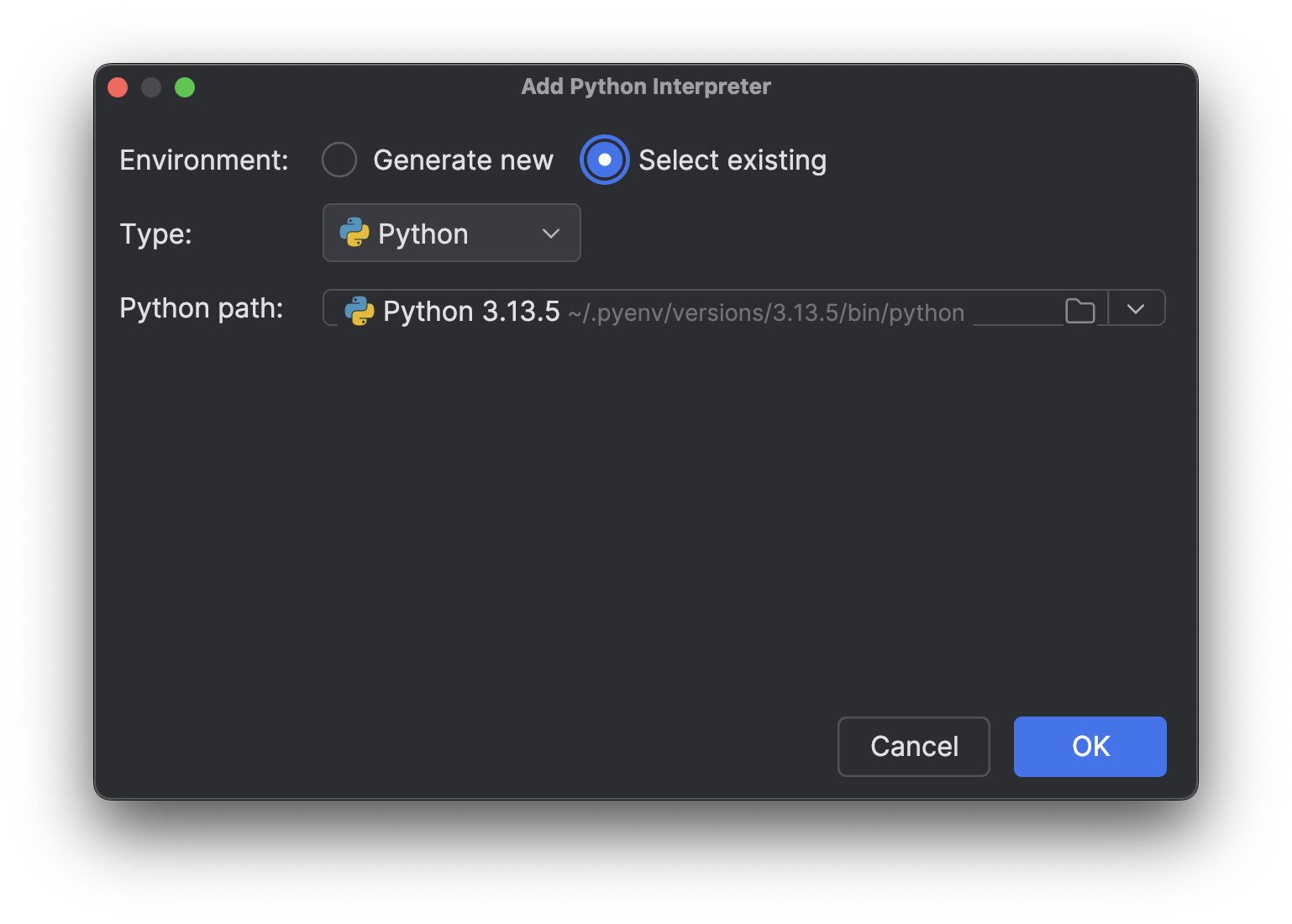
Click OK to add it. Repeat the same steps for the other interpreter. Now, when you click on the interpreter name at the bottom right again, you will see multiple Python 3.13 interpreters, just like in the image above.
Testing with a CPU-bound process
Next, we need a script to test the different versions. Remember, we explained in part 1 of this blog post series that to speed up CPU-bound processes, we need true multithreading. To see if removing the GIL will enable true multithreading and make Python faster, we can test with a CPU-bound process on multiple threads. Here is the script I asked Junie to generate (with some final adjustments by me):
import time
import multiprocessing # Kept for CPU count
from concurrent.futures import ThreadPoolExecutor
import sys
def is_prime(n):
"""Check if a number is prime (CPU-intensive operation)."""
if n <= 1:
return False
if n <= 3:
return True
if n % 2 == 0 or n % 3 == 0:
return False
i = 5
while i * i <= n:
if n % i == 0 or n % (i + 2) == 0:
return False
i += 6
return True
def count_primes(start, end):
"""Count prime numbers in a range."""
count = 0
for num in range(start, end):
if is_prime(num):
count += 1
return count
def run_single_thread(range_size, num_chunks):
"""Run the prime counting task in a single thread."""
chunk_size = range_size // num_chunks
total_count = 0
start_time = time.time()
for i in range(num_chunks):
start = i * chunk_size + 1
end = (i + 1) * chunk_size + 1 if i < num_chunks - 1 else range_size + 1
total_count += count_primes(start, end)
end_time = time.time()
return total_count, end_time - start_time
def thread_task(start, end):
"""Task function for threads."""
return count_primes(start, end)
def run_multi_thread(range_size, num_threads, num_chunks):
"""Run the prime counting task using multiple threads."""
chunk_size = range_size // num_chunks
total_count = 0
start_time = time.time()
with ThreadPoolExecutor(max_workers=num_threads) as executor:
futures = []
for i in range(num_chunks):
start = i * chunk_size + 1
end = (i + 1) * chunk_size + 1 if i < num_chunks - 1 else range_size + 1
futures.append(executor.submit(thread_task, start, end))
for future in futures:
total_count += future.result()
end_time = time.time()
return total_count, end_time - start_time
def main():
# Fixed parameters
range_size = 1000000 # Range of numbers to check for primes
num_chunks = 16 # Number of chunks to divide the work into
num_threads = 4 # Fixed number of threads for multi-threading test
print(f"Python version: {sys.version}")
print(f"CPU count: {multiprocessing.cpu_count()}")
print(f"Range size: {range_size}")
print(f"Number of chunks: {num_chunks}")
print("-" * 60)
# Run single-threaded version as baseline
print("Running single-threaded version (baseline)...")
count, single_time = run_single_thread(range_size, num_chunks)
print(f"Found {count} primes in {single_time:.4f} seconds")
print("-" * 60)
# Run multi-threaded version with fixed number of threads
print(f"Running multi-threaded version with {num_threads} threads...")
count, thread_time = run_multi_thread(range_size, num_threads, num_chunks)
speedup = single_time / thread_time
print(f"Found {count} primes in {thread_time:.4f} seconds (speedup: {speedup:.2f}x)")
print("-" * 60)
# Summary
print("SUMMARY:")
print(f"{'Threads':<10} {'Time (s)':<12} {'Speedup':<10}")
print(f"{'1 (baseline)':<10} {single_time:<12.4f} {'1.00x':<10}")
print(f"{num_threads:<10} {thread_time:<12.4f} {speedup:.2f}x")
if __name__ == "__main__":
main()
To make it easier to run the script with different Python interpreters, we can add a custom run script to our PyCharm project.
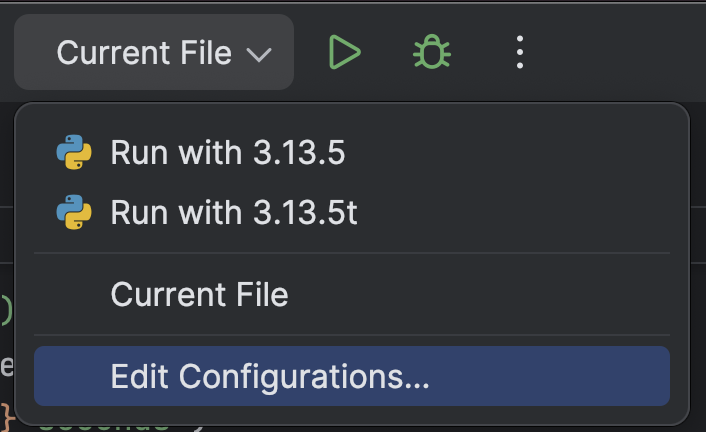
At the top, select Edit Configurations… from the drop-down menu next to the Run button (![]() ).
).
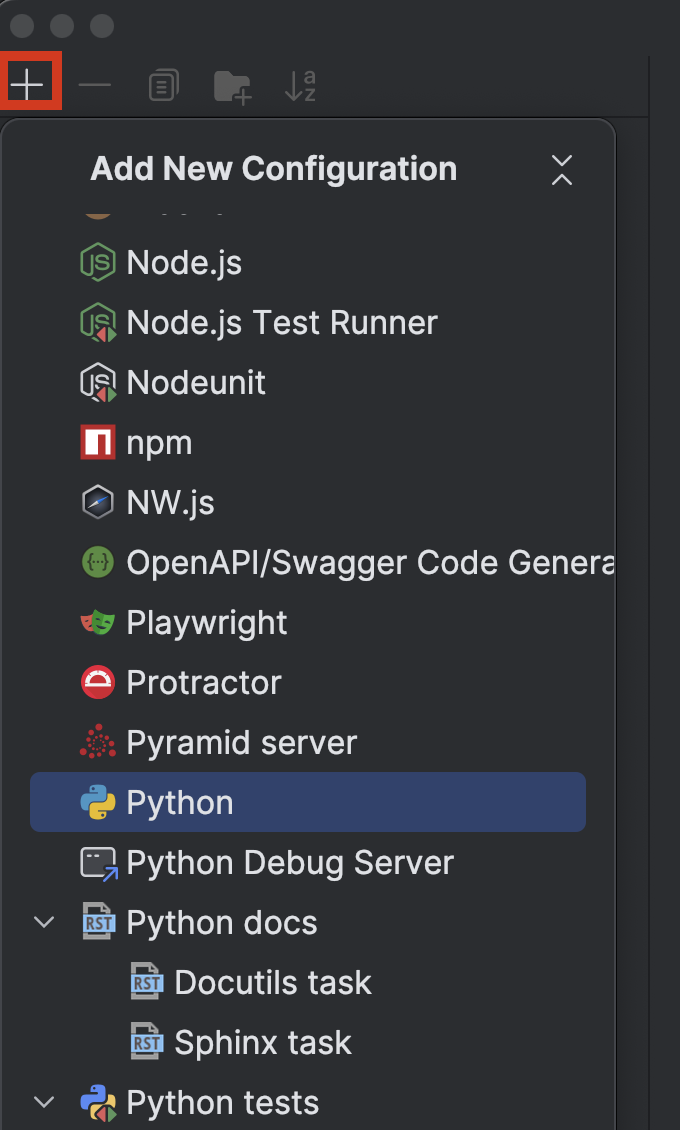
Click on the + button in the top left, then choose Python from the Add New Configuration drop-down menu.
Choose a name that will allow you to tell which specific interpreter is being used, e.g. 3.13.5 versus 3.15.3t. Pick the right interpreter and add the name of the testing script like this:
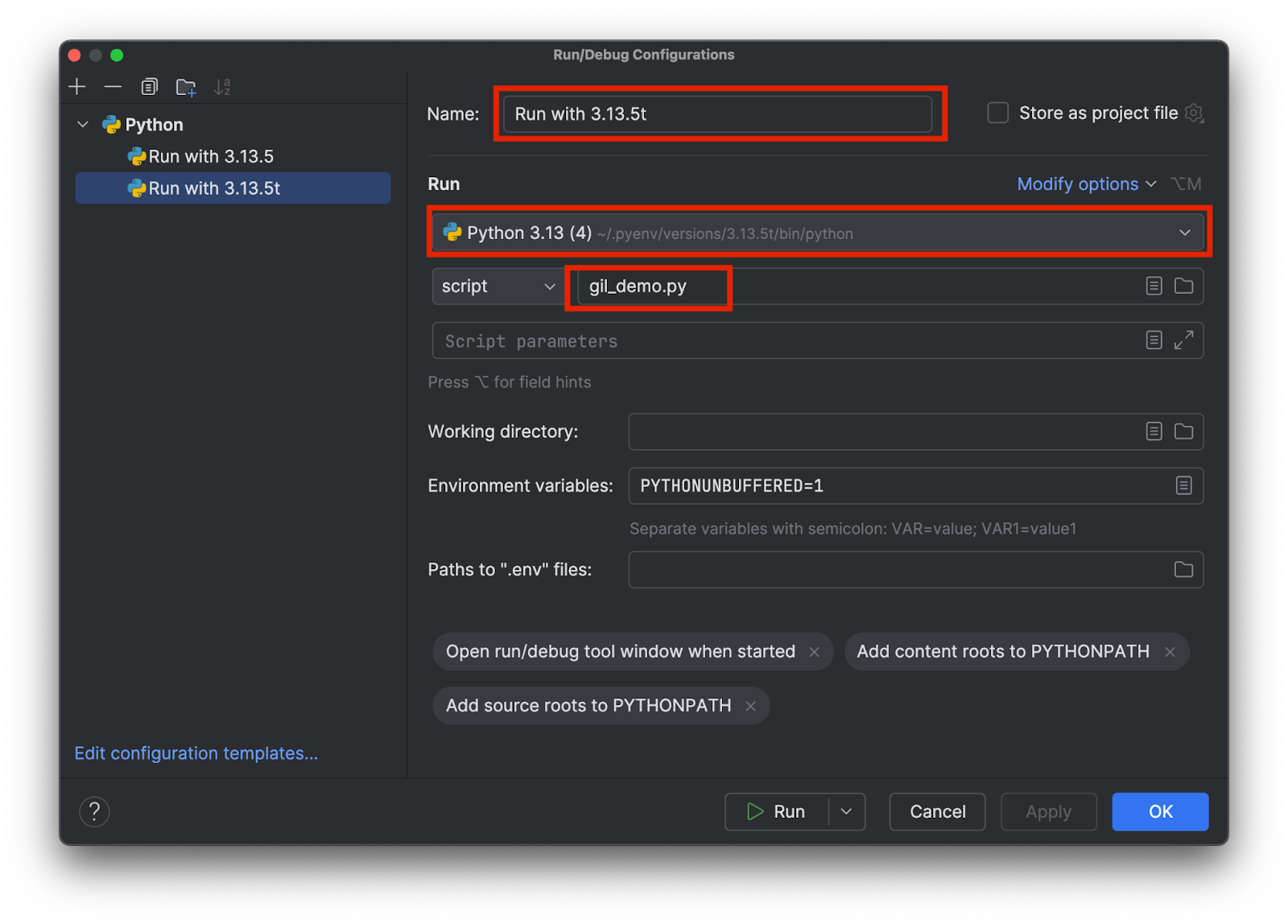
Add two configurations, one for each interpreter. Then click OK.
Now we can easily select and run the test script with or without the GIL by selecting the configuration and clicking the Run button (![]() ) at the top.
) at the top.
Comparing the results
This is the result I got when running the standard version 3.13.5 with the GIL:
Python version: 3.13.5 (main, Jul 10 2025, 20:33:15) [Clang 17.0.0 (clang-1700.0.13.5)] CPU count: 8 Range size: 1000000 Number of chunks: 16 ------------------------------------------------------------ Running single-threaded version (baseline)... Found 78498 primes in 1.1930 seconds ------------------------------------------------------------ Running multi-threaded version with 4 threads... Found 78498 primes in 1.2183 seconds (speedup: 0.98x) ------------------------------------------------------------ SUMMARY: Threads Time (s) Speedup 1 (baseline) 1.1930 1.00x 4 1.2183 0.98x
As you see, there is no significant change in speed when running the version with 4 threads compared to the single-threaded baseline. Let’s see what we get when running the free-threaded version 3.13.5t:
Python version: 3.13.5 experimental free-threading build (main, Jul 10 2025, 20:36:28) [Clang 17.0.0 (clang-1700.0.13.5)] CPU count: 8 Range size: 1000000 Number of chunks: 16 ------------------------------------------------------------ Running single-threaded version (baseline)... Found 78498 primes in 1.5869 seconds ------------------------------------------------------------ Running multi-threaded version with 4 threads... Found 78498 primes in 0.4662 seconds (speedup: 3.40x) ------------------------------------------------------------ SUMMARY: Threads Time (s) Speedup 1 (baseline) 1.5869 1.00x 4 0.4662 3.40x
This time, the speed was over 3 times as high. Notice that in both cases there is an overhead for multithreading. Therefore, even with true multithreading, the speed is not 4 times as high with 4 threads.
Conclusion
In part 2 of the Faster Python blog post series, we discussed the reason behind having the Python GIL in the past, side-stepping the limitation of the GIL using multiprocessing, and the process and effect of removing the GIL.
As of this blog post, the free-threaded version of Python is still not the default. However, with the adoption of the community and third-party libraries, the community is expecting the free-threaded version of Python to be the standard in the future. It has been announced that Python 3.14 will include a free-threaded version that will be past the experimental stage but still optional.
PyCharm provides best-in-class Python support to ensure both speed and accuracy. Benefit from the smartest code completion, PEP 8 compliance checks, intelligent refactorings, and a variety of inspections to meet all of your coding needs. As demonstrated in this blog post, PyCharm provides custom settings for Python interpreters and run configurations, allowing you to switch between interpreters with only a few clicks, making it suitable for a wide range of Python projects.






