

Big Data Tools
A data engineering plugin
Why We Need Hive Metastore

Everybody in IT works with data, including frontend and backend developers, analysts, QA engineers, product managers, and people in many other roles. The data used and the data processing methods vary with the role, but data itself is more often than not the key.

— “It’s a very special key, meant only for The One”
The Matrix Reloaded
— “What does it unlock?”
— “The future”
In the data engineering world, data is more than “just data” – it’s the lifeblood of our work. It’s all we work with, most of the time. Our code is data-centric, and we use the only real 5th-generation language there is – SQL. (5th-generation languages are those that let you define what you want to achieve and the language itself solves the problem for you.)
There is a huge “but”, though. Data is cool, working with it is exciting, but accessing it is often cumbersome. Data is stored in a multitude of different formats, in different locations, and under different access restrictions, and it is structured in very different ways. We must be aware of them all, query them all, and sometimes even join them in our queries.
So, we need one place where we can manage all the information we have about our data stores. And this place is Hive Metastore.
Hive Metastore
Hive Metastore was developed as a part of Apache Hive, “a distributed, fault-tolerant data warehouse system that enables analytics at a massive scale”, per the Amazon website. This basically means you can query everything from one place.
Hive achieves this goal by being the storage point for all the meta-information about your data storages. With its HSQL dialect (which has some limitations compared to regular SQL – but also some advantages), Hive allows you to project any data structure to a structure that is suitable for querying with SQL.
One slightly confusing thing about Hive Metastore is that, even though it has “Hive” in its name, in reality it is separate from and completely independent of Hive.
Since we’re talking about components, let’s explore Hive Metastore’s architecture.
Architecture
The actual architecture of Hive Metastore is quite simple:
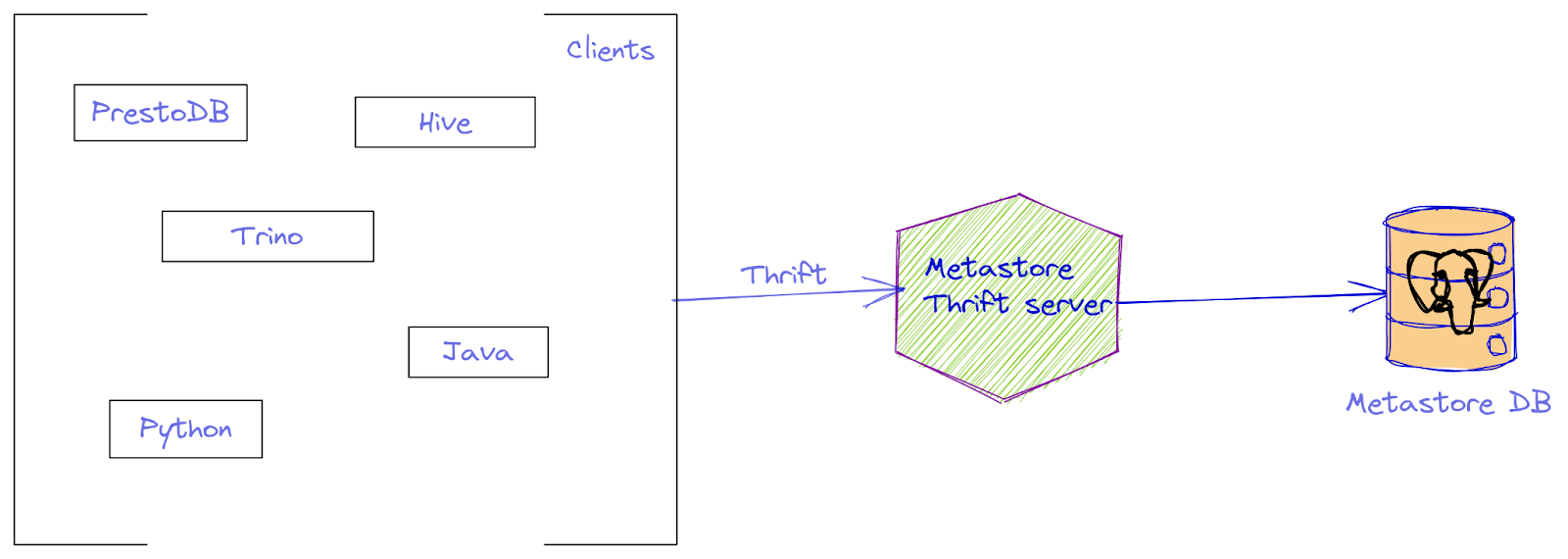
Since data is projected to SQL, information about it is very easy to map to a simple relational structure, almost in an entity-attribute-value kind of representation. For example, entity “table” – attribute “name” – value “clickstream”.
Hive Metastore projects types from an underlying store to supported HSQL types, and stores information about the location of the underlying data. This data is stored in the metastore database, which is usually MySQL, Postgres, or Derby.
But the database itself is only an implementation detail. Its schema is more or less fluid, and it changes over time and without any prior notice. (Well, you could keep track of the changes if you followed the hive-dev mailing list, but few people do.) This database serves only one purpose: to provide the Thrift server with data.
The Metastore Thrift server is the main entry point for its metastore clients. Let’s focus on Thrift for a moment. Thrift is an RPC protocol initially created by Facebook and now maintained by the Apache Software Foundation. I would choose Thrift over the very popular gRPC any day, for several reasons:
- It has typed exceptions. So you don’t just get a random exception from inside your RPC, but rather you can actually understand what’s going wrong.
- It has a rich standard library (if a set of predefined types can be called that).
- Like gRPC, it supports many languages, but in my opinion, Thrift’s generator produces much nicer code than gRPC’s generator does.
This Thrift protocol was developed by Facebook to meet the needs of its Big Data ecosystem, but that also makes it a perfect fit for Hive, and, in my opinion, for other ecosystems as well.
So, getting back to the Thrift server, it’s a fairly simple application with an API that lets you obtain the necessary information about the data sources that Hive Metastore is aware of. It’s typed, but you can still use it with dynamically typed languages like Python, which Thrift’s code generator also supports.
And the next part of the architecture is… there are no more parts! All the clients including Hive itself communicate only with the Hive Metastore thrift server. The Thrift server is so simple that we can spin it up with a single docker container for the Thrift server (assuming that we’ll use Derby as the Metastore database). Of course, it’s a rare setup for a production environment, but it comes in very handy for experiments.
Usage by third-party systems
Here comes the best part: Many of the new systems only need to know about the Thrift server and communicate with it. They don’t need Hive or any other query engine to access the data.
One example of such a system is Trino – a spin-off from PrestoDB being developed by a separate company called Starburst. When using Trino, you don’t need to have Hive installed. Having just Hive Metastore is enough. Trino is very simple to spin up in a Docker container, too – just one command is all it takes.
The same is true for lakeFS, a system that lets you work with a data lake using a Git-like interface. This can be very useful when you need to switch between different data sources quickly, as well as in many other situations. And with Hive Metastore’s help, integration is quite straightforward.
Criticism
Like most things, Hive Metastore isn’t perfect. Oz Katz from lakeFS wrote a great post on the limitations of Metastore. He sees three issues with Metastore:
- “Scaling Thrift.” While Thrift is not as widespread as HTTP, it’s built on top of HTTP, so I would argue that many popular tools will work with it just fine (such as HAProxy). But it’s true that you can’t just catch a random message from Thrift traffic and understand what it’s talking about. I agree this is a slight drawback.
- “Metastore is just a thin layer over RDBMS.” If I understand the argument correctly, very big Hive tables will create headaches while working with Metastore, owing to Hive’s partitioning scheme and the downsides of relational databases. Again, that’s a valid criticism, but here I should note that we actually don’t have to use Metastore with Hive. We can use it with different tools, too, and we don’t have to use partitioning either if we have other solutions that meet our needs.
- “Leaky abstractions.” This is a very valid criticism that’s hard to argue with. Still, I’m not aware of any abstractions that don’t leak at all. Yes, Metastore might be leakier than some others, but sometimes you might be able to turn this problem into an opportunity to fine-tune things when you need to. Granted, this is only possible when you know exactly what you’re doing, but I’d say that applies to any tool out there.
Summary
Today we talked about what Hive Metastore is, how it works, and what it’s used for. We got a brief overview of several products that make use of Hive Metastore, and we discussed some of the technology’s pros and cons.
So, why do we need Hive Metastore at the end of the day? Because it stores all the information about the structure of our data and its location. This is the reason why many big companies are using it, to good effect.
We’re well aware that many of our customers are working with Hive Metastore or its Amazon implementation, Glue Data Catalog. They are both great tools, and users deserve to have a tool that will help them work with Metastore in a more efficient way than just querying things with Hive.



