
JetBrains Research
Research is crucial for progress and innovation, which is why at JetBrains we are passionate about both scientific and market research
Cutting Through the Noise: Smarter Context Management for LLM-Powered Agents


Imagine you’re working on a project and jotting down every single idea, experiment, and failure. After a while, your notes pile up so high that finding what’s useful takes more time and energy than the work itself. A similar problem faces users of software engineering (SE) agents: the agents “take notes” on every generated output, iteratively adding the information to their context; this creates massive – and expensive – memory logs.
Huge contexts can be a problem for a couple of reasons. For one, AI models are priced per word (token), and as the context increases, the number of tokens spent drastically increases. Allowing the context to grow without intervention leads to the risk that the context window of modern LLMs is quickly exceeded. In addition, an agent’s effective context size is, in reality, quite small (see this paper and this paper).
This means that agent-generated context actually quickly turns into noise instead of being useful information. Another way to look at it: agent contexts grow so rapidly that they become very expensive, yet do not deliver significantly better downstream task performance. Currently, we are wasting resources for a suboptimal return on investment.
If growing contexts are problematic, what measures are being taken to manage them? Surprisingly little, considering the consequences. So far, the focus has been on enhancing the agent’s planning capabilities through strategies such as scaling training data and environments (e.g. papers 1 and 2), as well as enhanced planning and search-efficient strategies (e.g. papers 1 and 2).
However, there is still a significant gap in the research on efficiency-based context management. Our researchers have addressed this gap with an empirical study of the major approaches in efficiency-based context management, plus a novel hybrid approach that achieves significant cost reduction. This research is part of Tobias Lindenbauer’s Master’s thesis at TUM’s Software Engineering and AI Lab. We will present our insights at the Deep Learning 4 Code workshop, part of the NeurIPS 2025 Conference in San Diego on December 6th, 2025.
In this post, we will describe:
- The two main approaches to context management: observation masking and LLM summarization.
- Our experiment and its results comparing these two approaches against a baseline.
- Our hybrid solution and the broader application of our study.
Сontext management approaches
When AI agents work on complex coding tasks, they need to remember what they’ve done before, like which files they’ve read, what code they’ve tested, and how they’ve reasoned about errors. This “memory” is also known as context, and it helps the agents reason more effectively. However, managing that memory efficiently is a balancing act between giving the AI enough to think clearly and not overwhelming it with unnecessary clutter.
Recently, several studies have taken a closer look at how the size of an AI’s context window affects its performance (e.g. this 2024 study and this 2025 one). These papers consistently show that as the context grows, language models often struggle to make good use of all the information they’re given. Even though context management plays a huge role in both how well agents perform and how costly they are to run, most research still treats it as more of an engineering detail than a core research problem.
In the current state of the art, there are the following two main approaches for handling the context management challenge. Note that the first approach is both the more recent and the more sophisticated one; OpenHands initially presented it and is currently used in Cursor and Warp‘s (proprietary) SE agent solutions. The second approach is a bit older and is the simpler of the two.
- LLM summarization: another AI model generates short summaries
- Observation masking: older, less important bits of information are hidden
Both approaches preserve important context, which is why they fundamentally both work. The key difference is in how they do this. The following image depicts the difference, and then the text goes into further detail.
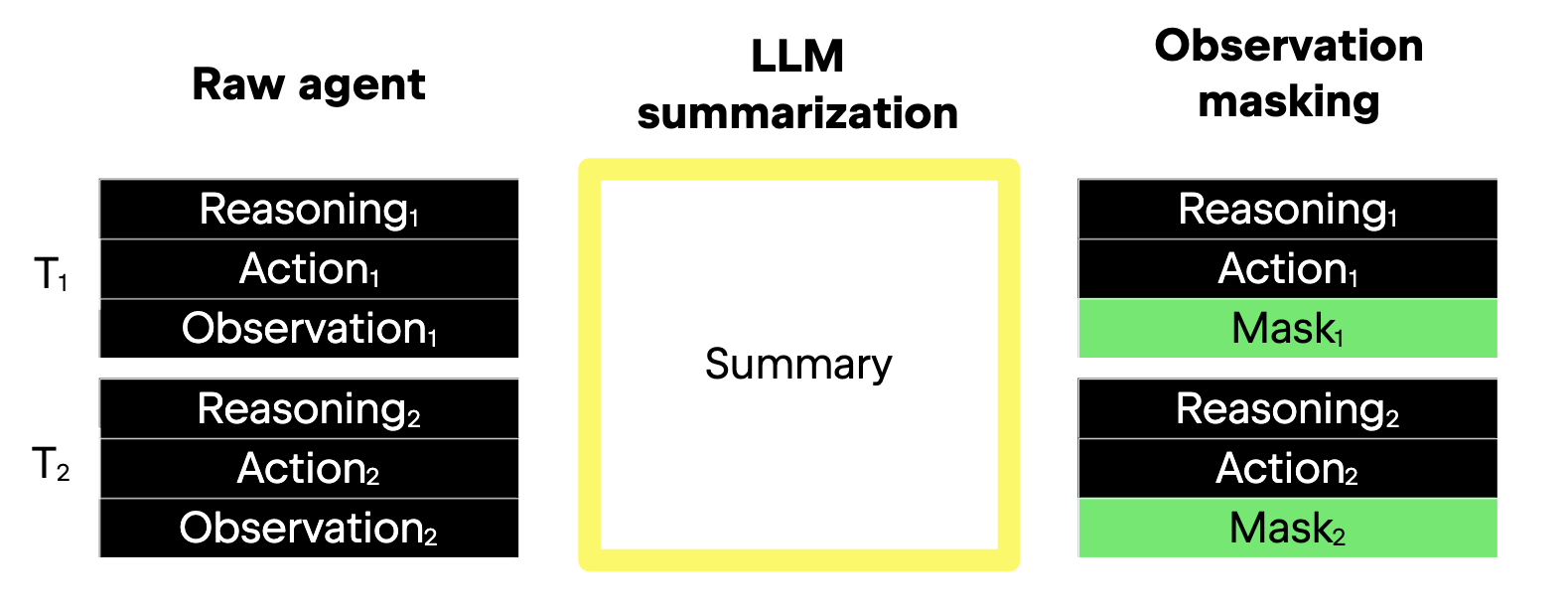
Figure based on Lindenbauer et al (2025): 4.
On the lefthand side of the image, we can see the default process, raw agent, omitting prompts for simplicity. Each turn, represented by T1 and T2 in the left margin, comprises three parts: reasoning, action, and observation.
Depicted in the middle of the above image is LLM summarization. It reduces the resolution of all three parts of the involved turns by essentially compressing the long history that is generated (in other words, the trajectory) into a compact form. The yellow-framed square represents the summary of the first two turns, T1 and T2.
On the right-hand side of the image, we can see how observation masking targets the environment observation only, while preserving the action and reasoning history in full. Only the third turn part is hidden by a mask, here in green. Considering that a typical SE agent’s turn heavily skews towards observation, it makes sense for this approach to only reduce the resolution of this specific turn element. And, the agent still has access to its past reasoning and decisions, but no longer reprocesses huge chunks of verbose text from earlier turns, such as test logs or full file reads.
An additional difference between the two approaches concerns infinite contexts. Namely,LLM summarization theoretically allows infinite scaling of turns without an infinitely scaling context, due to the repeated summarization and its consequence that a large enough context window would not be exceeded. On the other hand, observation masking significantly lowers the scope at which the context grows, but the context can grow to infinity if the number of turns is also allowed to grow infinitely.
The following table presents the advantages and disadvantages of each approach.

Recently, a few other researchers have developed context management tools and analysed their performance with respect to efficiency. Recent studies in this domain include the following:
- MEM1, which explored dynamic state management for tasks like multi-hop question answering and web navigation. Still, that work didn’t compare against simpler omission-based methods like observation masking, and the benchmarks they used were relatively short and lightweight (just a few hundred tokens), unlike the far longer trajectories seen in SE agents. Note that this approach involves training the model.
- A variant of the LLM summarization approach to help SE agents manage their context more efficiently. However, they didn’t include a comparison with the simpler observation masking method. Their closest alternative, called the Delete baseline, drops entire dialogue turns instead of summarizing them. That might sound efficient, but since these agents mostly interact with their environments, deleting whole turns can interrupt their reasoning, as well as hurt performance.
- An approach using observation masking worked remarkably well for reinforcement learning and inference in both deep research and computer-use agents. Note that this approach involves training the model.
Note: While the first approach preceded our study, the other two were published after it was completed.
While the above studies deliver interesting results on efficient context management, there’s still a lot to learn about the optimal strategies of managing context efficiently for agents. In our study, we questioned whether complex summarization strategies are really necessary to keep things efficient. To explore this, we ran experiments using SWE-agent and OpenHands to see how simpler techniques stack up, which we will discuss in the next section.
Our empirical look at current context management approaches
The experiments put three memory strategies to the test. The strategies are the following, where the first is a baseline and the second two are the main objects of investigation.
- Letting memory grow unchecked – raw agent
- Trimming old observations with placeholders – observation masking
- Using a separate AI to summarize past steps – LLM summarization
As a baseline for the experiment, we looked at raw agent scaffolds using either ReAct or CodeAct. In these frameworks, the agent’s trajectory is a sequence of interactions with an environment, and the context is unbounded.
For the two main objects of our investigation, we analyzed popular approaches to these through the following representative open-source implementations:
- Environment observation masking through a rolling window (SWE-agent), which:
- Keeps the agent’s reasoning and actions intact.
- Replaces older observations with placeholders once they fall outside a fixed window, essentially telling the model, “some details omitted for brevity.”
- Prompt-based LLM summarization (OpenHands), which:
- Uses a separate summarizer language model to compress older interactions (i.e. observations, actions, and reasoning) into summaries.
- Does not alter the most recent turns.
Based on preliminary experiments, we learned that to fairly compare the bounded property of LLM summarization to the slowed but unbounded growth of observation masking, we need to work with long-horizon task trajectories (described in our paper’s appendix). For the experiments reported here, we let our agents run for up to 250 turns. When it came to observation masking, we found that keeping a window of the latest 10 turns gave us the best balance between performance and efficiency. For LLM summarization, we summarized 21 turns at a time, always retaining the most recent 10 turns in full.
Furthermore, we used state-of-the-art models, both open-weight (Qwen3) and proprietary (Gemini 2.5 Flash) models, ranging in size from 32B to 480B; we also covered both thinking and non-thinking regimes. All experiments were run on SWE-bench Verified, with 500 instances each. For more details on the configuration, see Section 3 of the paper.
Observation masking is simple but effective
As described in the previous section, our experiments investigated three memory strategies: the first is a baseline, and the second two are the main objects of investigation. The main result of our experiments is that observation masking outperforms LLM summarization in terms of overall efficiency and reliability.
- Letting memory grow unchecked – raw agent
- Trimming old observations with placeholders – observation masking
- Using a separate AI to summarize past steps – LLM summarization
Both approaches (2) and (3) consistently cut costs by over 50% compared to (1), which leaves the agent’s memory unmanaged. These efficiency-first context management approaches drastically reduce context growth, all without hurting the agents’ ability to solve problems.
Surprisingly, the simple approach of observation masking wasn’t just cheaper; it often matched or even slightly beat LLM summarization in solving benchmark tasks. In four out of five test settings, agents using observation masking paid less per problem and often performed better.
For instance, with the powerful Qwen3-Coder 480B model, observation masking boosted solve rates by 2.6% compared to leaving the context unmanaged, while being 52% cheaper on average. In other situations, LLM summarization matched these results but rarely surpassed them. Even a slight difference – say, three cents per problem – can add up for large-scale AI deployments.
Agent-specific differences in performance
We also wanted to know whether the insights from the above experiments can be generalized to a different agent, using the same parameters but with a smaller subset. To investigate, we ran extra tests using the OpenHands agent in both context management approaches on a slice of the SWE-bench Verified benchmark (i.e. 50 instances instead of 500). In addition, the agent was limited to Gemini 2.5 Flash in no thinking mode.
The extra tests involved implementing the optimal value of SWE-Agent with the OpenHands agent, observing that there are significant differences in performance, and then changing parameters, which brought the performance back up to standard. We found out that observation masking matched LLM summarization in both cost savings and problem-solving ability – but only after tuning the masking “window” hyperparameter for each agent scaffold.
What does it mean to tune the masking window hyperparameter? Every agent keeps its conversation history differently. For the tools in our study, SWE-agent (using observation masking) skips over failed retry turns, while OpenHands (using LLM summarization) includes them all.
Considering parameters, i.e. that the context window is limited to the last 10 turns, the differences in conversation history can be immense. In other words, if the agent were to fail for all 10 turns in a row, the observations for the OpenHands agent’s context window would only be erroneous ones. This can be quite problematic, potentially derailing the agent.
A larger window size is therefore necessary for agents like OpenHands, so that we do not negatively affect performance. By tuning the window size, it is possible to account for such agent-specific differences in hyperparameters and increase the window when necessary, like in the case with OpenHands.
LLM summarization and trajectory elongation
One thing we really wanted to know was why LLM summarization, despite being the more sophisticated approach, was often less cost-effective than plain old observation masking. Turns out, there’s an interesting twist: when agents use the summary approach, they tend to run for more steps, which means bigger bills and less efficiency in the end.
When we dug into the data, we found that for models like Gemini 2.5 Flash, using LLM summarization led to agents running for an average of 52 turns, a whopping 15% longer than with observation masking. The same thing happened with Qwen3-Coder 480B: summaries stretched out the process by about 15% compared to letting the agent just handle its raw history, and 13% longer compared to masking.
Why? It seems like LLM-generated summaries may actually smooth over, or hide, signs indicating that the agent should already stop trying to solve the problem. This means it often keeps going past the point where it would normally stop – and where it would make sense to stop (see this paper on solve-rate plateaus).
So, even though summaries are designed to make things neater, they can backfire by encouraging the agent to keep chugging along, using more resources without solving problems any better. It’s a good reminder that sometimes, keeping things simple not only works, but works more efficiently.
What is more, every time the agent asks an LLM for a summary, it fires off a costly API call to process a long chunk of the trajectory, racking up additional charges. These summary-generation calls aren’t cheap, sometimes making up more than 7% of the total cost per instance, especially for the largest models. Because each LLM summarization API call has to work through a unique slice of the agent’s history, there’s very little cache reuse. When these summary costs are subtracted out, the gap in efficiency between LLM summarization and observation masking shrinks dramatically in most cases.
Both smart and simple strategies halved costs versus doing nothing, but simplicity often takes the prize for total efficiency and reliability. So, even though summarization sounds smart, in practice, it’s extra costly and doesn’t reliably outperform the simpler masking approach. This suggests that many current AI agents could reduce costs if they dialed down their reliance on summary calls or developed creative hybrid strategies that effectively combine both methods.
Our hybrid solution for even more efficiency
After seeing how both observation masking and LLM summarization held their own, with masking often as good as (or better than) summarizing, we wanted to see if combining the best parts of both would lead to even more savings. The approaches having complementary strengths, as shown in the table above, is one further argument for merging their strengths.
Our hybrid approach works by relying on observation masking as the agent’s first line of defense against context bloat. We designed it this way because observation masking is fast and inexpensive: it hides old, noisy tool outputs with placeholders, keeping only the most relevant part of the agent’s work as it moves forward.
But, instead of ignoring summaries altogether, the hybrid system occasionally uses LLM summarization as a last resort to create a short, AI-generated recap of the full story when the context starts getting truly unwieldy. In our setup, the agent let masking handle most steps, but would only trigger LLM summarization after collecting a big batch of turns. In those cases, the summaries are triggered by a tuned hyperparameter.
Advantages of our novel hybrid approach include:
- It lets the agent rack up quick savings from observation masking, especially right at the beginning when new problems are still short, and context isn’t a problem.
- It ensures that even for super-long or complex jobs, the occasional LLM summarization step prevents memory from spiraling out of control, without spending extra on summary generation during simple tasks.
- Because our approach does not involve training a model (i.e. changing weights), we can retrofit any existing model, including GPT-5 and Claude, with this approach. This equals immediate savings, even on models where it is not possible to train them. To the best of our knowledge, concurrent approaches lack this application.
As we know from above, hyperparameter tuning is important, and this is relevant for our hybrid approach as well. Specifically, we tuned the window for masking and the number of turns before summarizing, adjusting both for each specific type of agent or job. When we reused settings that worked for one agent in another setup, we didn’t always get the best results.
Beyond tuning, we rigorously tested our approach, and the numbers support our claims. In tests with the demanding SWE-bench-Verified benchmark and the super-sized Qwen3-Coder 480B model, the hybrid technique reduced costs by 7% compared to pure observation masking and by 11% compared to using only LLM summarization. It also nudged the percentage of successful answers up by about 2.6, all while saving a meaningful chunk of money, up to USD 35 across the entire benchmark, which really adds up when agents are running at scale.
Efficient context management
This study took a deep dive into different ways AI agents handle their growing context, testing them across a wide range of models and agent frameworks. On top of that, we were able to consistently reproduce these findings, given that the trajectories are long enough and special attention is paid to parameter tuning.
The main takeaways from our study are:
- Ignoring efficiency-based context management means ignoring important cost-saving strategies.
- If you want AI agents that are both sharp and thrifty, don’t rely on just one context management strategy – our hybrid approach combines the strengths of both observation masking and LLM summarization.
In addition to the paper, we have made our code available online. Check it out and see the difference in context management:
Subscribe to JetBrains Research blog updates






