

JetBrains AI
Supercharge your tools with AI-powered features inside many JetBrains products
使用 Kotlin 构建 AI 智能体 – 第 5 部分:让智能体学会忘记

本系列的前几篇文章:
- 使用 Kotlin 构建 AI 智能体 – 第 1 部分:极简编码智能体
- 使用 Kotlin 构建 AI 智能体 – 第 2 部分:深入探讨工具
- 使用 Kotlin 构建 AI 智能体 – 第 3 部分:受到密切观察
- 使用 Kotlin 构建 AI 智能体 – 第 4 部分:委托和子智能体
智能体最终会耗尽上下文。这种情况发生时,智能体会崩溃,你会在任务进行到一半时丢失所有数据。
从第 1 部分以来,我们运行的都是 GPT-5 Codex 。它在 SWE-bench Verified 上的得分为 0.58。接下来我们尝试了 Claude Sonnet 4.5,它的得分为 0.6,且大多数任务的运行速度更快。但复杂问题会更快耗尽 Claude 的 200K 上下文窗口。
你很可能也会切换模型,以追求更高的性能、更低的成本,或者实现本地运行。有时这意味着上下文窗口更小,尤其是对于受昂贵内存限制的本地模型。但即便是最大的上下文窗口,在处理复杂且冗长的任务时也会失败。你不能只是一味地购买上下文。
问题在于,智能体会保留所有数据:每一个文件、每一条命令输出、每一条搜索结果、每一条用户消息。最终会没有任何剩余空间。
因此,我们要采用压缩技术。但并不是仅在空间不足时直接丢弃旧消息的那种压缩。考虑一下把任务交接给另一位开发者的情况。你不会把所做的一切都逐字记录下来交给对方。你只需告诉他们目标是什么、你修改了哪些文件、哪些操作起作用了、哪些没有。这就是智能压缩:保留继续工作所需的上下文;丢弃冗长的历史记录。
我们来了解一下如何在 Koog 中实现智能压缩。首先,我们需要了解自第 1 部分以来 strategy = singleRunStrategy() 在做什么。在这里,你会看到策略如何控制智能体循环,以及如何进行修改才能创建你自己的流程。我们将深入了解 singleRunStrategy(),然后构建一个可以自动压缩的版本。
该策略行有什么功能
在之前的部分中,你构建了一个编码智能体。你为它提供了各种工具,以及这行代码:
strategy = singleRunStrategy()
在这里,策略是运行智能体循环的代码。所有策略共用相同的核心元素:调用 LLM、执行工具、返回结果,然后重复这一过程。但各个策略的差异在于其停止时间和迭代之间执行的操作。
singleRunStrategy() 是可实现的最简单版本。只要 LLM 返回工具调用,它就会一直迭代。也就是说:调用 LLM → 返回工具调用? → 执行 → 再次调用 → 返回文本? → 已完成.
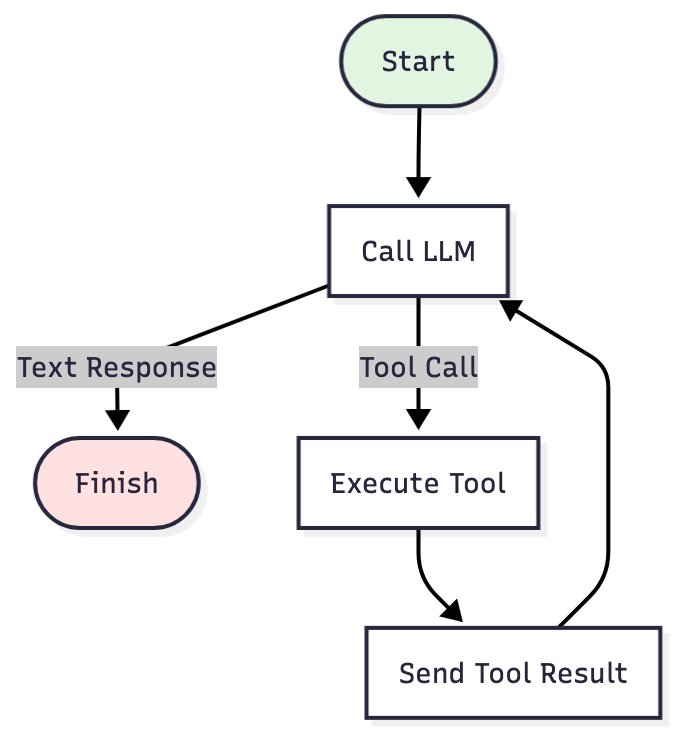
对于简单任务,这种方式很适用。但处理复杂问题时,历史记录会不断增多。每条命令输出、每个读取的文件、每个搜索结果,都会保留在上下文中。最终会超出限值,导致任务中途崩溃。
我们需要的策略是:它会运行相同的循环,但还会检查历史记录大小,并在历史记录过大时进行压缩。
添加压缩
我们要替换此流程:
strategy = singleRunStrategy()
对于此策略:
strategy = singleRunStrategyWithHistoryCompression()
循环不变,但目前在 Execute Tool 和 Send Tool 结果之间有一个检查点。每次工具执行后,策略都会询问:
- 检查:历史记录大于阈值吗?
- 如果大于阈值? 压缩历史记录:提取重要事实。丢弃剩余信息。
- 如果不大于阈值? 照常继续。
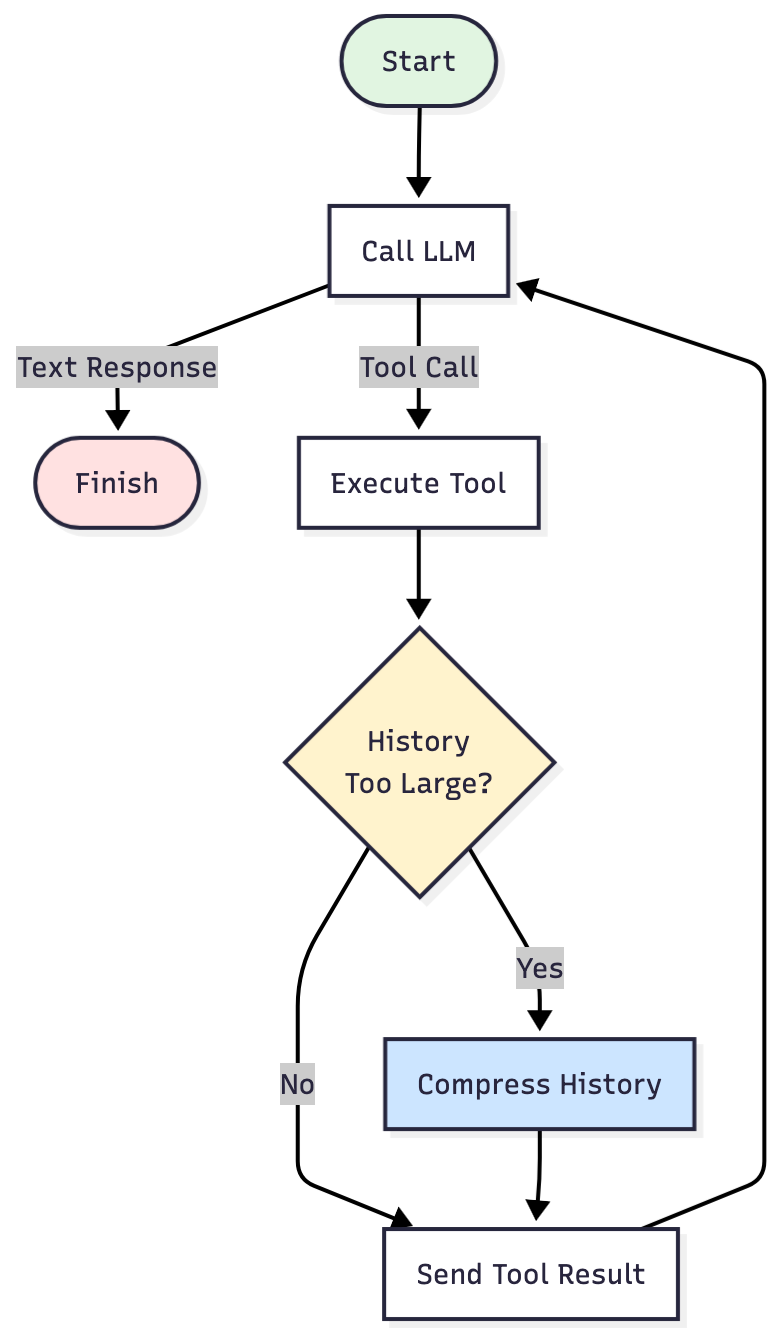
正是这个检查点,让你的智能体能在更严格的 token 预算范围内完成长时间运行的任务,从而避免出现“超出上下文窗口”的错误。
但你必须对该检查点进行配置。策略无法猜到历史记录何时过大,也无法确定对你的任务至关重要的事实。你必须告诉它两件事:何时压缩,以及保留哪些信息。
何时压缩
先设置阈值 – 触发压缩前允许的最大消息数或字符数:
val CODE_AGENT_HISTORY_TOO_BIG = { prompt ->
prompt.messages.size > 200 || prompt.messages.sumOf { it.content.length } > 200_000}
为什么设置这些数字? 在观察到出现错误的位置后,我们尝试了不同的阈值。

此智能体的 token 数达到 220K 后崩溃了。Claude 的上限是 200K 个 token。我们需要在达到该限值之前进行压缩。
我们将压缩触发条件设为 200 条消息或 200,000 个字符,以先达到者为准。请注意,代码统计的是字符数,而非 token 数。两者是不同的,但该阈值能确保我们不超过 token 限值 – 该限值足够高,可以避免过度压缩,足够低,则可以防止超出限值。
这些数字不是固定的。如果你的智能体较早达到限值,则可以降低阈值。即便如此,如果在任务完成之前超过了阈值, 请提高阈值。选择取决于你的用例:文件大小、消息长度、工具输出的详细程度、任务复杂度。不断试验,找到最佳方案。
保留的信息
你已设置压缩的触发条件。现在,选择要保留的信息。
有两个选项:信任 LLM 来决定重要的信息,或明确告诉它要提取哪些信息。
选项 1:信任 LLM 来总结
LLM 使用 WholeHistory 决定重要的信息:
compressionStrategy = WholeHistory
压缩触发时,Koog 会让 LLM 为整个对话历史生成一段 TL;DR。
压缩前:
- 达到阈值前的所有消息:系统提示、用户消息、助手回复、工具调用、工具结果。
压缩后:
- 系统提示(保留)。
- 第一条用户消息(保留,以便智能体记住最初目标)。
- 一条 TL;DR 总结消息(由 LLM 生成)。
权衡:这种方式简单快捷,但你要信任 LLM 来确定哪些信息重要。有时 LLM 能精准保留适当的详细信息。有时则会漏掉关键信息。
选项 2:明确告诉 LLM 要提取哪些信息
这种方式不会告诉模型总结所有信息,而是使用 RetrieveFactsFromHistory 明确指定要提取的事实:
compressionStrategy = RetrieveFactsFromHistory( Concept(...), Concept(...), ... )
运作方式:
你定义 Concept 对象:智能体必须记住的关于你的任务的特定问题。压缩触发时,Koog 会针对每个概念进行一次 LLM 调用,每次都发送完整对话历史记录,且只询问这一个问题。
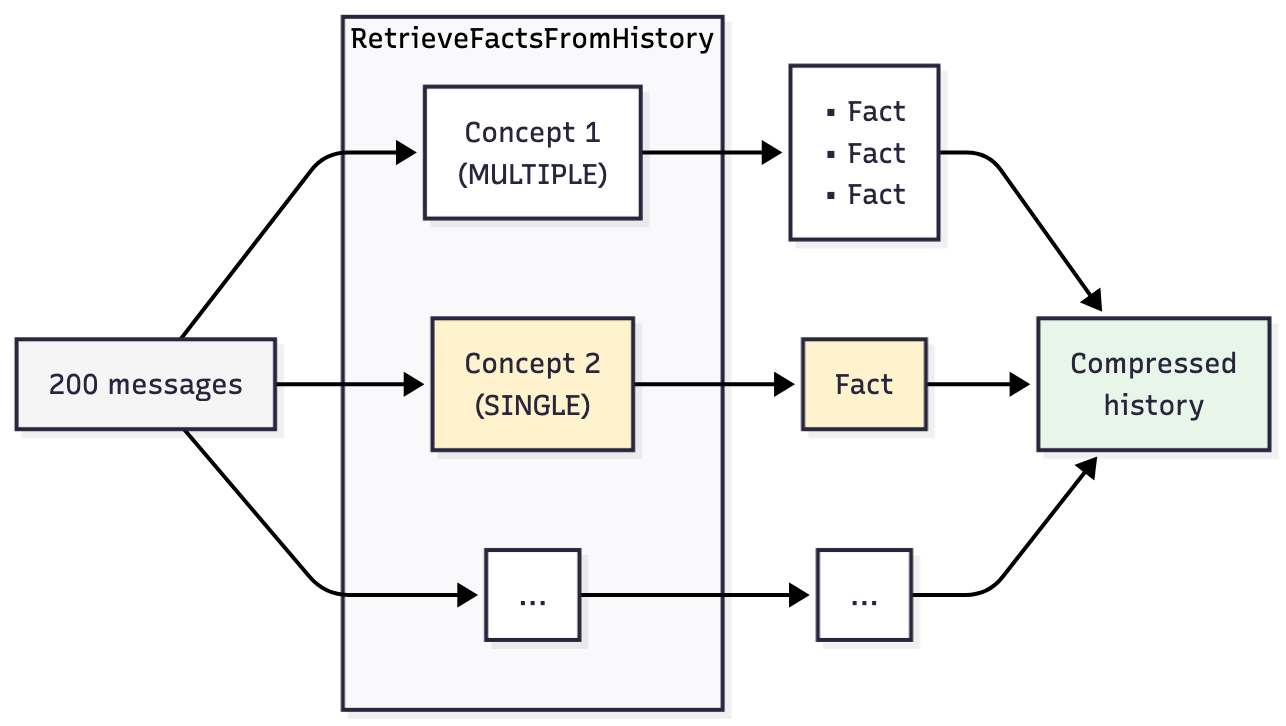
为什么要单独调用? 如果一次性询问多个问题,LLM 给出的回答会不尽人意。我们在测试时发现了这一问题:将八个概念捆绑到一个提示中,返回的部分回答很模糊或不完整。如果一次问一个问题,每次的回复都更加可靠。
定义概念
每个 Concept 实例都包含三部分:
keyword:日志标签description:LLM 应回答的实际问题或指令factType:预期的答案格式MULTIPLE表示列表SINGLE表示单个值
Concept(
keyword = "project-structure",
description = "What is the project structure?",
factType = FactType.MULTIPLE
)
选择合适的概念
对于我们的编码智能体,关键问题是:哪些信息一旦丢失,就会强制智能体从头开始?
如果压缩丢失关键信息,会发生以下情况:
- 智能体会将同一文件打开两次,就像之前从未见过该文件一样。
- 智能体会重写已经存在的测试。
- 智能体会偏离你最初分配给它的任务。
每一次失败都揭示了压缩必须保留的信息:
- 重新探索文件 → 你需要
project-structure概念。 - 重做已完成的工作 → 你需要
important-achievements概念。 - 失去方向 → 你需要
agent-goal概念。
我们的编码智能体概念
在 SWE-bench-Verified 上进行测试时,我们最终得出了八个概念。以下是其中三个概念:
val CODE_AGENT_COMPRESSION_STRATEGY = RetrieveFactsFromHistory(
Concept(
"project-structure",
"What is the structure of this project?",
FactType.MULTIPLE
),
Concept(
"important-achievements",
"What has been achieved during the execution of this current agent?",
FactType.MULTIPLE
),
Concept(
"agent-goal",
"What is the primary goal or task the agent is trying to accomplish in this session?",
FactType.SINGLE
),
...
你的智能体可能需要不同的概念。目标不是复制这份清单,而是识别出你的智能体继续工作所需的状态,并定义能够保留这些信息的概念。
使用哪个模型
就像子智能体(第 4 部分)一样,你可以为流程的不同环节使用不同的模型。借助 retrievalModel 形参,你可以指定由哪个 LLM 处理历史记录压缩。此形参为可选形参 – 如果不指定,压缩会使用你的智能体的主要模型。
retrievalModel = OpenAIModels.Chat.GPT4_1Mini
以下是编码智能体策略的完整配置:
strategy = singleRunStrategyWithHistoryCompression(
config = HistoryCompressionConfig(
isHistoryTooBig = CODE_AGENT_HISTORY_TOO_BIG,
compressionStrategy = CODE_AGENT_COMPRESSION_STRATEGY,
retrievalModel = OpenAIModels.Chat.GPT4_1Mini
)
)
三个形参:何时压缩 (isHistoryTooBig)、保留哪些信息 (compressionStrategy),以及哪个模型执行操作 (retrievalModel)。
结论
此时,你的智能体可以运行时间更长的任务,而不会达到上下文限值。压缩问题已解决。当空间不足时,智能体不会崩溃,而是会压缩其历史记录,保留决策和结果,同时丢弃冗余输出,并在你拥有的 token 预算内继续工作。
在本系列中,我们先在第 1 部分中介绍了基本编码智能体。后续又补充介绍了工具、可观察性、子智能体以及历史记录压缩。这五部分提供了使用 Kotlin 构建能够在实际模型约束条件下正常运行的 AI 智能体所需的一切信息。
如果你想继续构建和实践这些模式,规划和推理是值得探索的有趣方向:智能体如何在多轮交互中决定采取何种行动,以及如何拆解复杂问题。对于这部分内容,我们在这里未做介绍,但一旦你将这些部分都运行起来,这部分内容会是良好的做法。
完整代码位于 GitHub 上。如果你遇到任何问题,请留言。我们将随时为你提供帮助 😊
本博文英文原作者:




