Scala Plugin
Scala Plugin for IntelliJ IDEA and Android Studio
Data Engineering and Developer Tools for Big Data

This is a guest blog post by Jeff Zhang, a speaker at multiple events around Big Data, an active contributor to various open source projects related to Big Data, an Apache member, and a staff engineer at Alibaba Group. Last week, Jeff did a webinar for JetBrains Big Data Tools where he gave an overview on who data engineers are and what tools they use. The webinar was so interesting that we asked Jeff to write this guest post for our blog. This blog post will be especially interesting to you if you’re curious about data engineering, how it’s done, and what tools are used for it. Hopefully, we’ll have more webinars and blog posts on Big Data in the future.
Data engineering is becoming increasingly popular because of the rising interest in big data and AI. Big data creates technical challenges, but it also means there is more value in data. AI drives more data consumption with many applications. In this post, I would like to talk about data engineering and developer tools for big data.
What is Data Engineering?
Before we talk about what data engineering is, let’s first take a look at the data pipeline.
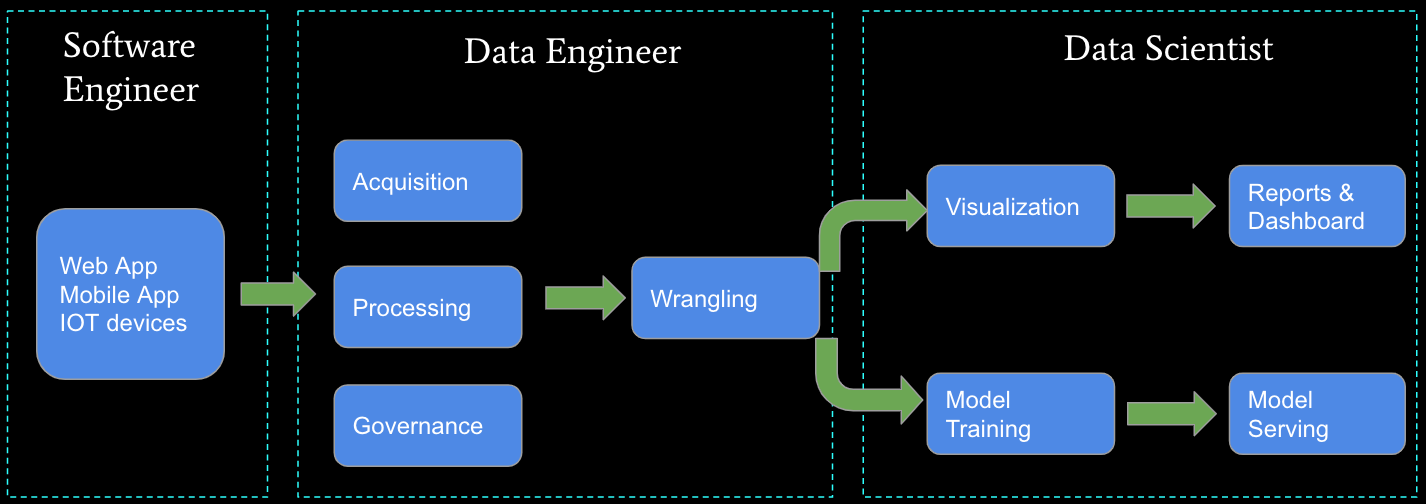
Over on the left side is the data source where the data is generated — it might be a web app, mobile app, or even IoT devices. After data is generated, it goes through acquisition, processing, and governance. Then the data is usually used in 2 scenarios. One usage is for Business Intelligence (BI), where we do data visualization, build reports, and create dashboards. The other usage is for Artificial Intelligence (AI), where data is used for model training and then serves the model online for your applications.
The left side represents the tasks of the software engineer, who builds the web or mobile app. The middle is the domain of the data engineer, who does the data acquisition, processing, governance, and further data wrangling. On the right side, data scientists do the BI and AI work. I’d like to clarify that it is the ideal depiction of the duties of software engineers, data engineers, and data scientists. But, in most cases, like in small or midsize companies, data engineers may also need to do some parts of the work that traditionally software engineers and data scientists do.
From the previous data pipeline, we can get a clear picture of what a data engineer is.
- A data engineer is essentially a software engineer but with professional data processing skills.
- Data engineers need to have a basic understanding of data science so that they can deliver the right data and tools to data scientists.
And as a data engineer, they will mainly do the following 2 things:
- Deliver clean and well-organized data.
- Build the BI / AI infrastructure / tools for data analysts or data scientists.
Tools/Skills for Data Engineering
Now that we have gone over what data engineering is, the next question is, how can we become good engineers. What kind of tools and skills are required?
Programming languages
I believe SQL is a must-know programming language for data engineering. Besides the language itself, you also need to understand the database, including the data model, storage, index, etc. SQL can be used in 2 main scenarios: one is for ETL (the process of extracting, transforming, and loading data), and the other is for data analysis.
The next two most widely used languages in data engineering are Java and Scala, which belong to the JVM languages. JVM has a very strong and powerful ecosystem, where you can find almost every library or tool needed for building a large system.
One more important language is Python, which has become very popular in recent years because of its application in AI. It is widely used by data analysts and data scientists.
Functional programming
Functional programming is widely used by data engineers today. Functional programming is a programming paradigm – a style of building the structure and elements of computer programs – which treats computation as the evaluation of mathematical functions without any side effects, which is the most critical aspect of functional programming in my opinion.
The reason functional programming is suitable for data engineering is that it can solve 2 critical issues in data engineering.
- Reproducibility. Reproducibility means that when given a specified input, you can always get the determined output through a pure function. Reproducibility is important for data engineering because errors are normal in data engineering and rerunning jobs is not rare, so reproducibility is pretty important to ensure data quality.
- Test. Usually, a data pipeline is a large DAG (directed acyclic graph) that is chained by many subtasks. Testing the whole pipeline is almost impossible, but with functional programming, we can test each subtask; as long as each subtask is correct, we can ensure the whole pipeline is correct.
Tools for Data Engineering
There are many tools/frameworks in data engineering, such as Hadoop, Hive, Spark, and so on. As I cannot talk about all of them in this post, I’ll mention the two tools that are the most useful in my daily work: Spark and Zeppelin.
Spark
Spark is widely used by data engineers for big data processing. Here are some of the key reasons people love Spark:
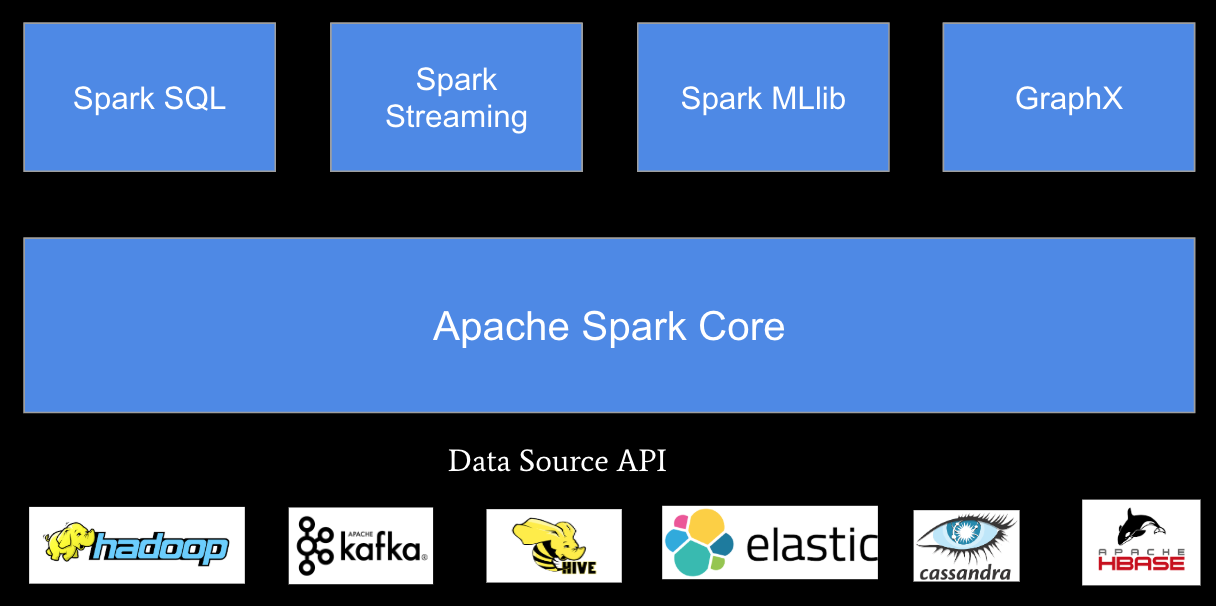
- Spark can be used in multiple areas, including batch processing, streaming processing, machine learning, and GraphX computing.
- Spark has very rich data sources, which make it easy for it to consume different data sources and integrate with other systems.
- Spark API is a functional style. As we mentioned before, functional programming is very suitable for data engineering, as the pure function can solve the two main issues, reproducibility and tests.
- Last but not least, high performance: compared to MapReduce, Spark’s performance has improved significantly.
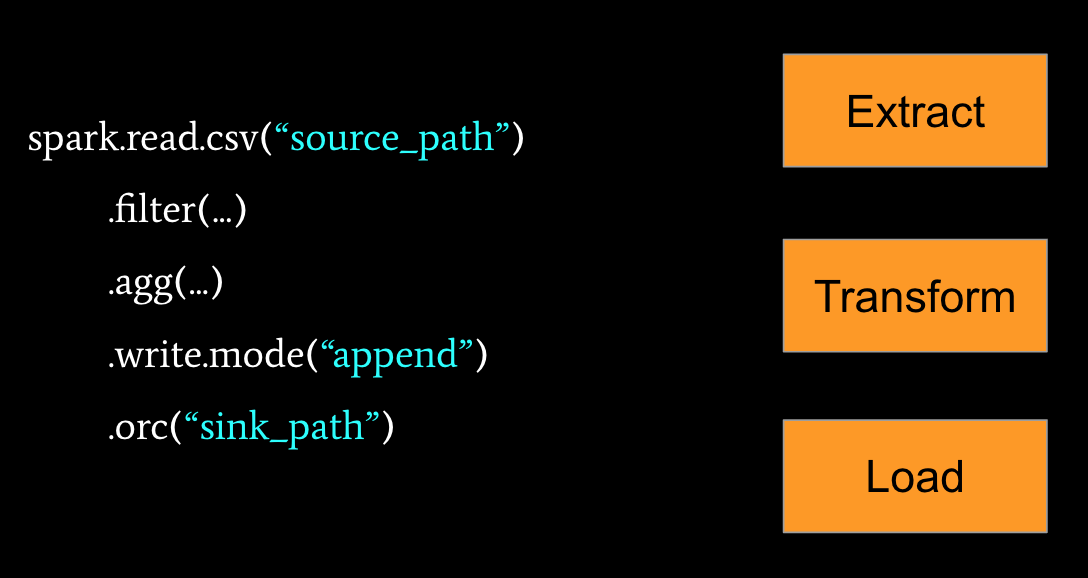
The most typical usage of Spark is ETL. Writing an ETL job is pretty simple. Here is one example: Spark reads the CSV data and then does the filtering and aggregating, finally writing it in ORC format.
Zeppelin
Besides Spark, there are many other tools you will need in data engineering. However, many of these big data tools have one big issue: accessibility/usability. Let’s take Spark as one example: the following diagram shows the traditional approach to developing a Spark application. You can see that the whole process is pretty inefficient.
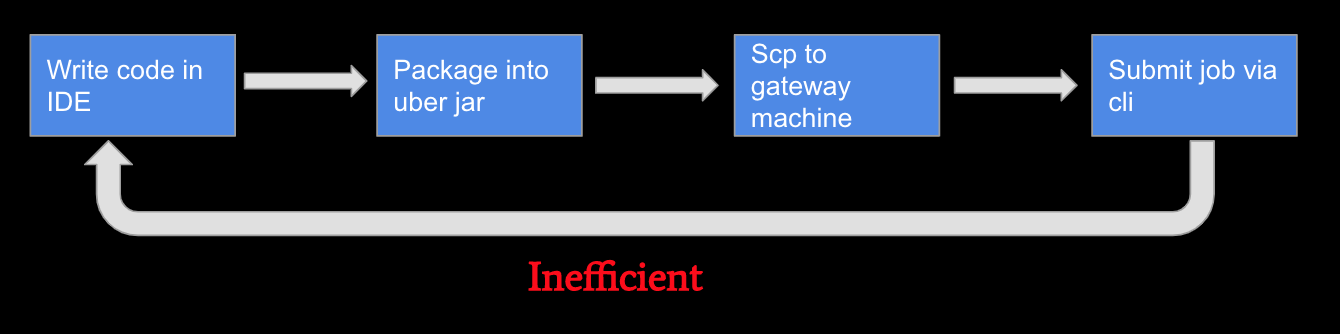
So how can we improve it? This is where Zeppelin comes in.
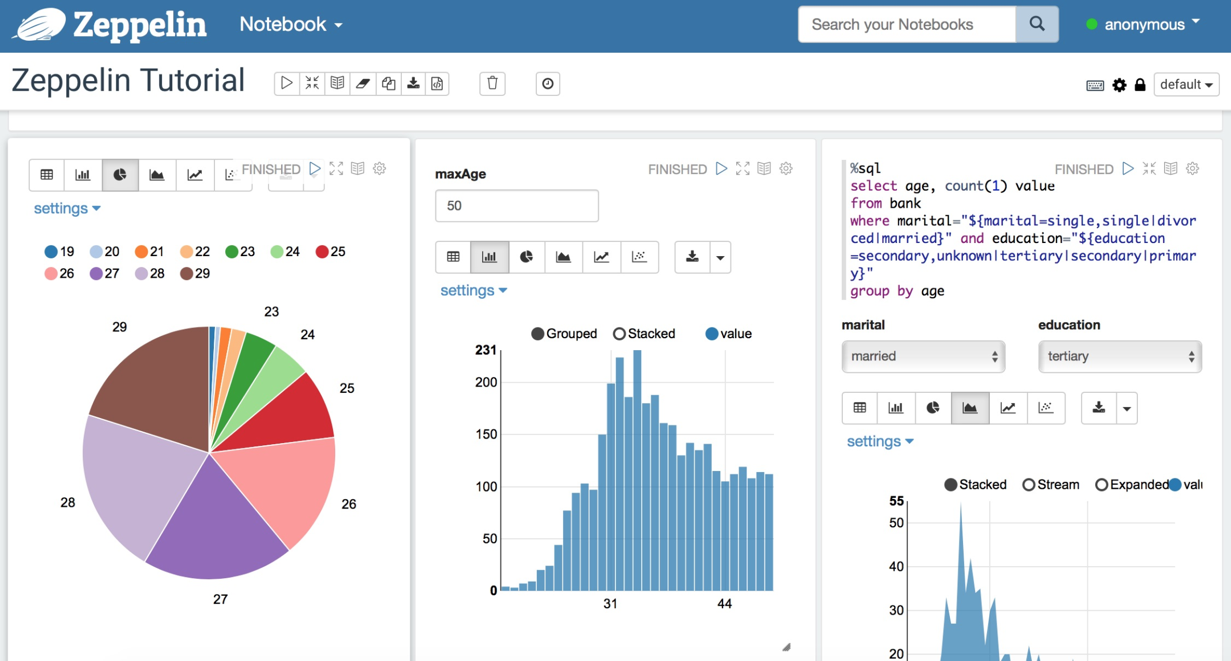
Zeppelin is a web-based notebook that enables data-driven, interactive data analytics and collaborative documents with SQL, Scala, Python, and more. In Zeppelin, you don’t need to build an uber JAR, SCP to gateway machine and deploy spark app manually. All of them are done by Zeppelin.
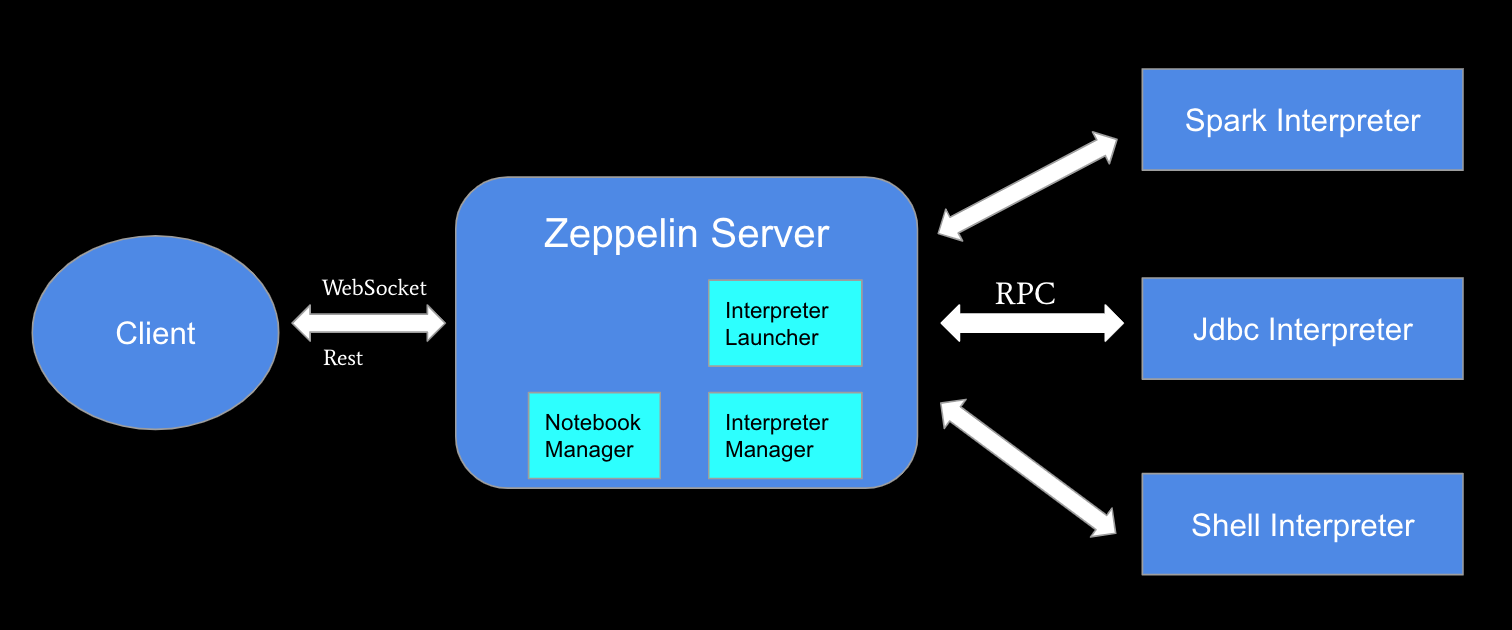
Now let’s look at Zeppelin’s architecture. Basically, Zeppelin has 3 layers: the client layer, the Zeppelin server layer, and the interpreter Layer. Zeppelin Server manages the notebook and interpreter, and will help to launch the interpreter. The interpreter is the component which does the real computation. In addition to Spark’s interpreter, Zeppelin also supports many other popular tools such as the JDBC interpreter and the command line interpreter. These interpreters communicate with the Zeppelin Server via an RPC protocol.
Besides Zeppelin’s ability to run code interactively, there are many other advanced features that can be useful in data engineering.
- Shared SparkContext/SparkSession across languages. We know that Spark not only has a Scala API, but it also has Python and R APIs. In Zeppelin, all of these three languages share the same SparkContext. This means there is data sharing across languages. You can register a Spark table in Scala and access it in PySpark and SparkR.
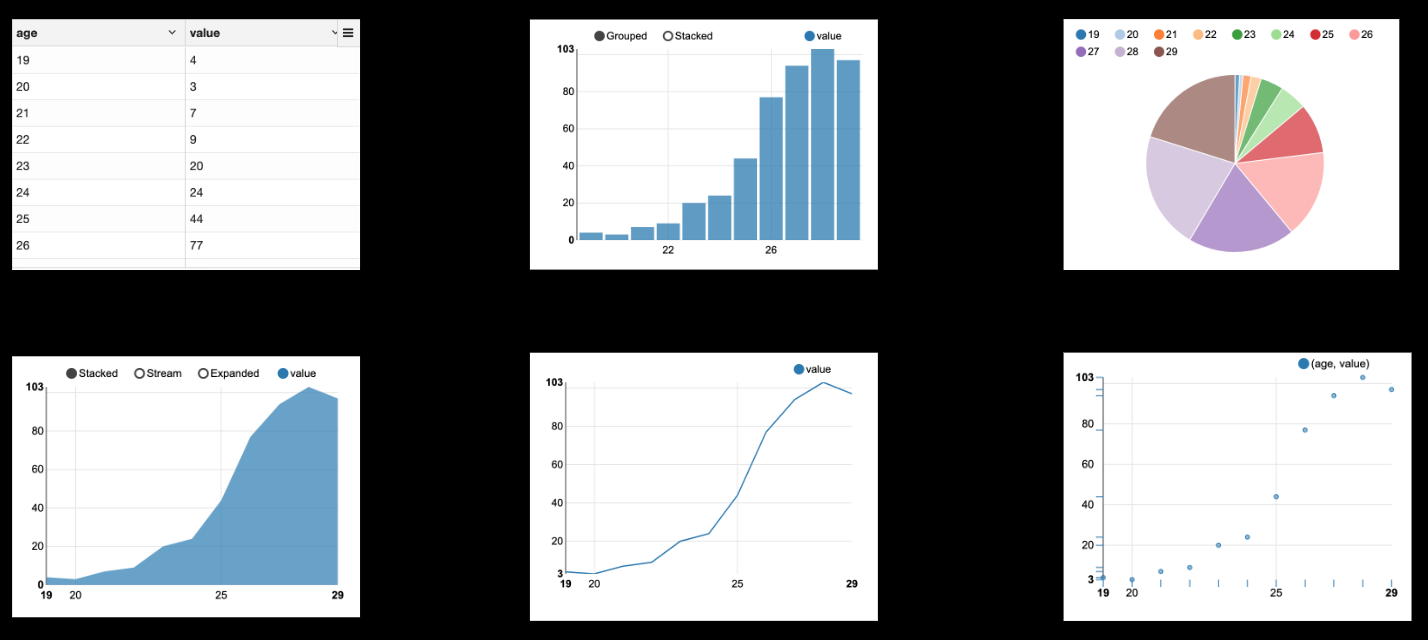
- Inline visualization. Most data engineers are backend engineers who are not very good at frontend. But sometimes you have to build reports or dashboard as a data engineer. Zeppelin can help with that. There are six kinds of display formats that Zeppelin supports.
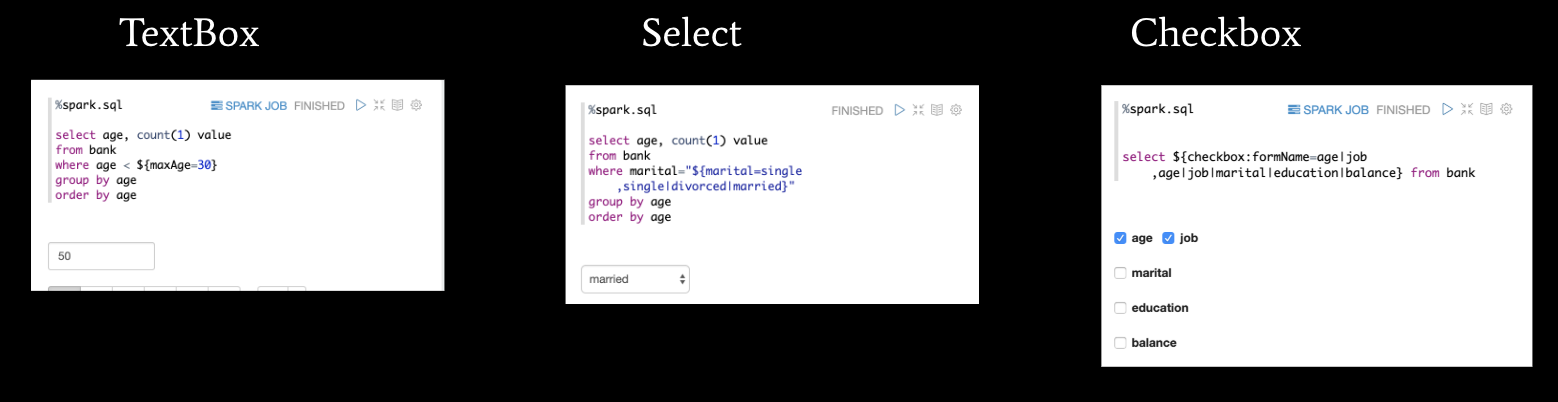
- Dynamic forms. Most of the time you need your program to accept a parameter so that you can customize it. Dynamic forms is built for this purpose. There are three main dynamic forms supported by Zeppelin to accept inputs: Text, Select, and Checkbox.
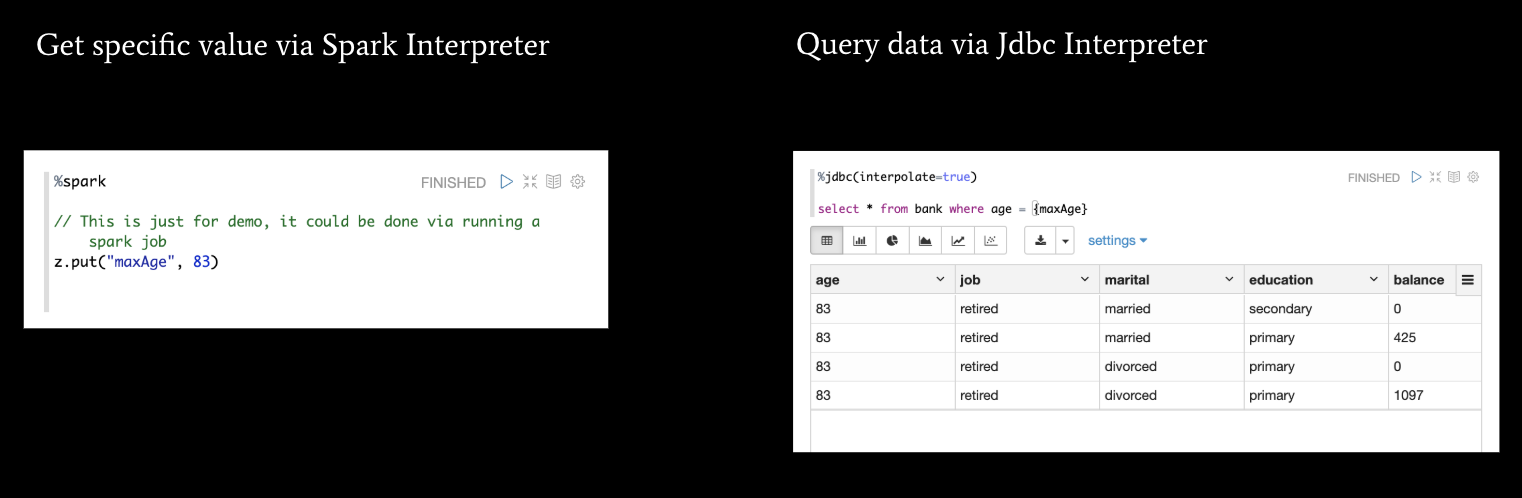
- Data exchanges across languages/interpreters. We know that we usually need to involve multiple tools for a complex task, so how we exchange data across interpreters is pretty important. In Zeppelin, you can exchange 2 kinds of data: string data and table data. Below are 2 examples to illustrate how to pass a string from a Spark interpreter to a JDBC Interpreter and how to pass table data from a JDBC Interpreter to a Python interpreter
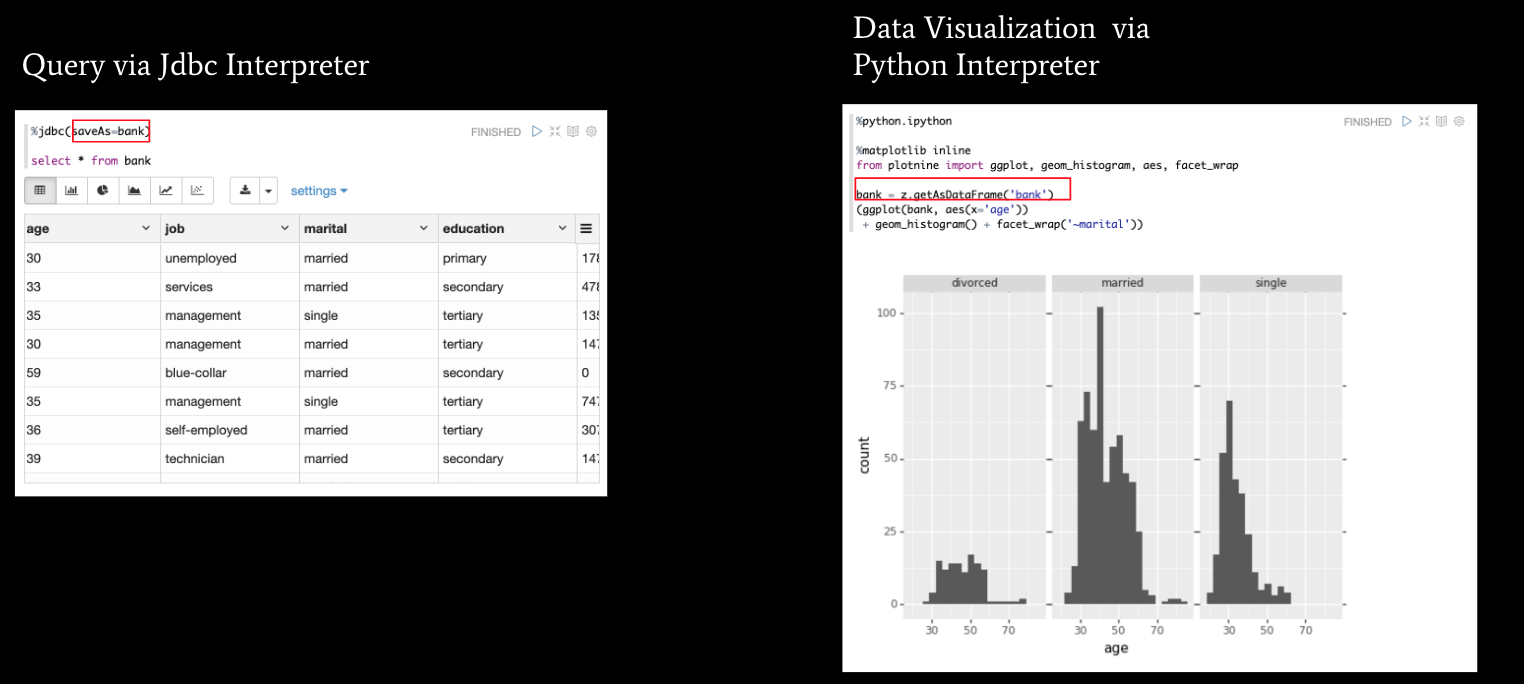
- Rest API. You can only run code in Google Chrome via the notebook interface, but also you can call its REST API. You can use the REST API to run paragraphs and paragraph results. So why do we need a REST API, and what can it be used for? There are two major use scenarios:
- Workflow. Usually, the data pipeline is a complex DAG that involves many small tasks. We can put each subtask into separate paragraphs, and assemble these paragraphs into a workflow DAG via other tools. For example, we can create an Airflow Operator for the Zeppelin paragraphs, and assemble them into a large DAG in Airflow.
- Integration with other systems. For example, we may have a Java application or a reporting system which can run paragraphs via a REST API and fetch results from Zeppelin and display it in an external system.

- Workflow. Usually, the data pipeline is a complex DAG that involves many small tasks. We can put each subtask into separate paragraphs, and assemble these paragraphs into a workflow DAG via other tools. For example, we can create an Airflow Operator for the Zeppelin paragraphs, and assemble them into a large DAG in Airflow.
Summary
In this post, I talked about what data engineering is and what kinds of skills and tools are required for data engineering. There are many other things in the area of data engineering, so here are several useful links you can use for further exploring this fascinating field.
- http://spark.apache.org
- http://zeppelin.apache.org/
- https://plugins.jetbrains.com/plugin/12494-big-data-tools
- https://medium.com/@acmurthy/hadoop-is-dead-long-live-hadoop-f22069b264ac
- https://towardsdatascience.com/who-is-a-data-engineer-how-to-become-a-data-engineer-1167ddc12811
- https://www.freecodecamp.org/news/the-rise-of-the-data-engineer-91be18f1e603/
We hope you’ve enjoyed reading this overview of data engineering. Please share your feedback with us, and also let us know what particular things you’d like us to cover in future webinars and guest blog posts.
If you’d like to watch the webinar recording, here it is:
Last but not least, if you’re involved in Big Data and know a thing or two about Spark, Hadoop, or Zeppelin, make sure to give a try to our Big Data Tools plugin for IntelliJ IDEA Ultimate.
Keep the drive to develop!