

Публикации и ответы на комментарии в блогах JetBrains не выходят на русском языке с 2022 года.
Приносим извинения за неудобства.
DataGrip 2021.3: Aggregate view в редакторе, табличное представление узлов дерева БД, новое окно сравнения БД

В этом посте мы расскажем, что нового в свежем релизе DataGrip 2021.3. Если вы работаете с базами данных в других IDE JetBrains, то этот пост и для вас тоже.

Редактор данных
Агрегаты
Как в Excel и Google таблицах: мы добавили возможность отображать панель с агрегированными данными для диапазона ячеек в редакторе данных. Это помогает работать с данными без необходимости писать дополнительные запросы.
Выберите диапазон ячеек, щелкните правой кнопкой мыши и выберите Show Aggregate View.
Вкратце:
- Aggregate и Value находятся на одной панели, для каждого отдельная вкладка. Панель можно переместить в нижнюю часть редактора данных.
- Вы можете убрать из представления ненужные агрегаты в меню под шестеренкой.
- Как и экстракторы, агрегаты это скрипты. Мы добавили девять готовых агрегатов, но вы можете создавать свои собственные и делиться ими с коллегами.
- Скрипты агрегатов и экстракторы взаимозаменяемы. Экстрактор, который вы использовали для получения одного значения, теперь можно скопировать в папку Aggregators и использовать для агрегатов. Папка находится в разделе Scratches and consoles / Extensions / Database Tools and SQL, рядом с папкой Extractors.
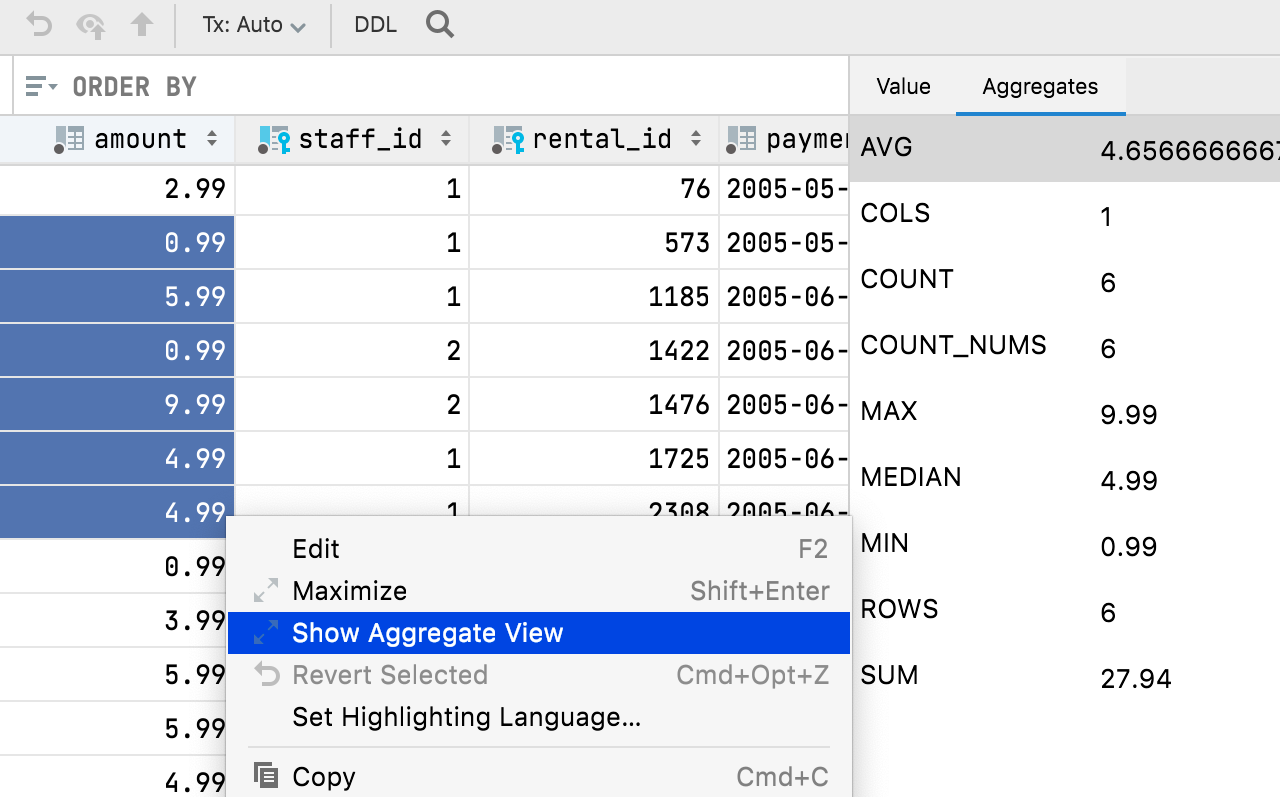 Агрегированное значение отображается в строке состояния — вы можете выбрать, какое именно вам нужно (сумма, минимальное/максимальное значение, среднее значение, медиана, и т. д.).
Агрегированное значение отображается в строке состояния — вы можете выбрать, какое именно вам нужно (сумма, минимальное/максимальное значение, среднее значение, медиана, и т. д.). 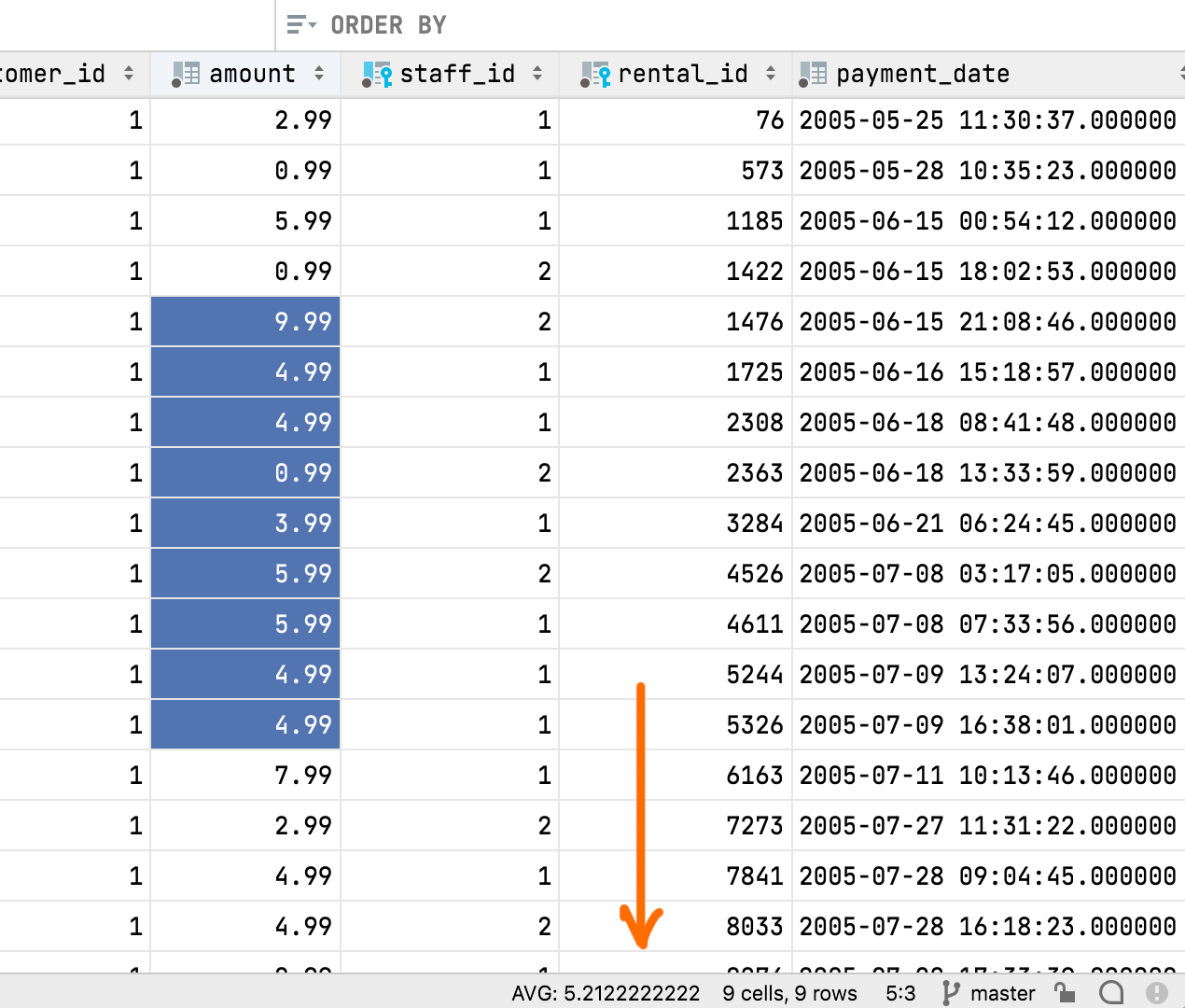
Табличное представление узлов дерева базы данных
Нажмите F4 на любом узле схемы, чтобы увидеть его содержимое в виде таблицы. Например, вы можете получить представление всех таблиц в схеме:

Или просмотреть столбцы в виде таблицы:

В табличном представлении можно скрывать/показывать столбцы, экспортировать данные в разных форматах и искать по текстовым вхождениям. Здесь также работают шорткаты:
- Ctrl / Cmd + B покажет DDL.
- F4 покажет данные.
- Alt / Opt + Shift + B подсветит объект в дереве базы данных.
Независимое разделение редактора данных
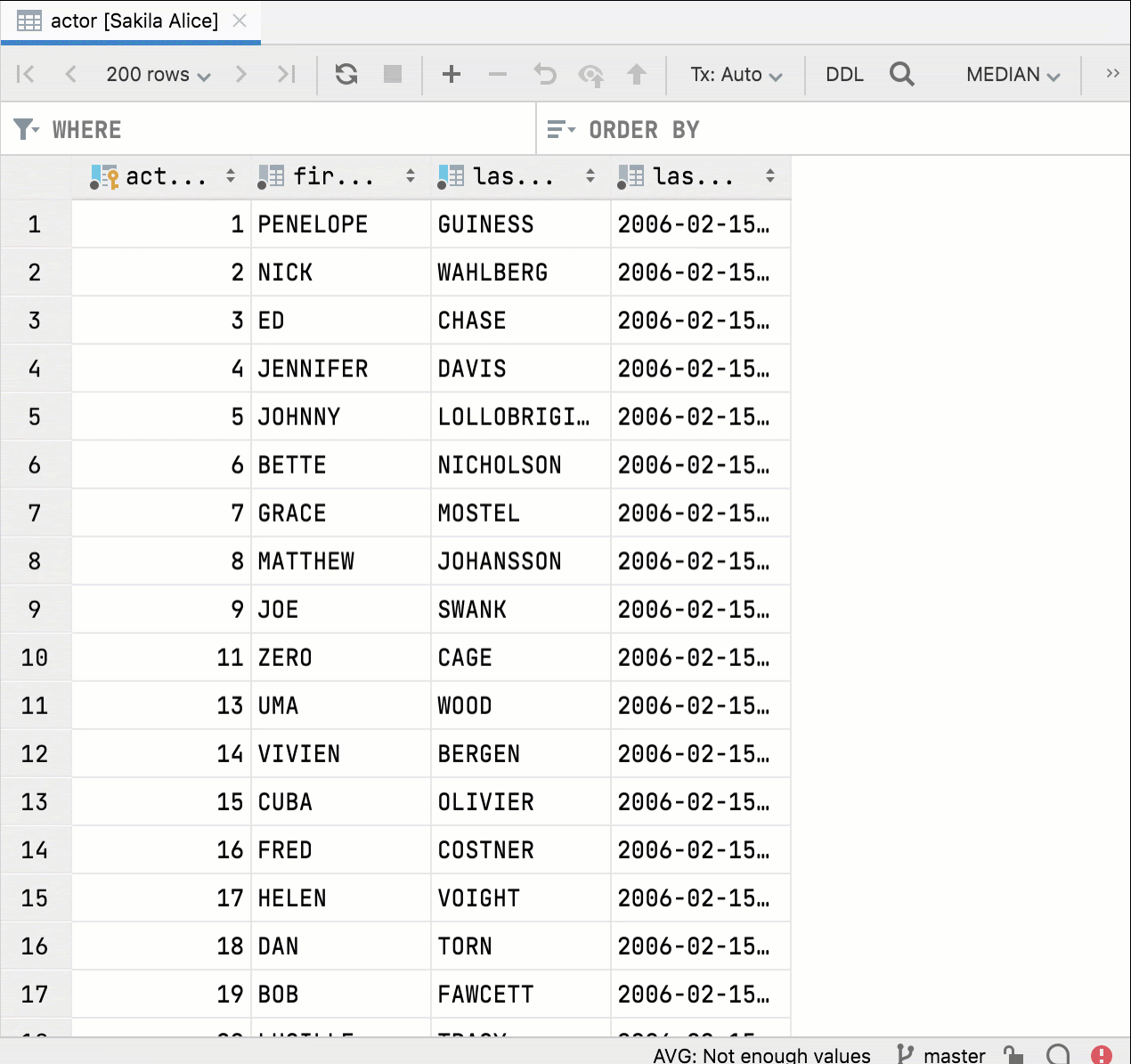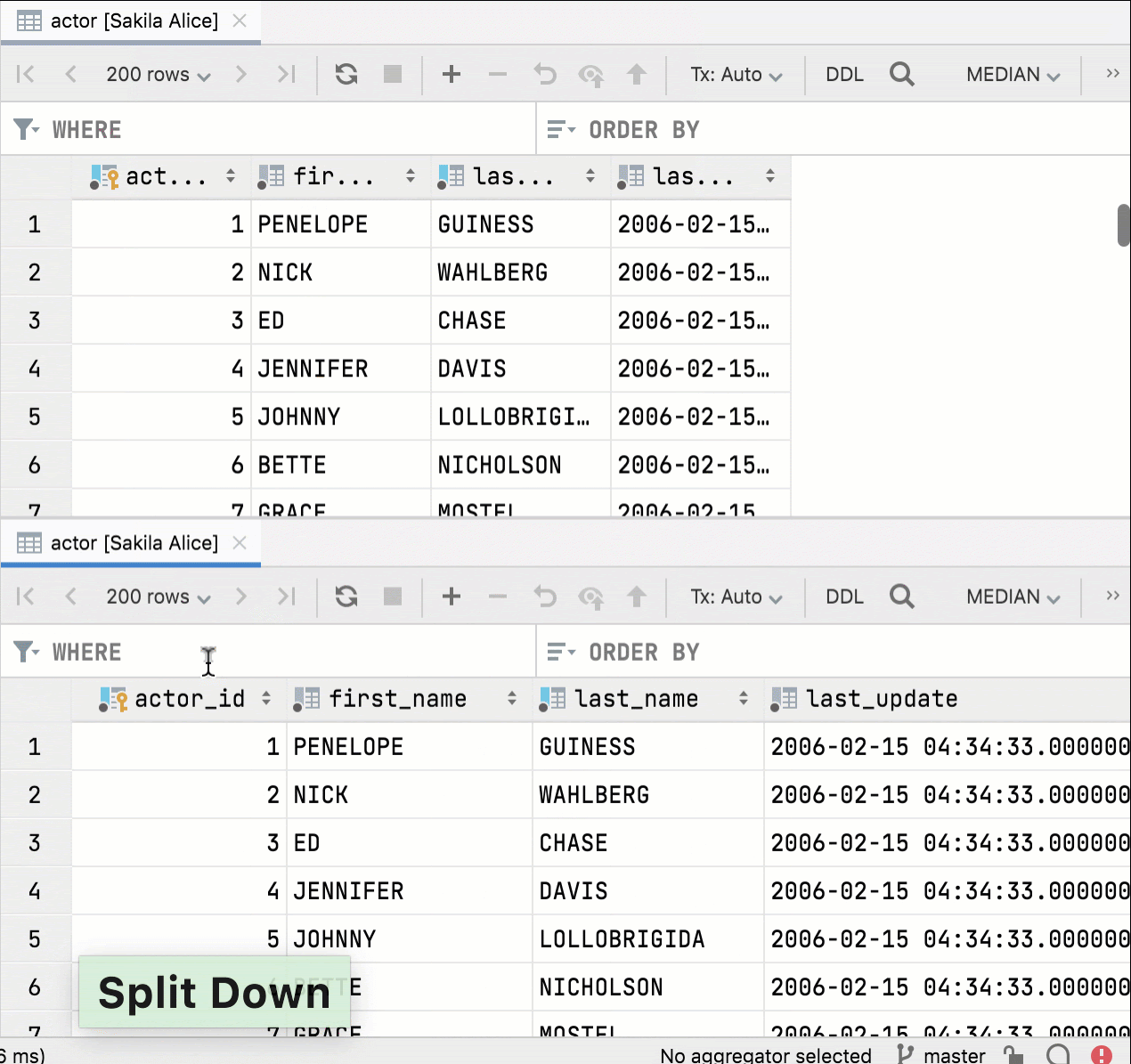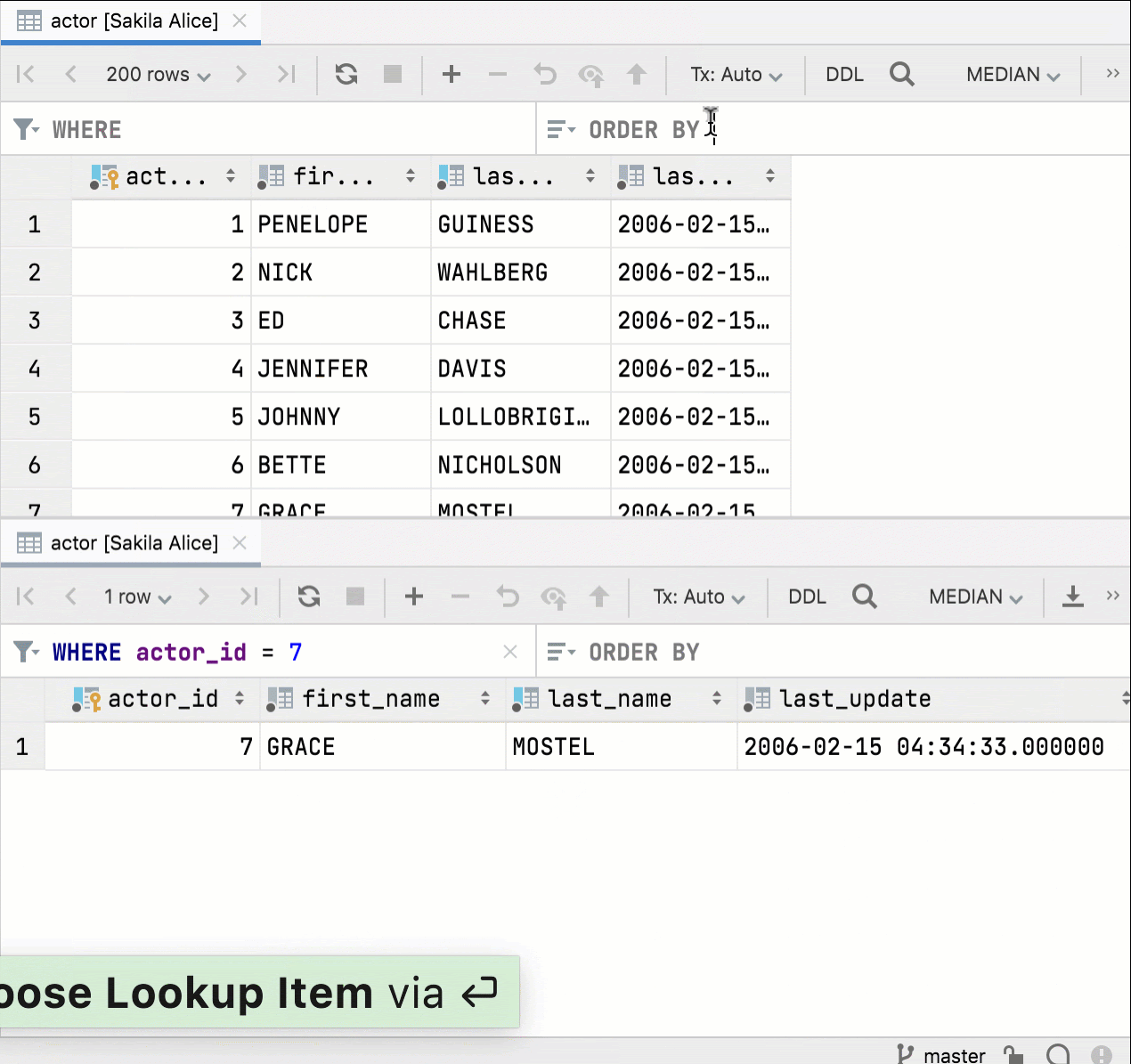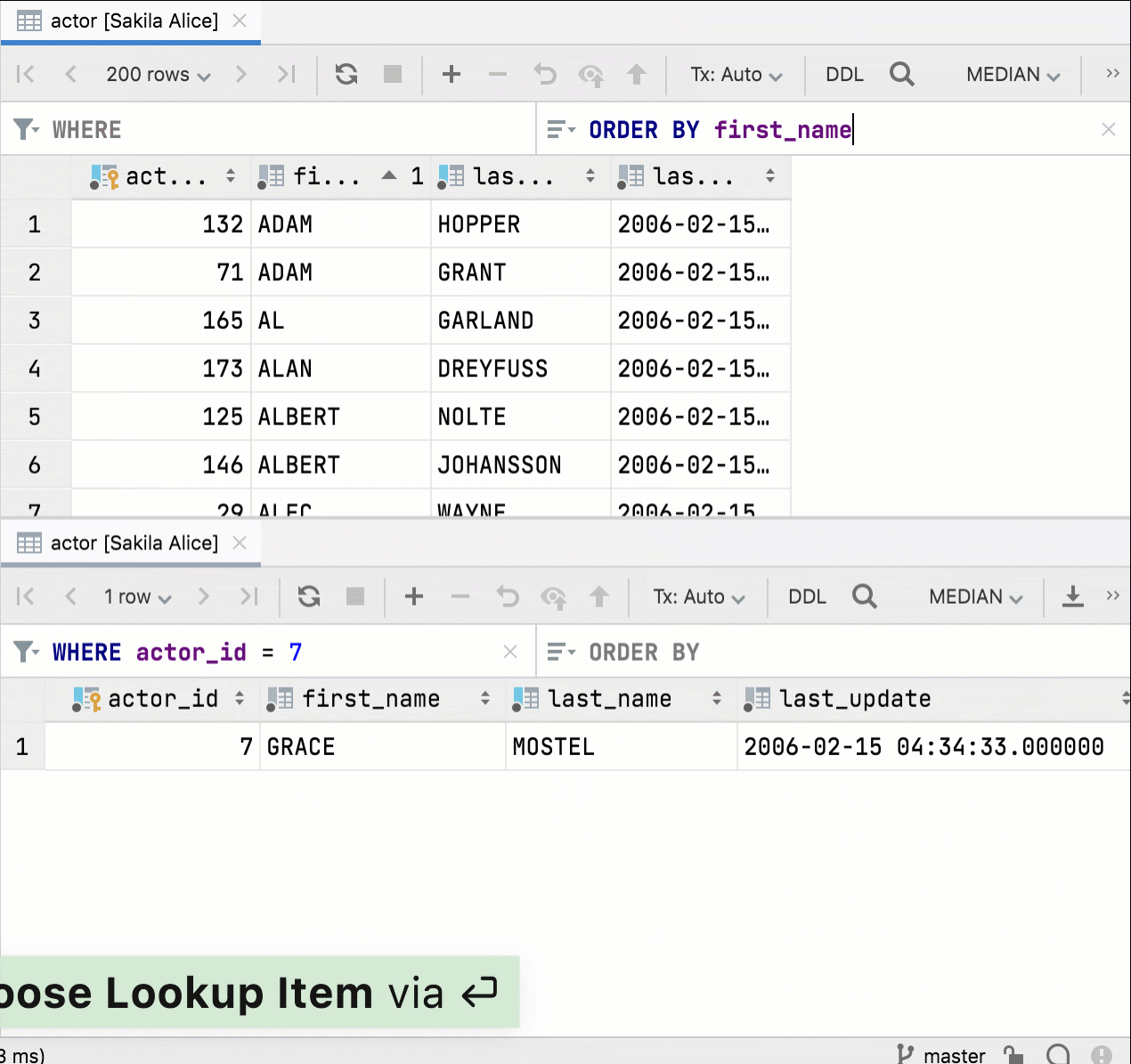
В DataGrip можно разделить редактор данных, но раньше фильтрация и сортировка были синхронизированы, а это неудобно.
Теперь, если вы разделите редактор и откроете одну и ту же таблицу, два окна редактора данных будут независимыми. Можно фильтровать и сортировать данные параллельно.
Пользовательские шрифты
Вы можете выбрать шрифт для отображения данных в разделе Database | Data views | Use custom font.

Навигация по внешним ключам на основе нескольких значений
Теперь в редакторе данных теперь можно выбрать сразу несколько значений и перейти к соответствующим данным по внешним ключам.
Настройка сортировки по умолчанию
Вы можете указать, какой метод будет использоваться по умолчанию для сортировки таблиц. При выборе сортировки на стороне клиента DataGrip не будет выполнять дополнительные запросы и отсортирует только текущую страницу. Чтобы выбрать сортировку на стороне сервера, перейдите в раздел Database | Data views | Sorting | Sort via ORDER BY.
Режим отображения бинарных данных
16-байтовые данные теперь по умолчанию отображаются как UUID. Вы можете настроить способ отображения бинарных данных в контекстном меню столбца.

[MongoDB] Автодополнение для filter {} and sort {}
При фильтрации данных в коллекциях MongoDB теперь работает автодополнение.
Хранение базы данных в VCS
Соотнесение источников данных на основе DDL с реальными
В прошлом релизе появилась возможность генерировать источник данных на основе DDL из реального источника данных. А теперь вы можете больше: соотносить источник данных DDL с реальным, сравнивать и синхронизировать их.
Напоминаем, что источник данных на основе DDL — это виртуальный источник данных, схема которого основана на SQL-скриптах. Сохраняя DDL- файлы в системе контроля версий, вы сохраняете в ней схему вашей базы данных.
В настройках конфигурации данных появилась новая вкладка DDL Mapping, где можно соотнести DDL-источники данных с реальными.
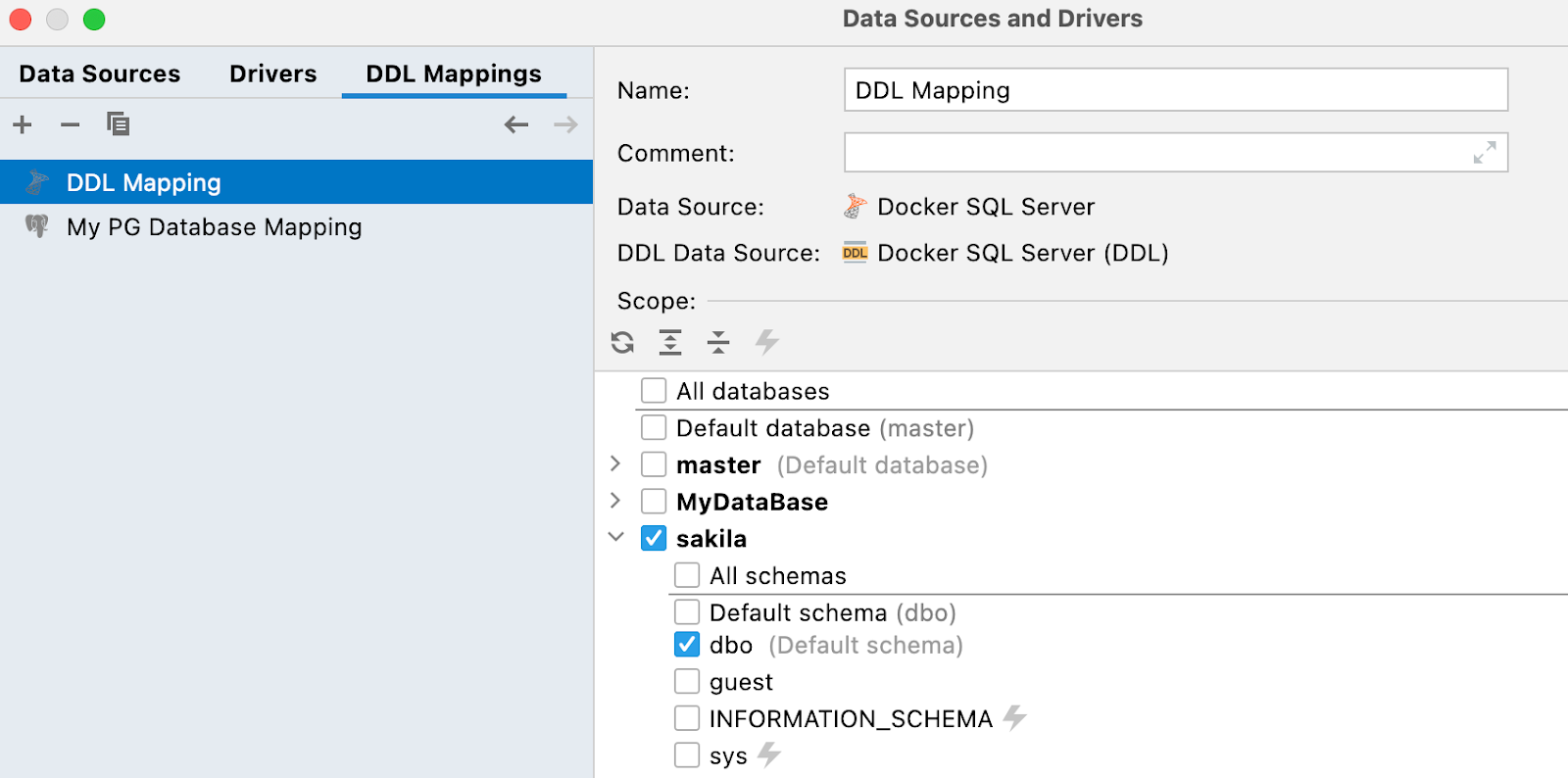
Новое окно сравнения баз данных
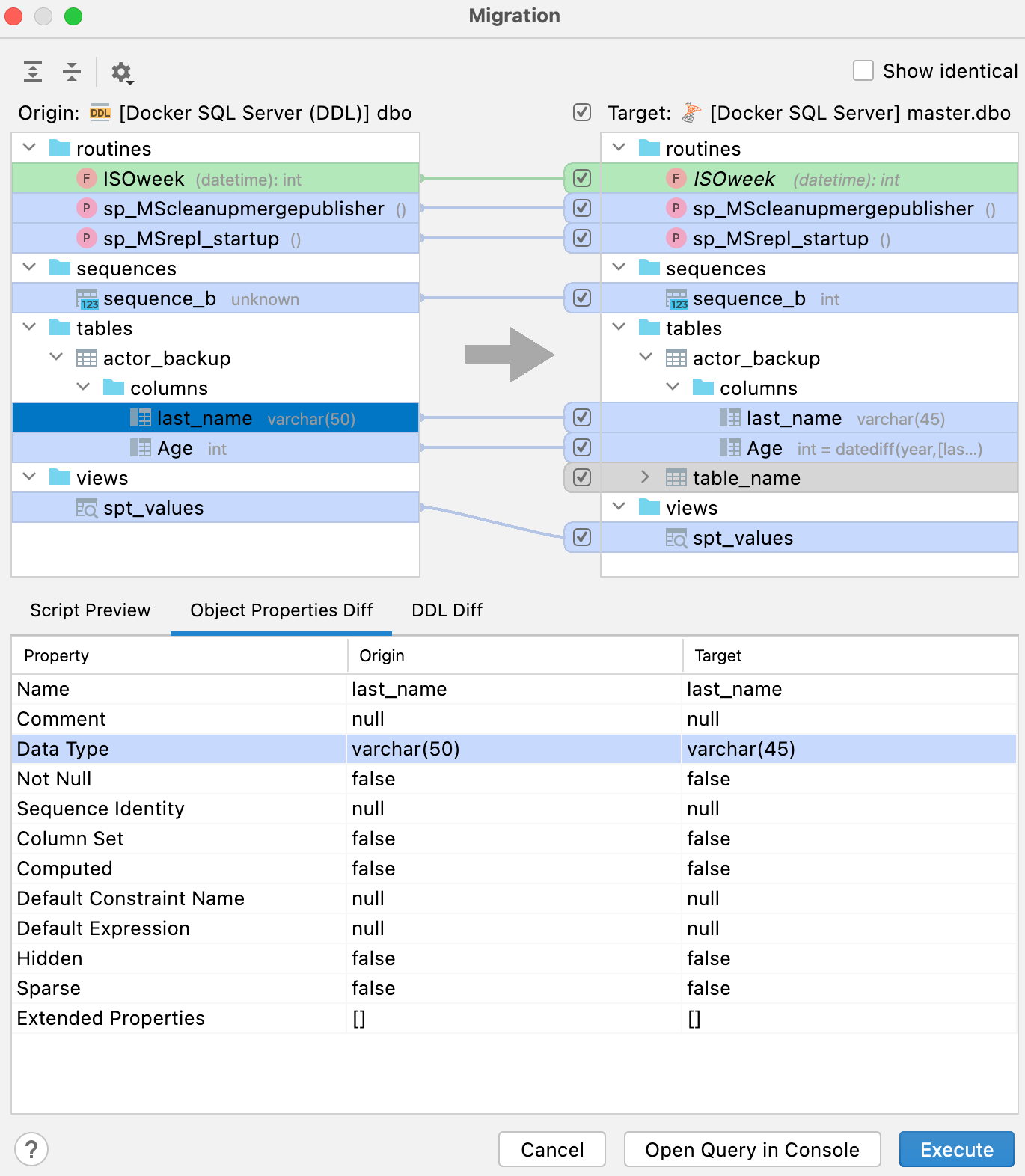
Чтобы сравнить и синхронизировать ваш источник данных на основе DDL с реальным, используйте контекстное меню и выберите Apply from… или Dump to… в подменю DDL Mapping.

Окно на правой панели показывает, какой результат вы получите после выполнения синхронизации.

Что означают цвета:
- Зеленый курсив: объект будет создан.
- Серый: объект будет удален.
- Синий: объект будет изменен.
На вкладке Script preview отображается скрипт миграции, который можно запустить из этого окна или открыть в новой консоли. Выполнив скрипт, вы преобразуете базу данных справа (целевую) в идентичную базе данных слева (исходной).
Кроме вкладки Script preview, на нижней панели есть еще две вкладки: Object Properties Diff и DDL Diff. Они показывают разницу между конкретными версиями объекта в исходной и целевой базах данных.
Напоминаем: если вы хотите просто сравнить две схемы или объекты, выберите их и нажмите Ctrl / Cmd + D.
Важно! Окно сравнения/миграции все еще находится в разработке. Каждая база данных имеет свои особенности, поэтому некоторые объекты могут отображаться как разные, хотя на самом деле они идентичны. Если вы столкнулись с такой ошибкой, создайте тикет в нашем трекере.
Файловые операции
Теперь любые файловые операции можно совершать с объектами в источниках данных на основе DDL. Например, из проводника базы данных вы можете удалять, копировать и коммитить файлы, связанные с объектами схемы.

Автосинхронизация
Раньше автосинхронизация была включена по умолчанию: источники данных на основе DDL автоматически обновлялись при изменениях соответствующих файлов. Теперь вы можете отключить эту опцию: изменения в исходных файлах не будут автоматически отражаться в DDL источниках данных. Тогда, чтобы применить их, нужно будет нажать Refresh.

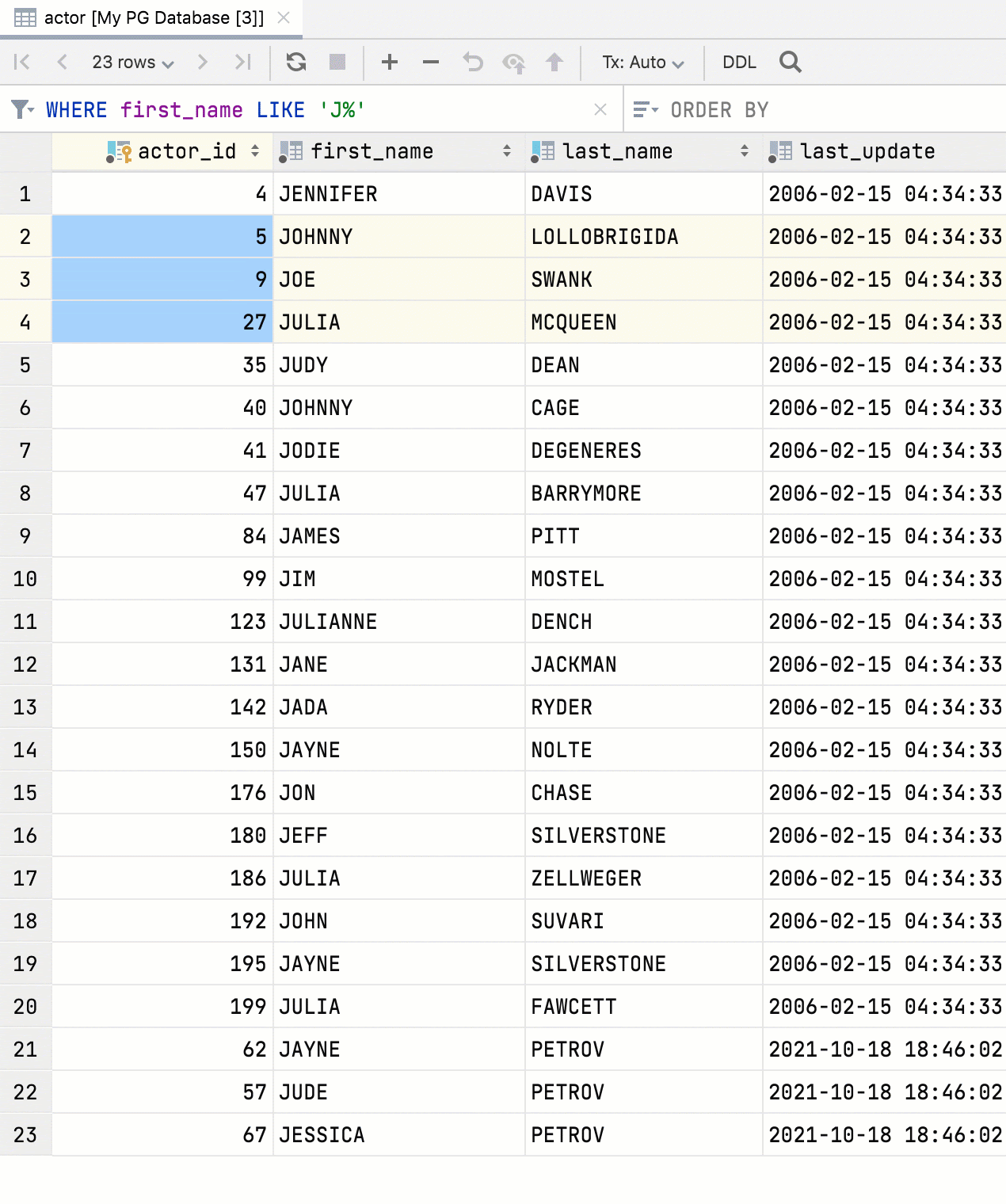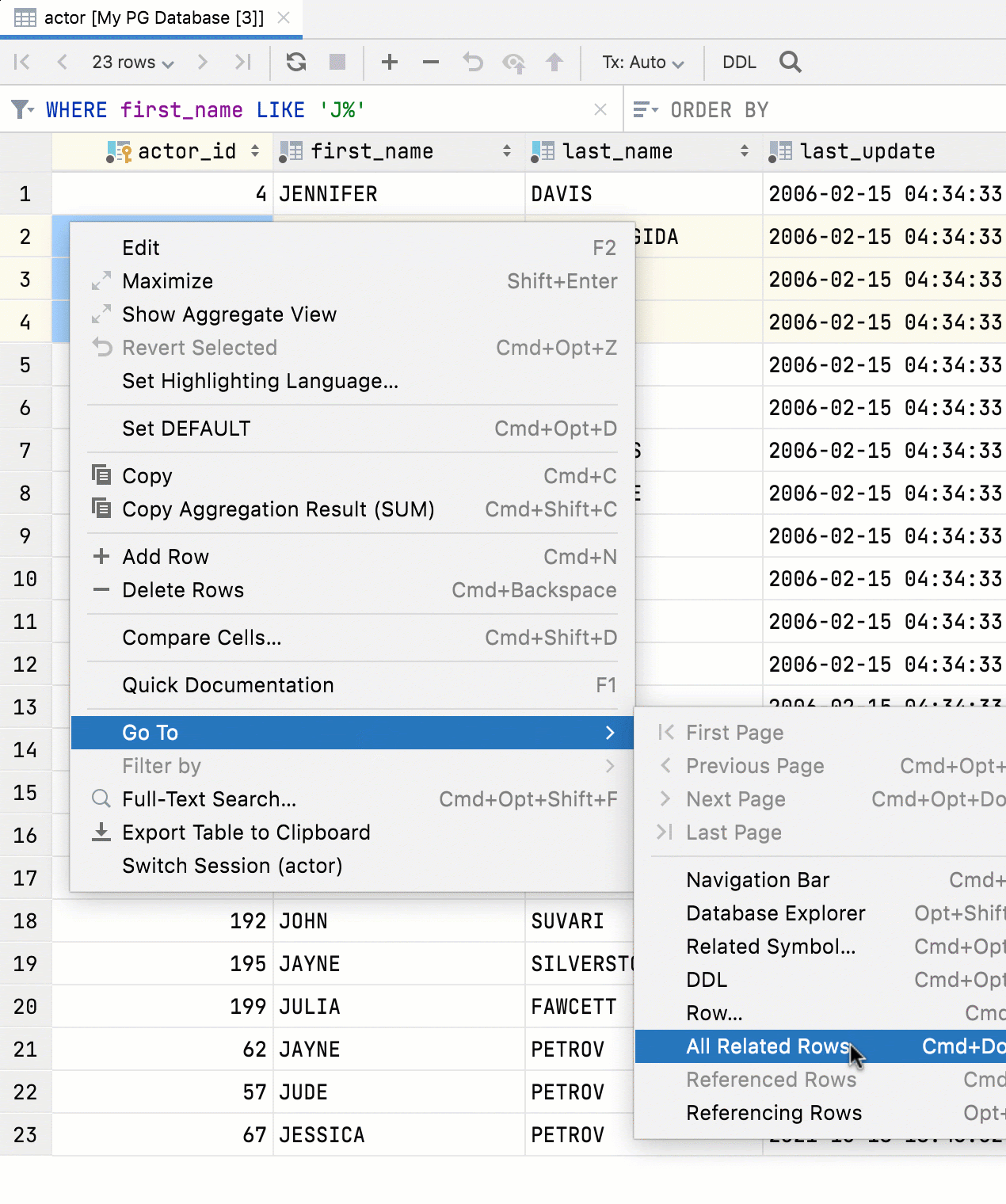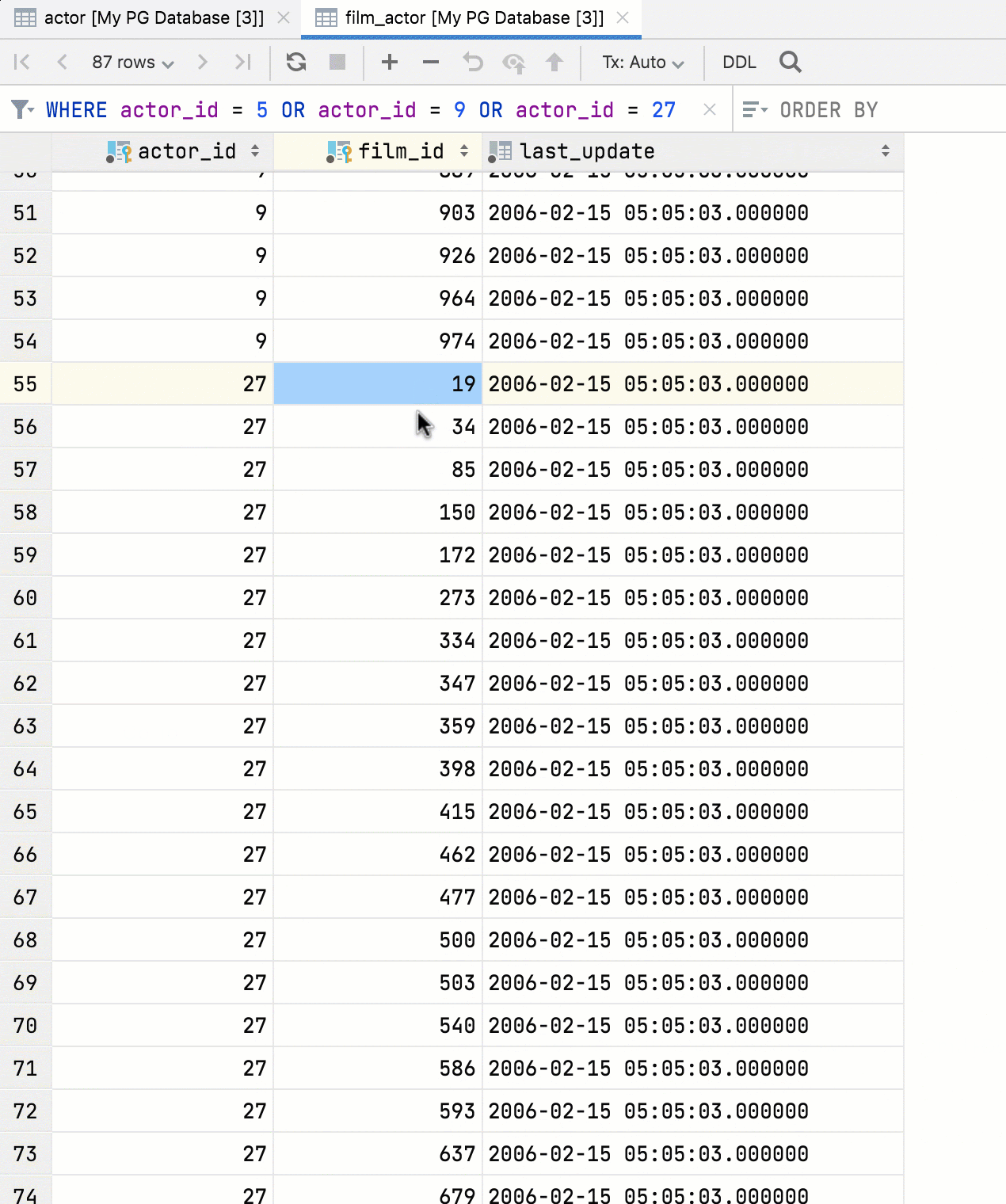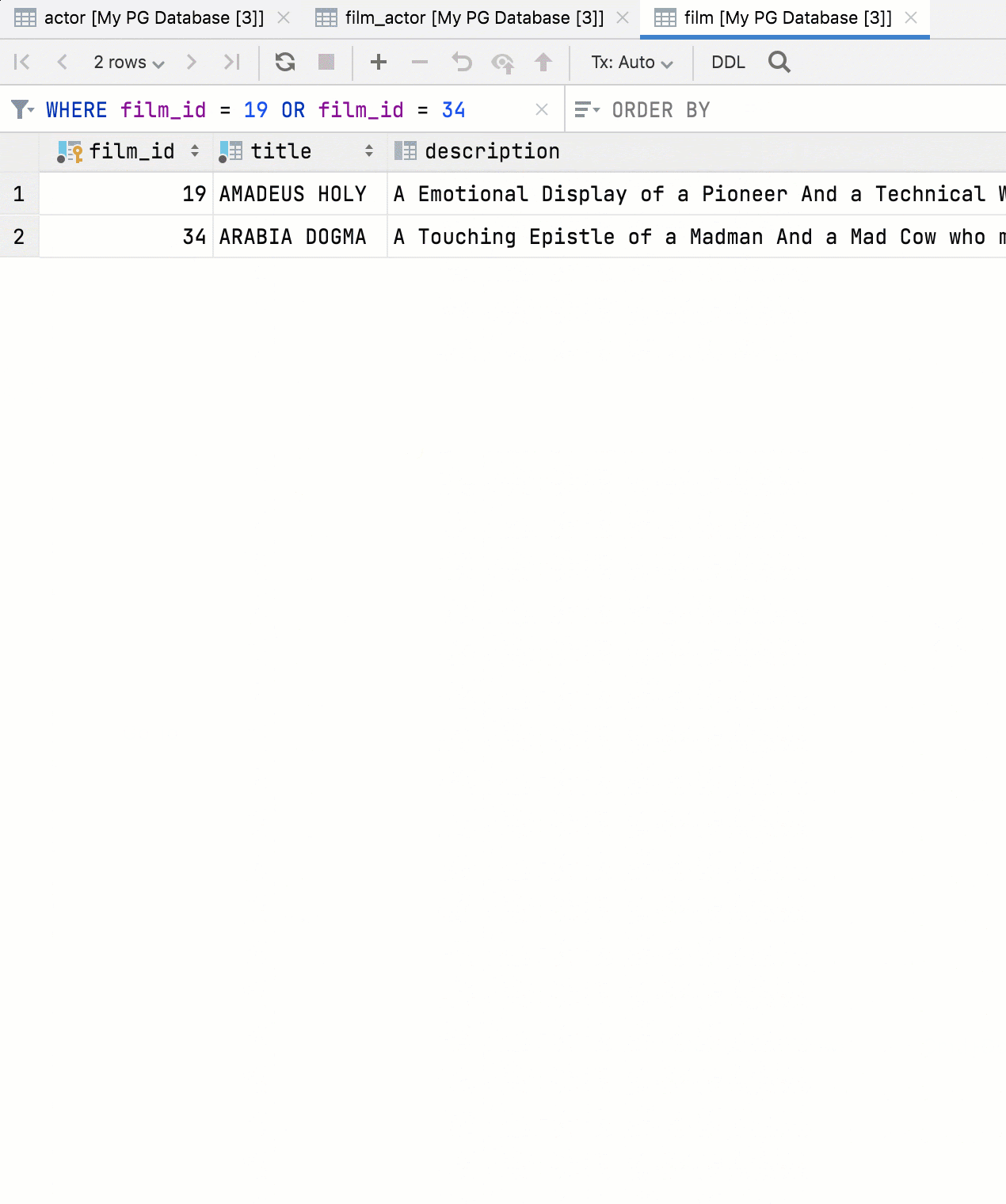
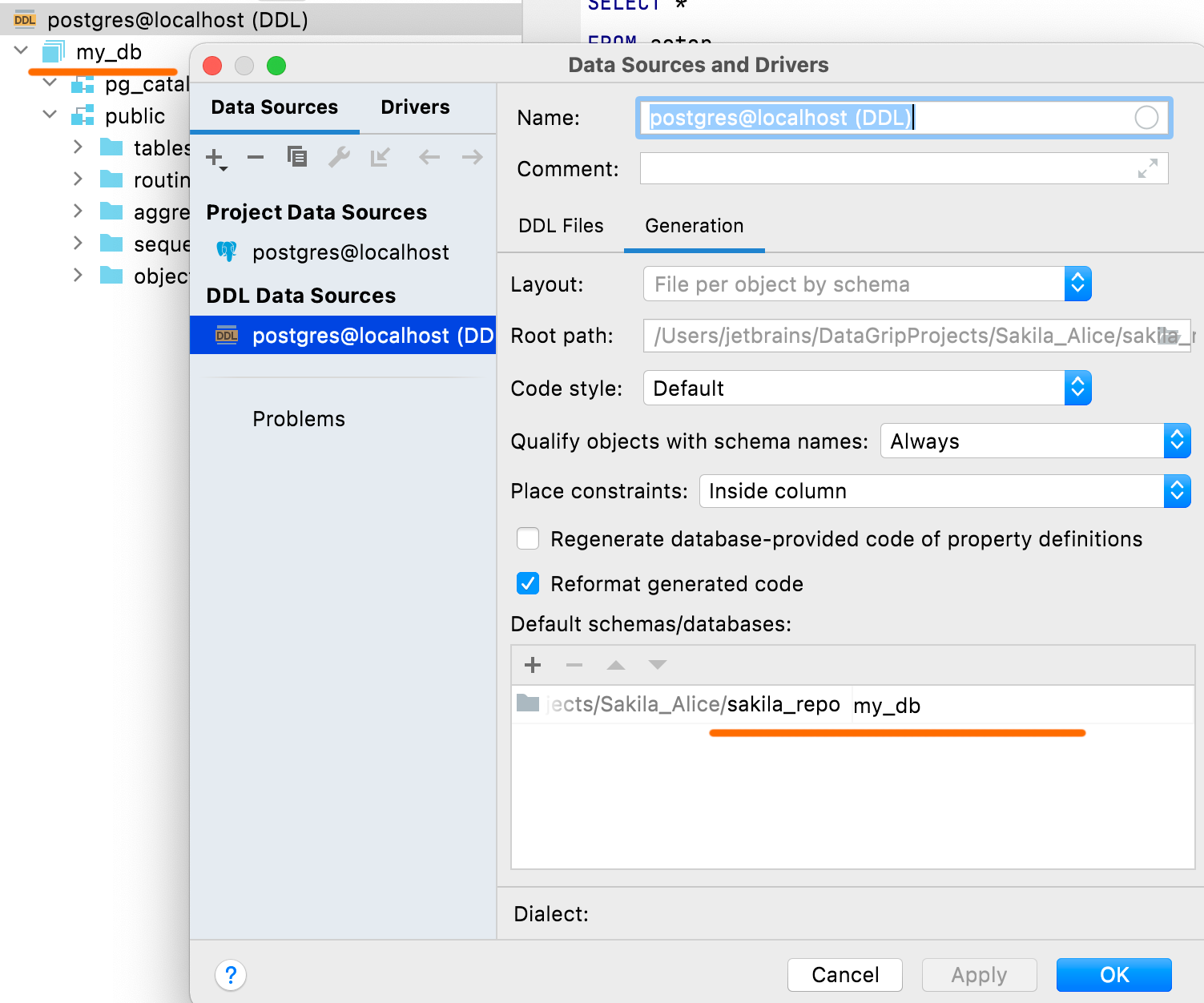
Схемы и базы данных по умолчанию
В панели Default schemas/databases можно указать имена баз данных и схем, которые будут отображаться для источника данных DDL. Скрипты DDL, как правило, не содержат имен, поэтому DataGrip автоматически создаст для баз данных и схем одноразовые названия, которые вы указали.
Соединение
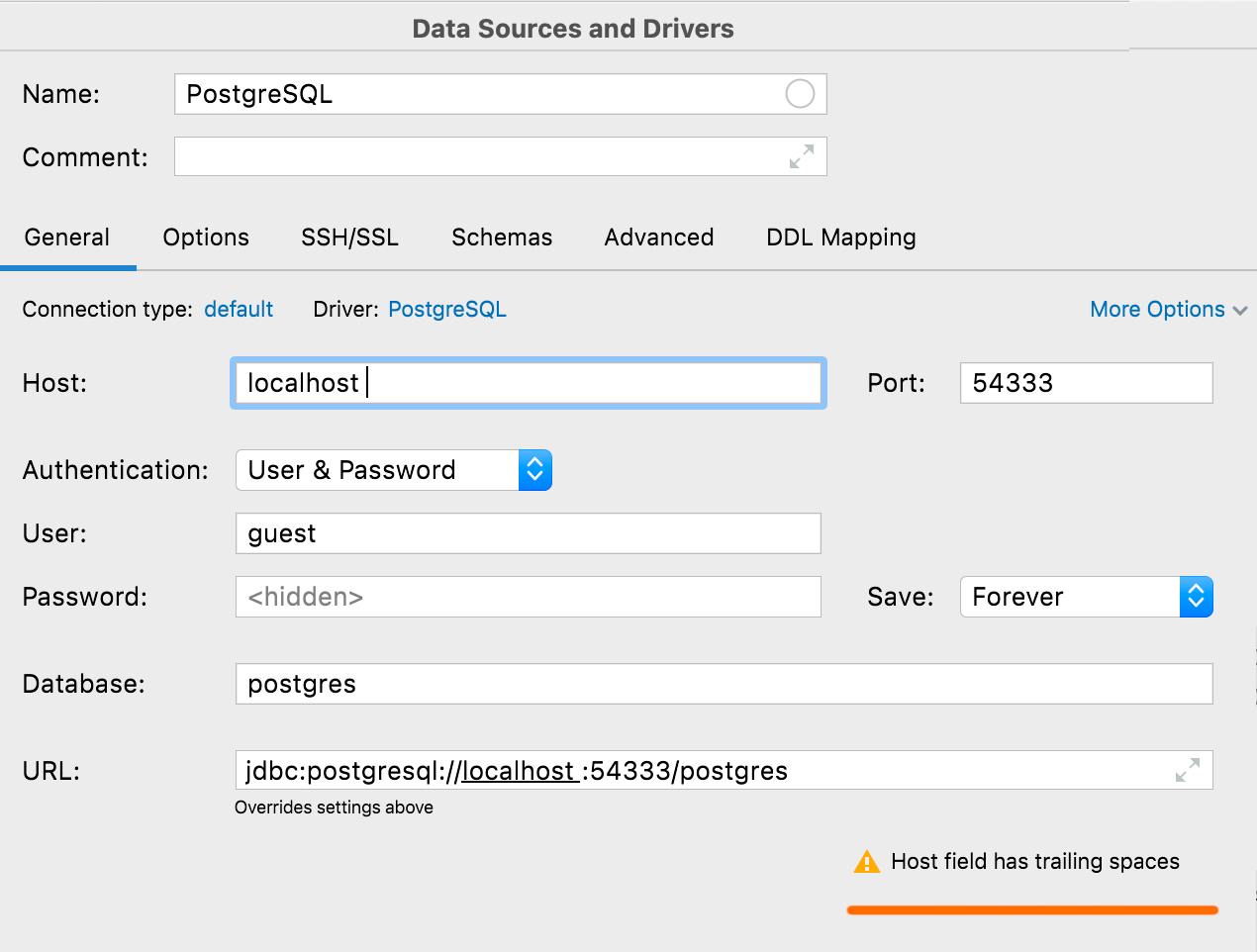
Предупреждение о лишних пробелах
Если при тестировании соединения в строках кроме User и Password обнаружатся лишние пробелы, DataGrip предупредит вас об этом.
[SQL Server] LocalDB как выделенный источник данных
Добавили в список драйверов выделенный драйвер SQL Server LocalDB.
- Подключение LocalDB проще найти.
- Достаточно один раз указать путь к исполняемому файлу в настройках драйвера, и он будет применен для всех источников данных.
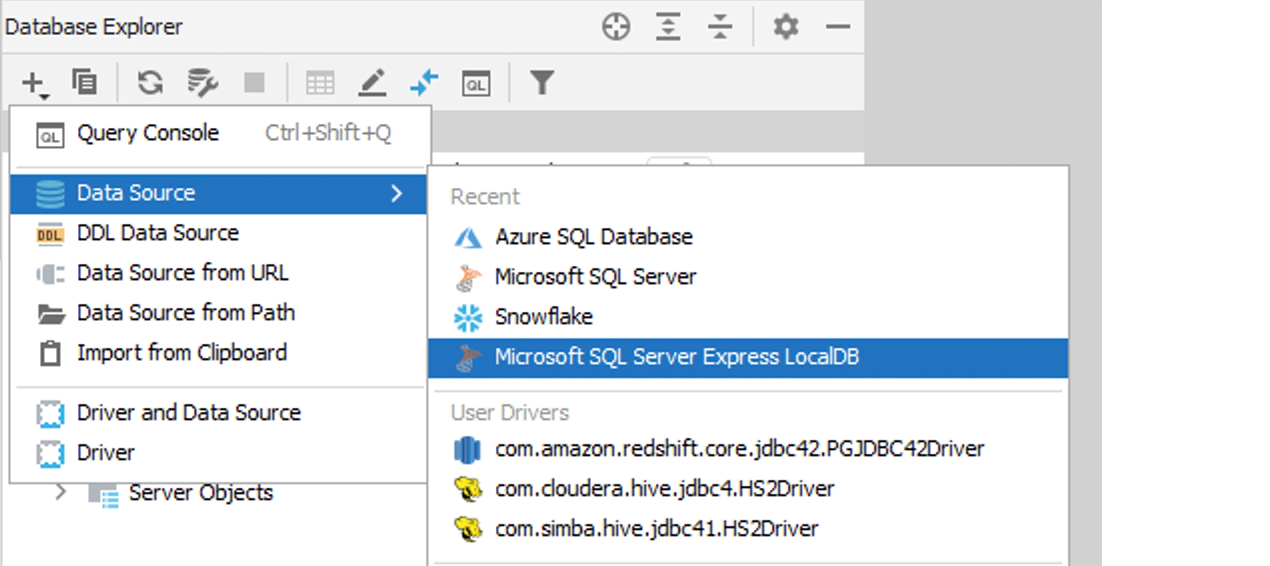
[Oracle, SQL Server] Аутентификация Kerberos
Для Oracle и SQL Server работает аутентификация Kerberos. Используйте команду kinit, чтобы получить исходный билет для принципала — DataGrip будет применять его при выборе опции Kerberos.

[Oracle, IBM Db2] Включение DBMS_OUTPUT
Теперь на вкладке Options можно по умолчанию включать DBMS_OUTPUT для новых сеансов.

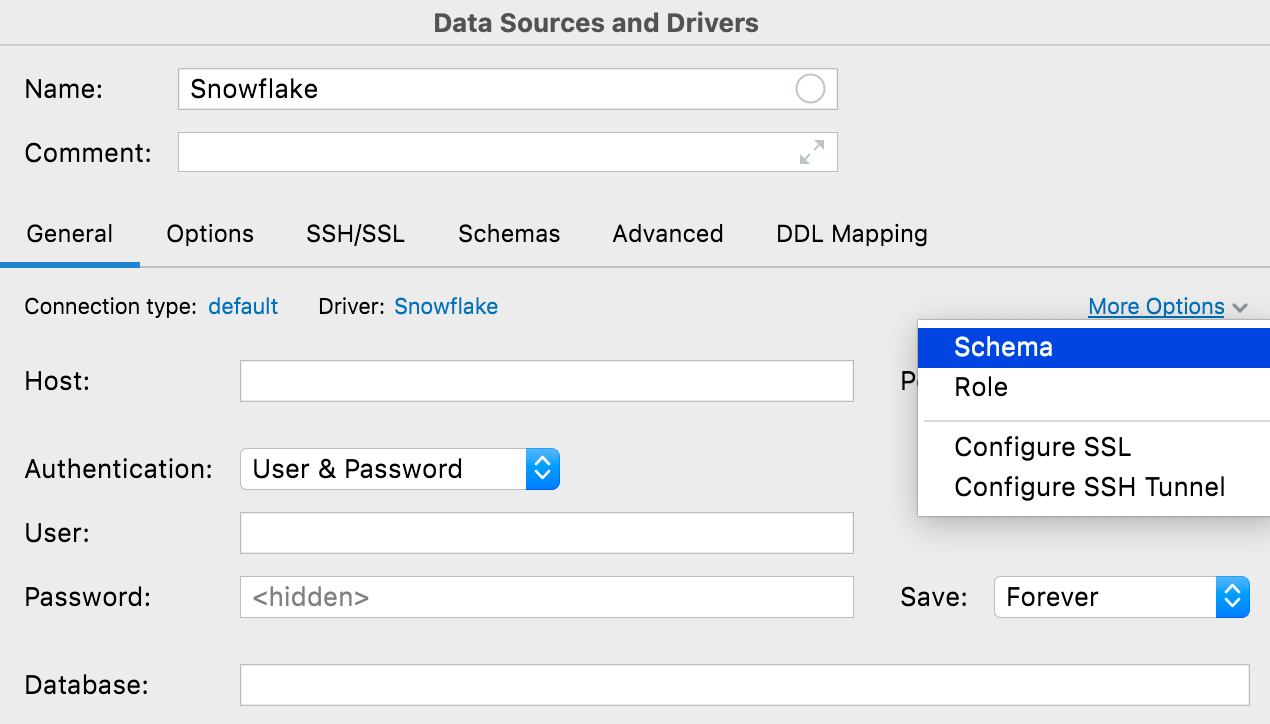
Кнопка More options
Если вам нужно особым образом настроить соединение, нажмите кнопку More Options. Вы сможете добавить поля Schema и Role для соединений Snowflake, а также настроить SSH и SSL.
Expert options
Некоторые опции созданы для решения конкретных проблем: неправильно определяется тип базы данных, не работает или тормозит интроспекция и пр. Мы убрали такие опции в список Expert options на вкладке Advanced, чтобы пользователи не активировали их случайно.
Туда входят:
- Включение интроспектора JDBC. Если это чем-то помогает, это не нормально. Пожалуйста, напишите нам, прежде чем включать эту опцию!
- Oracle: отключение инкрементальной интроспекции, выборки LONG значений и интроспекции серверных объектов .
- SQL Server: отключение инкрементальной интроспекции.
- PostgreSQL (и аналогичные БД): отключение инкрементальной интроспекции, запрет использования xmin в запросах к pgdatabase.
- SQLite: регистрация функции REGEXP.
- MYSQL: использование SHOW / CREATE в исходном коде.
- Clickhouse: автоматическое назначение sessionid.

Интроспекция
[Oracle] Уровни интроспекции
Пользователи Oracle сталкиваются с проблемой: если у них много баз данных и схем, интроспекция в DataGrip занимает много времени.
Интроспекция — это процесс получения метаданных базы данных: имена объектов, исходный код и др. DataGrip использует эти данные для автодополнения кода, навигации и поиска.
Системные каталоги Oracle работают довольно медленно, но мы поняли, что для повседневной работы (и даже для эффективного автодополнения кода) нет необходимости загружать всю информацию об объектах. Во многих случаях имен объектов базы данных достаточно. Поэтому мы разделили интроспекцию для баз данных Oracle на три уровня:
Уровень 1. Получаем метаданные только об именах всех поддерживаемых объектов, кроме имен столбцов индекса и приватных переменных пакета (package).
Уровень 2: Интроспектируем все, кроме исходников.
Уровень 3: Интроспектируем все.
Интроспекция происходит быстрее всего на первом уровне и медленнее всего на третьем.
Уровень интроспекции меняется в контекстном меню:

Уровень интроспекции может быть установлен либо для схемы, либо для всей базы данных. Схемы наследуют свой уровень от базы данных, но его можно установить независимо.
Иконка-пилюля рядом с иконкой источника данных показывает уровень интроспекции. Чем больше наполнена пилюля, тем выше уровень. Синий цвет иконки означает, что уровень установлен напрямую, а серый — что он унаследован.

[SQL Server, Oracle] Соотнесение связанных серверов и ссылок на базы данных с источниками данных
Теперь вы можете соотнести связанный сервер из SQL Server (linked server) или ссылку на базу данных в Oracle (db-links) с любым источником данных.

Если вы связали внешние объекты с источниками данных, будет работать автодополнение в запросах, использующих этот объект.
[PostgreSQL] Возможность скрыть системные схемы и базы данных шаблонов
Раньше список схем не показывал системные схемы (pg_toast, pg_temp и др.) и шаблоны баз данных. Мы добавили возможность отображать их: вы найдете эти настройки на вкладке Schemas.

[Snowflake] Поддержка потоков
Теперь в проводнике базы данных помимо таблиц и представлений отображаются потоки.

[ClickHouse] Распределенные таблицы
В проводнике баз данных появилась отдельная папка для распределенных таблиц.

Консоль запросов
Проверка логических выражений
Один из наших пользователей написал в Твиттере о неприятной ситуации: он выполнил запрос UPDATE в производственной базе данных с условием WHERE id – 3727 (вместо =) и обновил миллионы записей!
Мы тоже удивились, что в MySQL такое возможно, и сразу добавили проверку логических выражений в предложениях WHERE и HAVING.
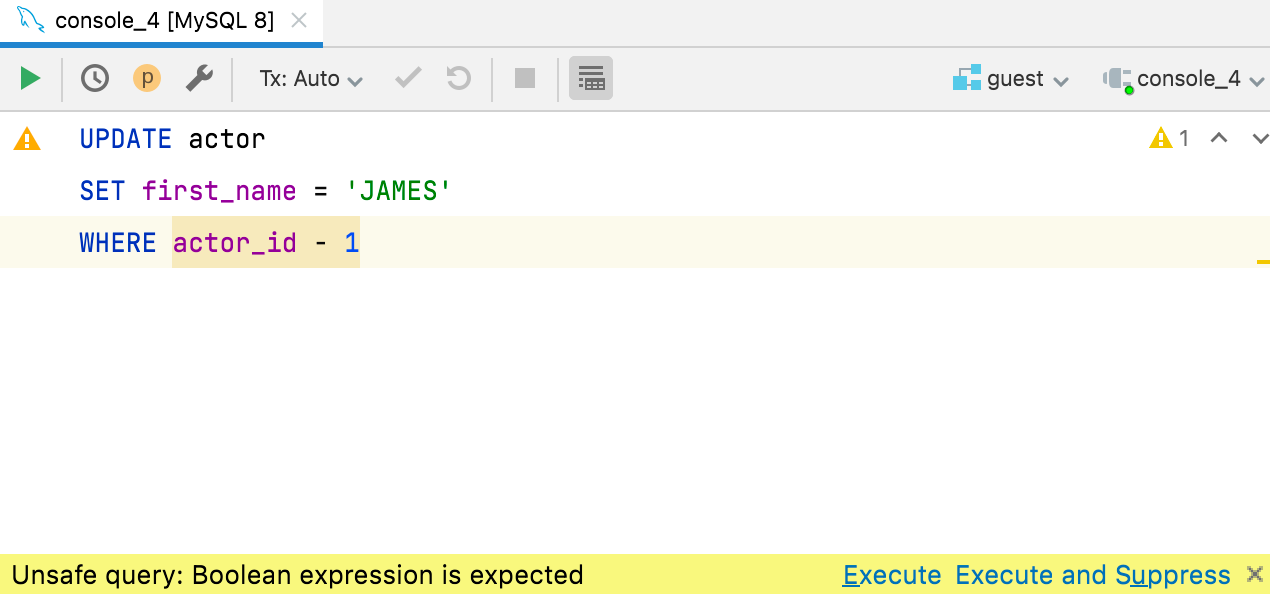
Если выражение не совсем похоже на логическое, DataGrip выделит его желтым цветом и предупредит перед выполнением запроса. Это работает для ClickHouse, Couchbase, Db2, H2, Hive / Spark, MySQL / MariaDB, Redshift, SQLite и Vertica. В других базах данных это будет отмечено как ошибка.
Создание табличных функций из запроса
Теперь команда Extract Routine умеет создавать табличные функции на основе SQL-запросов. Для этого выделите запрос, откройте меню Refactor и выберите опцию Extract Routine. Поддерживается для Db2, SQL Server, Postgres, Greenplum и Snowflake.

Подсказка о кратности JOIN
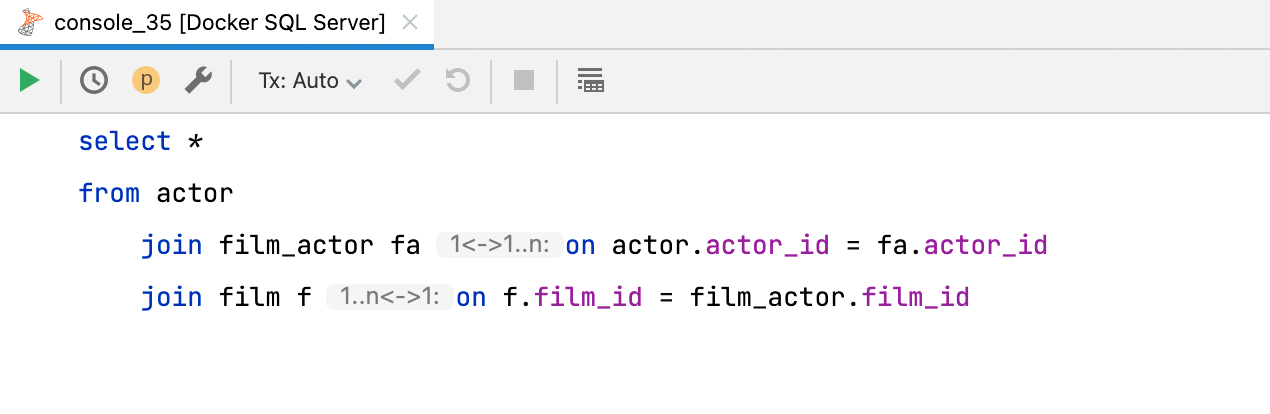
Появилась встроенная подсказка, показывающая количество узлов в условии для JOIN. Есть три основных опции: one-to-one, one-to-many, and many-to-many (подробнее об этом в статье на Wiki). Можно выключить подсказку в Preferences | Editor | Inlay Hints | Join cardinality.
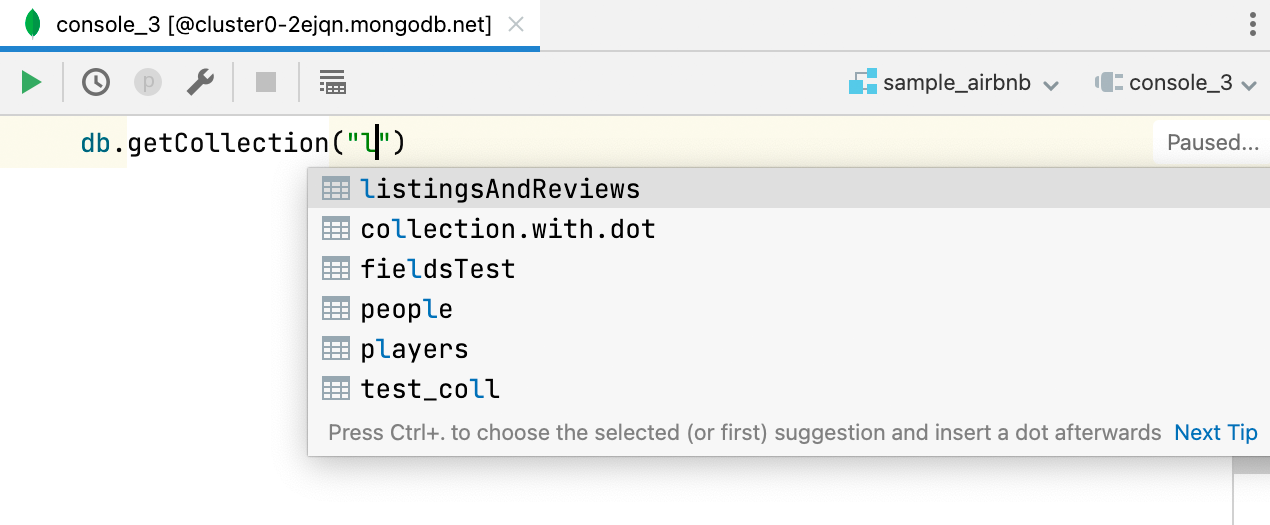
[MongoDB] Автодополнение имен баз данных
Автодополнение работает для названий баз данных при использовании getSiblingDB, а при использовании getCollection — для имен коллекций. Кроме того, автодополнение работает, если используются имена полей из коллекции, определенной с помощью getCollection.
Окно инструментов Services
Результаты без временных меток
Нас просили убрать временные метки в панели Output: они больше не отображаются по умолчанию. Если вы хотите вернуть как было, измените настройку в Database | General | Show timestamp for query output.

Новые настройки управления поведением панели Services
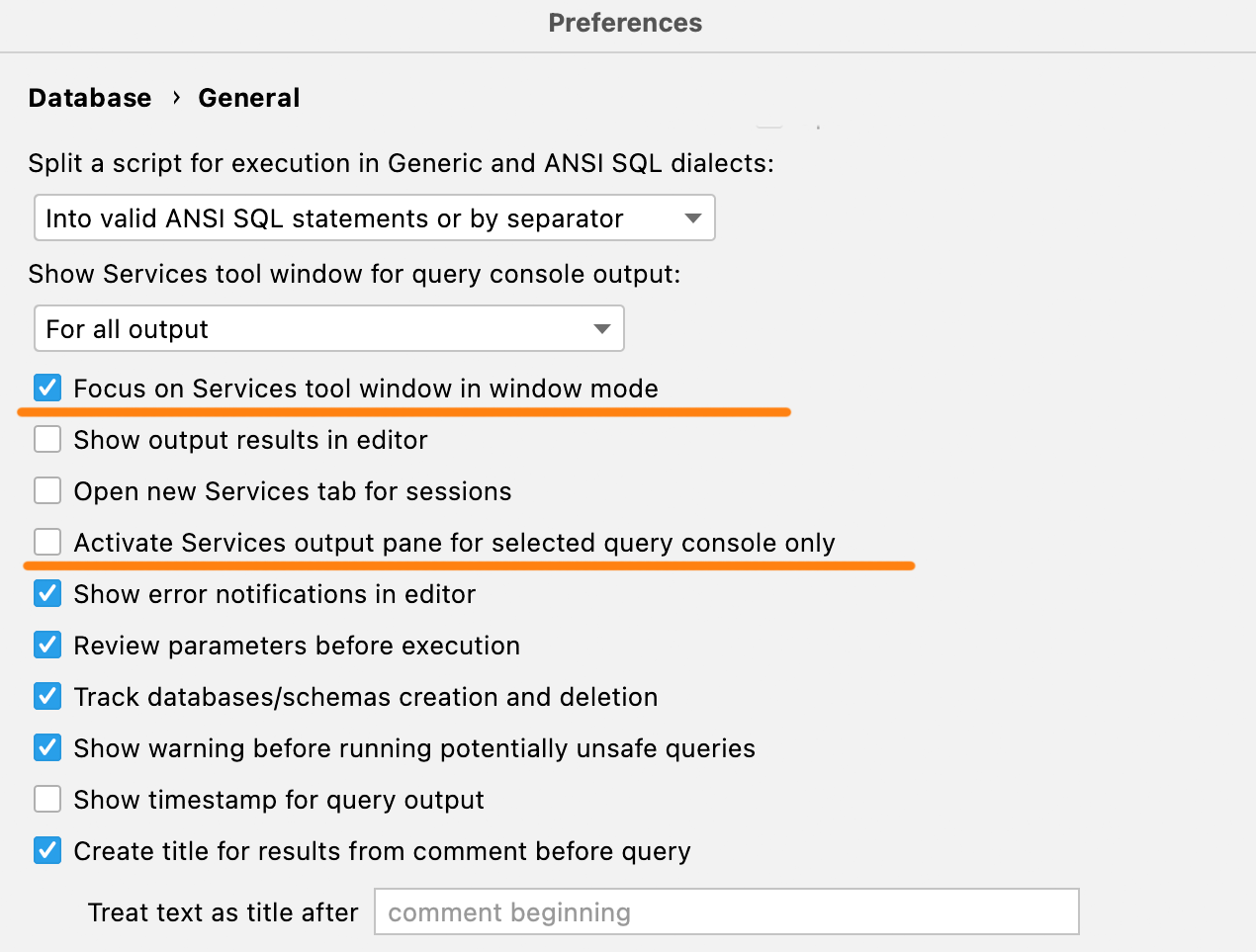
Если вы используете панель Services в оконном режиме, по умолчанию оно всегда скрыто за IDE. Мы добавили настройку, которая передает фокус окну при каждом запуске запроса — оно будет появляться, как только запрос выполнится.
Кроме того, если вам не нравится, что после выполнения долгого запроса в панели Services активируется соответствующая вкладка, установите флажок Activate Services output pane for selected query console only.
Import/Export
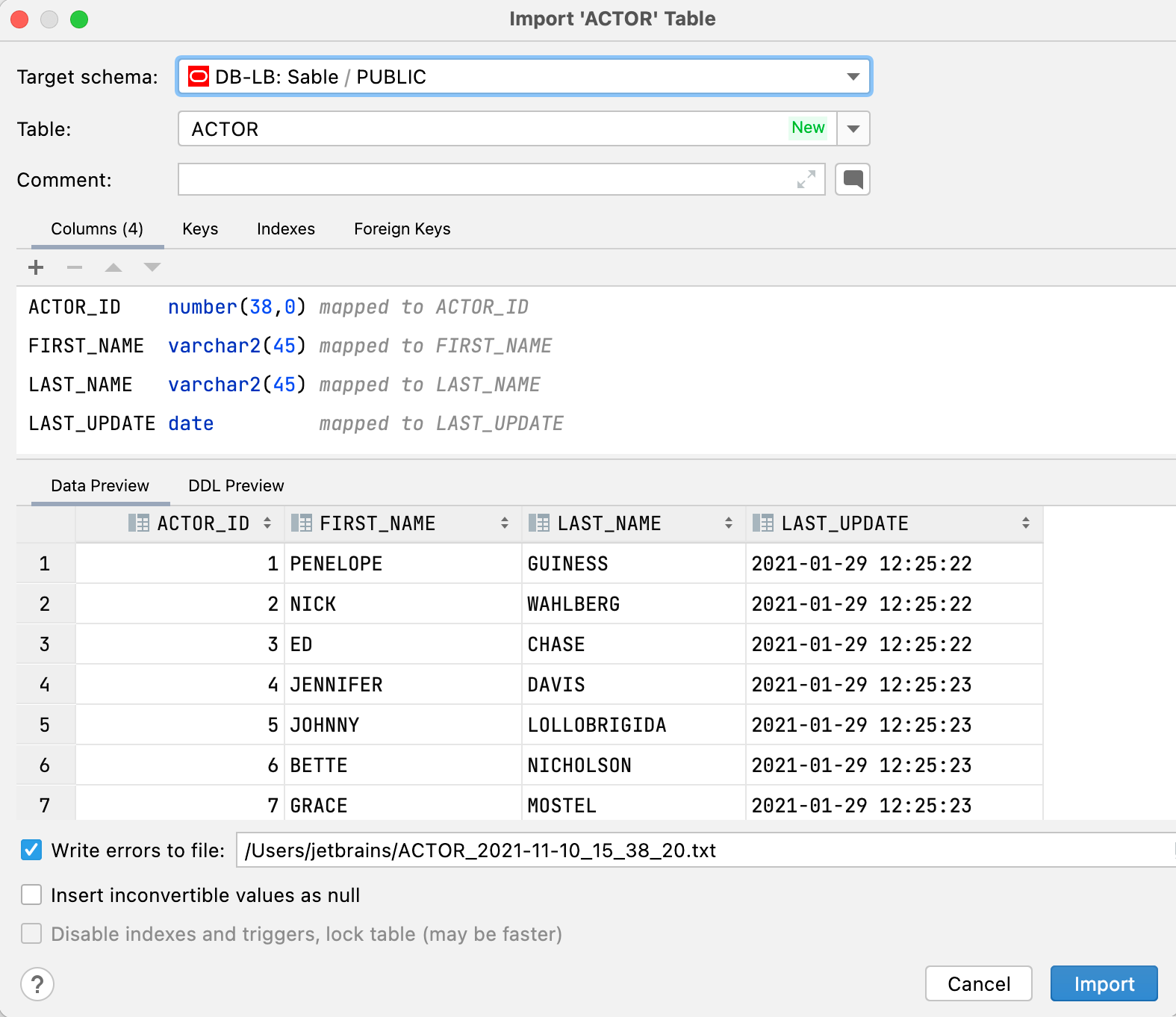
Новый интерфейс для импорта данных
Мы улучшили импорт .csv-файлов и копирование наборов данных:
- Вы можете выбрать существующую таблицу или создать новую.
- В окне можно поменять схему для направления импорта. Раньше открывалось отдельное окно для выбора схемы, теперь его нет.
- Выбор целевой схемы сохраняется по умолчанию. Если вы постоянно импортируете в одну и ту же схему, вам не придется указывать её заново каждый раз.
Автоматическое определение первой строки как заголовка
При открытии или импорте .csv-файла DataGrip автоматически определяет первую строку как заголовок с названиями столбцов.

Автоматическое определение типов столбцов в .csv-файлах
DataGrip теперь определяет типы столбцов в .csv-файлах. Теперь можно сортировать данные по числовым значениям. Раньше они определялись как текст, и это мешало сортировке.

Прочее
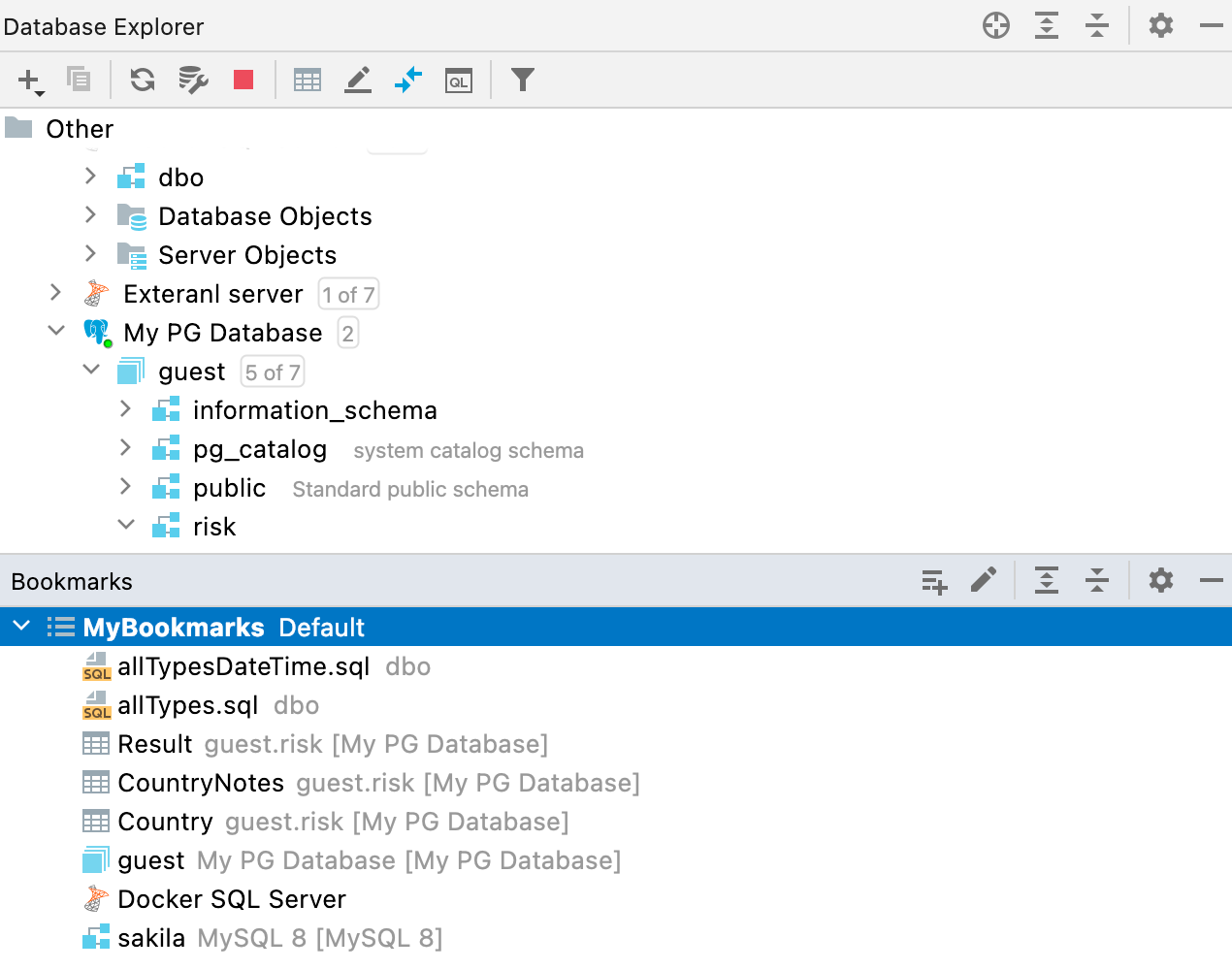
Новая панель Bookmarks
Раньше у нас было два похожих понятия — Favorites и Bookmarks. Разница между ними была не очень понятна, и мы решили оставить только Bookmarks. Мы поменяли логику для этой функции и сделали для закладок отдельную панель.
Теперь в новой панели Bookmarks будут все объекты или файлы, которые вы отметите как важные (F3 в macOS или F11 в Windows / Linux).
На этом все! Напоминаем, что у DataGrip есть свой канал в Телеграме, там можно задавать вопросы и делиться опытом. А про баги лучше сразу в трекер, чтобы не потерялись. Спасибо за внимание!
Ваша команда DataGrip
The Drive to Develop
Оригинал статьи опубликован на Habr.com.
Subscribe to DataGrip Blog updates






