

Big Data Tools EAP 6: Google Cloud Storage, Proxy, Kerberos, and Parquet Improvements

It’s been a while since our last update, but today we’re excited to give you a new EAP build. Originally we planned to exclusively work on bug fixes and stability improvements in this build. However, we couldn’t resist and added a completely new feature that has been on our roadmap for some time – integration with Google Cloud Storage.
Using the Google Cloud Storage integration is similar to working with AWS S3. Once you’ve configured a Google Cloud Storage bucket configuration in Big Data Tools Connections, you’ll see it and its contents in the Big Data Tools tool window.
Here’s what the configuration page looks like:
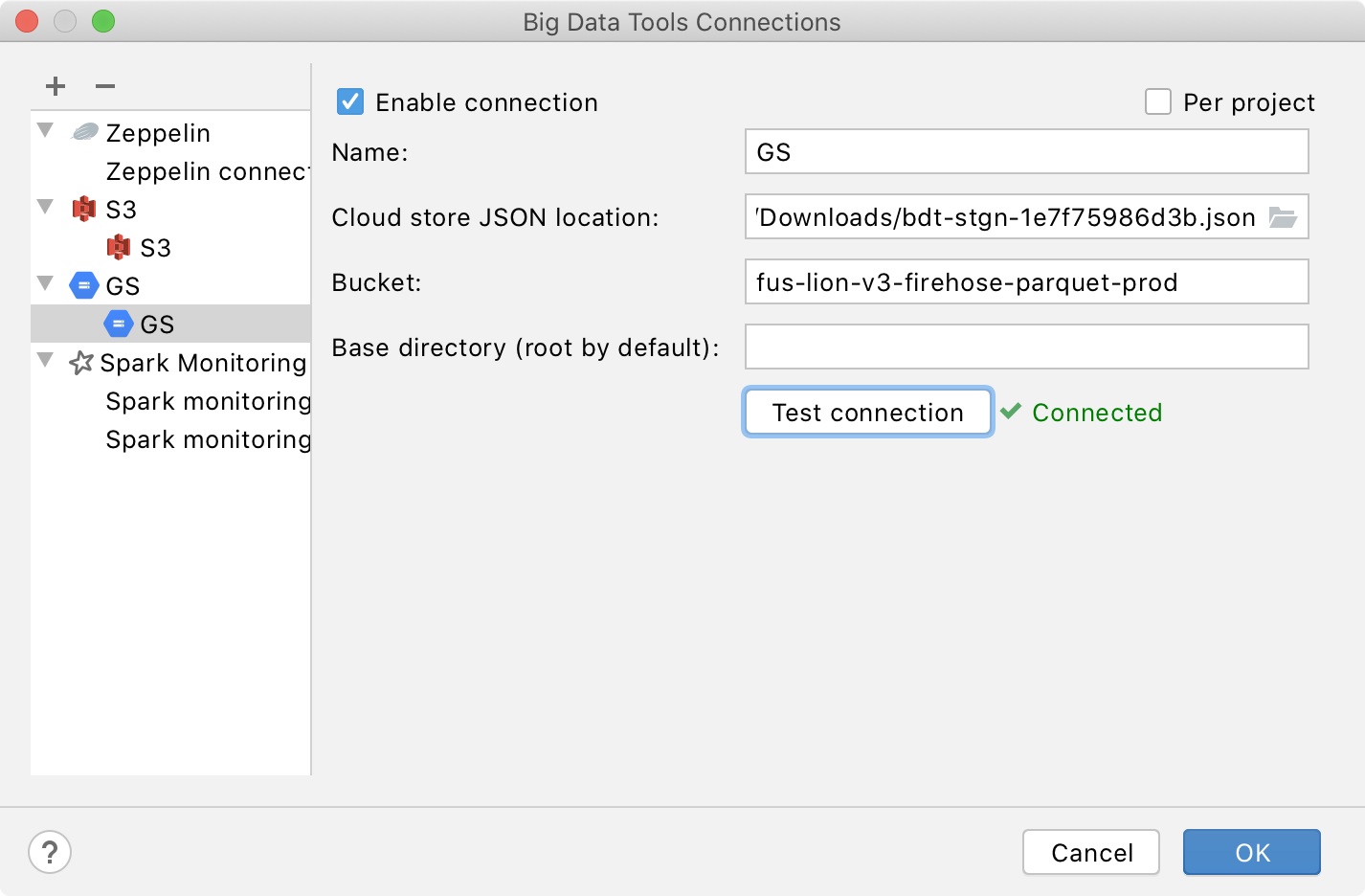
You have to specify the path to your credentials JSON file, choose a bucket, and optionally a prefix if you’d like to work with a specific subfolder.
Once the bucket is configured, you’ll see the files and folders hierarchically in the Big Data Tools tool window:
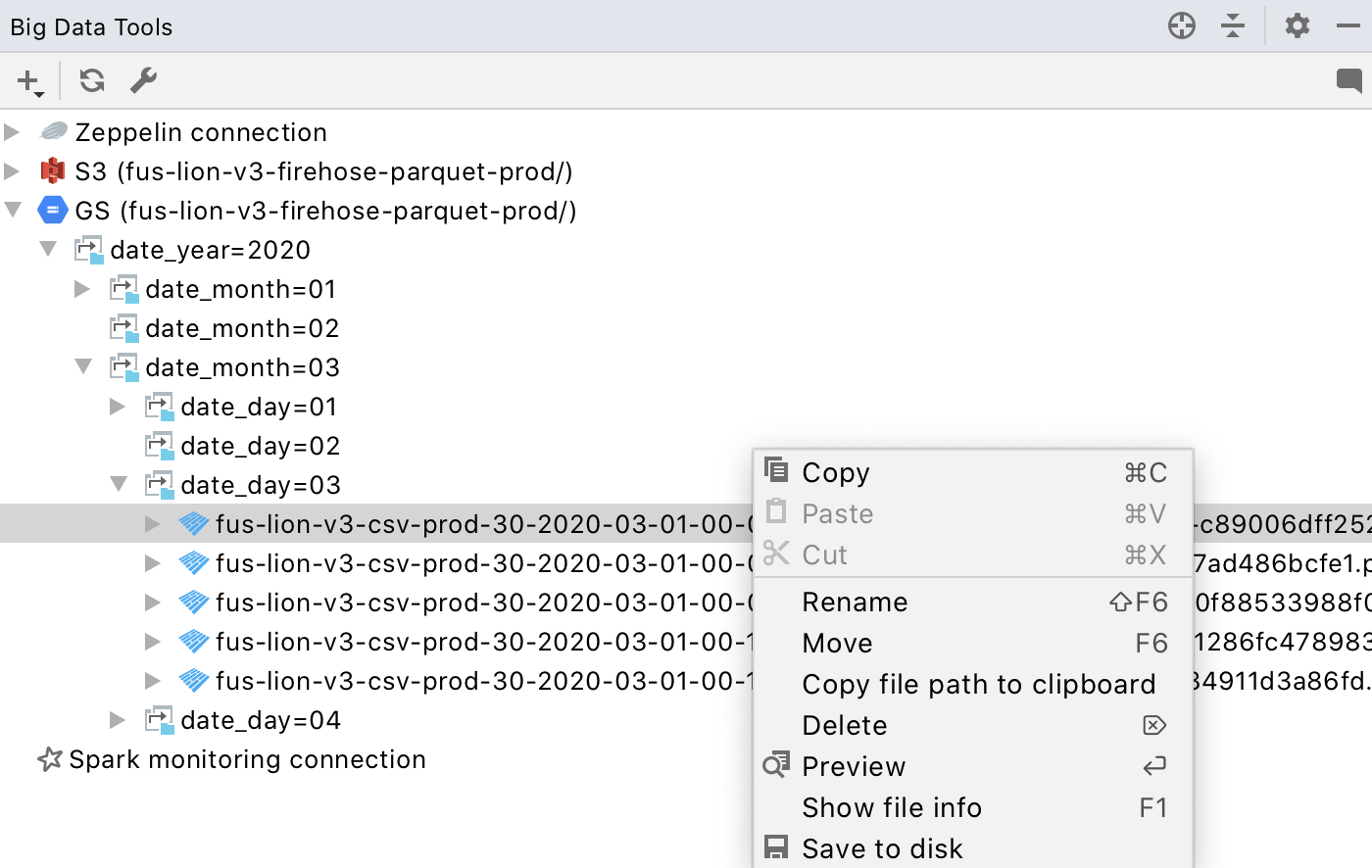
The context menu provides the same actions that work for AWS S3. You can copy, move, and rename your files and folders, download them to your local disk, and open them for a preview. In the case of a preview, the IDE downloads only a chunk of the file. This is very handy if you’d like to preview a large file, e.g. a Parquet or CSV.
Speaking of Parquet support, we’ve made certain improvements. First, we’ve fixed some edge cases in which it didn’t work. Second, we’ve reworked the appearance of the header to properly display the headers of the column and allow the user to sort the rows by any of the columns:
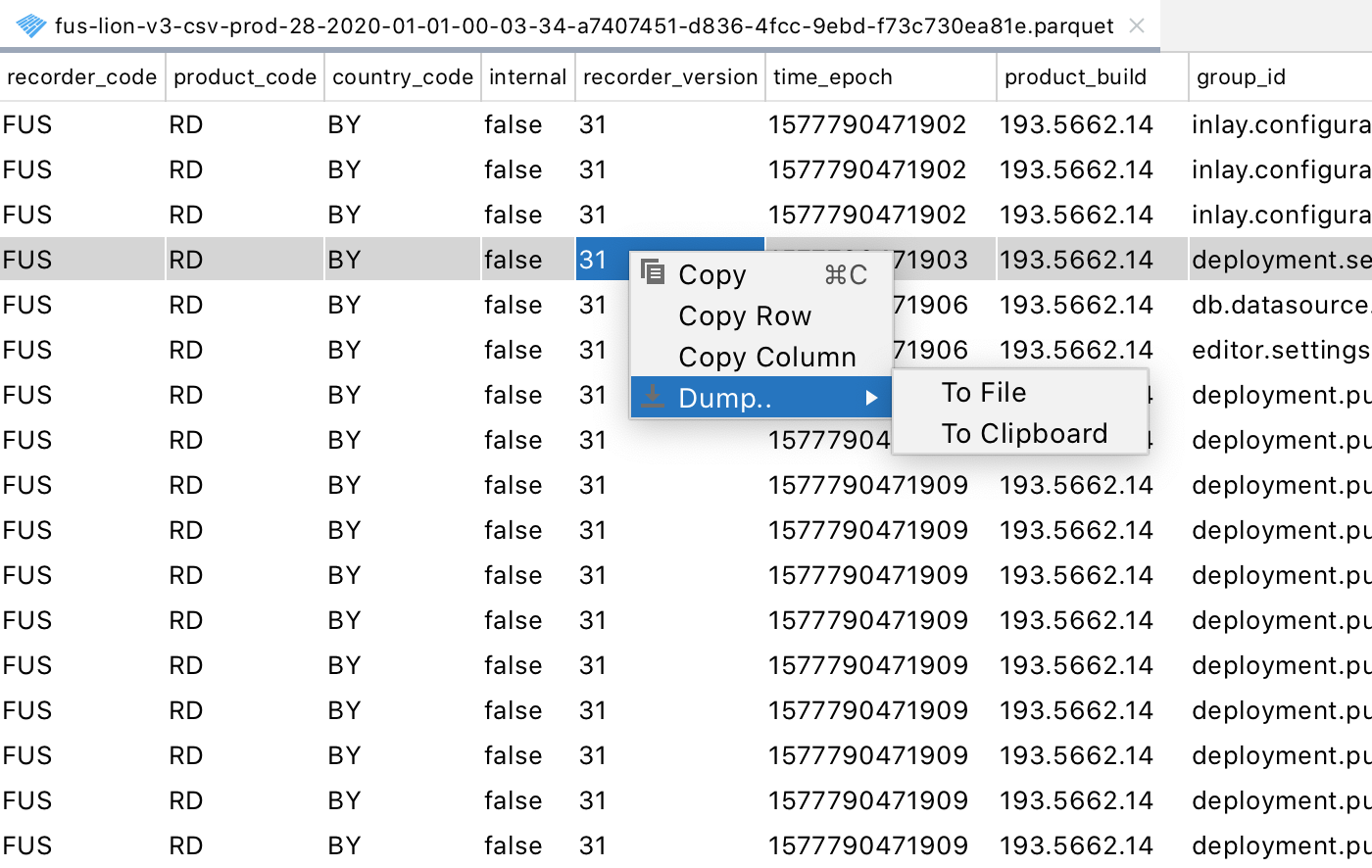
Last but not least, we’ve added actions that let you copy the selected values, columns, or rows, or dump the whole document to the clipboard or a .CSV file.
The connection configuration for Spark and Zeppelin now supports HTTP proxies. Now you can configure a proxy for any of the connections in the Big Data Tools Connections settings:
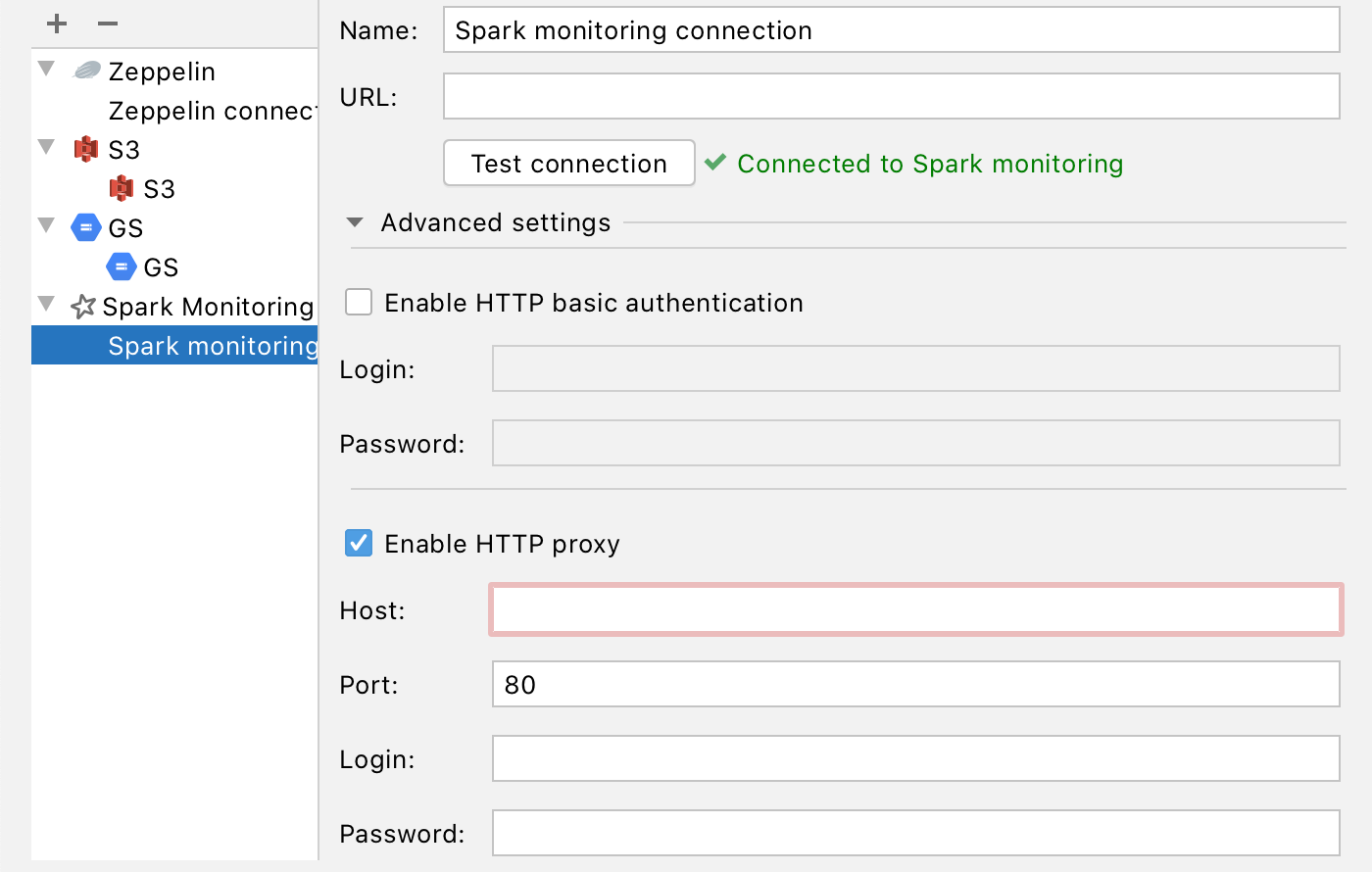
We hope this will make it easier for you to connect to Spark and Zeppelin in your secure environments.
Speaking of security, now the plugin also allows you to use and configure Kerberos authentication for connecting to your Spark server:
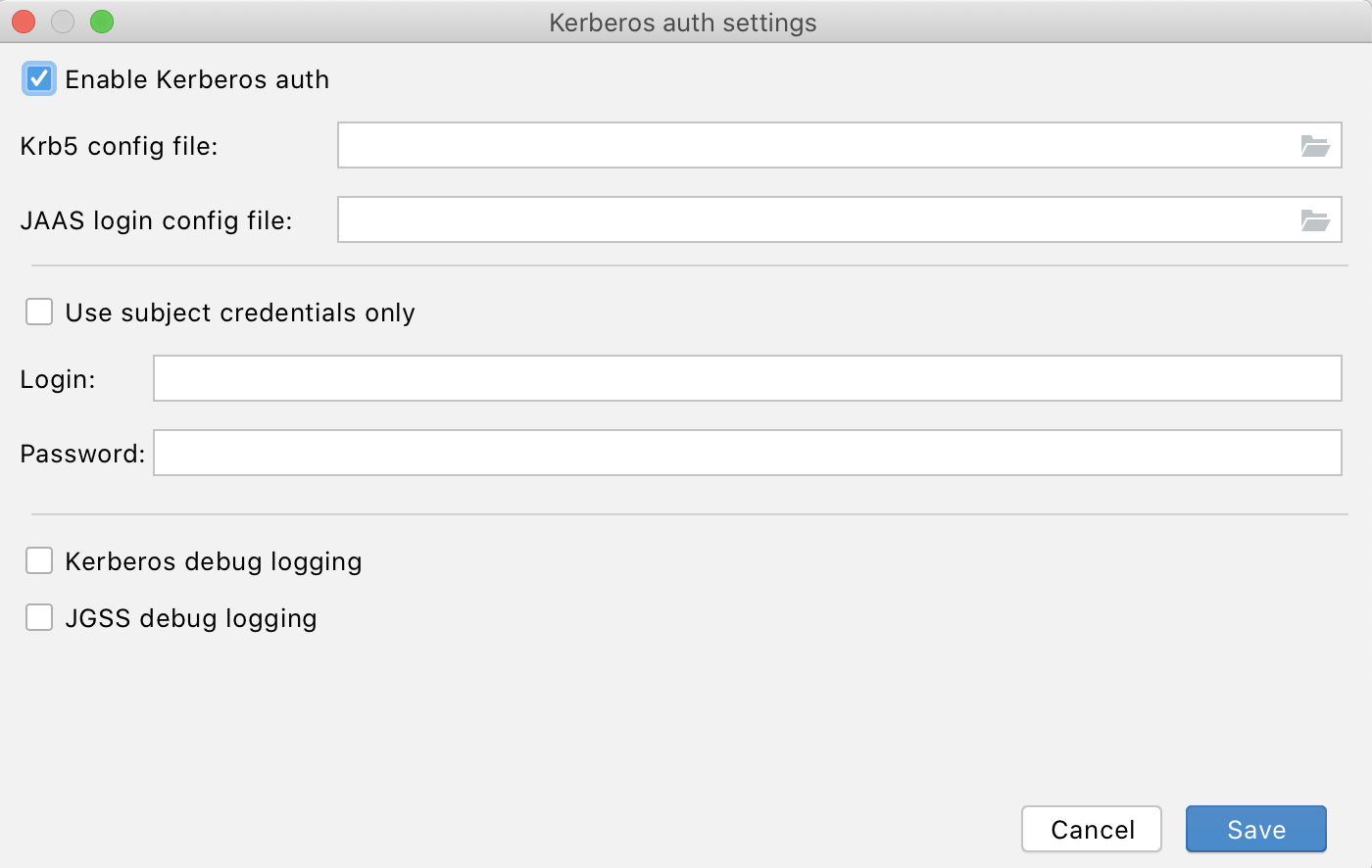
For more details on how to use the HTTP proxy and Kerberos, please see the updated documentation.
Those are all the major improvements in this update. The full list of changes (bug fixes and minor improvements) can be found in the release notes.
Having said that all, we’d like to ask you to try the new version of the plugin and share your feedback and bug reports with us.
If you have an idea for a cool feature that the Big Data Tools plugin could add in the future, please share it here in the comments or in the bug tracker, use this feedback form, or sound off in our Slack workspace. Thanks a lot!
The Big Data Tools team
The Drive to Develop







