
JetBrains Research
Research is crucial for progress and innovation, which is why at JetBrains we are passionate about both scientific and market research
Finding Order in the Mayhem: A Novel Concurrency Testing Tool that Improved the Kotlin Compiler



If you’ve ever tried to track down a bug in concurrent programs, you know how chaotic and frustrating it can be: everything seems to work fine, then suddenly crashes, and you can’t quite pin down why – all while the bugs slip through.
To bring order to this chaos, at JetBrains Research we built LitmusKt — a novel testing tool for Kotlin’s multiplatform concurrency. Designed specifically for Kotlin’s unique mix of JVM, Native, and JavaScript backends, LitmusKt helps developers uncover and eliminate subtle, platform-specific concurrency errors that traditional testing can’t catch.
In our previous post, we discussed a new approach to fuzzing the Kotlin compiler. Now we’re exploring how LitmusKt takes that work further – systematically revealing concurrency bugs hidden deep in the Kotlin runtime and compiler. In this post, we will:
- Talk about why concurrent programming is complex and why automated testing is particularly tricky.
- Explain how LitmusKt was needed for the Kotlin compiler and describe its cool technical features.
- Lay out the history of LitmusKt, from its infancy as a research prototype, some of the bugs it found, and how it is now integrated into Kotlin/Native development.
Concurrent programming
When multiple tasks or computations are executed simultaneously rather than sequentially, the approach is called concurrent programming. Although it may sound like a simple concept, it can sometimes act erratically when implemented improperly.
If it is so tricky, why is concurrent programming even implemented? Well, many programming problems are naturally concurrent: there are numerous tasks and external events running at the same time. Consider also how modern hardware itself is inherently concurrent, as most CPUs have multiple cores. Without concurrent code, we would not be able to use the cores to their full potential.
In Per Brinch Hansen’s The Invention of Concurrent Programming (which covers the history of concurrent programming up to 2001), he tells a story where he and Peter Kraft needed to design a real-time system for a large chemical plant. For this, a computer would perform a fixed number of tasks simultaneously. The tasks’ speed could be manually adjusted by the plant operators, which means that there was no set speed.
So they were working with simultaneous tasks and needed some sort of process synchronization. Sequential, task-independent programming wasn’t going to cut it. If you want to know what happens next, you can find it in Part I of their book (spoiler: they implemented Edsger Dijkstra’s semaphores).
Concurrent programming provides a number of advantages, including:
- Improved performance and throughput. More tasks are completed in a given timeframe. This is especially beneficial on multi-core processors, where different tasks can run on different cores.
- Efficient resource use, because system resources (like the CPU) can be used for other tasks while one task is waiting for input/output or another event. This reduces idle time and maximizes hardware efficiency.
- Better responsiveness and user experience, because applications like web browsers, graphical user interfaces, and real-time systems remain responsive to input while other tasks run in the background. This supports smooth and uninterrupted user interactions.
Challenges in concurrent programming
When concurrent programming was first introduced in the 1960s, the operating systems running it were rather unstable. Challenges included the following:
- A small programming error could cause a lot of problems but be really difficult to test for and therefore fix.
- Deadlocks, or when all parts of a concurrent process are blocked, usually due to a lack of resources.
Concurrent programming inherently involves simultaneously executed tasks. For this reason, challenges like the above arise because concurrent programming is highly dependent on unpredictable factors such as scheduling order or real-world timing. Let’s look at an example.
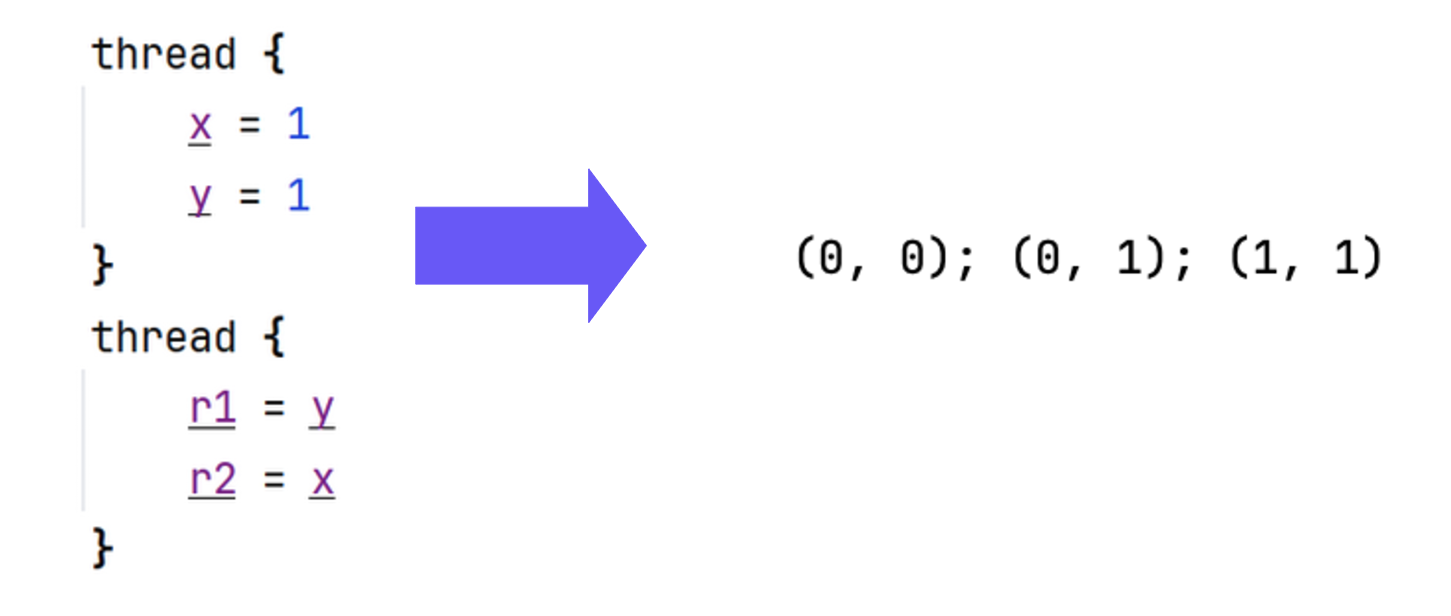
Consider a program that initializes two shared variables, x and y, with 0, and starts two threads running in parallel. Each thread writes 1 to its associated variable. Then, each reads the other variable and stores that value as its result (r1 and r2, respectively, which are also initialized with 0).
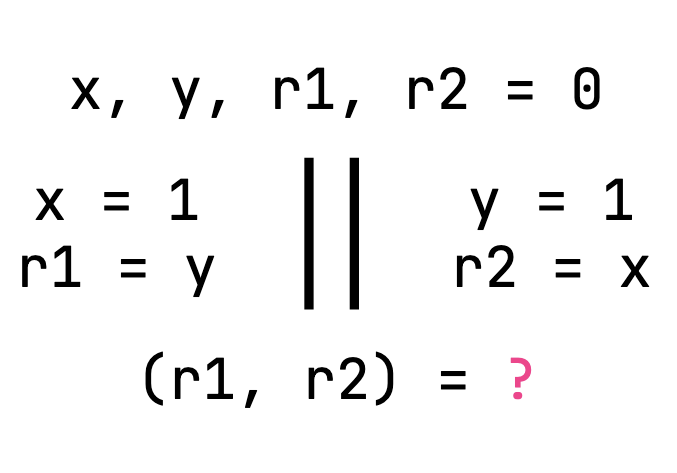
At first glance, the outcomes for r1 and r2 seem limited and predictable. Either:
- One thread finishes first, so it writes
1tox, reads0fromy, and the other reads the updated value1, giving us straightforward outcomes of(0, 1)or(1, 0), depending on which thread finished first. - Or both threads execute at the same time, so they both write
1, and both read1, yielding another expected result:(1, 1).
But then, after running the program many times, a seemingly impossible outcome starts to appear: Each thread reads 0, even though both have written 1.

This sort of bizarre outcome is called weak behavior. It can happen for one of two reasons:
- Compiler optimizations, where compilers rearrange instructions or eliminate redundant memory operations to increase performance. This can result in subtle bugs, or even break the code, as dependencies may be lost in the shuffle.
- CPU buffering and reordering, where the hardware itself may buffer, delay, or reorder reads and writes to maximize efficiency. Modern CPUs have weak memory models that allow operations to happen in surprising sequences, invisible in regular single-threaded programs.
Weak behaviors caused by the above are a central focus in analyzing and testing concurrent programs with specialized tools. If the programmer only looks at the code or thinks in terms of simple statement interleaving, these outcomes seem impossible.
In reality, compiler and CPU optimizations change the story, making concurrent programming far more elusive and unpredictable than it appears at first glance. This creates headaches for programmers and those designing programming languages. Because reasoning about these subtle interactions is so challenging, thorough testing is essential to ensure reliability.
Testing concurrent programs
Concurrent programming is difficult to test because nondeterministic thread interactions can produce subtle, non-reproducible failures. These are often called Heisenbugs, and they only appear under specific timings or schedules, making them inherently hard to find and troubleshoot. The same input can pass a test and then fail the very same test depending on subtle, uncontrollable sources of nondeterminism, and even the act of observing or debugging can mask or alter the bug’s behavior, contributing to flaky tests and prolonged debugging cycles.
Traditional testing approaches struggle here because listing all possible thread schedules is infeasible in practice, and even systematic methods that control scheduling to capture nondeterminism are time-consuming and resource-intensive. This challenge is compounded by state space explosion, where the number of possible interleavings grows combinatorially with threads and synchronization points, necessitating reductions such as partial-order reduction and guided exploration to avoid redundant paths.
For testing these notoriously tricky programs, developers use a variety of strategies. Some common ones are listed in the table below.

While code review and static analysis are both useful for early detection of concurrency bugs, they come with disadvantages as well. Namely, code review is susceptible to the reviewers’ errors and knowledge gaps; static analysis can generate false positives, thereby creating more work, and can miss runtime-only errors.
Random/fuzz/stress testing types are great for detecting rare or subtle bugs. They test programs under extreme conditions, for example with random inputs and under heavy load. These tests (especially stress testing) can also be useful to ensure smooth operation of a program in critical situations. These methods are usually resource-intensive, and they can sometimes produce false positives or miss more complex issues.
Many strategies work well with business logic and modest concurrency patterns, but fall short with the subtle hardware or compiler optimizations that lead to “impossible” results, like the (0,0) outcome above. For example, stress testing or fuzzing may uncover these bugs eventually, but a specific type of tests called litmus tests is designed to systematically target these subtle behaviors and confirm theoretical predictions. This strategy is highly effective for environments with well-defined memory models, like the Java Virtual Machine (JVM), or specific CPUs.
For the rest of this post, we will concentrate on litmus testing and then tell you about a specific litmus testing tool developed by JetBrains researchers.
Litmus testing
Litmus testing is like stress testing for concurrency: you write small concurrent programs (i.e., litmus tests) and run them thousands of times to catch rare, weird behaviors that only happen under specific timing conditions. Established tools like JCStress for Java and herdtools for assembly language have successfully found real bugs in production systems.
JCStress, for instance, is used by OpenJDK developers to test the JVM, catching subtle race conditions and memory model violations that could cause catastrophic failures in production. herdtools goes even deeper, testing assembly-level programs against processor memory models to ensure hardware behaves as expected. While these tools are useful for the respective languages, they run into limitations with multi-platform languages like Kotlin.
Unlike other languages, a key feature of Kotlin is that it compiles to JVM, Native, JavaScript, and WebAssembly, and each platform has its own distinct concurrency semantics and memory models. This diversity means some bugs cannot be caught with tools designed for just one backend – and so far existing tools hadn’t been able to handle this complexity. In other words, Kotlin needed its own litmus testing tool.
We took on the challenge of helping to discover bugs in the Kotlin compiler, and the result is a new tool that makes testing these tricky programs far easier.
Testing concurrency programs with LitmusKt
To overcome the lack of a proper Kotlin testing tool for concurrency programming, we at JetBrains Research) decided to build our own solution, LitmusKt (see their recent paper). This section will tell you about its design and tech highlights, as well as its practical applications.
LitmusKt’s design and cool technical features
LitmusKt allows developers to write litmus tests once and run them across both Kotlin/JVM and Kotlin/Native platforms. The tool uses a custom domain-specific language that makes writing tests straightforward. A few examples of what LitmusKt does:
- Declare shared states, such as shared variables, between threads.
- Write thread behavior so that it’s clear what each thread should do.
- Label expected outcomes as acceptable, interesting (i.e., noteworthy but allowed), or forbidden.
By using a custom DSL, developers can express thread interactions, shared variables, and outcome conditions flexibly, all within Kotlin. This lowers the barrier for writing complex concurrency tests.
Let’s run through an example. Below you can find the code for the Store Buffering test, which is a standard litmus test (it’s also the program we saw in the example before). The test involves (i) defining a shared state, (ii) running code for several threads, and (iii) specifying test outcomes; we will go through each one step by step.
object StoreBuffering {
val Plain = litmusTest({
object : LitmusIIOutcome() {
var x = 0
var y = 0
}
}) {
thread { x = 1; r1 = y }
thread { y = 1; r2 = x }
spec {
accept(r1 = 0, r2 = 1)
accept(r1 = 1, r2 = 0)
accept(r1 = 1, r2 = 1)
interesting(r1 = 0, r2 = 0)
}
reset { x = 0; y = 0 }
}
First, the test itself needs to be declared: we declare the state which will eventually be shared between the threads. In the example below, this comprises two int variables.
object StoreBuffering {
val Plain = litmusTest({
object : LitmusIIOutcome() {
var x = 0
var y = 0
}
Next comes the code for each thread, shown below.
}) {
thread { x = 1; r1 = y }
thread { y = 1; r2 = x }
Finally, we must declare the outcomes and their labels. The possible outcomes are:
- Acceptable: sequentially consistent outcomes
- Interesting: weak but tolerable outcomes according to the semantics of the programming language
spec {
accept(r1 = 0, r2 = 1)
accept(r1 = 1, r2 = 0)
accept(r1 = 1, r2 = 1)
interesting(r1 = 0, r2 = 0)
}
If you recall the example above, the result where r1 = 0 and r2 = 0 was unexpected, because it is weak behavior. In the code for the test, this result will be labelled as interesting, meaning it is acceptable but noteworthy. The other listed results are expected and therefore will be labelled as acceptable.
Let’s look at what happens when we run the test with LitmusKt. How often do we see weak behavior in one million tests?
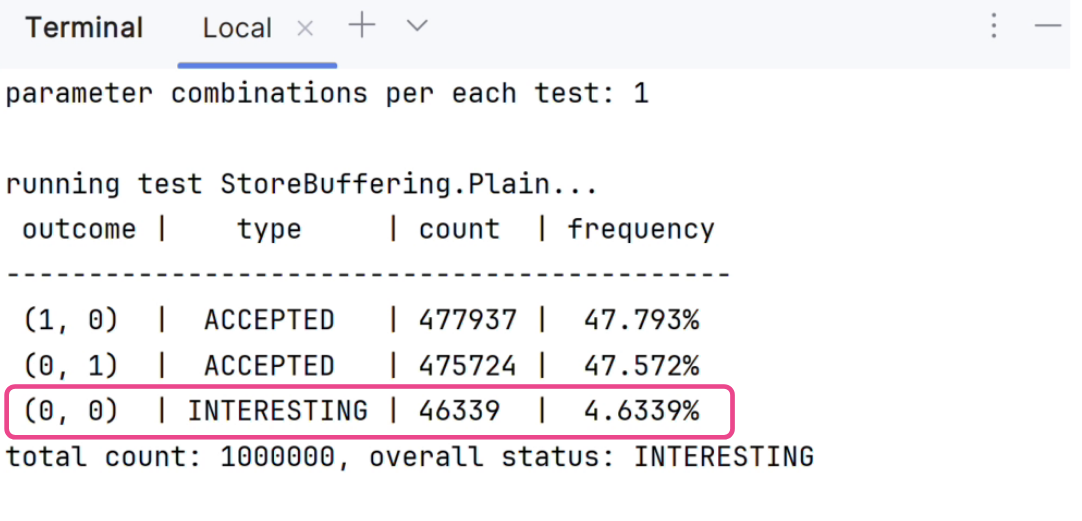
The above screenshot shows that interesting outcomes do occur, but that they are relatively rare, at less than five percent. To increase the frequency of finding these weak but tolerable outcomes, LitmusKt enables the user to apply different parameters to increase the number of complex interactions (see the paper for further details).
Now that we know how to write a test in LitmusKt, let’s look at the more technical details. Our team built a custom Kotlin/Native test runner from scratch because no solutions existed up until then. The test runner is built on techniques from other litmus testing tools, such as careful thread synchronization and CPU affinity control. We created a test runner so that the threads modify different states simultaneously many times over, significantly increasing the likelihood that a concurrent interaction occurs and weak behavior can be detected.
For Kotlin/JVM, we integrated the tool with the existing JCStress framework, as it is known to be successful in uncovering concurrency bugs in various JVM implementations. Despite some integration challenges, the end interface is seamless for the user.
To summarize, LitmusKt incorporates proven methods to maximize the frequency of rare behaviors and provides powerful reporting tools for manual and automated analysis. Users can also interact via a rich command-line interface, adjusting test parameters, durations, and system settings.
Considering all these features, has LitmusKt caught any Kotlin bugs? As we will see in the next section, it has.
LitmusKt and real code
We applied LitmusKt and several litmus tests to analyze the behavior of Kotlin programs, therefore testing the results of the Kotlin compiler and looking for previously unknown issues. The possible outcomes here are:
- Acceptable: sequentially consistent outcomes
- Interesting: weak but tolerable outcomes according to the semantics of the programming language
- Forbidden: weak intolerable outcomes, indicating bugs
In contrast to the Store Buffering Test above, this analysis includes two weak outcomes: one tolerable and one intolerable, where the latter outcome represents a bug. The testing results are shown in the following image, where ACC, INT, and FORB stand for acceptable, interesting, and forbidden.
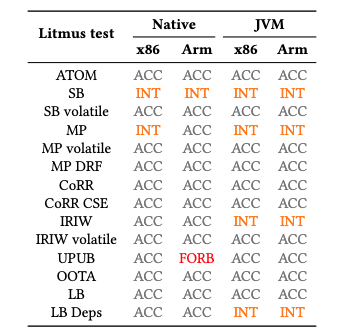
We can see that there are a number of tests uncovering interesting results, and one test in particular with forbidden results. The test abbreviated as UPUB in the table is unsafe publication. The forbidden results represent a situation where objects could be accessed before proper initialization, potentially causing rare and critical failures in production environments. The fact that memory-unsafe behavior could slip through in a memory-safe language like Kotlin demonstrates why systematic concurrency testing is essential.
Let’s look more closely at unsafe publication, shown in the code below, and what unexpected outcomes arose.
class IntHolder(val x: Int = 0)
val UnsafePublication = litmusTest({
object : LitmusIIOutcome() {
var h : IntHolder? = null
}
}) {
thread { h = IntHolder() }
thread { r1 = h?.x ?: -1 }
spec { accept(0); accept(-1) }
reset { h = null }
}
In the code above, we can see a simple class IntHolder with a single integer. The shared state is a reference to this class. Then, we have two threads: one which is going to create a new class, and one which will try to read its variable.
The outcome of running the unsafe publication test was expected to be one of two scenarios:
- The class
IntHolderis initialized —>0 - The class
IntHolderis not initialized —>-1
The actual outcome of running the unsafe publication test with Kotlin 1.9 is shown in the following image. Any result which is not declared as interesting or acceptable is considered forbidden.
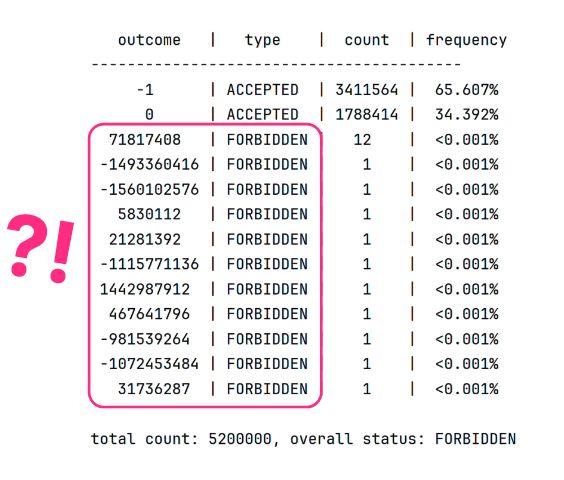
Unexpectedly, garbage values could be read from uninitialized memory. A memory-safe language like Kotlin definitely should not let this happen. In other words, our team found a new compiler bug thanks to LitmusKt. Since identifying the bug, our team has already fixed and merged it. As of Kotlin 1.9.20 and later, this bug no longer occurs.
We found further issues while running unsafe publication with LitmusKt (see the paper for more details). As these are valuable insights for the Kotlin compiler, and after discussion with the Kotlin/Native development team, LitmusKt is now embedded in the Kotlin CI/CD pipeline.
In addition to the issues arising from running different tests, we discovered more noteworthy outcomes. The below image contains the partial code of a standard litmus test and the resulting outcomes.
As can be seen in the above image, the test produces only three outcomes. So far, nothing crazy. The interesting bit happens when the code is slightly altered with semantically equivalent changes. That is, these changes theoretically should not result in any additional thread interactions. However, as the below image shows, another outcome actually does show up.

This extra outcome, marked in pink in the above image, is actually a weak outcome, as it cannot be achieved by interleaving execution of threads. We suspect that such behavior is caused by compiler optimizations. In the future, it might be worthwhile to combine compiler fuzzing (i.e., with random code mutations) with litmus testing to discover more edge cases.
Bringing order to Kotlin concurrency
LitmusKt proves that even in the mayhem of concurrent programming, order can be found. By catching bugs that once slipped through the cracks of the Kotlin compiler, it has made multiplatform Kotlin development more reliable than ever.
With LitmusKt now part of Kotlin’s CI pipeline, every new compiler version benefits from systematic concurrency testing – ensuring that subtle memory model violations are caught before they reach developers.
We didn’t just build a tool; we established a new way to think about concurrency testing for multiplatform languages.
In short, LitmusKt:
- Brings automated, multiplatform litmus testing to Kotlin for the first time.
- Uncovered and helped fix multiple concurrency bugs in Kotlin/Native.
- Opened new possibilities for hybrid testing approaches that combine compiler fuzzing with concurrency analysis.
LitmusKt is open-source and ready to help you explore, understand, and test the complex behaviors of concurrent programs across Kotlin’s many platforms.
Further reading
Curious to explore the research or try out litmus testing on your own code? Check out these resources!
- Our paper on LitmusKt by Denis Lochmelis, Evgenii Moiseenko, Yaroslav Golubev, and Anton Podkopaev in the 33rd ACM International Conference on the Foundations of Software Engineering proceedings
- Talks by Aleksey Shipilëv on concurrency in the Java Memory Model
- Our paper (PDF), A Survey of Programming Language Memory Models by Evgenii Moiseenko, Anton Podkopaev, and Dmitrii Koznov in Programming and Computer Software
- A video by Anton Podkopaev, one of our LitmusKt researchers, on problems, solutions, and directions for programming language memory models.
- Weak memory consistency course by Ori Lahav and Viktor Vafeiadis
- Chapter on Java Memory Model specification
- LLVM Atomic Instructions and Concurrency Guide






