

Big Data Tools EAP Is Now Also Available for DataGrip and PyCharm

At the end of last year, we announced a preview of the IntelliJ IDEA Ultimate plugin that integrated Apache Zeppelin notebooks into the IDE. At the same time we shared our roadmap, in which we promised to support more tools for working with Big Data. Since then, the plugin team has been working hard and has extended the plugin with support for Apache Spark, Apache Hadoop’s HDFS, AWS S3, Google Cloud Storage, and Parquet files.
Because the plugin originally started with the Scala support in Zeppelin notebooks, it was reasonable for it to only be available for IntelliJ IDEA Ultimate. Now that the plugin supports a much wider set of scenarios and tools, the time has come to make it available for other IDEs too. With that, we are excited to announce that Big Data Tools is now also available for DataGrip and PyCharm Professional.
Why DataGrip and PyCharm? Big Data Tools is one of the first JetBrains plugins that aims to solve problems involving both code and data. Since the plugin offers tools for working with data, we think it’s logical to make the plugin available to DataGrip users. We believe the plugin will extend the capabilities of DataGrip users when it comes to working with distributed file storage systems and columnar file formats. At the same time, the users of PyCharm who use PySpark or who also work with data will benefit from having this plugin available in their IDE.
It’s important to highlight that Big Data Tools is still under EAP and has some limitations. One of the most important limitations, for now, is that the current version of the plugin for PyCharm and DataGrip offers all features that are available in IntelliJ IDEA except Zeppelin notebooks. Adding Zeppelin notebooks support is in our roadmap and we hope to have it soon.
The current feature set includes:
- A file browser for distributed file storage systems, such as AWS S3, HDFS, GCS (support for other cloud storage is coming soon, too, e.g. Microsoft Azure). With this browser, you can browse folders and files, preview files, and manage files, e.g. creating, copying, renaming, deleting, uploading, and downloading them.
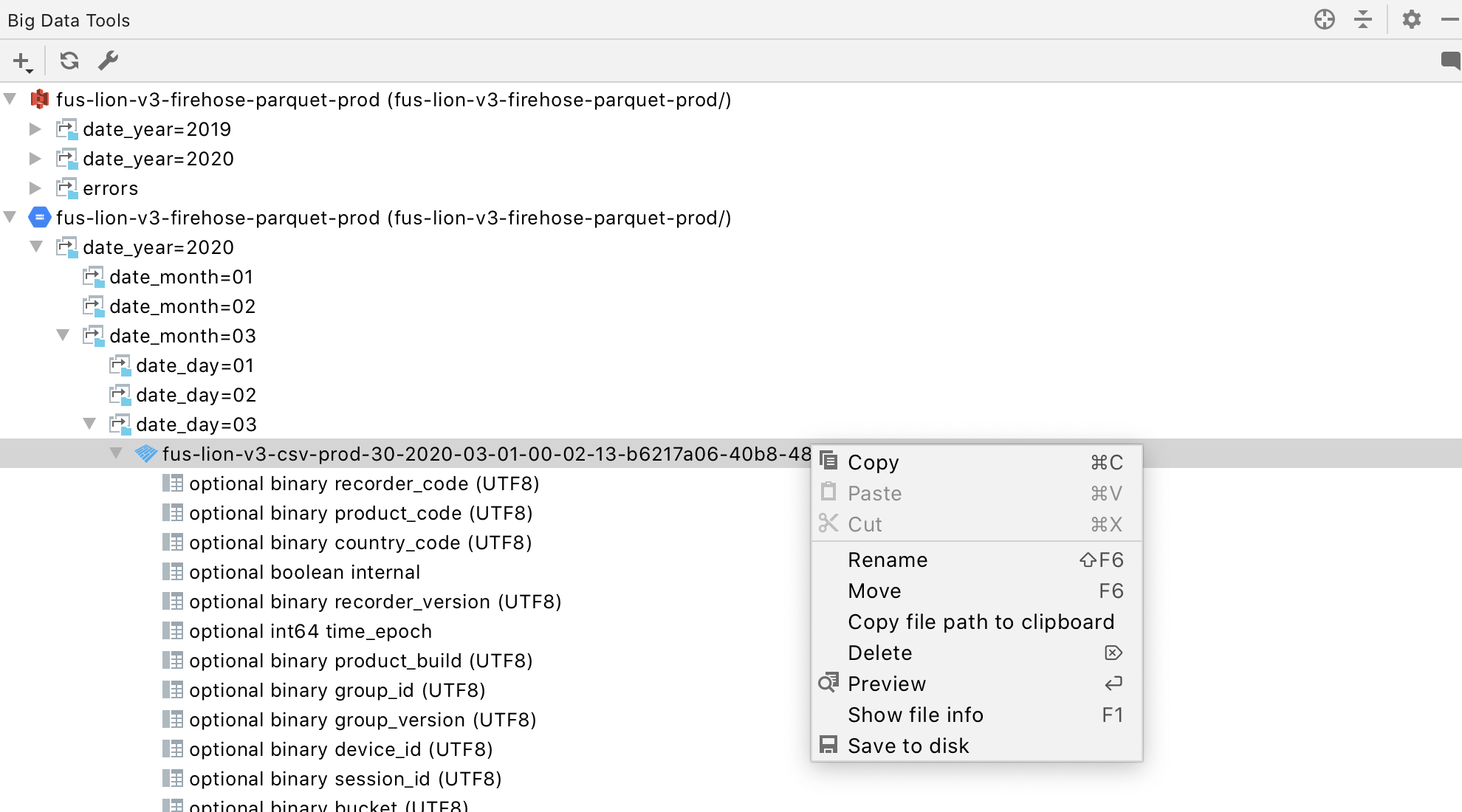
- A viewer for columnar file formats, such as Parquet (the support for other formats is coming soon too, e.g. Avro and ORC).

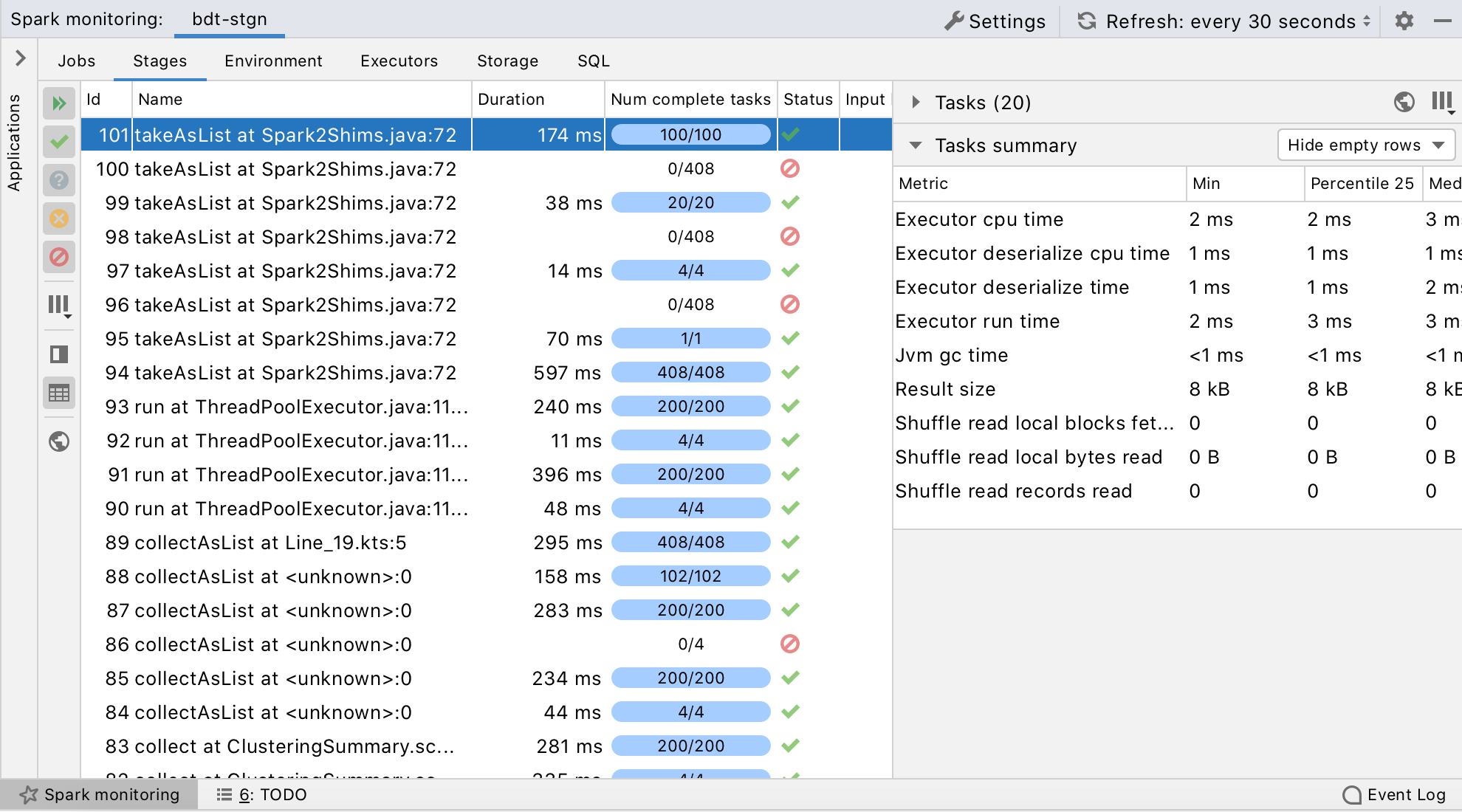
- A monitoring console for Spark clusters. With this console, you can browse cluster nodes, Spark jobs, their stages, and tasks.
Please note that the plugin is currently available for IDEs with version numbers 2020.1 or higher.
Additional information on the plugin can be found on JetBrains Marketplace.
Documentation for the plugin is now available for both DataGrip and PyCharm.
The easiest way to install the plugin is by opening the IDE’s Plugin settings, clicking Marketplace, searching for “Big Data Tools”, installing and then restarting the IDE.
Feel free to try the plugin, share your feedback, and spread the word!
The JetBrains team
The Drive to Develop







