Scala Plugin
Scala Plugin for IntelliJ IDEA and Android Studio
Combine IntelliJ IDEA with Hydra for the Fastest Scala Development Experience

For several years we’ve been working with Triplequote to help them develop the Hydra IntelliJ IDEA plugin. By combining IntelliJ IDEA with the Hydra parallel compiler, you can speed up both Scala development and Scala compilation. Here is a tutorial from the Triplequote team to explain the details.
1. What is Hydra?
2. Install the Hydra IntelliJ IDEA plugin
3. Compile!
4. Low memory detection
5. Compilation bottlenecks detection
6. What next?
What is Hydra?
Hydra, developed by Triplequote, is the only Scala compiler that parallelizes compilation across all available compute cores, speeding up compilation time up to 5x, and providing much faster return-to-productivity.
In addition to faster return to productivity, Hydra ships with built-in compile time monitoring, allowing you to crack open the compiler “black box” with the Hydra Dashboard, providing visualizations and metrics for optimizing your project’s compilation speed over time, and helping teams keep performance under control.
Hydra supports the full language (macros and compiler plugins – Scala.JS included), and it smoothly integrates with your build tool of choice, whether that is sbt, Maven or Gradle.
This article shows how to set up Hydra in IntelliJ IDEA and the many benefits delivered by Hydra in addition to parallel compilation.
Install the Hydra IntelliJ IDEA plugin
To install the Hydra IntelliJ IDEA plugin just search for “Triplequote Hydra” on the Plugins Marketplace.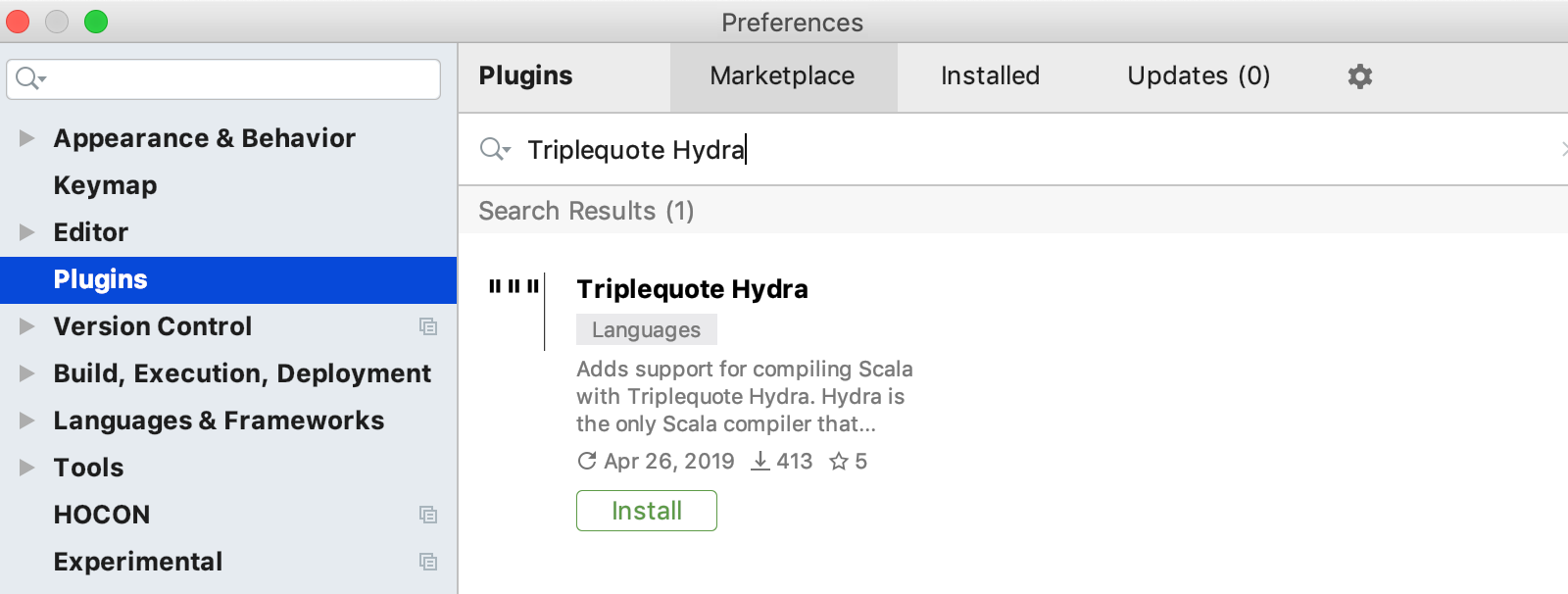
Once installed, open the “Hydra Compiler” page and notice that at the top it says “No license detected”.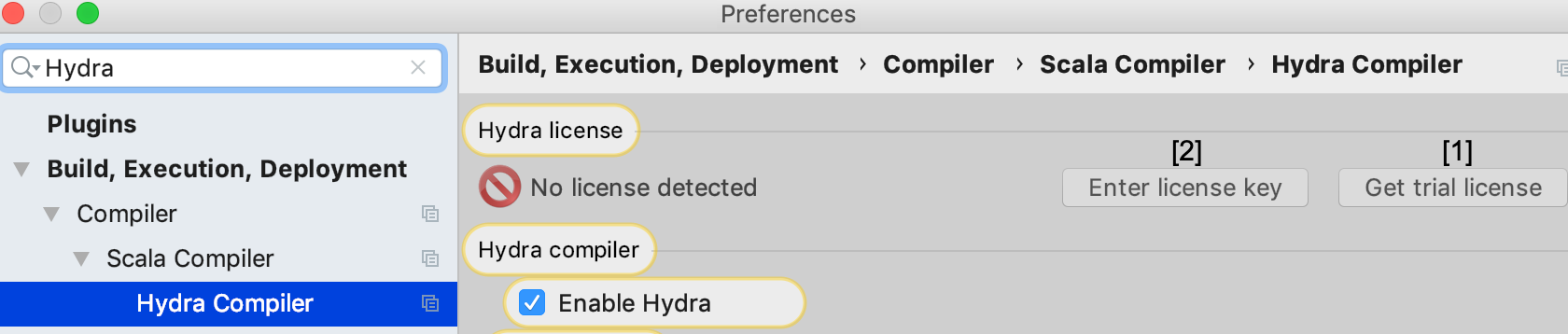
This is normal, as you need a license to compile with Hydra. Go ahead and hit the button “Get trial license” located on the top-right ([1]), and provide your full name and email. You will immediately receive the license key (check your SPAM folder if you can’t see it).
To use it, go back to the “Hydra Compiler” page, and click the “Enter license key” button ([2]). Paste the Hydra Developer license key you have received and proceed. The “Hydra Compiler” page is updated to confirm the validity of the license.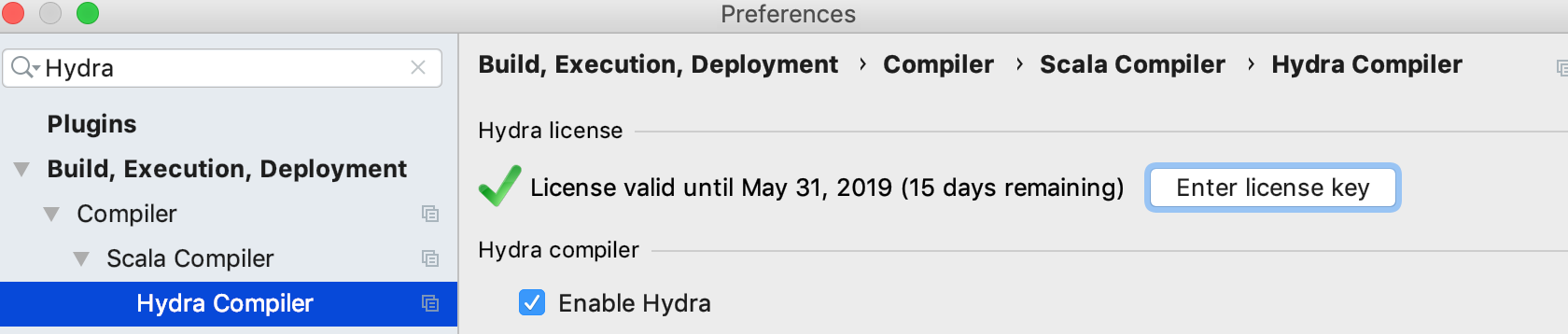
Congratulations! You are all set and ready to compile your Scala projects with Hydra.
Compile!
All Scala projects opened in IntelliJ IDEA will now be compiled with Hydra. You don’t need to do anything, it just works!
To try it out, hit “Build > Rebuild project” and notice in the Message view that “N Hydra workers” were used to compile your Scala sources.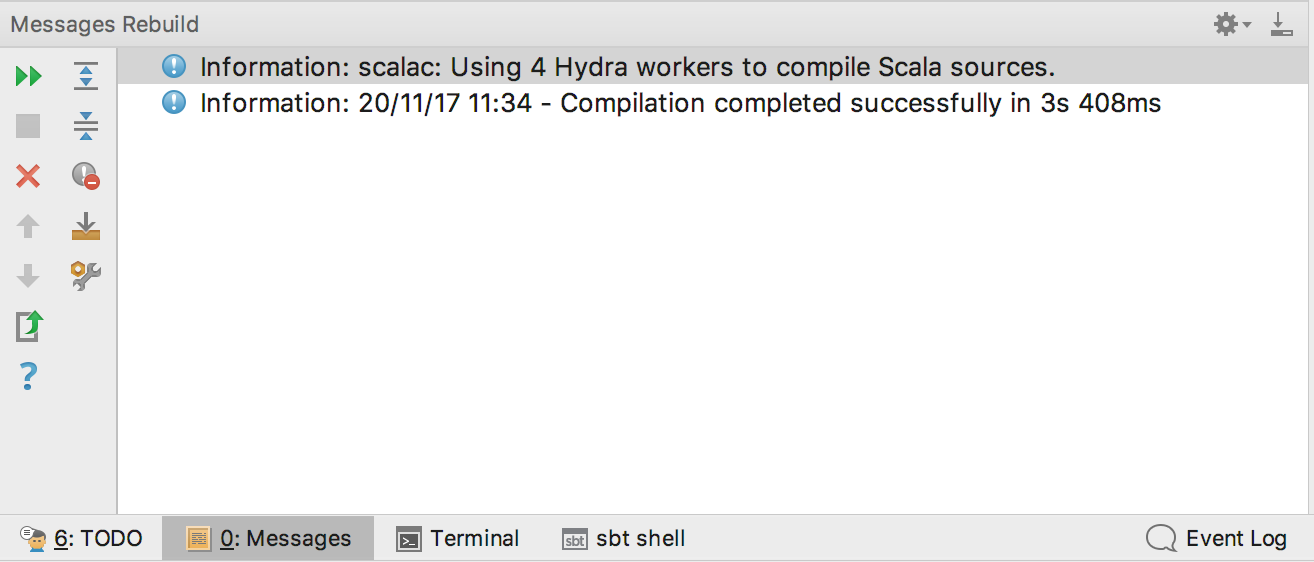
Keep in mind that the default number of Hydra workers used may vary depending on the machine’s hardware, what type of Hydra license is in use, and the number of compiled sources. You can always modify it yourself on the settings page.
Low memory detection
A common (and often ignored) reason for long compilation time is that not enough memory heap is reserved for compilation. In fact, Scala compilation is allocation hungry and can put considerable pressure on the JVM Garbage Collector (GC), to the extreme that more time may be spent GC-ing rather than compiling!
The default heap size reserved for Scala compilation inside IntelliJ IDEA is 1024MB (see the “Scala Compiler Server” preference page under “Preferences” > “Build, Execution, Deployment” > “Compiler” > “Scala Compiler” > “Scala Compile Server”). While this default is good to get started, as modules grows in size and complexity more memory is often needed. Hence, memory usage needs to be constantly monitored during compilation, as otherwise it’s easy to miss that a reason why compilation takes long is because a sizeable amount of time is wasted GC-ing.
The solution to this rather annoying problem is to monitor GC. This can be achieved with the help of a profiler (e.g., VisualVM), but we prefer to automate and when using Hydra to compile there is no need to profile GC, ever. In the event that a considerable amount of time is spent GC-ing during compilation, Hydra reports a warning so that you can act on it.
To fix the problem, increase the max heap size in the “Scala Compiler Server” preference page. Be aware that for the change to be picked up the Compiler Server process needs to be restarted – click the throttle icon located at the bottom of the editor, then “Stop” and “Run” again.
Compilation bottlenecks detection
We, as Scala developers, have a tendency to accept our project’s compilation time without ever questioning it. After all, what could we possibly do about it? It turns out there is actually a lot we can do, but to direct our efforts we need to gain visibility into what the compiler does and know where the biggest bangs for the bucks are. Said otherwise, we need to know what Scala sources in our project takes the longest to compile.
One of the greatest features of Hydra is its built-in compile-time monitoring capabilities, and once again Hydra does the heavy lifting for you: if it detects a source file takes more than 5 seconds to compile, it reports the information at the end of the compilation.
It’s surprising how having this simple piece of information changes entirely the attitude we have in the face of the compiler. All of a sudden, we are surprised that some sources may be taking 5, or 10 seconds, or even more to compile, and hence we dig deeper. How do we do that? And how to know what source(s) takes long to compile? We look at the compilation data collected in the Hydra Dashboard!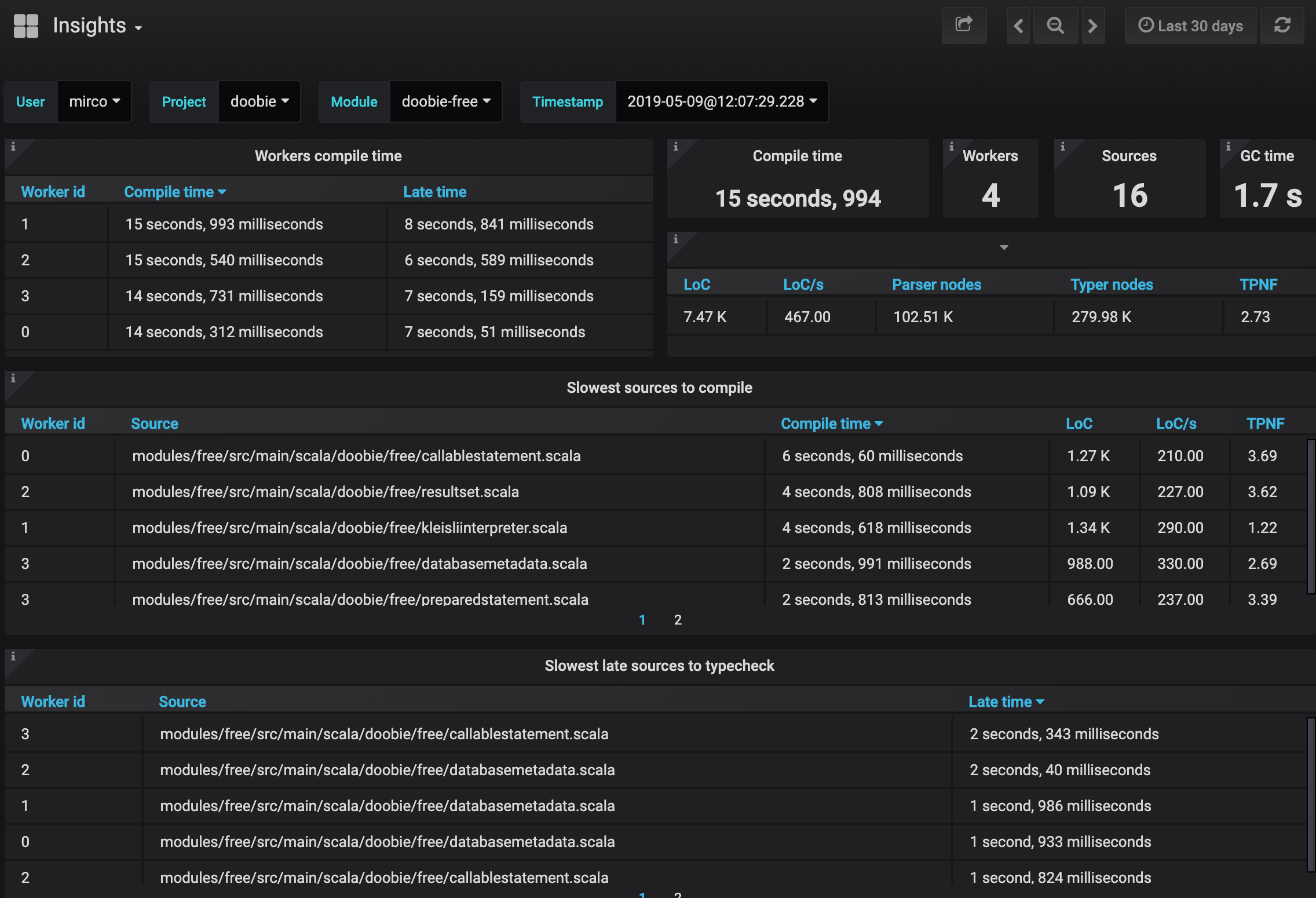
The compilation metrics above were collected while compiling the Doobie open-source project. The Dashboard points out immediately what source took more than 5 seconds to compile.
This source file contains 250+ case classes definitions. For each case class, the Scala compiler generates several methods in both the class and its companion object. So, while a single case class is very fast to compile, the time adds up when you have over 250+ defined in a single source file. But using case classes was a design decision for the library, so in this case we are ok with the implied compile time cost. This is a remarkable insight we just gained on the project!
Despite the above considerations, there is still value in breaking up a source file that takes a long time to compile, as this reduces the incremental compilation time when editing the specific source. Thanks to IntelliJ IDEA refactoring capabilities, this is easy to achieve, as we can use the “Move” refactoring to split the logic into multiple files, bringing the compilation time of all sources below 5 seconds (the smaller the better!).
As you start exploring the compilation metrics collected on your project, you’ll discover bottlenecks you didn’t expect. A common one is to have imports in scope that are used to generate implicit values through macros (for instance, using the Circe automatic derivation feature). To learn more on this specific topic and how to address it, you may want to watch this ScalaDays talk “5 Things you need to know about Scala compilation” or read the Zalando article “Achieving 3.2x faster compilation time”. The Hydra Dashboard documentation also provides additional useful advice for speeding up compilation further.
What next?
Check out the Hydra documentation to find out more about Hydra and discover how easy it is to integrate it with your build tool of choice. Also, if you would like to benchmark how Hydra performs against the vanilla Scala compiler, you might find the hydraBenchmark command very useful!
And don’t forget to install the Dashboard to quickly identify compilation bottlenecks affecting your Scala projects!