

Better AI Depends on Better Data: We Need Your Help


Update (November 10, 2025):
We’d like to provide an important update regarding the delivery of the detailed data-sharing functionality described in this post. While we originally planned to release these features in the 2025.2.X minor update, delivery has been postponed to version 2025.3.1 of JetBrains IDEs.
We’ve made this change because of our commitment to addressing the feedback provided by you, our users. We are refining the safeguards for data sharing based on the use cases you shared with us, and we have introduced several new changes that will allow us to enable more granular controls per project in the future.
We’ve also streamlined the opt-out mechanism for non-commercial users, making it faster and more user-friendly. Thank you for your collaboration and input as we work to ensure a smoother implementation!
TL;DR
Over the past few years, AI has made remarkable progress, but it doesn’t always deliver what professional developers need. One key reason is that most models are trained on public datasets that don’t reflect the complex, real-world scenarios faced by professional developers every day. Without such real-world data, our AI tools will fall short. To improve them, JetBrains – like the rest of the industry – needs to learn from actual usage.
We are asking our users to help with this, and here’s how it works:
What is changing: JetBrains IDEs now have the ability to collect detailed code-related data. However, we do not collect data from our commercial users without first obtaining explicit, informed consent. The option can be disabled by individual users in the IDE settings, and there is an additional organization-level safeguard that prevents data sharing from individual user machines and IDE instances unless authorized by an admin in the organization’s JetBrains Account.
When this change will take effect: With the 2025.3.1 update of JetBrains IDEs.
Who is affected:
- Companies willing to participate – admins can enable data sharing at the organizational level. To support early adopters, we’re offering a limited number of free All Products Pack subscriptions to organizations willing to participate while we explore this program.
- Individuals using a free, non-commercial license – data sharing is enabled by default, but you can turn it off at any time in the settings. A notification about the update will be displayed on the first launch of the corresponding version, and no data will be collected until this notification has been displayed.
Who is NOT affected:
- For companies that are not willing to opt in to the program, nothing changes, and admins remain in full control.
- For individuals using commercial licenses, free trials, free community licenses, or EAP builds, nothing changes.
For more details, please refer to the below blog post, the data collection notice, and the data collection FAQ.
AI is changing the way software is built, but it’s still a tool
For over 25 years, JetBrains has been building professional development tools that give you the power to turn your vision into code while enjoying the development process. We see AI as a revolutionary tool for advancing this mission, and while progress in AI has been significant, we know it can still be improved. Currently, AI already helps with many tasks, showing impressive results for simple and well-defined cases. But the quality of its output quickly degrades in complex scenarios typically seen in professional development environments, leading to mistakes, gaps in logic, or even hallucinated code.
Input data and feedback signals are essential for making AI work better
All AI layers can be trained, engineered, and improved, and the results they deliver depend on the quality of the input data and feedback signals. Today, most LLMs are trained on the same publicly available datasets, and we’re only beginning to see larger companies adopt real-world, closed-loop feedback from users to further enhance model performance. The result? AI tools that are great for simple tasks and greenfield projects, but fail to solve real problems and properly adapt to existing codebases. LLM providers recognize this, and their approaches to data collection have started to evolve.
In theory, the answer is right in front of us. Our IDEs help millions of professional developers complete everyday tasks – from boring and routine ones to solving the most advanced engineering problems. That is precisely the data that could be used to refine our models. But we also know how sensitive this is. Some information must stay private, as your solutions are your intellectual property and your whole business is often in your code.
To validate the idea that real data can actually improve AI output, we recently started collecting this sort of data inside our company and applying it to train our models. The results so far have been promising, but to take the next step forward, we need to scale the amount and variety of data we use.
We respect both individual and corporate privacy policies, and we are transparent in asking for your permission to collect this data. Data sharing is always your choice. It is never an obligation. If you decide to help, any data you share will be handled responsibly, in full compliance with the EU data protection laws. By contributing, you help us make AI tools smarter, safer, and more useful for the whole developer community. We would be truly grateful for your cooperation.
What exactly will improve
By sharing your data, you will shape the tools you rely on every day. Your data will help JetBrains ensure that:
- Unsafe code is detected and filtered out, making it less likely to be introduced into your code base. This is particularly important as more teams are starting to delegate longer-running tasks to coding agents without a strong security and test posture already in place.
- We can handle high-volume, low-intelligence tasks at a lower cost than would be possible using a foundation model alone.
- You benefit from smarter code completion, clearer explanations, fewer false positives, and AI that truly understands professional workflows – not just artificial examples in over-represented languages from the web, where code quality can be inconsistent. We’re building this for working developers, and your real‑world use cases make all the difference.
We’re also committed to giving back. For example, Mellum – our purpose‑built LLM specialized in code completion – is open source and available on Hugging Face and Amazon Bedrock.
Two layers of data
- Currently, our products collect anonymous telemetry – generalized, anonymous statistics about how features are used (like time spent, clicks, or general workflows).
- We’re now adding the option to allow the collection of detailed code‑related data pertaining to IDE activity, such as edit history, terminal usage, and your interactions with AI features. This may include code snippets, prompt text, and AI responses.
That sounds like a lot, and it is, but that’s where the real value for improvements comes from. If you allow us to collect this data, we will make sure that:
- No sensitive or personal information is shared.
- Data is properly secured.
- Access is restricted to authorized personnel and use cases.
Read more about what data is collected and how it is protected.
Anonymous telemetry is critical for evaluating feature usage and performance. Detailed code-related data is essential for training specialized models like Mellum that are best suited for a specific purpose, such as generation speed, cost efficiency, or accuracy on complex professional tasks involving large codebases. It’s also fundamental to the feedback loop and to faster iterations on any AI features we are building.
We will use this data for product analytics and model evaluation, as well as to train our own models, with the sole purpose of making our products perform better in your day-to-day work. We will not share this data with third parties.
Your code is your craft, and we’ll treat it that way – you’re completely in control. You can change your data-sharing preferences in the IDE at any time and withdraw consent with immediate effect.
Ready to help?
To get data for improving our products, including training AI, we’re launching several data sharing programs, all designed with your privacy in mind:
- For non-commercial users: Option to opt out
We already provide some of our IDEs at no cost for education, hobby projects, and open-source work. In these cases, data sharing will be enabled by default, but detailed code-related data sharing can be disabled at any time in the settings.
- For organizations
Users with organization licenses can only share detailed code‑related data if an admin enables sharing at the company level, preventing accidental IP leaks. As we are still in the exploratory stage for this option, we will be offering free All Products Pack licenses to a select number of companies willing to share data. Join the waitlist if you’re interested. We will review the submissions and notify you if you are approved.
For individuals using commercial licenses, free trials, free community licenses, or EAP builds, nothing changes for now. You can still opt in via the settings if you are willing to share data with JetBrains (and your admins, if any, allow it). For companies that are not willing to opt in to the program – nothing changes, and admins are in control.
When the changes will take place
The new and updated data-sharing options will be released with the 2025.3.1 update of JetBrains IDEs. Non-commercial users will get a notification about the updates in the terms of use. For holders of other types of licenses, if you never provided consent, nothing will change.
We’ve also introduced changes to the JetBrains AI Terms of Service to make sure the new data collection mechanisms are covered.
Where to find the settings
You can find the settings that control the data sharing in JetBrains IDEs in Settings | Appearance & Behavior | System Settings | Data Sharing:
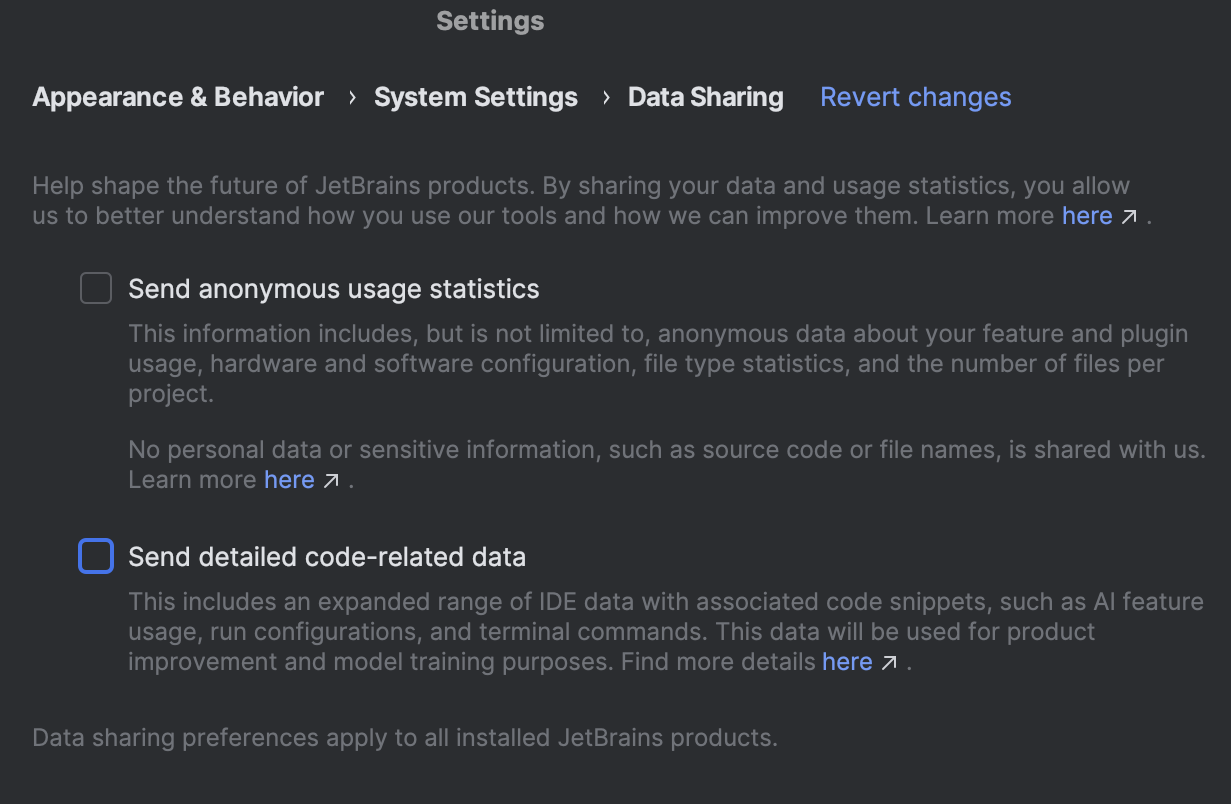
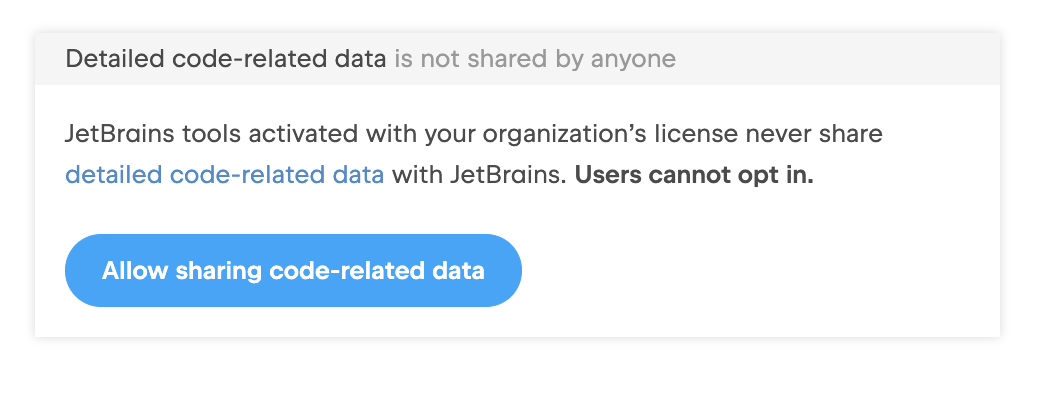
For companies that are unwilling or, for legal reasons, unable to opt in to the program, nothing changes, and their admins remain in full control. Admins can check the settings located in their JetBrains Account:
A fair deal, on your terms
We know this topic can be polarizing, but we truly believe in the value this change can bring to our tools and to you. We are transparent about our intentions and actions, and the ultimate choice about whether to share your data is up to you.
If you’re comfortable contributing, please enable data sharing in your IDE or have your company join the waitlist. Thank you for helping us build AI tools that meet the demands of real‑world development – securely, responsibly, and under your control.






