
JetBrains Research
Research is crucial for progress and innovation, which is why at JetBrains we are passionate about both scientific and market research
Supercharging Unit Test Generation with in-IDE TestSpark

Test generation is an essential yet time-consuming part of quality assurance. Automating test-generation techniques means accelerating the development process and improving the quality of the final software. However, traditional automated techniques, and their respective tools, are not usually user-friendly, having a command-line interface and not being integrated with the IDE. To boost acceleration and quality while also improving user-friendliness, some recent approaches have incorporated AI, often via large language models (LLMs), including our own AI Assistant and Junie.
Our Software Testing Research team recently collaborated with TU Delft to develop a research framework: TestSpark, which unites the above aspects for improved test generation for Java and Kotlin programs. Namely, the user can choose LLM-based and/or automated testing techniques, it has a good user interface, and it is well integrated with IntelliJ for research purposes.
In this blog post, we will tell you more about TestSpark. Specifically:
- How it compares to traditional test-generation techniques
- How it compares to other LLM-based approaches
- What cool technical features it presents
Automated test generation
Test generation is the process of creating test cases and test data to evaluate software systems. Generating effective tests is essential to developing good software, and failing to generate effective tests can negatively impact the quality and robustness of the project.
Unit test generation in particular is concerned with a functionally discrete unit, such as a method or a class. Other testing levels include integration or system: they are focused on bigger sets of units or components, and the data flow between them.
Even though writing tests, especially manual ones, can feel like a tedious task you might want to skip or delegate to AI, testing ultimately helps you move faster, not slower. Without the safety net that tests provide, any new changes to the code can also unintentionally introduce bugs hidden deep in the flow. Luckily, more advanced techniques have been developed since then that are less tedious, freeing up your time for what you most likely actually want to do: code.
Automated test generation techniques use algorithmic and AI-based methods to automatically produce unit tests for software code, optimizing for metrics like code coverage, fault detection, and test suite quality. The table summarizes some main types of automated test generation and examples of tools developed for Java.
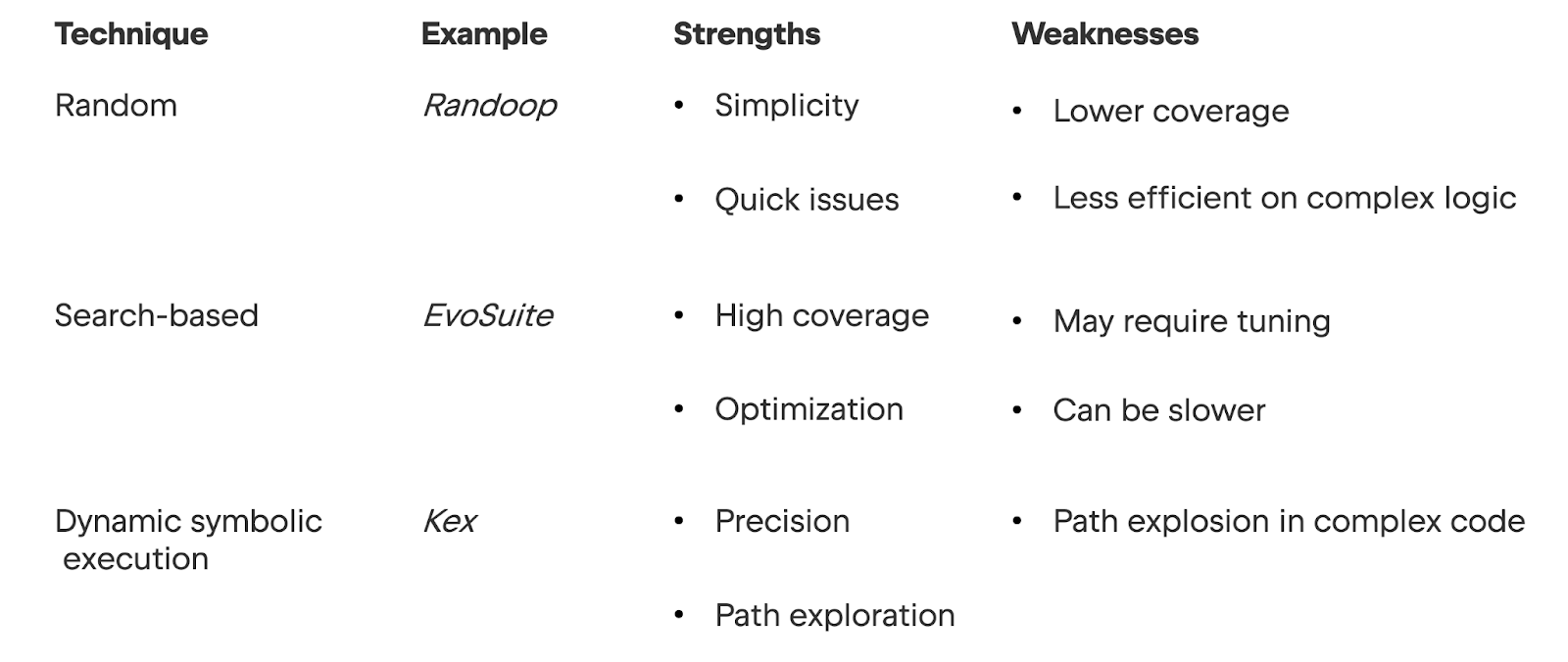
The first technique in the table above, random testing, involves generating test cases with randomly generated inputs. The second technique, search-based testing, uses algorithms to evolve test suites toward high coverage or fault-detection objectives, enabling more systematic detection of uncovered test scenarios. In the third technique, dynamic symbolic execution, a program is run using abstract inputs instead of concrete ones. That is, the code is executed symbolically and the program runs through every possible path for each input. This technique boosts testing coverage, but it is limited in complex scenarios.
While there are advantages to all of these techniques, combining any with LLMs can yield both higher coverage and more meaningful tests than any single technique alone. As we will see below, TestSpark allows the user to choose different test generation methods, including a search-based testing method and an LLM-based one.
The rest of this section will introduce search-based techniques in more detail, and then the following section introduces LLM-based test generation. If you already know this background, skip ahead to see how TestSpark improves on traditional testing!
Search-based techniques
Software testing can be approached as an optimization problem, i.e., a set of parameters that describe a specific system’s design, variables, objectives and constraint conditions; and search-based techniques can be used to solve such a problem. A big advantage of this type of technique is that it is able to handle bigger and more complex search spaces than random and manual testing.
Metaheuristic algorithms are designed to iterate through a complex search space, a term which refers to the set of all possible solutions. The technique includes one or more objective functions, called fitness functions, to evaluate the possible solutions. This also means that the fitness function is useful to provide a better guide for the algorithm in a very large, or even infinite, search space. The goal is to efficiently find a near-optimal solution out of that solution set.
These types of approaches date back to Webb Miller and David Spooner’s 1976 publication, where they proposed a simple yet innovative-at-the-time technique to generate test data with floating-point inputs. These data were input into a version of the software under test and executed. They used a cost function, akin to a fitness function, where the better-performing inputs received low-cost values and those receiving higher values were discarded.
The methods commonly used today are modelled after natural processes, such as those found in biology and physics. Two notable techniques are:
- Genetic algorithms, which can evolve a set of solutions over generations, similar to traits in the natural selection process.
- One example of a genetic algorithm-based test-generation tool is EvoSuite, which is used to evolve test suites in Java.
- Another example appeared in this recent blog post, where we went into more detail about how a type of genetic algorithm can be used in fuzz-testing compilers.
- Simulated annealing, which involves one solution that changes slightly in each iteration, much like the controlled process of heating, then slowly cooling down metal to remove defects in metallurgy’s annealing process.
- Some real-world examples of simulated annealing applications can be found in this older paper and this more recent paper.
Overall, search-based techniques involve encoding the solutions in a way that allows the search algorithm to manipulate them. We see that for both of the techniques introduced above:
- Genetic algorithms evolve the solutions with mutated and recombined solutions in multiple generation cycles.
- Simulated annealing involves changing the solution slightly or dramatically in each iteration.
On top of that, it is necessary to define fitness functions, so that the manipulated solution, or set of solutions, can be evaluated for optimality. For the two techniques, the function has the following application:
- In a genetic algorithm, the function evaluates characteristics of solutions, much like traits of organisms, with respect to how well they solve the relevant problem
- In simulated annealing, the function evaluates the current solution version: if it provides a better solution than the previous solution, the current one is accepted as the new solution. Otherwise, the current solution is discarded.
Optimization goals and advantages
Above, we talked about how search-based techniques approach testing as an optimization problem. So what goals in solving these problems, and what are the advantages over, say, a random search?
In general, developers or researchers optimize for testing aspects that increase time- and cost-efficiency. This is possible while maintaining high-quality results, overall rendering the testing process more effective and reliable as well as more efficient. A good test generation algorithm includes the following optimizations.
Techniques with the intent to maximize test coverage aim to generate test cases covering as many execution paths as possible. This coverage could target particular statements, branches, or paths, for example, and simulated annealing is useful for this.
When looking to minimize test suite size, the optimization’s goal is to reduce the number of test cases while maintaining or maximizing coverage. Such techniques consequently reduce the time spent and resources used – an important advantage in software testing. For instance, some approaches use a genetic algorithm to generate a set of test cases with high statement coverage, then apply a greedy algorithm to remove redundant ones and minimize the final suite size. Another objective for these algorithms is fault detection capability, which can be calculated by mutation score.
Despite automated testing’s improvement over manual testing, challenges remain, including incorporating domain knowledge and balancing exploration with exploitation in the search process. A major disadvantage of traditional automated research prototypes is their reliance on the command-line interface, severely limiting usability. Developers are unable to implement them within integrated development environments (IDEs); instead, they revert to using the tool outside the IDE and then manually integrating the output into their projects.
LLM-based test generation
Recently, LLM-based test generation has become a common technique for automated test generation and for attempting to overcome the challenges mentioned above. Research evaluating them has also shown that LLM-based test generation has the potential to help developers improve software testing (see also this review). Namely, tools using this technique are able to leverage the models’ understanding of source code, documentation, requirements, and even natural language bug reports to produce relevant test cases and suites.
Tools and techniques
Besides AI agents like Junie being able to automate test generation, a number of tools have been developed specifically for this purpose. Common LLM-based tools include TestPilot (paper), ChatUniTest (paper), and TestSpark (paper; GitHub). These particular tools are similar in their approach to test generation; the process comprises:
- Context collection
- LLM request
- Feedback loop that tries to improve the initial LLM response
Other tools like AthenaTest or SynPrompt are also LLM-based, although they differ in focus. AthenaTest generates tests for individual methods, and does not include a feedback loop. SynPrompt generates tests at the method level and uses code-aware prompts to target specific paths within the method under test. While these tools show promising results, they are limited in their applicability and are not being developed for general unit test generation.
LLM limitations in test generation
As promising as LLM-based tools are showing themselves to be, however, they might not be able to generate tests that are immediately ready to be executed without any issues.
Members of our research team published a 2025 paper in collaboration with TU Delft comparing different unit test generation approaches. Motivating the study are some critical limitations in previous evaluations of LLM-based techniques. These include the following (at the time the paper was submitted):
- No approaches were evaluated for Java test generation.
- Existing approaches were evaluated using the LLM’s training data. This introduces risks of data leakage, which can result in overestimating the model’s utility in a production environment.
- In particular for Java test generation up to the point of the paper’s submission: previous studies do not always account for the non-determinism of LLMs, nor do the researchers always run the models more than once. This means that the LLM may produce different outputs when queried with the same prompt.
In the paper, they examined three different automated test generation tools based on three different techniques: EvoSuite, a search-based tool; Kex, a symbolic execution tool; and TestSpark, an LLM-based hybrid tool, which can optionally include the other two approaches (here, only the LLM-based technique was investigated). To evaluate the differences in language model performance, TestSpark has been configured with different LLMs (i.e., ChatGPT-4, ChatGPT-4o, Llama Medium, and Code Llama 70b).
The researchers assessed each tool’s performance based on execution metrics (e.g., code coverage) and feature-based metrics (e.g., class under test complexity), and used GitBug Java, a recent dataset not previously used in such evaluation studies. Finally, they ran each tool ten times with different seeds, including independent sessions for TestSpark. These measures were meant to address the limitations of previous studies listed above.
The results can be summarized as follows:
- TestSpark, the LLM-based tool, significantly outperformed the other two in mutation scores, suggesting that LLM-based test generation tools can provide a deeper semantic understanding of code.
- In coverage-based metrics, EvoSuite and Kex, the search-based and symbolic execution tools, performed very similarly, and both performed better than TestSpark.
- The researchers’ feature-based analysis showed that all tools are primarily affected by the complexity and internal dependencies of the class under test, and the LLM-based approaches are especially sensitive to the class size.
- Among the LLMs evaluated for TestSpark, ChatGPT-4o performed the best, but the statistical analysis suggested that its performance still lagged behind traditional methods like search-based and symbolic execution.
A takeaway from the results is that LLM-based test generation shows potential for test generation, is better in some aspects than traditional approaches, but still has room for improvement. TestSpark, the LLM-based tool investigated in the reported study, is a research prototype integrated in the IDE, and it provides a new opportunity to better understand in-IDE test generation.
Advancing research on LLM-based test generation with in-IDE TestSpark
In collaboration with TU Delft, our Software Testing Research team developed TestSpark, an open-source unit test generation plugin for IntelliJ IDEA, and published a tool demo paper in the ICSE 2024 proceedings. This research prototype was designed to be more user-friendly while remaining a reliable test generation tool. It was also designed to let contributors easily integrate other test generation tools by following open-source documentation.

An aim of TestSpark is to ensure all tests generated by LLMs are compilable by proposing a feedback loop between the LLM and the IDE. In case of a compilation issue, the algorithm prepares a prompt with the compilation error and asks the LLM to fix the problem.
TestSpark and IDEs
TestSpark’s user-friendly interface is a significant improvement over other tools. Crucially, it is a standalone plugin, not needing any further installation, and it supports and runs within the latest versions of IntelliJ IDEA. As mentioned above, TestSpark’s current version allows the user to test with various techniques, including an LLM-based one and a search-based one using EvoSuite.
Users can initiate the test generation process for a unit under test by simply right-clicking on a unit and selecting the TestSpark option. Among the configuration options are the choice of test generation technique and, if using LLM-based, the choice of LLM. Upon selecting the desired test generation technique, the process starts. This process is depicted in the figure below (adapted from Sapozhnikov et al. 2024: 2).
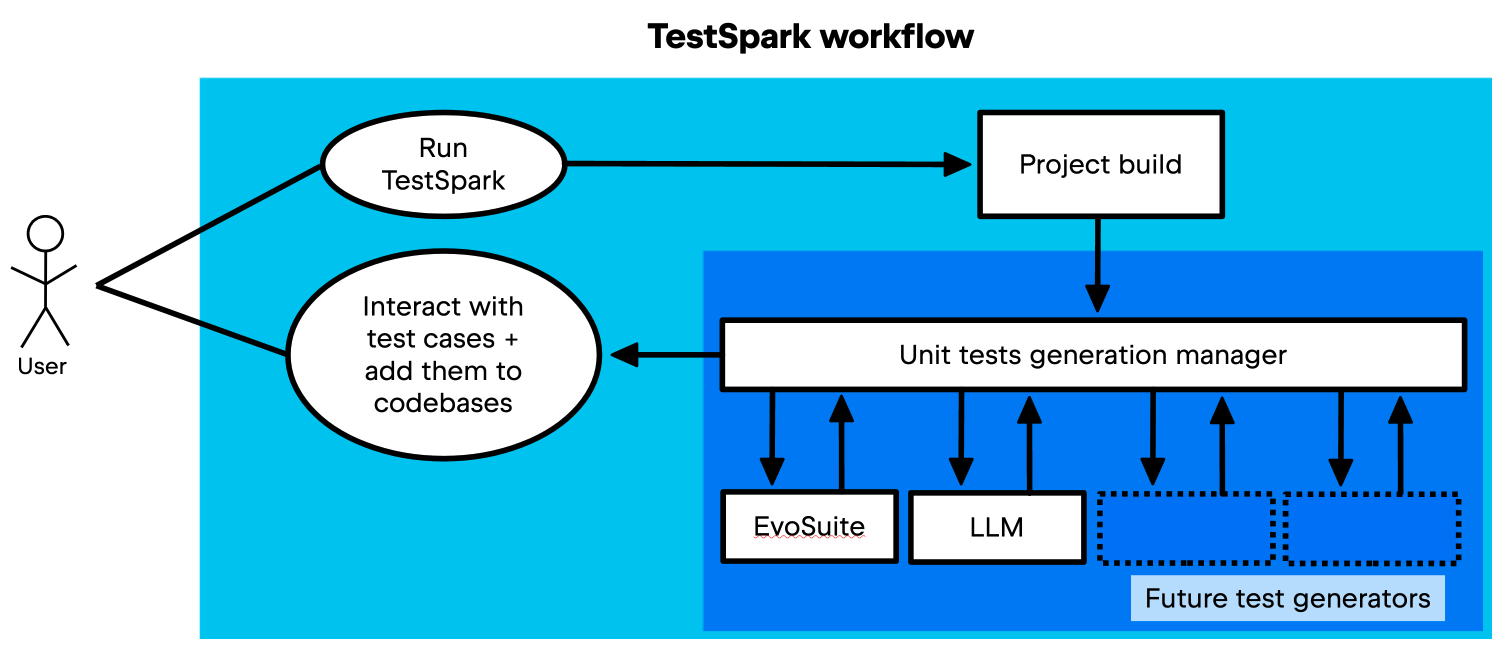
First, the user asks for test generation for a unit. Then, the plugin tries to build the project within IntelliJ IDEA. If it cannot compile, TestSpark informs the user. If it can compile, the unit test generation manager prompts the user to choose the test generation technique. After this, the tests are collected and seamlessly transmitted to the visualization service, where the results are presented to the user.
After test generation, TestSpark visualizes coverage and test results within the IDE. Each test case is listed with pass/fail status, detailed errors, and coverage impact. Users can directly modify, rerun, and select which to add to the codebase; all necessary imports and files are managed automatically. The below screenshot shows an example visualization (figure from Sapozhnikov et al. 2024: 4).
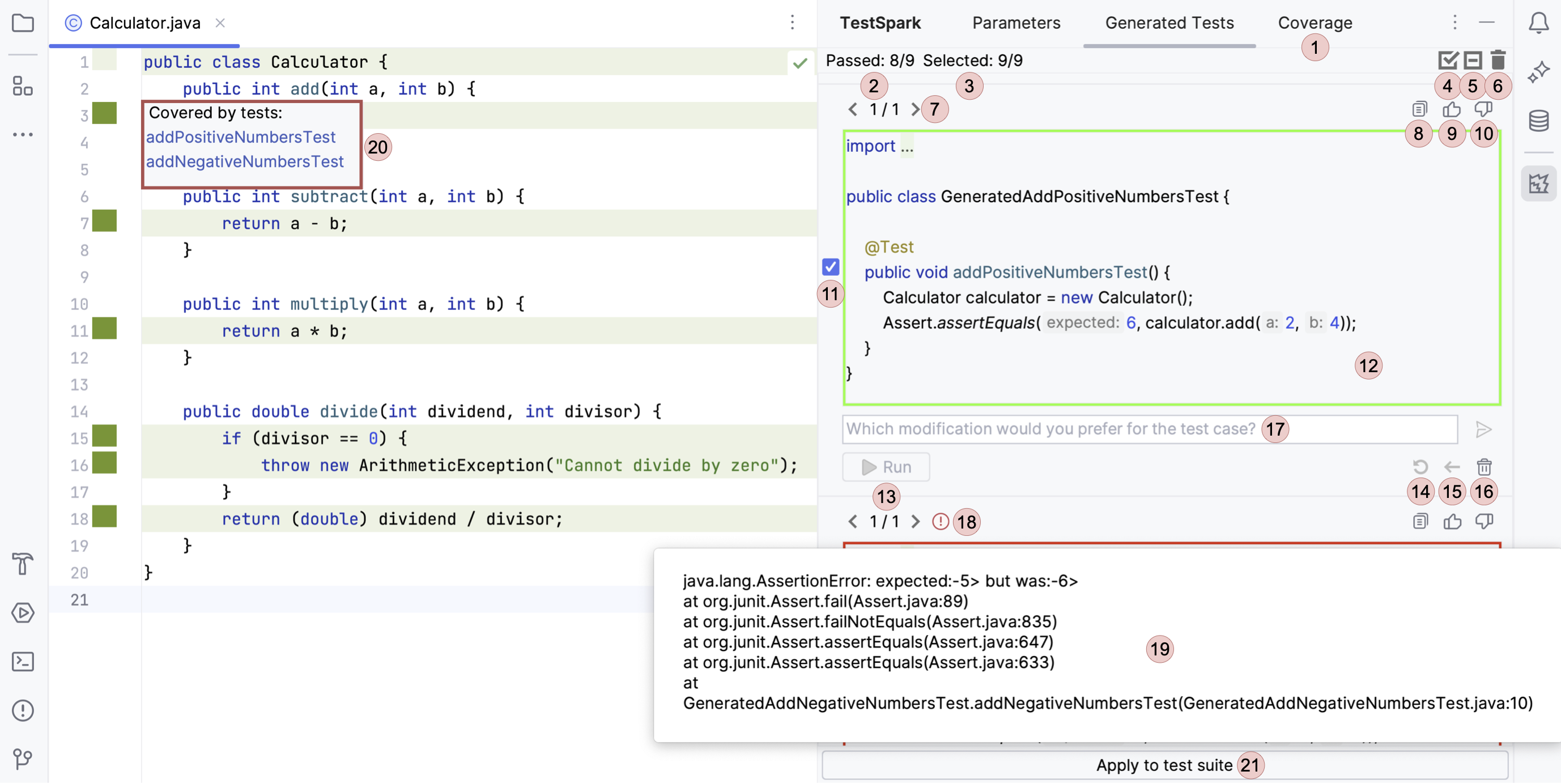
The figure above shows how the results of all the generated tests are visualized. Let’s begin with the right side: Each test is visible by clicking the Generated Test tab (in the image above, < 1/1 > indicates one out of one tests are being shown), and the Coverage tab displays the structural coverage and mutation scores of all tests.
Users have the option to copy, like, dislike, and select each test case. Also, the border color of each test block indicates whether it passed (green) or failed (red); in the test block shown above, the test passed. In case of failure, users can hover over the error symbol to view the error message, and each test case has a text field where users can directly send a modification request to the LLM.
Moving to the left side: Each covered line contains a green square on its left. Clicking on this square opens a list of test cases that cover this line. Finally, users can integrate the selected/modified tests into their project by clicking the “Apply to test suite” button. The user can put the tests either in a new or existing file.
With its smart feedback loop between LLMs and the IDE, TestSpark overcomes the common LLM pitfall of generating non-compiling or redundant tests. This guarantees robust, compilable test cases that raise code quality while saving precious developer time. Even though the feedback loop might increase the cost, the user can control the threshold – and the default value keeps the cost below that of an agentic approach.
TestSpark’s technical highlights
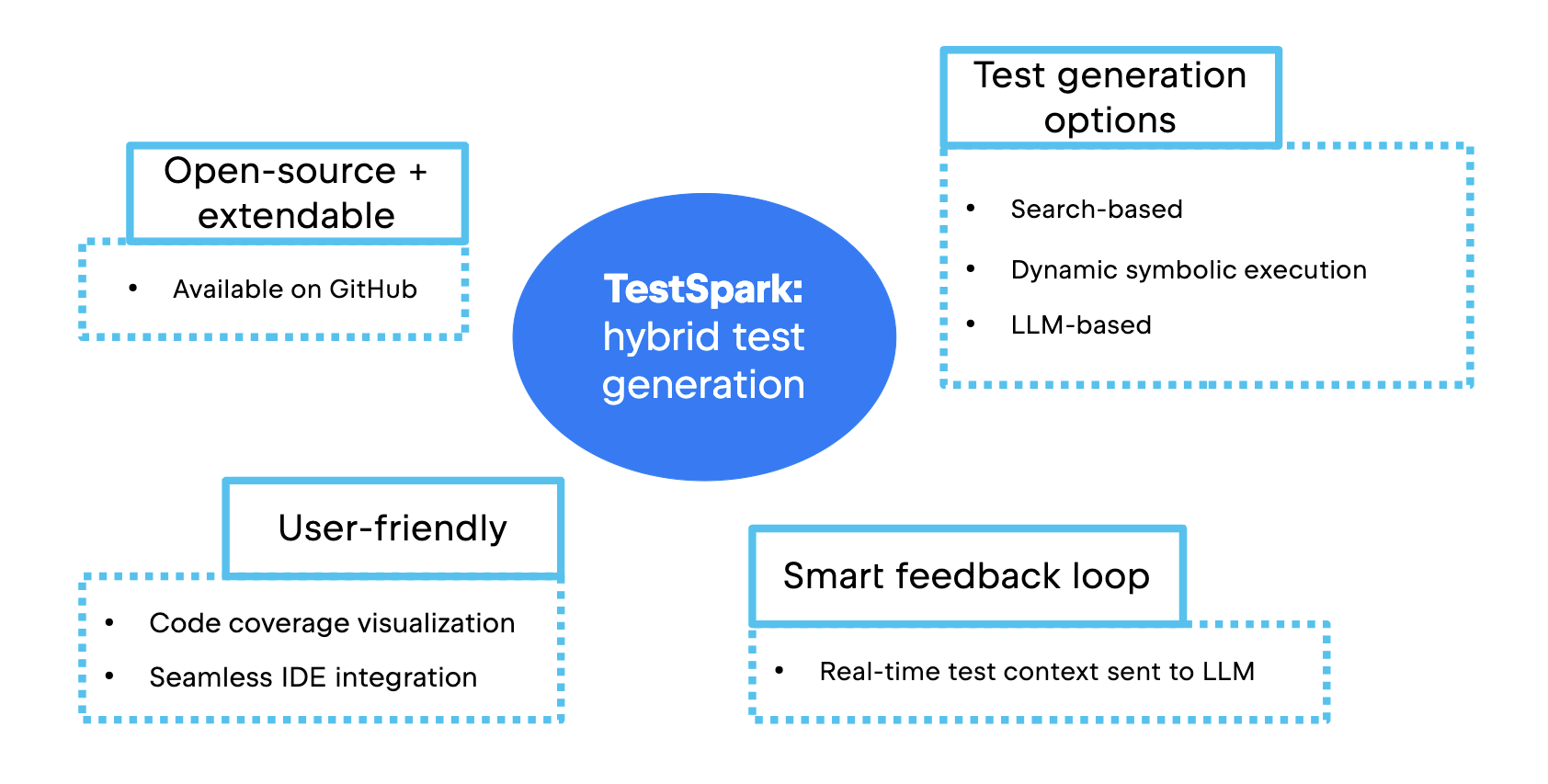
The hybrid nature of TestSpark’s test generation approach means it has a number of cool technical features and advantages over singular approaches.
Above, we can see how it fully embeds in the IDE. This is a big plus over existing tools, as it provides developers with seamless test generation, code coverage visualization, and integration into the project workflow. In other words, it is very user-friendly.
By design, TestSpark is extendable and open-source. Its codebase is publicly available on GitHub. Developers and researchers can contribute new test generation approaches by following the provided documentation and plugin architecture.
TestSpark is integrated in IntelliJ IDEA and as it is open source, you can try testing with it, too. Please note that while it is integrated in IntelliJ IDEA, TestSpark is not a part of the AI Assistant subscription, so you need your own token for any LLM you might use in TestSpark.
An important innovation of TestSpark is that it uses information collected from IntelliJ IDEA to generate the context for tests and uses the compilation result as feedback to LLM to improve the results. By leveraging the real-time context of the IDE, TestSpark makes AI-based test generation useful for everyday development, rather than theoretical research.
Key takeaways
TestSpark can be a practical, reliable part of the industrial developer’s workflow, bridging the gap between research innovation and everyday software engineering needs. Its advantages can be summarized as follows:
- Makes advanced test generation accessible to everyday developers, not just researchers, inside the IDE.
- Enables hybrid or future approaches using both search-based and LLM paradigms.
- Boosts the usefulness of LLM-generated tests with smart error-handling loop.





