

Big Data Tools EAP 9: Hadoop, Azure, S3 Compatible Storages, ORC, Avro, and More

It’s been a while since our last update, but we think the wait has been worth it. We’re thrilled to announce a new update, which is perhaps one of the biggest since the plugin was first released last year. This update introduces many new features and also brings a variety of important bug fixes.
Hadoop
First and foremost, we’re excited to introduce the Hadoop integration – a tool window that allows you to connect to a Hadoop cluster and monitor nodes, applications, and jobs. Even though this was one of the first features we put on our list when we started working on the plugin, finishing it has taken us a while.
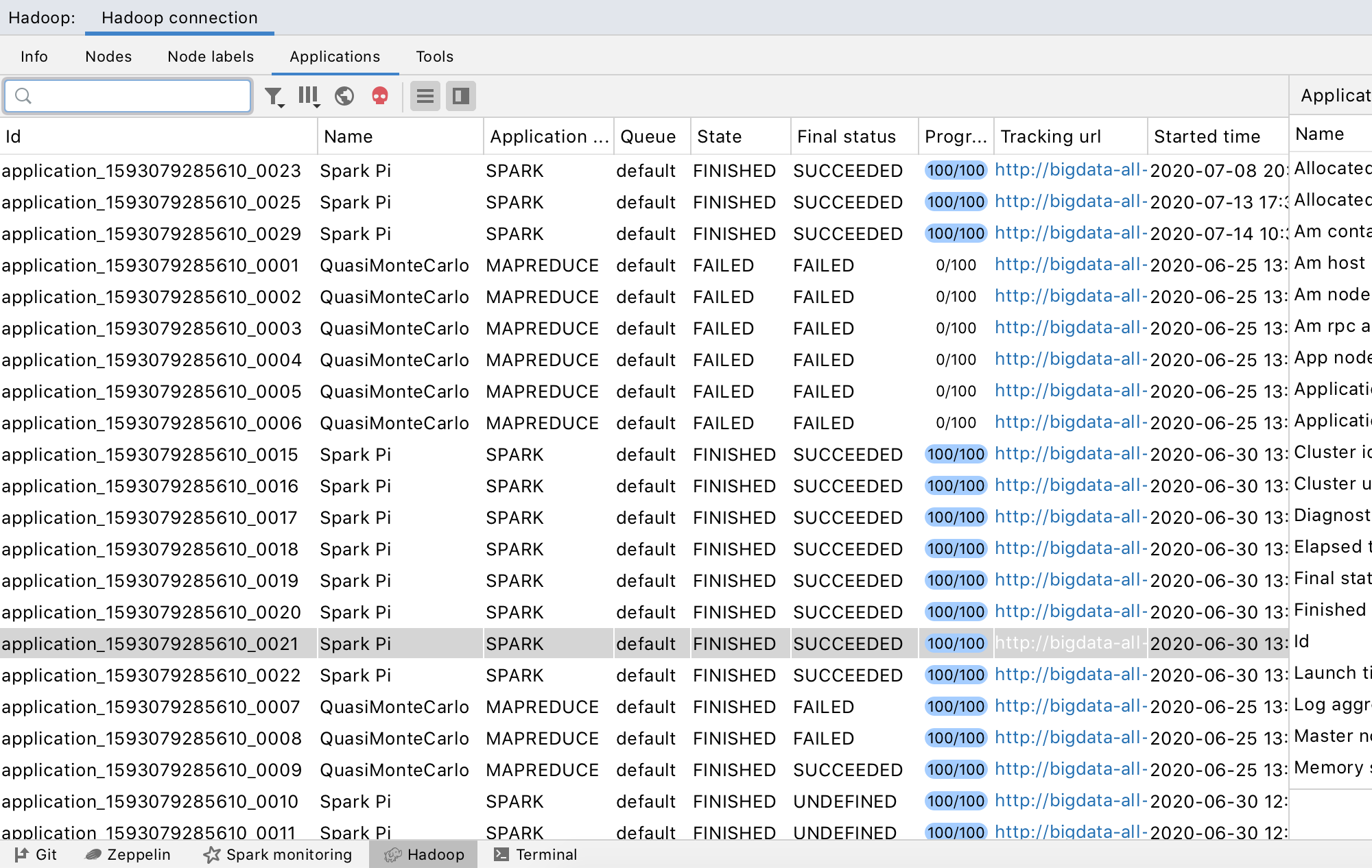
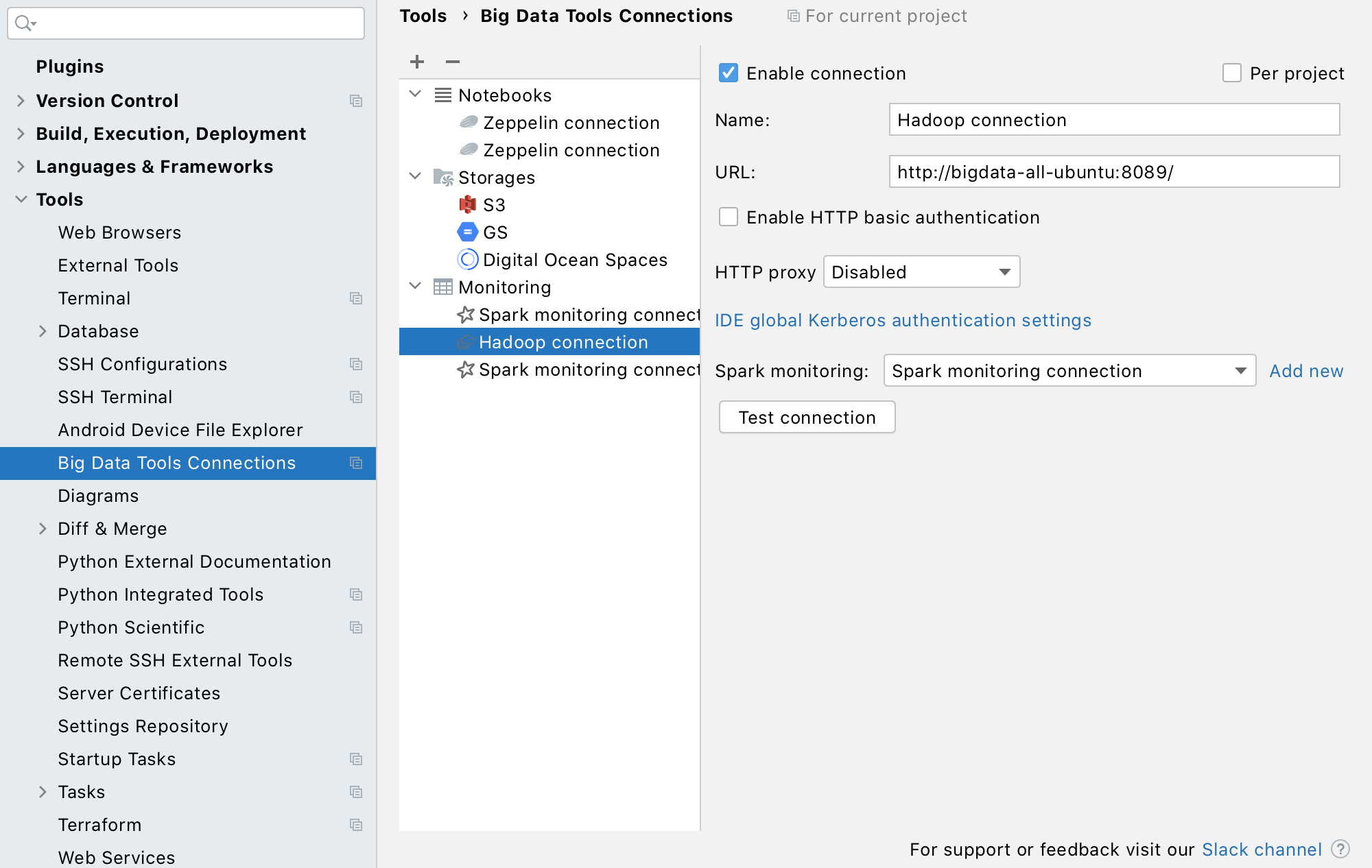
The tool window is quite similar to Spark monitoring and is actually integrated with it. You can open every Hadoop application that is also a Spark job in the Spark tool window to see its Spark-specific information. This feature requires you to configure the corresponding Spark connection. If it’s not configured, the IDE will prompt you to do so automatically. To associate a Hadoop connection with a Spark connection,you must specify the Spark connection in the Hadoop connection settings:
Microsoft Azure, Digital Ocean, Linode, Minio, and Custom S3 Endpoints
Another very important development is the introduction of support for more distributed file storage systems, including Microsoft Azure, Digital Ocean, Linode, and Minio. You can now also use custom S3 endpoints (for working with data stored on your servers).
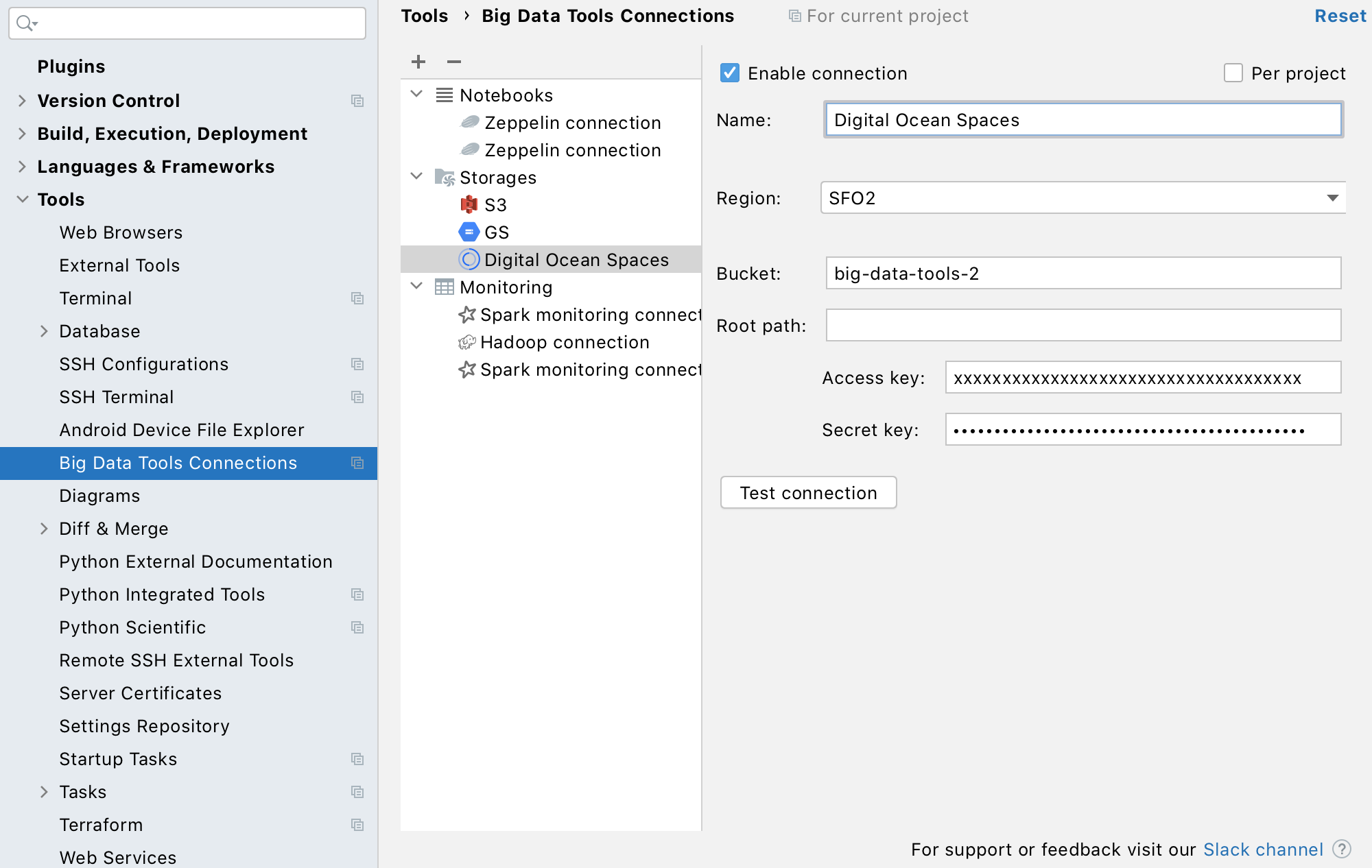
You can now browse and manage (preview, upload, download, and delete) folders and files on the supported distributed file storage systems..
ORC and Avro
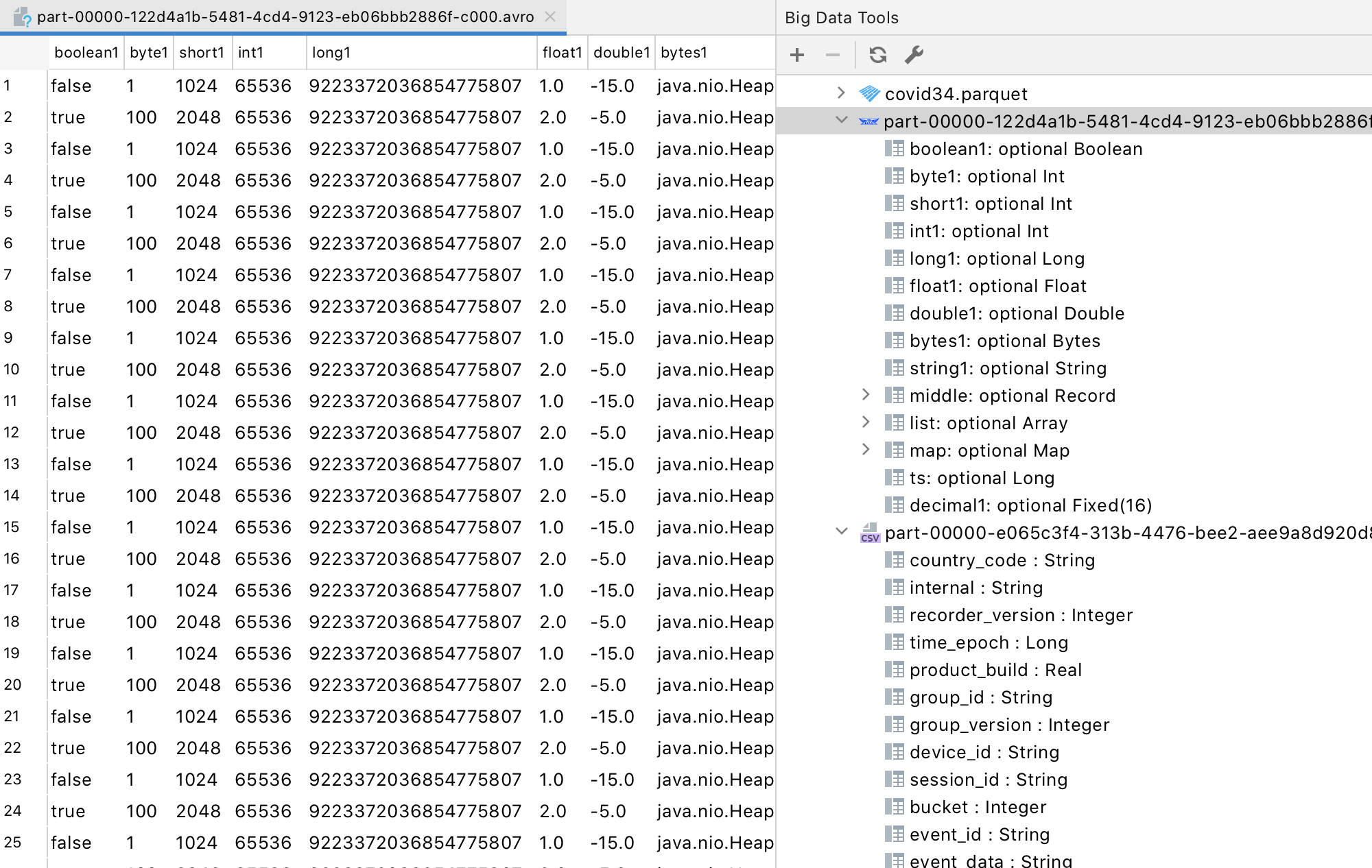
Large datasets often require that the data is stored in an optimized way. In these cases, columnar storage formats such as Parquet, Avro, and ORC are often useful. Prior to this update, the plugin supported only Parquet files. With this update, you can now also work with Avro and ORC files, which can be stored either locally or in a distributed file storage system.
You can preview the schema and content of these files without actually opening them. And of course, you can open the actual files, search through their content, and dump parts of them.
Smarter Zeppelin Coding Assistance
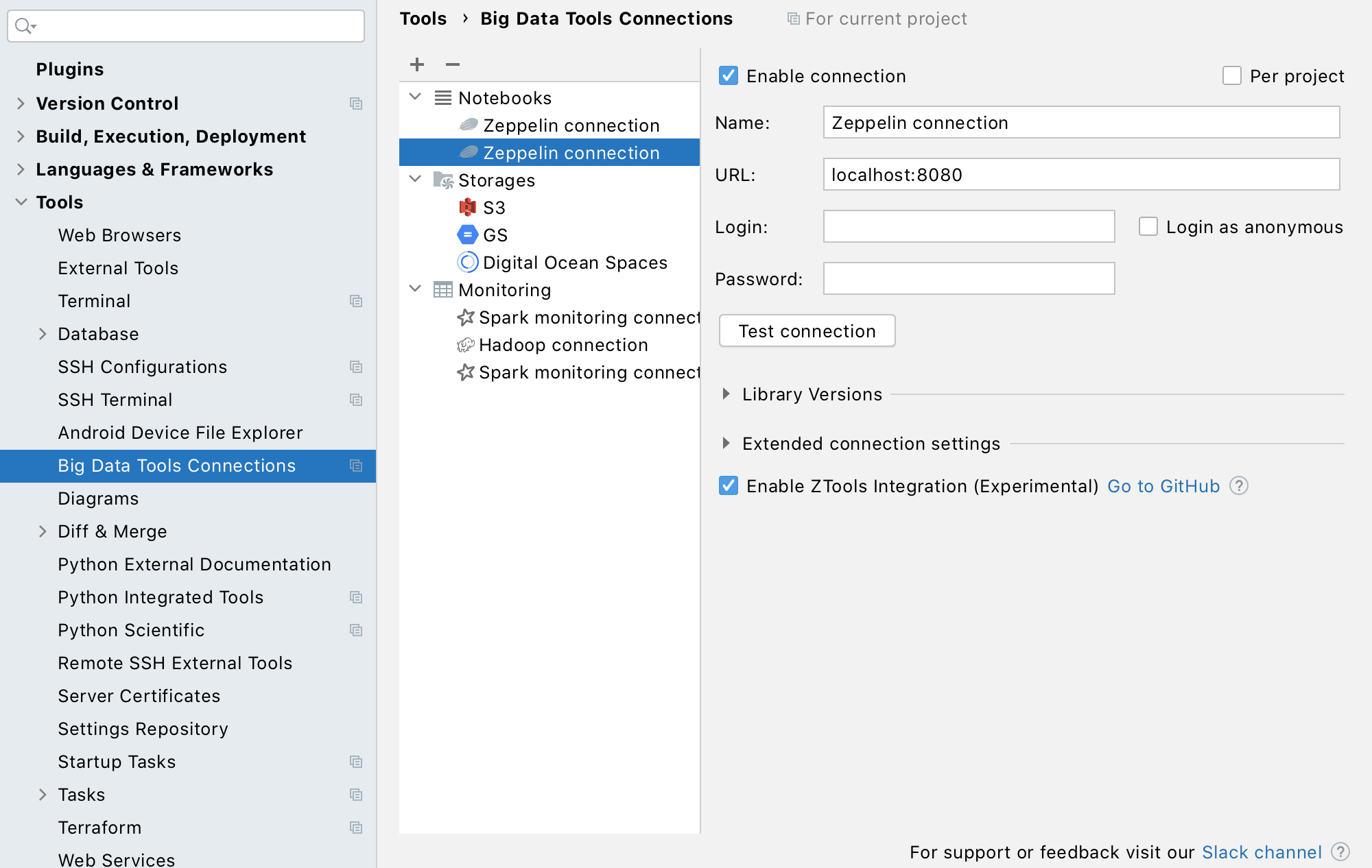
Here’s one more thing that can make working with Zeppelin notebooks a lot more enjoyable – ZTools. This is a Java library that establishes a protocol between the Zeppelin server and the IDE, and provides important runtime information the IDE needs in order to offer smart coding assistance. Enabling this dependency with the server gives you much smarter code completion along with other code insight features, such as information about local variables for the current Zeppelin session.
If you have permission to load dependencies, you can simply enable the ZTools integration in the Zeppelin connection settings:
The ZTools integration also provides runtime information on the schemas of tables, views, and even dataframes.
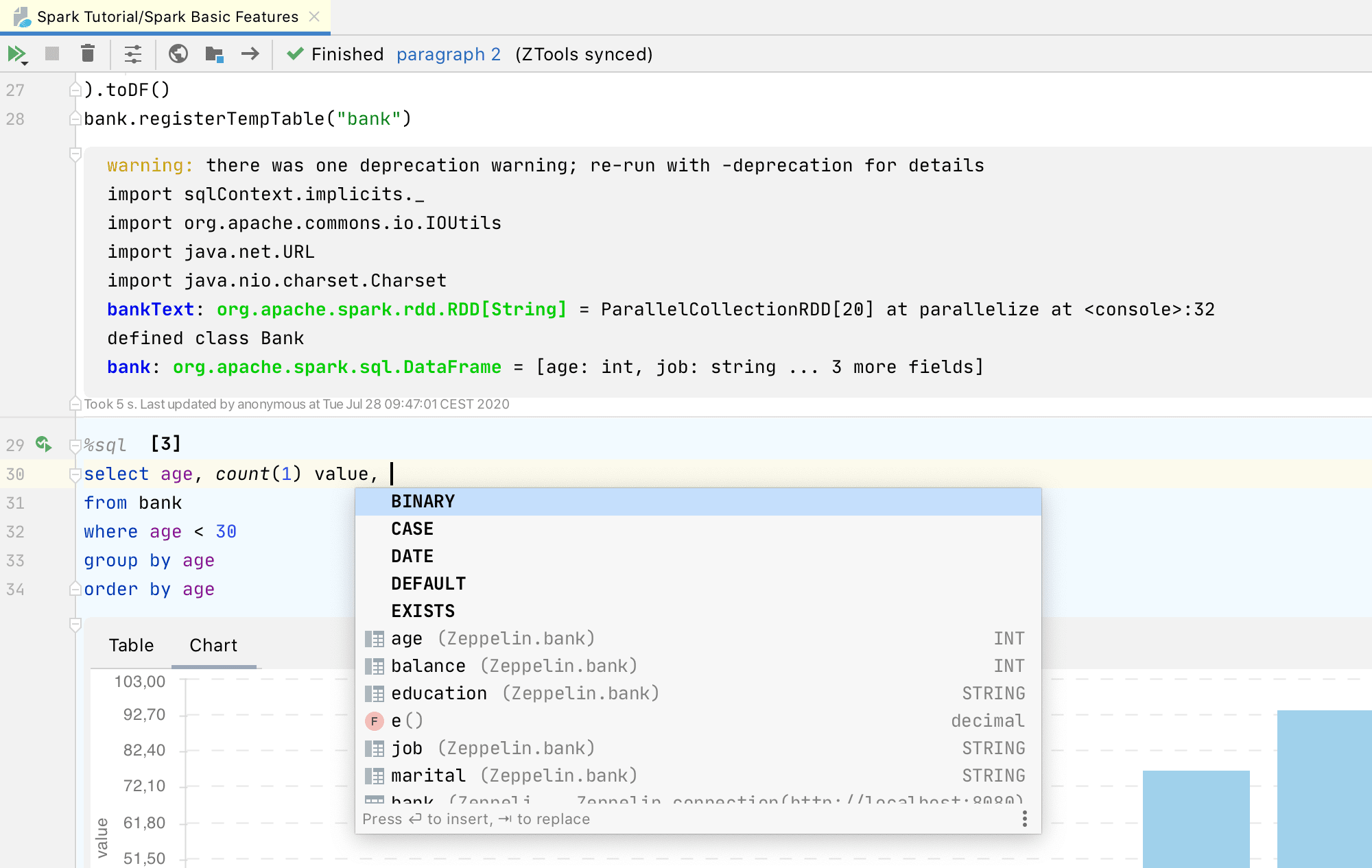
If you work with Spark SQL code, the Big Data Tools plugin will provide you with the exact names of columns in code completion suggestions, and will check that the names of your columns do not contain any errors (e.g. references to columns that do not exist):
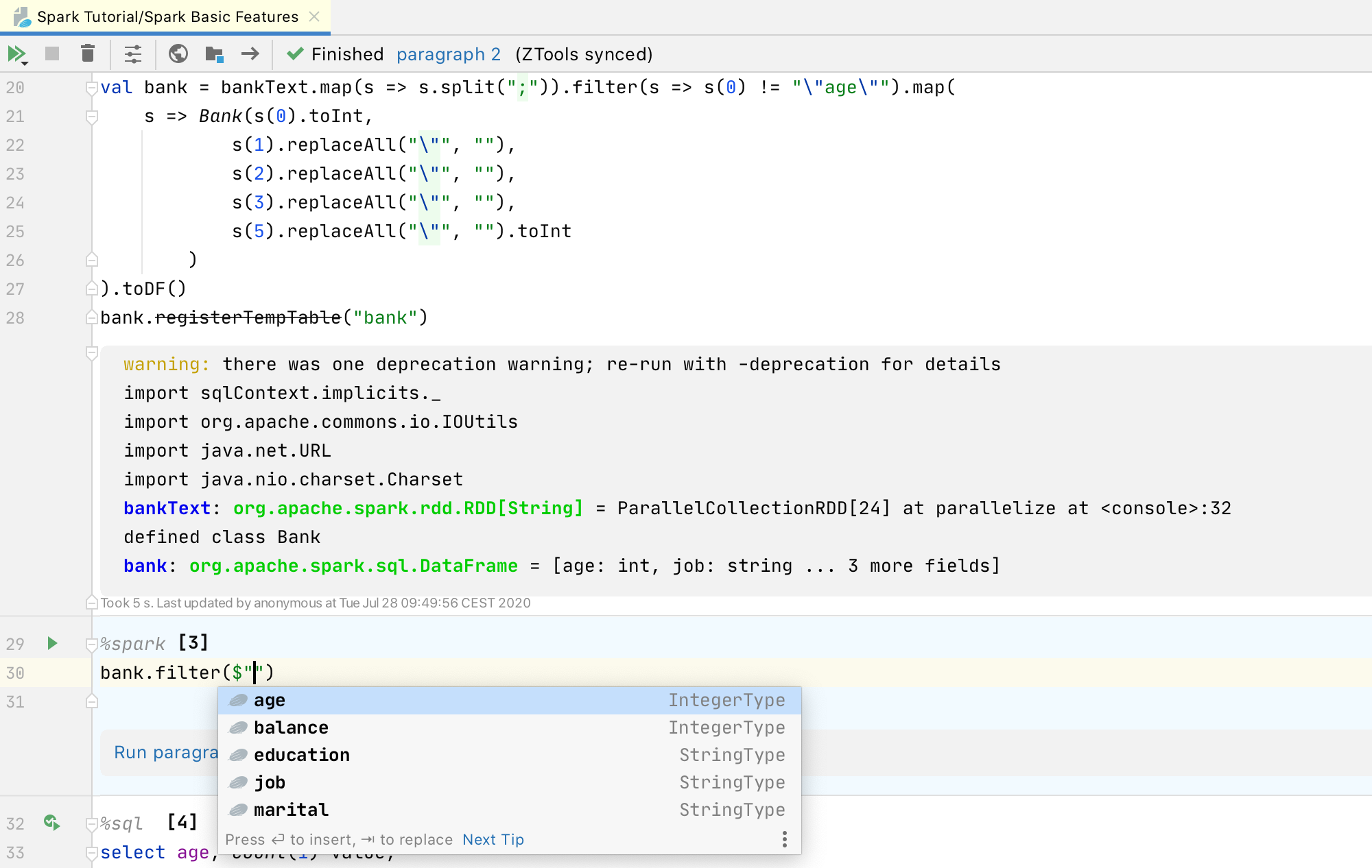
This also works for dataframes when you invoke code completion in Spark’s Scala code:
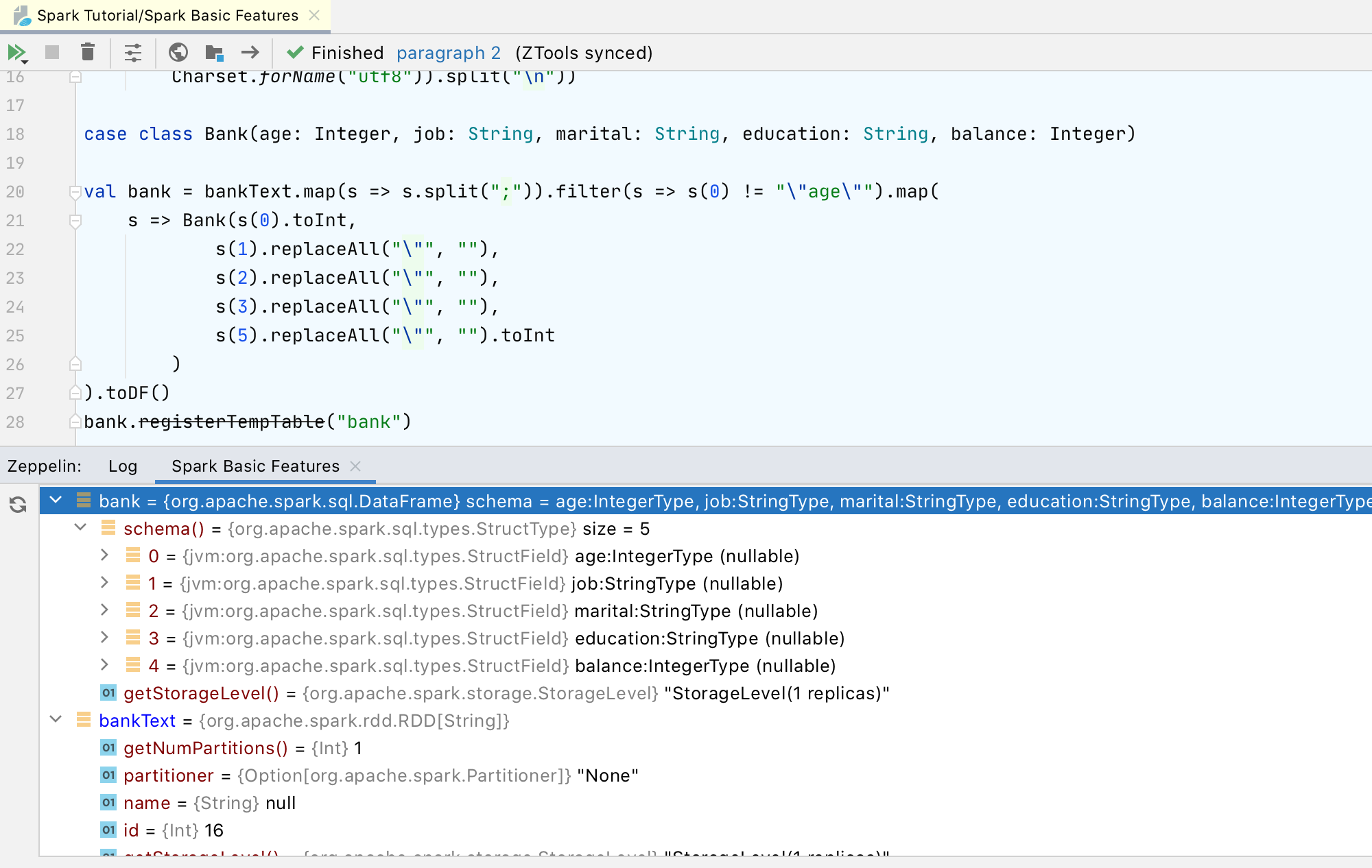
There is also a new tool window called “Variables” that lets you see all the local variables for the current session and introspect their values:
Note that in order to enable the ZTools integration, you must have permission to load Zeppelin dependencies. If you don’t have this permission, the Zeppelin server administrator must add the dependency on their side.
The current version of the dependency is available in our Maven repository. The source code and more details on the ZTools library can be found in its GitHub repository. We also plan to integrate this library with the Scala Shell.
The Zeppelin integration is not yet available for DataGrip or PyCharm, but we’re working to make it available very soon.
Other improvements
Besides the major features mentioned above, the IDE brings a lot of small improvements and bug fixes.
Here’s a list of the most notable bug fixes:
- [BDIDE-860] A self-signed certificate error for S3.
- [BDIDE-912] Empty strings are displayed instead of folder names in HDFS on Windows.
- [BDIDE-889] Encoding issues related to displaying column names for CSV files.
- [BDIDE-902] Shortcut for creating a new notebook not working.
- [BDIDE-874] Endless file downloading progress if the CSV file column list is expanded.
- [BDIDE-884] Performance issues when rendering notebooks if a specific font is used.
The complete list of changes is available in the release notes.
That’s it for today. If you haven’t already done so, go ahead and update the Big Data Tools plugin from your IDE – just click Help | Check for Updates. And if you haven’t tried the plugin at all yet, make sure to go to Settings, click Marketplace, type “Big Data Tools”, and click Install.
Finally, and most importantly, do you have any ideas for features you would like our team to add to the plugin? Have you encountered situations where the plugin doesn’t work? Please let us know about these things on our issue tracker or share them in our Slack workspace!
The Big Data Tools team
The Drive To Develop
