Scala Plugin
Scala Plugin for IntelliJ IDEA and Android Studio
Dataflow Analysis for Scala

One of the things IntelliJ IDEA is most famous for is its huge variety of helpful inspections and warnings. They make the lives of programmers significantly easier, frequently showing them errors in logic or style that they wouldn’t have noticed otherwise.
Those inspections come in various shapes and sizes, ranging from simple pattern searches to highly sophisticated inspections that require tons of complex static code analysis behind the scenes. Among the most advanced examples of the latter are those offered with the help of dataflow analysis.
These inspections have been available for Java for a long time and have proved invaluable in finding numerous obscure bugs. However, no such inspections have ever been implemented for Scala. This became the focus of my internship with the IntelliJ Scala team this summer, and now we’re happy to announce that we’re bringing dataflow-based inspections to Scala developers.
They come enriched with special support for many important Scala-specific structures, like case classes or sequences. You can already try them out in our regular Nightly builds or wait until the next major IntelliJ IDEA release at the end of November 2021.
Dataflow analysis in a nutshell
Dataflow analysis consists of two major phases: control flow building and proper dataflow analysis.
Control flow building
First, we transform the abstract syntax tree of the program into something that will give us more information about its actual execution flow – the control flow graph. In IntelliJ IDEA, we represent control flow using our own stack-based intermediate representation, which is similar to Java bytecode. In short, we compile the user code into this bytecode-like representation.
Proper dataflow analysis
Each method is then analyzed separately. We partially execute its body, using the body’s control flow representation and keeping track of useful semantic information, especially possible variable values. However, most of those are unknown and will only become known at runtime (e.g. values of method parameters). That is why often we can only obtain and process abstract information like “x is even and greater than 10” or “y is an immutable list with five elements”. For this reason, this procedure is called abstract interpretation.
Once we collect all of that dataflow information, we can analyze it to identify suspicious places and possible bugs in the code, like a complex expression that always evaluates to the same value or an access to a collection with an index larger than its size.
How it works
To illustrate this more concretely, let’s have a look at this very simple piece of code.

When we analyze the first method, we know everything about x. The condition 2 > 3 is always false, so x will always be 7. We can propagate this information and use it later when we see x again in the code – in this case in the returned expression.
In the second method however, we don’t know much about y. The values of a and b are unknown, so there are two possible paths: y can either be 5 or 7, but we don’t know which one. But this is already a lot of information – we can’t say anything about y == 7, but we can confidently say that y > 4 is always true in any possible program execution scenario.
This example is very simple, but the power of dataflow analysis lies in the fact that we can choose to track many different kinds of information about those variables. Those pieces of information can then be combined with each other, leading us to powerful insights about the code being analyzed. Let’s briefly take a look at several examples of what Scala DFA is capable of in its current state.
Current capabilities of Scala DFA
Tracking relations
One cool thing about the IntelliJ DFA framework, on top of which we built our Scala DFA, is that it can track relations between variables, even if nothing else is known about them.
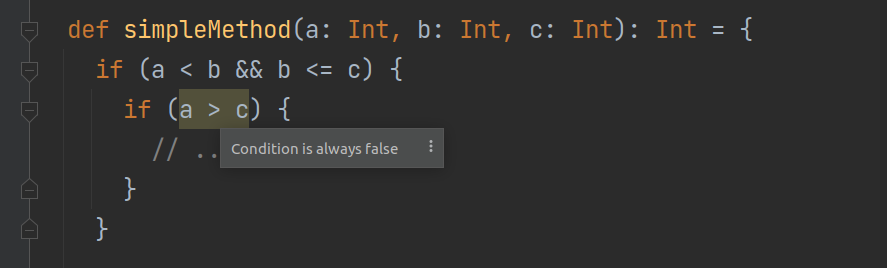

In the first example, dataflow analysis is able to figure out the relation between the otherwise unknown a and c by applying transitivity to the information it has collected from the outer condition. In the second one, it knows that inside the body of the else branch, !(a != b), which means a == b, and therefore a – b == 0.
A major advantage of this DFA is that many of its features easily extend to all types, not just simple ones like Int.
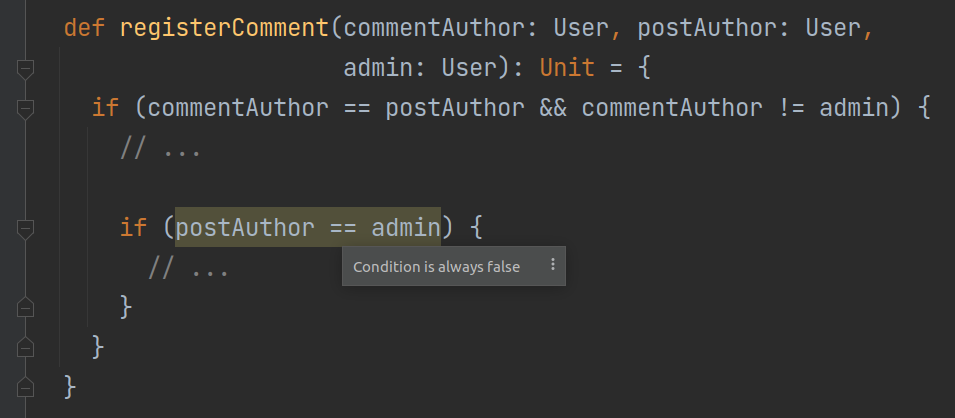
Support for known methods
A number of Scala-specific methods, including some standard math functions, receive their own special support in Scala DFA.
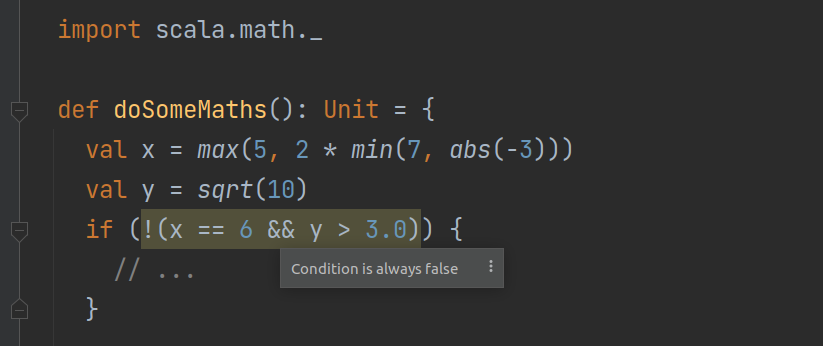
Support for Scala collections
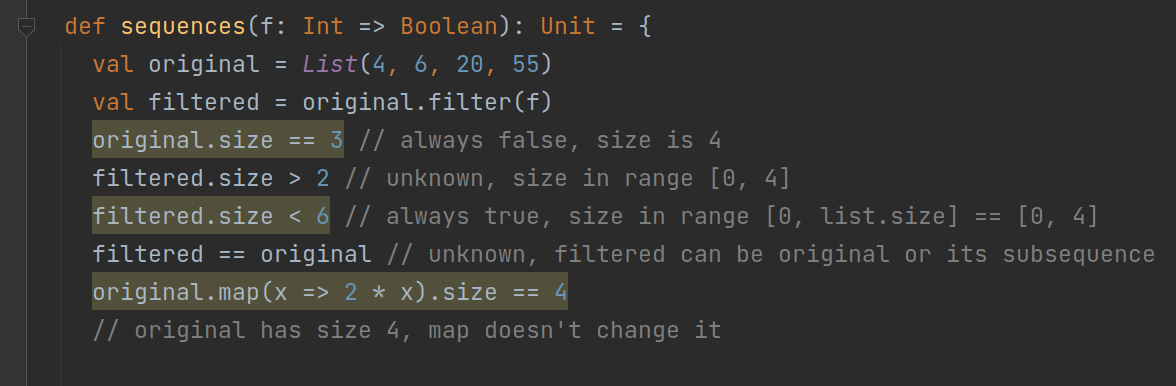
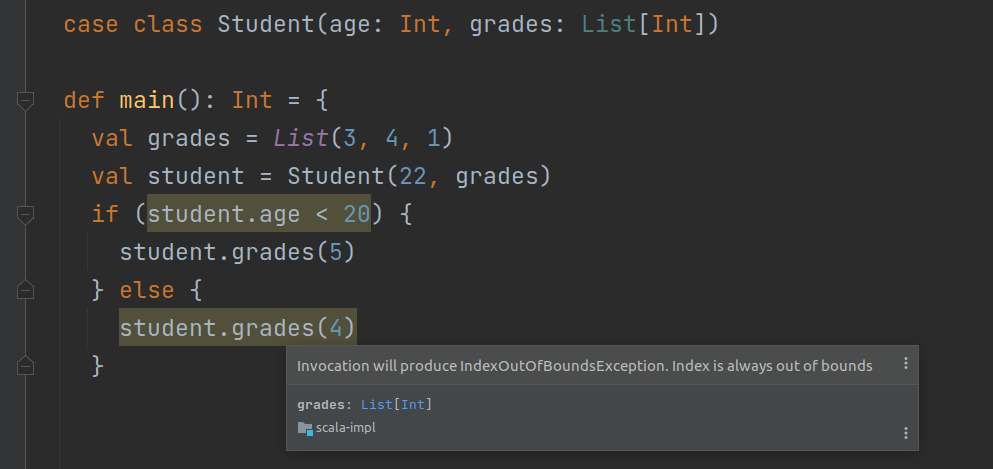
We have also added special support for Scala collections. Dataflow analysis can, for example, tell you that two sequences cannot be equal because they’re of different sizes, or that your collection access will produce an IndexOutOfBoundsException or NoSuchElementException.

Several of the most common sequence methods are supported as well.
Interprocedural analysis
Java DFA
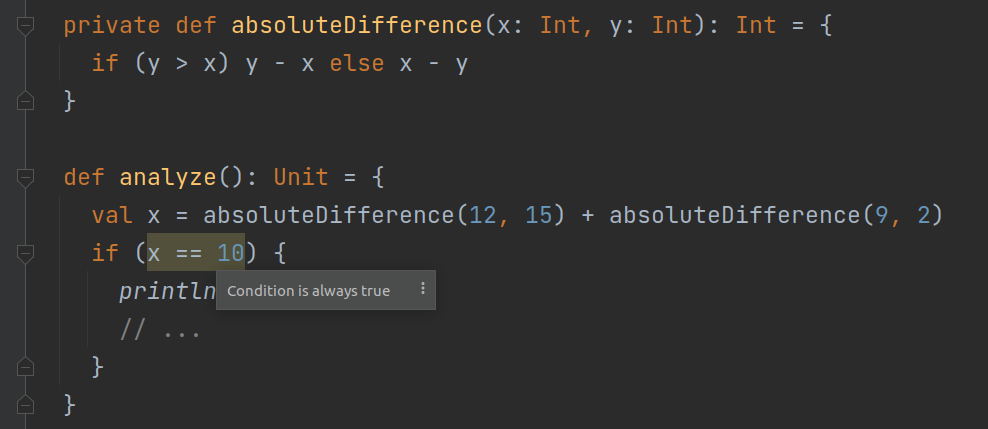
Dataflow analysis in IntelliJ IDEA analyzes the body of each method separately. As such, it inherently doesn’t support interprocedural analysis. This means that code like this won’t be fully analyzed in Java (the analysis won’t go inside absoluteDifference).

To be fair, the team responsible for Java DFA has been trying to overcome this limitation in many creative and efficient ways, like through static constant evaluation, getter inlining, contracts, etc., but in the vast majority of cases, it won’t do any interprocedural analysis.
Scala DFA
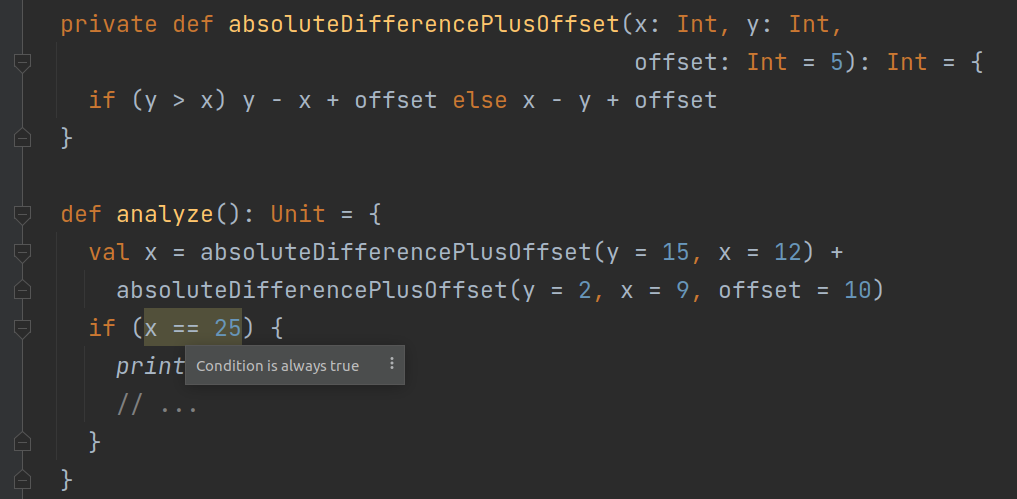
In Scala, a fundamentally functional language, this is a much more significant limitation, and we decided we needed to overcome it. We’ve laid a solid foundation for interprocedural analysis that, in the current state, supports two major features: interprocedural analysis for invocations of private and final methods (including methods in final classes and objects) and tracking class parameters. In effect, if we translate the above code to Scala, Scala DFA will go inside the external method and analyze it completely.
Another advantage of our analysis is that it supports all of the many kinds of Scala invocations and their syntactic sugars, like infix notation, apply methods, right-associativity, or named and default parameters. So it will still work if you do something like this.
As mentioned before, our DFA can also process and track class parameters.
Architecture and Invocation Info
The overall scope of the Scala DFA project is large. A lot has already been done, but the number of potential additions or improvements is even greater. That is why, from the very beginning, one of our main focuses was to lay a strong foundation that would make it easy to add new things in the future. Along the way, we encountered several major challenges, and many of the design ideas we came up with to overcome them are very interesting in their own right. Probably the best example of this is Invocation Info.
The challenge
The problem we faced was that, in Scala, a huge variety of things are some kind of method invocation. In Java, a method invocation is always either something.method(arg1, arg2) or Something.method(arg1, arg2). In Scala, both of these are present as well, but all of the following are also method invocations.
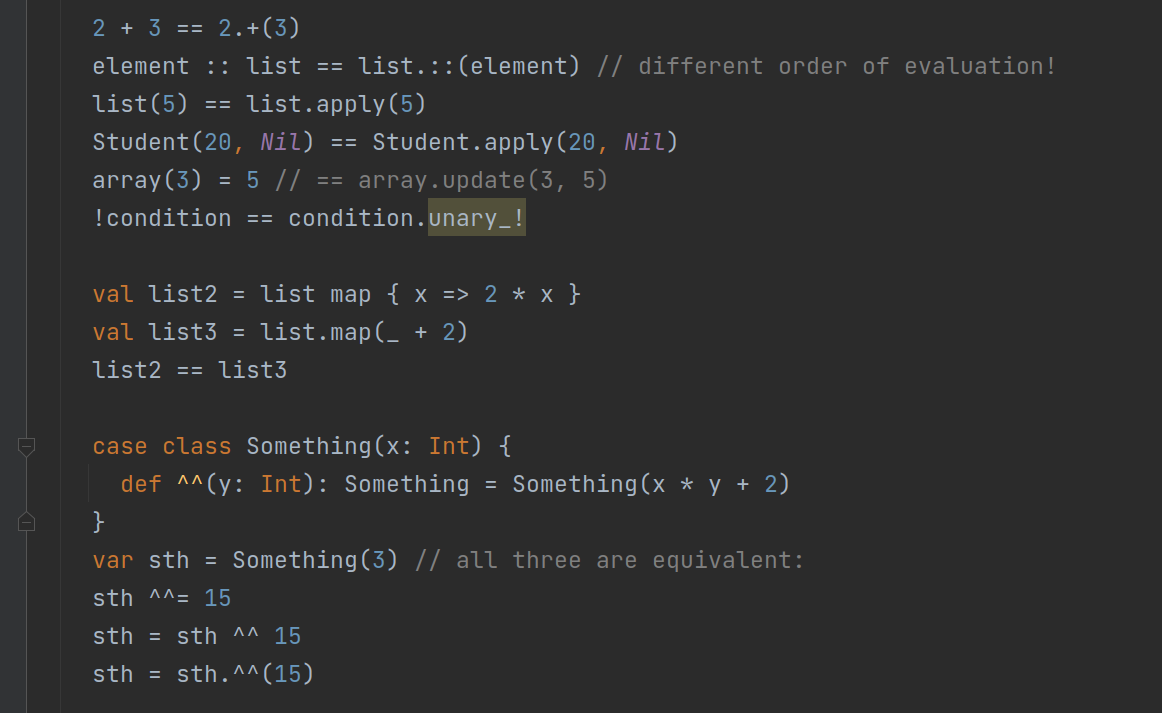
This is nice for a programmer who uses the language, but it is a nightmare for any compiler programmer, especially if you add named, default, and implicit parameters, multiple parameter lists, varargs, etc. Imagine needing to extract precise information about an invocation while having to remember and depend on every possible variant of this syntax in every possible place where we’re dealing with invocations.
The solution
This is why we designed and implemented an abstraction called Invocation Info. We have a factory that takes any possible invocation as its input, in any syntactic variant, and produces an InvocationInfo instance.
This class represents all possible Scala invocations in a standardized, convenient, and syntax-agnostic way. All sugared and desugared versions of equivalent invocations (like 3 + 8 and 3.+(8)) generate the same InvocationInfo. There are some fine details here, for example x :: list is almost equivalent to list.::(x) (because :: is right-associative), but argument expressions in Scala are always evaluated from left to right and this creates a slight difference in the semantics of these two expressions.
Invocation Info is designed to collect and offer all necessary information about the original invocation, including multiple argument lists, by-name arguments, evaluation order, this argument, etc.
The details of Invocation Info’s design and how it is used in the control flow builder and the analysis itself would make for another long and interesting article. But the key takeaway is that implementing all of that special support for various methods would have been impossible without it. We strongly believe that this tool and our control flow builder are so useful that they may find many different applications outside of dataflow analysis in the future development of the Scala plugin.
Learn more about DFA
I highly recommend watching the IntelliJ IDEA Conf talk by Tagir Valeev, which summarizes how our dataflow analysis in IntelliJ IDEA works behind the scenes, what it can do, and how we manipulate it to extract as many useful insights and high-quality inspections as possible.
If you’re curious about what kinds of bugs dataflow analysis can help you find, read Tagir’s JetBrains Blog article, where he discusses lots of real-life examples.
Credits
Special thanks to Tobias Kahlert who supervised my project, in particular for a great theoretical and practical introduction to the DFA field and many really fruitful design discussions and ideas.
Achieving such good results also wouldn’t have been possible if I hadn’t built on the existing, robust, and extensible IntelliJ DFA framework. Most of it has been created by Tagir Valeev, with whom I’ve also had several helpful discussions throughout my project. Tagir has also been implementing DFA for Kotlin, which was helpful for me as a reference in the early stages of my work.
Feedback
We need your feedback! If you encounter any bugs in this feature, please report them to our YouTrack. If you have any questions, feel free to ask them in our Gitter.